51
Distributed Databases @ KIDS Labs 1

Distributed Databases
@ KIDS Labs 1

Distributed Database System
A distributed database system consists of
loosely coupled sites that share no physical
component
Appears to user as a single system
Database systems that run on each site are
independent of each other
Processing maybe done at a site other than the
initiator of request
@ KIDS Labs 2

Reasons for
Distributed Database • Business unit autonomy and distribution
• Data sharing
• Data communication costs
• Data communication reliability and costs
• Multiple application vendors
• Database recovery
• Transaction and analytic processing
@ KIDS Labs 3

Figure 13-1 – Distributed database environments (adapted
from Bell and Grimson, 1992)
@ KIDS Labs 4

Distributed Database Options
• Homogeneous - Same DBMS at each node – Autonomous - Independent DBMSs
– Non-autonomous - Central, coordinating DBMS
– Easy to manage, difficult to enforce
• Heterogeneous - Different DBMSs at different nodes – Systems – With full or partial DBMS functionality
– Gateways - Simple paths are created to other databases without the benefits of one logical database
– Difficult to manage, preferred by independent organizations
@ KIDS Labs 5

Distributed Database Options (cont.)
• Systems - Supports some or all functionality of
one logical database
– Full DBMS Functionality - All distributed DB functions
– Partial-Multi database - Some distributed DB functions
• Federated - Supports local databases for unique data requests
– Loose Integration - Local dbs have their own schemas
– Tight Integration - Local dbs use common schema
• Unfederated - Requires all access to go through a central,
coordinating module
@ KIDS Labs 6

Homogenous Distributed Database
Systems
All sites have identical software
They are aware of each other and agree to
cooperate in processing user requests
It appears to user as a single system
@ KIDS Labs 7
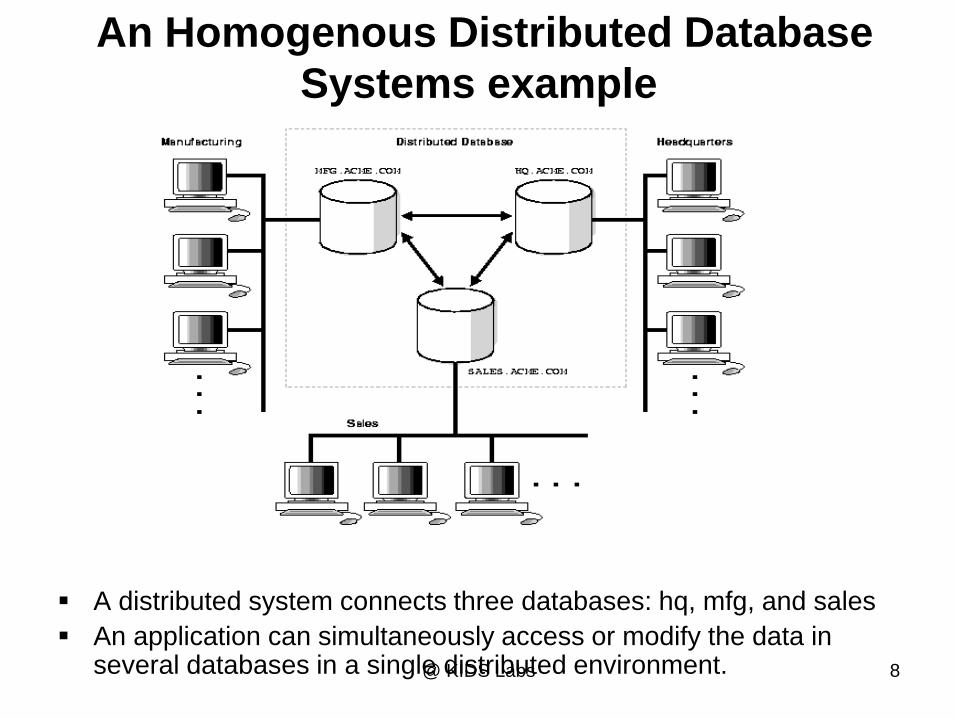
An Homogenous Distributed Database
Systems example
A distributed system connects three databases: hq, mfg, and sales
An application can simultaneously access or modify the data in several databases in a single distributed environment. @ KIDS Labs 8

