21
Dynamics of Cooperation in Spatial Prisoner’s Dilemma of Memory-Based Players Chenna Reddy Cotla Department of Computational Social Science George Mason University Fairfax, VA, USA

Dynamics of Cooperation in Spatial Prisoner’s Dilemma of Memory-Based Players
Chenna Reddy CotlaDepartment of Computational Social ScienceGeorge Mason UniversityFairfax, VA, USA

Research QuestionWhat are the emergent dynamics
of cooperation in a population of memory based agents whose interaction is spatially constrained to local neighborhoods on a square lattice?

Prisoner’s Dilemma Prisoner’s Dilemma is an extensively studied Social Dilemma that
characterizes the problem of cooperation. Not enough evidence to convict two suspects of armed robbery,
enough for theft of getaway car Both confess (3 years each), both stay quiet (1 years each), one
tells (0 years) the other doesn’t (5 years) Stay quiet= cooperate (C) ; confess = defect (D) Payoff Matrix:
T > R > P > S
R is REWARD for mutual cooperation = 3S SUCKER’s payoff = 0T TEMPTATION to defect = 5P PUNISHMENT for mutual defection = 1

Cooperation in a finite population:Evolutionary Spatial Prisoner’s Dilemma Evolutionary dynamics along with non-random localized
strategic interactions on a spatial structure can support cooperation.
Players are located on a lattice and play bilateral PD with their neighbors depending upon the notion of neighborhood.
Sum payoff is gathered in each generation. Each player imitates the strategy of best scoring neighbor
in the next generation.
Moore Neighbors Von Neumann Neighbors
Nowak, M. and May, R. (1992). Evolutionary games and spatial chaos. Nature, 359(6398):826–829.

Evolutionary SPD
Fraction of cooperators in evolutionary SPD independent of initial configurationfor Von Neumann neighborhood
Nowak, M. and May, R. (1992). Evolutionary games and spatial chaos. Nature, 359(6398):826–829.

Evolutionary SPD: SignificanceRegular lattices represent a
limiting case of interaction topologies in the real world.
Emphasizes the importance of localized interaction in the emergence of cooperation.

Why we may need alternative models?Very simplistic assumptions about players:
no memory or reasoning.Players are pure imitators.May be more suitable for biological context
than social context.Recent experiments with human subjects
have shown that humans do not unconditionally imitate the best scoring neighbor as assumed in evolutionary SPD (Traulsen et al., 2009, Grujic et al., 2010 ).
Traulsen, A., Semmann, D., Sommerfeld, R., Krambeck, H., and Milinski, M. (2010). Human strategy updating in evolutionary games. Proceedings of the National Academy of Sciences, 107(7):2962.Grujic, J., Fosco, C., Araujo, L.,Cuesta, A.,and Sanchez, A. (2010). Social experiments in the meso scale: Humans playing a spatial prisoner’s dilemma, PLOS ONE, 5(11):e13749.

SPD with ACT-R agentsSPD with agents that make use of
memory model embodied in ACT-R cognitive architecture.
Why ACT-R?◦ ACT-R memory model was able to
reproduce important empirical dynamics in two person Prisoner’s Dilemma (Lebiere et al., 2000).
Lebiere, C., Wallach, D., and West, R. L. (2000). A memory-based account of the prisoner’s dilemma and other 2× 2 games. In Proceedings of the 3rd International Conference on Cognitive Modeling, pages 185–193.,

Higher Level Decision Making in ACT-R: Knowledge Representation In ACT-R Procedural and Declarative Knowledge interact to
produce higher level cognition. Procedural Memory:
◦ Implemented as a set of productions.◦ Basically IF THEN conditions that specify when a particular production
rule apply and what it does.◦ Example : A production to add two numbers IF the goal is to add n1 and n2 and n1 + n2 = n3 THEN set as subgoal to write n3 as a result.
Declarative Memory ◦ Memory of facts represented as a collection of declarative structures
called chunks. Example: An Addition fact Fact 3+4
isa additionfact addend1 three addend2 four sum seven

Higher Level Decision Making in ACT-R: Knowledge Deployment In ACT-R Procedural and Declarative Knowledge interact to produce
higher level cognition. The production rules are selected based on their utility and the
declarative chunks are retrieved based on sub symbolic quantities called activation levels.
Activation of a chunk:
In ACT-R the activation levels of declarative chunks reflect frequency and recency of usage and the contextual similarity. Also, noise is added to account for stochastic component in decision making.
Base level activation Bi reflects the general usefulness of a given chunk based on how recently and frequently it was used in the past for achieving a goal. It is calculated using the following equation:
◦ d is forgetting rate and tj is the time since jth access.

