38
EEM 486 EEM 486: Computer Architecture Lecture 6 Memory Systems and Caches
| Date post: | 22-Dec-2015 |
| Category: |
Documents |
| View: | 233 times |
| Download: | 2 times |

EEM 486
EEM 486: Computer Architecture
Lecture 6
Memory Systems and Caches

Lec 6.2
The Five Classic Components of a Computer
The Big Picture: Where are We Now?
Control
Datapath
Memory
Processor
Input
Output
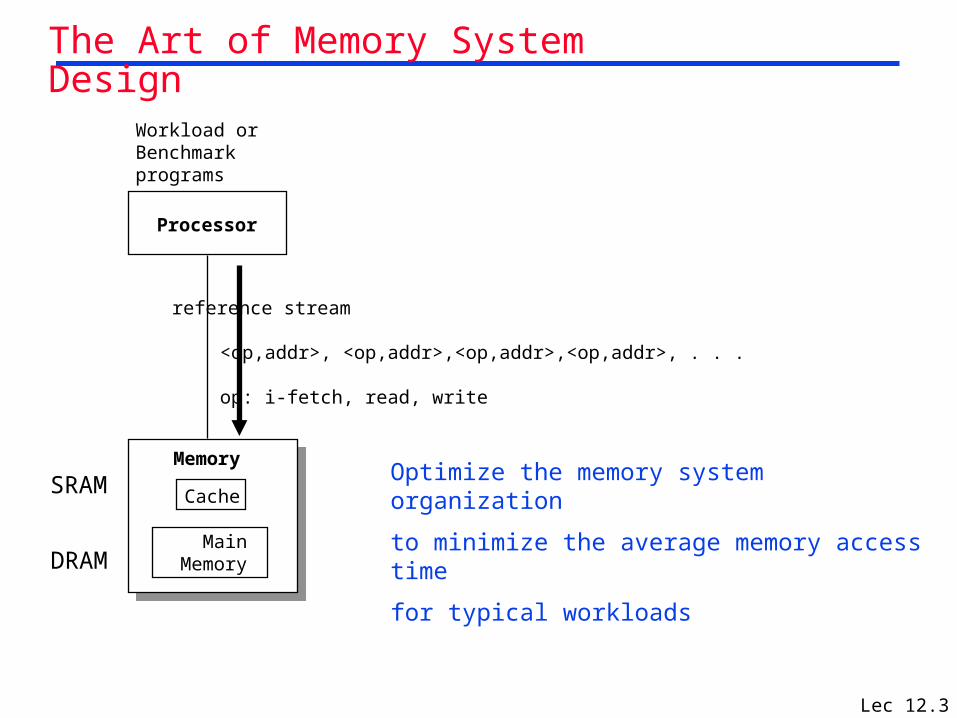
Lec 12.3
Processor
Cache
MainMemory
Memory
reference stream
<op,addr>, <op,addr>,<op,addr>,<op,addr>, . . .
op: i-fetch, read, write
Optimize the memory system organization
to minimize the average memory access time
for typical workloads
Workload orBenchmarkprograms
The Art of Memory System Design
SRAM
DRAM

