59
ECE 7995 CACHING AND PREFETCHING TECHNIQUES
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 3 times |

ECE 7995CACHING AND PREFETCHING TECHNIQUES

Locality In Search Engine Queries And Its Implications For Caching
By:LAKSHMI JANARDHAN – ba8671JUNAID AHMED – ax9974

Outline Introduction Related previous work Analysis of search engines and its
query traces Query locality and its implications User lexicon analysis and its
implication Results Conclusion and Scope of
improvement

Introduction Serving a search request requires a significant amount
of computation as well as I/O and network bandwidth, caching these results could improve performance in 3 ways.
Repeated query results. Because of the reduction in server workload,
scarce computing cycles in the server are saved, allowing these cycles to be applied to more advanced algorithms.
Distribute part of the computational tasks and customize search results based on user contextual information.

Questions Still Open?? Where should we cache these results? How long should we keep a query in cache
before it becomes stale? What might be the other benefits gained from
caching? Do we have to study the real time search
engines in order to understand caching search engine results?

Related work & Motivation
Due to the exponential growth of the Web, there has been much research on the impact of Web caching and how to maximize its performance benefits.
Deploying proxies between clients and servers yields a number of performance benefits. It reduces server load, network bandwidth usage as well as user access latency.

There are previous studies on search engine traces like the Excite search engine trace to determine how users search the Web and what they search for and the AltaVista search engine trace, studying the interaction of terms within queries and presenting results of a correlation analysis of the log entries.
Although these studies have not focused on caching search engine results, all of them suggest queries have significant locality, which hence motivates the authors in writing the paper.

Analysis of search engines & its query traces
Analysis of VIVISIMO & EXCITE Search Engines.
Query Trace description of both VIVISIMO & EXCITE Search Engines.
Statistical summary of the above traces.

Vivisimo search engine Vivisimo is a clustering meta-search engine
that organizes the combined outputs of multiple search engines.
Upon reception of each user query, Vivisimo combines the results from other search engines and organizes these documents into meaningful groups.
The groupings are generated dynamically based on extracts from the documents, such as titles, URLs, and short descriptions.

Excite search engine Excite is a basic search engine that
automatically produces search results by listing relevant web sites and information upon reception of each user query.
Capitalization of the query is disregarded. The default logic operation to be performed is
’ALL'. It also supports other logic operations like ’AND’, ’OR’, ’AND NOT’.
More advanced searching features of Excite include wild card matching, ’PHRASE’ searching and relevance feedbacks.

Query traces of vivisimo & excite search engines Vivisimo trace captures the behavior of early
adopters who may not be representative of a steady state user group.
Both Vivisimo & Excite traces were collected at different times
Even though they were captured at different time periods and user populations, their results seems to be the same.

In both traces, there are entries which contain the following fields of interest:-
An Anonymous ID – Identifying the user IP address.
A Timestamp – Specifying when the user request is received.
A Query String – Submitted by the user. Any advanced query operations are selected, they will also be specified in this string.
A Number – Indicating whether the request is for next page results or a new user query.

Statistical summaries Users do not issue many next-page requests.
Fewer than two pages on average are examined for each query.
Users do repeat queries a lot. In the Vivisimo trace, over 32% of the queries are
repeated ones that have been submitted before by either the same user or a different user.
In the Excite trace, more than 42%of the queries are repeated queries.

