Esperonto Services IST-2001-34373 Deliverable Ontology Alignment Solution D1.4 v2.0 Anna V. Zhdanova, Jos de Bruijn, Kerstin Zimmermann, Francois Scharffe {anna.zhdanova, jos.debruijn, kerstin.zimmermann, francois.scharffe}@deri.org Institute of Computer Science University of Innsbruck
Transcript
Esperonto ServicesIST-2001-34373
Deliverable
Ontology Alignment SolutionD1.4 v2.0
Anna V. Zhdanova, Jos de Bruijn,Kerstin Zimmermann, Francois Scharffe
Institute of Computer ScienceUniversity of Innsbruck
15-12-2004
Esperonto Services IST-2001-34373
Executive SummaryIn this deliverable, existing methods and tools for ontology mapping and alignment are reviewed and evaluated, requirements for ontology mapping and aligning solutions are defined, and the ontology solution for the Esperonto project is presented and evaluated. Specifically, the ontology alignment solution comprises a proposal for a language independent expressive mapping language formalism, an implementation support of a selected ontology alignment tool that aims at a wide language-independent usage, and a solution for integrating proposed formalisms and tool in an ontology management system.
This deliverable is the second and final version of the ontology alignment deliverable in the Esperonto project. Comparing to the previous (first) version of the ontology alignment deliverable, this version contains an update of the survey on the state-of-the-art in ontology alignment methods and tools as their development progressed since the latest deliverable version, the ontology alignment solution specified in further details and a vision on further development and integration aspects of the solution.
D1.4 v2.0 Ontology Alignment Solution i
Esperonto Services IST-2001-34373
Document InformationIST Project Number IST-2001-34373 Acronym Esperonto Services
Full title Application Service Provision of Semantic Annotation, Aggregation, Indexing and Routing of Textual, Multimedia, and Multilingual Web Content
Project URL www.esperonto.net
Document URL
EU Project officer Werner Janusch
Deliverable Number D1.4 Name Ontology Alignment Solution v2.0
Task Number D1.4 Name Ontology Alignment Solution
Work package Number 1
Date of delivery Contractual 30-11-2004 Actual
Code name Status draft final
Nature Prototype Report Specification Tool Other
Distribution Type Public Restricted Consortium
Authors (Partner) Anna V. Zhdanova (IFI), Jos de Bruijn (IFI), Kerstin Zimmermann (IFI), Francois Scharffe (IFI)
This deliverable evaluates existing methods and tools for ontology mapping and alignment, defines requirements for an ontology mapping and aligning solutions, and proposes a solution to be used for the Esperonto project.
Keywords Ontology alignment, ontology mapping, information integration
iSOCO Dr. V. Richard Benjaminsc/ Pedro de Valdivia, 1028006 Madrid, Spain#e [email protected]#t +34-91-334-97-97, #f +34-91-334-97-99
Universidad Politécnica de Madrid UPM
Dr. Asunción Gómez-PérezCampus de Montegancedo, sn Boadilla del Monte, 28660, Spain #e [email protected] #t +34-91 336-7439, #f +34-91 352-4819
Institut für Informatik, Leopold-Franzens Universität Innsbruck
IFI
Prof. Dieter FenselInstitute of computer scienceUniversity of InnsbruckTechnikerstr. 25A-6020 Innsbruck, Austria#e [email protected] #t +43 512 507 6486
Universität des Saarlandes UdS Thierry Declerck DFKI GmbH (German Research Center for AI),Stuhlsatzenhausweg 3, D-66123 Saarbruecken (Germany)#e: [email protected]#t: +49-681-302-5358, #f: +49-681-302-5338
The University of Liverpool UniLiv Dr. Valentina A.M. TammaDepartment of Computer Science,University of LiverpoolRoom 1.11, Chadwick BuildingPeach StreetLiverpool L69 7ZF, UK#e [email protected] #t +44 151 794 6797, #f +44 151 794 3715
AcknowledgmentsWe would like to thank Ying Ding (IFI), Sinuhe Arroyo (IFI) and Holger Lausen (IFI) for their contributions to the deliverable “Ontology Alignment Solution v1.0” which served as a starting point for this deliverable.
D1.4 v2.0 Ontology Alignment Solution iv
Esperonto Services IST-2001-34373
Table of Contents
1. Introduction...........................................................................................................................11.1. Definitions....................................................................................................................11.2. Ontology Alignment in the Esperonto project..............................................................3
2. Survey of Ontology Alignment Methods and Tools.............................................................62.1 InfoSleuth’s Reference Ontology.................................................................................72.2 Stanford’s Ontology Algebra and ONION...................................................................82.3 AIFB’s Formal Concept Analysis and FCA-Merge...................................................102.4 KRAFT’s Ontology Clustering...................................................................................122.5 Chimaera.....................................................................................................................142.6 PROMPT....................................................................................................................152.7 OBSERVER................................................................................................................172.8 OntoMerge..................................................................................................................192.9 MoA............................................................................................................................212.10 MAFRA......................................................................................................................222.11 INRIA Ontology Alignment API................................................................................232.12 Other Methods for Ontology Alignment....................................................................252.13 Summary.....................................................................................................................27
3 Requirements for Ontology Alignment Solution......................................................................283.1 Problems of Ontology Alignment...............................................................................283.2 Requirements Analysis...............................................................................................30
3.2.1 Ontology Mapping Language Requirements..........................................................313.2.2 Ontology Alignment Service Implementation Requirements................................333.2.3 Ontology Alignment Integration Requirements.....................................................34
4.2.1 Ontology Alignment Implementation Architecture................................................384.2.2 Functionality and Limitations.................................................................................394.2.3 Integration and Interoperation with External Systems...........................................41
4.3 Ontology Alignment in Ontology Management System...................................................414.3.1 Introduction............................................................................................................414.3.2 The alignment tool components.............................................................................424.3.2.1 Mapping Module................................................................................................434.3.2.2 Runtime module.................................................................................................434.3.2.3 Architecture........................................................................................................434.3.3 Participants.............................................................................................................45
1. IntroductionEffective use or reuse of knowledge is essential. Especially nowadays this is the case due to the overwhelming amount of information that is continually being generated, which in turn has forced organizations, businesses and people to manage their knowledge more effectively and efficiently. Simply combining knowledge from distinct domains invokes problems, such as, different knowledge representation formats and semantic inconsistencies.
Therefore, ontology alignment solutions are needed to be specified and deployed. In the first part of this section, we introduce the terms that constitute understanding of ontology alignment and provide a formal notion of the ontology alignment problem we consider in this deliverable. In the second part of the section, the ontology alignment problem and approach are defined in the context of the Esperonto project.
1.1. DefinitionsIn this section, terms that are used in this report are clarified. We deem this necessary, because there exist many different understandings of the terminology in the literature. The term definitions are adopted from the deliverable of the SEKT project (de Bruijn et al., 2004).
Ontology An ontology O is a 4-tuple <C;R; I;A>, where C is a set of concepts, R is a set of relations, I is a set of instances and A is a set of axioms. Note that these four sets are not necessarily disjoint (e.g. the same term can denote both a class and an instance), although the ontology language might require this.All concepts, relations, instances and axioms are specified in some logical language. This notion of an ontology coincides with the notion of an ontology described in (Roman et al, 2004, Chapter 2) and is similar to the notion of an ontology in OKBC (Chaudhri et al, 1998) . Concepts correspond with classes in OKBC, slots in OKBC are particular kinds of relations, facets in OKBC are a kind of axiom and individuals in OKBC are what we call instances4.In an ontology, concepts are usually organized in a subclass hierarchy, through the is-a (or subconcept-of) relationship. More general concepts reside higher in the hierarchy.
Instance Base Although instances are logically part of an ontology, it is often useful to separate between an ontology describing a collection of instances and the collection of instances described by the ontology. We refer to this collection of instances as the Instance Base. Instance bases are sometimes used to discover similarities between concepts in different ontologies (e.g. Stumme and Maedche, 2001, Doan, 20004). An instance base can be any collection of data, such as a relational database or a collection of web pages. Note that this does not rule out the situation where instances use several ontologies for their description. However, most approaches in this survey which make use of instances assume a collection of instances described by one ontology.
Ontology Language The ontology language is the language which is used to represent the ontology. Popular ontology languages for the Semantic Web are RDFS (Brickley and Guha, 2004) and OWL (Dean and Schreiber, 2004). Semantic Web ontology languages can be split up into two parts: the logical and the extra-logical parts. The logical part usually amounts to a theory in some logical language, which can be used for reasoning. The logical part basically consists of a number of logical axioms, which form the class (concept) definitions, property (relation) definitions, instance definitions, etc. The extra-logical part of the language typically consists of non-functional properties (e.g. author name, creation date, natural language comments, multi-lingual labels) and other extra-logical statements, such as namespace declarations, ontology imports, versioning, etc. Non-functional properties are typically only for the human reader, whereas many of the other extra-logical statements are machine-processable.
D1.4 v2.0 Ontology Alignment Solution 1
Esperonto Services IST-2001-34373
For example, namespaces can be resolved by the machine and the importing of ontologies can be achieved automatically by either (a) appending the logical part of the imported ontology to the logical part of the importing ontology to create one logical theory or (b) using a mediator, which resolves the heterogeneity between the two ontologies (see also the definition of Ontology Mediation below).
Ontology Mediation Ontology mediation is the process of reconciling differences between heterogeneous ontologies in order to achieve inter-operation between data sources annotated with and applications using these ontologies. This includes the discovery and specification of ontology mappings, as well as the use of these mappings for certain tasks, such as query rewriting and instance transformation. Furthermore, the merging of ontologies also falls under the term ontology mediation.
Ontology Mapping An ontology mapping M is a (declarative) specification of the semantic overlap between two ontologies OS and OT . This mapping can be one-way (injective) or two-way (bijective). In an injective mapping we specify how to express terms in OT using terms from OS in a way that is not easily invertible. A bijective mapping works both ways, i.e. a term in OT is expressed using terms of OS and the other way around.
Mapping Language The mapping language is the language used to represent the ontology mapping M. It is important here to distinguish between a specification of the similarities of entities between ontologies and an actual ontology mapping. The specification of similarities between ontologies is usually a level of confidence (usually between 0 and 1) of the similarity of entities, whereas an ontology mapping actually specifies the relationship between the entities in the ontologies. This is typically an exact specification and typically far more powerful than simple similarity measures. Mapping languages often allow arbitrary transformation between ontologies, often using a rule-based formalism and typically allowing arbitrary valuetransformations.
Mapping Pattern Although not often used in current approaches to ontology mediation, patterns can play an important role in the specification of ontology mappings, because they have the potential to make mappings more concise, better understandable and reduce the number of errors (Park et al., 1998). A mapping pattern can be seen as a template for mappings which occur very often. Patterns can range from very simple (e.g. a mapping between a concept and a relation) to very complex, in which case the pattern captures comprehensive substructures of the ontologies, which are related in a certain way.
Matching We define ontology matching as the process of discovering similarities between two source ontologies. The result of a matching operation is a specificationof similarities between two ontologies. Ontology matching is done through application of the Match operator (Rahm and Bernstein, 2001). Any schema matching or ontology matching algorithm can be used to implement the Match operator, e.g. (Doan et al, 2004, Giunchiglia et al., 2004, Madhavan et al, 2001).We adopt here the definition of Match given by Rahm and Bernstein (2001): “[Match is an operation], which takes two schemas [or ontologies] as input and produces a mapping between elements of the two schemas that correspond semantically to each other”.
For the definitions of merging, aligning and relating ontologies, we adopt the definitions given by Ding et al. (2002).
Ontology Merging Creating one new ontology from two or more ontologies. In this case, the new ontology will unify and replace the original ontologies. This often requires considerable adaptation and extension.Note that this definition does not say how the merged ontology relates to the original ontologies. This is intentionally left open because not all approaches merge ontologies in the same way.
D1.4 v2.0 Ontology Alignment Solution 2
Esperonto Services IST-2001-34373
The most prominent approaches are the union and the intersection approaches. In the union approach, the merged ontology is the union of all entities in both source ontologies, where differences in representation of similar concepts have been resolved. In the intersection approach, the merged ontology consists only of the parts of the source ontology which overlap (c.f. the intersection operator in ontology algebra by Wiederhold, 1994).
Ontology Aligning1 Bringing the ontologies into mutual agreement. Here, the ontologies are kept separate, but at least one of the original ontologies is adapted such that the conceptualization and the vocabulary match in overlapping parts of the ontologies. However, the ontologies might describe different parts of the domain in different levels of detail.
Relating Ontologies Specifying how the concepts in the different ontologies are related in a logical sense. This means that the original ontologies have not changed, but that additional axioms describe the relationship between the concepts. Leaving the original ontologies unchanged often implies that only a part of the integration can be done, because major differences may require adaptation of the ontologies. The term “Ontology Mapping” was defined above as a specification of the relationship between two ontologies. We can also interpret the word “Mapping” as a verb, i.e. the action of creating a mapping. In this case the term corresponds with the term “Relating Ontologies”.
1.2. Ontology Alignment in the Esperonto project
The overall goal of the Esperonto project is to provide a bridge between the current web and the Semantic Web. In order to provide such a bridge, the first objective of the Esperonto project is to construct a service that provides content providers with tools and techniques to publish their (existing and new) content on the SW, independently of their native language. This service to be developed is called the SEMantic Annotation Service Provider (SemASP)2. Content on the Semantic Web is annotated on the basis of ontologies. Because of the distributed nature of the Web, many different providers provide similar content, for example, many book vendors publish their book catalogues on the Web. These different content providers use different ontologies to annotate their content, since it is hard to agree on a common vocabulary for a large, and, especially, distributed group (Uschold, 2000). The example of different book vendors, annotating their content using (different) ontologies is illustrated in Figure 1.
Figure 1: Example annotation using ontologies
In the example, a user agent that only knows about ontology1 or ontology2, or possibly even only about some other ontology3, will never be able to understand all published
1 In literature, there are disagreements on the term ontology alignment. We use the term ontology alignment as a synonym to the terms ontology aligning and ontology mapping.2 For a detailed description of SemASP, see Deliverable 7.1 of the Esperonto project
D1.4 v2.0 Ontology Alignment Solution 3
bookcatalogue
A
ontology1 ontology2
bookcatalogue
B
bookcatalogue
CUser Agent
ontology3
Esperonto Services IST-2001-34373
catalogues. In order to enable interoperation between these different representations, there should be a mapping between the different ontologies. When in our example, there exists a mapping between the user agent’s ontology ontology3 and ontology2, the user agent would be able to understand book catalogues B and C. When there would also be a mapping between ontology1 and ontology23, then the user agent would also be able to understand book catalogue A.