Lec 6.4
Technology Trends
DRAM
Year Size Cycle Time
1980 64 Kb 250 ns
1983 256 Kb 220 ns
1986 1 Mb 190 ns
1989 4 Mb 165 ns
1992 16 Mb 145 ns
1995 64 Mb 120 ns
1000:1! 2:1!
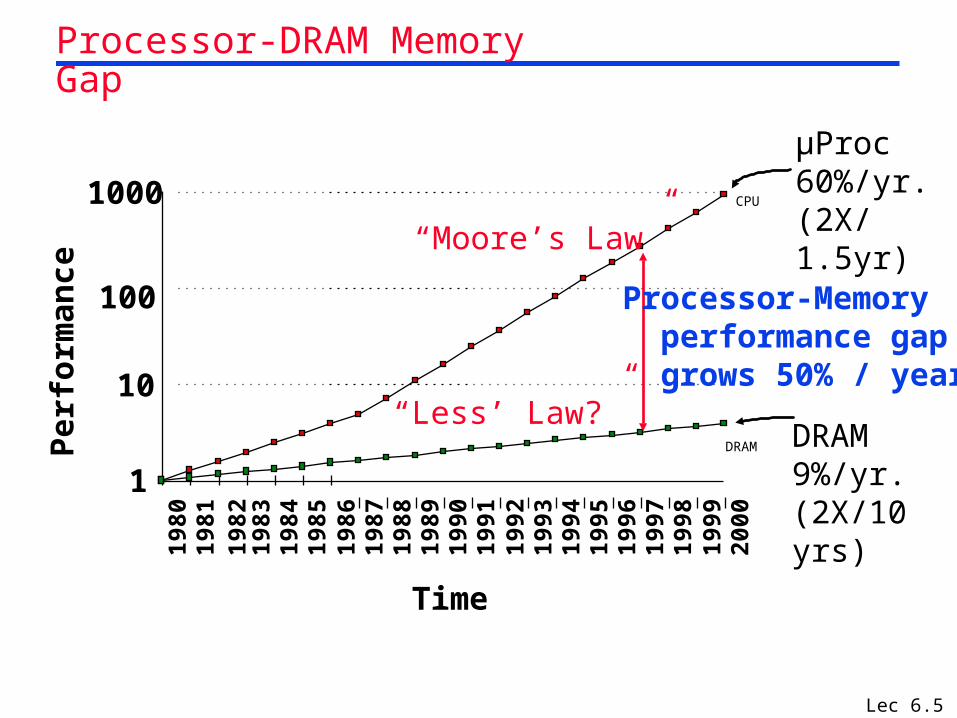
Lec 6.5
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)
1
10
100
1000198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU
198
2
Processor-Memory performance gap grows 50% / year
Per
form
ance
Time
“Moore’s Law”
“Less’ Law?”
Processor-DRAM Memory Gap

Lec 6.6
The Goal: illusion of large, fast, cheap memory
Facts
• Large memories are slow but cheap (DRAM)
• Fast memories are small yet expensive (SRAM)
How do we create a memory that is large, fast and cheap?
• Memory hierarchy
• Parallelism

Lec 6.7
The Principle of Locality
The principle of locality: Programs access a relatively small
portion of their address space at any instant of time
Temporal Locality (Locality in Time)
=> If an item is referenced, it will tend to be referenced again soon
=> Keep most recently accessed data items closer to the processor
Spatial Locality (Locality in Space)
=> If an item is referenced, nearby items will tend to be referenced soon
=> Move blocks of contiguous words to the upper levels
Q: Why does code have locality?
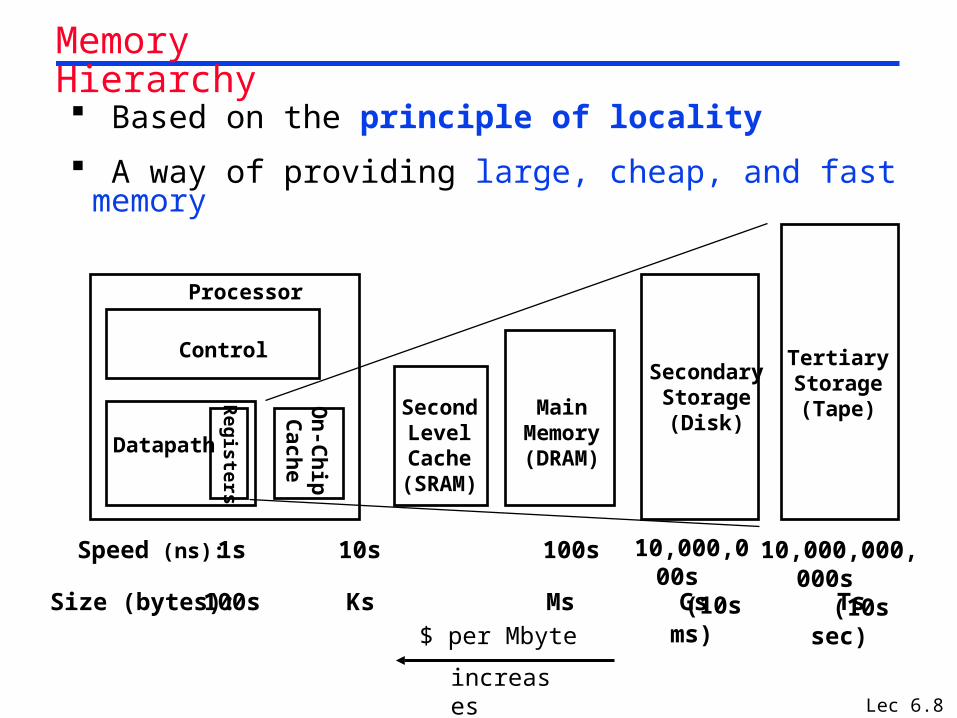
Lec 6.8
Memory Hierarchy Based on the principle of locality
A way of providing large, cheap, and fast memory
Control
Datapath
SecondaryStorage(Disk)
Processor
Registers
MainMemory(DRAM)
SecondLevelCache
(SRAM)
On
-Ch
ipC
ache
1s 10,000,000s
(10s ms)
Speed (ns): 10s 100s
100s GsSize (bytes): Ks Ms
TertiaryStorage(Tape)
10,000,000,000s (10s sec)
Ts
$ per Mbyte
increases