The majority of users do not use advanced query options
97% of the queries from the Vivisimo trace and 3% of the queries from the Excite trace use the default logic operations offered by the corresponding search engines.
Users on average do not submit many queries. The average numbers of queries submitted by a user are 5.48 and 3.69, respectively.
About 70%of the queries consist of more than one word, although the average query length is fewer than three terms, which is short.
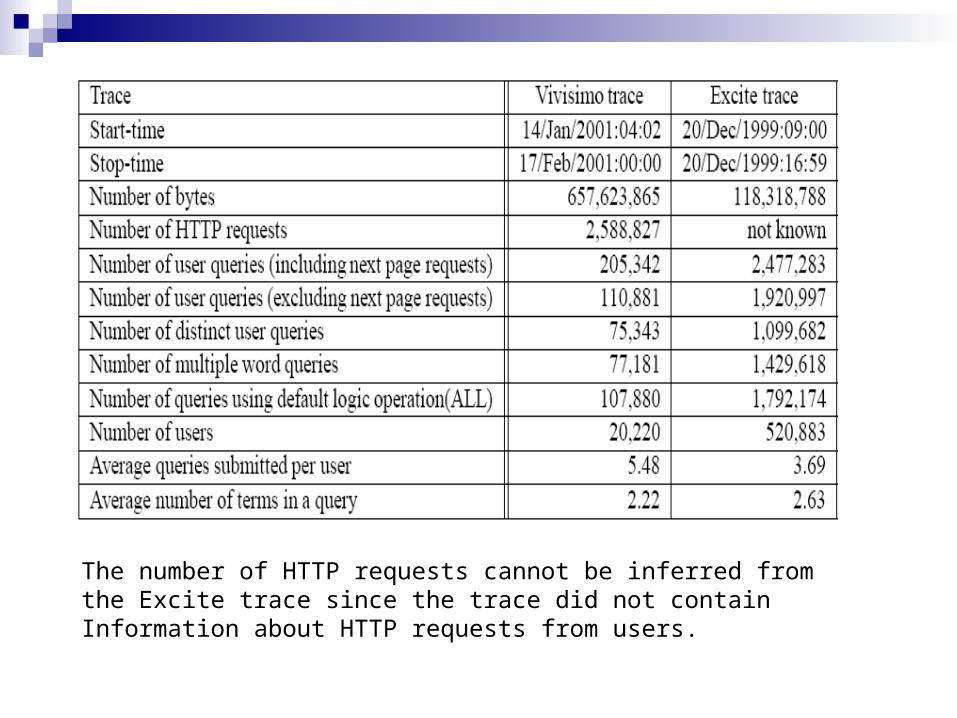
The number of HTTP requests cannot be inferred from the Excite trace since the trace did not contain Information about HTTP requests from users.
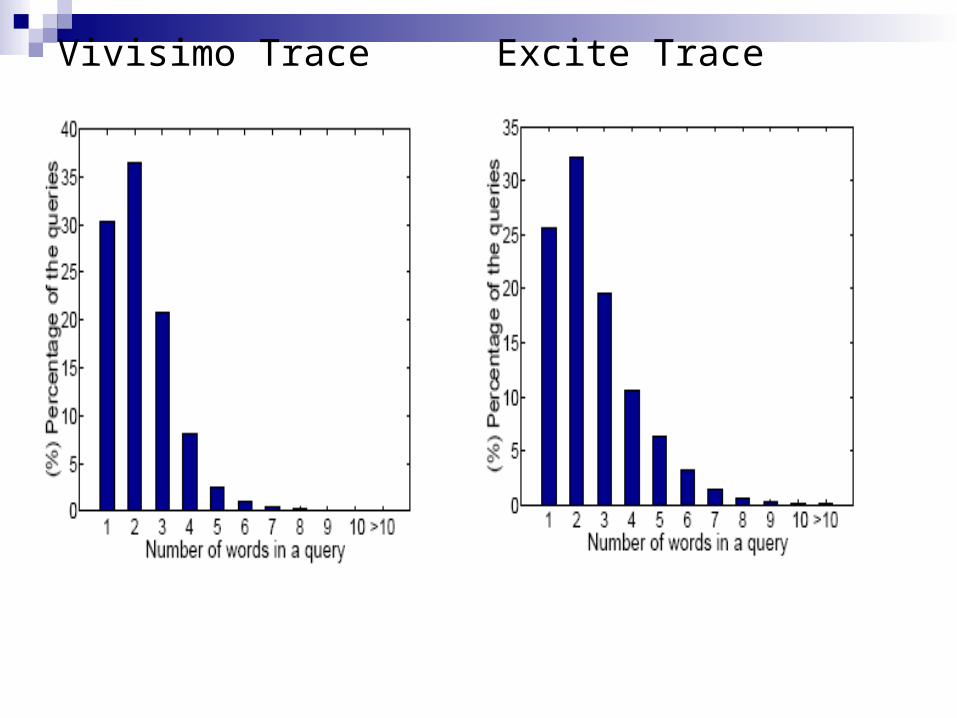
Vivisimo Trace Excite Trace

Query locality & its Implications
Query Repetition and Distribution
Query Locality based on Individual User
Temporal Query Locality
Multiple Word Query Locality
Users with shared IP Address
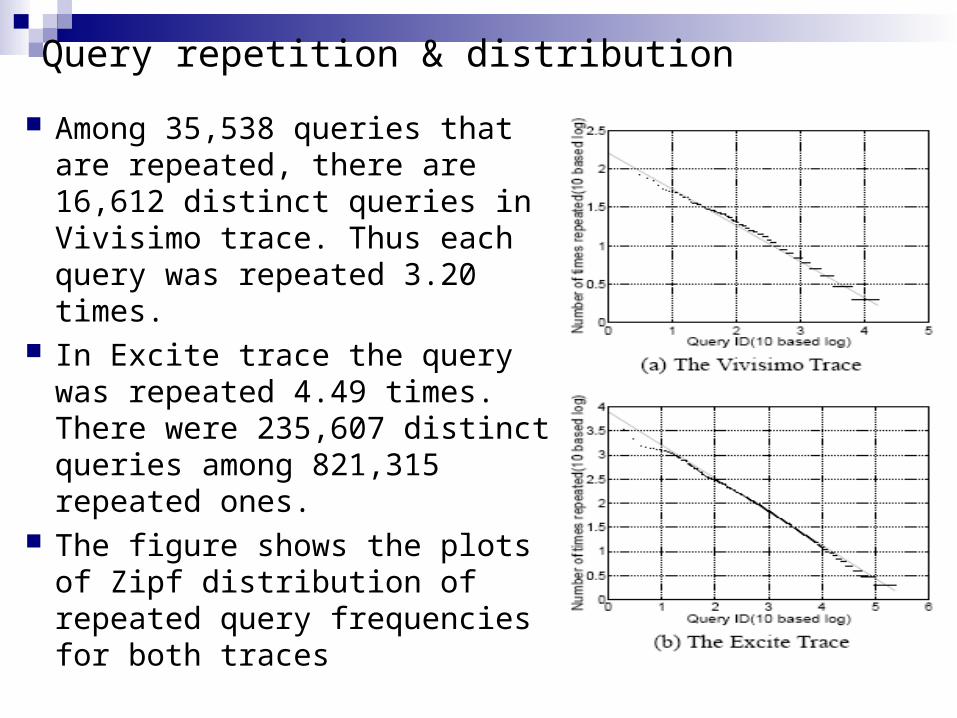
Query repetition & distribution
Among 35,538 queries that are repeated, there are 16,612 distinct queries in Vivisimo trace. Thus each query was repeated 3.20 times.
In Excite trace the query was repeated 4.49 times. There were 235,607 distinct queries among 821,315 repeated ones.
The figure shows the plots of Zipf distribution of repeated query frequencies for both traces

