22
Digital Library Service – An overview Introduction System Architecture Components and their functionalities Experimental Results
| Date post: | 14-Dec-2015 |
| Category: |
Documents |
| Upload: | lia-herrin |
| View: | 227 times |
| Download: | 1 times |

Digital Library Service – An overview
Introduction System Architecture Components and their functionalities Experimental Results

Introduction Peer-to-Peer (P2P) Information Retrieval
framework Peers that share informationCumulative bandwidthHigh processing power and storageAbsence of high cost hardware
Three generations of P2P networks

1st Generation Centralized DB for coordinated look upNapster
2nd Generation Flooding to search every node on the networkGneutella
3rd Generation’Distributed Hash TablesTapestry, Chord, Pastry, CAN, Kademlia Uses routing tables to maintain the addresses of its
neighbours

In 3G P2P networks log N to N nodes have to be contacted to reach destination.
Proposed method, the target peer can be contacted directly from
the source peer.Search occurs within the target peer to
retrieve file reference using keyword indices in a B+ tree

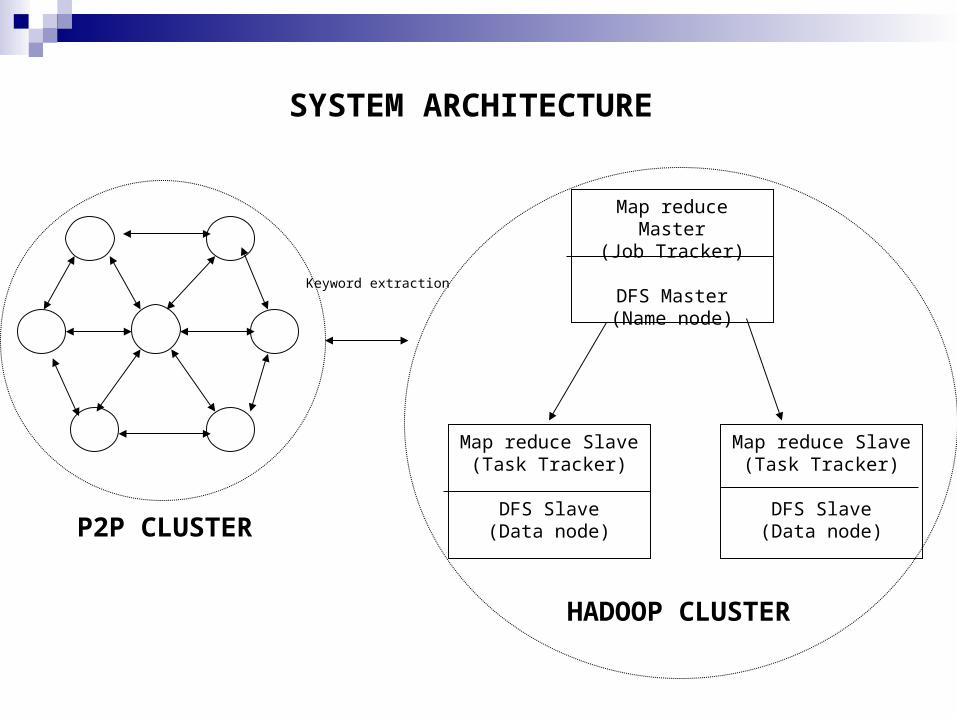
System Architecture
P2P cluster and Hadoop cluster Hadoop cluster
Extract keywords for efficient searchingMapReduce programming paradigm
P2P clusterUpload filesServicing search requests
Map reduce Master(Job Tracker)
DFS Master(Name node)
Map reduce Slave(Task Tracker)
DFS Slave(Data node)
Map reduce Slave(Task Tracker)
DFS Slave(Data node)
HADOOP CLUSTER
P2P CLUSTER
Keyword extraction
SYSTEM ARCHITECTURE

Hadoop Software platform to handle vast amounts of data Moving computation to the place of data rather than
moving large data blocks to the place of computation
HDFS and MapReduce frameworkHDFS – NameNode and DataNodeMapReduce computation
Map – splits input data set into fragments and assigns each fragment to a map task. (K,V)
Reduce – Merges all intermediate values associated with a key

D1,B1 D2,B1 D1,B2 D1,B3 D3,B1 D2,B2 D3,B2
M M M M M M M
K1,C1
K2,C1
K3,C1
K2,C2
K5,C2
K3,C2
K6,C3
K3,C3
K4,C3
K5,C4
K2,C4
K4,C4
K4,C5
K1,C5
K6,C5
K6,C6
K3,C6
K1,C6
K5,C7
K6,C7
K4,C7
Sort and Group (D2)
K1,[C6] K2,[C2] K3,[C2,C6] K5,[C2] K6,[C6]
Sort and Group (D1)
R R R R R R
K1,[C1] K2,[C1,C4] K3,[C1,C3] K4,[C4,C3] K5,[C4] K6,[C3]
R R R R R
K1,I K2,I K3, I K4, I K5, I K6,I K1, I K2, I K3, I K5, I K6, I
Map Task 1 Map Task 2 Map Task 3
Reduce Task 1 Reduce Task 2