Figure 2: Sample annotation using ontologies with mappings (depicted using straight arrows) in place
Figure 2 shows the mappings between different ontologies and how they enable the user agent to use the different book catalogues.
To summarize, the challenge in ontology alignment in the Esperonto project is to provide explicit mappings between different ontologies, in order to enable interoperation between different entities on the Semantic Web. In the Esperonto project, we only consider Ontology Aligning and not Ontology Merging. We deem important to support a distributed architecture with different interconnected ontologies, (possibly) maintained by various different organizations. If we consider ontology merging, the (distributed) source ontologies do not remain and the ontology infrastructure would shift from a distributed to a centralized infrastructure, which is undesirable for our architecture. The ontology maintenance task would shift to one specific organization, so that organizations cannot in general maintain their own ontologies, which would be undesirable from a usability point-of-view and would hinder ontology evolution.
In this report we aim at providing a solution for the ontology alignment problem in the Esperonto project. The solution includes an implementation that enables a wide audience to publish their content on the Semantic Web to enhance interoperation issues in general. Further, an integrated ontology mapping publishing repository and environment supporting multiple communities using multiple ontology languages is envisioned.
This report is organized as follows: in section 2, we conduct a survey on existing ontology mapping and aligning methods and tools, provide a summary of the functionalities and the methods, and investigate reuse opportunities. In section 3, requirements for ontology alignment solution are identified. In section 4, we describe the ontology alignment solution for the Esperonto project. The solution consists of a novel, expressive language formalism for ontology 3 Note that, when there is a mapping between ontology1 and ontology2, instances can be translated from the ontology1 to ontology2 representation. Now, these instances of ontology2 can, through the mapping to ontology3, be translated to the ontology3 representation.
D1.4 v2.0 Ontology Alignment Solution 4
bookcatalogue
A
ontology1 ontology2
bookcatalogue
B
bookcatalogue
C
User Agent
ontology3
Esperonto Services IST-2001-34373
mapping representation, choice of an appropriate ontology tool and an implementation of its adoption, and a solution of how novel ontology alignment theoretical developments and tools can be integrated in a single commonly and openly used environment – ontology management system. Finally, conclusions are presented.
D1.4 v2.0 Ontology Alignment Solution 5
Esperonto Services IST-2001-34373
2. Survey of Ontology Alignment Methods and Tools
In this section, we describe existing ontology alignment tools and methods, and evaluate applicability and reusability of these tools and methods for the Esperonto ontology alignment solution. One of the goals of this survey is to reuse elements of the previously developed methods and tools for the ontology alignment solution in the Esperonto project.At present, there are two main approaches to ontology alignment:
In the local model, or local ontology, approach the user is represented by an agent in the system and this agent presents the user with its own local data model. The agent performs the translation between the user's local model and either the global model or other local models in order to allow interaction with multiple data sources in the system. And example of the local model approach is the KRAFT project (Preece et al., 2001).
In the global model, or global ontology, approach the user will view the system through the global data model using a mediator, which is ``a system that supports an integrated view over multiple information sources'' (Hull, 1997). Note that in the local model approach, a user agent will in most cases also contact a mediator in order to allow inter-operation with the system, which contains multiple information sources. An example is the InfoSleuth (Fowler et al., 1999) architecture, where user agents view the individual data models through shared ontologies.
This categorization concerns the run-time approach of ontology mapping, that is, the way translations between different representations are carried out during operation of the system.In the following sections we provide an overview of the state of development of ontology mapping, aligning, merging in several projects in the corresponding areas. Information about each project along with the important features associated with the project are provided and highlighted.
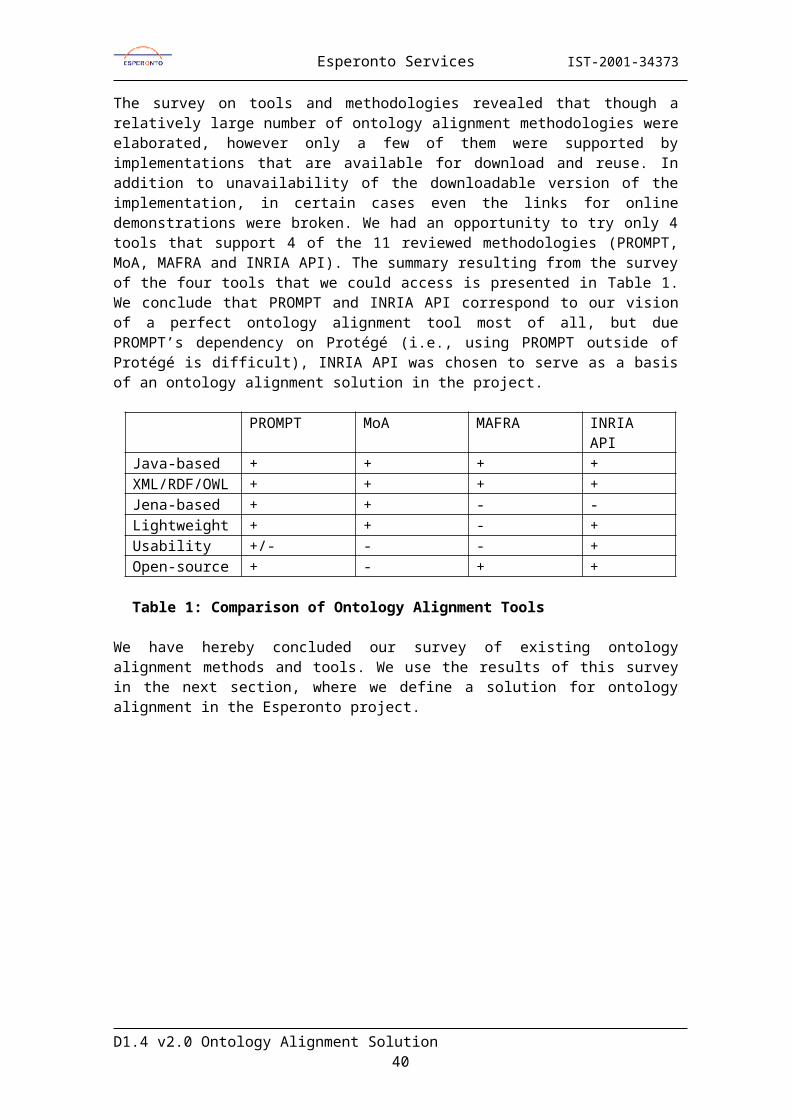
Clearly, it is high time for the developed models and methodologies to be supported by the implementation works. Further, to prove their value and have influence, the implemented tools and libraries should be accepted and shared across the wide communities. Design and implementations of such tools and libraries are highly demanding tasks that require both deep knowledge and proficiency in ontology alignment research and software developments trends. Nowadays, the state of the art in ontology alignment only starts to merge from defining methodologies to actual tool development, thus the major work in ontology alignment development is in the area of prototype construction and identification of requirements and criteria for widely accepted ontology alignment software. We consider the following criteria for choosing the ontology alignment library for an ontology alignment support module important for acceptance of resulting ontology alignment solution by the current community ontology-based environments and the current Semantic Web in general (Zhdanova, 2004):1. the library written in Java2. the library supports alignment of ontologies represented in XML/RDF/OWL languages3. the library is preferably based on the Jena ontology model4. the library is lightweight 5. the library’s API is understandable and preferably well documented6. the library is open source.
We keep in mind the above criteria in the survey we conduct here. In addition, to assistance with orientation in the area of ontology alignment tools, a general and widely known assessment of ontology translation and mapping tools can also be found at SemWebCentral4. However, this assessment includes to a large extent tools that are used to transform ontologies in one language
4 Translation and mapping tool assessment:http://www.semwebcentral.org/assessment/report?type=category&category=Translation
to ontologies in another language or to a database. In this section, a more thorough attention is paid to the ontology alignment methodologies and assessment of tool support for these methodologies. In the following sections, we provide general descriptions of the main features of ontology alignment methodologies and describe the tool support for these approaches.
2.1 InfoSleuth’s Reference OntologyDescriptionInfoSleuth (Fowler et al, 1999) is an agent-based system, which supports construction of complex ontologies from smaller component ontologies so that tools tailored for one component ontology can be used in many application domains. Examples of reused ontologies include units of measure, chemistry knowledge, geographic metadata, and so on. Mapping is explicitly specified among these ontologies as relationships between terms in one ontology and related terms in other ontologies. All mappings between ontologies are maintained by a special class of agents known as “resource agents”. A resource agent encapsulates a set of information using ontology mapping rules, and presents that information to the agent-based system in terms of one or more ontologies (called reference ontologies). All mapping is encapsulated within the resource agents. Ontologies are represented in OKBC (Open Knowledge Base Connectivity) (Chaudhri et al., 1998) format and stored in an OKBC server by a special class of agents called ontology agents, which provide ontology specifications to users (for request formulation) and to resource agents (for mapping).The InfoSleuth architecture (Nodine et al., 2000, Figure 3) consists of a number of different types of agents:
The user agents act on behalf of the user and maintain the user’s state. They provide a system interface that enables users to communicate with the system.
The resource agents wrap and activate databases and other repositories of information. They translate queries and data stored in external repositories between their local forms and their InfoSleuth forms. There are resource agents for different types of data sources, including relational databases, flat files, and images.
Service agents provide internal information for the operation of the agent system. Service agents include Broker agents, which collectively maintain the information the agents advertise about themselves, Ontology agents, which maintain a knowledge base of the different ontologies used for specifying requests, and Monitor agents, which monitor the operation of the system.
Query and analysis agents fuse and/or analyze information from one or more resources into single (one-time) results. Query and analysis agents include Multi-resource query agents, that process queries that span multiple data sources, Deviation detection agents, that monitor streams of data to detect deviations, and other data mining agents.
Planning and temporal agents guide the request through some processing which may take place over a period of time, such as a long-term plan, a workflow, or the detection of complex events. Planning and temporal agents include Subscription agents, that monitor how a set of information (in a data source) changes over time, Task planning and execution agents plan the processing of users’ requests in the system, and Sentinel agents monitor the information and event stream for complex events.
Value mapping agents provide value mapping among equivalent representations of the same information.
D1.4 v2.0 Ontology Alignment Solution 7
Esperonto Services IST-2001-34373
Figure 3: The InfoSleuth architectureJava templates were made available to facilitate the development of new agents. To create a resource agent using such a template, it is in general sufficient to just supply a configuration and a mapping file to complete the agent (Nodine et al., 2000). It is possible to use different ontologies in an InfoSleuth system. Each OKBC-compliant Knowledge Base can be used in InfoSleuth by wrapping it using an ontology agent (Nodine et al., 2000).
SummaryInfoSleuth is a multi-agent system for semantic inter-operability in heterogeneous data sources. Agents are used for query and instance transformations between data schemas. An agent is aware of its own ontology and the mapping between that ontology and the data schema, it is aware of the shared ontologies and it can map it’s ontology to those of other agents. InfoSleuth uses several shared ontologies, made available through the ontology agents. Individual data sources have (through the resource agents) a mapping to these shared ontologies. The shared ontologies are linked together through one-to-one ontology mapping.
Applicability and reusability
URL: http://www.argreenhouse.com/InfoSleuth/
No downloadable software is found to be available from the InfoSleuth Agent System. Taking into account the time of the project execution and its database orientation, we assume that the InfoSleuth software in case of its availability would likely not suit the requirements to a large extent.
2.2 Stanford’s Ontology Algebra and ONIONDescriptionIn this application, the mapping between ontologies is created using by ontology algebra (Wiederhold, 1994; Mitra and Wiederhold, 2001) that consists of three operations, namely, intersection, union and difference. The objective of ontology algebra is to provide the capability
for interrogating many largely semantically disjoint knowledge resources. Here, articulations (the rules that provide links across domains) can be established to enable knowledge interoperability. The ontology resulting from the mappings between two source ontologies is assumed to be consistent only within its own context, known as an articulation context (Jannink et. al., 1998). A context is defined here as a unit of encapsulation for well-structured ontologies. Contexts guarantee consistency in the knowledge they export.Mitra, Wiederhold & Kersten (2000) used ontology algebra to enable interoperation between ontologies via articulation ontologies. The input to the algebra consists of the ontology graphs of both source ontologies. The operators in the algebra include unary operators like filter and extract, and binary operators include union, intersection and difference (as in normal set operators):
The intersection operator produces an ontology graph, which is the intersection of the two source ontologies with respect to a set of articulation rules, generated by an articulation generator function. The nodes in the intersection ontology are those that appear in the articulation rules. The edges are those edges between nodes in the intersection ontology that appear in the source ontologies or have been established as an articulation rule. The intersection determines the portions of knowledge bases that deal with similar concepts.
The union operator generates a unified ontology graph comprising of the two original ontology graphs connected by the articulation. The union presents a coherent, connected and semantically sound unified ontology.
The difference operator, used to distinguish the difference of two ontologies (O1-O2), is defined as the terms and relationships of the first ontology that have been determined not to exist in the second. This operation allows a local ontology maintainer to determine the extent of one’s ontology that remains independent of the articulation with other domain ontologies so that it can be independently manipulated without having to update any articulation.
Figure 4: The components of the ONION system
They built up a system known as ONION (Ontology compositION) which is an architecture based on a sound formalism to support a scalable framework for ontology integration. The special feature of this system is that it separated the logical inference engine from the representation model (the graph representation) of the ontologies as much as possible. This
D1.4 v2.0 Ontology Alignment Solution 9
Esperonto Services IST-2001-34373
allowed the accommodation of different inference engines in the architecture. This system contains the following main components (see Figure 4, taken from (Mitra and Wiederhold, 2001)):
The ONION data layer. This layer contains the wrappers for the external sources and the articulation ontologies that form the semantic bridges between the sources.
The ONION viewer. This is the user interface component of the system. The viewer visualizes both the source and the articulation ontologies.
The ONION query system. The query system translates queries formulated in terms of an articulation ontology into a query execution plan and executes the query.
The Articulation Engine. The articulation generator takes articulation rules proposed by SKAT (Mitra et al., 1999), the Semantic Knowledge Articulation Tool, and generates sets of articulation rules, which are forwarded to the expert for confirmation.
