50
Design and Implementation of a NoC- Based Cellular Computational System By: Shervin Vakili Supervisors: Dr. Sied Mehdi Fakhraie Dr. Siamak Mohammadi February 09, 2009
| Date post: | 02-Jan-2016 |
| Category: |
Documents |
| Upload: | erick-hubbard |
| View: | 215 times |
| Download: | 2 times |

Design and Implementation of a NoC-Based Cellular Computational System
By: Shervin Vakili Supervisors: Dr. Sied Mehdi Fakhraie Dr. Siamak Mohammadi
February 09, 2009

2
Outline
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

3
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

4
Introduction and Motivations (1)
Computing systems have played an important role in advances of human life in last four decades.
Number and complexity of applications are countinously increasing.
More computational power is required.
Three main hardware design approaches:
- ASIC (hardware realization)
- Reconfigurable Computing
- Processor-Based Designs (software realization)
Fle
xib
ilit
y
Pe
rfo
rma
nc
e

5
Introduction and Motivations (2)
Microprocessors are the most pupular approach.
- Flexibility and reprogramability
- Low performance
Architectural techniques to improve processor performance:
- Pipeline, out of order execution, Super Scalar, VLIW, etc.
Seems to be saturated in recent years.

6
Introduction and Motivations (3)
Emerging trends aim to achieve:
- More performance
- Preserving the classical software development process.
[1]

7
Why Multi-Proseccor?
One of the main trends is to increase number of processors.
Uses Thread-level Parallelism (TLP)
Similarity to single-processor:
- Short time-to market
- Post-fabricate reusability
- Flexibility and programmability
Moving toward large number of simple processors on a chip.

8
Number of Processing Cores in Different Products [3]
[3]

9
MPSoC Development Challenges (1)
MP systems faces some major challenges.
Programming models:
- MP systems require concurrent software.
- Concurrent software development requires two operations:
- Decomposition of the program into some tasks
- Scheduling the tasks among cooperating processors
- Both are NP-complete problems
- Strongly affects the performance

10
MPSoC Development Challenges (2)
- Two main solutions:
1. Software development using parallel programming libraries.
- e.g. MPI and OpenMP
- Manually by the programmer.
- Requires huge investment to re-develop existing software.
2. Automatic parallelization at compile-time
- Does not require reprogramming but requires re-compilation.
- Compiler performs both Task decomposition and scheduling.

11
MPSoC Development Challenges (3)
Control and Synchronization
- To Address inter-processor data dependencies
Debugging
- Tracking concurrent execution is difficult.
- Particularly in heterogeneous architecture with different ISA processors.

12
MPSoC Development Challenges (4)
All MPSoCs can be divided into two categories:
- Static scheduling
- Task scheduling is performed before execution.
- Predetermined number of contributing processors.
- Has access to entire program.
- Dynamic scheduling
- A run-time scheduler (in hardware or OS) performs task scheduling.
- Does not depend on number of processors.
- Only has access to pending tasks and available resources.

13
Introduction and Motivations
Basics of Evolvable Multiprocessor System
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

14
Proposal of Evolvable Multi-processor System (1)Proposal of Evolvable Multi-processor System (1)
This thesis introduces a novel MPSoC
- Uses evolutionary strategies for run-time task decomposition and scheduling.
- Is called EvoMP (Evolvable Multi-Processor system).
Features:
- Can directly execute classical sequential codes on MP platform.
- Uses a hardware evolutionary algorithm core to perform run time task decomposition and scheduling.
- Distributed control and computing
- Flexibility
- NoC-Based, 2D mesh, and homogeneous

15
All computational units have one copy of the entire program
EvoMP architecture exploits a hardware evolutionary core
- to generates a bit-string (chromosome).
- This bit-string determines the processor which is in charge of executing each instruction.
Primary version of EvoMP uses a genetic algorithm core.
Proposal of Evolvable Multi-processor System (2)Proposal of Evolvable Multi-processor System (2)

16
Target Applications
Target Applications:
- Applications, which perform a unique computation on a stream of data, e.g.:
- Digital signal processing
- Packet processing in network applications
- Huge sensory data processing
- …

17
Streaming Applications Code Style
Streaming programs have two main parts:- Initialization
- Infinite (or semi-infinite) Loop
;Initial;Initial
1- MOV R1, 01- MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, R17- MOV Output, R1
8- MOV R1, R28- MOV R1, R2
9- Genetic9- Genetic
10-JUMP L110-JUMP L1Two-Tap FIR Two-Tap FIR FilterFilter

18
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

19
EvoMP Top ViewEvoMP Top View
Genetic core produces a bit-string (chromosome)
- Determines the location of execution of each instruction
SW00
P-01
SW01
SW10 SW11
P-00
P-11P-10
Genetic Core
1- MOV R1, 01- MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, R17- MOV Output, R1
8- MOV R1, R28- MOV R1, R2
9- JUMP L19- JUMP L1
1- MOV R1, 01- MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, R17- MOV Output, R1
8- MOV R1, R28- MOV R1, R2
9-JUMP L19-JUMP L1
1- MOV R1, 01- MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, R17- MOV Output, R1
8- MOV R1, R28- MOV R1, R2
9- JUMP L19- JUMP L1
1- MOV R1, 01- MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, R17- MOV Output, R1
8- MOV R1, R28- MOV R1, R2
9- JUMP L19- JUMP L1
Chromosome: Chromosome: 0110110…110110110…11

20
How EvoMP Works? (1)How EvoMP Works? (1)
Following process is repeated in each iteration:
- At the beginning of each iteration:
- genetic core generates and sends the bit-string (chromosome) to all processors.
- Processors execute this iteration with the determined decomposition and scheduling scheme.
- A counter in genetic core counts number of spent clock cycles.
- When all processors reached end of the loop:
- The genetic core uses the output of this counter as the fitness value.

