Design and Implementation Design and Implementation of the CCC of the CCC Parallel Programming Parallel Programming Language Language Nai-Wei Lin Department of Computer Science and Information Engine ering National Chung Cheng University
Transcript
Design and ImplementationDesign and Implementationof the CCC of the CCC
Parallel Programming LanguageParallel Programming Language
Nai-Wei Lin
Department of Computer Science and Information Engineering
National Chung Cheng University
ICS2004 2
OutlineOutline
Introduction
The CCC programming language
The CCC compiler
Performance evaluation
Conclusions
ICS2004 3
MotivationsMotivations
Parallelism is the future trendProgramming in parallel is much more
difficult than programming in serialParallel architectures are very diverseParallel programming models are very diverse
ICS2004 4
MotivationsMotivations
Design a parallel programming language that uniformly integrates various parallel programming models
Implement a retargetable compiler for this parallel programming language on various parallel architectures
ICS2004 5
Approaches to ParallelismApproaches to Parallelism
void get_haircut( ){ open += 1; signal(door_open); while (open > 0) wait(customer_left);}
ICS2004 19
ChannelsChannels
The channel construct is a modular and efficient construct for message passing among concurrent tasks
Pipe: one to oneMerger: many to oneSpliter: one to manyMultiplexer: many to many
ICS2004 20
ChannelsChannels
Communication structures among parallel tasks are more comprehensive
The specification of communication structures is easier
The implementation of communication structures is more efficient
The static analysis of communication structures is more effective
ICS2004 21
An Example - Consumer-Producer An Example - Consumer-Producer
producer consumer
consumer
consumer
spliter
ICS2004 22
An Example - Consumer-Producer An Example - Consumer-Producer
task::main( ){ spliter int chan; int i;
par { producer( chan ); parfor (i = 0; i < 10; i++) consumer( chan ); }}
ICS2004 23
An Example - Consumer-Producer An Example - Consumer-Producer
task::producer(spliter in int chan){ int i;