B+ Tree – IP and its hash Represents sorted data indexed by a key for efficient
insertion, retrieval and removal of records. Inserting / Searching a record requires O(logBN)
operations in the worst case B - order, N - nodes
450
IP3
454
IP19
460
IP24
521
IP18
270
IP4
291
IP22
294
IP17
297
IP12
298
IP6
299
IP2
153
IP1
156
IP15
200
IP20
225
IP11
229
IP8
305
IP7
327
IP13
421
IP16
305
153 270 450
32
IP21
44
IP10
63
IP5
82
IP23
151
IP9
75
IP14 450
IP3
454
IP19
460
IP24
521
IP18
450
IP3
450
IP3
454
IP19
454
IP19
460
IP24
460
IP24
521
IP18
521
IP18
270
IP4
291
IP22
294
IP17
297
IP12
298
IP6
299
IP2
270
IP4
270
IP4
291
IP22
291
IP22
294
IP17
294
IP17
297
IP12
297
IP12
298
IP6
298
IP6
299
IP2
299
IP2
153
IP1
156
IP15
200
IP20
225
IP11
229
IP8
153
IP1
153
IP1
156
IP15
156
IP15
200
IP20
200
IP20
225
IP11
225
IP11
229
IP8
229
IP8
305
IP7
327
IP13
421
IP16
305
IP7
305
IP7
327
IP13
327
IP13
421
IP16
421
IP16
305305
153 270153 270 450450
32
IP21
44
IP10
63
IP5
82
IP23
151
IP9
75
IP14
32
IP21
32
IP21
44
IP10
44
IP10
63
IP5
63
IP5
82
IP23
82
IP23
151
IP9
151
IP9
75
IP14
75
IP14

DLS Components Start up component: Starting up the Hadoop cluster Identifying nodes to participate in the P2P
cluster. Determining the IP hash values for the peers
Using SHA1 (160-bit 40-bit) Forming the B+ tree. Uploading B+ trees in other peers. Starting the Web Server.

DB Distribution Component
Keyword extraction using Hadoop cluster Hashing keywords (SHA1 (160-bit40-bit) Find peer with relatively close match Upload in target peer Update B+ tree (Keyword – file-ref) in target

HADOOP CLUSTER
Doc 1 Doc 2 Doc n
File name, list of keywords
Hash search keys
Target Identification
Upload the documentin target
node
PEERS in P2P network

Search Component Process keywords Find 40-bit hash value Search the B+ tree in peer to identify target node Search B+ tree in target node to retrieve file
reference
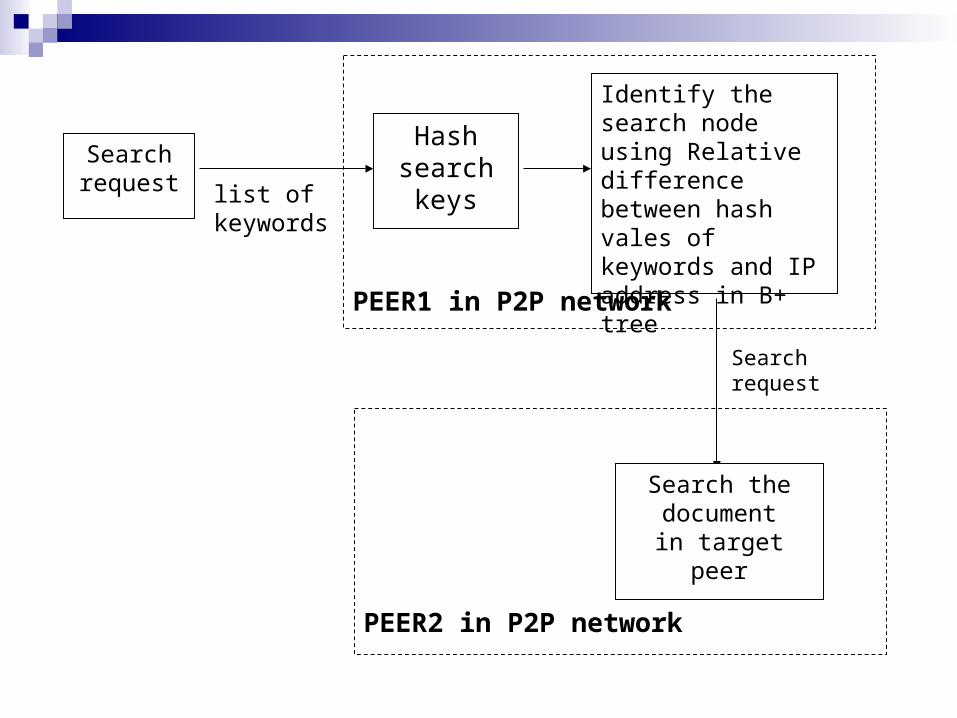
list of keywords
Hash search keys
Identify the search node using Relative difference between hash vales of keywords and IP address in B+ tree
Search the document
in target peer
PEER2 in P2P network
Search request
Search
request
PEER1 in P2P network