21
How EvoMP Works? (2)How EvoMP Works? (2)
Three main working statesThree main working states- Initialize:Initialize:
- Just in first populationJust in first population- Genetic core generates random particles.Genetic core generates random particles.
- Evolution: Evolution: - Uses recombination to produce new populations .Uses recombination to produce new populations .- When the termination condition is met, system goes to final state.When the termination condition is met, system goes to final state.
- Final:Final: - The best chromosome is used as constant output of the genetic core.The best chromosome is used as constant output of the genetic core.- When one of the processors becomes faulty, the system returns to evolution stageWhen one of the processors becomes faulty, the system returns to evolution stage
Initialize Evolution Final
Fault detected
Terminate

22
How Chromosome Codes the Scheduling How Chromosome Codes the Scheduling Data? (1)Data? (1)
Each chromosome consists of some small words (gene).
Each word contains two fields:
- A processor number
- Number of instructions
23
10
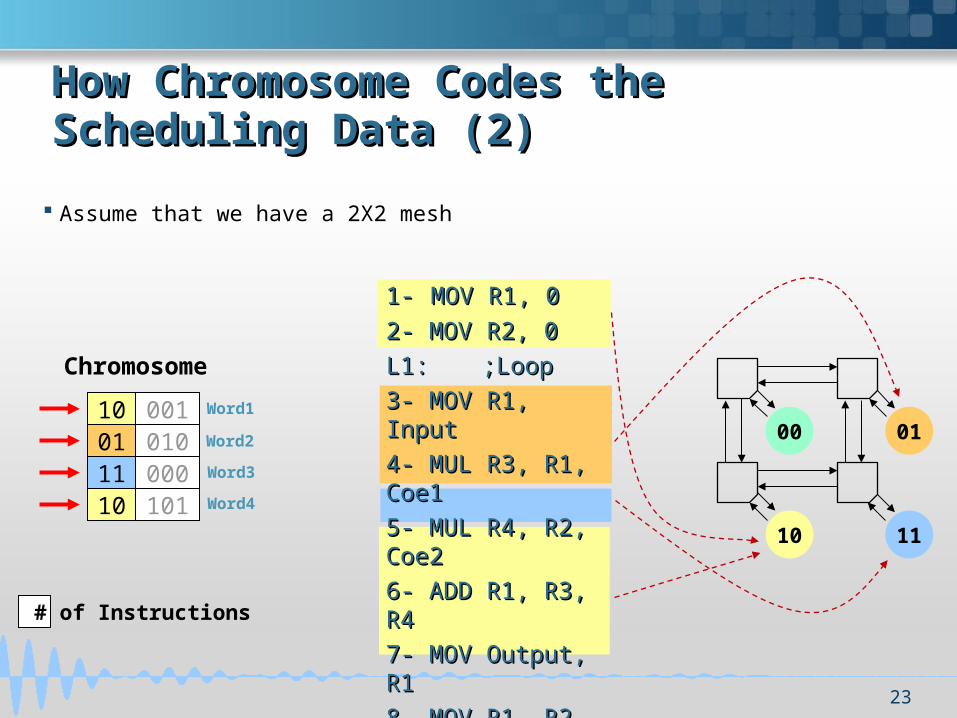
How Chromosome Codes the Scheduling How Chromosome Codes the Scheduling Data (2)Data (2)
Assume that we have a 2X2 mesh
10 001
# of Instructions
01 01011 00010 101
Chromosome
00
10
01
11
1-1- MOV R1, 0MOV R1, 0
2- MOV R2, 02- MOV R2, 0
L1:L1: ;Loop;Loop
3- MOV R1, Input3- MOV R1, Input
4- MUL R3, R1, 4- MUL R3, R1, Coe1Coe1
5- MUL R4, R2, 5- MUL R4, R2, Coe2Coe2
6- ADD R1, R3, R46- ADD R1, R3, R4
7- MOV Output, 7- MOV Output, R1R1
8- MOV R1, R28- MOV R1, R2
9- GENETIC9- GENETIC
10-JUMP L110-JUMP L1
Word1
Word2
Word3
Word4

24
Data Dependency ProblemData Dependency Problem
Data dependencies are the main challenge.
Must be detected dynamically at run-time.
Is addressed using:
- Particular machine code style
- Architectural techniques

25
EvoMP Machine Code Style
Source operands are replaced by line-number of the most recent instructions that has changed it (ID).
Will enormously simplify dependency detection.
10. ADD R1,R2,R3 ; R3=R1+R2
11. AND R2,R6,R7 ; R7=R2&R6
12. SUB R7,R3,R4 ; R4=R7-R3 12. SUB (11), (10), R4