Lec 6.9
Cache Memory
CacheCPU Memoryword block
Tag Block
Block length (K words)
0
1
2
C-1
Block
Block
Word
012
2^n-1
CACHE MEMORY

Lec 6.10
Elements of Cache Design Cache size
Mapping function• Direct
• Set Associative
• Fully Associative
Replacement algorithm• Least recently used (LRU)
• First in first out (FIFO)
• Random
Write policy• Write through
• Write back
Line size
Number of caches• Single or two level
• Unified or split

Lec 6.11
Terminology Hit: data appears in some block in the upper level
• Hit Rate: the fraction of memory accesses found in the upper level
• Hit Time: time to access the upper level which consists of
RAM access time + Time to determine hit/miss
X2
X3
Xn-1
Xn-2
X1
X4Cache
Processor
X1
(2)(1) Xn
Memory
Upper level
Lower level
Read hit

Lec 6.12
Terminology Miss: data needs to be retrieved from a block
in the lower level
• Miss Rate = 1 - (Hit Rate)
• Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block the processor
Hit Time << Miss Penalty
X2
X3
Xn-1
Xn-2
X1
X4Cache
Processor
Xn
(4)(1) Xn
Memory
Upper level
Lower level
Read miss
Xn
(3)(2)

Lec 6.13
Direct Mapped Cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
01
001
11
001
011
101
11
Each memory location is mapped to exactly one location
in the cache:
Cache block # = (Block address) modulo (# of cache blocks)
= Low order log2 (# of cache blocks) bits of the address
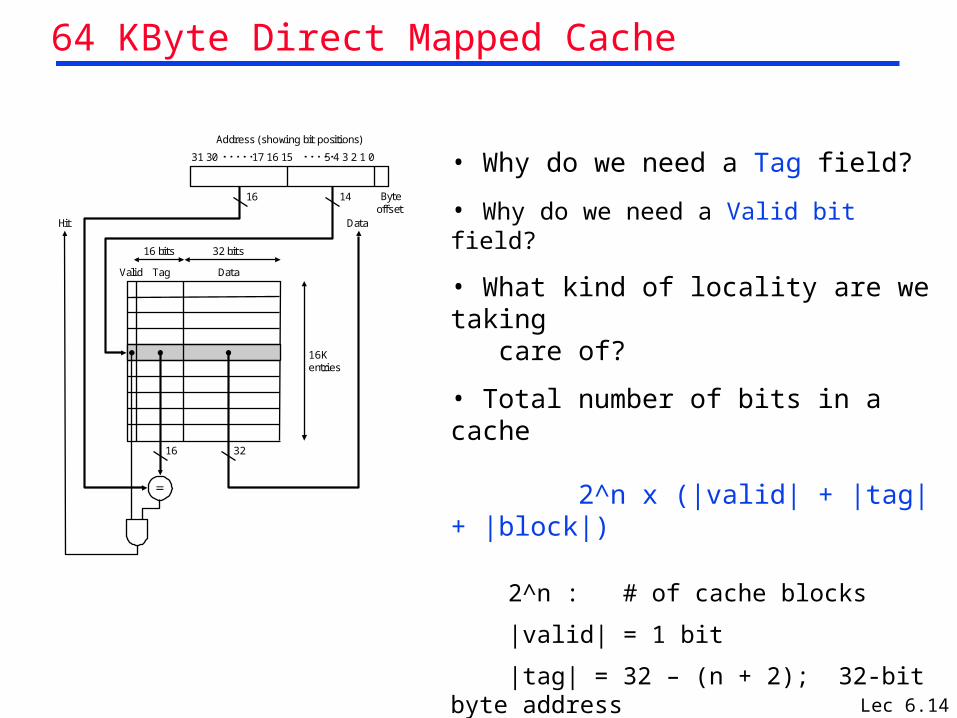
Lec 6.14
64 KByte Direct Mapped Cache
• Why do we need a Tag field?
• Why do we need a Valid bit field?
• What kind of locality are we taking care of?
• Total number of bits in a cache
2^n x (|valid| + |tag| + |block|)
2^n : # of cache blocks
|valid| = 1 bit
|tag| = 32 – (n + 2); 32-bit byte address 1 word blocks
|block| = 32 bit
Address (showing bit positions)
16 14 Byteoffset
Valid Tag Data
Hit Data
16 32
16Kentries
16 bits 32 bits
31 30 17 16 15 5 4 3 2 1 0

Lec 6.15
Address the cache by PC or ALU
If the cache signals hit, we have a read hit
• The requested word will be on the data lines
Otherwise, we have a read miss
• stall the CPU