Identical DBMSs
Figure 13-2: Homogeneous Database
Source: adapted from Bell and Grimson, 1992.
@ KIDS Labs 9

Heterogeneous Distributed Database
System
In a heterogeneous distributed database
system, at least one of the databases uses
different schemas and software.
A database system having different schema may
cause a major problem for query processing.
A database system having different software may
cause a major problem for transaction processing.
@ KIDS Labs 10
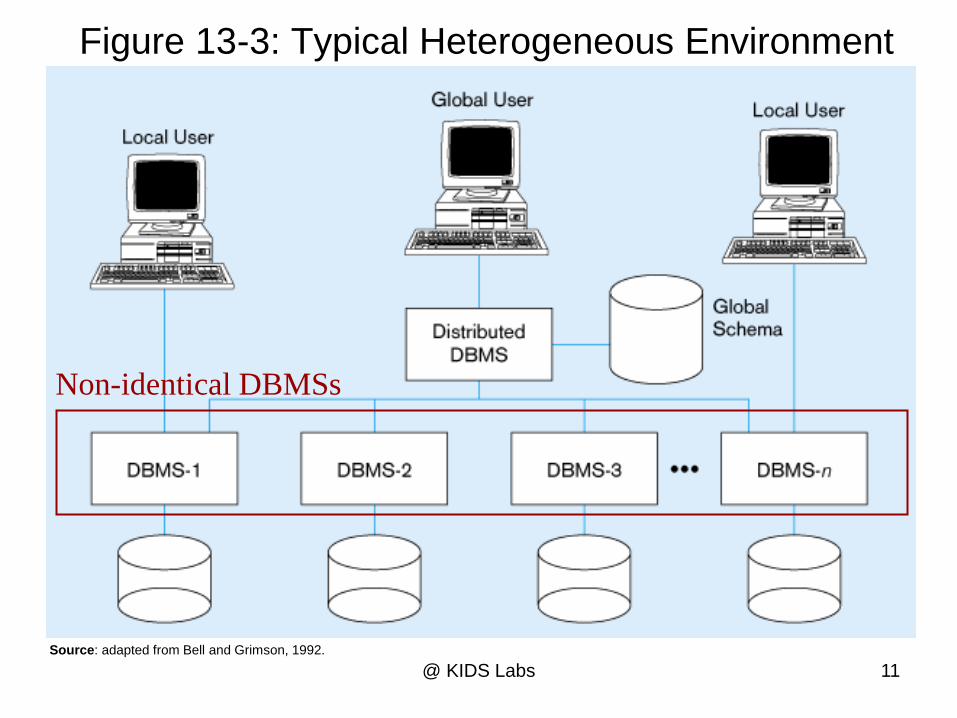
Figure 13-3: Typical Heterogeneous Environment
Non-identical DBMSs
Source: adapted from Bell and Grimson, 1992.
@ KIDS Labs 11

Major Objectives
• Location Transparency
– User does not have to know the location of the
data
– Data requests automatically forwarded to
appropriate sites
• Local Autonomy
– Local site can operate with its database when
network connections fail
– Each site controls its own data, security, logging,
recovery
@ KIDS Labs 12

Significant Trade-Offs • Synchronous Distributed Database
– All copies of the same data are always identical
– Data updates are immediately applied to all copies throughout network
– Good for data integrity
– High overhead slow response times
• Asynchronous Distributed Database – Some data inconsistency is tolerated
– Data update propagation is delayed
– Lower data integrity
– Less overhead faster response time
@ KIDS Labs 13

Advantages of
Distributed Database over Centralized Databases
• Increased reliability/availability
• Local control over data
• Modular growth
• Lower communication costs
• Faster response for certain queries
@ KIDS Labs 14

Disadvantages of
Distributed Database Compared to
Centralized Databases
• Software cost and complexity
• Processing overhead
• Data integrity exposure
• Slower response for certain queries
@ KIDS Labs 15

