25
End-to-End Data Pipelines with Apache Spark Matei Zaharia April 27, 2015
| Date post: | 15-Jul-2015 |
| Category: |
Software |
| Upload: | databricks |
| View: | 965 times |
| Download: | 0 times |

End-to-End Data Pipelines with Apache Spark Matei Zaharia April 27, 2015

What is Apache Spark?
Fast and general cluster computing engine that extends Google’s MapReduce model
Improves efficiency through: – In-memory data sharing – General computation graphs
Improves usability through: – Rich APIs in Java, Scala, Python – Interactive shell
Up to 100× faster
2-5× less code
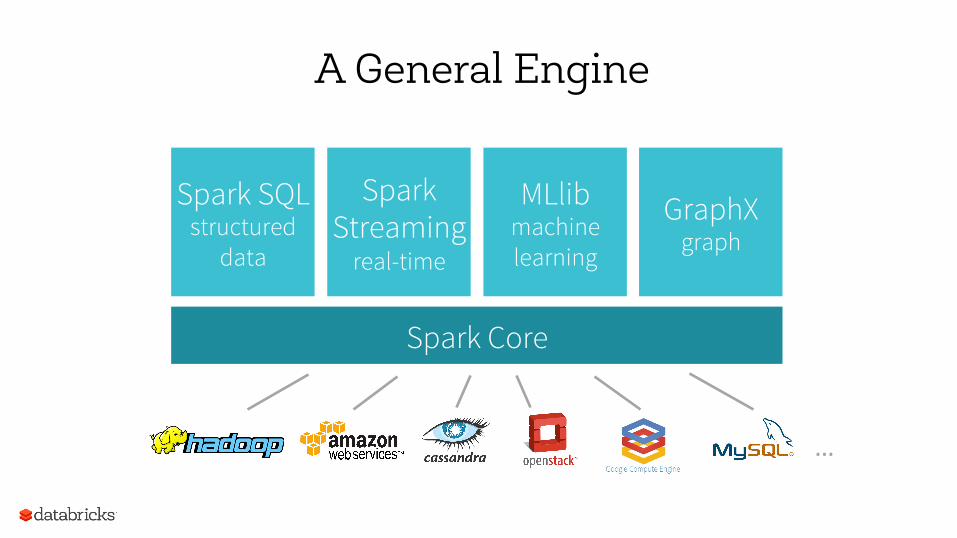
Spark Core
Spark Streaming
real-time
Spark SQL structured
data
MLlib machine learning
GraphX graph
A General Engine
…

About Databricks
Founded by creators of Spark and remains largest contributor
Offers a hosted service, Databricks Cloud – Spark on EC2 with notebooks, dashboards, scheduled jobs

This Talk
Introduction to Spark Spark for machine learning New APIs in 2015

Spark Programming Model
Write programs in terms of parallel transformations on distributed datasets Resilient Distributed Datasets (RDDs)
– Collections of objects that can be stored in memory or disk across a cluster
– Built via parallel transformations (map, filter, …) – Automatically rebuilt on failure

Example: Log Mining
Load error messages from a log into memory, then interactively search for various patterns lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(‘\t’)[2])
messages.cache()
Block 1
Block 2
Block 3
Worker
Worker
Worker
Driver
messages.filter(lambda s: “foo” in s).count()
messages.filter(lambda s: “bar” in s).count()
. . .
tasks
results Cache 1
Cache 2
Cache 3
Base RDD Transformed RDD
Action
Full-text search of Wikipedia in <1 sec (vs 20 sec for on-disk data)

Example: Logistic Regression
Find hyperplane separating two sets of points
+
– + + +
+
+
+ + +
– – –
–
– –
– – +
target
–
random initial plane

Example: Logistic Regression
data = spark.textFile(...).map(readPoint).cache() w = numpy.random.rand(D) for i in range(iterations): gradient = data.map(lambda p: (1 / (1 + exp(-p.y * w.dot(p.x)))) * p.y * p.x ).reduce(lambda x, y: x + y) w -= gradient
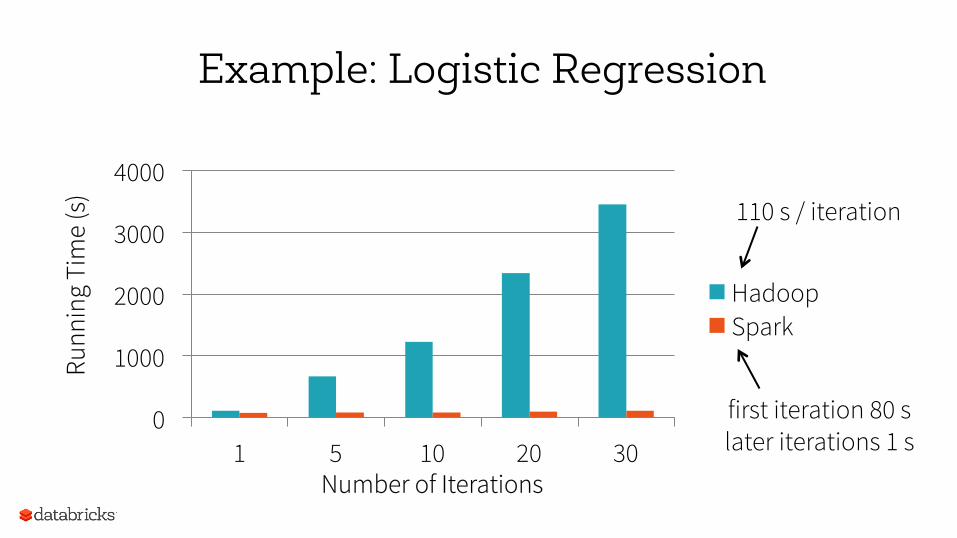
0
1000
2000
3000
4000
1 5 10 20 30
Runn
ing
Tim
e (s
)
Number of Iterations
Hadoop Spark
110 s / iteration
first iteration 80 s later iterations 1 s
Example: Logistic Regression

