Digital Language Divide Measuring Linguistic Diversity on the Internet UNESCO/UNU Conference on Globalization and Languages: Building on our Rich Heritage Tokyo, Japan, 27 – 28 August 2008 Yoshiki Mikami Leader, Language Observatory Project Executive Committee member of MAAYA Professor, Nagaoka Univ. of Technology
Transcript
Digital Language DivideMeasuring Linguistic Diversity
on the Internet
UNESCO/UNU Conference on Globalization and Languages: Building on our Rich Heritage
Tokyo, Japan, 27 – 28 August 2008
Yoshiki MikamiLeader, Language Observatory Project
Executive Committee member of MAAYAProfessor, Nagaoka Univ. of Technology
LANGUAGE OBSERVATORY 2
Outlines
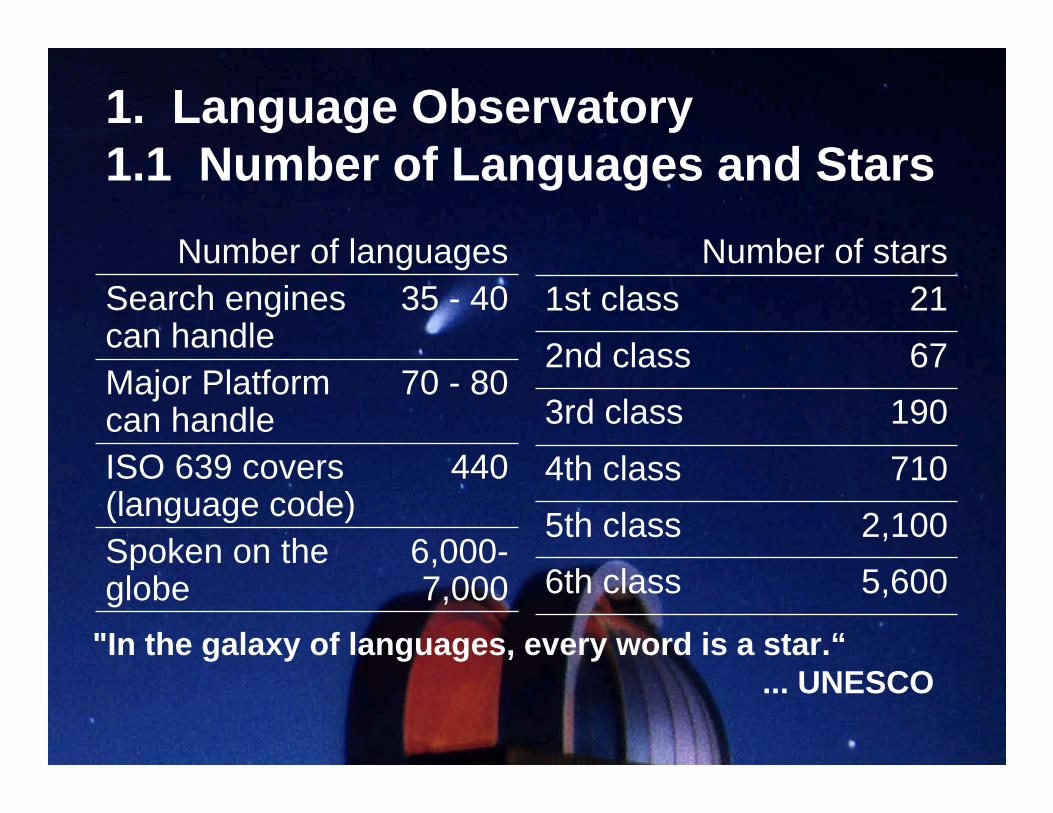
1. Language Observatory1.1 Language and Stars1.2 How It Functions?
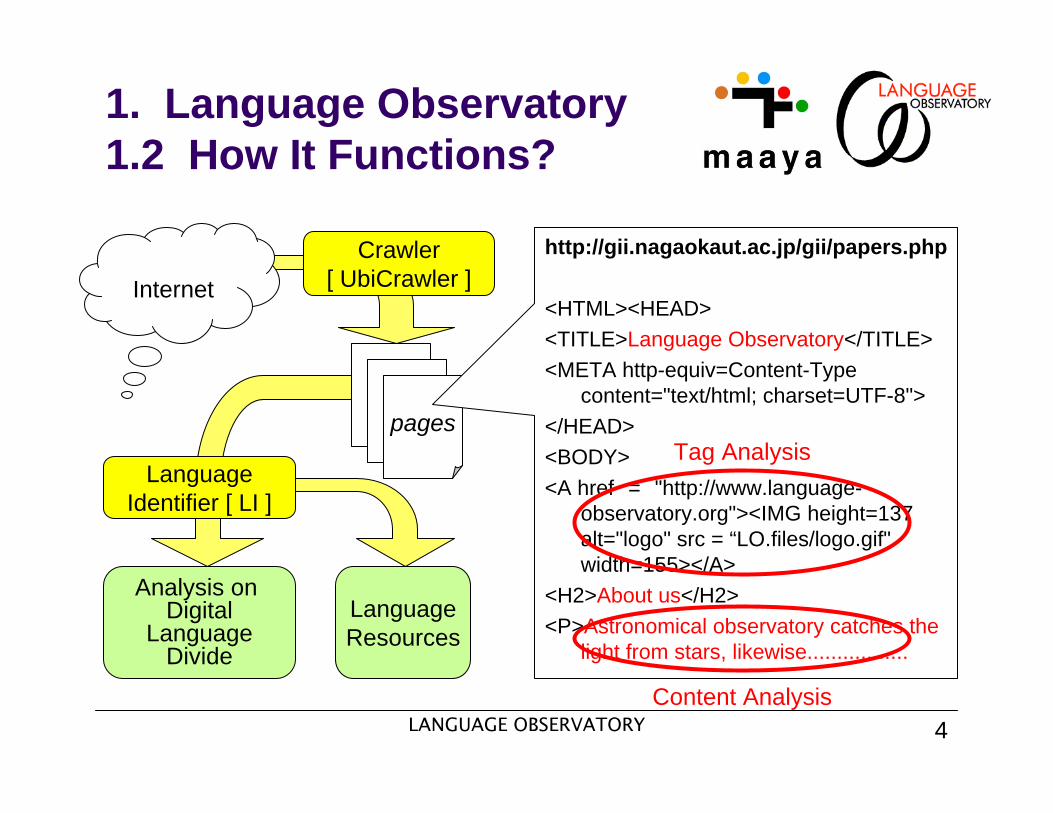
<H2>About us</H2><P>Astronomical observatory catches the
light from stars, likewise.................
