ESTADÍSTICA GENERAL. UNIVERSIDAD NORORIENTAL PRIVADA “GRAN MARISCAL DE AYACUCHO”. FACULTAD DE CIENCIAS ECONÓMICAS Y SOCIALES. ESCUELA DE ADMINISTRACIÓN. INTEGRANTE: ROXANA LÓPEZ. C.I:26.896.088 PROF: HAMLET MATA MATA.
Transcript
ESTADÍSTICA
GENERAL.
UNIVERSIDAD NORORIENTAL PRIVADA
“GRAN MARISCAL DE AYACUCHO”.
FACULTAD DE CIENCIAS ECONÓMICAS Y SOCIALES.
ESCUELA DE ADMINISTRACIÓN.
INTEGRANTE:
ROXANA LÓPEZ.
C.I:26.896.088
PROF:
HAMLET MATA MATA.
1
ÍNDICE
INTRODUCCIÓN..……………………………………………….……………………….2
PROGRAMA
SPSS…………………………………………………………………………………….…...3
HISTORIA ....................................................................................................................... 4
VERSIONES DEL
SPSS…………………………………………………………………………………………4
SPSS Opciones………………………………………………………………………………9
PASW es SPSS ................................................................................................................ 12
PROCEDIMIENTO GENERAL DE RESOLUCIÓN DE UN PROBLEMA CON
SPSS………………………………………………………………………………………..11
UTILIZACION DEL SPSS………………………………………………………………...12
CAPTURA DE DATOS E INTRODUCCIÓN DIRECTA EN SPSS
OPERACIONES HABITUALES CON VARIABLES EN SPSS
RECODIFICAR VARIABLES
CALCULAR NUEVAS VARIABLES A PARTIR DE OTRAS EXISTENTES
FILTRAR CASOS
FUNDIR ARCHIVOS
OTRAS OPERACIONES FRECUENTES
ANÁLISIS PRIMARIO DE INFORMACIÓN
LECTURA DE DATOS
TRANSFORMACIÓN DE VARIABLES.
Definición de las variables………………………………………………………………21
Nombres de las variables
Tipos de las variables
Etiquetas de las variables
Propiedades de variables………………………………………………………………..24
Definición de propiedades de variables………………………………………………..25
El formato de columna de las variables……………………………………………….29
ESTRUCTURA DEL SPSS……………………………………………………………34
2
SISTEMA DE VENTANAS DE SPSS
VENTANAS
BOTONES
MENÚ PRINCIPAL
ICONOS
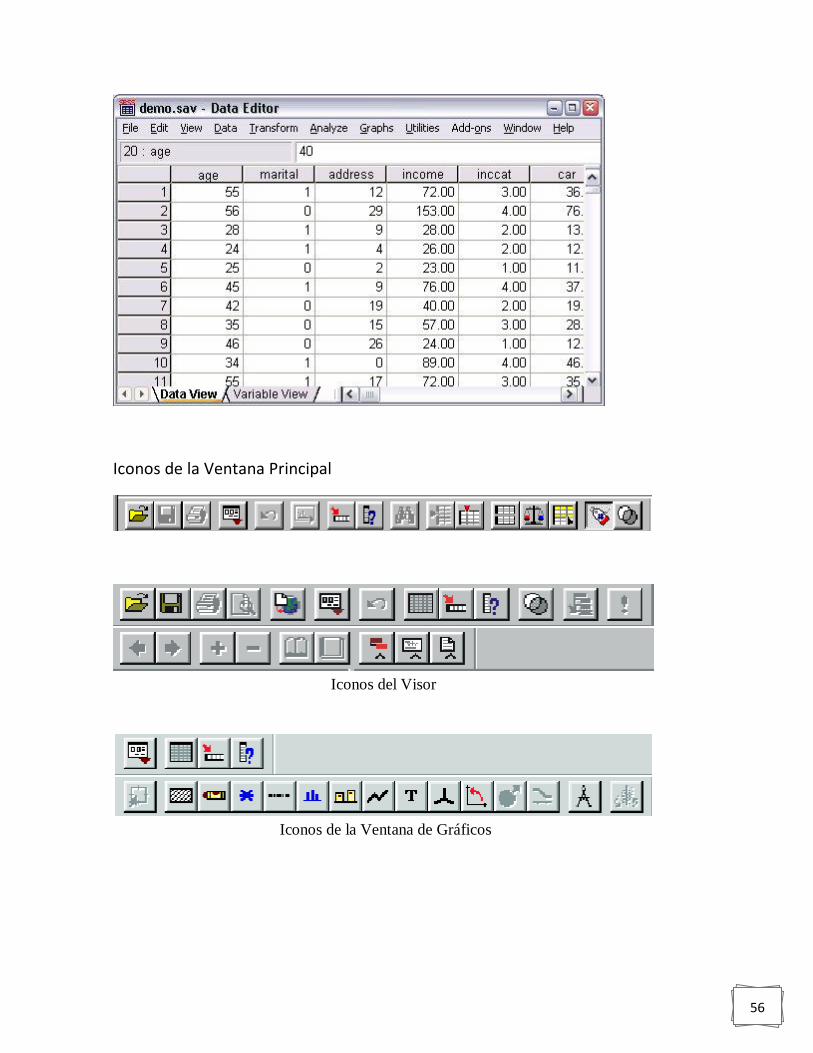
Iconos de la Ventana Principal ......................................................................................... 39
Iconos del Visor ............................................................................................................... 41
Iconos de la Ventana de Gráficos ..................................................................................... 42
BARRA DE ESTADO ................................................................................................. 44