11
On-Disk Performance Time to sort 100TB
Source: Daytona GraySort benchmark, sortbenchmark.org
2100 machines 2013 Record: Hadoop
72 minutes
2014 Record: Spark
207 machines
23 minutes

User Community
Over 500 production users Clusters up to 8000 nodes, processing 1 PB/day Most active open source big data project
12

Project Activity in Past Year
Map
Redu
ce
YARN
HD
FS St
orm
Sp
ark
0 500
1000 1500 2000 2500 3000 3500 4000 4500
Map
Redu
ce
YARN
HD
FS Stor
m
Spar
k
0
100000
200000
300000
400000
500000
600000
700000
800000
Commits Lines of Code Changed

This Talk
Introduction to Spark Spark for machine learning New APIs in 2015

Machine Learning Workflow
Machine learning isn’t just about training a model! – In many cases most of the work is in feature preparation – Important to test ideas interactively – Must then evaluate model and use it in production
Spark includes tools to perform this whole workflow
15

Machine Learning Workflow
Traditional Spark
Feature preparation MapReduce, Hive RDDs, Spark SQL
Model training Mahout, custom code MLlib
Model evaluation Custom code MLlib
Production use Export (e.g. to Storm) model.predict()
16 All operate on RDDs

Short Example
// Load data using SQL ctx.jsonFile(“tweets.json”).registerTempTable(“tweets”) points = ctx.sql(“select latitude, longitude from tweets”)
// Train a machine learning model model = KMeans.train(points, 10)
// Apply it to a stream sc.twitterStream(...) .map(lambda t: (model.predict(t.location), 1)) .reduceByWindow(“5s”, lambda a, b: a + b)

Workflow Execution
Separate engines:
. . . HDFS read
HDFS write pr
epar
e
HDFS read
HDFS write tra
in
HDFS read
HDFS write ap
ply
HDFS write
HDFS read prep
are
train
ap
ply
Spark:
HDFS
Interactive analysis

19
Available ML Algorithms Generalized linear models Decision trees Random forests, GBTs Naïve Bayes Alternating least squares PCA, SVD AUC, ROC, f-measure
K-means Latent Dirichlet allocation Power iteration clustering Gaussian mixtures FP-growth Word2Vec Streaming k-means

Overview
Introduction to Spark Spark for machine learning New APIs in 2015

Goal for 2015
Augment Spark with higher-level data science APIs similar to single-machine libraries DataFrames, ML Pipelines, R interface
21

22
DataFrames
Collections of structured data similar to R, pandas
Automatically optimized via Spark SQL
– Columnar storage – Code-gen. execution
df = jsonFile(“tweets.json”)
df[df[“user”] == “matei”]
.groupBy(“date”)
.sum(“retweets”)
0
5
10
Python Scala DataFrame Ru
nnin
g Ti
me
Out now in Spark 1.3

23
Machine Learning Pipelines
High-level API similar to SciKit-Learn
Operates on DataFrames Grid search and cross validation to tune params
tokenizer = Tokenizer()
tf = HashingTF(numFeatures=1000)
lr = LogisticRegression()
pipe = Pipeline([tokenizer, tf, lr])
model = pipe.fit(df)
tokenizer TF LR
model DataFrame
Out now in Spark 1.3

24
Spark R Interface
Exposes DataFrames and ML pipelines in R Parallelize calls to R code
df = jsonFile(“tweets.json”)
summarize(
group_by(
df[df$user == “matei”,],
“date”),
sum(“retweets”))
Target: Spark 1.4 (June)

To Learn More
Downloads & docs: spark.apache.org Try Spark in Databricks Cloud: databricks.com Spark Summit: spark-summit.org
25








![[@NaukriEngineering] Apache Spark](https://static.documents.pub/doc/80x56/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)