Content Analysis
Tag Analysis
1. Language Observatory 1.2 How It Functions?
LANGUAGE OBSERVATORY 5
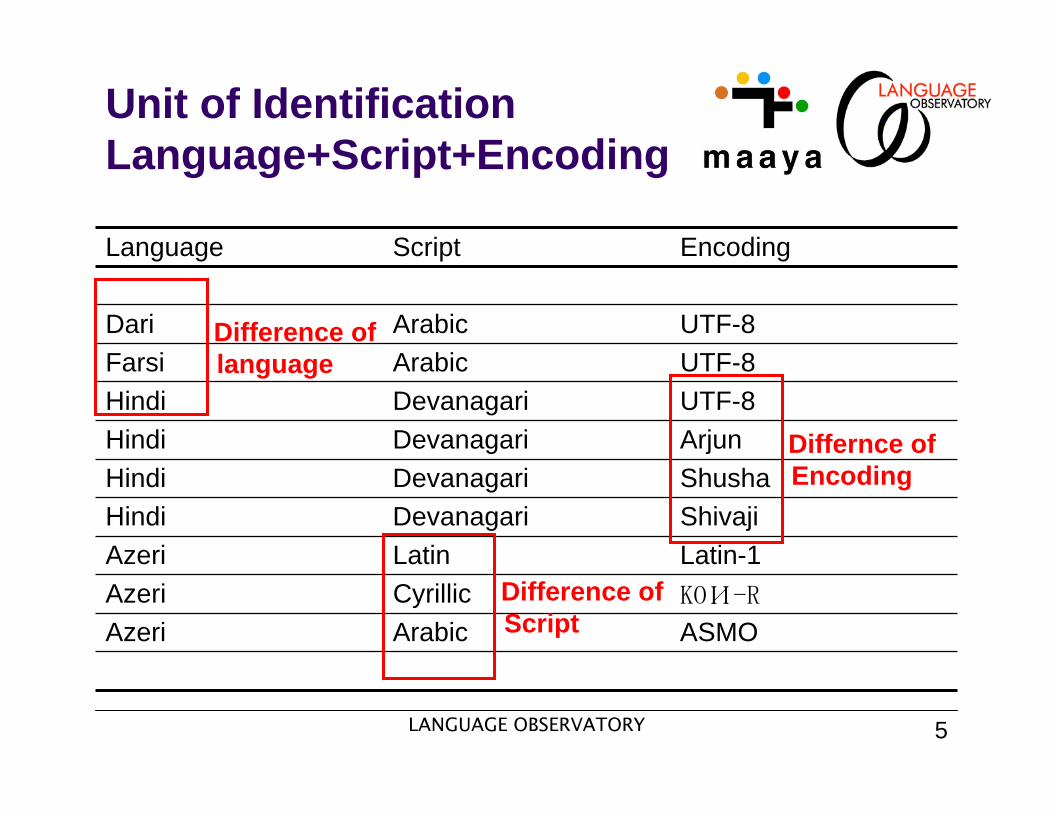
Language Script Encoding
Dari Arabic UTF-8Farsi Arabic UTF-8Hindi Devanagari UTF-8Hindi Devanagari ArjunHindi Devanagari ShushaHindi Devanagari ShivajiAzeri Latin Latin-1Azeri Cyrillic KOИ-R
Azeri Arabic ASMO
Differnce ofEncoding
Difference ofScript
Difference oflanguage
Unit of IdentificationLanguage+Script+Encoding
LANGUAGE OBSERVATORY 6
The Project Launched in 2004on Int’l Mother Language Day
UNESCO reported the launch of the project
LANGUAGE OBSERVATORY 7
Recommendation concerning the Promotion and Use of Multilingualism and Universal Access to Cyberspace, October 2003
[PREAMBLE]Noting that linguistic diversity in the global information networks and universal access to information in cyberspace are at the core of contemporary debates and can be a determining factor in the development of a knowledge-based society,