In ONION there are two types of ontologies, individual ontologies, referred to as source ontologies and articulation ontologies, which contain the terms and relationships expressed as articulation rules (rules that provide links across domains). Articulation rules are established to enable knowledge interoperability, and to bridge the semantic gap between heterogeneous sources. They indicate which terms, individually or in conjunction, are related in the source ontologies (Mitra et al., 2000).In ONION, an ontology is represented by a conceptual graph and the ontology mapping is based on graph mapping. The main innovation of ONION is that it uses articulations of ontologies to interoperate among ontologies. Another important aspect of ONION is the graphical representation of ontologies, which allows the usage of different inference engines in the architecture.
SummaryONION takes a centralized, hierarchical approach to ontology mapping. The source ontologies are mapped to each other via articulation ontologies that are in turn used by the user to express queries. The articulation ontologies are organized in a tree structure. An articulation ontology used for the mapping of two source ontologies can in turn be one of the sources for another articulation ontology (e.g. in Error: Reference source not found Art12 is one of the sources of Art123). The creation of a hierarchy can be seen as a form of ontology clustering. But while Visser and Tamma (1999) take a top-down approach to ontology clustering (first the root application ontology is specified, then child ontologies are created as is necessary), ONION takes a bottom-up approach in the creation of the articulation ontologies; furthermore, there is no explicit root ontology for the cluster. This cluster of articulation ontologies acts as a mediator between all the data sources.
Applicability and reusability
URL: no URL assigned especially to ONION is found, the URL of the OntoAgents project where ONION was created is http://www-db.stanford.edu/Ontoagents/.
No downloadable software of ONION is found to be available. Taking into account the time of the project execution and its DAML and database orientation, we assume that the ONION software in case of its availability would likely not suit the requirements to a large extent.
2.3 AIFB’s Formal Concept Analysis and FCA-MergeDescriptionThe ontology learning group at AIFB (Institute of Applied Informatics and Formal Description Methods, University of Karlsruhe, Germany), through Stumme, Studer & Sure (2000), preliminarily discussed steps towards an order-theoretic foundation for maintaining and
merging ontologies and articulated some questions about how a structural approach can improve the merging process, for instance:
Which consistency conditions should ontologies verify in order to be merged? Can the merging of ontologies be described as a parameterized operation on the set of
ontologies? How can other relations beside the is-a relation be integrated? How can an interactive knowledge acquisition process support the construction of the
aligning function? How can meta-knowledge about concepts and relations provided by axioms be
exploited for the aligning process, and so on.They proposed Formal Concept Analysis (FCA) (Ganter & Wille, 1999) for merging and maintaining ontologies. FCA offers a comprehensive formalization of concepts by mathematising them as a unit of thought constituting of two parts: its extension (the set of instances of a concept) and its intension (the meaning of the concept). Formal Concept Analysis starts with a formal context defined as a triplet K := (G, M, I), where G is a set of objects, M is a set of attributes, and I is a binary relations between G and M. The interested reader can refer to Ganter & Wille (1999) for a more detailed account of this technique.Stumme and Maedche (2001) worked out this technique for ontology merging to create a method called FCA-Merge. FCA-Merge follows a bottom-up approach to ontology merging, which means it is based on application-specific instances of the two ontologies that are to be merged. A set of documents, relevant to both ontologies, are provided as input. Natural language processing techniques are employed to extract instances from the set of natural language documents for both ontologies. A lattice of concepts is generated, explored and interactively transformed to the merged ontology.FCA-Merge takes as an input two ontologies O1 and O2, which are to be merged, and a set of domain-specific documents D that contain instances of both ontologies. The FCA-Merge method (Figure 5, taken from (Stumme and Maedche, 2001)) consists of three steps:
1. Linguistic Analysis and Context generation. Instances for both source ontologies are extracted from the set of source documents using linguistic analysis. The final result of the step consists of the two formal contexts K1 and K2, which indicate which concepts in the respective source ontologies appear in which documents.
2. Generating the Pruned Concept Lattice. The two formal contexts K1 and K2 are taken as input and a pruned concept lattice is returned as the output of this step. First, the two contexts are merged into one formal context. Then the pruned concept lattice is computed using the TITANIC algorithm, assuring that concepts are not more specific than the concepts in the source ontologies.
Generating the merged ontology. The pruned concept lattice is taken as an input; the result of this step is the merged ontology. While the previous steps were all fully automatic, this step requires human interaction. Based on the pruned concept lattice and the sets or relations in the source ontologies, the user creates the concepts and relations for the merged ontology.
Figure 5: The FCA-Merge Method
D1.4 v2.0 Ontology Alignment Solution 11
Esperonto Services IST-2001-34373
SummaryFCA-Merge uses instances of ontologies contained in Natural Language text in order to find relationships between two ontologies. FCA-Merge is geared towards ontology merging (i.e. creating a new ontology based on two source ontologies, while not maintaining the sources), but the same method could be used in order to find relationships between concepts in the ontologies in order to enable ontology mapping.
Applicability and reusability
URL: Not available.
No downloadable software implementing AIFB’s Formal Concept Analysis and FCA-Merge is found to be available. However, the bottom up approach of ontology merging corresponds to the idea of the Esperonto project to a large extent. An Esperonto partner (Saarbrucken University), supporting upgrade of language sources to ontology-based environments in FCA-Merge, is involved in Esperonto where similar techniques are practiced.
2.4 KRAFT’s Ontology ClusteringDescriptionThe KRAFT architecture (Visser et al., 1999) is an agent-middleware architecture that proposes a set of mapping types to map ontologies:
Class mapping. Maps a source ontology class name to a target ontology class name. Attribute mapping. Maps the set of values of a source ontology attribute to a set of
values of a target ontology attribute; or maps a source ontology attribute name to a target ontology attribute name.
Relation mapping. Maps a source ontology relation name to a target ontology relation name.
The KRAFT architecture (Figure 6; Preece et al., 2001) has three types of agents: Wrappers translate the heterogeneous protocols, schemas and ontologies into the
KRAFT application internal ’standards’. A wrapper agent effectively contains a one-to-one mapping between the source schema and the internal ontology.
Facilitators look up services (provided by mediators and wrappers) requested by other agents.
Mediators are the KRAFT-internal problem-solvers. They provide the querying, reasoning, and information gathering from the available resources. Mediators contain the mappings between the different ontologies present at the wrappers and perform the translations between them.
D1.4 v2.0 Ontology Alignment Solution 12
Esperonto Services IST-2001-34373
Figure 6: Conceptual view of the KRAFT architecture
The mediation between two agents in terms of matching service requesters with services providers is realized by a facilitator. It will recommend an agent that appears to provide that service. The facilitator provides a routing service by trying to match the requested service to the advertised knowledge-processing capabilities of agents with which it is acquainted. When a match is located, the facilitator informs the service-requesting agent of the identity, network location, and advertised knowledge-processing capabilities of the service provider. The service-requesting agent and service-providing agent can now communicate directly.KRAFT defines a shared ontology in order to overcome the problem of semantic heterogeneity among service requesters and providers. A shared ontology formally defines the terminology of the problem domain. Messages exchanged among agents in a KRAFT network must be expressed using terms that are defined in the shared ontology. Each knowledge source defines a local ontology; a number of semantic mismatches (homonyms and synonyms) will occur between the local ontology and the shared ontology. To overcome these mismatches, an ontology mapping is defined for each knowledge source. An ontology mapping is a partial function that specifies mappings between terms and expressions defined in a source ontology to terms and expressions defined in a target ontology. To enable bidirectional translation between a KRAFT network and a knowledge source, two such ontology mappings must be defined. Visser and Tamma (1999) suggest using the concept of “ontology clustering” instead of a single-shared ontology to provide heterogeneous resources integration. Ontology clusters are based on the similarities between the concepts known to different agents. An ontology cluster is organized in a hierarchical fashion, with the application ontology as the root node. The application ontology is used to describe the specific domain, which means it is not reusable. The application ontology contains a subset of WordNet5 concepts relevant for the domain. Every agent has a mapping of its local ontology to a cluster in the hierarchy. When some agents share concepts that are not shared by other agents, these new concepts are defined by creating a new ontology cluster. A new ontology cluster is a child ontology that defines certain new concepts using the concepts already contained in its parent ontology. Concepts are described in terms of attributes and inheritance relations, and are hierarchically organized.The three different types of agents have been implemented in a prototype in the network data services area together with an industrial partner (Preece et al., 2001). Besides this big project, several other (small) prototypes have been implemented.
SummaryThe KRAFT project takes an agent-based approach to information integration. Three types of agents work together in order to provide services to the user. Wrappers provide access to data sources, mediators provide query interfaces and reasoning services, and facilitators enable the look-up of the former two.Originally, KRAFT used a single-shared ontology in order to enable integration of local ontologies in the overall architecture. Later on, Visser and Tamma (1999) suggested the use of ontology clustering for this purpose. The advantage of the use of ontology clustering is the distinction of abstract and refined ontologies; these more abstract ontologies enable the mapping between the more refined ontologies.
The KRAFT project runtime was May 1996 - Aug 1999. No downloadable software of KRAFT is found to be available. Taking into account the time of the project execution and its database orientation, we assume that the KRAFT software in case of its availability would likely not suit the requirements to a large extent.
2.5 ChimaeraDescriptionChimæra (McGuinness et al., 2000) is an ontology merging and diagnostic tool developed by the Stanford University Knowledge Systems Laboratory (KSL).McGuinness et al. (2000) distinguish two major tasks in the merging of ontologies, namely (1) to coalesce equivalent terms from the source ontologies so that they are referred to by the same name in the target ontology and (2) to identify related terms in the source ontologies and identify the type of relationship (e.g. subsumption and disjointness). Chimæra supports the merging task by generating two resolution lists, a name resolution list and a taxonomy resolution list. The name resolution list (Figure 7) contains terms from different ontologies that are candidates for merging or that have taxonomic relationships that have not yet been identified. Chimæra finds these suggestions based on the names of the terms, the presentation names, the definition of terms, etc. The taxonomy resolution list suggests areas in the taxonomy that are candidates for reorganization. It finds such edit points by looking for classes that have direct subclasses from more than one ontology.The name and taxonomy resolution lists correspond to two modes of operation in the Chimæra tool6. In the name mode, similar classes are presented that are candidates for merging. In the taxonomy mode, areas of the merged taxonomy are presented that might contain conflict, such as subclasses that came from different source ontologies. Besides these two modes, there is also the slot traversal mode that guides the user through the classes that have slots that came from multiple different source ontologies and might need editing.
Figure 7: The Chimæra tool in name resolution list modeBesides the merging of ontologies, Chimæra also supports a number of diagnostic tasks, like completeness checking, syntactic analysis, taxonomic analysis, and semantic evaluation.The Chimæra tool has been implemented as a web application, which is available at the Chimæra’s web site7. The tool has been built on top of the OntoLingua8 distributed collaborative ontology engineering environment, although ontologies developed in any OKBC-compliant (Chaudhri et al., 1998) application could be used in Chimæra. The editing functionality in Chimæra is restricted. Currently, editing and merging support is only available for classes and
6 More information about the specifics of the Chimaera tool can be found at http://www-ksl-svc.stanford.edu:5915/doc/chimaera/chimaera-docs.html7 http://www.ksl.stanford.edu/software/chimaera/8 http://www.ksl.stanford.edu/software/ontolingua/
D1.4 v2.0 Ontology Alignment Solution 14
Esperonto Services IST-2001-34373
slots, but there are plans to include support for the merging of facets, relations, functions, individuals, and arbitrary axioms.
SummaryChimæra (McGuinness et al., 2000) is a browser-based editing, merging, and diagnosis tool. For the merging of ontologies, the system employs similarity matching between names of classes and properties in the original ontologies. Based on these similarities, the system presents a name resolution list suggesting terms that are candidates to be merged. Chimæra also employs heuristics to identify areas in the taxonomy that are candidates for reorganization and presents them in a taxonomy resolution list.
No downloadable software of Сhimaera is found to be available. The online demonstration failed to work when it was accessed (end of October, 2004).
2.6 PROMPTDescriptionNoy & Musen (1999) developed SMART, which is an algorithm that provides a semi-automatic approach to ontology merging and alignment. SMART assists the ontology engineer by prompting to-do lists as well as performing consistency checks. SMART forms the basis for PROMPT (Noy & Musen, 2000a), which is an algorithm for ontology merging and alignment that is able to handle ontologies specified in OKBC compatible format. It starts with the identification of matching class names. Based on this initial step an iterative process is carried out for performing automatic updates, finding resulting conflicts, and making suggestions to remove these conflicts. PROMPT is implemented as an extension to the Protégé 2000 knowledge acquisition tool and offers a collection of operations for merging classes and related slots.The PROMPT algorithm consists of a number of steps. First, it identifies potential merging candidates based on class-name similarities and presents this list to the user. Then, the user picks an action from the list. The system performs the requested action and automatically executes additional changes derived from the action. It then makes a new list of suggested actions for the user based on the new structure of the ontology, determines conflicts introduced by the last action, finds possible solutions to these conflicts and displays these to the user. At Figure 8, an initial to do list with merge operations is shown. The user has selected one of the operations and PROMPT provides the reason for the suggestion (‘frame names are synonyms’).
Figure 8: An example of Ontology Merging in PROMPT
PROMPT uses a measure of linguistic similarity among concept names to solve terms matching. In the first implementation of the algorithm linguistic-similarity matches were used for the initial comparison, now it concentrates on finding clues based on the structure of the ontology and the user’s actions. PROMPT identifies a set of knowledge-base operations (merge classes, merge slots, merge bindings between a slot and a class, etc…) for ontology merging or alignment; for each operation in this set, PROMT defines (1) changes performed automatically, (2) new suggestions presented to the user, and (3) conflicts that the operation may introduce and that the user needs to resolve. When the user invokes an operation, PROMPT creates members of these three sets based on the arguments to the specific invocation of the operation. Among the conflicts that may appear in the merged ontology as the result of these operations are counted:
name conflicts (more than one frame with the same name), dangling references (a frame refers to another frame that does not exist), redundancy in the class hierarchy (more than one path from a class to a parent other
than root), slot-value restrictions that violate class inheritance.