Query repetition & distribution (contd..)
We are interested only in repeated queries whether they are from same users or shared by different users
Out of 32.05% of repeated queries, only 70.58% are from same users in Vivisimo trace.
Out of 42.75% of repeated queries, only 37.35% are repeated from same users in Excite trace.
Thus, these results suggest that queries having high degree of shareness should be cached at the server side
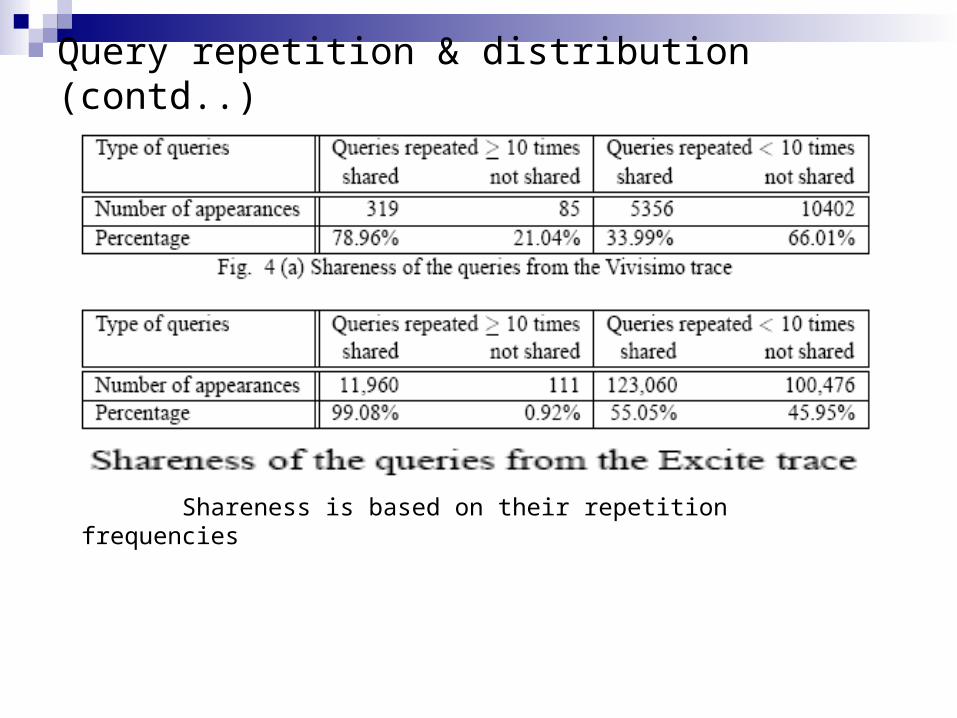
Query repetition & distribution (contd..)
Shareness is based on their repetition frequencies

Query locality based on individual user
The query shareness distribution indicates that query locality exists with respect to the same users as well as among different users.
In Vivisimo trace, out of 20,220 users, 6,628 queries are repeated at least once. Each user on avg repeated 5.36 queries.
In Excite trace, out of 520,883 users who submitted queries, 136,626 repeated queries. Each user on avg repeated 6.01 queries.
Figure shows the percentage of the repeated queries over the total number of queries submitted by each user.

Query locality based on individual user (contd..) Thus from these results, we can see that not only lot
of users repeated queries but each user repeated queries a lot.
Since16% to 22% of all queries were repeated by the same users and that search engine servers can cache only limited data, caching these queries and query results based on individual user requirements in a more distributed way is important.
It reduces user query submission overheads and access latencies as well as server load.
By caching queries at the user side, we also have the opportunity to improve query results based on individual user context, which cannot be achieved by caching queries at a centralized server.

