36
DRIZZLE: Low latency execution for apache spark Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout
| Date post: | 21-Feb-2017 |
| Category: |
Data & Analytics |
| Upload: | spark-summit |
| View: | 127 times |
| Download: | 1 times |

DRIZZLE: Low latency execution for apache spark
Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout

Who am I ?
PhD candidate, AMPLab UC Berkeley Dissertation: System design for large scale machine learning Apache Spark PMC Member. Contributions to Spark core, MLlib, SparkR

Low latency: SPARK STREAMING
“Delivering low latency, high throughput, and stability simultaneously:* Right now, our own tests indicate you can get at most two of these characteristics out of Spark Streaming at the same time.” From https://goo.gl/wGCrtE
“How to choose right DStream batch interval” From https://goo.gl/6UX0FW
“Getting the best performance out of a Spark Streaming application on a cluster requires a bit of tuning…Reducing the processing time of each batch of data by efficiently using cluster resources. Setting the right batch size such that the batches of data can be processed as fast as they are received….” From spark.apache.org/docs/latest/streaming-programming-guide

Large Scale Stream Processing Goals

State
Low Latency
High Throughput
LARGE SCALE STREAM PROCESSING: PERFORMANCE

LARGE SCALE STREAM PROCESSING: ADAPTABLE
Straggler Mitigation
Fault Tolerance
Elasticity
Query Optimization

Execution Models

Computation models: RECORD-AT-A-TIME
Long-lived operators
Distributed Checkpoints (Chandy-Lamport)
Naiad Task
Control Message Driver
Network Transfer Streaming DBs: Borealis, Flux etc
Mutable State
Google MillWheel
Centralized task scheduling
Lineage, Parallel Recovery
Microsoft Dryad
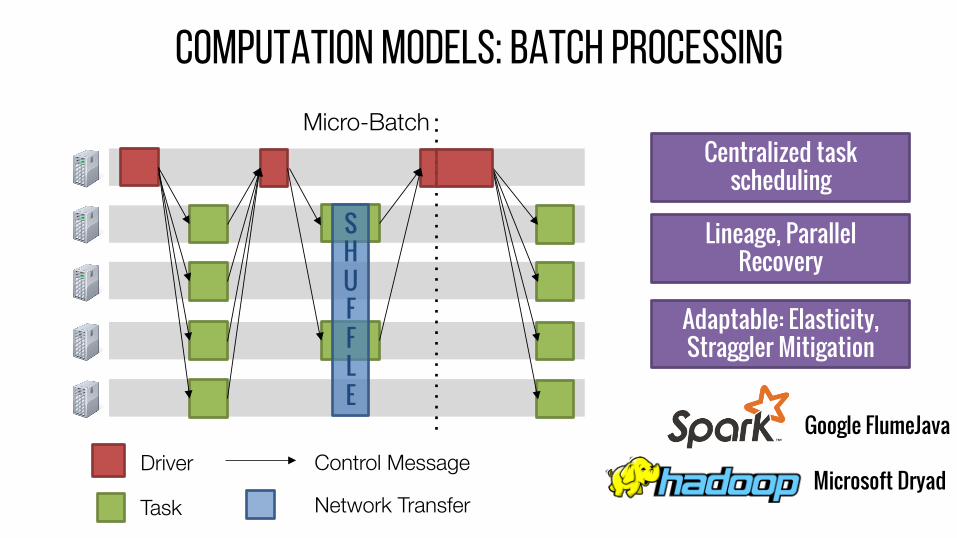
Computation models: batch processing
Task
Control Message Driver
SHUFFLE
Network Transfer
Micro-Batch
Adaptable: Elasticity, Straggler Mitigation
Google FlumeJava
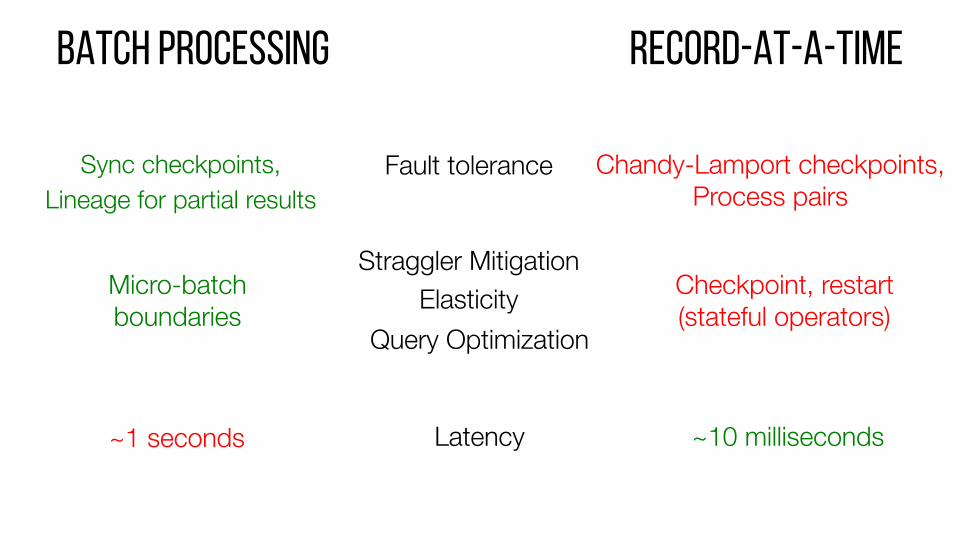
Sync checkpoints, Lineage for partial results
Fault tolerance
Straggler Mitigation Elasticity
RECORD-AT-A-TIME Batch processing
Micro-batch boundaries
~1 seconds
Checkpoint, restart (stateful operators)
Chandy-Lamport checkpoints, Process pairs
~10 milliseconds Latency
Query Optimization