Both the list of operations and conflicts grow during the process of merging as more experience is gained.The PROMPT algorithm has been implemented as an extension to the Protégé-2000 tool and as such can take advantage of all the ontology engineering capabilities of the tool. The tool supports import and export of ontologies in several ontology languages as well as database schemas using the appropriate JDBC connection, and therefore allows merging of both ontologies and data schemas. The plug-in architecture of Protégé allows for the inclusion of different other schemas sources. Examples of plug-ins available for storage are OWL, DAML+OIL, XML Schemas, and RDF(S).The creators of PROMPT have created an algorithm, called Anchor-PROMPT (Noy & Musen, 2000b), that enhances the detection of matching terms using non-local context. Whereas PROMPT takes only local structural similarities between terms into account, Anchor-PROMPT uses paths of a greater length in order to determine similarities. The input of the algorithm consists of a number of anchors, which are pairs of matching terms in the source ontologies.
D1.4 v2.0 Ontology Alignment Solution 16
Esperonto Services IST-2001-34373
Anchor-PROMPT now takes these anchors to produce a new set of semantically close terms. It does this by comparing paths between the anchors in both ontologies. A graph is constructed with the classes as nodes and the slots as edges and a path consists of a number of edges in a graph. The Anchor-PROMPT algorithm can be used in the context of any ontology merging or aligning method and is not specific to PROMPT.Noy and Musen suggest in (Noy & Musen, 2003) that several strategies developed for the comparison of ontology versions can also be used for finding similarities across different ontologies. While ontology versioning is concerned with finding differences between versions of an ontology, ontology aligning is concerned with its complement, namely finding similarities between different ontologies. This leads to the possibility of reuse of several matchers developed for PromptDiff (Noy & Musen, 2003) in the area of ontology merging and aligning.
SummaryPROMPT uses a semi-automatic approach to the merge process. It uses linguistic similarities to determine possible candidates for merging and presents these choices to the user. Conflicts arising during merging (e.g. merged concepts that refer to concepts in one of the original ontologies) are detected and presented to the user along with possible solutions to the problem. During tests done with PROMPT it turned out that in the merging of ontologies in a particular test case about 74% of all operations executed had been proposed by the system (Noy and Musen, 2000). By applying Anchor-PROMPT and concepts from PromptDiff it might be possible to get an even higher quality of suggestions from the system.
The PROMPT tool is supported and under development. Currently, the latest version is 2.1.3 from July 23, 2004. The tool is written in Java, open source (Mozilla Public License), and downloadable from the project web-site. PROMPT supports processing ontologies in the currently popular languages (such as OWL and RDFS) as it is backed up with Protégé support. The major obstacle in reusability of the PROMPT’s development arises also from the Protégé back up: being developed as a Protégé plugin, the source code needs additional tailoring to be adapted to other contexts.
2.7 OBSERVERDescriptionLehmann & Cohn (1994) require that concept definitions of the ontologies include more specialized definitions for typical instances, and assume that the set relation between any two definitions can be identified as equivalence, containment, overlap or disjointness. OBSERVER (Ontology Based System Enhanced with Relationships for Vocabulary hEtereogenity Resolution) (Mena, et al., 2000) combines intentional and extensional analysis to calculate lower and upper bounds for the precision and recall of queries that are translated across ontologies on the basis of manually identified subsumption relations.OBSERVER uses a component-based approach to ontology mapping. It provides brokering capabilities across domain ontologies to enhance distributed ontology querying, thus avoiding the need to have a global schema or collection of concepts.OBSERVER uses multiple pre-existing ontologies to access heterogeneous, distributed and independently developed data repositories. Each repository is described by means of one or more ontology expressed in Description Logics (DL). The information requested from OBSERVER is expressed according to the user’s domain ontology, also expressed using DL. DL allows matching the query with the available relevant data repositories, as well as translating it to the languages used in the local repositories.
The system contains a number of component nodes, one of which is the user node. Each node has an ontology server that provides definitions for the terms in the ontology and retrieves data underlying the ontology in the component node. If the user wants to expand its query over different ontology servers, the original query needs to be translated from the vocabulary of the user’s ontology into the vocabulary of another’s component ontology. Such translation can not always be exact, since not all the abstractions represented in the user ontology may appear in the component ontology. If this is the case the user can define a limit in the amount of Loss of Information. Anyhow, the user can always set this parameter to 0, thereby specifying no loss at all. An Inter-ontology Relationship Manager (IRM) provides the translations between the terms among the different component ontologies. The IRM effectively contains a one-to-one mapping between every pair of component nodes. This module is able to deal with Synonym, Hyponym, Hypernym, Overlap, Disjoint and Covering inter-ontology relationships. The user submits a query to the query processor in its own component node (in fact, each component node has a query processor). The query processor uses the IRM to translate the query into terms used by the other component ontologies and retrieves the results from the ontology servers.
Figure 9: The general OBSERVER architectureThe OBSERVER architecture, depicted in Figure 9 (taken from (Mena et al., 2000)), consists of a number of component nodes and the IRM node. A component node contains an Ontology Server that provides for the interaction with the ontologies and the data sources. It uses a repository of mappings to relate the ontologies and the data sources and to be able to translate queries on the ontology to queries on the underlying data sources. The architecture contains one Inter-Ontology Relationship Manager (IRM), which enables semantic inter-operation between the of component nodes by maintaining the relationships between the ontologies
SummaryOBSERVER is an architecture consisting of component nodes, each of which has its own ontology, and the Inter-ontology Relationship Manager (IRM), which maintains mappings between the ontologies at the different component nodes. Besides the ontology, each component node contains a number of data repositories along with mappings to the ontology, to enable semantic querying of data residing in these repositories. When other components need to be queried, the IRM provides mappings to ontologies of other component nodes in order to enable querying.This can be seen as a combination of one-to-one ontology mapping (the IRM contains one-to-one mappings between all ontologies) and a single-shared ontology. The latter is the case,
D1.4 v2.0 Ontology Alignment Solution 18
Esperonto Services IST-2001-34373
because mappings between the ontologies are maintained at a central location, the IRM. The IRM can now actually be seen as maintaining a virtual central ontology, along with mappings to all local source ontologies.
Applicability and reusability
URL: http://sid.cps.unizar.es/OBSERVER/
No downloadable software implementing OBSERVER is found to be available. The OBSERVER tool is described as being able to extract information from the sources represented as HTML files, XML files and in relational databases. However, the latest ontology formalisms are not supported, and the tool have not been developed and promoted for at least one year.
2.8 OntoMergeDescription
Dou et al., 2002, introduce an approach to ontology mediation “ontology translation be ontology merging and automated reasoning”. In this approach, ontologies are merged by taking the union of both ontologies, where all terms are separated through the differences in the namespace. So-called Bridging Axioms are used to connect the overlapping part of the two ontologies.In general, when merging ontologies, one would either create a new namespace for the merged ontology or import one ontology into the other, so that the merged ontology uses the namespace of the importing ontology. Having in the end an ontology which uses different namespaces in its definitions can be very confusing for the user, since an ontology is intended to be shared among multiple parties. Furthermore, the bridging axioms in the merged ontology might also be very confusing for the user, since they serve no other purpose than linking together related terms in the ontology. Thus, the merged ontology contains a lot of clutter, which makes the ontology hard to understand and hard to use. The clutter in the ontology consists of: (1) terms with different namespaces, (2) similar and equivalent terms exist in the ontology and (3) bridging axioms between the related terms. These three factors impede usability and especially sharing of the ontology.On the other hand, Dou et al., 2002, does not propose to use the merged ontologies as such, but to merely use them for three different tasks:1. Dataset translation (cf. instance transformation by de Bruijn and Polleres, 2004). Dataset translation is the problem of translating a set of data (instances) from one representation to the other.2. Ontology extension generation. The problem of ontology extension generation is the problem of generating an extension O2s, given two related ontologies O1 and O2 and an extension (subontology) O1s of ontology O1. The example given by the authors is to generate a WSDL extension based on an OWL-S description of the corresponding Web Service.3. Querying different ontologies. This relates very much to the query rewriting described by de Bruijn and Polleres, 2004. However, query rewriting is a technique for solving the problem of querying different ontologies, whereas Dou et al., 2002 merely stipulate the problem.As we have also suggested by de Bruijn and Polleres, 2004, and Dou et al., 2002, uses mappings between ontologies in order to enable the translation. In fact, the ontology translation (except for the extension generation) can be seen as run-time mediation de Bruijn and Polleres, 2004.Dou et al. use an internal representation for the ontologies, called Web-PDDL, which is a typed first-order logic language. They support im- and export of DAML+OIL and OWL, but im- and exporters for other languages could be written as well, because Web- PDDL is able to capture many different ontology languages, because of its expressiveness.Dataset translation Dou et al. perform dataset translation in two distinct steps. First, given the source dataset (a set of facts) and the merged ontology, all possible inferences are drawn from the source facts. Secondly, the results are projected on the target vocabulary, retaining only the results expressed in terms of the target ontology. These two steps guarantee that a maximal
translation is performed, with respect to the merged ontology and the source dataset. In their practical evaluation of the system, the authors only work with very small datasets consisting of several thousands of facts. The fact that they use a theorem prover leaves open questions about scalability for large numbers of facts.Ontology extension generation For example, there are two related ontologies O1 and O2 and a subontology O1s of O1. Using the relationships between the two ontologies, it is possible to automatically generate a subontology O2s of O2 which corresponds with O1s.The subontology O2s is identified by creating skolem constants during inference with the merged ontology and then creating predicates based on these skolem constants. The new predicates should be made sub-predicates of the existing predicates, in which the skolem constant is.The major disadvantage to this approach for ontology extension generation, identified by the authors, is that the generated subontology only contains subproperty axioms, whereas many subontologies might be specified using general axioms.Querying through Different Ontologies Querying is done in OntoMerge by selecting the merged ontology which merges the query ontology and the other ontology. They, a query selection and reformulation module (not described in detail) is used to select subqueries and reformulate the subqueries. Each subquery is executed on respective knowledge bases and the results are combined.In fact, what we call an Ontology mapping is very similar to a set of bridging axioms by Dou et al., 2002. However, we do not presume the source and target ontologies use the same language as the mapping, whereas Dou et al., 2002, require the merged ontology to consist of the source and target ontologies and the bridging axioms.A major drawback of OntoMerge is that bridging axioms need to be written using a first-order language. Only very few people are familiar with the first-order logic.
Summary
The idea behind OntoMerge is that ontology translation is best thought of in terms of ontology merging. Ontology as a formal specification of a vocabulary of concepts is defined, including axioms relating these concepts. The merge of two ontologies is obtained by taking the union of the axioms defining them, using XML namespaces to avoid name clashes. The bridging axioms that relate the terms in one ontology to the terms in the other are added. Inferences can be conducted in this merged ontology in either a demand-driven (backward-chaining) or data-driven (forward chaining) way. OntoMerge serves as a semi-automated nexus for agents and humans to find ways of coping with notational differences between ontologies with overlapping subject areas. OntoMerge is developed on top of PDDAML (PDDL-DAML Translator) and OntoEngine (inference engine). These are built using some code from other people's programs, such as Jena (from HP Research) and JTP (from SRI/KSL).
MoA is an OWL ontology merging and alignment library and tool. MoA is a representative name for the following two components. MoA is developed in Java (J2SE 1.4.1), thus a J2SE (1.4 or later) runtime is required to run MoA.
ComponentsMoA consists of basic two componets.
MoA core: basic libraries for add, remove, merge and align operations on ontology model, and similarity comparison between two concepts.
MoA shell: A simple shell to run MoA core algorithm.
MoA usageMoA can be used as a helping tool for an ontology editor, since its conflict comparison algorithm uses linguistic information of classes, properties and individuals. By using MoA, one can load requested ontologies of the same domain and for instance merge them into a single ontology, remove conflicts from that ontology, and then proceed with doing further editing with an ontology editor. The architecture and application environment of MoA is depicted at Figure10.
Figure 10: MoA Usage Diagram
Applicability and reusability
URL: http://mknows.etri.re.kr/moa/
The application is available for download and testing, however only binaries are available, i.e., the application is not open source. The copyright is owned by ETRI (Electronics and Telecommunications Research Institute), Korea. Another disadvantage of the software is its meagre documentation: we consider the current documentation following the software to be insufficient for a full-fledged usage of the system. For example, the parameters in alignment algorithm can not be adjusted by the user, because a description for the meaning of these parameters is missing.
DescriptionMAFRA (MApping FRAmework for distributed ontologies) (Maedche et al., 2002, Silva and Rocha, 2003) is a framework defined for mapping distributed ontologies on the SemanticWeb. In its core, MAFRA is based on the idea that complex mappings and reasoning about those mappings is an appropriate approach in a decentralized environment like the Web.
MAFRA methodology has two main characteristic traits: Semantic Bridges and service-centric approaches. Semantic bridge is defined as “a declarative representation of a semantic relation between source and target ontologies entities” (Silva and Rocha, 2003). A Semantic bridge provides the necessary mechanisms to transform instances and property fillers of a particular source ontology into instances and property fillers of a particular target ontology. The service oriented approach complements the semantic bridges mechanism providing the transformation services necessary to perform the mapping transformations. Thus, MAFRA supports a decentralized solution where independent transformation modules are attached to the system.
The main goal in MAFRA is to transform instances of the source ontology into instances of the target ontology. Semantic Bridges specify how to perform these transformations and categorize them between concept bridges and property bridges. Concept bridges define the transformations between source instances and target instances, whereas property bridges specify the transformations between source properties and target properties. The Semantic Bridge phase defines in the following steps the necessary structures to describe the mapping between two ontologies:1. Based on the analysis of similarities that were discovered in the Similarity phase, the first step is to select the pairs of entities, which could be concepts, relations and attributes, to be bridged that correspond with concept bridges. MAFRA allows relations of different cardinality between source and target entities. Thus, a source or target entity can belong to one or more semantic bridges.2. The property bridging step specifies matching properties for each concept bridge. The authors of MAFRA distinguish two types of properties: attributes and relations. In the case that the type of source and target properties is different the transformation specification information is required, and the domain expert is asked to supply this information. Note that an attribute defines a relation between a concept and a data type value and a relation defines a relation between two concepts.3. This step (together with the next one) is part of a refinement process to improve the matching results, and focuses on looking for mapping alternatives where there is no target entities. If it is not possible to find a target entity for a source entity, the algorithm analyzes the hierarchy of the source ontology and proposes an equivalent mapping of some of the parents of the unmapped source entity. So the source entity is mapped to the same target entities as some of its parents.4. As a part of the refinement process mentioned previously, in this step the system tries to improve the quality of bridges between source sub/concepts and target concepts. It can be viewed as a complementary routine to the similarity phase.5. Associate transformation procedures with the mapping relations identified in previous phases. Although one of the main goals of the authors of MAFRA is to provide an elevated level of automation in the mapping procedure, they recognize that in this step the intervention of an expert is highly recommended.
