32
Big Data University of Kent 23 rd April 2015 @DigContactLtd
| Date post: | 18-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | digitalcontact |
| View: | 198 times |
| Download: | 0 times |

Big DataUniversity of Kent
23rd April 2015
@DigContactLtd

Discussion items
• Who are Digital Contact?
• Problems with Big Data
• Hadoop
• Word2Vec
• (More) Problems with Big Data
• Election debates

Who are Digital Contact?
• We are a big data product company
• Focus on developing products and services
for business-to-business and business-to-
consumers
• Currently developing trading.co.uk

Problems with big data
• Often described as the three V’s:
1. Volume – Huge quantities of data available
2. Velocity – Data constantly produced by both people and
3. Variety – Data can be both structured and un-structured
• How can we tackle some of these problems?


Hadoop
• Hadoop is an open-source software framework
• Developed at Yahoo to deal with ever-increasing amounts of content
• It allows you to store and process data in a distributed fashion (ie over a number of machines)
• This allows for 2 key things: massive data storage and faster processing
• It’s an incredibly powerful system but, as it’s relatively new, there is little documentation on it
• Used by Amazon, Ebay, Facebook, LinkedIn and many more

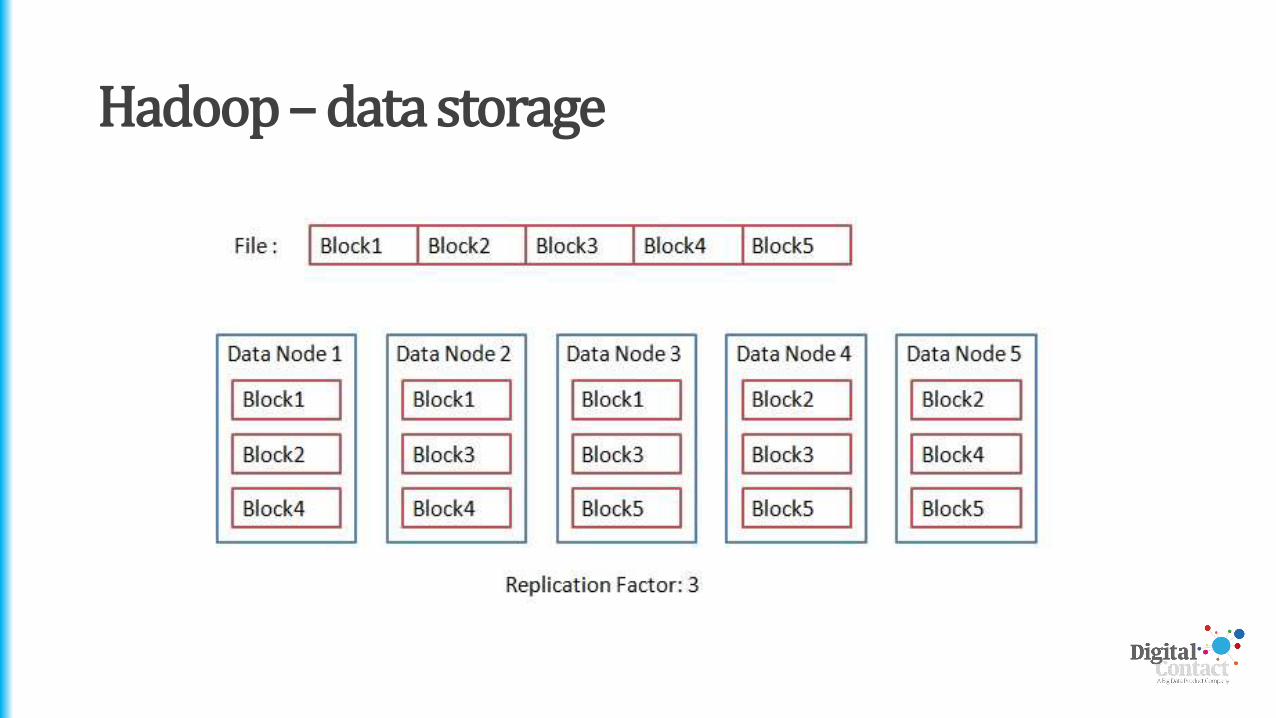
Hadoop – Data Storage
• Hadoop allows for huge data files to be stored across multiple machines
• Takes files and breaks them into blocks (normally 64/128mb)
• Blocks are stored in data nodes and are typically replicated across 3 nodes per block
• A master node maintains the location of the blocks and which file they belong to – however, it doesn’t store the blocks itself
Hadoop – data storage

Hadoop – data storage
• Allows for complete redundancy – data nodes are easily replacable
• Allows for faster access to the data – system can request data from 3 places and use the fastest return
• Storage is reduced to 1/3 capacity but:
• Files can be read in a compressed format
• Redundancy is worth the cost
• Higher failure rates permissible for data nodes
• Storage is cheap!