Temporal query locality Tendency of users to repeat queries within a
short time interval In Vivisimo about 65% of the queries were
repeated within an hour, and 83% in Excite. 45.5% of the queries were repeated by the
same users within 5 minutes. Out of 21.98% of the queries that were
repeated over a day, only 5.09 came from same users.

Temporal query locality (contd..)
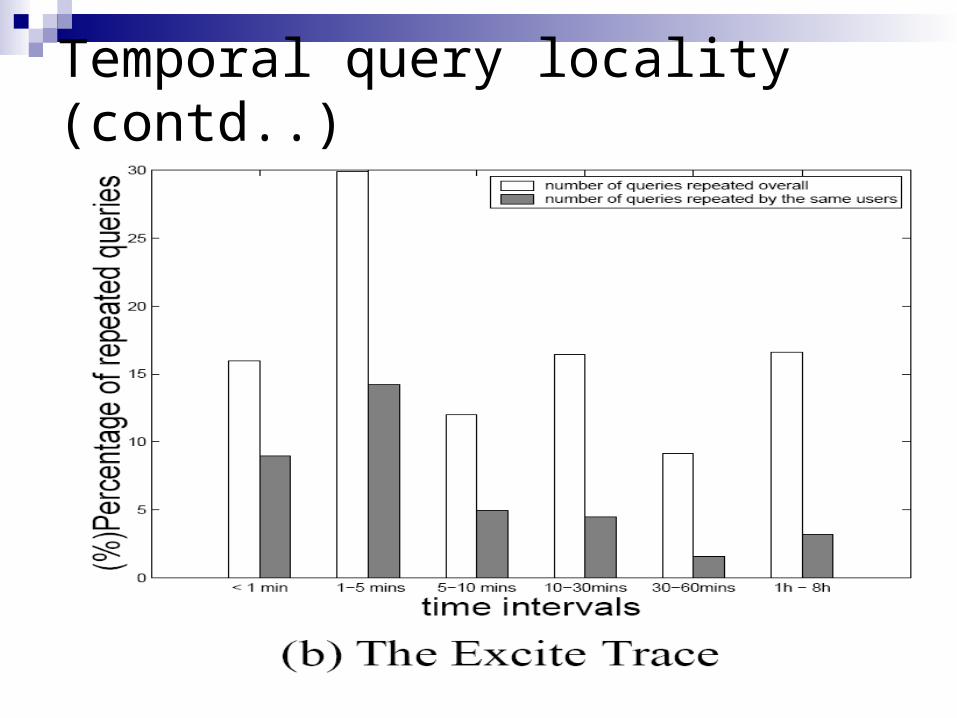
Temporal query locality (contd..)

Multi word query locality This comes into picture if a user uses more
than one word for his/her query Multiword locality has less degree of
shareness. Caching multiword queries are more
promising because it takes more time for computing.
Since they have less degree of shareness, they are mostly cached at the user side.

Multi word query locality (contd..)
Multiple word query summary and comparison between single and multi word queries.

Users with shared ip addresses For those users, their IP addresses are
dynamically allocated by DHCP servers. Unfortunately, there is no common way to identify these kinds of users. This impacts our analysis in two ways.
First, because different users can share the same IP address at different times, their queries seem like they come from the same user, leading to an overestimate of the query locality from the same users.
Second, because the same users can use different IP addresses at different times, it is also possible for us to underestimate the query locality from the same users.

User Lexicon Analysis and Implication
User Lexicon: lexicon is a synonym for dictionary. It is user vocabulary.
By analyzing the user query lexicons, it is possible to pre-fetch query results for each user based on frequently used terms

User Lexicon Analysis and Implication
All the words used by each user individually were grouped and the user lexicon size distribution was observed
Vivisimo Trace:
249,541 words in queries 51,895 are distinct words (20.8%)
Excite Trace:
5,095,189 words in queries 350,879 distinct words (6.9%)

