30
Deriving Paraphrases for Highly Inflected Languages from Comparable Documents Kfir Bar, Nachum Dershowitz Tel Aviv University, Israel
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | ann-robertson |
| View: | 220 times |
| Download: | 0 times |

Deriving Paraphrases for Highly Inflected Languages from Comparable Documents
Kfir Bar, Nachum Dershowitz
Tel Aviv University, Israel

Paraphrases
I exposed my secret about my personal life
I spilled the beans and told Jacky I loved her
China did not change its policy toward Taiwan
Beijing’s policy toward Taiwan remains unchanged
phrase level
sentence level

Motivation? MT coverage problem
10000 100000 10000000.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
0.900
unigrams
bigrams
trigrams
4-grams
Arabic
covered ngrams
parallel corpus size

Related work on paraphrasing
• Continuing our previous work on Arabic synonyms (Bar and Dershowitz, AMTA, 2010)
• Using parallel corpus (Callison-Burch et al., 2006)
• Using monolingual corpus (Marton et al., 2009)
• Using comparable documents (Wang and Callison-Burch, 2011)
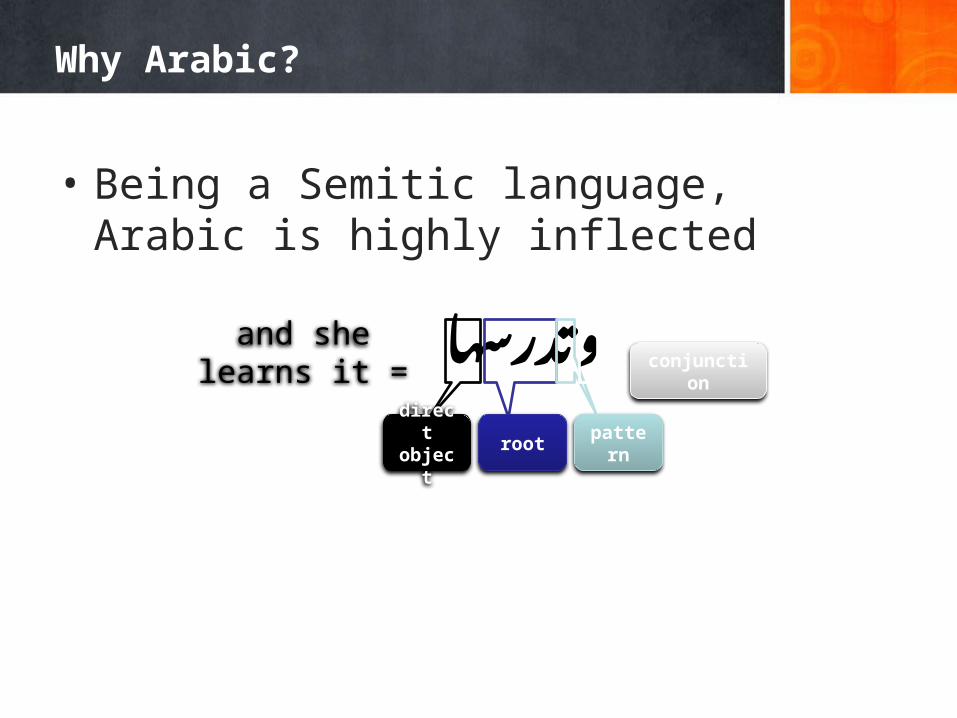
Why Arabic?
• Being a Semitic language, Arabic is highly inflected
وتدرسهاdirect object root pattern
conjunctionand she learns it =

Extracting paraphrases
• Inspired by:Extracting Paraphrases from a Parallel Corpus, Regina Barzilay and Kathleen R. McKeown (2001)
• Working on Arabic comparable documents

Preparing the corpus
• Using Arabic Gigaword. We automatically paired documents –– published on the same day
– maximize the cosine similarity over the lemma-frequency vector
AFP XIN
24.12.2002
24.12.2002
25.12.2002
27.12.2002
24.12.2002
24.12.2002
24.12.2002
27.12.2002
max cos similarity