Summary
MAFRA is a framework for ontology mapping targeted at mapping distributed ontologies on the Semantic Web and reasoning over these mapping. Technically, MAFRA module is a plugin for KAON9. Conceptually, the MAFRA methodology is based on Semantic bridging and service-centric approach for mapping transformations.
9 KAON: http://kaon.semanticweb.org
D1.4 v2.0 Ontology Alignment Solution 22
Esperonto Services IST-2001-34373
Applicability and reusability
URL: http://mafra-toolkit.sourceforge.net
The tool is open-source and implemented in Java. From the architecture point of view, MAFRA is a plugin for KAON. At the moment, the tool is not supported by its main developers (Nuno Silva, private communication). The ontology alignment module reuse is hindered by absence of up-to-date Java documentation and the module’s tight integration with KAON and GUI.
2.11 INRIA Ontology Alignment APIDescription
The problem which INRIA API (Euzenat, 2004) aims to resolve is provision of a design of an alignment format which is general enough for covering most of the needs (in terms of languages and alignment output) and developed enough for offering the adding value services. An alignment format and an application programming interface (API) for manipulating alignments are being developed.
As described by Euzenat, 2004, in first approximation, an alignment is a set of pairs of elements from each ontology. However, as already pointed out in (Noy and Musen, 2002), this first definition does not cover all needs and all alignments generated. So the alignment format is provided on several levels, which depend on more elaborate alignment definitions.
AlignmentThe alignment description is stated as follows:a level used for characterizing the type of correspondence (see below);a set of correspondences which express the relation holding between entities of the first ontology and entities of the second ontology. This is considered in the following subsections;an arity (default 1:1) Usual notations are 1:1, 1:m, n:1 or n:m. We prefer to note if the mapping is injective, surjective and total or partial on both side. We then end up with more alignment arities (noted with, 1 for injective and total, ? for injective, + for total and * for none and each sign concerning one mapping and its converse): ?:?, ?:1, 1:?, 1:1, ?:+, +:?, 1:+, +:1, +:+, ?:*, *:?, 1:*, *:1, +:*, *:+, *:*. These assertions could be provided as input (or constraint) for the alignment algorithm or as a result by the same algorithm.
Level 0The very basic definition of a correspondence is the one of a pair of discrete entities in the language. This first level of alignment has the advantage not to depend on a particular language. Its definition is roughly the following:entity1 the first aligned entity. It is identified by an URI and corresponds to somediscrete entity of the representation language.entity2 the second aligned entity with the same constraint as entity1.relation (default "=") the relation holding between the two entities. It is not restricted to the equivalence relation, but can be more sophisticated operators (e.g., subsumption, incompatibility (Giunchiglia and Shvaiko, 2003), or even some fuzzy relation).strength (default 1.) denotes the confidence held in this correspondence. Since many alignment methods compute a strength of the relation between entities, this strength can be provided as a normalized measure. This measure is by no mean characterizing the relationship (e.g., as a fuzzy relation which should be expressed in the relation attribute), but reflects the confidence of the alignment provider in the relation holding between the entities. Currently, we restrict this value to be a float value between 0. and 1.. If found useful, this could be generalized into any lattice domain.id an identifier for the correspondence.
A simple pair can be characterised by the default relation "=" and the default strength "1.". These default values lead to consider the alignment as a simple set of pairs. On this level, the aligned entities may be classes, properties or individuals. But they also can be any kind of complex term that is used by the target language. For instance, it can use the concatenation of firstname and lastname considered in [Rahm and Bernstein, 2001] if this is an entity, or it can use a path algebra like in: hasSoftCopy.softCopyURI = hasURL However, in the format described above and for the purpose of storing it in some RDF format, it is required that these entities (here, the paths) are discrete and identifiable by a URI.Level 0 alignments are basic but found everywhere: there are no algorithm that cannot account for such alignments. It is, however, somewhat limited: there are other aspects of alignments that can be added to this first approximation.
Level 1Level 1 replaces pairs of entities by pairs of sets (or lists) of entities. A level 1 correspondence is thus a slight refinement of level 0, which fills the gap between level 0 and level 2. However, it can be easily parsed and is still language independent.
Level 2 (L)Level 2 considers sets of expressions of a particular language (L) with variables in these expressions. At this level, the kind of rules (or restrictions) which are commonly used in logic-based languages or in the database world for defining the views in “global-as-view” of “local-as-view”approaches (Calvanese et al., 2002) can be expressed.
The API allows to plug in different algorithms for supporting ontology alignment process. The algorithms that can be currently triggered via the alignment API are as follows:NameEqAlignment Simply compares the equality of class and property names (once downcased) and align those objects with the same name;EditDistNameAlignment Uses an editing (or Levenstein) distance between (downcased) entity names. It thus has to build a distance matrix and to choose the alignment from the distance;SubsDistNameAlignment Computes a substring distance on the (downcased) entity name;StrucSubsDistNameAlignment Computes a substring distance on the (downcased) entity names and uses and aggregates this distance with the symmetric difference of properties in classes.
SummaryIn order to exchange and evaluate results of alignment algorithms, an alignment format was provided. A Java API has been proposed for this format and a default implementation created. The possibility of integration of new alignment algorithms, composing algorithms, generating transformations and axioms and comparing alignments was considered and supported. The INRIA API and its implementation could fairly easily be adapted to other representation languages than OWL.
Applicability and reusability
URL: http://co4.inrialpes.fr/align
The API is open-source and implemented in Java. All source code is available at the URL above. Currently, the research and development of the API is partially driven in the KnowledgeWeb NoE10 which promises its further evolution. The API module is easy to understand, install and use, and there is a javadoc documentation available.
For reference purposes, we include in this section some other methods that can be employed for ontology mapping and aligning. These methods will not be investigated further.
Heuristic rulesHovy, E. (1998) described several heuristics rules to support the merging of ontologies. For instance, the NAME heuristic compares the names of two concepts, the DEFINITION heuristics uses linguistic techniques for comparing the natural language definitions of two concepts, and the TAXONOMY heuristic checks the closeness of two concepts to each other.
Neural network and semantic distanceLi (Li, 1995) identifies similarities between attributes from two schemas using neural networks. Campbell and Shapiro (1995) described an agent that mediates between agents that subscribe to different ontologies. Bright et, al. (1994) use a thesaurus and a measure of “semantic-distance” based on path distance to merge ontologies. Kashyap and Sheth (1996) define the “semantic proximity” of two concepts as a tuple encompassing contexts, value domains and mappings, and database states. The resulting analysis yields a hierarchy of types of semantic proximity, including equivalence, relationship, relevance, resemblance, and incompatibility.
Description compatibilityWeinstein & Birmingham (1999) compared concepts in differentiated ontologies, which inherit definitional structure from concepts in shared ontologies. Shared, inherited structure provides a common ground that supports measures of "description compatibility." They use description compatibility to compare ontology structures represented as graphs and identify similarities for mapping between elements of the graphs. The relations they find between concepts are based on the assumption that local concepts inherit from concepts that are shared. Their system was evaluated by generating description logic ontologies in artificial words.
Global Reference OntologyUschold (2000) pointed out the global reference ontology will be the perfect candidate for the ontology mapping of the local ontologies. Different user communities can view the global reference ontology from their own preferred perspectives through mapping and projecting. The basic idea is to define a set of mapping rules to form a perspective for viewing and interacting with the ontology. Different sets of mapping rules enable the ontology, or a portion of it to be viewed from three different perspectives: viewing the global ontology using own local terminologies; viewing a selected portion of the ontology; and viewing at a higher level of abstraction.
An instance-based approachWilliams and Tsatsoulis (2000) proposed an instance-based approach for identifying candidate relations between diverse ontologies using concept cluster integration. They discussed how their agents represent, learn, share, and interpret concepts using ontologies constructed from Web page bookmark hierarchies. The concept vector represents a specific Web page and the actual semantic concept is represented by a group of concept vectors judged to be similar by the user (according to the meaning of the bookmark). The agents use supervised inductive learning to learn their individual ontologies. The output of this ontology learning is semantic concept descriptions (SCD) represented as interpretation rules. They built up one system to fulfil this purpose called DOGGIE, which could apply the concept cluster algorithm (CCI) to look for candidate relations between ontologies. The experimental results have demonstrated the feasibility of the instance-based approach for discovering candidate relations between ontologies using concept cluster integration. However, here they assume all the relations are
D1.4 v2.0 Ontology Alignment Solution 25
Esperonto Services IST-2001-34373
only general is-a relations. This method could be very useful for ontology mapping and aligning.
OntoMorphThe ISI’s OntoMorph system aims to facilitate ontology merging and the rapid generation of knowledge base translators (Chalupsky, 2000). It combines two powerful mechanisms to describe KB transformations. The first of these mechanisms is syntactic rewriting via pattern-directed rewrite rules that allow the concise specification of sentence-level transformations based on pattern matching, and the second mechanism involves semantic rewriting which modulates syntactic rewriting via semantic models and logical inference. The integration of ontologies can be based on any mixture of syntactic and semantic criteria.In syntactic rewriting process, input expressions are first tokenized into lexemes and then represented as syntax trees, which are represented internally as flat sequences of tokens and their structure only exists logically. OntoMorph’s pattern language and execution model is strongly influenced by Plisp (Smith, 1990). The pattern language can match and de-structure arbitrarily nested syntax trees in a direct and concise fashion. Rewrite rules are applied to the execution model. For the semantic rewriting process, OntoMorph is built on top of the PowerLoom11 knowledge representation system, which is a successor to the Loom system. Using semantic import rules, the precise image of the source KB semantics can be established within PowerLoom (limited only by the expressiveness of first-order logic).
ODEMergeODEMerge (Gómez-Pérez, 2002) is a tool for merging ontologies, integrated in the WebODE ontology engineering environment. The tool takes as input the source ontologies O1 and O2, a table of synonyms, which contains the synonyms of terms in O1 and O2, and a table of hyperonyms, which contains the hyperonymy relations between the terms in O1 and O2. ODEMerge now compares O1 and O2 using the tables of synonyms and hyperonyms to automatically create the merged ontology. The tool might benefit from user interaction, so as to enable interactive merging of ontologies, because syntactic resemblance of terms does not imply semantic resemblance (e.g., even if terms are synonymous, this does not imply that the have the same intended meaning).
2.13 SummaryFrom the survey of existing methodologies and tools, it became evident that matching process and its success depend on the inputs of human experts to a large extent. Although some tools are available to facilitate the mapping, the limited functions they could provide are class or relation name checking, consistency checking, to-do list recommendation, etc. Generally, ontology mapping is not a simple one-to-one mapping (linking the class name, relation name, attribute name from one ontology to another) but on the contrary, demands substantial deeper checking and verification for inheritance, consistency of the inference, etc. Furthermore, ontology mapping can be enhanced by many-to-one, one-to-many or many-to-many relations either within one domain or one that transcends across different domains. Ontology mapping could also be viewed as the projection of the general ontologies from different point of views, either according to the different application domains or various tasks or applications (Uschold, 2000).
The survey on tools and methodologies revealed that though a relatively large number of ontology alignment methodologies were elaborated, however only a few of them were supported by implementations that are available for download and reuse. In addition to unavailability of the downloadable version of the implementation, in certain cases even the links
11 http://www.isi.edu/isd/LOOM/PowerLoom/
D1.4 v2.0 Ontology Alignment Solution 26
Esperonto Services IST-2001-34373
for online demonstrations were broken. We had an opportunity to try only 4 tools that support 4 of the 11 reviewed methodologies (PROMPT, MoA, MAFRA and INRIA API). The summary resulting from the survey of the four tools that we could access is presented in Table 1. We conclude that PROMPT and INRIA API correspond to our vision of a perfect ontology alignment tool most of all, but due PROMPT’s dependency on Protégé (i.e., using PROMPT outside of Protégé is difficult), INRIA API was chosen to serve as a basis of an ontology alignment solution in the project.
We have hereby concluded our survey of existing ontology alignment methods and tools. We use the results of this survey in the next section, where we define a solution for ontology alignment in the Esperonto project.
D1.4 v2.0 Ontology Alignment Solution 27
Esperonto Services IST-2001-34373
3 Requirements for Ontology Alignment Solution
In this section, we identify problems of ontology alignment and requirements for the ontology alignment solution from three prospective: formalisms for representing ontology alignment results, functionality that is to be provided by a tool to the final user, and general integration requirements for the solution.
3.1 Problems of Ontology Alignment The use of several online ontologies is problematic because you have to overcome heterogeneity. Problems can occur at different levels. In this section we list mismatches which were identified in literature.
Mismatches by Hameed et.al.
Hameed et.al. (2004) talk about ontology reconciliation in a multiple-ontology world. They mention three levels on which it happens: inter-personal, intra-organizational and interorganisational. The bottom up approach is bidirectional mapping.
Mismatches can occur at conceptual, terminological, definitional and purely syntactic levels. They explained them in more detail.
Conceptual mismatches
These may arise between two or more conceptualisations of a domain. They could differ in the ways shown below.
Class mismatches occur with classes and their subclasses distinguished in the conceptualization
Categorization mismatches occur when two conceptualizations distinguish the same class, but divide this class into a different subclass
Aggregation-level mismatches occur if both conceptualizations recognize the existence of a class, but define classes at different levels of abstraction.
Relation mismatches are associated with the relations distinguished in the conceptualization
Structure mismatches occur when two conceptualizations perceive the same set of classes but differ in the way these classes are structured via relations.
Attribute-assignment mismatches occur when two conceptualizations differ in the way they assign an attribute to various classes
Attribute-type mismatches occur when two conceptualizations distinguish the same attribute, but differ in their assumed instantiations
Explication mismatches
These are not defined on the conceptualisation of a domain but on the way they are specified. There are three components of a definition: the term to denote the concept, the definiens to comprise the body of the definition and the underlying concept.
D1.4 v2.0 Ontology Alignment Solution 28
Esperonto Services IST-2001-34373
Concept mismatches occur if the definitions have the same terms and definiens but differ conceptually
Concept & Definiens mismatches occur if the definitions share the same term but have different concepts and definiens
Definiens mismatch occur if the definitions have the same concept and the same term but different definiens.
Term mismatch occur if the definitions share the same concept and the same definiens but use different terms
Concept & Term mismatch occur if the definitions share the same definiens but different concepts and terms
Term & Definiens mismatch occur if the definitions have the same concept but dissimilar terms and definiens
This classification was taken over from Visser. But it was presented in a more clear way with given examples. The process of ontology reconciliation is human-mediated with three possibilities: merging, aligning or integration.They also mention Klein.