UNESCO Recommendation
LANGUAGE OBSERVATORY 8
Milestones, 2003 to 2007
Oct. 2003 UNESCO Adopted “Cyberspace Recommendation”Oct. 2003 Project started by the support of Japan Science and
Technology Agency (JST)Feb. 2004 The First Language Observatory WorkshopJun. 2004 Started to collect web data by “UbiCrawler”Aug. 2005 The First version of ”Language Identification Module”Nov. 2005 WSIS Tunis meetingFeb. 2006 World Network for Linguistic Diversity (MAAYA) createdJun. 2006 Workshop at Bamako, Mali on African SurveyFeb. 2007 Workshop at UNESCO, ParisSep. 2007 JST Funded Project Completed
LANGUAGE OBSERVATORY 9
Expert CollaborationCase of African Survey
June 26-28, 2006 at Bamako, Mali ACALANMaliAlgeriaBurkina FasoEthiopiaKenyaMalawiNigeriaTunisiaCNRS, France
LANGUAGE OBSERVATORY 10
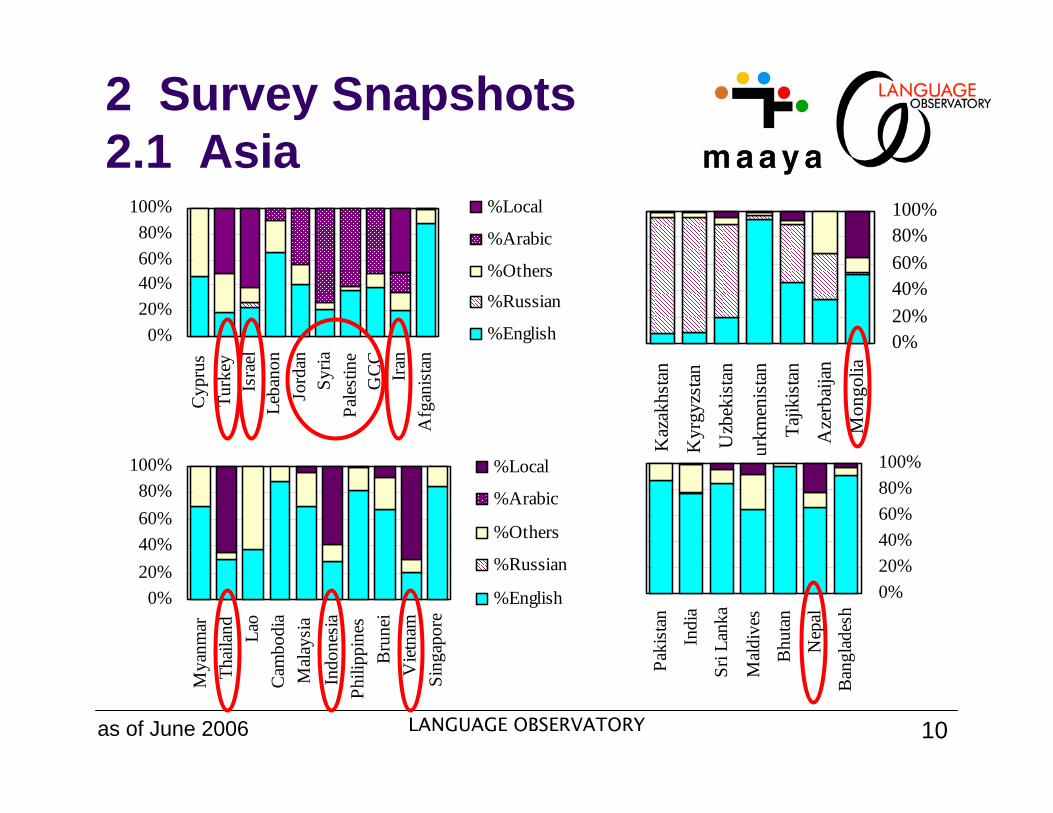