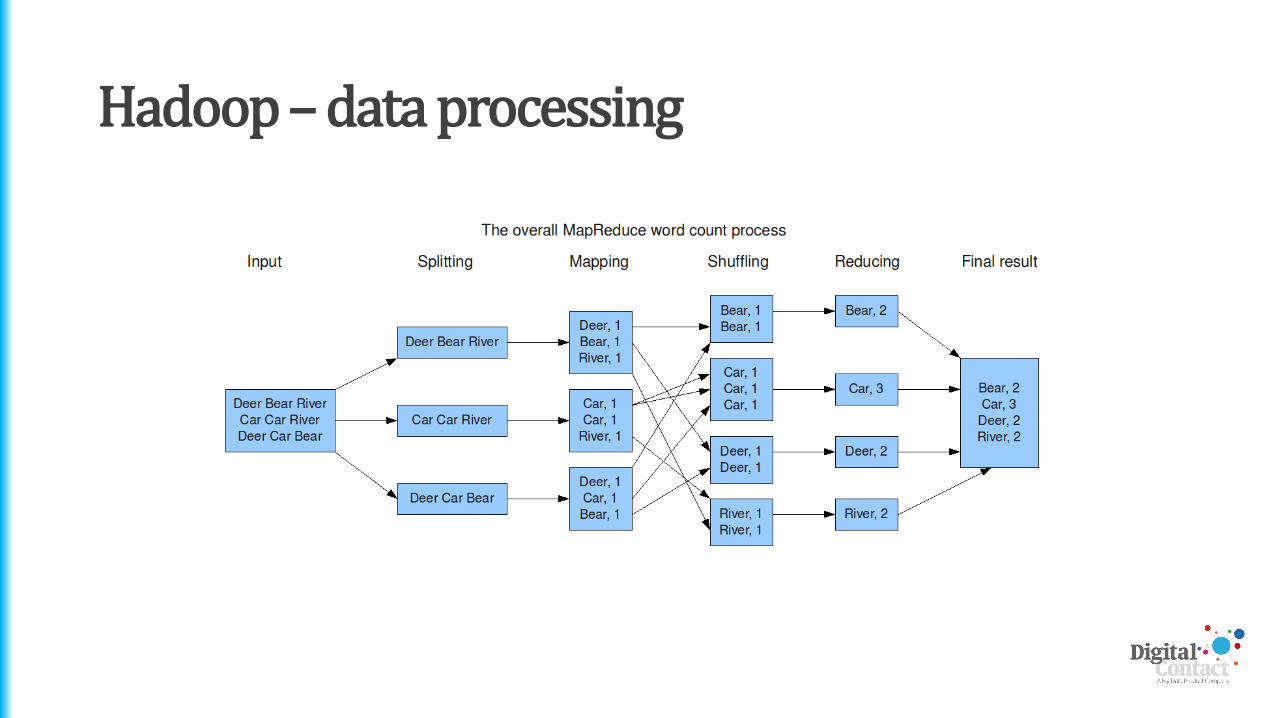
Hadoop – data processing
• Once the data’s in, how is it processed?
• One major component of Hadoop is MapReduce
• Doesn’t try and process everything all at once
• Instead, processes chunks of data and tallies up results
Hadoop – data processing

Hadoop – data processing
• Designed for massive data sets
• Not suitable for processing small sets quickly (although other tools on Hadoop can do this
in real-time)
• Allows users to stream data through other programming languages
• During most recent debate, able to extract named entities and sentiment from 10,000,000
tweets in 3:30 minutes! (more on this later)

Working with data
• Hadoop can help with volume and velocity of data – what about
variety
• Need methods to add structure to unstructured data
• For working with text, we’ve been looking at Word2Vec

Word2Vec
• Developed and released as an open source project by Google
• Described as a ‘really, really big deal’ by the head of Kaggle (a data science
competition website)
• Works by representing every word as a vector (a series of numbers for each word
showing how likely it is to be found in relation to other words)
• Trains by taking a word and working out how likely other words are to come
before and after it
• It’s maths with words
• Allows you to do some really interesting stuff…

Word2Vec uses
>>> model.doesnt_match("man woman child kitchen".split())
‘kitchen’
>>>model.most_similar("awful")
(u'terrible', 0.6721246242523193),
(u'horrible', 0.6031243205070496),
(u'dreadful', 0.5896061658859253),
(u'atrocious', 0.5460706949234009),
(u'laughable', 0.5287274122238159),
(u'horrendous', 0.521348237991333),
(u'abysmal', 0.5080942511558533),
(u'appalling', 0.4996950328350067),
(u'amateurish', 0.4995490610599518),
(u'lousy', 0.49693402647972107)