Mismatches by Klein
In his paper Klein (2001) gives an analysis of problems and solutions. He tries to classify the mismatches in order to make them comparable. Merging and alignment can cause mismatches between separate ontologies as well as versioning and revisioning. Problems occur at two levels. The first level is the language or meta-model level. The second level is the ontology or model level. At the language level combining ontologies written in different ontology languages can cause mismatches. Four types can be distinguished.
Language level mismatchesSyntaxObviously, different ontology languages often use different syntaxes. For example in RDF Schema one uses < rdfs:Class ID=”Person” >. A typical example of a ’syntax only’ mismatch is on an ontology language that has several syntactical representations.
Logical representationA more complicated mismatch is the difference in representation of logical notions to combine ontologies. For example, in some languages it is possible to state explicitly that two classes are disjoint (e.g., disjoint A B), whereas it is necessary to use negation in subclass statements (e.g., A subclass-of (NOT B), B subclass-of (NOT A) in other languages.
Semantics of primitivesAnother possible difference at the metamodel level is the semantics of language constructs. Despite the fact that sometimes the same name is used for a language construct in two languages, the semantics may differ; e.g., there are several interpretations of A equalTo B. Note that even when two ontologies seem to use the same syntax, the semantics can differ. For example, the OIL RDF Schema syntax (Broekstra et al., 2001) interprets multiple <rdfs:domain> statements as the intersection of the arguments, whereas RDF Schema itself uses union semantics.
Language expressivityThe mismatch with the most impact is the difference in expressivity between two languages. For example, some language have the constructs to express negation, other have not.
Ontology level mismatches
D1.4 v2.0 Ontology Alignment Solution 29
Esperonto Services IST-2001-34373
The first two mismatches at the model level are instances of the conceptualization mismatches (Visser et al., 1997).
ScopeTwo classes seem to represent the same concept, but do not have exactly the same instances, although theses intersect.
Model coverage and granularityThis is a mismatch in the part of the domain that is covered by the ontology, or the level of detail to which the domain is modelled. The other ontology-level mismatches can be categorized as explication mismatches. The first two of them result from explicit choices of the modeler about the style of modeling.
ParadigmDifferent paradigms can be categorized can be used to represent concepts such as time, action, plans, etc. For example one model might use temporal representation based on interval logic while another might use a representation based on point. The use of different ’top-level’ ontology is also an example of this kind of mismatch.
Concept descriptionSeveral choices can be made for the modelling of concepts in an ontology. For example, a distinction between two classes can be modeled using a qualifying attribute or by introducing a separate class. An other way is how the hierarchy is build e.g. thesis < book < scientific publication or thesis < scientific book < publication.
Further, the next two types of differences can be classified as terminological mismatches.
Synonym termsConcepts are represented by different names. A trivial example is the use of the term ’car’ in one ontology and the term ’automobile’ in another ontology. This is a natural language problem and the technical solution seems relatively simple by using a thesaurus. But usually a lot of human effort is required.
Homonym termsThe meaning of terms is different in another context e.g. the term ’conductor’ has a different meaning in a music domain than in an electric engineering domain. Human knowledge is required to solve this ambiguity.
EncodingValues in the ontology may be encoded in different formats, e.g. a date may be represented as ’dd/mm/yyyy’ or as ’mm-dd-yy’, instances are described in miles or kilometres, etc. Klein (2001) focuses ontology mismatches on a detailed level.
3.2 Requirements AnalysisWe consider ontology alignment solution along three dimensions: mapping language, user functionality, and integration of the solution in the outside world (or an open ontology management system). First, requirements for ontology mapping language are identified, second, a tool functionality from the user point of view is described, and third, interoperation and integration requirements are defined. Altogether, these requirements are a staring point to the work towards an ontology alignment solution that can be widely and effectively applied.
D1.4 v2.0 Ontology Alignment Solution 30
Esperonto Services IST-2001-34373
3.2.1 Ontology Mapping Language Requirements
This section presents a number of requirements on the Ontology Mapping Specification Language. Particularly, we identify the following requirements on an Ontology Mapping Specification Language (see also (de Bruijn & Polleres, 2004)):
Mapping on the Semantic Web. Our goal is to develop an ontology mapping language for the Semantic Web. Therefore, we must be able to specify mappings between ontologies on the Web and the ontology mapping itself must also be available on the Web. The current standard for specifying ontologies on the web is the Web Ontology Language OWL (Dean & Schreiber, 2004). We must therefore support mapping between ontologies written in OWL.
Mapping between Description Logic Ontologies. An important species of OWL is OWL DL, which is a syntactical variant of the SHOIN(D) Description Logic language (Horrocks & Patel-Schneider, 2003). Therefore, mappings between OWL ontologies can be reduced to mappings between Description Logic ontologies.
Specify Instance Transformations. It follows from the generic use cases presented in the previous section that the ontology mapping language must support transformations between instances of the different ontologies. In fact, Rahm and Bernstein (2001) define the mapping process as the set of activities required to transform instances of the source ontology into instances of the target ontology. Also MAFRA (Maedche et al., 2002) explicitly addresses the transformation of instances on the basis of a mapping between two ontologies.In instance transformation, we identify two dimensions: structural transformation and value transformation:
A structural transformation is a change in the structure of an instance. This means that an instance might be split into two instances, two instances might be merged into one, properties might be transformed to instances, etc. For example, an instance of the concept PhD-Student in one ontology might need to be split into two instances, one of Student and one of Researcher, in the target ontology. A different example is the use of aggregate functions. An ontology OS might have a concept Parent with a property hasChild, whereas the ontology OT might also have a class Parent, but in this case only with the property \ nrOfChildren. An aggregate function is required to count the number of children of a specific parent in OS in order to come up with a suitable property filler for nrOfChildren.
A value transformation is a simple transformation from one value into another. An example of such a value transformation is the transformation from kilograms into pounds.
An example of a transformation, which requires both a structural and two value transformations is the transformation from a full name to separate first and last names. Splitting the full name instance into both the first and the last name requires structural transformation. After the structural transformation, two value transformations are required; on for the first and one for the last name.
Specify Instance Similarity Conditions. One of the generic use cases presented in section is the instance unification use case. It turned out in this use case that when instances need to be unified, first the similarity between the instances must be established. In order to detect the similarity, one can compare the values of all properties and describe the similarity as a function over all the individual property similarities. The other extreme is to designate one property as
D1.4 v2.0 Ontology Alignment Solution 31
Esperonto Services IST-2001-34373
the identifying property (cf. primary keys in relational databases) and designate instances that have equivalent values for these designated properties as equivalent and unify them12.We shall take a hybrid approach, where it is possible to specify equality of instances as a logical condition over its property values. We call this the exact approach for instance unification. In the second case, the probabilistic approach, it is possible to specify a matching function over the property values, which yields a probability between 0 and 1, specifying the similarity between the instances. When combined with a threshold, this function also becomes a condition for similarity.We are currently not aware of any existing approach which addresses the specification of instance similarity in the same sense we do here.
Query Rewriting and Ontology Merging. The Query Rewriting and Ontology Merging obviates the need for the ontology mapping to not only map instances of the ontologies but to also map concepts and relations in the source and target ontologies. This is necessary for the case when a query written in terms of ontology OS needs to be executed on an instance base, which is described by ontology OT. The mapping needs to specify exactly how concepts and relations in OS relate to concepts in relations in OT in order to enable the rewriting.After execution of the query, the result instances need to be transformed back to OS which involves all requirements for instance transformation described above. The querying use case scenario does, however, indicate the need for a mapping which supports query rewriting in one direction and instance transformation in the other direction.
One mapping for all tasks. It is clearly advantageous to have one common declarative mapping language, which suffices for the different use cases of instance transformation, instance unification, query rewriting and ontology merging.MAFRA (Maedche et al., 2002) combines relating entities (such as concepts and relations) in ontologies with instance transformations. So-called semantic bridges specify the relationship between entities in different ontologies. Each instance of a semantic bridge has a transformation attached to it, which specify the instance transformations. The semantic bridges can be used for query rewriting and ontology merging, whereas the attached transformations can be used for instance transformation.
Use of Mapping patterns. It is our expectation that many similar ontologies will appear on the Semantic Web. When many similar ontologies exist in a specific domain, the mappings between the ontologies will also be similar. In order to capture these similarities and to reuse existing mapping specification we aim to identify recurring mapping patterns. A mapping pattern can be seen as a template for mappings between classes of ontologies, which can be instantiated to create specific mappings between specific ontologies (cf. (Park et al., 1998)).Mapping patterns furthermore reduce the complexity of a mapping for the user and can be used as a way to modularize a mapping.
Versioning support. The ontology mapping language must support constructs for the versioning of the mapping and for referring to specific version of the source and target ontologies.The latter of course depends on the scheme chosen for ontology versioning. In the case of a new name for each new version of the ontology, no additional provisions have to be taken in the mapping language. This is currently the only way to do versioning in the Web Ontology Language OWL. Therefore, we will assume this situation.
Treating classes as instances. Different ontologies might be modeled within slightly different domains with different granularity. What is seen as a class in one ontology might be seen as an instance of a different class in another ontology (Schreiber, 2002).
12 Note that, as with primary keys in relational databases, it is possible to designate several properties as the unique identification for instances
D1.4 v2.0 Ontology Alignment Solution 32
Esperonto Services IST-2001-34373
In order to support inter-operation between two ontologies with such differences, classes need to be mapped to instances and vice versa.In fact this can be seen more general. The mapping language should support the mapping of any entity in the source ontology, whether it is a class, instance, relation, to any entity in the target ontology. For example, it should be possible to have a relation-instance mapping, a class-relation mapping, etc.
Mappings of different cardinalities. It might be necessary to map a class in one ontology to a number of different classes in the other ontology. It might also be necessary to map a class in one ontology to a class and a relation in the other ontology. In other words, the language needs to support mappings of arbitrary cardinalities. One-to-one mappings are not enough.
3.2.2 Ontology Alignment Service Implementation Requirements
At this point of time, where reusable and widely adaptable ontology matching tools only start to emerge, automatic mapping of ontologies seems more science fiction than reality. Therefore, we focus on semi-automatic mapping, where the system will suggest mappings between concepts in the source ontologies and the user will either discard or follow these suggestions.
Because the mapping process cannot be completely automated, we need a User Interface to allow user interaction with the alignment module. We assume for now that the user is presented with suggestions for possible mappings that have been found by the system. The user can choose to either follow or discard the suggestions, on a per suggestion basis (i.e. after the user chooses to follow a suggestion, the list of suggestions is revised by the system). For this we need mechanisms for the display of the suggestions to the user and for the user to provide feedback on these suggestions.We will furthermore assume that the system will not be able to find all required mapping rules. The user has to be able to manually specify a mapping rule. We need an advanced User Interface for this, where it is possible for the user to select a certain mapping type and to select concepts from the ontologies that are to be mapped using this mapping rule. Furthermore, the user needs to be able to specify certain parameters for the mapping rules, which is necessary for the partial mappings and the value transformations. For the value transformations we need an expression language that is able to perform transformations on string and numeric values, which can also be used by the user as a parameter for this mapping rule. For the partial mappings the user needs to be able to create arbitrary formulas using the concepts in the ontologies in order to describe the intersection of the concepts to be mapped.The following functions will be offered to the user:
Choose two ontologies to align. Before the ontology alignment process can start, the user needs to select two ontologies O1 and O2 in the ontology management module and give the command to start the alignment.
Choose an existing alignment to edit. The user needs to be able to modify existing alignment in the case of faulty or missing mappings between concepts.
Provide feedback on generated suggestions. When the alignment process has started, the system will try to find suggestions for mappings between concepts in O1 and O2 and present these to the user. The user can now choose to either follow or discard these suggestions (on a per-suggestion basis).
Create a mapping rule. When a user identifies a mapping rule to be applied that is not on the list of suggestions provided by the system, the user will be able to select the type of mapping rule to be defined, the concepts in O1 and O2 to apply the rule to, and, if necessary, some parameters (i.e. for the partial mapping and the value transformation mapping rules).
Store mapping. Once the user has decided that all necessary mapping rules are in place, the user will tell the system to store the defined mapping for later use.
D1.4 v2.0 Ontology Alignment Solution 33
Esperonto Services IST-2001-34373
These User Interface requirements provide an overview of the functionality to be offered to the user. The solution accommodates these user requirements as they were identified in this and previous version of this deliverable.
We find the above requirements reasonable from the users’ point of view. Further back-end requirements on ontology alignment tools can be derived from the section where methodologies and tools were described – a perfect solution should comply and combine effective results of those.
3.2.3 Ontology Alignment Integration Requirements
The alignment solution will be integrated in the ontology management module. In the first version of this deliverable, we proposed the reuse of two mapping algorithms coming from the PROMPT and Chimaera tools. It appears now that we cannot be satisfied with a unique mapping algorithm, even if it combines advantages from these two methods. There is currently different works on ontology alignment, and new algorithms will be developed. The alignment solution should therefore integrate different methods to define mappings. In this respect we will concentrate our effort on developing a platform method independent. We have to define an alignment algorithm format and an interface, dealing with different kinds of ontology languages. We’re distinguishing three kinds of mappings, regarding the automation degree of the process:
Manual mapping the user does the mapping by hand. She can link different entities and define mapping rules.
Semi-automatic mapping an algorithm suggests mappings to the user who can choose to accept or reject them. The results can be complemented by a manual mapping. This will be the most common mapping way.
Automatic mapping here the user has nothing to do; it supposes that the mapping algorithm is very efficient.
The user will be able to modify an old mapping, manually, or by the use of an algorithm. This means that mappings will have to be saved and loaded, and that algorithms specifications will include a field to indicate whether or nor the algorithm can work with a pre-existing mapping. Once a mapping is created between two ontologies, it will be used to either to merge the ontologies or align them. We consider two modules for an alignment solution:
A mapping module is used to create and modify mappings between ontologies.
A runtime module uses the created mappings to rewrite queries and transform instances.
D1.4 v2.0 Ontology Alignment Solution 34
Esperonto Services IST-2001-34373
4 Ontology Alignment SolutionIn this section, the proposed ontology alignment solution is described. The solution is three-fold: provision of a formalism for effective expression of language mappings, an adoption and provision to a wide community of a chosen ontology alignment tool (INRIA API) and an overview of an open Ontology Management System with highlighting of a role and position of an ontology alignment module there.