Preparing the corpus
• 690 document pairs
• Manual evaluation by two Arabic speakers: – randomly selected 120 document pairs
– question: “Do both documents discuss the same event”?
83%
4% 13%
Correct1 evaluatorWrong

Preprocessing
• AMIRAN [Diab et al. – to appear] is a tool for finding context-sensitive morpho-syntactic information– Segmentation– Diacritized lemma– Stem– Full part-of-speech tag– Base-phrase tag– Named-entity-recognition (NER) tag

Extracting paraphrases: co-training technique
extracting pairs of phrases
co-training (context <-> phrase)
itera
tions
paraphrases
alignmentparaphrases✗
✗
✔
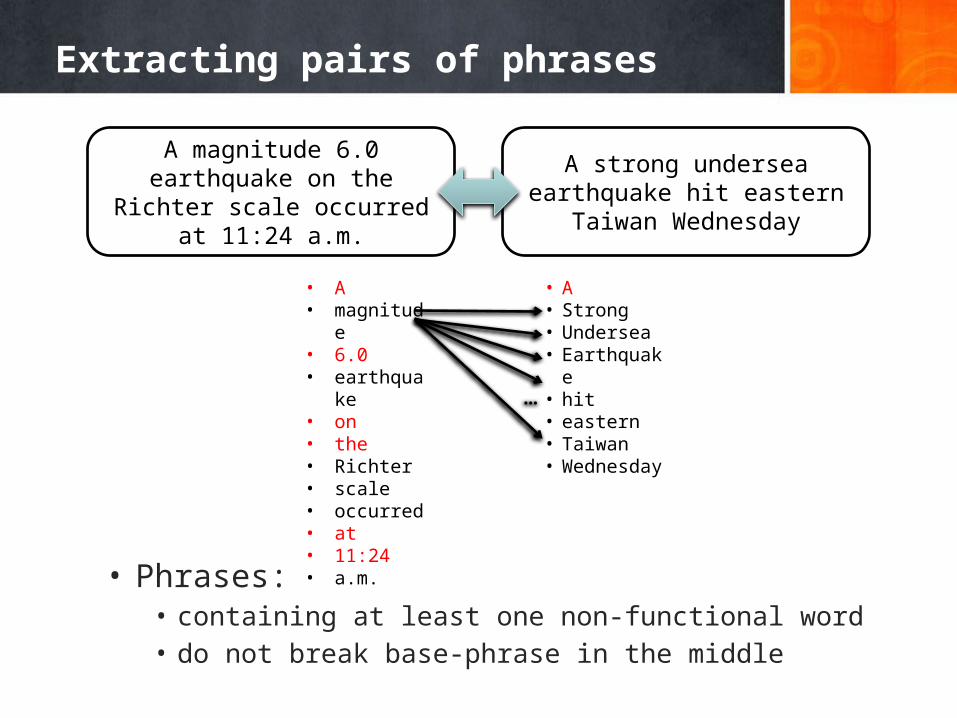
Extracting pairs of phrases
• Phrases:• containing at least one non-functional word• do not break base-phrase in the middle
A magnitude 6.0 earthquake on the Richter scale occurred at
11:24 a.m.
A strong undersea earthquake hit eastern Taiwan Wednesday
• A • magnitude • 6.0 • earthquake • on • the • Richter • scale • occurred • at • 11:24 • a.m.
• A • Strong• Undersea• Earthquake• hit • eastern • Taiwan • Wednesday
…

Co-training
dEA xAfyyr swlAnA Almnsq Al>Ely llsyAsp AlxArjyp wAl>mnyp
dEA xAfyyr swlAnA Almmvl Al>ElY llsyAsp AlxArjyp fy
Inner (Phrase)
Outer (Context)
Outer (Context)