ESTADISTICA DESCRIPTIVA CON SPSS…………………………………………..44
GRÁFICOS CON SPSS………………………………………………………………….48
VENTAJAS DE SPSS……………………………………………………………………53
DESVENTAJAS DE SPSS………………………………………………………………53
CONCLUSIÓN…………………………………………………………………………..54
ANEXOS…………………………………………………………………….…………...55
3
INTRODUCCIÓN
El SPSS es una potente aplicación de análisis estadísticos de datos, dotada de una intuitiva
interfaz gráfica que resulta muy fácil de manejar.
El paquete estadístico SPSS, responde al funcionamiento de todo programa que lleva a cabo
análisis estadísticos: pasados los datos a analizar a un fichero con las características del
programa, éste es analizado con una serie de órdenes, dando lugar a unos resultados de tipo
estadístico que el investigador debe interpretar.
SPSS implementa menús que permiten realizar análisis complejos de manera rápida y
sencilla. Previo a todo ello se debe tener clara la metodología de actuación.
SPSS lleva a cabo las tres etapas claves para la realización del estudio estadístico:
Implementa de forma organizada y ordenada la base de datos.
Nos ayuda en la manipulación de los datos.
Implementa técnicas estadísticas para el análisis de los datos.
Al igual que muchos paquetes de software, el SPSS es guiado por menús. Esto significa que
los usuarios pueden ejecutar análisis estadísticos, simples o complejos, haciendo clic en una
serie de menús desplegables y seleccionando los comandos deseados pre-programados. Sin
embargo, muchos investigadores y analistas pueden utilizar ciertos procedimientos
estadísticos que no son pre-programados en el programa SPSS. Como resultado, permite a
los usuarios crear programas personalizados, o para unir múltiples operaciones de pre-
programados para ser aplicados en secuencia.
4
PROGRAMA SPSS
Es un programa estadístico informático muy usado en las ciencias exactas, sociales y
aplicadas, además de las empresas de investigación de mercado. Originalmente SPSS fue
creado como el acrónimo de Statistical Package for the Social Sciences aunque también se
ha referido como "Statistical Product and Service Solutions" (Pardo, A., & Ruiz, M.A.,
2002, p. 3). Sin embargo, en la actualidad la parte SPSS del nombre completo del software
(IBM SPSS) no es acrónimo de nada.