for (i = 0; i < 100; i++) put(chan, i); for (i = 0; i < 10; i++) put(chan, END);}
ICS2004 24
An Example - Consumer-Producer An Example - Consumer-Producer
task::consumer(spliter in int chan){ int data;
while ((data = get(chan)) != END) process(data);}
ICS2004 25
Data ParallelismData Parallelism
Concurrency domain – an aggregate of synchronous tasks
Synchronization and communication domain – variables in global name space
ICS2004 26
An Example – Matrix MultiplicationAn Example – Matrix Multiplication
=
ICS2004 27
An Example– Matrix MultiplicationAn Example– Matrix Multiplication
domain matrix_op[16] { int a[16], b[16], c[16]; multiply(distribute in int [16:block][16], distribute in int [16][16:block], distribute out int [16:block][16]);};
ICS2004 28
task::main( ) { int A[16][16], B[16][16], C[16][16]; domain matrix_op m;
An Example– Matrix MultiplicationAn Example– Matrix Multiplication
ICS2004 29
matrix_op::multiply(A, B, C) distribute in int [16:block][16] A;distribute in int [16][16:block] B;distribute out int [16:block][16] C;{ int i, j; a := A; b := B; for (i = 0; i < 16; i++) for (c[i] = 0, j = 0; j < 16; j++) c[i] += a[j] * matrix_op[i].b[j]; C := c;}
An Example– Matrix MultiplicationAn Example– Matrix Multiplication
ICS2004 30
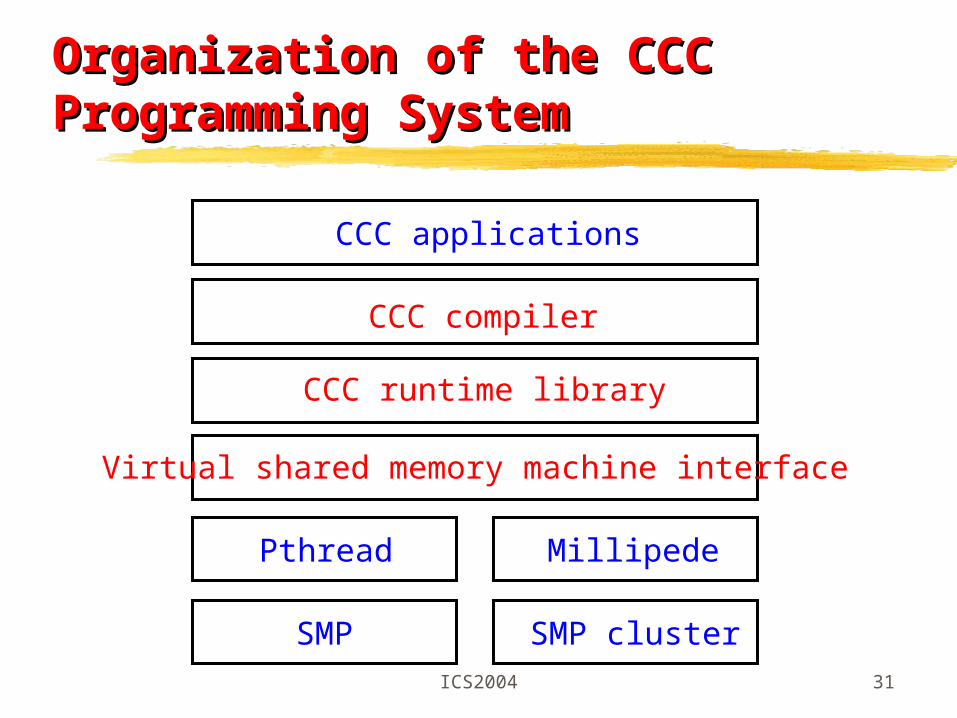
Platforms for the CCC CompilerPlatforms for the CCC Compiler
PCs and SMPs Pthread: shared memory + dynamic thread creat
The CCC runtime library contains a collection of functions that implements the salient abstractions of CCC on top of the virtual shared memory machine interface
ICS2004 35
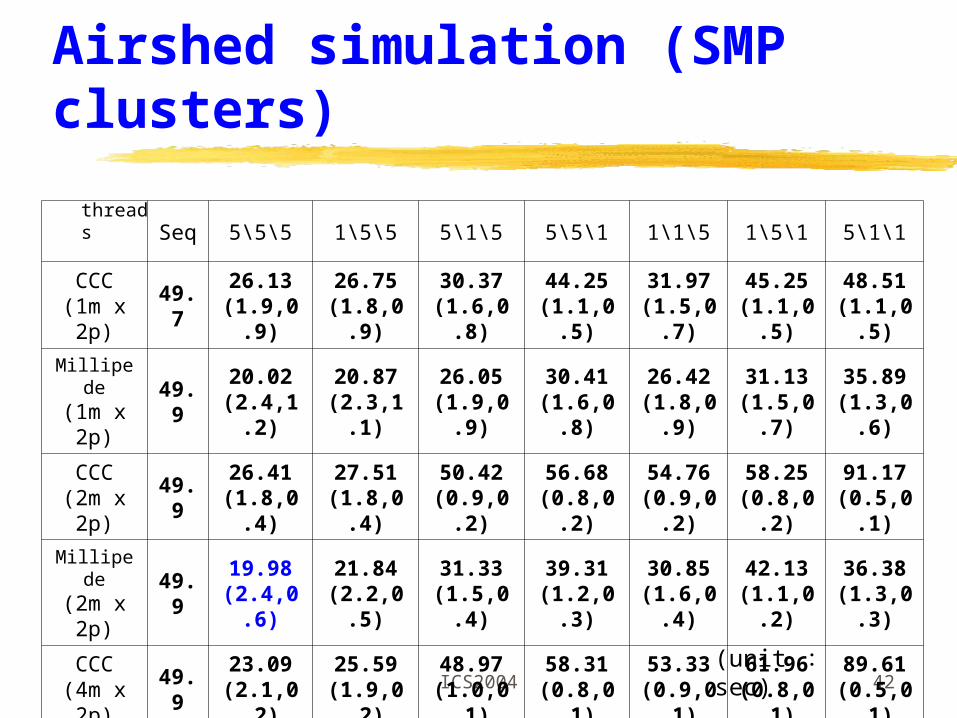
Performance EvaluationPerformance Evaluation
SMPs Hardware : an SMP machine with four CPUs, each CPU i
s an Intel PentiumII Xeon 450MHz, and cache is 512K Software : OS is Solaris 5.7 and library is pthread 1.26
SMP clusters Hardware : four SMP machines, each of which has two C
PUs, each CPU is Intel PentiumIII 500MHz, and cache is 512K
Software : OS is windows 2000 and library is millipede 4.0
Network : Fast ethernet network 100Mbps
ICS2004 36
BenchmarksBenchmarks
Matrix multiplication (1024 x 1024)W arshall’s transitive closure (1024 x 1024)Airshed simulation (5)