0%20%40%60%80%
100%C
ypru
sTu
rkey
Isra
elLe
bano
nJo
rdan
Syria
Pale
stin
eG
CC
Iran
Afg
anis
tan
%Local
%Arabic
%Others
%Russian
%English
0%20%40%60%80%
100%
Mya
nmar
Thai
land La
oC
ambo
dia
Mal
aysi
aIn
done
sia
Phili
ppin
esB
rune
iV
ietn
amSi
ngap
ore
%Local
%Arabic
%Others
%Russian
%English
0%20%40%60%80%100%
Kaz
akhs
tan
Kyr
gyzs
tan
Uzb
ekis
tan
Turk
men
ista
n
Tajik
ista
n
Aze
rbai
jan
Mon
golia
0%20%40%60%80%100%
Paki
stan
Indi
a
Sri L
anka
Mal
dive
s
Bhu
tan
Nep
al
Ban
glad
esh
as of June 2006
2 Survey Snapshots2.1 Asia
LANGUAGE OBSERVATORY 11
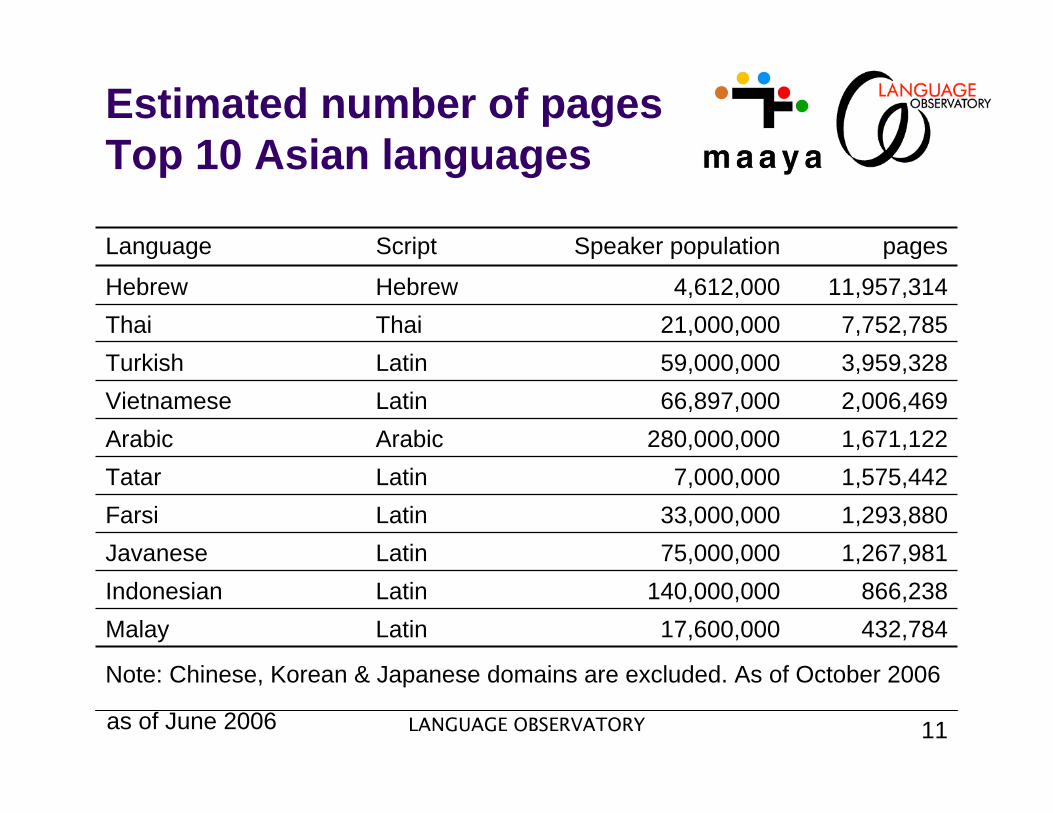
Estimated number of pagesTop 10 Asian languages
as of June 2006
Note: Chinese, Korean & Japanese domains are excluded. As of October 2006
Language Script Speaker population pages