Distributed Data Storage
Replication – System maintains multiple copies of data, stored in
different sites, for faster retrieval and fault tolerance.
Fragmentation – Relation is partitioned into several fragments stored in
distinct sites
Replication and fragmentation can be combined • Relation is partitioned into several fragments: system
maintains several identical replicas of each such fragment.
@ KIDS Labs 16

Advantages of Replication
Availability: failure of site containing relation
r does not result in unavailability of r is
replicas exist.
Parallelism: queries on r may be processed
by several nodes in parallel.
Reduced data transfer: relation r is available
locally at each site containing a replica of r.
@ KIDS Labs 17

Disadvantages of Replication
Increased cost of updates: each replica of relation r must be updated.
Increased complexity of concurrency
control: concurrent updates to distinct
replicas may lead to inconsistent data unless
special concurrency control mechanisms are
implemented.
• One solution: choose one copy as primary copy
and apply concurrency control operations on
primary copy.
@ KIDS Labs 18

Fragmentation
Data can be distributed by storing individual
tables at different sites
Data can also be distributed by decomposing a
table and storing portions at different sites –
called Fragmentation
Fragmentation can be horizontal or vertical
@ KIDS Labs 19

Why use Fragmentation?
Usage - in general applications use views so it’s appropriate to
work with subsets
Efficiency - data stored close to where it is most frequently used
Parallelism - a transaction can divided into several sub-queries to
increase degree of concurrency
Security - data more secure - only stored where it is needed
Disadvantages:
Performance - may be slower
Integrity - more difficult
@ KIDS Labs 20

Horizontal Fragmentation
Each fragment, Ti , of table T contains a
subset of the rows
Each tuple of T is assigned to one or more
fragments.
Horizontal fragmentation is lossless
@ KIDS Labs 21

Horizontal Fragmentation Example
A bank account schema has a relation
Account-schema = (branch-name, account-number, balance).
It fragments the relation by location and stores each fragment locally: rows with branch-name = `Hillside` are stored in the Hillside in a fragment
@ KIDS Labs 22

Vertical Fragmentation
Each fragment, Ti, of T contains a subset of the columns, each column is in at least one fragment, and each fragment includes the key:
Ti = attr_listi (T)
T = T1 T2 ….. Tn
All schemas must contain a common candidate key (or superkey) to ensure lossless join property.
A special attribute, the tuple-id attribute may be added to each schema to serve as a candidate key.
@ KIDS Labs 23

Vertical Fragmentation Example
A employee-info schema has a relation
employee-info schema = (designation, name, Employee-id, salary).
It fragments the relation to put information in two tables for security concern.
@ KIDS Labs 24

Types of Data Replication
• Push Replication –
–updating site sends changes to other sites
• Pull Replication –
–receiving sites control when update messages will be processed
@ KIDS Labs 25

Types of Push Replication
• Snapshot Replication -
– Changes periodically sent to master site
– Master collects updates in log
– Full or differential (incremental) snapshots
– Dynamic vs. shared update ownership
Near Real-Time Replication -
– Broadcast update orders without requiring
confirmation
– Done through use of triggers
– Update messages stored in message queue until
processed by receiving site
@ KIDS Labs 26

Issues for Data Replication
• Data timeliness – high tolerance for out-of-date data may be required
• DBMS capabilities – if DBMS cannot support multi-node queries, replication may be necessary
• Performance implications – refreshing may cause performance problems for busy nodes
• Network heterogeneity – complicates replication
• Network communication capabilities – complete refreshes place heavy demand on telecommunications
@ KIDS Labs 27

Horizontal Partitioning
• Different rows of a table at different sites
• Advantages - – Data stored close to where it is used efficiency
– Local access optimization better performance
– Only relevant data is available security
– Unions across partitions ease of query
• Disadvantages – Accessing data across partitions inconsistent
access speed
– No data replication backup vulnerability
@ KIDS Labs 28

Vertical Partitioning
• Different columns of a table at different
sites
• Advantages and disadvantages are the
same as for horizontal partitioning except
that combining data across partitions is
more difficult because it requires joins
(instead of unions)
@ KIDS Labs 29

Figure 13-6
Distributed processing system for a manufacturing company
@ KIDS Labs 30