User Lexicon Analysis and Implication
User lexicon sizes are much smaller than overall lexicon size
Largest user lexicons in Vivisimo trace have only 885 words and 202 words for Excite trace
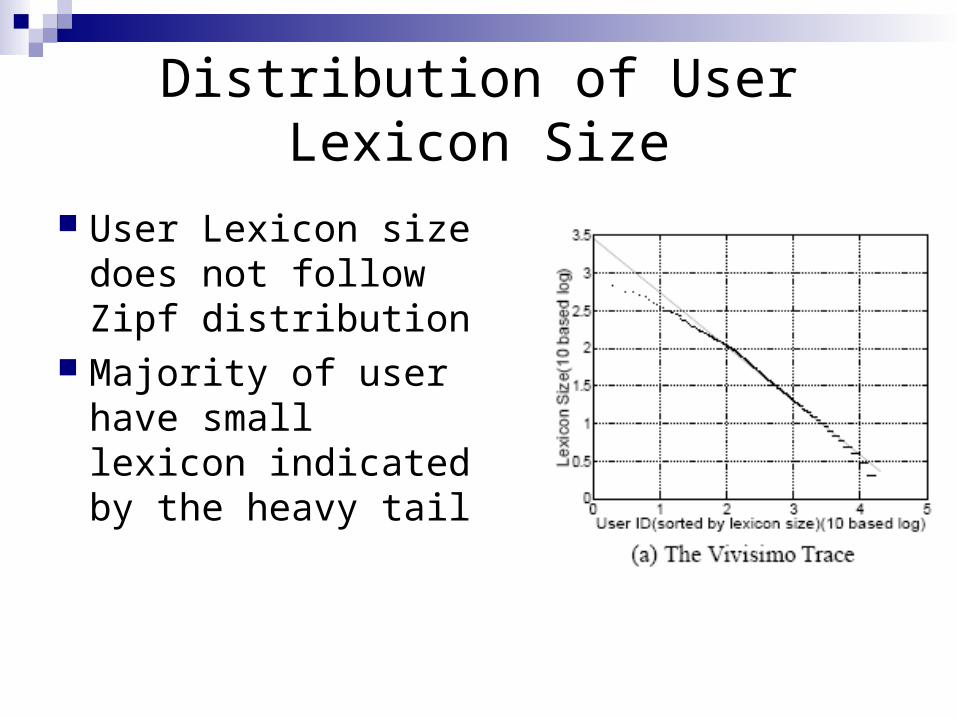
Distribution of User Lexicon Size
User Lexicon size does not follow Zipf distribution
Majority of user have small lexicon indicated by the heavy tail
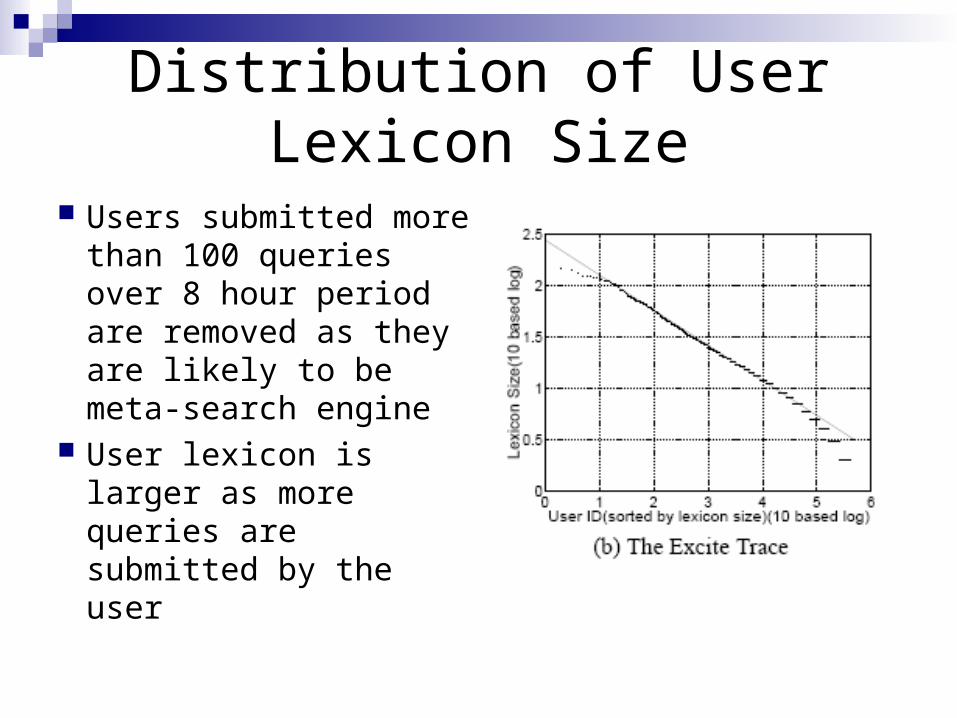
Distribution of User Lexicon Size
Users submitted more than 100 queries over 8 hour period are removed as they are likely to be meta-search engine
User lexicon is larger as more queries are submitted by the user
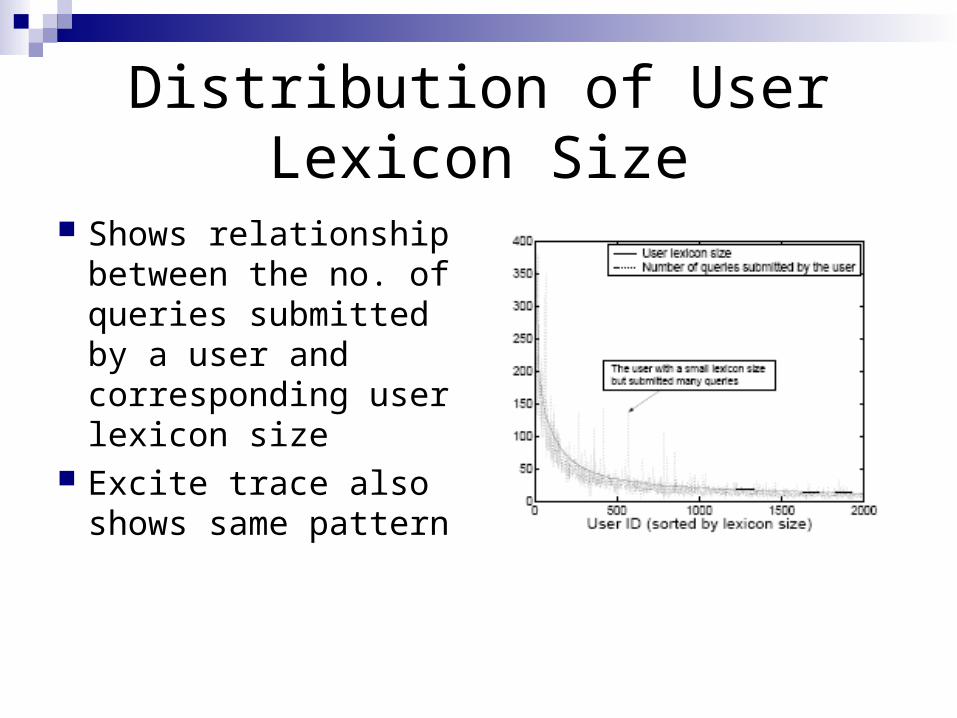
Distribution of User Lexicon Size
Shows relationship between the no. of queries submitted by a user and corresponding user lexicon size
Excite trace also shows same pattern