26
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary
27
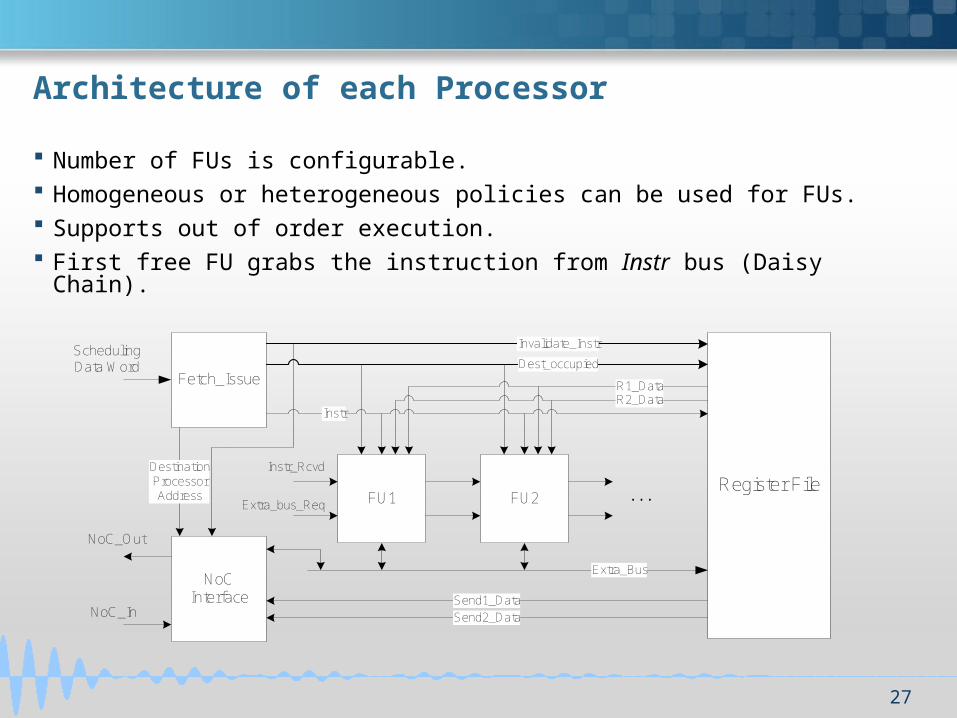
Architecture of each Processor
Number of FUs is configurable. Homogeneous or heterogeneous policies can be used for FUs. Supports out of order execution. First free FU grabs the instruction from Instr bus (Daisy Chain).
Fetch_Issue
Register File
NoC Interface
NoC_In
NoC_Out
Scheduling Data Word
FU1 FU2
Invalidate_Instr
Dest_occupied
InstrR2_DataR1_Data
Send2_Data
Send1_Data
Extra_Bus
...Instr_Rcvd
Extra_bus_Req
Destination Processor Address
28
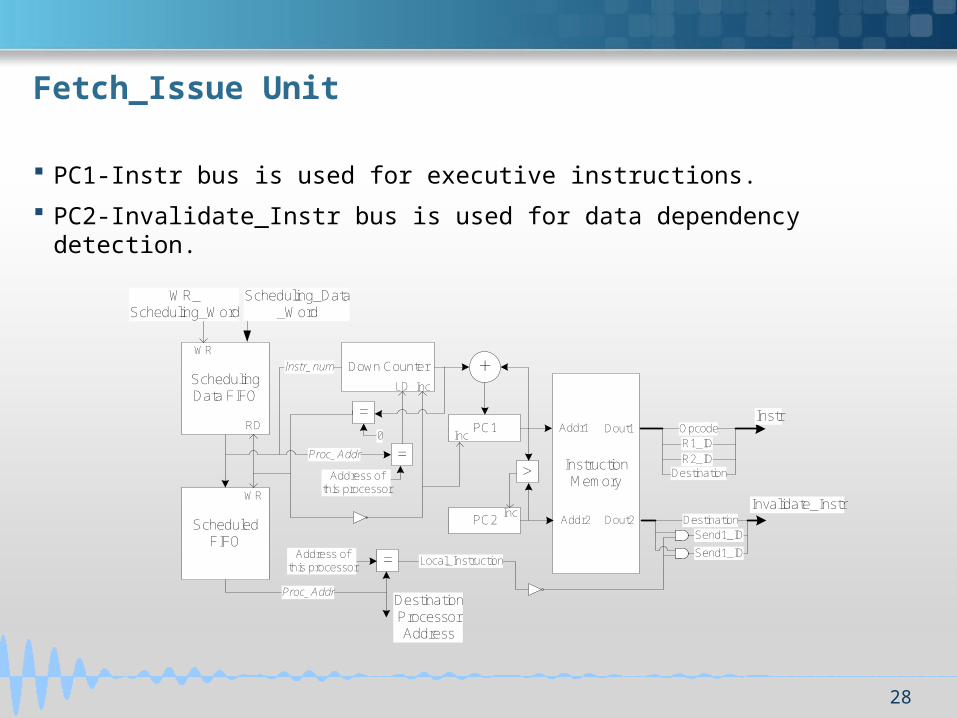
Fetch_Issue Unit
PC1-Instr bus is used for executive instructions.
PC2-Invalidate_Instr bus is used for data dependency detection.
Scheduling Data FIFO
Scheduled FIFO
=
PC1
PC2
Instruction Memory
+Down Counter
Proc_Addr
Instr_num
Address of this processor
=0
RD
WR
LD
OpcodeR1_ID
R2_ID
Instr
Destination
=Address of this processor
Proc_Addr
Local_Instruction
Send1_ID
Send1_ID
Invalidate_Instr
Destination
WR_Scheduling_Word
Scheduling_Data_Word
Addr1
Addr2
Dout1
Dout2
WR
>
Inc
Inc
Inc
Destination Processor Address
29
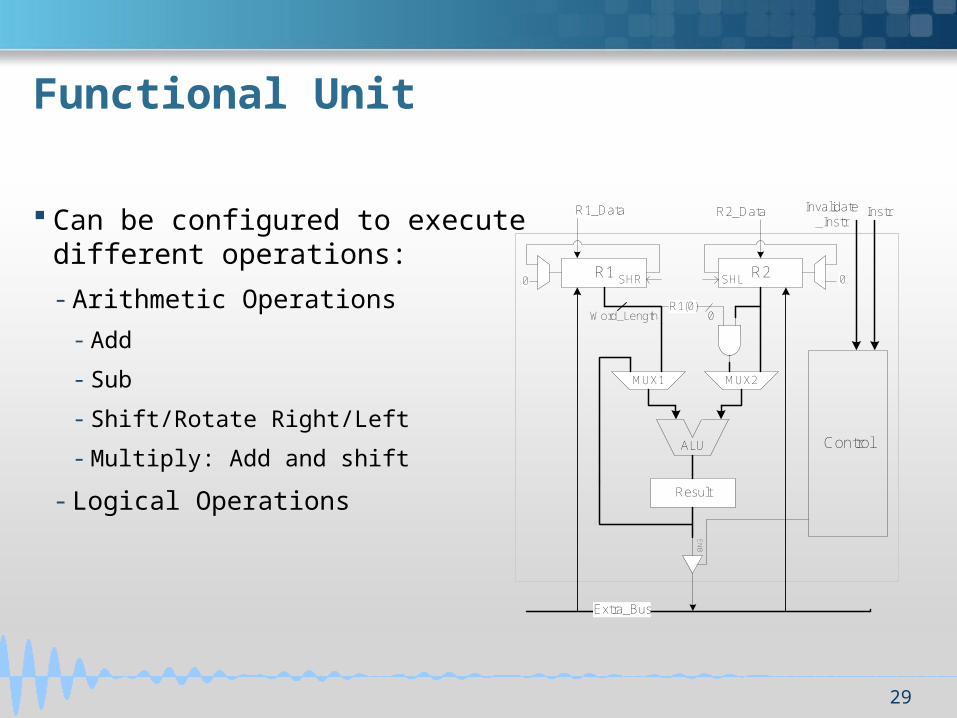
Functional Unit
Can be configured to execute different operations:
- Arithmetic Operations
- Add
- Sub
- Shift/Rotate Right/Left
- Multiply: Add and shift
- Logical Operations
R1 R20
MUX2MUX1
Result
EN
B
Control
R1(0)Word_Length 0
R1_Data R2_Data
SHLSHR
Extra_Bus
InstrInvalidate_Instr
ALU
0