• fetch the block from memory and write into cache
• restart the execution
Reading from Cache

Lec 6.16
Writing to Cache
Address the cache by PC or ALU
If the cache signals hit, we have a write hit
• We have two options:
- write-through: write the data into both cache and memory
- write-back: write the data only into cache and
write it into memory only when it is replaced
Otherwise, we have a write miss
• Handle write miss as if it were a write hit

Lec 6.17
Taking advantage of spatial locality
Address (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
64 KByte Direct Mapped Cache

Lec 6.18
Writing to Cache
Address the cache by PC or ALU
If the cache signals hit, we have a write hit
• Write-through cache: write the data into both cache and memory
Otherwise, we have a write miss
• stall the CPU
• fetch the block from memory and write into cache
• restart the execution and rewrite the word

Lec 6.19
Associativity in Caches
Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data
Eight-way set associative (fully associative)
Tag Data Tag Data Tag Data Tag Data
Four-way set associative
Set
0
1
Tag Data
One-way set associative(direct mapped)
Block
0
7
1
2
3
4
5
6
Tag Data
Two-way set associative
Set
0
1
2
3
Tag Data
Compute the set number:
(Block number) modulo (Number of sets)
Choose one of the blocks in the computed set

Lec 6.20
Set Asscociative Cache
Address
22 8
V TagIndex012
253254255
Data V Tag Data V Tag Data V Tag Data
3222
4-to-1 multiplexor
Hit Data
123891011123031 0
N-way set associative• N direct mapped caches operates in parallel
• N entries for each cache index
• N comparators and a N-to-1 mux
• Data comes AFTER Hit/Miss decision and set selection
A four-way set associative cache

Lec 6.21
Fully Associative Cache
A block can be anywhere in the cache => No Cache Index
Compare the Cache Tags of all cache entries in parallel
Practical for small number of cache blocks
:
Cache Data
Byte 0
0431
:
Cache Tag (27 bits long)
Valid Bit
:
Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :
Cache Tag
Byte Select
Ex: 0x01
=
=
=
=
=