Analysis of Frequent Users and Their Lexicons
Users have large lexicons but they do not use all words uniformly
We are interested in how frequently words are used by frequent users in the queries
Users submitted only few queries over long period (35 days) or whose trace lasts for too short a period are ignored.

Analysis of Frequent Users and Their Lexicons
Fre-user: if user has submitted at least 70 queries over 35 days.
Fre-lexicon: Consist of words that were used at least 5 times by the corresponding users
Number of fre-users 157
Number of queries submitted by fre-users
25,722
Number of fre-users with fre-lexicon size >= 1
153
Number of fre-users with fre-lexicon size <= 20
128

Analysis of Frequent Users and Their Lexicons
Most of the fre-users had small fre-lexicons
A small no. of users with relatively large fre-lexicons

Analysis of Frequent Users and Their Lexicons
Prefetching based on fre-lexicons for these users will reduce no. of queries
But would required large cache size to store all possible word combination
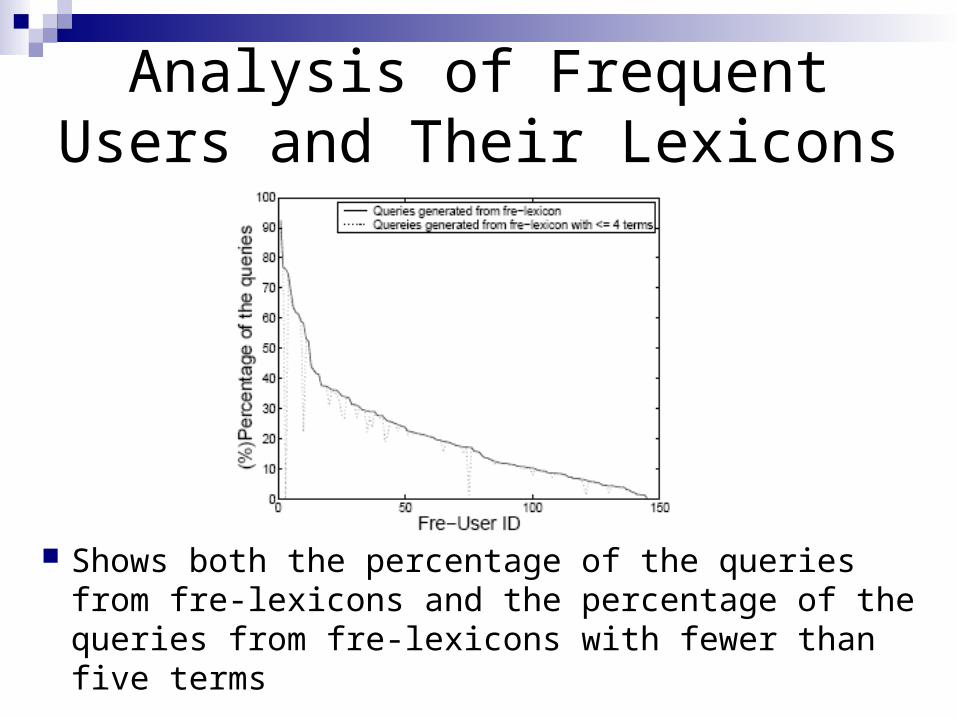