30
Genetic Core
SW00
Cell-01
SW01
SW10 SW11
Cell-00
Cell-11Cell-10
Genetic Core
Population size and mutation rate are configurable.
Elite count is constant and equal to two in order to reduce the hardware complexity
Chromosome Memory
Address Fitness
Clock_Count
Address Fitness
LFSR
MUX
Crossover
RD_Addr1
RD_Addr2
Data1
Data2
Best_Chrom1
Best_Chrom2
Convert_Address
Proc_Addr
Instr_num
Control
>
>
End_Loop
Dec_Sch_ Data_Word
In1 In2
Accumulator
+

31
EvoMP Challenges
Current versions uses centralized memory unit.
- In “00” address.
- This address does not contain computational circuits.
- Major issue for scalability
Search space of genetic algorithm is very large.
- Exponentially grows up with linear increase of number of processors.
32
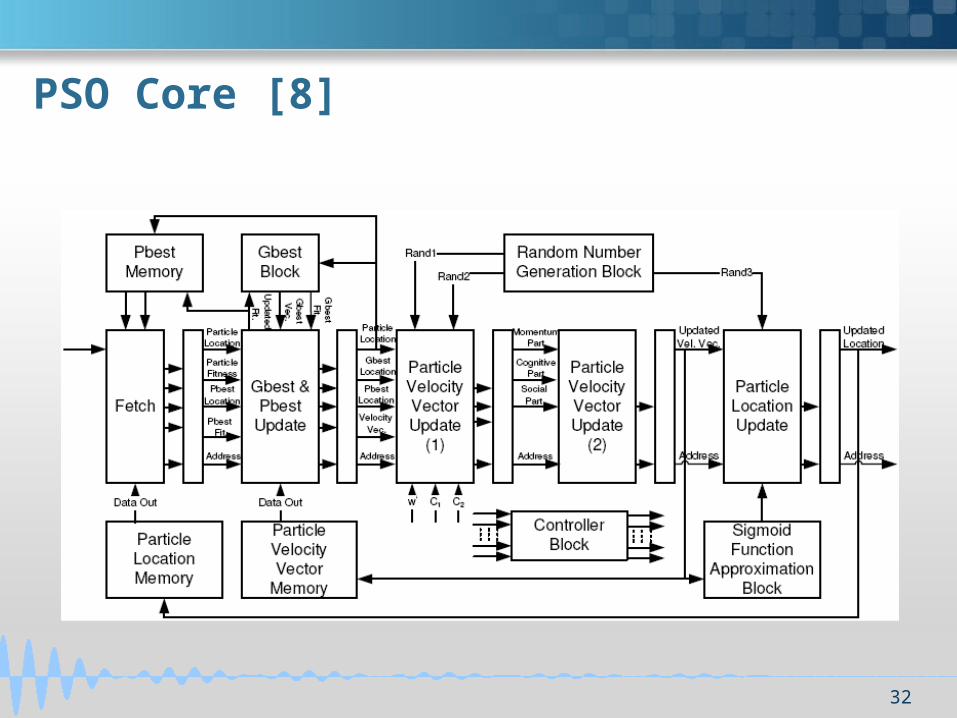
PSO Core [8]

33
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

34
Configurable Parameters
There are some configurable parameters in EvoMP:
- Word-length of the system
- Size of the mesh (number of processors)
- Flit length: bit-length of NoC switch links
- Population size
- Crossover rate