Distributed DBMS
• Distributed database requires distributed DBMS
• Functions of a distributed DBMS:
– Locate data with a distributed data dictionary
– Determine location from which to retrieve data and process
query components
– DBMS translation between nodes with different local
DBMSs (using middleware)
– Data consistency (via multiphase commit protocols)
– Global primary key control
– Scalability
– Security, concurrency, query optimization, failure recovery
@ KIDS Labs 31

Figure 13-10: Distributed DBMS architecture
@ KIDS Labs 32

Local Transaction Steps
1. Application makes request to distributed DBMS
2. Distributed DBMS checks distributed data repository for location of data. Finds that it is local
3. Distributed DBMS sends request to local DBMS
4. Local DBMS processes request
5. Local DBMS sends results to application
@ KIDS Labs 33

Figure 13-10: Distributed DBMS Architecture (cont.)
(showing local transaction steps)
Local transaction – all
data stored locally
1
3
4
5
2
@ KIDS Labs 34

Global Transaction Steps
1. Application makes request to distributed DBMS
2. Distributed DBMS checks distributed data repository for location of data. Finds that it is remote
3. Distributed DBMS routes request to remote site
4. Distributed DBMS at remote site translates request for its local DBMS if necessary, and sends request to local DBMS
5. Local DBMS at remote site processes request
6. Local DBMS at remote site sends results to distributed DBMS at remote site
7. Remote distributed DBMS sends results back to originating site
8. Distributed DBMS at originating site sends results to application
@ KIDS Labs 35
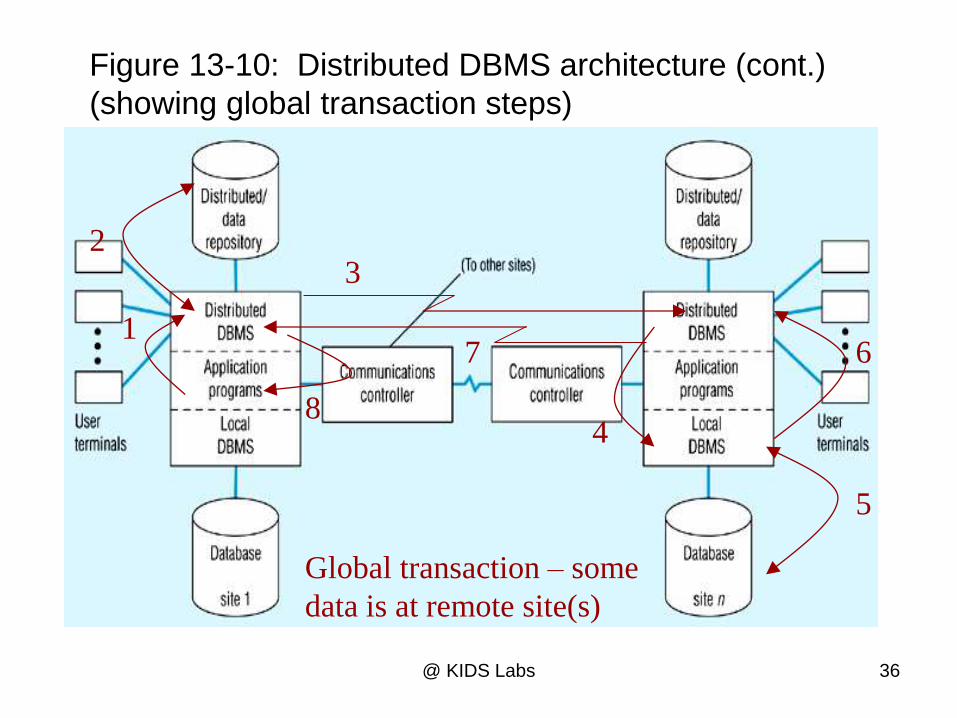
Figure 13-10: Distributed DBMS architecture (cont.)
(showing global transaction steps)
Global transaction – some
data is at remote site(s)
1
2
4
5
6
3
7
8
@ KIDS Labs 36

Distributed DBMS
Transparency Objectives • Location Transparency
– User/application does not need to know where data resides
• Replication Transparency
– User/application does not need to know about duplication
• Failure Transparency
– Either all or none of the actions of a transaction are committed
– Each site has a transaction manager
• Logs transactions and before and after images
• Concurrency control scheme to ensure data integrity
– Requires special commit protocol
@ KIDS Labs 37