Analysis of Frequent Users and Their Lexicons
Shows both the percentage of the queries from fre-lexicons and the percentage of the queries from fre-lexicons with fewer than five terms
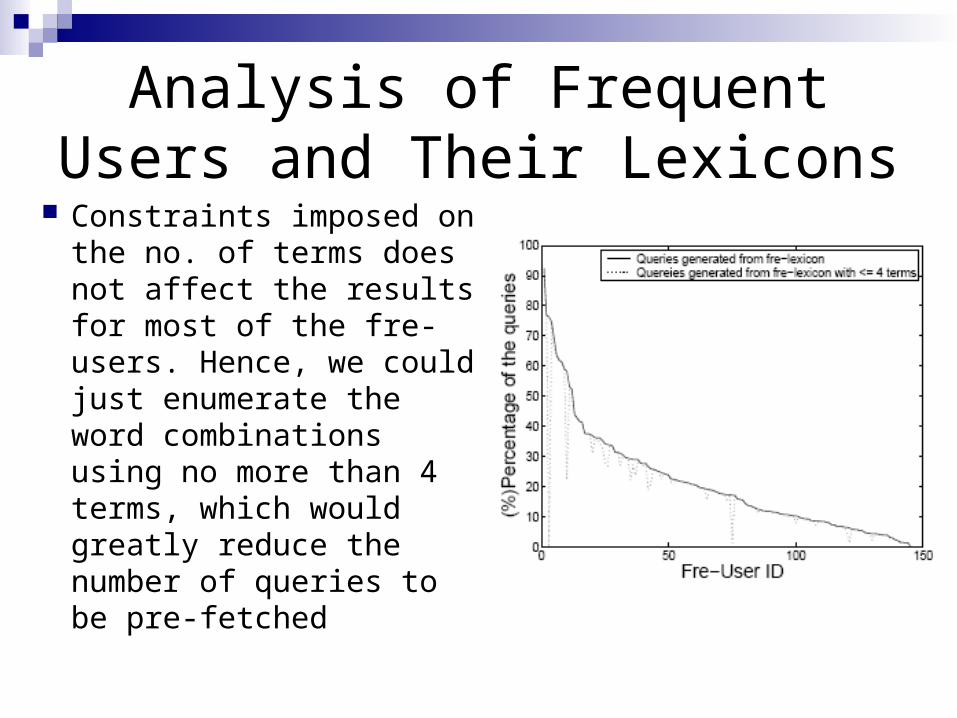
Analysis of Frequent Users and Their Lexicons
Constraints imposed on the no. of terms does not affect the results for most of the fre-users. Hence, we could just enumerate the word combinations using no more than 4 terms, which would greatly reduce the number of queries to be pre-fetched

Research Implications
Review the statistical results derived from both traces and discuss their implications
Focus on 3 aspects:
1. Caching search engine results
2. Prefetching search engine results
3. Improving query result rankings

Caching search engine results
Query results can be cached on the servers, the proxies, and the clients. For optimal performance, we should make decisions based on the following aspects:
1. Scalability 2. Performance improvement 3. Hit rate and shareness 4. Overhead. 5. Opportunity for other benefits
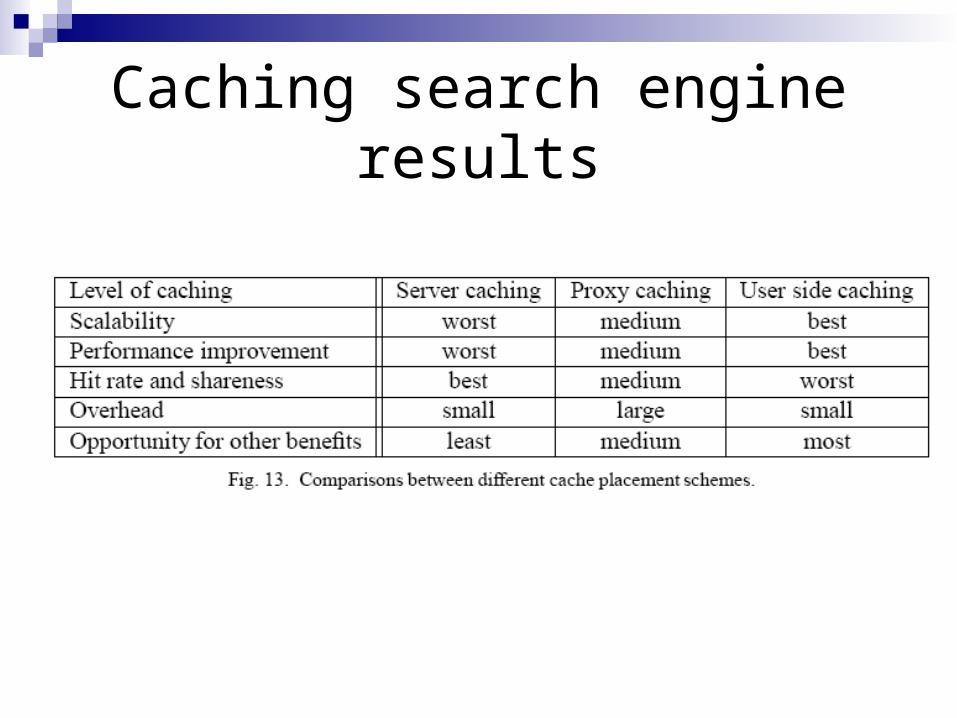
Caching search engine results