Hebrew Hebrew 4,612,000 11,957,314Thai Thai 21,000,000 7,752,785Turkish Latin 59,000,000 3,959,328Vietnamese Latin 66,897,000 2,006,469Arabic Arabic 280,000,000 1,671,122Tatar Latin 7,000,000 1,575,442Farsi Latin 33,000,000 1,293,880Javanese Latin 75,000,000 1,267,981Indonesian Latin 140,000,000 866,238Malay Latin 17,600,000 432,784
LANGUAGE OBSERVATORY 12
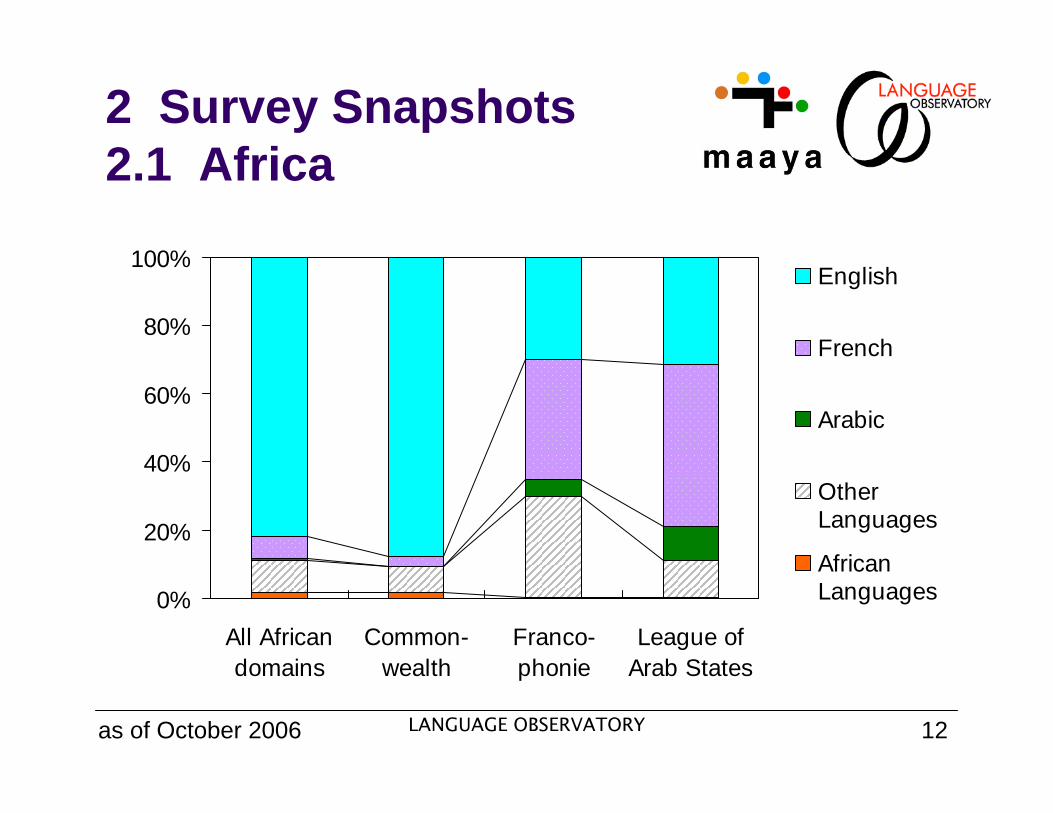
2 Survey Snapshots2.1 Africa
0%
20%
40%
60%
80%
100%
All Africandomains
Common-wealth
Franco-phonie
League ofArab States
English
French
Arabic
OtherLanguages
AfricanLanguages
as of October 2006
LANGUAGE OBSERVATORY 13
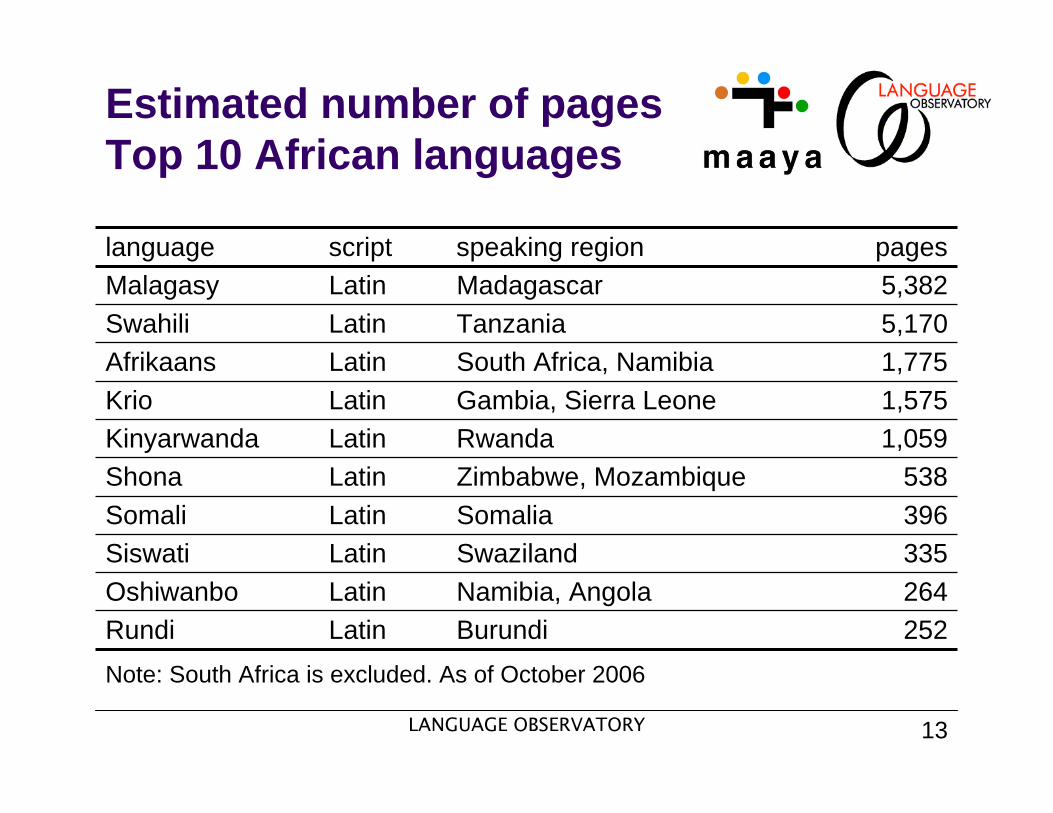
Estimated number of pagesTop 10 African languages
Note: South Africa is excluded. As of October 2006
language script speaking region pagesMalagasy Latin Madagascar 5,382Swahili Latin Tanzania 5,170Afrikaans Latin South Africa, Namibia 1,775Krio Latin Gambia, Sierra Leone 1,575Kinyarwanda Latin Rwanda 1,059Shona Latin Zimbabwe, Mozambique 538Somali Latin Somalia 396Siswati Latin Swaziland 335Oshiwanbo Latin Namibia, Angola 264Rundi Latin Burundi 252