35
Simulation Results
Two sets of applications are used for performance evaluation.
- Some DSP programs
- Some sample neural Network
Two other decomposition and scheduling methods are implemented enabling the comparison
- Static Decomposition Genetic Scheduler (SDGS)
- Decomposition is performed statically i.e. tasks are predetermined manually
- Genetic core only specifies scheduling scheme
- Static Decomposition First Free Scheduler (FF)
- Assigns the first task in job-queue to the first free processor in the system
36
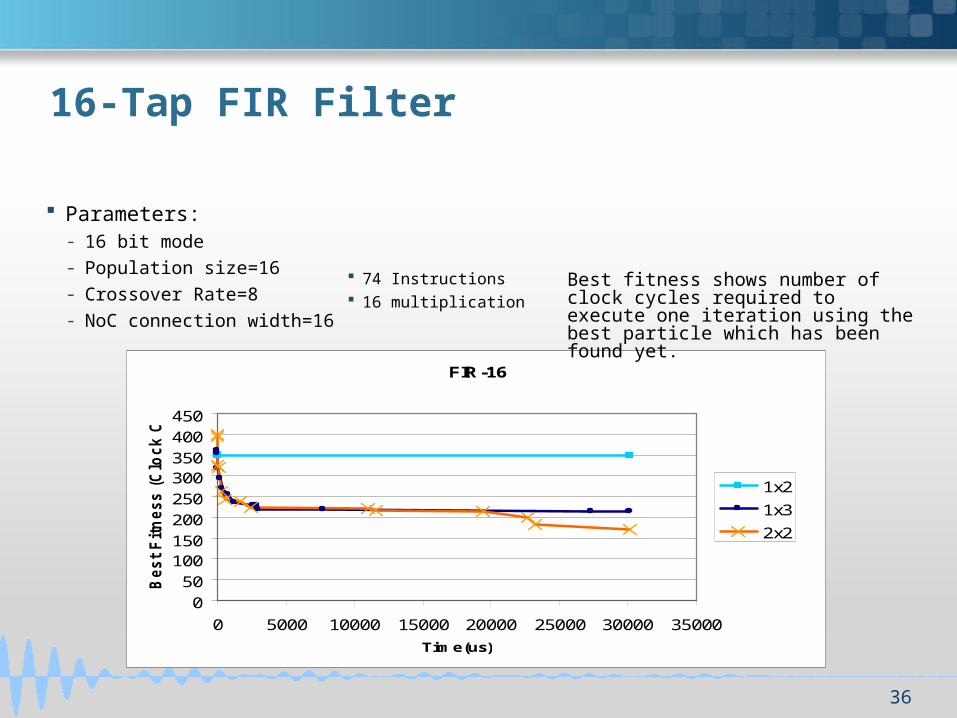
16-Tap FIR Filter
FIR-16
0
50
100150
200
250
300350
400
450
0 5000 10000 15000 20000 25000 30000 35000
Time(us)
Best
Fit
ness (
Clo
ck C
ycle
s)
1x2
1x3
2x2
Parameters:- 16 bit mode
- Population size=16
- Crossover Rate=8
- NoC connection width=16
74 Instructions 16 multiplication
Best fitness shows number of clock cycles required to execute one iteration using the best particle which has been found yet.

37
8-Point DCT
Parameters:- 16 bit mode
- Population size=16
- Crossover Rate=8
- NoC connection width=16
DCT-8
0
100
200
300
400
500
600
700
800
0 20000 40000 60000 80000 100000
Time, us
Best
Fit
ness,
Clo
ck C
ycle
s
1x2
1x3
2x2
2x3
88 Instructions 32 multiplication

