18
eNTERFACE’08 Multimodal high-level data integration Project 2 1
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| Upload: | mervin-charles |
| View: | 224 times |
| Download: | 2 times |

eNTERFACE’08
Multimodal high-level data integration
Project 2
1

TeamOlga Vybornova (Université catholique de
Louvain, UCL-TELE, Belgium)Hildeberto Mendonça (Université
catholique de Louvain, UCL-TELE, Belgium)
Ao Shen (University of Birmingham, UK)
Daniel Neiberg (TMH/CTT, KTH Royal Institute of Technology, Sweden)
David Antonio Gomez Jauregui (TELECOM and Management SudParis, France)

Project objectivesto augment and improve the previous
work, look for new methods of data fusionto resolve the problem and implement
a/the technique distinguishing between the data from different modalities that should be fused and the data that should not be fused but analyzed separately
to explore and employ a context-aware cognitive architecture for decision-making purposes.
3

4
A set of variables describing states of the world (user’s input, an object, an event, behavior, etc.) represented in different media and through different information channels.
GOAL OF DATA FUSION: The result of the fusion (merging semantic content from multiple streams) should give an efficient joint interpretation of the multimodal behavior of the user(s) – to provide effective and advanced interaction
Background - Multimodality

Cognitive behavior is goal-oriented, it takes place in a rich, complex, detailed environment, so…
the system should: o acquire and process a large amount of
knowledge,o be flexible and be a function of the
environment, o be capable of learning from the
environment and experience.
Requirements
behavior = architecture + content

6
Types of contextDomain context (prior knowledge of the
domain, semantic frames with predefined action patterns, user s profiles, situation modelling, a priori developed and dynamically updated ontology defining subjects, objects, activities and relations between them for a particular person)
Video context (capturing the users’ actions in the observation scene)
Linguistic context (derived from natural language semantic analysis)
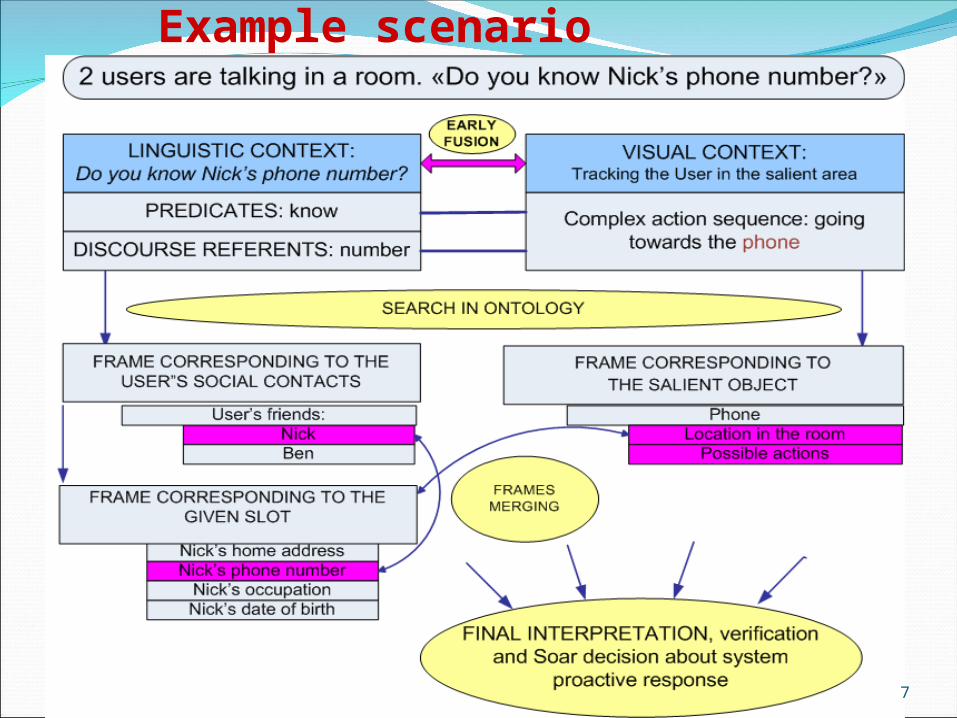
Example scenario
7

Knowledge-based approach
Restricted-domain ontology – structure and its instantiation
Pattern situations (semantic frames)User profile - a priori collected
information about users - preferences, social relationships information, etc. - and dynamically obtained data
8

Audio Stream Video Stream
SpeechRecognizer
Video Analyzer
Sound Waves
SyntacticAnalyzer
Recognized String
Sequence ofImages
SemanticAnalyzer
Syntactic Triple
KnowledgeBase
Fusion Mechanism
Human BehaviorAnalyzer
KnowledgeBase
Movements Coordinates
Movements Meanings
Advise PeopleLinguistic meanings