Es un sistema amplio y flexible de análisis estadístico y gestión de información que capaz
de trabajar con datos procedentes de distintos formatos generando, desde sencillos gráficos
de distribuciones y estadísticos descriptivos hasta análisis estadísticos complejos que nos
permitirán descubrir relaciones de dependencia e interdependencia, establecer
clasificaciones de sujetos y variables, predecir comportamientos, etc...
Su aplicación fundamental está orientada al análisis multivariante de datos experimentales.
HISTORIA
Fue creado en 1968 por Norman H. Nie, C. Hadlai (Tex) Hull y Dale H. Bent.
Entre 1969 y 1975 la Universidad de Chicagopor medio de su National Opinion Research
Center estuvo a cargo del desarrollo, distribución y venta del programa. A partir de 1975
corresponde a SPSS Inc.
Originalmente el programa fue creado para grandes computadores. En 1970 se publica el
primer manual de usuario del SPSS por Nie y Hall. Este manual populariza el programa
entre las instituciones de educación superior en EE. UU. En 1984 sale la primera versión
para computadores personales.
Desde la versión 14, pero más específicamente desde la versión 15 se ha implantado la
posibilidad de hacer uso de las librerías de objetos del SPSS desde diversos lenguajes de
programación. Aunque principalmente se ha implementado para Python, también existe la
posibilidad de trabajar desde Visual Basic, C++ y otros lenguajes.
El 28 de junio de 2009 se anuncia que IBM, meses después de ver frustrado su intento de
compra de Sun Microsystems, adquiere SPSS, por 1.200 millones de dólares.
Con la era del PC y Windows evolucionó muy rápidamente y hoy, en su versión 12,
constituye un programa que ofrece un conjunto de herramientas de análisis gráfico y
cuantitativo, estructurado en partes independientes e integrables que reciben el nombre de
módulos. Así, partiendo desde un módulo base que contiene, como su propio nombre
indica, el conjunto básico de utilidades, es posible añadir diferentes partes para realizar una
amplia gama de análisis.
Su éxito en el mercado español como herramienta de análisis fue rápido debido a su
versatilidad, facilidad de uso, buen precio, y los algoritmos robustos y continuamente
varianza, amplitud, valores mínimo y máximo, error típico de la media, asimetría y curtosis
(ambos con sus errores típicos), cuartiles y percentiles.
El botón Gráficos permite solicitar gráficos de barras, gráficos de sectores e histogramas.
En general cuando la variable tenga nivel de medida nominal no solicitaremos ningún
estadístico y tampoco solicitaremos el histograma, si solicitaremos en cambio la tabla de
frecuencias y el diagrama de barras.
Tablas de variables múltiples.
Variables multirespuesta:
Las variables vistas hasta este momento se caracterizan por asignar un único valor a cada
caso u observación.
Existen situaciones donde una variable puede ofrecer más de un único valor. Por ejemplo,
si preguntamos a un individuo su edad obtendremos un único valor numérico; sin embargo;
si preguntamos a una persona que deportes práctica, nos podrá dar un número
indeterminado de deportes.
Este tipo de variables recibe el nombre de variables multirespuesta o de respuesta múltiple.
Codificación de las variables multirespuesta:
Es evidente que si una persona puede dar más de una respuesta, tendremos que tener más
de una variable para almacenar dichas respuestas.
Existen dos formas o esquemas de codificación para almacenar estas respuestas:
- Codificación dicotómica.
- Codificación categórica.
Codificación dicotómica.
En el esquema de codificación dicotómica, creamos tantas variables como respuestas
posibles, por ejemplo si la pregunta es: “¿Que idiomas hablas?”, vamos a crear tantas
variables como idiomas. Todas estas variables se codifican de la siguiente forma:
- 0 - No habla.
- 1 - Si Habla.
Este esquema de codificación está indicado cuando el número de categorías no es muy
amplio.
46
Codificación categórica.
En el esquema de codificación categórica se hace una pequeña concesión que consiste en
estimar el número máximo de respuestas, y se crean tantas variables como el máximo de
respuestas posibles y todas estas variables con los mismos códigos para especificar cada
respuesta. Este esquema está indicado cuando el número de respuestas puede ser muy
amplio, pero sólo tendrán interés las primeras respuestas.