4.1 Ontology Mapping LanguageIn this section we describe a language-independent ontology mapping language. This language can be used for conceptual mapping between ontologies and to guide developers of mapping tools. In future work we will provide a formal semantics for this language for mapping between OWL DL (Patel-Schneider et al., 2004) ontologies and for mapping between WSML (de Bruijn et al., 2004a) ontologies.
The abstract syntax is written in the form of EBNF, similar to the OWL Abstract Syntax (Patel-Schneider et al., 2004). Any element between square brackets '[' and ']' is optional. Any element between curly brackets '{' and '}' can have multiple occurrences.
Each element of an ontology on the Semantic Web, whether it is a class, attribute, instance, or relation, is identified using a URI (Berners-Lee et al., 1998). In the abstract syntax, a URI is denoted with the name URIReference. We define the following identifiers:
The lexical form is a unicode string in normal form, as in RDF. The language tag is an XML language tag, as in RDF.First of all, the mapping itself is declared, along with the ontologies participating in the mapping.
A mapping consists of a number of annotations, corresponding to non-functional properties in WSMO (Roman et al., 2004), and a number of mapping expressions. The creator of the mapping is advised to include a version identifier in the non-functional properties.
Expressions are either class mappings, relation mappings or instance mappings. Special kind of relation mappings are attribute mappings. Attributes are binary relations with a defined domain and are thus associated with a particular class. In the mapping itself the attribute can be either associated with the domain defined in the (source or target) ontology or with a subclass of this domain.A mapping can be either uni- or bidirectional. In the case of a class mapping, this corresponds with class equivalence and class subsumption, respectively. In order to distinguish these kinds of mappings, we introduce two different keywords for class, relation and attribute mappings. Individual mappings are always bidirectional. Unidirectional and bidirectional mappings are differentiated with the use of a switch. By default mappings are bidirectional, unless explicitly indicated.
It is possible, although not required, to nest attribute mappings inside class mappings. Furthermore, it is possible to write down an axiom, in the form of a class condition, which defines general conditions over the mapping, possibly involving terms of both source and target ontologies. Notice that this class condition is a general precondition for the mapping and thus is applied in both directions if the class mapping is a bidirectional mapping. Thus, we expect that this condition would generally be an implication for one-way mappings and an equivalence relation for two-way mappings, although the user has full flexibility in writing down any formula the specific mapping language allows. Notice that we allow arbitrary axioms in the form of a logical expression. The form of such a logical expression is very much dependent on the logical language being used for the mappings and is thus not further specified here.
There is a distinction between attributes mapping in the context of a class and attributes mapped outside the context of a particular class. Because attributes are defined locally for a specific class, we expect the attribute mappings to occur mostly inside class mappings. The keywords for the mappings are the same. However, attribute mappings outside of the context of a class mappings need to be preceded with the class identifier, followed by a dot '.'.
For class expressions we allow basic boolean algebra. This corresponds loosely with Wiederhold's ontology algebra (Wiederhold, 1994). Wiederhold included the basic intersection and union, which correspond with our and and or operators. Wiederhold's difference operator corresponds with a conjunction of two class expressions, where one is negated, i.e. for two class expressions C and D, the different C-D corresponds with and(C,not(D)). The join expression is explained at the end of this section.
Attribute expressions are defined as such, allowing for inverse, transitive close, symmetric closure and reflexive closure, where inverse(A) stands for the inverse of A, symmetric(A)} stands for the symmetric closure of A13, reflexive(A) stands for the reflexive closure of A14 and\abssyn{trans($A$)} stands for the transitive closure of A:
Especially when mapping several source ontologies into one target ontology, different classes and relations need to be joined. Although apparently similar, a join mapping is fundamentally different from an intersection mapping.
13 Notice that the symmetric closure of an attribute is equivalent to the union of the attribute and its inverse: or(A inverse(A)).14 The reflexive closure of an attribute A includes for each value v in the domain a tuple with equivalent domain and range v: v,v.
D1.4 v2.0 Ontology Alignment Solution 37
Esperonto Services IST-2001-34373
As an example we demonstrate the difference between a class intersection mapping and a class join mapping. Say, we have two source classes A and B and a target class C. A class intersection is specified as such:
classMapping(and(A B) C)
The interpretation of this mapping is roughly as follows: every individual that is an instance of both A and B is consequently also an instance of C. However, this means that the fractions of the classes A and B which correspond with C already have to be specified as instances of both A and B. In a single ontology, assuming the ontology has been modelled perfectly, this is feasible. However, when dealing with multiple ontologies, this cannot be assumed, and even within one ontology, the classes are not necessarily related to each other.
Furthermore, if A and B are actually not related to each other, this mapping would not work. Say A and B correspond with (disjoint) parts of C. In this case, clearly A and B do not relate to each other, only via C. In this case, A and B have to be joined to create new instances for the class C. This can be specified in the following way:
classMapping(join(A B { condition }) C)
Notice that in order to do a join, a condition on the join has to be given in order to identify which instances of A and B are to be joined. The condition is between curly brackets to indicate that it is a formula in the logical language.
4.2 Ontology Alignment ImplementationIn this section, the practical implementation of the ontology alignment solution module is described.
INRIA API (Euzenat, 2004) was chosen to be reused in the ontology alignment solution for implementation. The choice stems up from the survey of the ontology alignment methods and tools that revealed that most considered methodologies did not gain a reusable implementation and often even vanished without any trace of implementation. INRIA API is reasonable to be a core of the ontology alignment solution as it provides an implementation of a general infrastructure that can be enriched by additional algorithms, ontology mapping formalisms support and interfaces. Furthermore, the implementation of INRIA API has proven to be usable and evolving.
The resulting application containing runs on a Tomcat server. The application has three major outside modules as a core: INRIA API, OWL API and Jena 2. A JSP interface to make the application available for the final user and to realize the semi-automatic matching process was implemented.
All the mappings that are verified by a human via the implementation are stored in an OWL serialization in a publicly available place: http://align.deri.org:8080/people/mappings.owl. Therefore, usage and experiment with the online version of ontology alignment implementation will result in generation of human-verified data on matched ontology items that can be reused by Semantic Web applications.
The implementation is available for public testing and use at the URL: http://align.deri.org
The implementation is based on INRIA ontology alignment API and allows to - select two ontologies for alignment via providing their web URIs or indicating a file,
containing an ontology, on the local hard drive, select alignment method among the inbuilt methods and instantiate the alignment process
- browse through the proposals of the algorithm for ontology alignment and choose the acceptable ones
- save the chosen ontology mappings in common repository available on the web for everyone’s reuse and receive an output containing the just chosen mappings in an OWL serialization
The implementation has the following main limitations:- the implemented algorithms are for ontologies specified in OWL only (this limitation
comes from current algorithms triggered via INRIA API)- the OWL ontologies only specified in a subset and dialect of OWL syntax supported by
employed OWL API can be processed (this limitation comes from OWL API from Manchester that is used by the implementation)
- the service requires direct human interaction, and is not available for machine to machine interaction (this limitation comes from the interface)
User Interface
The screenshots of the user interfaces for the online ontology alignment tool are shown at Figure 11, Figure 12 and Figure 13. The three stages are shown:
1) ontology selection (by inputting URI or a file from the local disk)2) verification of the proposed ontology mapping suggestions3) generation/output and storage of the versified mappings available for reuse
Selection of Ontologies and Method for Alignment
D1.4 v2.0 Ontology Alignment Solution 39
Esperonto Services IST-2001-34373
Figure 11: Ontology and Alignment Method Selection
Verifying Proposed Mappings
Figure 12: Matching Proposal Verification
Storage and Acquisition of Verified Mappings
Figure 13: Mapping Output
4.2.3 Integration and Interoperation with External Systems
The ontology alignment solution described in this section is oriented more on the human-user than to a usage by a machine, and has other limitations that put obstacles on the way to
D1.4 v2.0 Ontology Alignment Solution 40
Esperonto Services IST-2001-34373
providing an ontology alignment module that is easy to integrate and combine with outside applications and services.
We consider the following issues to be crucial for development of a widely accepted ontology alignment tool:- input of ontologies in different ontology languages - improvement of ontology alignment algorithms- providing a possibility to easily plug in new ontology alignment algorithms- output of ontology mappings in multiple possible mapping representations, including the ones compatible with web-service and process mediation areas- provision of the alignment service as a web service to enable machine-machine interoperation
Thus, improving the existing ontology alignment services is a complex task that should involve experts working in different fields and unite their efforts towards building an ontology alignment service that can be actually be accepted by a large community and finally lead to a greater interoperability.
4.3 Ontology Alignment in Ontology Management SystemIn this subsection, an overview of an ontology management system is given, and a role, function and place of ontology alignment functionality are explained.
4.3.1 Introduction
A working group on ontology management15 has been recently created by DERI and Ontotext laboratories. The aim of this group is to develop an ontology management suite including the last advances in ontology management research. This system will include versioning, merging and alignment tooling, as part of an editing and browsing tool. A repository is also developed with its management tools. In this chapter we present the architecture of the alignment part of the Ontology Management System. Figure 14 show the component view of the ontology management system.
15 Ontology Management Working Group: www.omwg.org
Figure 14: Component View of the Ontology Management System
4.3.2 The alignment tool components
The alignment tool will be developed following the solution defined in the first version of this deliverable and adding new support from our researches recent advances.Ontology merging and ontology aligning tasks both require the use of mappings: between the two source ontologies and the newly merged one for the former, and between the two aligned ontologies for the latter. Mapping specification is currently a semi-automatic task for which many algorithms exists. In the first version of this deliverable (de Bruijn et al., 2003) we present one based on PROMPT (section 2.6) and suggest using it in our system. Like new algorithms are likely to emerge from the research community, the alignment tool should be able to include them and the user to use her preferred one. In this perspective we will support a general alignment API on which different algorithms could be implemented.The alignment functionality is to satisfy all the requirements raised in the upcoming OMWG working draft.
From the architecture point of view, the alignment tool contains two components: The mapping module helps the user to create mappings and construct merged ontologies.The runtime module uses the created mappings to perform the tasks required by the external components.
We will next detail the composition of each module.
4.3.2.1 Mapping Module
D1.4 v2.0 Ontology Alignment Solution 42
Esperonto Services IST-2001-34373
Mapping languageAs seen in section 4.1, the mappings are based on a general mapping language.
PatternsPatterns are templates that match the more usual mistakes between two ontologies. The use of predefines patterns considerably reduce the mapping designer task. In this solution we propose the use of a pattern language to define them, a pattern library allowing storing and retrieving them efficiently.
Mapping algorithms interfaceThe architecture of the module allows the use of different mapping algorithms. These algorithms are stored and can be combined to create efficient mappings. The interface specifies the ontology language in input and the mapping language in output.
Graphical user interfaceThis interface plays the main role in the mapping module. It allows the user to graphically create or modify mappings by linking similar entities. Mapping proposals as results of the mapping algorithms are also integrated in this part of the component.
4.3.2.2 Runtime module
This module is used by the reasoning part of the ontology management system. It can also be implemented as a web service but we won’t discuss this here.This module uses the mappings to perform the following tasks:
Query rewritingUsed to rewrite a query written for an ontology into one for another ontology. This process uses the mapping between the two ontologies or proposes to create one using the mapping module.
Instance transformationUse to transform instances from one ontology to another. This process also uses the mapping between the two ontologies.
4.3.2.3 Architecture
Error: Reference source not found sums up OMWG alignment solution architecture.
D1.4 v2.0 Ontology Alignment Solution 43
Esperonto Services IST-2001-34373
Figure 15 : alignment module architecture
The ontology representation and data integration functionality will be realized with respect to the ORDI framework (Kiryakov et al., 2004). Figure 16 : ORDI frameworkillustrates ORDI framework.
D1.4 v2.0 Ontology Alignment Solution 44
User Interface
Mapping Methods/Algorithms
Stored Mappings
Query engineRepository(Merged ontologies)
Alignment module
Runtime Module
Query rewriting Instance transformation
Esperonto Services IST-2001-34373
Figure 16 : ORDI framework
4.3.3 Participants
This work is driven by DERI Innsbruck and Ontotext labs.
5 ConclusionsIn this report, we defined and analyzed the ontology alignment problem, surveyed existing methods and tools for ontology aligning and ontology mapping. We have identified requirements for an ontology mapping application and the types of mappings necessary for ontology alignment. Generally, we argue for the solutions that are ontology language and ontology mapping language independent, with possibilities of adoption multiple ontology alignment algorithms or triggering different ontology alignment services to enable broad interoperation. The resulting solution is also required to have a potential of easy integration and communication with affiliated ontology management modules, such as an ontology management system. Meanwhile, at the moment fully-automated ontology alignment processes do not have secure implementations, so the user-interactive aspect and user interfaces are of importance.We have defined a solution for the ontology alignment problem in the Esperonto project. The final solution for the Esperonto project is three-fold: provision of a formalism for effective expression of language mappings, an adoption and provision to a wide community of a chosen ontology alignment tool (Euzenat, 2004) and an open ontology management system with highlighting of a role and position of an ontology alignment module there. A mapping language formalism, which brings the currently missing expressivity and clarity in the field of mapping languages, was proposed. As a result of survey of possibilities of reusing existing tools, INRIA ontology alignment API was found to be the most appropriate and was practically reused in the implementation. In addition, certain approaches earlier practiced in existing solutions, such as in PROMPT (Noy and Musen, 2000), have reappeared in the general solution. The described ontology management system infrastructure provides an integration filed and supportive environment for integration of recent implementations for theoretical approaches and existing tools. The complexity of the ontology alignment problem can not be underestimated: a comprehensive solution of this problem requires a solid integration of efforts of specialists from many fields, as well as involvement of user communities, presence of rich ontology network on
D1.4 v2.0 Ontology Alignment Solution 45
Esperonto Services IST-2001-34373
the current Semantic Web and existence of advanced services for ontology management support.
D1.4 v2.0 Ontology Alignment Solution 46
Esperonto Services IST-2001-34373
ReferencesBerners-Lee, T., Fielding, R., Irvine, U.C., and Masinter, L. (1998). Uniform resource
identifiers (URI): Generic syntax. RFC 2396, Internet Engineering Task Force, 1998.Brickley, D., Guha, R.V. (2004). RDF vocabulary description language 1.0: RDF schema.
Recommendation 10 February 2004, W3C. Available from http://www.w3.org/TR/rdf-schema/.