Lec 6.22
Q1: Block placement?
Where can a block be placed in the upper level?
Q2: Block identification?
How is a block found if it is in the upper level?
Q3: Block replacement?
Which block should be replaced on a miss?
Q4: Write strategy?
What happens on a write?
Four Questions for Caches
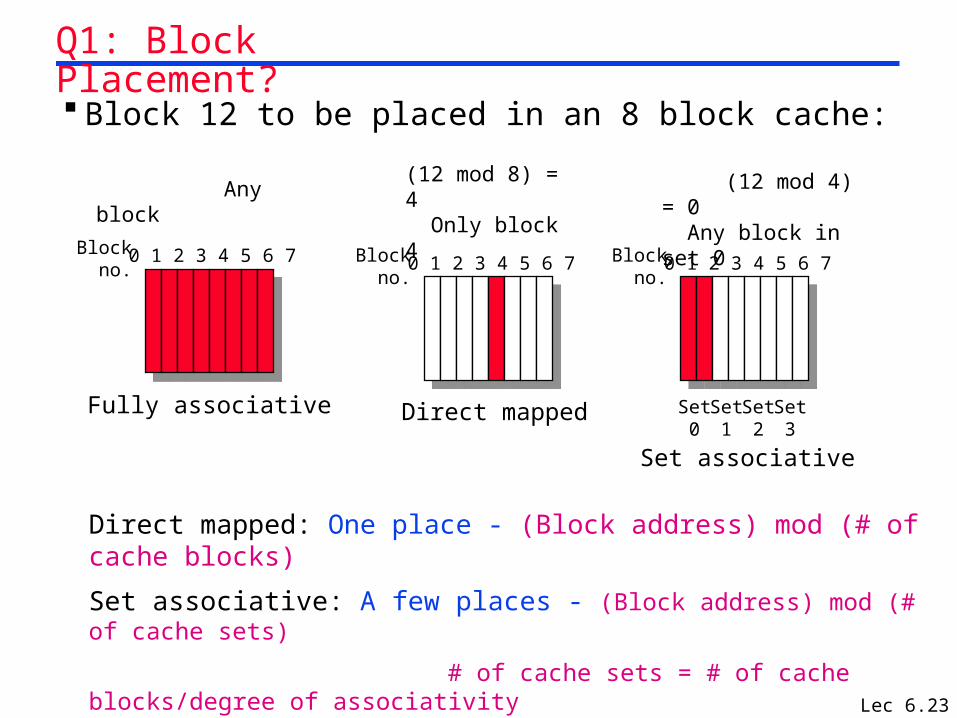
Lec 6.23
Block 12 to be placed in an 8 block cache:
Q1: Block Placement?
Any block(12 mod 8) = 4 Only block 4
0 1 2 3 4 5 6 7Blockno.
Fully associative
0 1 2 3 4 5 6 7Blockno.
Direct mapped
0 1 2 3 4 5 6 7Blockno.
Set0
Set1
Set2
Set3
Set associative
(12 mod 4) = 0 Any block in set 0
Direct mapped: One place - (Block address) mod (# of cache blocks)
Set associative: A few places - (Block address) mod (# of cache sets)
# of cache sets = # of cache blocks/degree of associativity
Fully associative: Any place

Lec 6.24
Q2: Block Identification?
Blockoffset
Block AddressTag Index
Set Select
Data Select
Direct mapped: Indexing – index, 1 comparison
N-way set associative: Limited search – index the set, N comparison
Fully associative: Full search – search all cache entries

Lec 6.25
Easy for Direct Mapped
Set Associative or Fully Associative:• Random: Randomly select one of the blocks in the set
• LRU (Least Recently Used): Select the block in the set which has been
unused for the longest time
Associativity: 2-way 4-way 8-way
Size LRU Random LRU Random LRU Random
16 KB 5.2% 5.7% 4.7% 5.3% 4.4% 5.0%
64 KB 1.9% 2.0% 1.5% 1.7% 1.4% 1.5%
256 KB 1.15% 1.17% 1.13% 1.13% 1.12% 1.12%
Q3: Replacement Policy on a Miss?

