9
Designing a CCA Framework for Accelerators Khushbu Agarwal Daniel Chavarría Manoj Krishnan Ian Gorton
| Date post: | 17-Dec-2015 |
| Category: |
Documents |
| Upload: | elizabeth-harris |
| View: | 222 times |
| Download: | 0 times |

Designing a CCA Framework for Accelerators
Khushbu AgarwalDaniel ChavarríaManoj Krishnan
Ian Gorton

Motivation
Emerging hybrid applications & architectures:Many codes & kernels being ported to hybrid CPU/GPU clusters“Production”-level applications not yet (?)
Other accelerated systems being deployed/developed:
FPGA-accelerated systemsTraditional
Convey systems
Cray XMT system: x86 front-end nodes + multithreaded compute nodes
2

Motivation (cont.)
3

Motivating Applications
4
Molecular dynamics GPU-based kernels being developed at PNNL
Evolving into more sophisticated/complete hybrid MD application
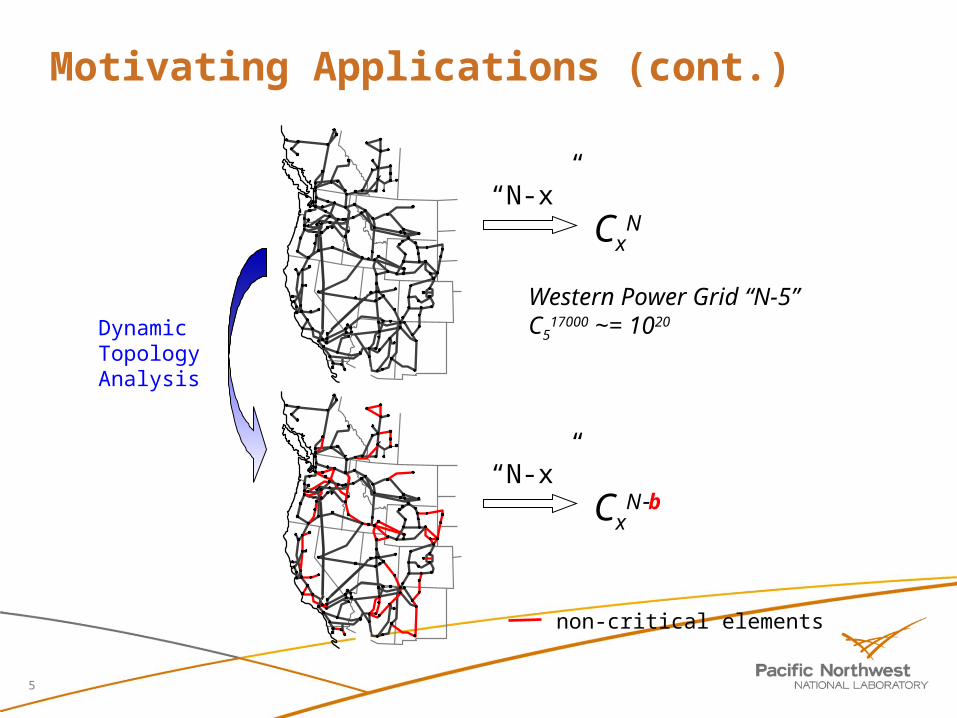
CCSD(T) GPU-based kernels also being developedCray XMT-based power grid contingency analysis application:
Dynamic power flow-based topology analysis on multithreaded processors to determine non-critical elements
Numerical solution of critical contingency cases on x86-based cluster
Motivating Applications (cont.)
5
“N-x”
CxN
“N-x”
CxNb
non-critical elements
Dynamic Topology Analysis
Western Power Grid “N-5” C5
17000 ~= 1020

Objective
Provide a device independent interface to access accelerators and execute computations on them. e.g.:
Graphics Processor Units (GPUs)Field-Programmable Gate Arrays (FPGAs)Cray XMT
6

Proposed SIDL Framework
Initialize()Initializes the connection between accelerator and local host
opaque AllocMem()Allocate Memory on the accelerator and returns a pointer to it
opaque ReadMem( opaque m)Synchronous - Reads data from the accelerator and copies it to local buffer
WriteMem(opaque m, opaque data)Synchronous - Copy data from local buffer to accelerator memory
Exec()Synchronous - Executes the computation kernel on the accelerator
int AsyncExec()Asynchronous – Executes the computation kernel on the accelerator and returns a handle
7

Proposed SIDL Framework
AsyncWriteMem(opaque m, opaque data)Asynchronous – Issue request to copy data from local buffer to accelerator memory
opaque AsyncReadMem (opaque m)Asynchronous – Issue a request to read data from accelerator and copy it to local buffer
Wait() Wait for all the asynchronous data transfer operations to complete
WaitExec(int handle)Wait for asynchronous execution (identified by the handle) to complete
8

Implementation Challenges
Needs to differentiate between on board vs “farther away” accelerators.Init – will need to set up a connection between host and acceleratorHow do we start the execution of a kernel (move data) on an accelerator?
Heavily system and platform dependent
Good to hide behind a component interface!
9

