Tooling / Implementation
Speech recognition: Sphinx-4Syntactic Analysis: C&C Parser + semantic analyzer (
http://svn.ask.it.usyd.edu.au/trac/candc/wiki)Semantic Analysis
Ontology construction and instatiation: Protégé (http://protege.stanford.edu/)
Analysis: Soar (http://sitemaker.umich.edu/soar/home)
Video Analysis: Visual Hull (developed by Diego Ruiz, UCL-TELE)
Human Behavior Analysis: SoarOntology: Protégé
Fusion Mechanism: SoarIntegration: OpenInterface (www.openinterface.org)

Challenges
Unrestricted natural languageFree natural behavior within
home/office environment
11

Why do we need Soar ? CAPABILITIES:manages a full range of tasks expected of an intelligent
agent, from routine to extremely difficult, open-ended problems
represents and uses different forms of knowledge – procedural (rules), semantic (declarative, facts), episodic
employs various problem solving methods interacts with the outside worldintegrates reaction, deliberation, planning, meta-reasoning
dynamically switching between them has integrated learning (chunking, reinforcement learning,
episodic & semantic learning)is useful in cognitive modeling + taking into account
emotions, feeling and moodis easy to integrate with other systems and environments
(SML – Soar Markup Language – efficiently supports many languages) 12
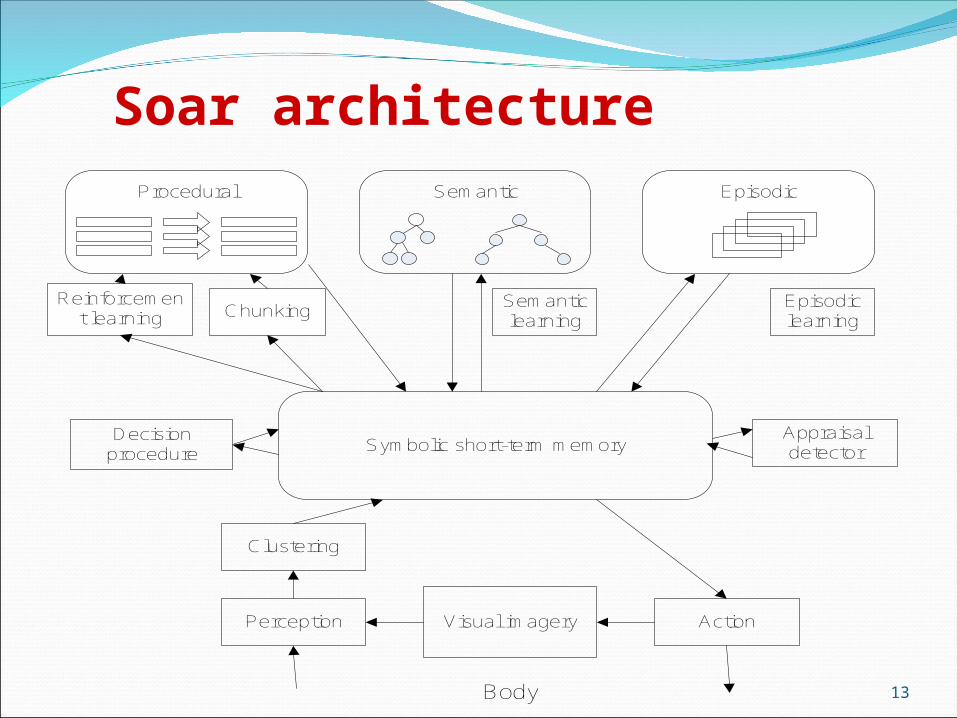
Soar architecture
13
Procedural Semantic Episodic
Symbolic short-term memory
Reinforcement learning Chunking
Semantic learning
Episodic learning
Decision procedure
Appraisal detector
Clustering
Perception Visual imagery Action
Body

Project schedule
14

WP 1Pre-workshop preparation
Task 1.1 - Identify and investigate the necessary multimodal components and systems to use during the workshop;
Task 1.2 - define the system architecture taking advantage of the previously accumulated experience and existing results;
Task 1.3 - describe precisely the scenario to work on it during the workshop
Task 1.4 - make the video sequences15

WP 2Integration of multimodal components
and systems (1st week)
Task 2.1 - implement the architecture, putting all multimodal components and systems work together.
Task 2.2 - explore and select the most suitable method(s) for action-speech multimodal fusion.
Task 2.3 - investigate the fusion implementation
16

WP 3Multimodal fusion implementation (2nd
week)
Task 3.1 - fusion algorithms implementation
Task 3.2 - fusion algorithms testing in a distributed computer environment.
17

WP 4Scenario implementation and reporting
(3rd and 4th weeks)
Task 4.1 – integrate and test of all the components and systems on the OpenInterface platform
Task 4.2 - prepare a presentation and reports about the results
Task 4.3 - demonstrate the results
18
![Monitoria multimodal cerebral multimodal monitoring[2]](https://static.documents.pub/doc/80x56/552957004a79599a158b46fd/monitoria-multimodal-cerebral-multimodal-monitoring2.jpg)
















