20
Effective and Efficient Entity Search in RDF data Roi Blanco 1 , Peter Mika 1 and Sebastiano Vigna 2 1 Yahoo! Research 2 Università degli Studi di Milano
| Date post: | 15-Jul-2015 |
| Category: |
Technology |
| Upload: | roi-blanco |
| View: | 545 times |
| Download: | 1 times |

Effective and Efficient Entity Search in RDF data
Roi Blanco1, Peter Mika1 and Sebastiano Vigna2
1 Yahoo! Research
2 Università degli Studi di Milano

- 2 -
Semantic Search
• Unstructured or hybrid search over RDF data
– Supporting end-users
• Users who can not express their need in SPARQL
– Dealing with large-scale data
• Giving up query expressivity for scale
– Dealing with heterogeneity
• Users who are unaware of the schema of the data
• No single schema to the data
– Example: 2.6m classes and 33k properties in Billion Triples 2009
• Entity search
– Queries where the user is looking for a single entity named or
described in the query
– e.g. kaz vaporizer, hospice of cincinnati, mst3000

- 3 -
Use cases in web search
Top-1 entity with
structured data
Related entitiesStructured data
extracted from HTML

- 4 -
Information access in the Semantic Web
• Database-style indexing of RDF data
– Triple stores
– Structural queries (SPARQL)
– No ranking
– Evaluation focused on efficiency
• IR-style indexing of RDF data
– Search engines
– Keyword queries
– Ranking
– Evaluation focused on effectiveness
• Combined methods
– Keyword matching and limited join processing

- 5 -
Related works
• Ranking methods on RDF data
– Wang et al. Semplore: A scalable IR approach to search the
Web of Data. ISWC 2007, JWS 7(3)
– Pérez-Agüera et al. Using BM25F for semantic search.
SemSearch 2010
– (many others)
• Evaluation campaigns
– SemSearch Challenge 2010, 2011
– Question-Answering over Linked Data (QALD) 2011
– TREC Entity Track 2010, 2011
• Keyword search in databases
– No open evaluation campaigns

- 6 -
Architecture overview
Doc
1. Download, uncompress,
convert (if needed)
2. Sort quads by subject
3. Compute Minimal Perfect
Hash (MPH)
map
map
reduce
reduce
map reduce
Index
3. Each mapper reads part of
the collection
4. Each reducer builds an
index for a subset of the
vocabulary
5. Optionally, we also build an
archive (forward-index)
5. The sub-indices are
merged into a single
index
6. Serving
and
Ranking
1st part of the talk 2nd part

- 7 -
RDF indexing using MapReduce
• Text indexing using MapReduce
– Map: parse input into (term, doc) pairs
• Pre-processing such as stemming, blacklisting
• To support phrase queries values are (doc, position) pairs
– Reduce: collect all values for the same key: (term, {doc1,doc2…}),
output posting-list
• Secondary sort to pre-sort document ids before iteration
• RDF indexing using MapReduce (see Mika, SemSearch 2009)
– Document is all triples with a given subject
• Variations: index also RDF molecules, triples where the URI is an object
– Index terms in property-values
• Keys are (field, term) pairs
• Variation: distinguish values for the same property
– Index terms in the subject URI
• Variation: index also terms in object URIs

- 8 -
Horizontal index structure
• One field per position
– one for object (token), one for predicates (property), optionally one for context
• For each term, store the property on the same position in the
property index
– Positions are required even without phrase queries
• Query engine needs to support fields and the alignment operator
Dictionary is number of unique terms + number of properties
Occurrences is number of tokens * 2

- 9 -
Vertical index structure
• One field (index) per property
• Positions are not required
• Query engine needs to support fields
Dictionary is number of unique terms
Occurrences is number of tokens
✗ Number of fields is a problem for merging, query performance
• In experiments we index the N most common properties

- 10 -
Efficiency improvements
• r-vertical (reduced-vertical) index
– One field per weight vs. one field per property
– More efficient for keyword queries but loses the ability to
restrict per field
– Example: three weight levels
• Pre-computation of alignments
– Additional term-to-field index
– Used to quickly determine which fields contain a term (in any
document)

- 11 -
Indexing efficiency
• Billion Triples 2009 dataset
– 249 GB in uncompressed N-Quad
– 114 million URIs and 274 million triples with datatype properties
– 2.9B / 1.4B occurrences (horiz/vert)
• Selected 300 most frequent datatype properties for vertical indexing
• Resulting index is 9-10GB in size
• Horizontal and vertical indexing using Hadoop
– Scale is only limited by number of machines
– Number of reducers is a trade-off between speed and number of sub-indices to be merged

- 12 -
Run-time efficiency
• Measured average execution time (including ranking)
– Using 150k queries that lead to a click on Wikipedia
– Avg. length 2.2 tokens
– Baseline is plain text indexing with BM25
• Results
– Some cost for field-based retrieval compared to plain text indexing
– AND is always faster than OR
• Except in horizontal, where alignment time dominates
– r-vertical significantly improves execution time in OR mode
AND mode OR mode
plain text 46 ms 80 ms
horizontal 819 ms 847 ms
vertical 97 ms 780 ms
r-vertical 78 ms 152 ms