Can we achieve low latency with Apache Spark ?

DESIGN INSIGHT
Fine-grained execution
with
Coarse-grained scheduling
Data Processing
Coordination
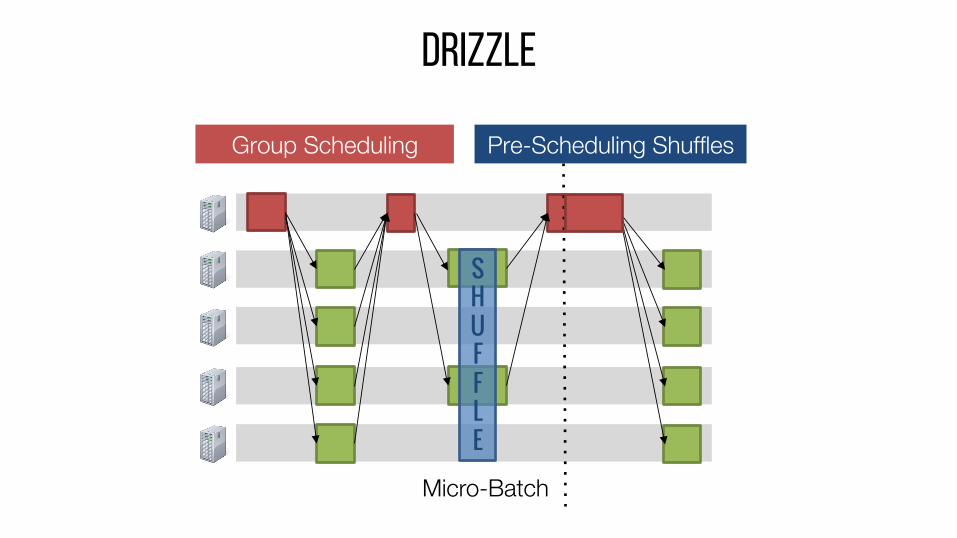
DRIZZLE
SHUFFLE
Micro-Batch
Group Scheduling Pre-Scheduling Shuffles
BACKGROUND: STREAMING On SPARK
Scheduler

DAG scheduling
Assign tasks to hosts using (a) locality preferences (b) straggler mitigation (c) fair sharing etc.
Tasks Host1
Host2
Driver
Host1
Host2
Serialize & Launch
Host Metadata
Scheduler
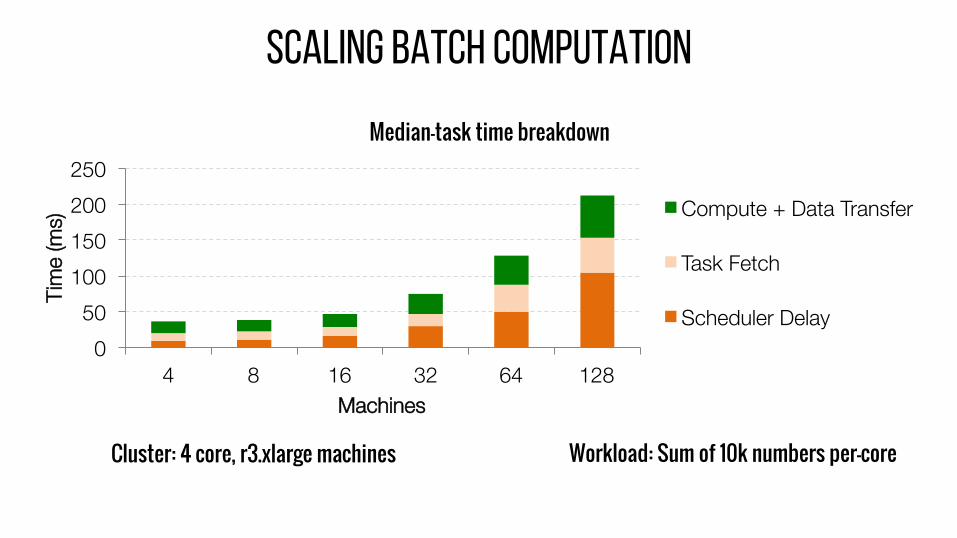
SCALING BATCH COMPUTATION
Cluster: 4 core, r3.xlarge machines Workload: Sum of 10k numbers per-core
Median-task time breakdown
0 50
100 150 200 250
4 8 16 32 64 128
Tim
e (m
s)
Machines
Compute + Data Transfer
Task Fetch
Scheduler Delay