Ejemplo:
Supongamos que se pregunta a los encuestados que idiomas hablan, es evidente que
dependiendo de cada persona, variara el número de respuestas.
Esquema de codificación dicotómico
Variables que vamos a crear:
Francés.
Ingles.
Alemán.
Italiano.
Portugués.
Otros.
Estas variables al indicar la presencia o ausencia de una cualidad reciben el nombre de
variables dicotómicas. Etiquetas de los valores comunes a todas ellas.
- 0 - No habla.
- 1 - Si habla.
Hay que observar que tenemos que crear tantas variables como idiomas nos puedan
responder.
Esquema de codificación categórico.
En este esquema tenemos que estimar el número máximo de idiomas que puede hablar una
persona, vamos a suponer tres idiomas como máximo, por lo tanto creamos tres variables
que serán:
- Idioma1.
- Idioma2.
- Idioma3.
Las etiquetas de los valores de las variables serán:
47
- 1 Inglés
- 2 Francés
- 3 Alemán
- 4 Italiano
- 5 Portugués
- 6 Ruso
- 9 No habla
Para solicitar las frecuencias de los idiomas debemos de utilizar un módulo específico del
SPSS denominado respuesta múltiple.
Antes de solicitar cualquier estadístico, deberemos de definir la variable multirespuesta e
indicar su esquema de codificación.
Ya tenemos definida la variable multirespuesta con el nombre Idioma, para solicitar una
tabla de frecuencias utilizamos el módulo Frecuencias del procedimiento Respuestas
múltiples.
Análisis de Variables Categóricas
En las investigaciones de mercados y otros trabajos de investigación, en ocasiones, es
importante entregar resultados categorizados, es decir, agrupados por alguna categoría o
variable que sirva para separar los resultados y dar visiones separadas de estos, como por
ejemplo cuando se entregan resultados separados para mujeres y hombres.
Para realizar estas labores SPSS posee una herramienta de análisis que se llama “Tablas de
contingencia”, que consiste en una tabla que muestra información categorizada de acuerdo
a los parámetros que se haya definido previamente.
Para que este tipo de análisis tenga sentido, se necesita al menos de dos variables: una
variable que sirva para categorizar y una variable que se desee categorizar. Estas variables
deben poseer unidades de medida “Ordinal” o “Nominal”, por lo que utilizar variables con
medida de Escala no tiene mayor sentido y no ofrecería resultados de los que se pueda
extraer mucha información.
Tablas de doble entrada.
Las tablas de doble entrada también llamadas tablas de contingencias, son aquellas tablas
de datos referentes a dos variables nominales o categóricas, formada en las cabeceras de las
filas, por las categorías o valores de una variable y en las de las columnas por los de la otra,
y en las casillas de la tabla, por las frecuencias que reúnen a la vez las dos categorías o
valores de las dos variables que se cruzan en cada casilla.
GRÁFICOS CON SPSS.
48
Una parte importante a la hora de exponer los resultados estadísticos es presentar algunos
de ellos en forma de gráficos. A ello dedica SPSS todo un menú de la ventana principal,
que es el menú Gráficos, con las opciones que aparecen en la Figura 8.4. De ese menú no se
explicarán todas las opciones, sino sólo las más útiles para los objetivos del manual. Las
dos primeras opciones son: Galería e Interactivos. La primera ofrece de una manera gráfica
y guiada (mediante un tutor) cada uno de los gráficos que se pueden invocar por separado y
que se describen a continuación; esta opción puede ser seguida con facilidad por parte del
lector pues el tutor que emplea SPSS es bastante amigable y claro. Interactivos permite
construir los gráficos que veremos a continuación también de una manera interactiva y con
un tutor; es el procedimiento gráfico más moderno de SPSS y mejora sensiblemente el
manejo de los gráficos del mismo, así como su calidad de presentación (3D, colores,
sombreados, etc....); una vez más debido a la facilidad de uso no nos detendremos más en
él, por lo que el usuario puede intentarlo por su cuenta.