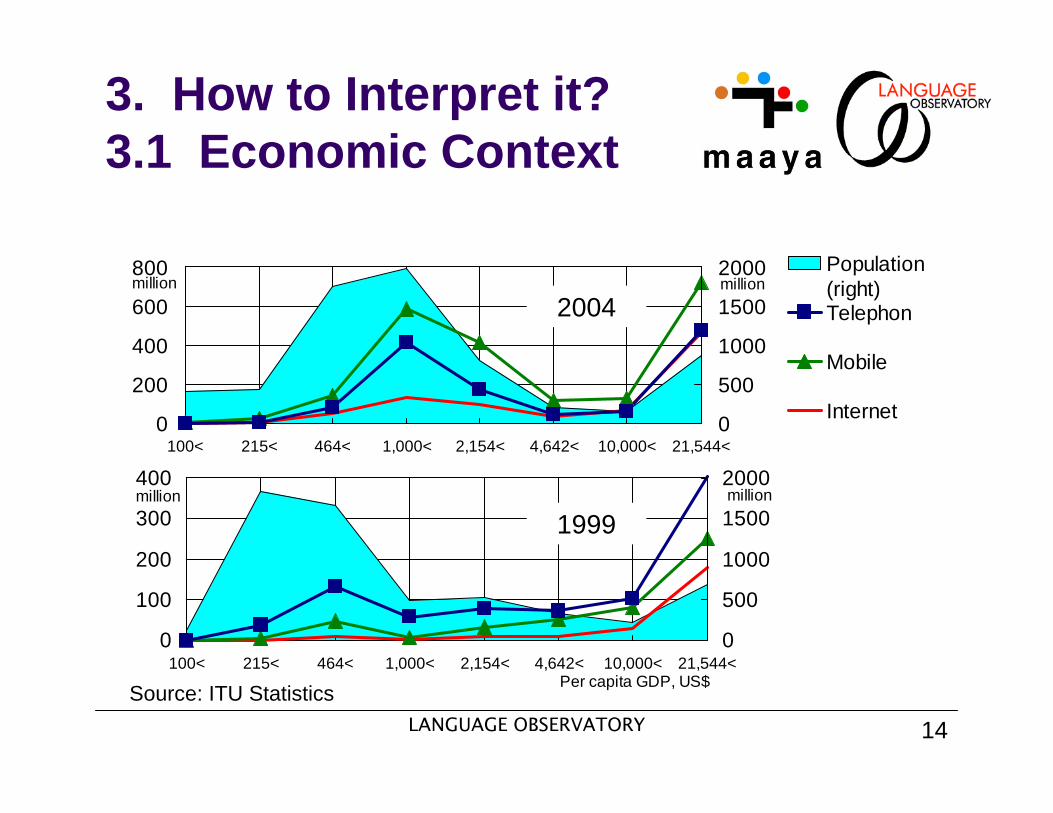
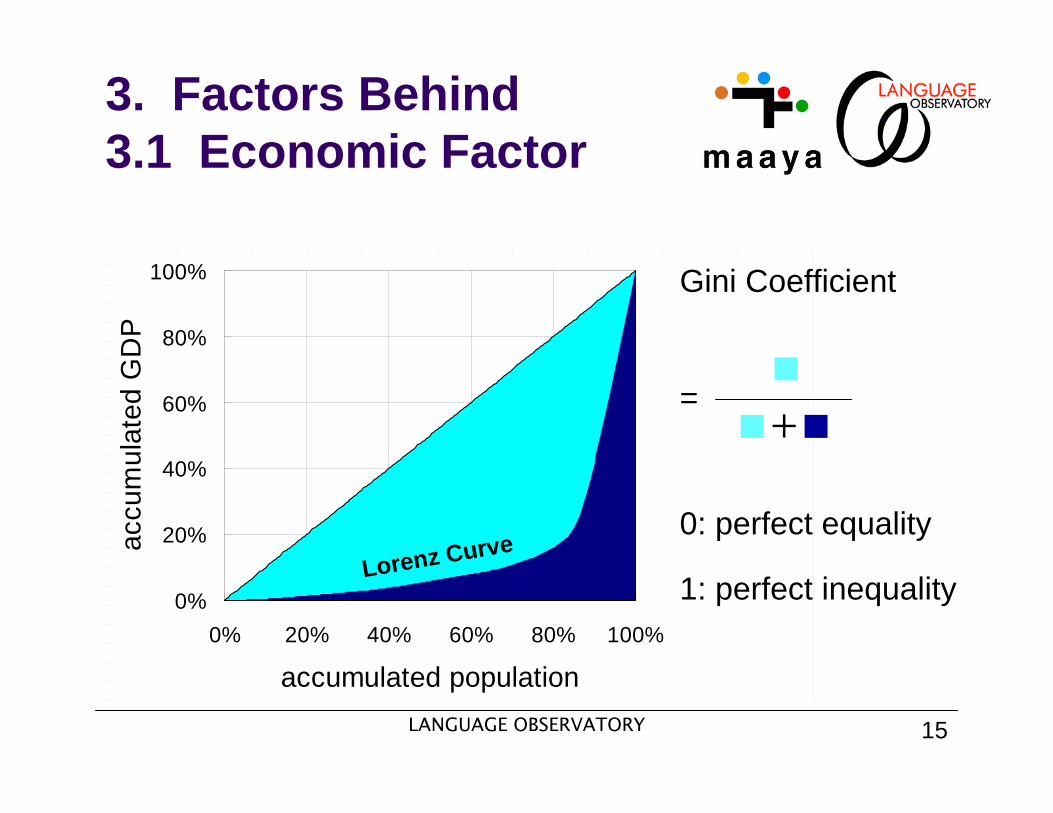
Gini-coefficient: Telephony 0.51 < GDP 0.73 < Internet 0.91
Telephony has been improved, but Internet is…
LANGUAGE OBSERVATORY 17
3.2 Technical FactorWorld Map of Scripts
Source: Akira Nakanishi, Writing Systems of the World, Charles Tuttle Co., Tokyo, 1980.
LANGUAGE OBSERVATORY 18
"Before I end this letter I wish to bring before Your Paternity's mind the fact that for many years I very strongly desired to see in this Province some books printed in the language and alphabet of the land, as there are in Malabar with great benefit for that Christian community. And this could not be achieved for two reasons; the first because it looked impossible to cast so many moulds amounting to six hundred, whilst as our twenty-four in Europe."