DAG scheduling
Assign tasks to hosts using (a) locality preferences (b) straggler mitigation (c) fair sharing etc.
Tasks Host1
Host2
Driver
Host1
Host2
Serialize & Launch
Host Metadata
Scheduler
Same DAG structure for many iterations Can reuse scheduling decisions

GROUP scheduling
Schedule a group of iterations at once
Fault tolerance, scheduling at group boundaries
1 stage in each iteration
group = 2

How much does this help ?
1
10
100
1000
4 8 16 32 64 128
Tim
e / I
ter (
ms)
Machines
Apache Spark Drizzle-10 Drizzle-50 Drizzle-100
Workload: Sum of 10k numbers per-core
Single Stage Job, 100 iterations – Varying Drizzle group size

DRIZZLE
SHUFFLE
Micro-Batch
Group Scheduling Pre-Scheduling Shuffles

coordinating shuffles: Existing systems
Task
Control Message
Data Message
Driver
Intermediate Data
Driver sends metadata Tasks pull data

coordinating shuffles: PRE-SCHEDULING
Pre-schedule down-stream tasks on executors
Trigger tasks once dependencies are met
Task
Control Message Data Message
Driver
Intermediate Data
Pre-scheduled task

0 50
100 150 200 250 300
4 8 16 32 64 128
Tim
e / I
ter (
ms)
Machines
Baseline Only Pre-Scheduling
Drizzle-10 Drizzle-100
Micro-benchmark: 2-stages 100 iterations – Breakdown of pre-scheduling, group-scheduling

EXTENSIONS
Group size auto tuning Query optimization Iterative ML algorithms Fault tolerance

EXTENSIONS
Group size auto tuning Query optimization Iterative ML algorithms Fault tolerance

group=1 à Batch processing
GROUP scheduling trade-offs
Higher overhead Smaller window for fault tolerance
group=N à Parallel operators
Lower overhead Larger window for fault tolerance

GROUP scheduling – AUTO TUNING
Goal : Smallest group such that overhead is between fixed threshold
Tuning algorithm - Measure scheduler delay, execution time per group - If overhead > threshold, multiplicatively increase group size - If overhead < threshold, additively decrease group size
Similar to AIMD schemes used in TCP congestion control

QUERY OPTIMIZATION
Intra-Batch Inter-Batch
Predicate Push Down Vectorization
...
Operator Selection Data Layout
...
…

MLLIB ALGORITHMS
Iterative patterns à Gradient Descent PCA …
Similar structure to streaming ! Model stored, updated as shared state Parameter server integration
State

EVALUATION
Yahoo! Streaming Benchmark Experiments
- Latency - Throughput - Fault tolerance
Comparing Spark 2.0, Flink 1.1.1, Drizzle Amazon EC2 r3.xlarge instances

0 0.2 0.4 0.6 0.8
1
0 500 1000 1500 2000 2500 3000 Event Latency (ms)
Spark
Drizzle
Flink
Streaming BENCHMARK - performance
Yahoo Streaming Benchmark: 20M JSON Ad-events / second, 128 machines
Event Latency: Difference between window end, processing end

Optimize execution of each micro-batch by pushing down aggregation
INTRA-BATCH QUERY optimization
Yahoo Streaming Benchmark: 20M JSON Ad-events / second, 128 machines
0 0.2 0.4 0.6 0.8
1
0 500 1000 1500 2000 2500 3000 Event Latency (ms)
Spark
Drizzle
Flink
Drizzle-Optimized

Weak-scaling throughput Yahoo Streaming Benchmark: 150,000 events/sec per machine
Weak scaling from 4 to 128 machines (600k to 19.2M events/s)
0
400
800
1200
1600
4 8 16 32 48 64 96 128 Med
ian E
vent
Lat
ency
(ms)
Machines
Spark Flink Drizzle Drizzle-Optimized

FAULT TOLERANCE
0
5000
10000
15000
20000
150 200 250 300 350
Late
ncy
(ms)
Time (seconds)
Drizzle Spark Flink
Inject machine failure at 240 seconds

OPEN SOURCE UPDATE
Spark Scheduler Improvements - SPARK-18890, SPARK-18836, SPARK-19485 - Addresses serialization, RPC bottlenecks etc.
Design discussion to integrate Drizzle: SPARK-19487
Open source code at: https://github.com/amplab/drizzle-spark

conclusion
Low latency during execution and while adapting Drizzle: Decouple execution from centralized scheduling Amortize overheads using group scheduling, pre-scheduling
Shivaram Venkataraman [email protected]
Source Code: https://github.com/amplab/drizzle-spark




![[Venkataraman] at the Speed of Light](https://static.documents.pub/doc/80x56/55cf8cd75503462b139013a3/venkataraman-at-the-speed-of-light.jpg)