Todos los gráficos tienen una forma de invocarlos y una serie de opciones que matizan su
uso, por ello encontraremos que la exposición de los mismos es similar a la de otros
procedimientos estadísticos. En el primer gráfico que presentemos haremos mención al
editor de gráficos de SPSS que permite la manipulación de los mismos de manera muy
avanzada.
En numerosas ocasiones, el investigador se enfrenta con lectores que difícilmente podrán
comprender gran parte de los resultados obtenidos en el marco de una investigación. Sin
embargo, esto puede mejorar en la medida que el investigador busca nuevas formas de
presentar la información. Una de estas formas es la utilización de gráficos, los que resultan
un complemento visual importante para el desarrollo de una correcta investigación y
ofrecen herramientas que permiten al lector hacerse una mejor idea de lo que visualizarían
si solamente mirasen los resultados numéricos. Si bien es cierto que hay numerosos estilos
de gráficos que se pueden utilizar, en este apartado solamente se utilizarán los más
comunes: Gráficos de torta, Gráficos de Barra, Gráficos de dispersión (diagramas de
dispersión).
Gráficos de Torta.
Este tipo de gráficos es muy común para visualizar información de carácter cualitativo y
categórico, ya que ofrece una forma muy gráfica para visualizar el peso (o cuantía) de algún
aspecto de una variable en relación a otros.
Es importante mencionar que para que este tipo de gráficos tenga sentido, la unidad de
medida de los datos debe ser “Nominal” u “Ordinal”. Con variables medidas en Escala no
tiene mucho sentido realizar este tipo de gráficos, pues entregarán un dibujo muy complejo
de leer y sin lógica aparente.
49
1. Para generar un gráfico cualquiera, se debe ir al Menú “Gráficos” (Al lado del menú
“Analizar”) y se debe escoger alguna de las opciones. Se recomienda que se escoja la
opción “Cuadros de diálogo antiguos” (por asuntos de comodidad). Posteriormente se debe
escoger el tipo de gráfico que se desea, en este caso, un gráfico de “Sectores... ” (Que es
comúnmente llamado “Gráfico de Torta”).
2. Posteriormente ofrece la opción de cómo se desea obtener los datos desde la base de
datos. Como este es un manual de orden básico, se recomienda dejar tal cual lo ofrece el
software, es decir, se debe seleccionar la opción “Resúmenes para grupos de casos”. Con lo
anterior, el investigador se asegura que se utilizará todos los datos de la base de datos de
acuerdo a los grupos en los que se encuentren definidos.
3. Una vez abierto el cuadro de diálogo, se debe definir los sectores del gráfico. Para ello,
se debe seleccionar la variable que se desee graficar y se debe ubicar en el sector que dice:
“Definir sectores por:” Con esto, el investigador le está diciendo al software que defina los
sectores del gráfico de acuerdo a las etiquetas de la variable seleccionada. Posteriormente
se recomienda agregar títulos al gráfico. Para ello se debe hacer clic en el botón “Títulos...”.
4. En el cuadro de diálogo de títulos, se debe agregar el título principal (Línea 1 y Línea 2),
el Subtítulo y las notas al pie (Línea 1 y Línea 2 de la zona inferior). Sin embargo es
posible que el investigador decida solo colocar un título y dejar el resto en blanco, o
simplemente colocar nada. No es obligación llenar cada uno de los espacios disponibles en
esta ventana. Finalmente se debe hacer clic en el botón “Continuar” y posteriormente en el
botón “Aceptar”.
Una vez hecho clic en el botón aceptar, el software abrirá una ventana de resultados con un
gráfico. El gráfico aún se puede encontrar muy incompleto o falto de identificadores. Para
ello SPSS ofrece herramientas para editar gráficos. Solo basta con hacer doble clic sobre el
gráfico en el visor de resultados y abrirá una nueva ventana con el editor de gráficos, donde
el investigador podrá editar el gráfico a gusto.
Gráficos de Barras.