Extracting paraphrases
We maintain two sets
unlabeledlabeled
positive = paraphrases
negative = NOT paraphrases
instances
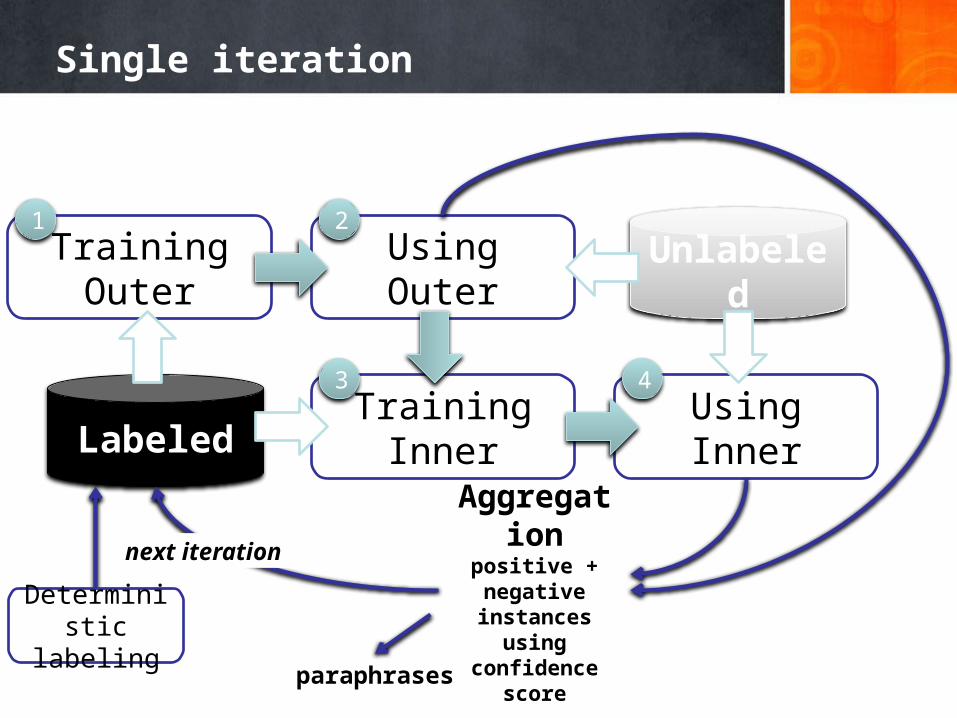
Single iteration
Unlabeled
Labeled
Training Outer1
Using Outer2
Training Inner3
Using Inner4
Aggregationpositive + negative
instances using confidence score
Deterministic labeling
next iteration
paraphrases

Deterministic labeling of potential paraphrases
Labeling similar phrases as positive
A strong undersea earthquake hit eastern Taiwan Wednesday, and there are no immediate reports of damage or casualties, according to reports from Taipei.The earthquake registering 6.0 on the Richter scale struck at 11:24 a.m. local time (0324 GMT), was about 76 km southeast of Hualien on the eastern coast, at a depth of 4 km, Taiwan's Central Weather Bureau said in a statement.
A magnitude 6.0 earthquake on the Richter scale occurred at 11:24 a.m. Wednesday in the waters off Hualian, eastern Taiwan, with no immediate reports of casualties or property damage, the Central Weather Bureau (CWB) said.The quake's epicenter was 76 kilometers southeast of Hualien, according to the CWB.

Deterministic labeling of potential paraphrases
• Negative examples are also labeled – in the first iteration (single words):
words don’t have similar gloss values– not using in subsequent iterations

The outer (context) classifier
Features
Feature Description
lemma, POS, NER, BP of each context word
gloss-match rate left and right
lemma-match rate left and right
Using SVM, quadratic kernel

The inner (phrase) classifier
Features
Feature Description
POS, NER, BP of each phrase word
morphological features (Boolean): conjunction, possessive, determiner, prepositions
of each phrase word
length number of words
n-gram score 2-4 grams
Experiments & results
• Arabic– 240 document pairs (165K words)– 5 iterations