Caching search engine results
Server Caching: Server has limited resources so it doesn’t scale
well with increasing size of Internet We can’t reduce no. of request received by the
server Server Caching has small overhead It allows max query shareness and hit rate would
be high by caching popular queries

Caching search engine results
Proxy Caching: It is effective to reduce both server workload and
network traffic. In the case of caching query results, this assumes
that the users nearby a proxy would share queries.
However, one of the main disadvantages of proxy caching is the significant overhead of placing dedicated proxies among the Internet.

Caching search engine results
User Side Caching: User side caching achieves the best scalability. Because the overhead of caching can be
amortized to a large number of users, the overhead at each user side is small.
User side caching make possible to prefetch or improve query results based on individual user requirements.
No shareness can be exploited with user side caching.

Caching search engine results
Degree of shareness tells where should query results be cached
Two extreme case:
1. User never repeat query gives max degree of shareness. In this case cache query at servers/proxies
2. User never share queries results caching query at user side

Caching search engine results
32% to 42% are repeated queries 16% to 22% are repeated queries by same user Queries repeated by same user can be cached at
user side Rest of repeated queries can be cached at
server/proxy side Multiple-word queries should be cached at user
side

Caching search engine results
How long cache query result? Temporal query locality indicates that most of the
queries are repeated within short time intervals User side caching query results should be cached
for hours. This also helps to remove or update stale query results in time
Long-term caching such as couple of days should be done at servers/proxies

Caching search engine results
Time to live (TTL) tells whether or not the query has been in the cache for too long and should be discarded. Set to relative short time interval
The If-Modified-Since request-header field is used in each user request. If the requested resource has not been modified since the time specified in this field, a copy of the resource will not be returned from the server. This guarantees query freshness but has an overhead

Caching search engine results
For server side and proxy caching, we should use different mechanisms to maintain cache consistency
With server side caching, we can easily ensure cache consistency by removing or updating stale query results whenever new query results are computed

Caching search engine results
For proxy caching, queries are shared by different users repeats over longer time intervals, TTL based approach would incur more overhead. TTL is usually set to a relatively short interval to prevent caches from serving stale data
Advanced protocols should be used to update stale query results while keeping the overhead low
Proxy polling technique can be used where proxies periodically check back with server to determine if cached objects are still valid

Prefetching Search Engine Results
Lexicon Analysis suggest that pre-fetching query result based on user fre-lexicon is promising
Prefetching has always been an important method to reduce user access latency

Prefetching Search Engine Results
User lexicon analysis shows that majority of user have small lexicon sizes
Prefetching can be done by enumerating all the word combinations from fre-lexicons and prefetch the corresponding query results into a user level cache
Analysis shows that same performance improvement can be achieved by skipping queries longer than 4 words

Prefetching Search Engine Results
When user interests stay relatively stable, the majority of the words from a fre-lexicon will remain the same. Hence fewer new query results to fetch during prefetching. Thus overhead at the user side is small.
With user interests changing gradually, the fre-lexicons should also be updated to match user interests. New queries will be formed and results will need to be prefetched to achieve the best cache hit rates

Prefetching Search Engine Results
Same algorithm can be used at server side. Redundant query can be sent to the server
If prefetching algorithm is performed regularly when user machines are idle and servers are not busy, most of these requests will be processed at non-peak times by servers
Hence, server peak time workload can even be reduced since many of the queries have already been satisfied by user prefetching

Prefetching Search Engine Results
Prefetching can also be performed at proxies. In such cases, server’s global knowledge about user query patterns can be utilized to decide what and when to prefetch
Since proxies allow query shareness among different users, exploring how to achieve the maximum hit rate is left as future work

Improving Query Result Rankings
Search engines return thousand of results but actually few are used by users i.e less than 2 pages of result
Improving query result rankings based on individual user requirements is more important than ever
With user side/proxy caching, it is now possible to re-rank the returned search engine results based on the unique interest of individual user
For example, a naive algorithm would be to increase the ranks of the Web pages visited by the user among the next query results

Conclusion
In Conclusion, we answer the questions again hat we had in the beginning
Where should we cache search engine results? How long should we cache search results? What are the other benefits of caching search
engine results?

















![Ichong vs. Hernandez [101 Phil 1155; L-7995; 31 May 1957]](https://static.documents.pub/doc/80x56/577c77e61a28abe0548def3f/ichong-vs-hernandez-101-phil-1155-l-7995-31-may-1957.jpg)