SPSS denomina Gráfico de barras a un gráfico de variables categóricas en el que sobre cada
modalidad se levanta una barra de altura proporcional a la frecuencia. La llamada del
Gráfico de Barras da lugar a una primera ventana en la que ha de seleccionarse el tipo de
gráfico de barras que se desea representar. La ventana es como la de la Figura 8.5. Lo
primero es elegir entre los gráficos: Simple, Agrupado y Apilado. En el Simple, sólo se
representa en el Gráfico una única variable (que es lo más común); en el Agrupado se hace
un gráfico simultáneo (compuesto) en el que se presenta la distribución de una variable
dentro de cada una de las categorías de otra variable. En el gráfico Apilado, se representan
las categorías de una variable apiladas en cada una de las barras en las que se representa la
otra variable. Elegido el tipo de Gráfico de Barras, se debe seleccionar ahora si el Gráfico
50
estará hecho con casos, a base de resúmenes de variables o a partir de valores individuales
de los casos; nosotros nos ceñiremos siempre a la primera opción dejando las otras para
situaciones más complejas. Una vez elegida la primera opción pasamos a lo que es la
definición del Gráfico de Barras pulsando el botón Definir.
Cuando se pulsa el botón Aceptar aparece el gráfico en el Visor de resultados, como si
fuera un resultado más.
Lo primero será decir que cuando se pincha sobre el gráfico en el Visor de resultados,
aparece el recuadro en el que está integrado el gráfico y en él una serie de puntos en su
contorno que permiten agrandarlo y achicarlo; para ello colocado el ratón sobre uno de los
puntos y pulsado el botón izquierdo basta con desplazarlo para conseguir un cambio de
tamaño proporcional al tamaño original.
Esta idea de los componentes del gráfico es básica para entender la edición del mismo; en
efecto, cuando decidamos editar el gráfico. SPSS nos permitirá la edición parcial de cada
uno de sus componentes siendo la modificación deseada la suma de las modificaciones
parciales. Pero, antes de entrar en la ventana de edición, decir que cuando se selecciona un
gráfico y seleccionamos el menú contextual para él (recuérdese con el botón de la derecha)
podremos realizar una copia del gráfico al Portapapeles de Windows y de ahí recuperarlo
en la aplicación que deseemos como ha ocurrido en el caso de este manual.
El Editor de gráficos es una ventana a todos los efectos, lo mismo que la ventana del Editor
de Datos o la ventana del Visor de resultados. Como toda ventana muestra unos menús y
una barra de herramientas análogos a los de los otros editores, salvo que ahora están
pensados para editar los gráficos. Debajo de los menús aparecen los iconos que nos sirven
para acceder de manera rápida a determinadas opciones, más usuales, de los menús. Si el
usuario pasa el ratón por ellos, se despliega una pequeña leyenda con el título de la opción.
Por último indiquemos que la forma más rápida de acceder a las opciones de modificación
es pulsar (sobre la componente que se desea modificar) dos veces con el ratón y
automáticamente se despliega la ventana de modificación oportuna.
Para editar un componente del gráfico (barras, ejes, títulos,…), en primer lugar hay que
seleccionarlo (quedará remarcado dicho componente) y luego hacer los cambios oportunos
utilizando los menús desplegables, la barra de herramientas, el menú contextual o la
ventana de propiedades (que se despliega haciendo doble clic sobre el componente, o con el
icono correspondiente de la barra de herramientas). Cuando se termine la edición del
gráfico, cerrar la ventana del editor y volvemos al Visor SPSS.
Gráficos de Líneas.
Los gráficos de líneas no son más que polígonos de frecuencias que se pueden representar
para una, dos o más variables. En la primera ventana del Gráfico de líneas se debe elegir
51
entre los gráficos Simple, Múltiple y de Líneas Verticales. El gráfico Simple permite un
polígono de frecuencias para una variable. En el Múltiple se pueden hacer varios polígonos
de frecuencias simultáneamente (gráfico compuesto). En el caso de gráficos de Líneas
verticales se lleva a cabo un gráfico más complejo que no describiremos aquí. El resto de la
ventana es como en los gráficos de barras. Pulsando el botón Definir aparece la ventana en
todo. Por ello todo lo dicho para el diagrama de barras es válido ahora. Lo dicho para el
editor de gráficos sigue siendo válido por lo que pasaremos a un nuevo gráfico.