Experiments & results
negative pairs positive pairs unique paraphrases
unlabeled pairs
Initialization 22,885,104 66,317 19,480
After iteration 1 23,799,787 (+1,726) 68,043 3,166,935
After iteration 2 24,759,791 (+3,757) 71,800 954 2,790,574
After iteration 3 25,349,489 (+2,623) 74,423 416 2,198,253
After iteration 4 26,221,889 (+451) 74,874 331 1,557,931
After iteration 5 26,900,833 (+101) 74,975 72 878,987
Total 1,773

Evaluation
• 2 native speakers• Pairs are provided with their context• 4 labels:– paraphrases – entailment
(e.g. a magnitude 6.0 earthquake the quiver)– related
(e.g. San Diego ~ Los Angeles)– wrong
(e.g. a poor and little-developed province ≠its resource-rich northwestern province)

Manual evaluation
Length Evaluated Paraphrases Entailment Related Wrong Precision2 120 49 12 25 34 71%
3 95 45 10 11 31 69%
4 70 26 4 5 35 50%
5 50 24 2 7 20 66%
Total 335 144 28 48 120 66%
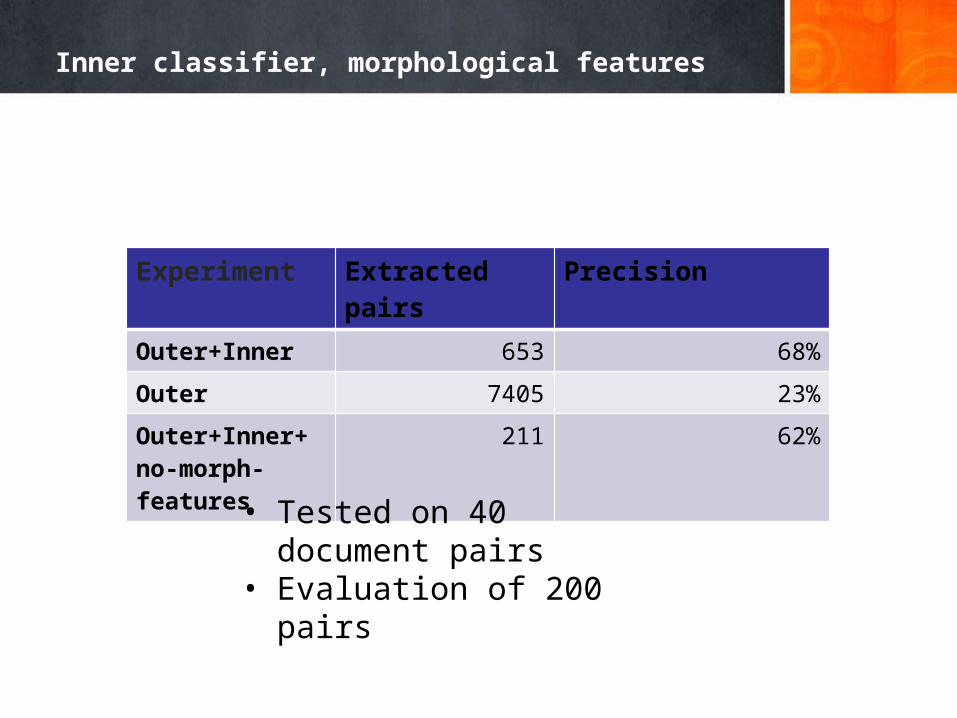
Inner classifier, morphological features
Experiment Extracted pairs PrecisionOuter+Inner 653 68%
Outer 7405 23%
Outer+Inner+no-morph-features
211 62%
• Tested on 40 document pairs• Evaluation of 200 pairs