- 13 -
BM25F Ranking
BM25(F) uses a term-frequency (tf) that accounts for the
decreasing marginal contribution of terms
where
vs is the weight of the field
tfsi is the frequency of term i in field s
Bs is the document length normalization factor:
ls is the length of field s
avls is the average length of s
bs is a tunable parameter

- 14 -
BM25F ranking cont.
• Final term score is a combination of tf and idf
where
k1 is a tunable parameter
wIDF is the inverse-document frequency:
• Finally, the score of a document D is the sum of the scores
of query terms q

- 15 -
Effectiveness evaluation
• Semantic Search Challenge 2010
– Data, queries, assessments available online
• Billion Triples Challenge 2009 dataset
• 92 entity queries from web search
– Queries where the user is looking for a single entity
– Sampled randomly from Microsoft and Yahoo! query logs
• Assessed using Amazon’s Mechanical Turk
– Halpin et al. Evaluating Ad-Hoc Object Retrieval, IWEST 2010
– Blanco et al. Repeatable and Reliable Search System
Evaluation using Crowd-Sourcing, SIGIR2011

- 16 -
Evaluation form

- 17 -
Implementation
• Simplified model to reduce the number of parameters
– Three levels of vs: important, neutral, unimportant
– Assign weights to domains instead of individual doc weights wD
– Single parameter b for all bs
– Single parameter ls for all l, bounded by a maximum lmax=10
• Manually classified a small number of properties and
domains into important, neutral, unimportant
– Future work to learn this classification
– Weights are learned (see next)
- 18 -
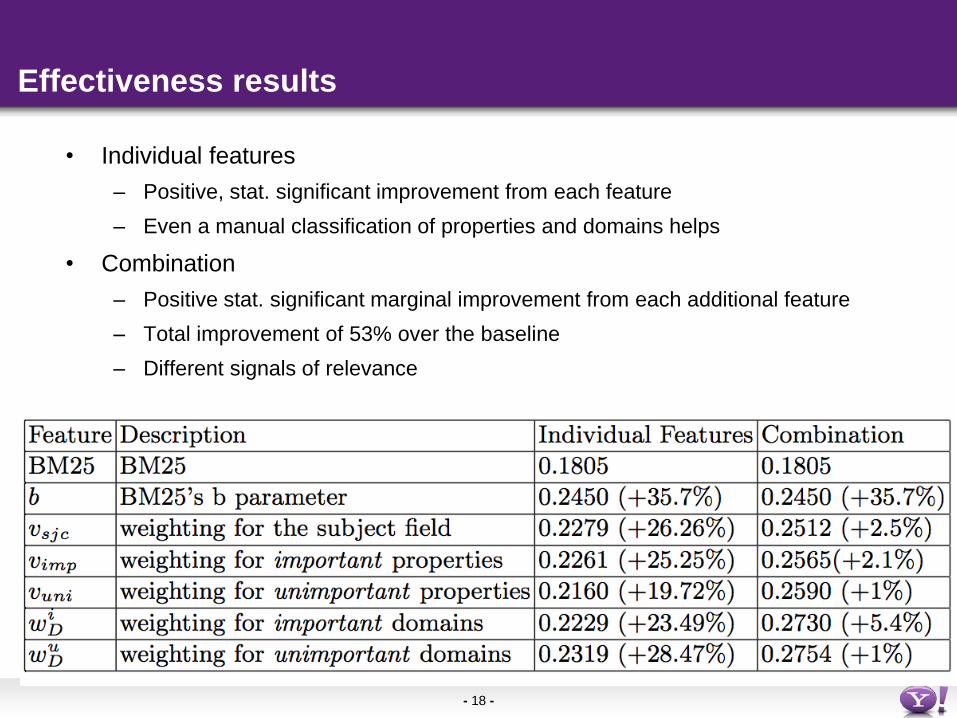
Effectiveness results
• Individual features
– Positive, stat. significant improvement from each feature
– Even a manual classification of properties and domains helps
• Combination
– Positive stat. significant marginal improvement from each additional feature
– Total improvement of 53% over the baseline
– Different signals of relevance

- 19 -
Comparison to SemSearch’10
• Two-fold cross validation
• Tuning all parameters at the same time
– Promising directions algorithm (Robertson and Zaragoza)
• 42% improvement over the best method submitted
• Performs well on short, specific queries with many results
– Negative examples: the morning call lehigh valley pa

- 20 -
Conclusions
• Indexing and ranking RDF data
– Novel index structures
– Ranking method based on BM25F
• Future work
– Ranking documents with metadata
• e.g. microdata/RDFa
– Exploiting more semantics
• e.g. sameAs
– Ranking triples for display
– Question-answering

