Representational Details of Game Playing Mechanism Basic idea is to store game outcomes as chunks and use a single
production rule that captures decision making. If we consider a neighborhood of size n there are 2n+1 outcomes.
◦ Exponential computational time and space requirements.◦ We may run out of memory as n increases and we may need to wait for
years to compute according to current computational standards. To simplify matters a totalistic representation is used based on the
total payoff. Chunk C-kC is used to represent outcome when the given player
cooperated and k neighbors have also cooperated. D-kC represent the same scenario with the given player defecting.
Only 2n+2 chunks are needed. Activation is calculated using following computationally efficient
approximation (Petrov, 2006):
Petrov, A. (2006). Computationally efficient approximation of the base-level learning equation in act-r. In Proceedings of the Seventh International Conference on Cognitive Modeling, pages, 391–392.

Chunks and Production Rule Declarative Memory when a neighborhood of size n is
considered: (2n+2) Chunks
(C-nC isa outcome p-action C N-config nC payoff nR)(C-(n-1)C isa outcome p-action C N-config (n-1)C payoff (n-1)R + S)…(C-kC isa outcome p-action C N-config kC payoff kR + (n − k)S)…(C-1C isa outcome p-action C N-config 1C payoff R + (n − 1)S) (C-0C isa outcome p-action C N-config 0C payoff nS)
(D-nC isa outcome p-action D N-config nC payoff nT ) (D-(n − 1)C isa outcome p-action D N-config (n − 1)C payoff (n − 1)T + P
…(D-kC isa outcome p-action D N-config kC payoff kT + (n − k)P )…(D-1C isa outcome p-action D N-config 1C payoff T + (n − 1)P ) (D-0C isa outcome p-action D N-config 0C payoff nP)

Chunks and Production Rule Production Rule:
IF the goal is to play Spatial Prisoner’s Dilemma and the most likely outcome of C is OutcomeC and the most likely outcome of D is OutcomeD THEN make the move associated with the largest payoff of OutcomeC and OutcomeD
Observe the opponent move and push new goal to make the next play.

Illustrative Scenario: Von Neumann Neighborhood Declarative Memory when V-N neighborhood is considered: 10 Chunks
(C-4C isa outcome p-action C N-config 4C payoff 4R)(C-3C isa outcome p-action C N-config 3C payoff 3R + S)(C-2C isa outcome p-action C N-config 2C payoff 2R + 2S)
(C-1C isa outcome p-action C N-config 1C payoff R + 3S)(C-0C isa outcome p-action C N-config 0C payoff 4S)(D-4C isa outcome p-action D N-config 4C payoff 4T)(D-3C isa outcome p-action D N-config 3C payoff 3T + P)(D-2C isa outcome p-action D N-config 2C payoff 2T + 2P)(D-1C isa outcome p-action D N-config 1C payoff T + 3P)(D-0C isa outcome p-action D N-config 0C payoff 4P)
Production Rule: IF the goal is to play Spatial Prisoner’s Dilemma and the most likely outcome of C is OutcomeC and the most likely outcome of D is OutcomeD THEN make the move associated with the largest payoff of OutcomeC and OutcomeD
Observe the opponent move and push new goal to make the next play.