source: Priolkar, The Printing Press in India,Bombay, 1958
Doctrina Christam in Tamil, 1578
A Jesuit Friar’s letter, 1608Six hundred versus 24
LANGUAGE OBSERVATORY 19
“Doctrina Christiana”, bi-lingual version, printed in Tagalog by Tagalog script / in Tagalog by Latin script / in Spanish by Latin script. (1593)
Philippines postal stamp issued in 1995
Case of Tagalog:The script was finally lost
LANGUAGE OBSERVATORY 20
top to bottom
Tamil, Bengali, Sinhalese /
English, Hindi, Korean /
Myanmar, Thai
Asian Language Typewriter Collection
LANGUAGE OBSERVATORY 21
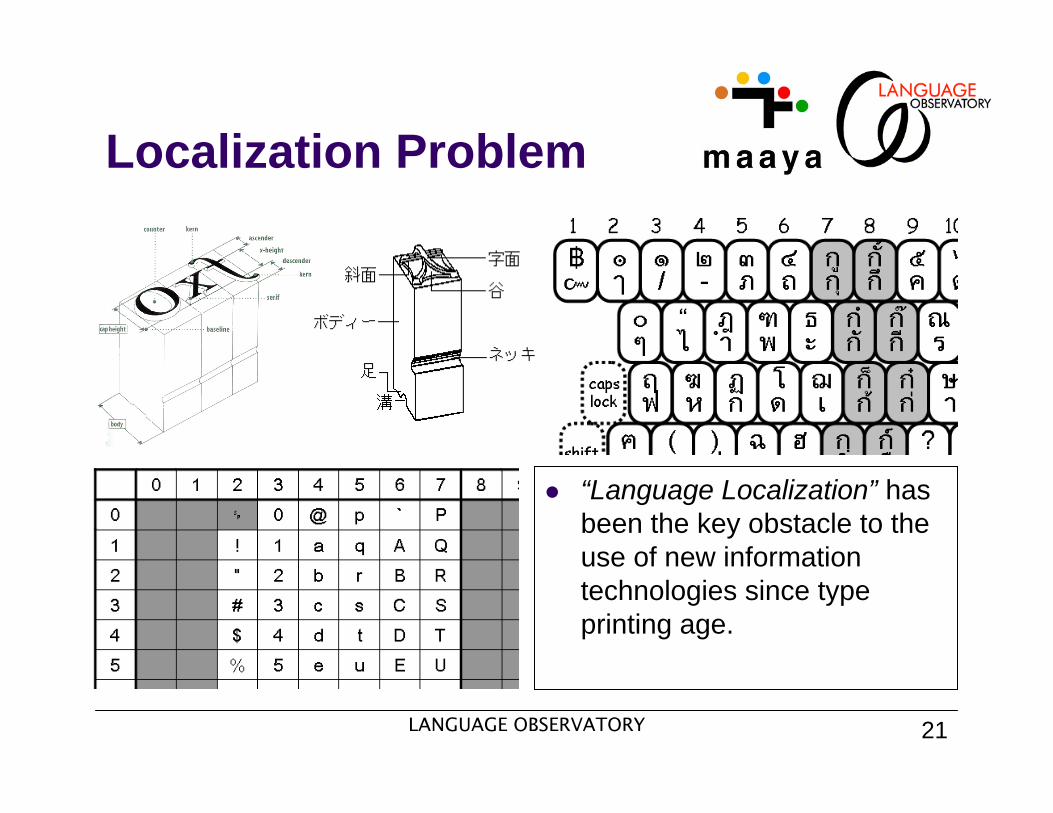
“Language Localization” has been the key obstacle to the use of new information technologies since type printing age.
Localization Problem
LANGUAGE OBSERVATORY 22
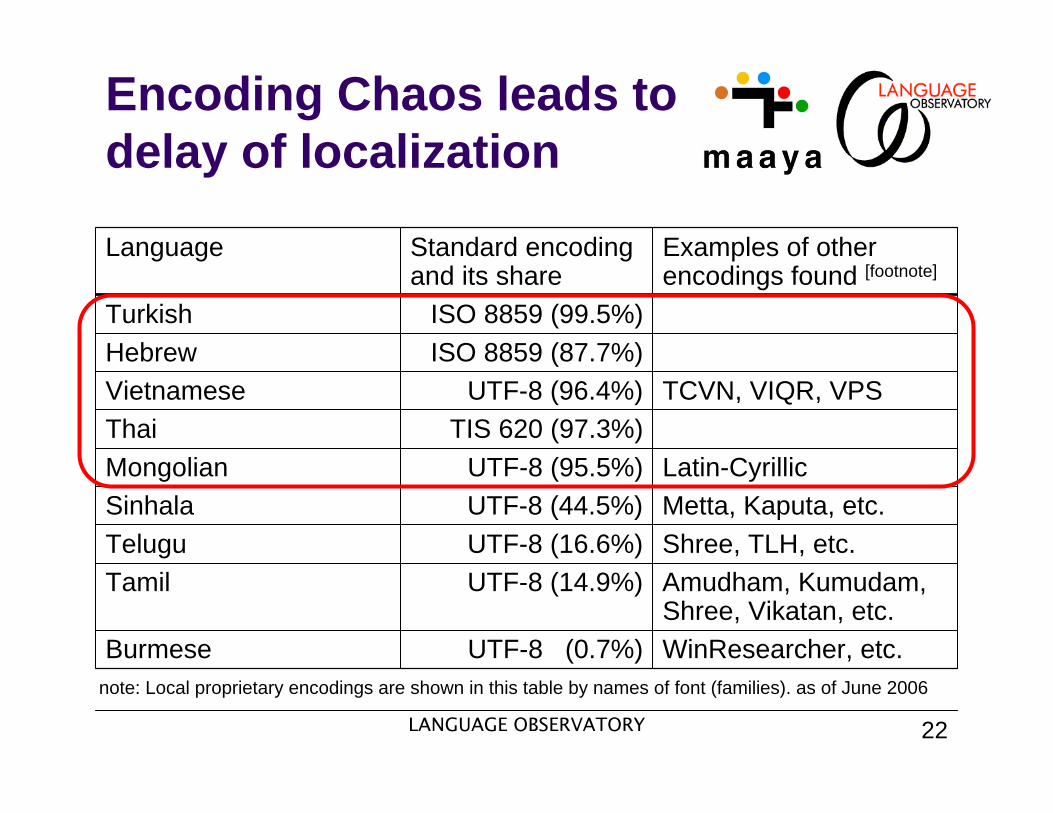
note: Local proprietary encodings are shown in this table by names of font (families). as of June 2006
Shree, Vikatan, etc.Burmese UTF-8 (0.7%) WinResearcher, etc.