Lec 6.26
Write through— The information is written to both the block in the cache and to the block in the lower-level memory
Write back— The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced
• is block clean or dirty?
Pros and Cons of each?• WT: read misses cannot result in writes
• WB: no writes of repeated writes
WT always combined with write buffers to avoid
waiting for lower level memory
Q4: Write Policy?

Lec 6.27
Cache PerformanceCPU time = (CPU execution clock cycles +
Memory stall clock cycles) x Cycle time
Note: memory hit time is included in execution cycles
Stalls due to cache misses:
Memory stall clock cycles = Read-stall clock cycles +
Write-stall clock cycles
Read-stall clock cycles= Reads x Read miss rate x Read miss penalty
Write-stall clock cycles= Writes x Write miss rate x Write miss penalty
If read miss penalty = write miss penalty,
Memory stall clock cycles = Memory accesses x Miss rate x Miss penalty

Lec 6.28
Cache PerformanceCPU time = Instruction count x CPI x Cycle time
= Inst count x Cycle time x
(ideal CPI + Memory stalls/Inst + Other stalls/Inst)
Memory Stalls/Inst =
Instruction Miss Rate x Instruction Miss Penalty +
Loads/Inst x Load Miss Rate x Load Miss Penalty +
Stores/Inst x Store Miss Rate x Store Miss Penalty
Average Memory Access time (AMAT) =
Hit Time + (Miss Rate x Miss Penalty) =
(Hit Rate x Hit Time) + (Miss Rate x Miss Time)

Lec 6.29
Example Suppose a processor executes at
• Clock Rate = 200 MHz (5 ns per cycle)• Base CPI = 1.1 • 50% arith/logic, 30% ld/st, 20% control
Suppose that 10% of memory operations get 50 cycle miss penalty
Suppose that 1% of instructions get same miss penalty
CPI = Base CPI + average stalls per instruction = 1.1(cycles/ins) +
[ 0.30 (Data Mops/ins) x 0.10 (miss/Data Mop) x 50 (cycle/miss)] +
[ 1 (Inst Mop/ins) x 0.01 (miss/Inst Mop) x 50 (cycle/miss)]
= (1.1 + 1.5 + .5) cycle/ins = 3.1
AMAT= (1/1.3)x[1+0.01x50]+ (0.3/1.3)x[1+0.1x50]= 2.54

Lec 6.30
Options to reduce AMAT:
1. Reduce the miss rate,
2. Reduce the miss penalty, or
3. Reduce the time to hit in the cache
CPU Time = IC x CT x (ideal CPI + memory stalls)
Average Memory Access time = Hit Time + (Miss Rate x Miss Penalty)
= (Hit Rate x Hit Time) + (Miss Rate x Miss Time)
Improving Cache Performance

Lec 6.31
Block Size (bytes)
Miss Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
Reduce Misses: Larger Block Size
Increasing block size also increases miss penalty !

Lec 6.32
Reduce Misses: Higher Associativity
0%
3%
6%
9%
12%
15%
Eight-wayFour-wayTwo-wayOne-way
1 KB
2 KB
4 KB
8 KB
Mis
s ra
te
Associativity 16 KB
32 KB
64 KB
128 KB
Increasing associativity also increases both time and hardware cost !

Lec 6.33
L2 Equations
AMAT = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
AMAT = Hit TimeL1 +
Miss RateL1 x (Hit TimeL2 + Miss RateL2 x Miss PenaltyL2)
Reducing Penalty: Second-Level Cache
Proc
L1 Cache
L2 Cache

Lec 6.34
Simple: • CPU, Cache, Bus,
Memory same width (32 bits)
Interleaved: • CPU, Cache, Bus- 1 word
• N Memory Modules
Wide: • CPU/Mux 1 word;
Mux/Cache, Bus, Memory N words
Designing the Memory System to Support Caches