Illustrative Scenario: Von Neumann Neighborhood
Chunk Activation
C-4C 0.10C-3C 0.31C-2C 0.03C-1C 0.11C-0C 0.05
Chunk PayoffC-4C 12C-3C 9C-2C 6C-1C 3C-0C 0D-4C 20D-3C 16D-2C 12D-1C 8D-0C 4
Chunks associated with CChunk Activati
onD-4C 0.14D-3C 0.04D-2C 0.23D-1C 0.29D-0C 0.05
Chunks associated with D
Chunks and payoffs
C
C-3C with payoff 9 D-1C with payoff 8

Global Cooperation in SPD with Memory Based Agents (Synchronous Updating)
Lattice size: 100 × 100 Pay off matrix considered: { T = 5, R = 3, P = 1, S = 0} Cooperation levels fluctuate around 0.3214

Continued.
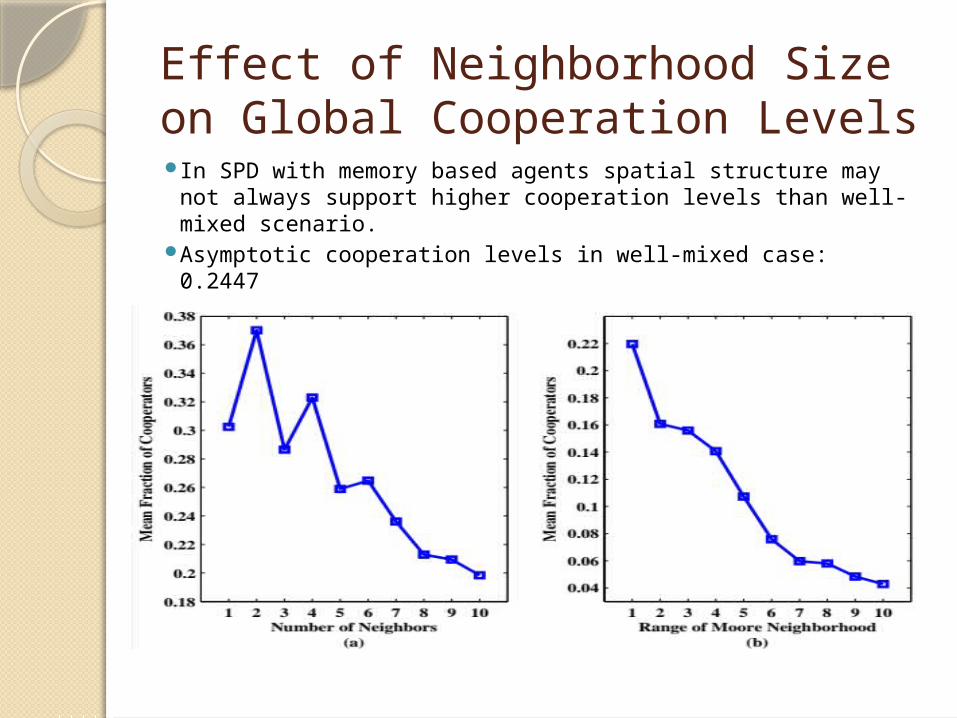
Effect of Neighborhood Size on Global Cooperation Levels In SPD with memory based agents spatial structure may not
always support higher cooperation levels than well-mixed scenario.
Asymptotic cooperation levels in well-mixed case: 0.2447

Different Activation Regimes and Size of the LatticeAsynchronous updating (Axtell,
2001)◦Asymptotic cooperation levels for
Uniform Activation with V-N neighbors: 0.3238
◦ Asymptotic cooperation levels for Random Activation with V-N neighbors: 0.3220
Size of the lattice◦Global cooperation level is almost
invariant with size of the lattice. Axtell, R. (2001). Effects of interaction topology and activation regime in several multi-agent systems. Multi-Agent-Based Simulation, pages 33–48.

Conclusion and Further Research Partial cooperation levels are sustained in a SPD with
memory based agents. Spatial structure may not always support higher
cooperation levels than well-mixed case as in the evolutionary framework.
Decision making mechanism that is grounded in a cognitive architecture may present a convincing middle-way between the strict rationality assumptions of behavior and the overly simplistic characterization of behavior in Evolutionary game theory.
Future Directions:◦ Validation of model output using experimental results.◦ Effect of interaction topology on emergent cooperation
levels. Properties of Interaction topologies in real world lie between that of random networks and regular lattices.

Questions?

