38
16-point DCT
Parameters:- 16 bit mode
- Population size=16
- Crossover Rate=6
- NoC connection width=16
DCT-16
0
500
1000
1500
2000
2500
3000
0 100000 200000 300000 400000 500000 600000 700000
Time(us)
Be
st
Fit
ne
ss
(C
loc
k C
yc
les
)
1x2
1x3
2x2
2x3
320 Instructions 128 multiplication
39
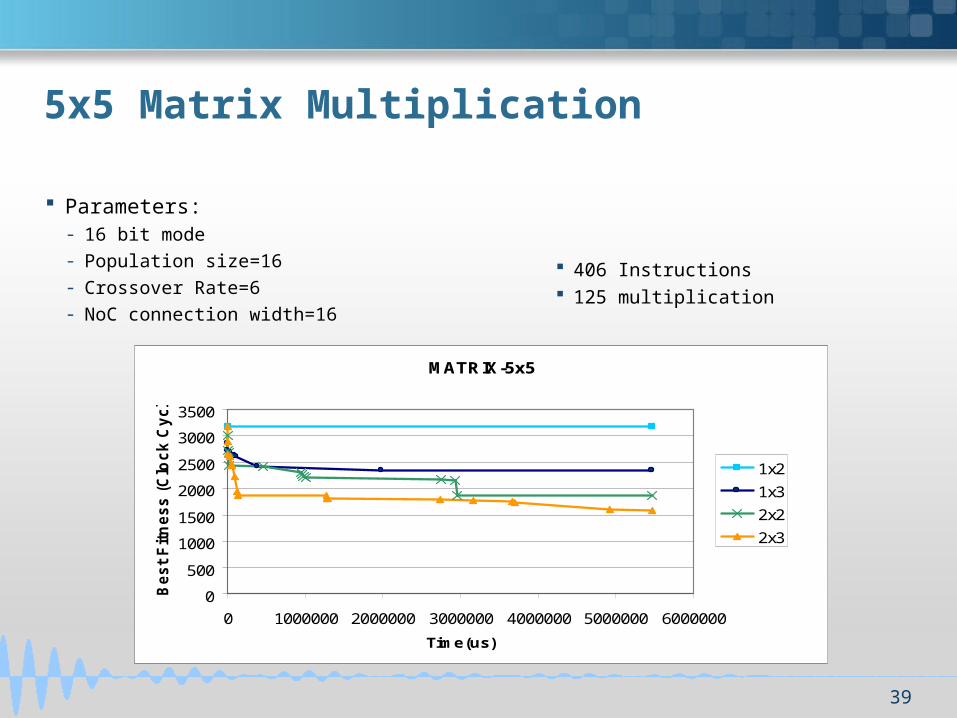
5x5 Matrix Multiplication
MATRIX-5x5
0
500
1000
1500
2000
2500
3000
3500
0 1000000 2000000 3000000 4000000 5000000 6000000
Time(us)
Be
st
Fit
ne
ss
(C
loc
k C
yc
les
)
1x2
1x3
2x2
2x3
Parameters:- 16 bit mode
- Population size=16
- Crossover Rate=6
- NoC connection width=16
406 Instructions 125 multiplication
40
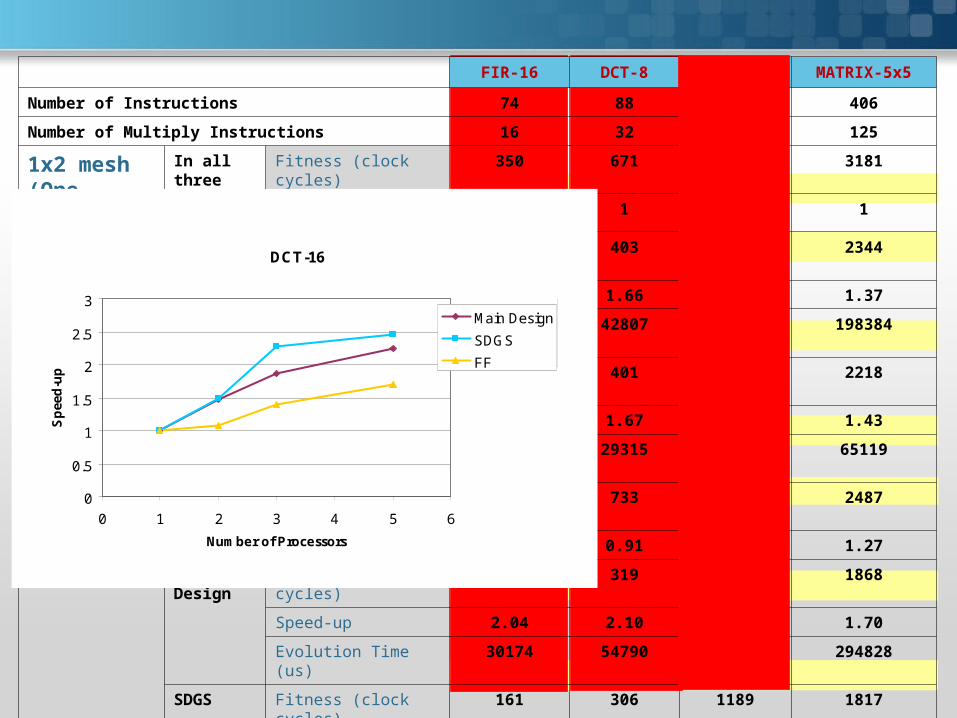
FIR-16 DCT-8 DCT-16 MATRIX-5x5
Number of Instructions 74 88 324 406
Number of Multiply Instructions 16 32 128 125
1x2 mesh(One Proc.)
In all three schemes
Fitness (clock cycles) 350 671 2722 3181
Speed-up 1 1 1 1
1x3 mesh Main Design
Fitness (clock cycles) 214 403 1841 2344
Speed-up 1.63 1.66 1.47 1.37
Evolution Time (us) 27342 42807 74582 198384
SDGS Fitness (clock cycles) 202 401 1812 2218
Speed-up 1.73 1.67 1.50 1.43
Evolution Time (us) 1967 29315 84365 65119
First Free Fitness (clock cycles) 293 733 2529 2487
Speed-up 1.19 0.91 1.08 1.27
2x2 mesh Main Design
Fitness (clock cycles) 171 319 1460 1868
Speed-up 2.04 2.10 1.86 1.70
Evolution Time (us) 30174 54790 23319 294828
SDGS Fitness (clock cycles) 161 306 1189 1817
Speed-up 2.17 2.19 2.28 1.75
Evolution Time (us) 10739 52477 536565 10092
First Free Fitness (clock cycles) 239 681 1933 2098
Speed-up 1.46 0.98 1.40 1.51
FIR-16
0
0.5
1
1.5
2
2.5
0 1 2 3 4
Number of Processors
Sp
eed
-up
Main design
SDGS
FF
DCT-8
0
0.5
1
1.5
2
2.5
3
0 1 2 3 4 5 6
Number of Processors
Sp
eed
-up
SDGS
Main Design
FF
DCT-16
0
0.5
1
1.5
2
2.5
3
0 1 2 3 4 5 6
Number of Processors
Sp
eed
-up
Main Design
SDGS
FF