Conclusions
• We will try to better understand the effect of the morphological features on Arabic
• Utilize the paraphrases for improving Arabic-English translation system
corpus size extracted document pairs
pairs used in paraphrasing
words used in inference
unique paraphrases
Precision
Arabic ~20,000,000 690 240 165,369 1,773 66%
English ~1,000,000 294 40 11,600 525 63%
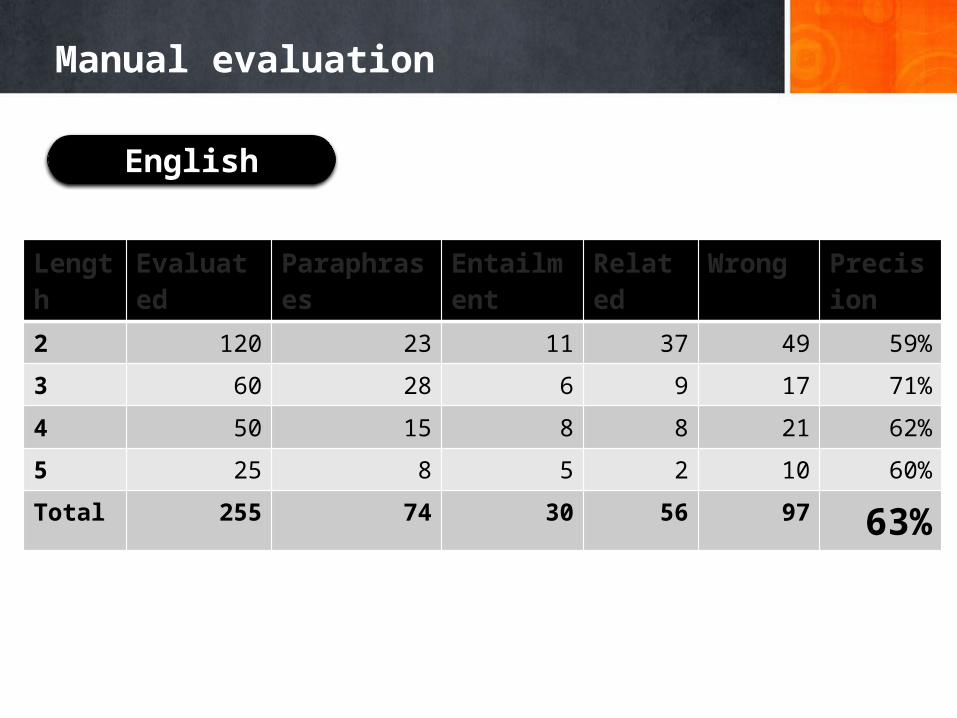
Manual evaluation
Length Evaluated Paraphrases Entailment Related Wrong Precision2 120 23 11 37 49 59%
3 60 28 6 9 17 71%
4 50 15 8 8 21 62%
5 25 8 5 2 10 60%
Total 255 74 30 56 97 63%
English

Experiments & results
negative pairs positive pairs unique paraphrases
unlabeled pairs
Initialization 876,947 32,972 3,597
After iteration 1 960,840 (+868) 33,840 86,648
After iteration 2 1,058,970 (+1,633) 35,473 230 58,648
After iteration 3 1,109,746 (+1,194) 36,667 177 21,332
After iteration 4 1,127,643 (+339) 37,006 94 6,677
After iteration 5 1,128,475 (+52) 37,058 24 1,490
Total 525
English

Co-training
was 76 kilometers southeast of Hualien according to the
about 76 km southeast of Hualien on the eastern
Inner (Phrase)
Outer (Context)
Outer (Context)

Manual evaluation
Length Evaluated Paraphrases Entailment Related Wrong Precision2 120 49 12 25 34 71%
3 95 45 10 11 31 69%
4 70 26 4 5 35 50%
5 50 24 2 7 20 66%
Total 335 144 28 48 120 66%
Arabic

Experiments & results
negative pairs positive pairs unique paraphrases
unlabeled pairs
Initialization 22,885,104 66,317 19,480
After iteration 1 23,799,787 (+1,726) 68,043 3,166,935
After iteration 2 24,759,791 (+3,757) 71,800 954 2,790,574
After iteration 3 25,349,489 (+2,623) 74,423 416 2,198,253
After iteration 4 26,221,889 (+451) 74,874 331 1,557,931
After iteration 5 26,900,833 (+101) 74,975 72 878,987
Total 1,773
Arabic


