Gráficos de Sectores.
Como su propio nombre indica, permite hacer un diagrama de sectores para la distribución
de una variable. La primera ventana del gráfico de sectores es muy simple, en ella aparecen
las opciones que conocemos de gráficos anteriores. Por ello, todo lo dicho para el diagrama
de barras es válido ahora. Lo dicho para el editor de gráficos sigue siendo válido, salvo que
aparecerá algún icono adicional, como el que permite desgajar cada porción del diagrama
de sectores.
Histograma.
Con este procedimiento obtendremos un histograma para un carácter cuantitativo continuo.
Cuando se selecciona el procedimiento se obtiene una ventana. Como siempre, aparece una
caja a la izquierda en la que figuran todas las variables del fichero activo, de entre las que
se seleccionará la variable para la que se va a hacer el histograma. Pinchando sobre Mostrar
curva normal se representará la curva Normal teórica que se ajustaría al histograma. Por
último, lo referente a Plantilla y al botón Títulos... ya se ha comentado en un gráfico
anterior. Elegidas todas las opciones, pulsando el botón Aceptar, se mostrará el histograma.
Correlación.
Con frecuencia el investigador necesita determinar si existe relación entre un conjunto de
variables, como por ejemplo, la existencia de una relación entre el salario y los años de
estudio de una persona, u otra.
La correlación lineal mide el grado de relación lineal entre dos variables o conjuntos de
variables. Los resultados entregan al investigador nociones sobre la dirección de esta
relación (positiva, negativa), la fuerza (correlación fuerte, correlación débil, sin
correlación).
La medida de correlación más utilizada en investigaciones de mercado es la denominada
“Correlación lineal de Pearson”, que indica el grado de relación lineal de las variables que
se desea medir. El valor de la correlación fluctúa entre -1 y 1, donde valores cercanos a -1
52
indican una fuerte correlación negativa, mientras que valores cercanos a 1 indican una
fuerte relación positiva.
Si el valor de la correlación es cercano a cero, se puede decir que el grado de relación lineal
entre las variables es cero o muy débil.
Ejemplo Práctico:
Comúnmente se cree que existe una fuerte relación entre los años de estudio de una persona
con el salario que recibe en su trabajo. Por lo mismo se le pide a usted que determine si es
efectiva esta afirmación y si realmente más años de estudio implican un mejor salario. Para
ello se utilizará una base de datos que contiene información sobre salario actual, salario
inicial, años de educación y años de experiencia previa de 30 trabajadores de distintas
empresas. La base de datos se encuentra en el archivo “BaseDatosC8.sav”
1. En el menú “Analizar”, se debe ubicar el mouse sobre el menú “Correlaciones” y
posteriormente se debe escoger el tipo “Bivariadas”, que corresponde a
correlaciones para dos variables. Una nota importante es que para que este tipo de
análisis tenga sentido se debe tratar de utilizar variables con unidad de medida de
Escala u Ordinales (aunque este último tipo podría generar problemas).
2. Una vez abierto el cuadro de diálogo, se debe escoger las variables entre las que se
desea determinar la correlación: en este caso se trata de las variables: “Años de
educación” y “Salario actual”. Una vez seleccionadas las variables, se deben
posicionar donde dice “Variables” (como muestra la figura) y se debe cerciorar que
se encuentra marcada la casilla “Pearson” dentro de “Coeficientes de correlación”.
Finalmente se debe hacer clic en el botón “Aceptar”.
Importar Datos de Microsoft Excel®
Una forma común de encontrar bases de datos es en formatos distintos a SPSS, como por
ejemplo Microsoft Excel (.xls), Para poder trabajar con bases de datos de otro software
primero se debe importar de manera de transformarla en datos comprensibles para SPSS.