Lec 6.35
DRAM (Read/Write) Cycle Time >>
DRAM (Read/Write) Access Time
DRAM (Read/Write) Cycle Time :• How frequent can you initiate an access?
DRAM (Read/Write) Access Time:• How quickly will you get what you want once you initiate an
access?
DRAM Bandwidth Limitation
TimeAccess Time
Cycle Time
Main Memory Performance
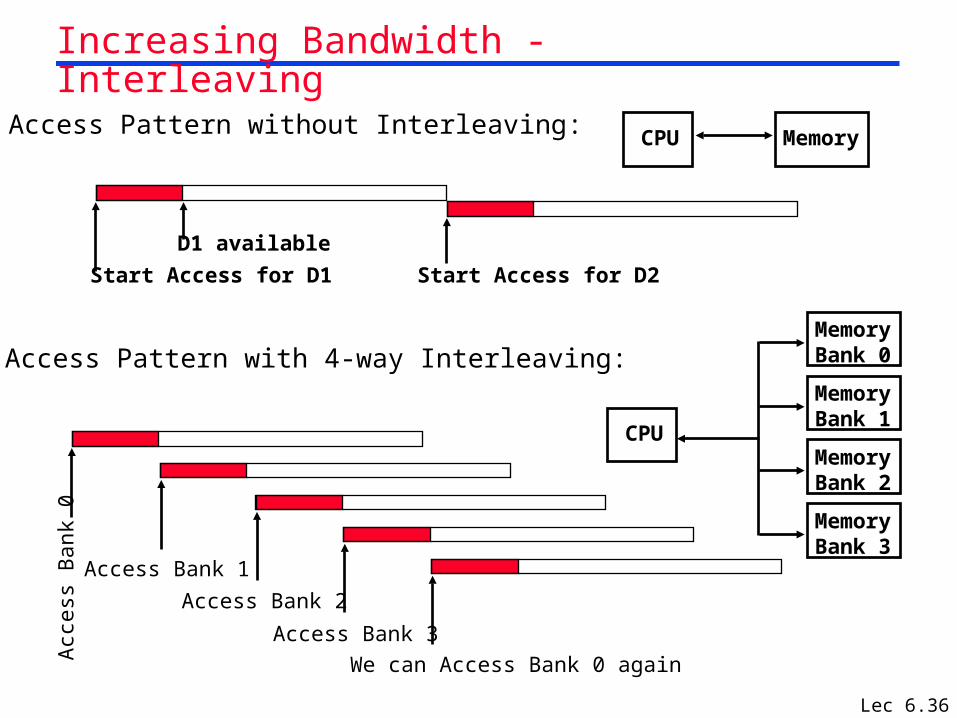
Lec 6.36
Access Pattern without Interleaving: CPU Memory
Start Access for D1 Start Access for D2
D1 available
Access Pattern with 4-way Interleaving:
Acc
ess
Bank
0
Access Bank 1
Access Bank 2
Access Bank 3
We can Access Bank 0 again
CPU
MemoryBank 1
MemoryBank 0
MemoryBank 3
MemoryBank 2
Increasing Bandwidth - Interleaving

Lec 6.37
Summary #1/2 The Principle of Locality:
• Program likely to access a relatively small portion of the address space at any instant of time.
- Temporal Locality: Locality in Time
- Spatial Locality: Locality in Space
Three (+1) Major Categories of Cache Misses:• Compulsory Misses: sad facts of life. Example: cold start misses.
• Conflict Misses: increase cache size and/or associativity.Nightmare Scenario: ping pong effect!
• Capacity Misses: increase cache size
Cache Design Space• total size, block size, associativity
• replacement policy
• write-hit policy (write-through, write-back)
• write-miss policy

Lec 6.38
Summary #2/2: The Cache Design Space Several interacting dimensions
• cache size
• block size
• associativity
• replacement policy
• write-through vs write-back
• write allocation
The optimal choice is a compromise• depends on access characteristics
- workload
- use (I-cache, D-cache, TLB)
• depends on technology / cost
Simplicity often wins
Associativity
Cache Size
Block Size
Bad
Good
Less More
Factor A Factor B

