Word2Vec uses
• Works well as a thesaurus
• Able to look for similar words and find odd ones out
• Useful to overcome issues around synonymy
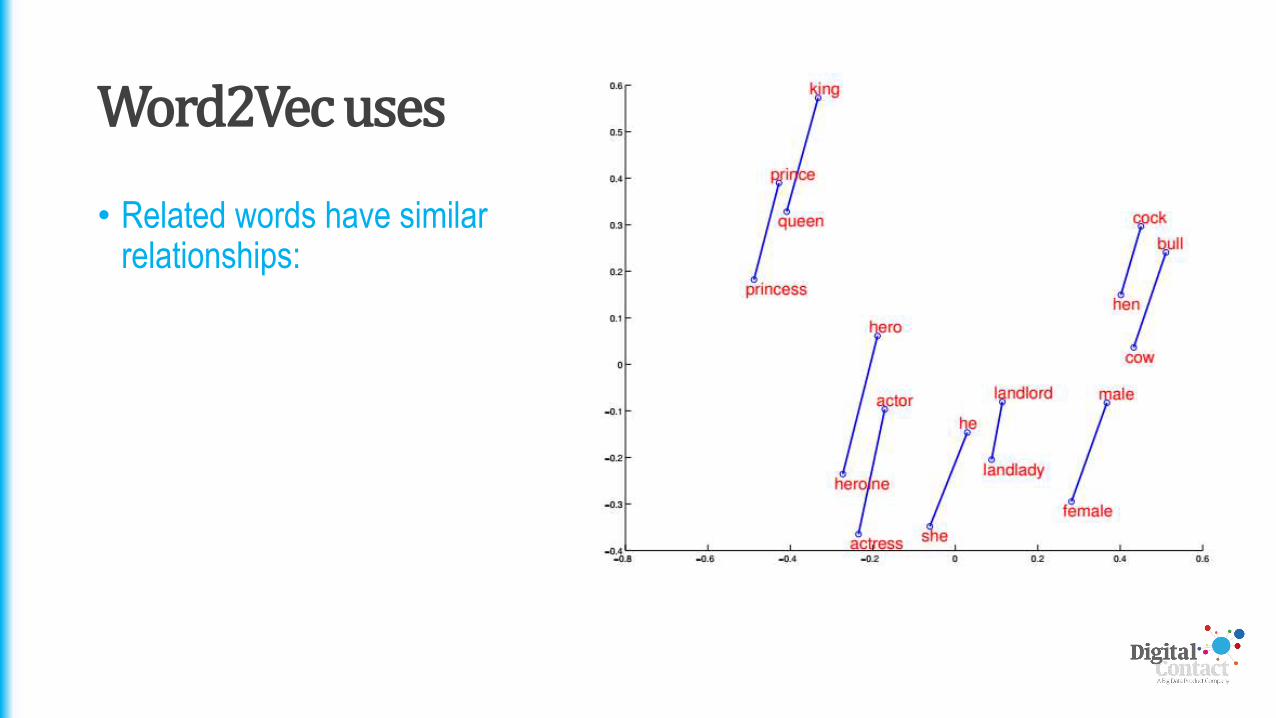
• Even more helpful is that it models relationships between words
• We can see this when we model the words on a 2d space