41
FIR-16 DCT-8 DCT-16 MATRIX-5x5
Number of Instructions 74 88 324 406
Number of Multiply Instructions 16 32 128 125
1x2 mesh(One Proc.)
In all three schemes
Fitness (clock cycles) 350 671 2722 3181
Speed-up 1 1 1 1
2x3 mesh Main Design
Fitness (clock cycles) Unevaluated 285 1213 1596
Speed-up 2.33 2.25 1.99
Evolution Time (us) 93034 630482 546095
SDGS Fitness (clock cycles) 256 1106 1575
Speed-up 2.62 2.46 2.01
Evolution Time (us) 41023 111118 178219
First Free Fitness (clock cycles) 496 1587 1815
Speed-up 1.35 1.71 1.75
42
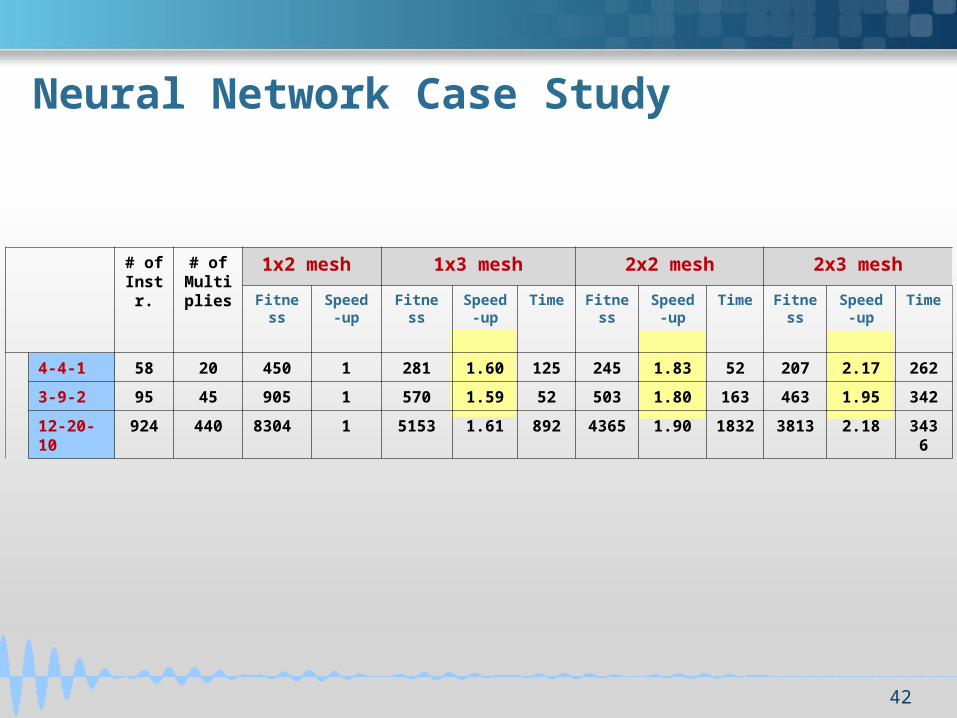
Neural Network Case Study
# of Instr.
# of Multiplies
1x2 mesh 1x3 mesh 2x2 mesh 2x3 mesh
Fitness Speed-up
Fitness Speed-up
Time Fitness Speed-up
Time Fitness
Speed-up
Time
4-4-1 58 20 450 1 281 1.60 125 245 1.83 52 207 2.17 262
3-9-2 95 45 905 1 570 1.59 52 503 1.80 163 463 1.95 342
12-20-10 924 440 8304 1 5153 1.61 892 4365 1.90 1832 3813 2.18 3436
43
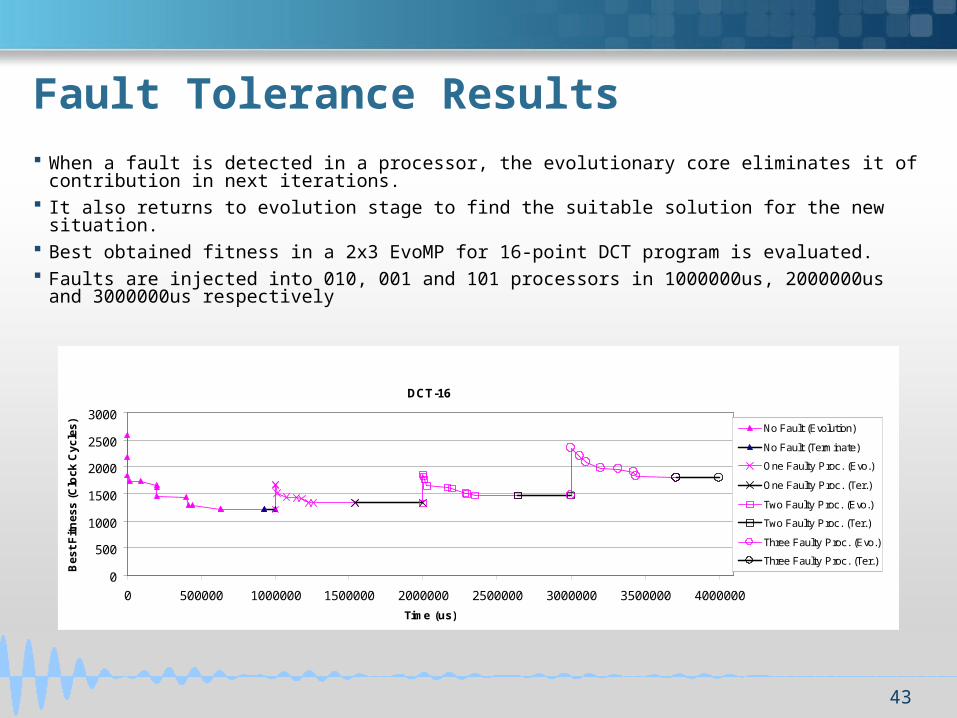
Fault Tolerance Results
When a fault is detected in a processor, the evolutionary core eliminates it of contribution in next iterations.
It also returns to evolution stage to find the suitable solution for the new situation. Best obtained fitness in a 2x3 EvoMP for 16-point DCT program is evaluated. Faults are injected into 010, 001 and 101 processors in 1000000us, 2000000us and
3000000us respectively
DCT-16
0
500
1000
1500
2000
2500
3000
0 500000 1000000 1500000 2000000 2500000 3000000 3500000 4000000
Time (us)
Be
st
Fit
ne
ss
(C
loc
k C
yc
les
)
No Fault (Evolution)
No Fault (Terminate)
One Faulty Proc. (Evo.)
One Faulty Proc. (Ter.)
Two Faulty Proc. (Evo.)
Two Faulty Proc. (Ter.)
Three Faulty Proc. (Evo.)
Three Faulty Proc. (Ter.)