Two-Phase Commit
• Prepare Phase
– Coordinator receives a commit request
– Coordinator instructs all resource managers to get ready to “go either way” on the transaction. Each resource manager writes all updates from that transaction to its own physical log
– Coordinator receives replies from all resource managers. If all are ok, it writes commit to its own log; if not then it writes rollback to its log
@ KIDS Labs 38

Two-Phase Commit (cont.)
• Commit Phase
– Coordinator then informs each resource manager of
its decision and broadcasts a message to either
commit or rollback (abort). If the message is commit,
then each resource manager transfers the update
from its log to its database
– A failure during the commit phase puts a transaction
“in limbo.” This has to be tested for and handled with
timeouts or polling
@ KIDS Labs 39

Concurrency Control
Concurrency Transparency
– Design goal for distributed database
• Timestamping
– Concurrency control mechanism
– Alternative to locks in distributed databases
@ KIDS Labs 40

Query Optimization
• In a query involving a multi-site join and, possibly, a distributed database with replicated files, the distributed DBMS must decide where to access the data and how to proceed with the join. Three step process:
1 Query decomposition - rewritten and simplified
2 Data localization - query fragmented so that fragments reference data at only one site
3 Global optimization - • Order in which to execute query fragments
• Data movement between sites
• Where parts of the query will be executed
@ KIDS Labs 41

Evolution of Distributed DBMS
• “Unit of Work” - All of a transaction’s steps.
• Remote Unit of Work
– SQL statements originated at one location can
be executed as a single unit of work on a single
remote DBMS
@ KIDS Labs 42

Evolution of Distributed DBMS
(cont.)
• Distributed Unit of Work – Different statements in a unit of work may refer to
different remote sites
– All databases in a single SQL statement must be at a single site
• Distributed Request – A single SQL statement may refer to tables in
more than one remote site
– May not support replication transparency or failure transparency
@ KIDS Labs 43

Commit Protocols
Commit protocols are used to ensure atomicity across sites
Atomicity states that database modifications must follow an “all or nothing” rule.
a transaction which executes at multiple sites must either be committed at all the sites, or aborted at all the sites.
@ KIDS Labs 44

The Two-Phase Commit (2 PC) Protocol
What is this?
Two-phase commit is a transaction protocol designed
for the complications that arise with distributed resource managers.
Two-phase commit technology is used for hotel and airline reservations, stock market transactions, banking applications, and credit card systems.
With a two-phase commit protocol, the distributed transaction manager employs a coordinator to manage the individual resource managers. The commit process proceeds as follows:
@ KIDS Labs 45

Phase1: Obtaining a Decision
Step 1 Coordinator asks all participants to prepare to commit transaction Ti.
Ci adds the records <prepare T> to the log and forces log to stable storage (a log is a file which maintains a record of all changes to the database)
sends prepare T messages to all sites where T executed
@ KIDS Labs 46

Phase1: Making a Decision
Step 2 Upon receiving message, transaction
manager at site determines if it can commit the
transaction
if not:
add a record <no T> to the log and send abort T
message to Ci
if the transaction can be committed, then:
1). add the record <ready T> to the log
2). force all records for T to stable storage
3). send ready T message to Ci
@ KIDS Labs 47

Phase 2: Recording the Decision
Step 1 T can be committed of Ci received a ready T message from all the participating sites: otherwise T must be aborted.
Step 2 Coordinator adds a decision record, <commit T> or <abort T>, to the log and forces record onto stable storage. Once the record is in stable storage, it cannot be revoked (even if failures occur)
Step 3 Coordinator sends a message to each participant informing it of the decision (commit or abort)
Step 4 Participants take appropriate action locally.
@ KIDS Labs 48

Two-Phase Commit Diagram
@ KIDS Labs 49

Costs and Limitations
There have been two performance issues
with two phase commit:
– If one database server is unavailable, none of
the servers gets the updates.
– This is correctable through network tuning
and correctly building the data distribution
through database optimization techniques.
@ KIDS Labs 50

@ KIDS Labs 51

