Add/Delete Peer Update IP address table Compute IP-hash of newly added peer Reconstruct the B+ tree and update in peers Relocate appropriate files to new peer Modify metadata in peers

Experimental Results – Keyword Extraction from multiple files(1MB each)
1 . 0 E + 0
1 0 0 . 0 E + 0
1 0 . 0 E + 3
1 . 0 E + 6
1 0 0 . 0 E + 6
1 0 . 0 E + 9
1 . 0 E + 1 2
1 f ile 2 f ile 3 f ile 4 f ile 5 f ile 6 f ile 7 f ile
N o o f F ile s
Tim
e in
nse
c
Observation – depends on no of keywords
0 . 0 0 E + 0 0
1 . 0 0 E + 0 9
2 . 0 0 E + 0 9
3 . 0 0 E + 0 9
4 . 0 0 E + 0 9
5 . 0 0 E + 0 9
6 . 0 0 E + 0 9
7 . 0 0 E + 0 9
8 . 0 0 E + 0 9
9 . 0 0 E + 0 9
2 4 6 1 0N o o f N o d e s
Tim
e i
n n
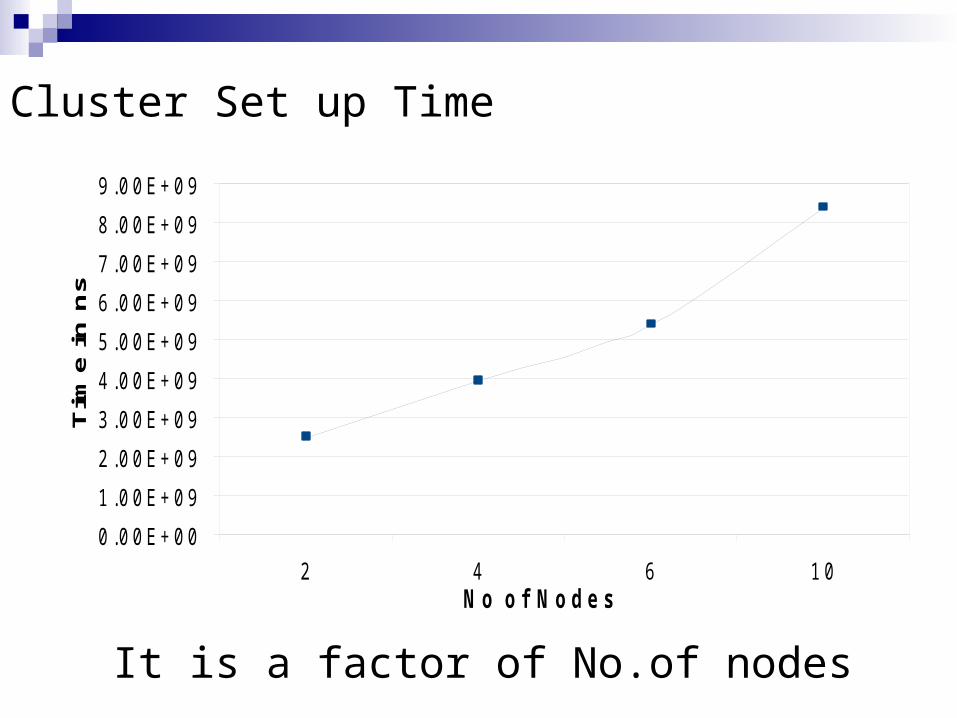
sCluster Set up Time
It is a factor of No.of nodes

0 . 0 0 E + 0 0
5 . 0 0 E + 0 9
1 . 0 0 E + 1 0
1 . 5 0 E + 1 0
2 . 0 0 E + 1 0
2 . 5 0 E + 1 0
2 – 3 3 – 4 4 – 5 5 – 6 6 – 7 7 – 8 8 – 9 9 – 1 0
N o . o f N o d e s
T
ime
in N
an
o
Se
co
nd
s
5 K e y w o r d s 1 0 K e y w o r d s 2 0 K e y w o r d s
Add a new Peer
It is a factor of No. of keywords (for 1 peer)

Performance of data distribution Component
0
2 E + 1 0
4 E + 1 0
6 E + 1 0
8 E + 1 0
1 E + 1 1
1 . 2 E + 1 1
5 1 0 2 0N o . o f K e y w o r d s
Tim
e i
n N
an
o
Se
co
nd
s
2 N o d e s 4 N o d e s 6 N o d e s 1 0 N o d e s
Load time is a factor of No.of keywords

Performance of Search Component
1 . 0 0 E + 0 6
1 . 0 0 E + 0 7
1 . 0 0 E + 0 8
1 2 3 4 5
N o o f N o d e s
Tim
e i
n n
se
c
Search time remains a constant (9 msec)
- B+ tree and search distribution
2 4 6 8 10

Conclusion P2P Information Retrieval Framework uses
3G P2P DHT approach B+ trees are maintained in peers Hadoop is used for keyword extraction from
multiple files in parallel Efficient search on peers

THANK YOU

