44
Genetic vs. PSO
# of Instr.
# of Multi-plies
Particle length (bits)
1x2 mesh
1x3 mesh 2x2 mesh 2x3 mesh
Both Genetic PSO Genetic PSO Genetic PSO
Fit Time Fit Time Fit Time Fit Time Fit Time Fit Time
FIR-16 74 16 240 350 214 23.7 211 12.3 171 30.1 174 14.3 unevaluated
DCT-8 88 32 280 671 403 93.0 393 6.2 319 99.8 308 21.8 285 138.1 203 15.6
DCT-16 324 128 720 2722 1841 74.5 1831 41.7 1460 23.3 1439 45.3 1213 633.7 1191 98.3
MAT-5x5 406 125 800 3181 2344 198.3 2312 86.3 1868 294.8 1821 148.3 1596 546.7 1518 240.9
Population size in both experiments is 16

45
Synthesis ResultsSynthesis Results
Synthesis results on VIRTEX II (XC2V3000) FPGA using Sinplify using Sinplify Pro.Pro.
NoC switch Genetic Core PSO Core MMU Processor Total System
Area (Total LUTs) 729( 2%) 1864( 6%) 1642( 5%) 3553( 12%) 4433( 15%) 20112( 70%)
Max Freq. (MHz) - 68.4 94.6 - - 61.4

46
Introduction and Motivations
Basics of Evolvable Multiprocessor System (EvoMP)
EvoMP Operational View
EvoMP Architectural View
Simulation and Synthesis Results
Summary

47
Summary
The EvoMP which is a novel MPSoC system was studied.
EvoMP exploits evolvable strategies to perform run-time task decomposition and scheduling.
EvoMP does not require concurrent codes because it can parallelize th sequential codes at run-time.
Exploits particular and novel processor architecture in order to address data dependency problem.
Experimental results confirm the applicability of EvoMP novel ideas.

48
Main References
[1] N. S. Voros and K. Masselos, System Level Design of Reconfigurable Systems-on-Chip. Netherlands: Springer, 2005.
[2] G. Martin, “Overview of the MPSoC design challenge,” Proc. Design and Automation Conf., July 2005, pp. 274-279.
[3] S. Amarasinghe, “Multicore programming primer and programming competition,” class notes for 6.189, Computer Architecture Group, Massachusetts Institute of Technology, Available: www.cag.csail.mit.edu/ps3/lectures/6.189-lecture1-intro.pdf.
[4] M. Hubner, K. Paulsson, and J. Becker, “Parallel and flexible multiprocessor system-on-chip for adaptive automo tive applications based on Xilinx MicroBlaze soft-cores,” Proc. Intl. Symp. Parallel and Distributed Processing, 2005.
[5] D. Gohringer, M. Hubner, V. Schatz, and J. Becker, “Runtime adaptive multi-processor system-on-chip: RAMP SoC,” Proc. Intl. Symp. Parallel and Distributed Processing, April 2008, pp. 1-7.
[6] A. Klimm, L. Braun, and J. Becker, “An adaptive and scalable multiprocessor system for Xilinx FPGAs using minimal sized processor cores,” Proc. Symp. Parallel and Distributed Processing, April 2008, pp. 1-7.
[7] Z.Y. Wen and Y.J. Gang, “A genetic algorithm for tasks scheduling in parallel multiprocessor systems,” Proc. Intl. Conf. Machine Learning and Cybernetics, Nov. 2003, pp.1785-1790.
[8] A. Farmahini-Farahani, S. Vakili, S. M. Fakhraie, S. Safari, and C. Lucas, “Parallel scalable hardware implementation of asynchronous discrete particle swarm optimization,” Elsevier J. of Engineering Applications of Artificial Intelligence, submitted for publication.

49
Main References (2)
[9] A. A. Jerraya and W. Wolf, Multiprocessor Systems-on-Chips. San Francisco: Morgan Kaufmann Publishers, 2005.
[10] A.J. Page and T.J. Naughton, “Dynamic task scheduling using genetic algorithms for heterogeneous distributed computing,” Proc. Intl. Symp. Parallel and Distributed Processing, April 2005, pp. 189.1.
[11] E. Carvalho, N. Calazans, and F. Moraes, “Heuristics for dynamic task mapping in NoC based heterogeneous MPSoCs”, Proc. Int. Rapid System Prototyping Workshop, pp. 34-40, 2007.
[12] R. Canham, and A. Tyrrell, “An embryonic array with improved efficiency and fault tolerance,” Proc. NASA/DoD Conf. on Evolvable Hardware, July 2003, pp. 265-272.
[13] W. Barker, D. M. Halliday, Y. Thoma, E. Sanchez, G. Tempesti, and A. Tyrrell, “Fault tolerance using dynamic reconfiguration on the POEtic Tissue,” IEEE Trans. Evolutionary Computing, vol. 11, num. 5, Oct. 2007, pp. 666-684.

50
Related Publications
Journal:
1. S. Vakili, S. M. Fakhraie, and S. Mohammadi, “EvoMP: a novel MPSoC architecture with evolvable task decompo sition and scheduling,” Submitted to IET Comp. & Digital Tech., (Under Revision).
2. S. Vakili, S. M. Fakhraie, and S. Mohammadi, “Low-cost fault tolerance in evolvable multiprocessor system: a graceful degradation approach,” Submitted to Journal of Zhejiang University SCIENCE A (JZUS-A).
Conference:
1. S. Vakili, S. M. Fakhraie, and S. Mohammadi, “Designing an MPSoC architecture with run-time and evolvable task decomposition and scheduling,” Proc. 5’th IEEE Intl. Conf. Innovations in Information Technology, Dec. 2008.
2. S. Vakili, S. M. Fakhraie, S. Mohammadi, and Ali Ahmadi, “Particle swarm optimization for run-time task decomposition and scheduling in evolvable MPSoC,” Proc. IEEE. Intl. conf. Computer Engineering and Technology, Jan. 2009.

