Bright, M.W., Hurson, A.R. and Pakzad, S. (1994). Automated resolution of semantic heterogeneity in multidatabases. ACM Transactions on Database Systems, 19(2), 212-253.
Calvanese, D., Giacomo, G., Lenzerini, M. (2002). A framework for ontology integration. In Isabel Cruz, Stefan Decker, Jérôme Euzenat, and Deborah McGuinness, editors, The emerging semantic web, pages 201–214. IOS Press, Amsterdam (NL).
Campbell, A. E. and Shapiro, S.C. (1995). Ontologic mediation: An overview. IJCAI95 Workshop on Basic Ontological Issues in Knowledge Sharing, Montreal, Canada.
Chalupsky, H. (2000). OntoMorph: A translation system for symbolic knowledge. In. Proc. 7th
Intl. Conf. On Principles of Knowledge Representation and Reasoning (KR2000), Breckenridge, Colorado, USA, April 2000.
Chaudhri, V. K., Farquhar, A., Fikes, R., Karp, P. D., and Rice, J. P. (1998). Okbc: A programmatic foundation for knowledge base interoperability. In Proceedings of the Fifteenth National Conference on Artificial Intelligence(AAAI-98), pages 600–607, Madison, Wisconsin, USA. MIT Press.
de Bruijn, J., Ding, Y., Arroyo, S., Lausen, H. (2003). Ontology Alignment Solution. D14 v1.0, Esperonto project deliverable (http://esperonto.semanticweb.org).
de Bruijn, J. Polleres, A. (2004). Towards and ontology mapping language for the semantic web. Technical Report DERI-2004-06-30, DERI.
de Bruijn, J., Martin-Recuerda, F., Manov, D., Ehrig, M. (2004). D4.2.1 State-of-the-art Survey on Ontology Merging and Aligning, SEKT project deliverable (http://sekt.semanticweb.org).
de Bruijn, J., Lausen, H., and Fensel, D. (2004a). The WSML Family of Representation Languages. Deliverable D16v0.2, WSML, 2004. Available from http://www.wsmo.org/2004/d16/v0.2/.
Dean, M., Schreiber, G., (Eds.) (2004). OWL Web Ontology Language Reference. 2004. W3C Recommendation 10 February 2004.Dou, D., McDermott, D., Qi, P. (2002). Ontology translation by ontology merging and
automated reasoning. In Proc. EKAW2002Workshop on Ontologies for Multi-Agent Systems, pp. 3–18.
Doan, A., Madhaven, J., Domingos, P., Halevy, A. (2004). Ontology matching: A machine learning approach. In Steffen Staab and Rudi Studer, editors, Handbook on Ontologies in Information Systems, pages 397–416. Springer-Verlag.
Euzenat, J. (2004). An API for Ontology Alignment. In Proc. of the International Semantic Web Conference, Hiroshima, Japan, November 2004.
Farquhar, A., R., F., and Rice, J. (1996). The Ontolingua Server: a Tool for Collaborative Ontology Construction. In Proceedings of the Tenth Knowledge Acquisition for Knowledge-Based Systems Workshop, Banff, Canada.
Fowler, J., Nodine, M., Perry, B., and Bargmeyer, B. (1999). Agent-based semantic interoperability in Infosleuth. Sigmod Record, 28, 1999.
Ganter, B. and Wille, R. (1999). Formal concept analysis: Mathematical Foundations. Springer, Berlin-Heidelberg.
Gómez-Pérez, A. et al. (2002). A survey on ontology tools. Deliverable 1.3, OntoWeb project (http://www.ontoweb.org/).
Giunchiglia, F., Shvaiko, P., Yatskevich, M. (2004). S-match: an algorithm and an implementation of semantic matching. In Proceedings of ESWS’04, number 3053 in LNCS, pages 61–75, Heraklion, Greece, 2004. Springer-Verlag.
Hameed, A. and Preece, A. and Sleeman, D. (2004). Ontology reconciliation, International handbooks on information systems. Springer- Verlag, Berlin, Germany.
Hammer J. and McLeod D. (1993). An approach to resolving Semantic Heterogeneity in a Federation of Autonomous, Heterogeneous, Database Systems. International Journal on Intelligent and Cooperative Information Systems, 2(1):51-83
Horrocks, I. and Patel-Schneider, P.F. (2003). Reducing OWL entailment to description logic satisdiability. In Proc. of the 2003 International Semantic Web Conference (ISWC 2003), Sanibel Island, Florida.
Hovy, E. (1998). Combining and standardizing large-scale: practical ontologies for machine learning and other uses. In. Proc. 1st Intl. Conf. On Language Resources and Evaluation, Granada, Spain, May 1998.
Hull, R. (1997). Managing semantic heterogeneity in databases: A theoretical perspective. In ACM Symposium on Principles of Database Systems (pp. 51–61). Tuscon, Arizona, USA.
Jannink, J., Srinivasan, P., Verheijen, D. and Wiederhold, G. (1998). Encapsulation and Composition of Ontologies. In. Proc. AAAI Workshop on Information Integration, AAAI Summer Conference, Madison WI, July 1998.
Kashyap, V. and Sheth, A. (1996). Semantic and schematic similarities between database objects: A context-based approach. International Journal on Very Large Databases, 5(4), 276-304.
Kiryakov, A., Ognyanoff, D., Kirov, V. (2004). An Ontology Representation and Data Integration (ORDI) Framework. Deliverable D2.2 of the DIP (http://dip.semanticweb.org) project.Klein, M. (2001). Combining and relating ontologies: an analysis of problems and solutions. In
Gomez-Perez, A., Gruninger, M., Stuckenschmidt, H., and Uschold, M., editors, Workshop on Ontologies and Information Sharing, IJCAI’01, Seattle, USA.
Lehmann, F. and Gohn, A.G. (1994). The EGG/YOLK reliability hierarchy: Semantic data integration using sorts with prototypes. In., Third International ACM Conference on Information and Knowledge Management (CIKM-94), New York, ACM Press.
Li, W.S. (1995). Knowledge gathering and matching in heterogeneous databases. In C. Knoblock and O. Levy (eds.), Working Notes of the AAAI Spring Symposium on Information Gathering from Heterogeneous, Distributed Environments. Menlo Park, California, pp. 116-121.
Madhavan, J., Bernstein, P.A., Rahm, E. (2001). Generic schema matching with cupid. In Proc. 27th Int. Conf. on Very Large Data Bases (VLDB).
Maedche, A., Motik, B., Silva, N., Volz, R. (2002). Mafra a mapping framework for distributed ontologies. In Proceedings of the 13th European Conference on Knowledge Engineering and Knowledge Management EKAW-2002, Madrid, Spain, 2002.
McCarthy, J. (1993). Notes on formalizing context. Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence, AAAI, 1993.
McGuinness, D.L., Fikes, R., Rice, J. and Wilder, S. (2000). An environment for merging and testing large ontologies. In. Proc. 7th Intl. Conf. On Principles of Knowledge Representation and Reasoning (KR2000), Colorado, USA, April 2000.
Mena, E., Illarramendi, A., Kashyap, V., and Sheth, A. P. (2000). OBSERVER: An approach for query processing in global information systems based on interoperation across pre-existing ontologies. Distributed and Parallel Databases, 8(2):223–271.
Mitra, P. and Wiederhold, G. (2001). An algebra for semantic interoperability of information sources. In IEEE International Conference on Bioinformatics and Biomedical Engineering, pages 174–182.
Mitra, P., Wiederhold, G. and Kersten, M. (2000). A Graph-Oriented Model for articulation of Ontology Interdependencies. In Proceedings of Conference on Extending Database Technology, (EDBT 2000), Konstanz, Germany, Mar. 2000.
Mitra, P., Wiederhold, G. and Jannink, J. (1999). Semi-automatic Integration of knowledge Sources. In Proceedings of Fusion 99. Sunnyvale CA, July, 1999.
Nodine, M. H., Fowler, J., Ksiezyk, T., Perry, B., Taylor, M., and Unruh, A. (2000). Active information gathering in infosleuth. International Journal of Cooperative Information Systems, 9(1-2).
Noy, N. F. and Musen, M. A. (1999). SMART: Automated support for ontology merging and alignment. SMI Report Number: SMI-1999-0813.
Noy N. F., Musen M. A. (2000a). PROMPT: Algorithm and Tool for Automated Ontology Merging and Alignment. In P. Rosenbloom, H. A. Kautz, B. Porter, R. Dechter, R. Sutton and V. Mittal (eds) 17th National Conference on Artificial Intelligence (AAAI’00), Austin, Texas, pp 450–455.
Noy, N. F. and Musen, M. A. (2000b). Anchor-prompt: Using non-local context for semantic matching. In Proceedings of the Workshop on Ontologies and Information Sharing at the Seventeenth International Joint Conference on Artificial Intelligence (IJCAI-2001), Seattle, WA, USA.
Noy, N. F. and Musen, M. A. (2003). Ontology Versioning as an Element of an Ontology-Management Framework. To be published in IEEE Intelligent Systems.
Park, J.Y., Gennari, J.H., Musen, M.A. (1998). Mappings for reuse in knowledge-based systems. In Proceedings of the 11th Workshop on Knowledge Acquisition, Modelling and Management (KAW 98), Banff, Canada.
Patel-Schneider, P.F., Hayes, P., and Horrocks, I. (2004). OWL web ontology language semantics and abstract syntax. Recommendation 10 February 2004, W3C.
Predoiu, L. et.at. (2004). Framework for Representing Ontology Networks with Mappings that Deal with Condicting and Complementary Concept Definitions, DIP deliverable 1.5 (http://dip.semanticweb.com), October 2004.
Preece, A. D., Hui, K, K., Gray, W. A., Marti, P., BenchCapon, T. J. M., Cui, Z., and Jones, D. (2001). KRAFT: An agent architecture for knowledge fusion. International Journal of Cooperative Information Systems, 10(1-2):171–195.
Rahm, E., Bernstein, P.A. (2001). A survey of approaches to automatic schema matching. VLDB Journal: Very Large Data Bases, 10(4):334–350.
Roman, D., Lausen, H., Keller, U. (2004). Web service modeling ontology standard (WSMO-standard). Working Draft D2v0.2, WSMO, 2004.
Schreiber, G. (2002). The web is not well-formed. IEEE Intelligent Systems, 17(2). Contribution to the section Trends and Controversies: Ontologies KISSES in Standardization.
Silva, N., Rocha, J. (2003). Service-oriented ontology mapping system. In Proceedings of the Workshop on Semantic Integration of the International Semantic Web Conference (ISWC2003), Sanibel Island, USA, 2003.
Smith, D.C. (1990). Plisp Users Manual. Apple Computer, August, 1990.Stumme, G. and Maedche, A. (2001). FCA-merge: Bottom-up merging of ontologies. In 7th
Intl. Conf. on Artificial Intelligence (IJCAI ’01), Seattle, WA, USA, pp. 225–230.Stumme, G., Studer, R. and Sure, Y. (2000). Towards an order-theoretical foundation for
maintaining and merging ontologies. In. Proc. Referenzmodellierung 2000, Siegen, Germany, October 12-13, 2000.
Tamma, V. A. M. and Bench_Capon, T.J.M. (2000). Supporting different inheritance mechanisms in ontology representations. In. Proceedings of the First Workshop on Ontology Learning (OL-2000) in conjunction with the 14th European Conference on Artificial Intelligence (ECAI 2000). August, Berlin, Germany.
Uschold, M. (2000). Creating, integrating and maintaining local and global ontologies. In. Proceedings of the First Workshop on Ontology Learning (OL-2000) in conjunction with the 14th European Conference on Artificial Intelligence (ECAI 2000). August, Berlin, Germany.
Visser, P. and Jones, D., Bench-Capon, T.J.M. and Shave, M.J.R. (1997). An Analysis of Ontology Mismatches; Heterogeneity versus Interoperability.
Visser, P.R.S. and Cui, Z. (1998). On accepting heterogeneous ontologies in distributed architectures. In. Proceedings of the ECAI98 workshop on applications of ontologies and problem-solving methods. Brighton, UK, 1998.
Visser, P.R.S. and Tamma, V.A.M. (1999). An experience with ontology clustering for information integration. In. Proceedings of the IJCAI-99 Workshop on Intelligent Information
D1.4 v2.0 Ontology Alignment Solution 49
Esperonto Services IST-2001-34373
Integration in conjunction with the Sixteenth International Joint Conference on Artificial Intelligence, Stockholm, Sweden, July 31, 1999.
Visser, P.R.S., Jones, D.M., Beer, M., Bench-Capon, T.J.M., Diaz, B. & Shave, M.J.R. (1999). Resolving Ontological Heterogeneity in the KRAFT Project. In., DEXA-99, 10th International Conference and Workshop on Database and Expert Systems Applications, Florence, Italy, August, 1999.
Visser, P. R. S., Jones, D. M., Bench-Capon, T. J. M., and Shave, M. J. R. (1997). An analysis of ontological mismatches: Heterogeneity versus interoperability. In AAAI 1997 Spring Symposium on Ontological Engineering, Stanford, USA.
Weinstein, P.C. and Birmingham, P. (1999). Comparing Concepts in Differentiated Ontologies. In. Proceedings of the Twelfth Workshop on Knowledge Acquisition, Modeling and Management (KAW99). October 1999, Banff, Alberta, Canada.
Wiederhold, G. (1994). An algebra for ontology composition. In. Proceedings of 1994 Monterey Workshop on formal Methods (pp. 56-61), U.S. Naval Postgraduate School, Monterey CA, 1994.
Wiederhold, G. (1994a). Interoperation, mediation, and ontologies. In. Proceedings International Symposium on Fifth Generation Computer Systems (FGCS), Workshop on Heterogeneous Cooperative Knowledge-Bases, Vol.W3, pp.33--48, ICOT, Tokyo, Japan, Dec. 1994.
Williams, A.B. and Tsatsoulis, C. (2000). An instance-based approach for identifying candidate ontology relations within a multi-agent system. In. Proceedings of the First Workshop on Ontology Learning (OL-2000) in conjunction with the 14th European Conference on Artificial Intelligence (ECAI 2000). August, Berlin, Germany.
Zhdanova, A.V. (2004). The People's Portal: Ontology Management on Community Portals. In Proceedings of the 1st Workshop on Friend of a Friend, Social Networking and the Semantic Web (FOAF'2004), 1-2 September 2004, Galway, Ireland, pp. 66-74. URL: http://www.w3.org/2001/sw/Europe/events/foaf-galway/papers/fp/peoples_portal/.