La forma de hacer esto es la siguiente: Primero se debe ir al menú “Archivo \ Leer datos de
texto”. En la ventana que abre debemos seleccionar “Excel [.xls]” donde dice “Tipo” y
posteriormente buscar y seleccionar el archivo Excel que se desee importar.
Una vez seleccionado el archivo se debe hacer clic en el botón “Abrir” y se abrirá un nuevo
cuadro de diálogo.
Se recomienda dejar este diálogo tal cual aparece en el programa, pues generalmente
cambiar esto puede generar problemas al investigador cuando no comprende a cabalidad los
software que se están haciendo funcionar (SPSS y Excel). Hacer clic en el botón “Aceptar”
53
para continuar e importar los datos. Una vez seleccionado el archivo se debe hacer clic en
el botón “Abrir” y se abrirá un nuevo cuadro de diálogo. Una vez importados los datos
desde la planilla excel, se abrirá una ventana del “Editor de datos”.
Los usuarios pueden crear una amplia variedad de programas SPSS para satisfacer sus
necesidades de gestión de datos y análisis de necesidades. Se pueden guardar programas de
la sintaxis de SPSS para la exportación de datos de otra fuente, como una hoja de cálculo
Excel. Otros programas que se pueden guardar como sintaxis incluyen procedimientos para
las variables de la recodificación, fusión de archivos de datos o el cálculo de valores. Por
último, los usuarios pueden guardar los programas SPSS para los procedimientos
estadísticos de los cuales es capaz SPSS. Estos son desde simples estadísticas descriptivas
hasta regresiones multivariantes.
VENTAJAS DE SPSS
El programa utiliza una serie de cuadros de dialogo que permiten determinar las
acciones y seleccionar aquellos análisis útiles.
Potente herramienta para el cálculo estadístico.
Es un software rápido.
Permite un importantísimo ahorro de tiempo y esfuerzo, realizando en segundos un
trabajo que requeriría horas e incluso días.
Hace posible cálculos más exactos, evitando los redondeos y aproximaciones del
cálculo manual.
Permite trabajar con grandes cantidades de datos, utilizando muestras mayores e
incluyendo más variables.
Permite trasladar la atención desde las tareas mecánicas de cálculo a las tareas
conceptuales: decisiones sobre el proceso, interpretación de resultados, análisis
crítico.
DESVENTAJAS DE SPSS
Si el usuario no tiene experiencia previa utilizando SPSS o si sus conocimientos de estadísticas no están actualizados es difícil discernir que opciones seleccionar.
La mayoría de los reportes de resultados contiene un nivel excesivo de información
que muchas veces confunde al usuario.
Posee una gran cantidad de información en forma automática que distrae al usuario.
El aprendizaje del manejo de paquetes de programas estadísticos requiere un cierto
esfuerzo.
A veces, la capacidad de cálculo del evaluador supera la capacidad para comprender
el análisis realizado e interpretar los resultados.
Lleva a veces a una sofisticación innecesaria, al permitir el empleo de técnicas
complejas para responder a cuestiones simples.
54
CONCLUSIÓN
Statistical Package for the Social Sciences (SPSS) como programa
estadístico informático muy usado en las ciencias sociales y las empresas de investigación
de mercado, es de gran ayuda para muchas personas, además, es uno de los programas con
mayor uso en el continente americano, este permite manejar datos de gran magnitud y
efectuar análisis estadísticos muy complejos, en general hacer un mejor uso de la
información capturada en forma electrónica y rápida.
Un programa SPSS permite a un usuario llevar a cabo el mismo procedimiento en repetidas
ocasiones, sin tener que recordar los menús desplegables o los comandos que debe hacer
clic y elegir con el fin de establecer la serie de los procedimientos necesarios. Esto ahorra
tiempo al organizar y analizar los datos. Estos programas también pueden ser modificados
para funcionar con diferentes modelos estadísticos, analizar diferentes variables o acceder a
archivos de datos diferentes. Para ejecutar un programa, simplemente haz clic en la sintaxis
y arrastra para resaltarlo. Después de esto, haz clic en el comando "execute" (ejecutar), una
clave en forma de flecha en el menú de archivo de sintaxis.