Encoding Chaos leads todelay of localization
LANGUAGE OBSERVATORY 23
Personaldomain
Publicdomain
Occupationaldomain
Educational domain
Conversation, mail, phone, blog, magazines, newspaper, novel, songs, etc.
Official documents, laws and regulations, traffic signs, contract, legal, etc.
Business letter, invoice, manual, contract, name card, packaging, etc.
Textbook, academic journal, dictionary, scientific communication, etc.
Based on EU’s “Common European Framework of Reference for Languages”(2004)
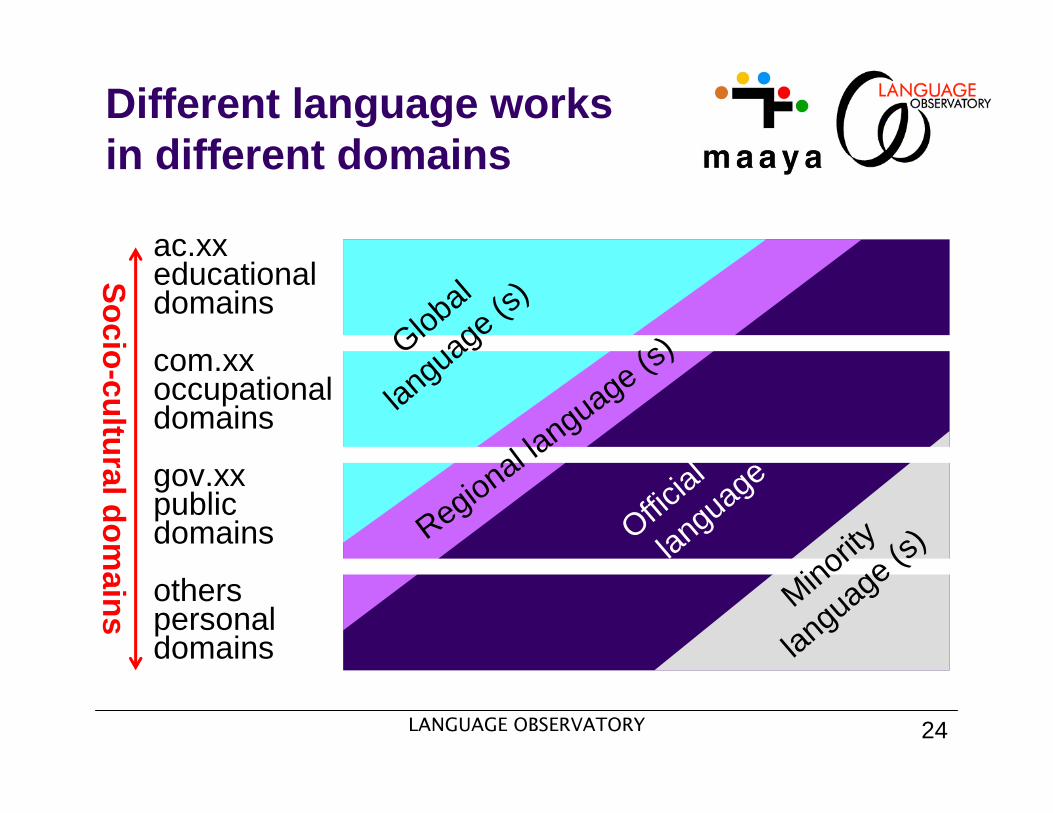
3.3 Socio-cultural FactorFour Domains of languages
LANGUAGE OBSERVATORY 24
ac.xxeducationaldomains
com.xxoccupationaldomains
gov.xxpublicdomains
otherspersonaldomains
Socio-cultural domains
Regional language (s
)
Official
language
Minority
language (s)
Global
language (s)
Different language works in different domains
LANGUAGE OBSERVATORY 25
others
gov
com
ac
English Others Turkish Tatar
others
gov
co
ac
English Russian Others Kazakh
others
gov
co
ac
English Arabic Others Farsi
Turkey
Kazakhstan Iran
others
gov
com
ac
English Greek Others Turkish
Cyprus
Specialization of LanguageSecondary domain analysis
LANGUAGE OBSERVATORY 26
4. Conclusion
“Digital Language Divide” observedEconomic context: Access opportunity divideTechnical context: Localization delaySocio-cultural context: Empowerment of Mother Languages is needed
Future of Language ObservatoryLanguage-specific search enginesLanguage Observatory Network
World Network for Linguistic Diversity
LANGUAGE OBSERVATORY 28Jehan Rectus Square, Parisphoto: courtesy by Wunna Ko Ko, June 2005
"In the galaxy of languages, every word is a star.“...UNESCO
























![Digital Language Divide - United Nations Universityarchive.unu.edu/globalization/2008/files/UNU-UNESCO...LANGUAGE OBSERVATORY 4 pages Crawler [ UbiCrawler ] Analysis on Digital Language](https://static.documents.pub/doc/80x56/5ab884da7f8b9ad5338ce7e4/digital-language-divide-united-nations-observatory-4-pages-crawler-ubicrawler.jpg)