Word2Vec uses
• Related words have similar relationships:
Word2Vec uses
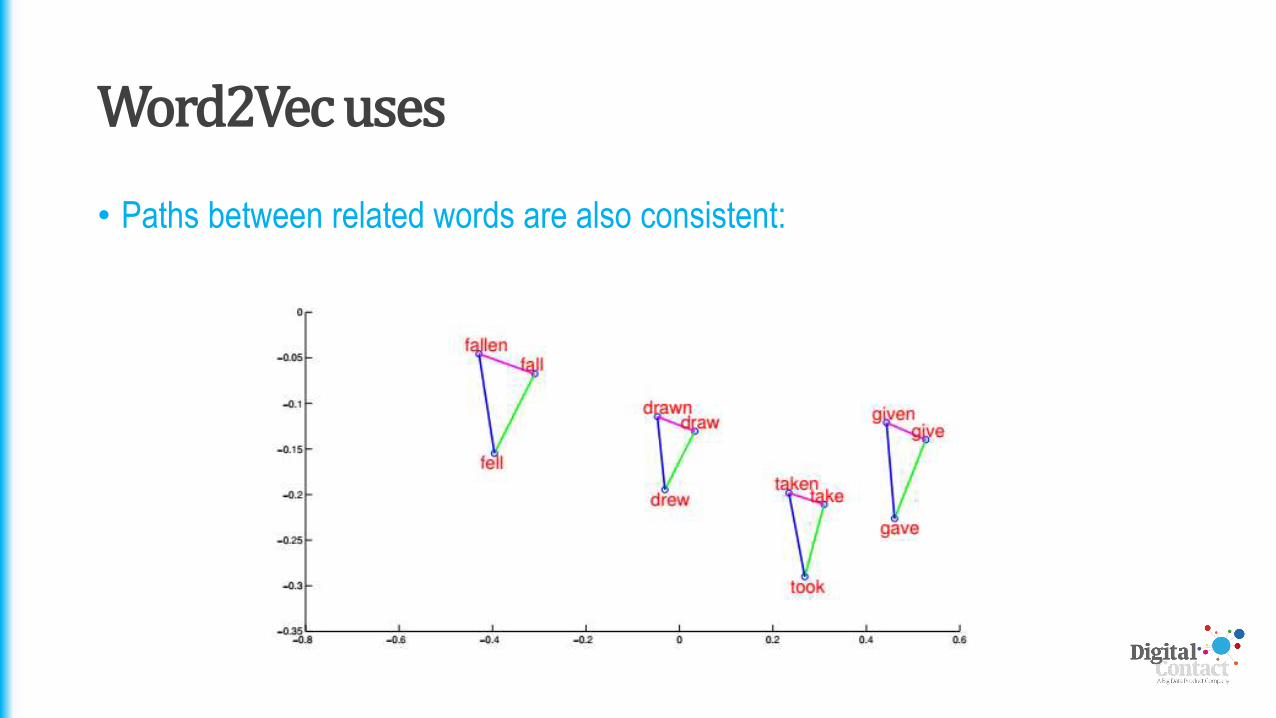
• Paths between related words are also consistent:
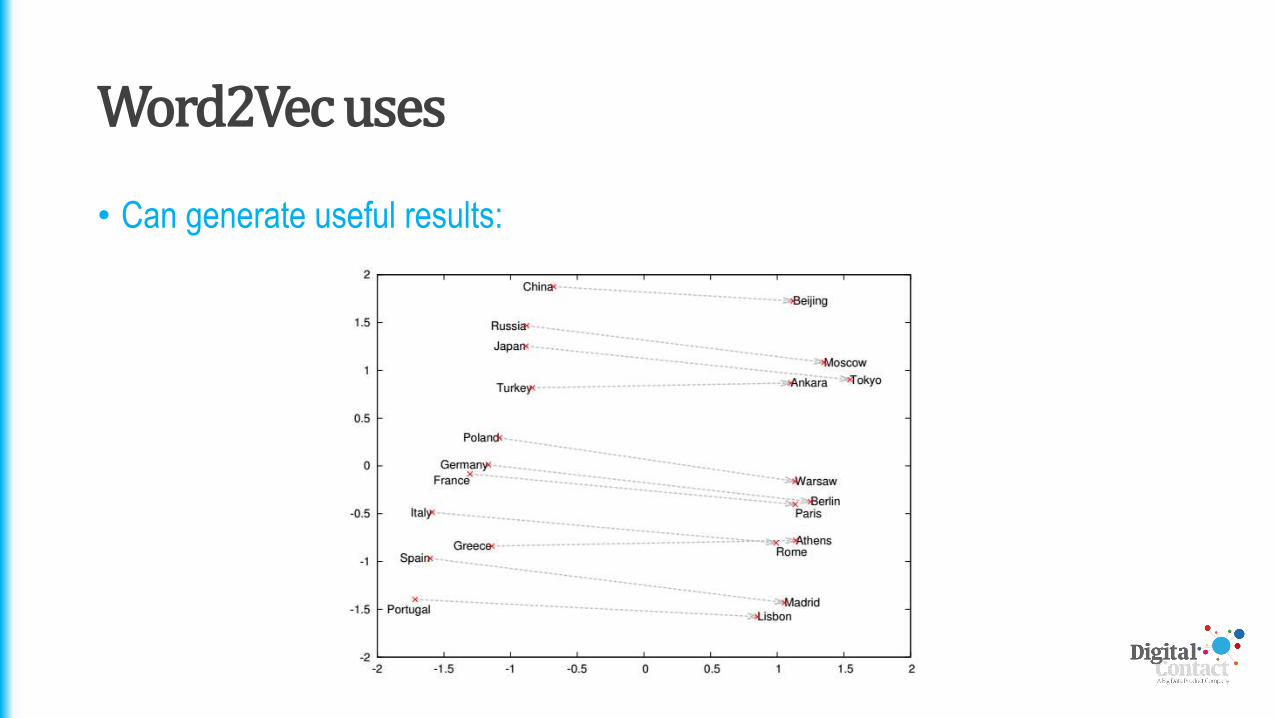
Word2Vec uses
• Can generate useful results:

Word2Vec uses
We can also add and subtract words for more information:
• King + Woman – Man = Queen
• London + France – England = Paris
• Bigger – Big + Cold = Colder
• Sushi – Japan + Germany = Bratwurst
• Cu – Copper + Gold = Au
• Windows – Microsoft + Google = Android
• Tim Cook – Apple + Microsoft = Satya Nadella
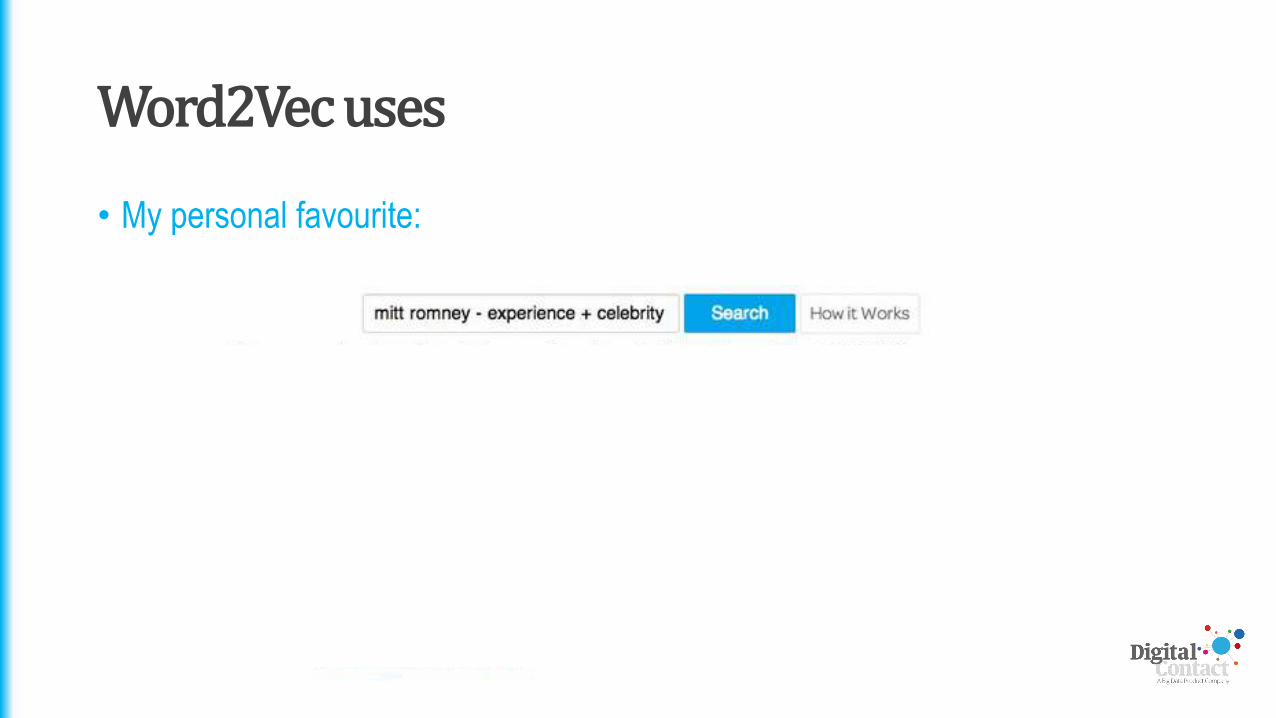
Word2Vec uses
• My personal favourite:
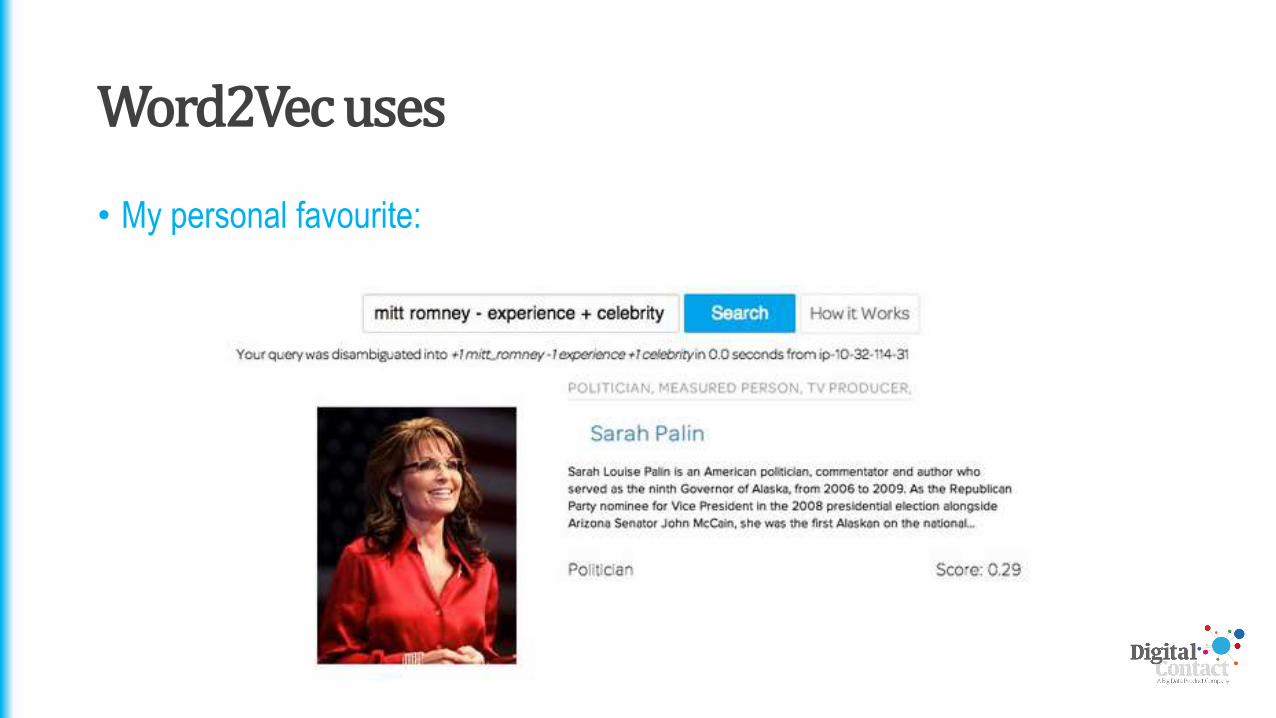
Word2Vec uses
• My personal favourite:

Word2Vec uses
Wide range of applications for this model:
• Answering queries
• Understanding meaning of new words
• Easy to understand results
• Good for finding similar documents in a large corpus
• Intelligent localised searches
• Machine Translation
• Detecting sarcasm
• Sentiment analysis
• Pub quizzes…

(More) Problems with big data
• More V’s for data science to deal with:
1. Veracity – Data contains noise – need to keep data ‘clean’
2. Validity – Data needs to be correct and fit for purpose
3. Volatility – Data needs to be relevant to the analysis
4. Viewership – Results need to be appropriate to the audience
• Quick case study

Leaders’ Debates
• Over 10,000,000 election tweets
• Looked for mentions of parties or leaders
• Analysed tweets for sentiment
• Gave interesting insights into debates
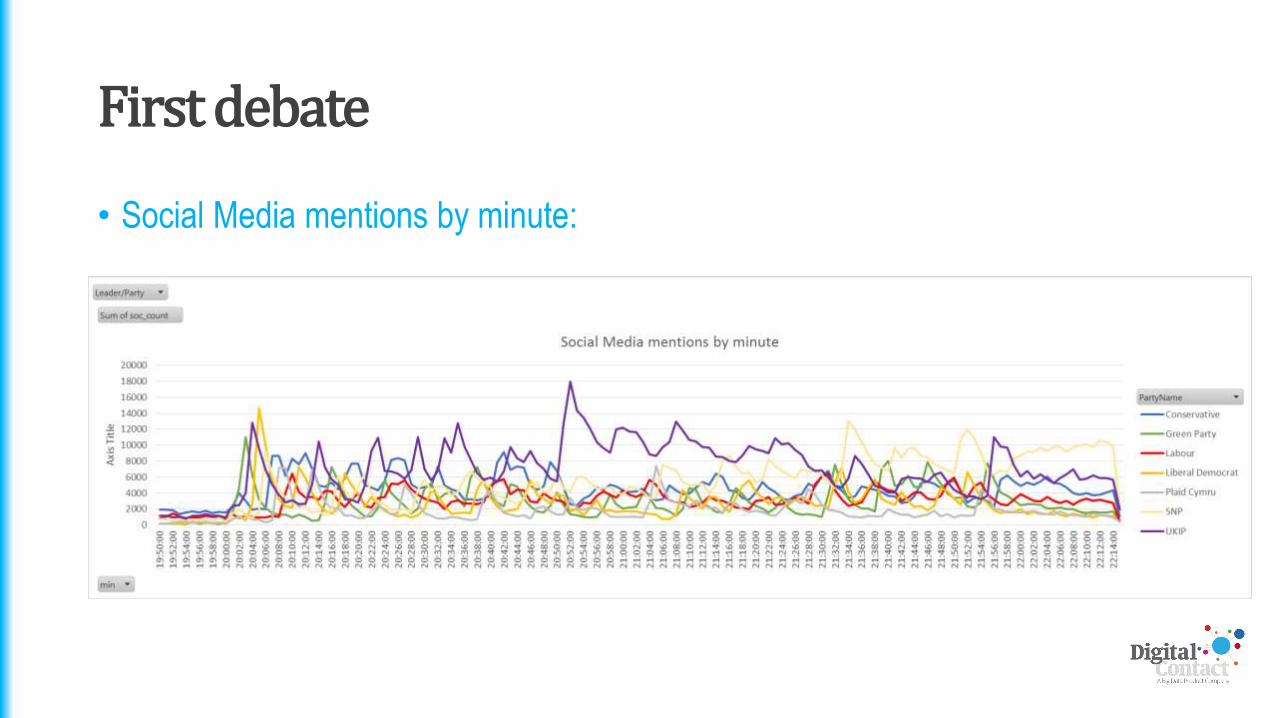
First debate
• Social Media mentions by minute:
First debate
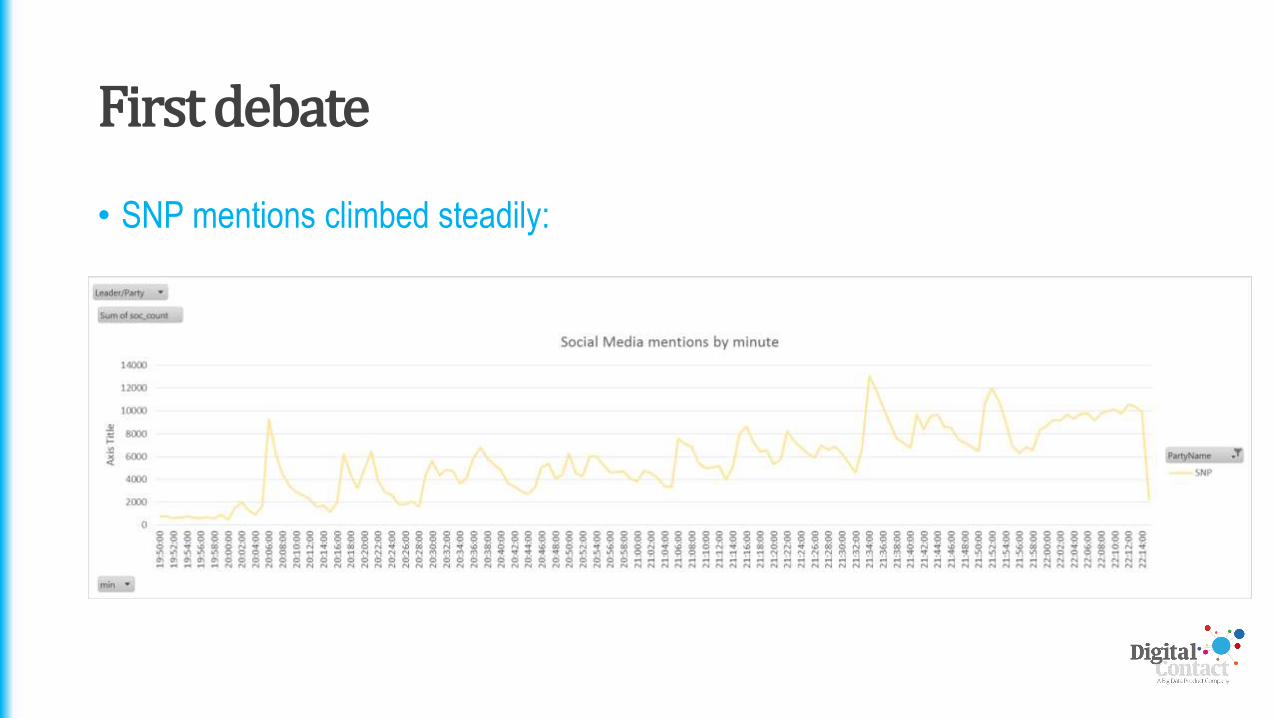
• SNP mentions climbed steadily:
First debate
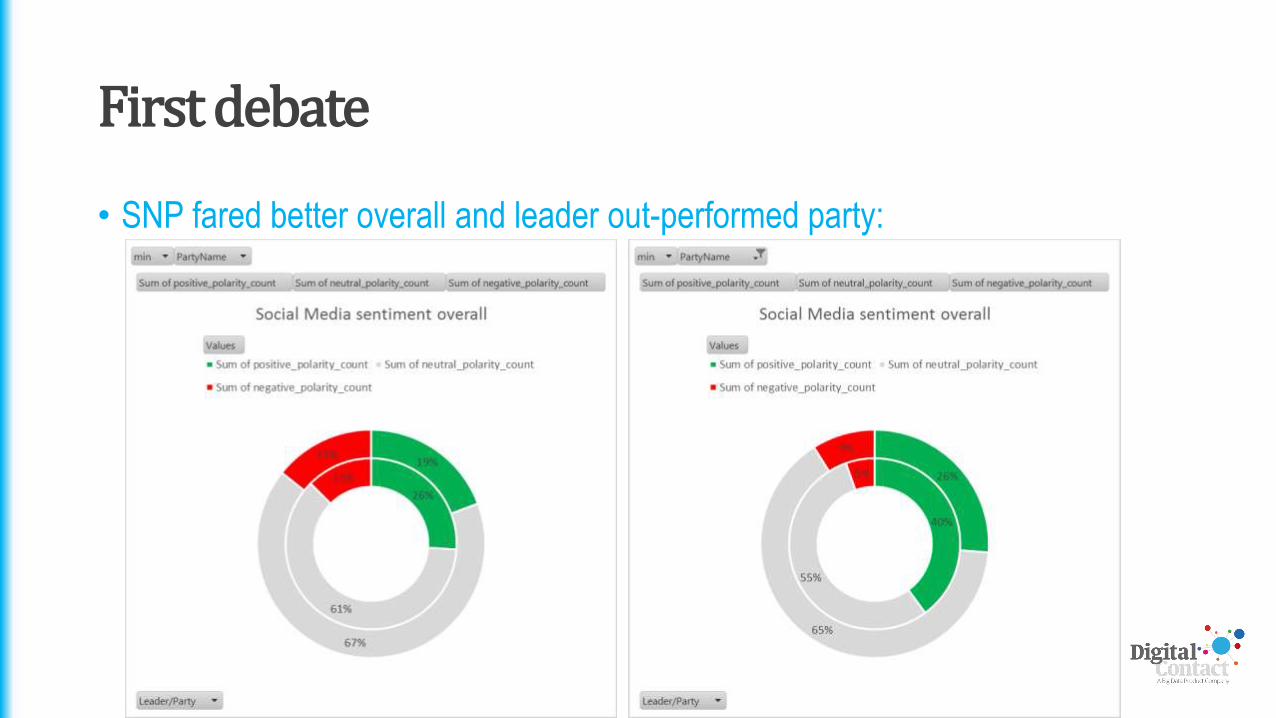
• SNP fared better overall and leader out-performed party:

Leaders’ Debates
• Data was processed with Hadoop within 5 minutes of debate being finished
• Analysed 10,000,000 tweets and extracted relevant information
• Able to provide a clear picture of social media
• Interesting result in second debate…
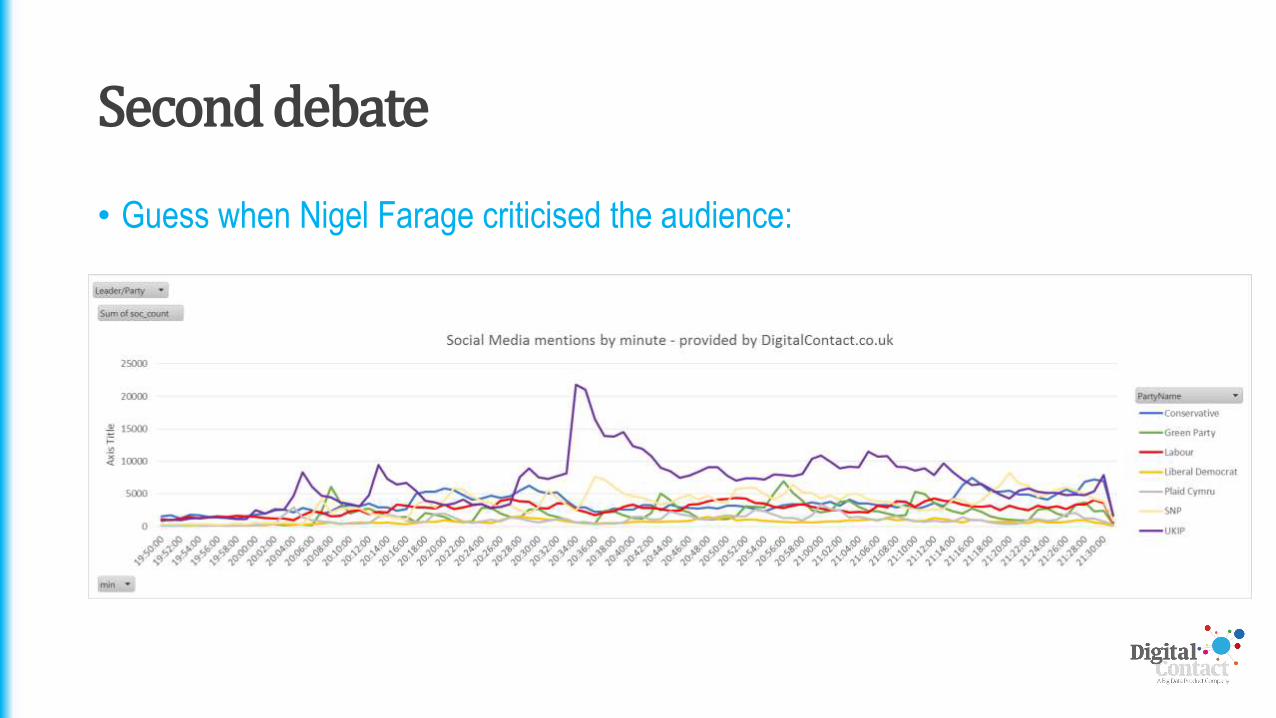
Second debate
• Guess when Nigel Farage criticised the audience:

Final Points
• Huge number of tools and methods for dealing with Big Data
• Good idea to work out what you want to find
• Is your data big? Can it be made bigger?
• Are your results useful? Can they be improved?
• Have fun!


















