18
Biohackathon 2015 Europe PubMed Central and Linked Data Jee-Hyub Kim 0000-0002-0359-2887 Nagasaki 13 Sep 2015
| Date post: | 13-Apr-2017 |
| Category: |
Data & Analytics |
| Upload: | jee-hyub-kim |
| View: | 371 times |
| Download: | 0 times |

Biohackathon 2015
Europe PubMed Central and Linked Data
Jee-Hyub Kim0000-0002-0359-2887
Nagasaki 13 Sep 2015

Contents
● Europe PubMed Central● Linking Literature● Mining Identifiers● Publishing Mined Identifiers on RDF● Web Annotation Data Model● Use Case for Database Curation

Europe PubMed Central
● Europe PMC is a literature database○ Abstracts: 30 million PubMed, Agricola and patent
records, updated daily○ Full text articles: over 3 million full text articles, of
which over 900,000 are free to read and reuse, updated daily

Services in Europe PMC
● RESTful web service:○ http://europepmc.org/RestfulWebService○ Text-mined terms, metadata, full text
● ORCID article claiming tool● Embassy Cloud for 3rd party contents providers● BioJS literature module: http://biojs.io/d/biojs-vis-
pmccitation● RSS

Linking Literature
● Europe PMC provides various types of linking methods○ By external links: to any URL (e.g., database,
Wikipedia, press release, etc.)○ By text mining
■ Biological entities■ Identifiers (e.g., accession numbers)
○ By ORCID (article claims)● 24 external links providers, 1 ORCID, 9 cross-reference
DBs, 20 DB identifiers, 6 named entity types
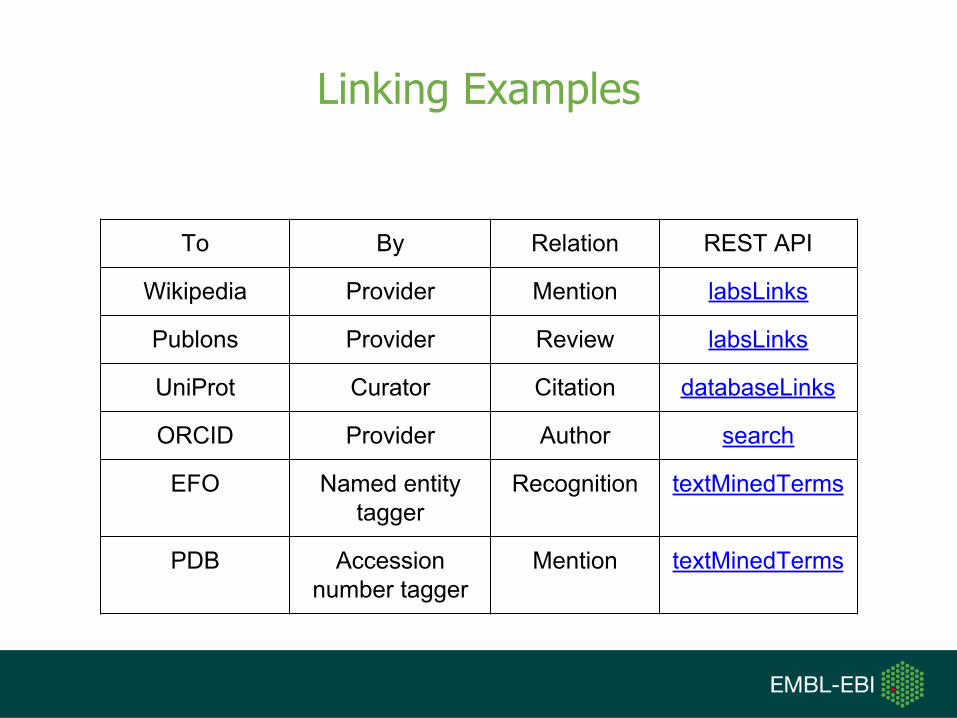
Linking Examples
To By Relation REST API
Wikipedia Provider Mention labsLinks
Publons Provider Review labsLinks
UniProt Curator Citation databaseLinks
ORCID Provider Author search
EFO Named entity tagger
Recognition textMinedTerms
PDB Accession number tagger
Mention textMinedTerms

Mining Identifiers in Free Text
● Motivation○ Started for cross-linking with EBI databases○ Data citation, impact analysis○ Now, moving for linked data
● We use patterns from identifiers.org and link back to it.● A IE problem: ID matching + NER for resource names● Some ambiguities
○ PDB: 4min○ OMIM and ERC funding id: both 6-digit numbers○ Resource name variations: UniProt, Swiss-Prot, etc.
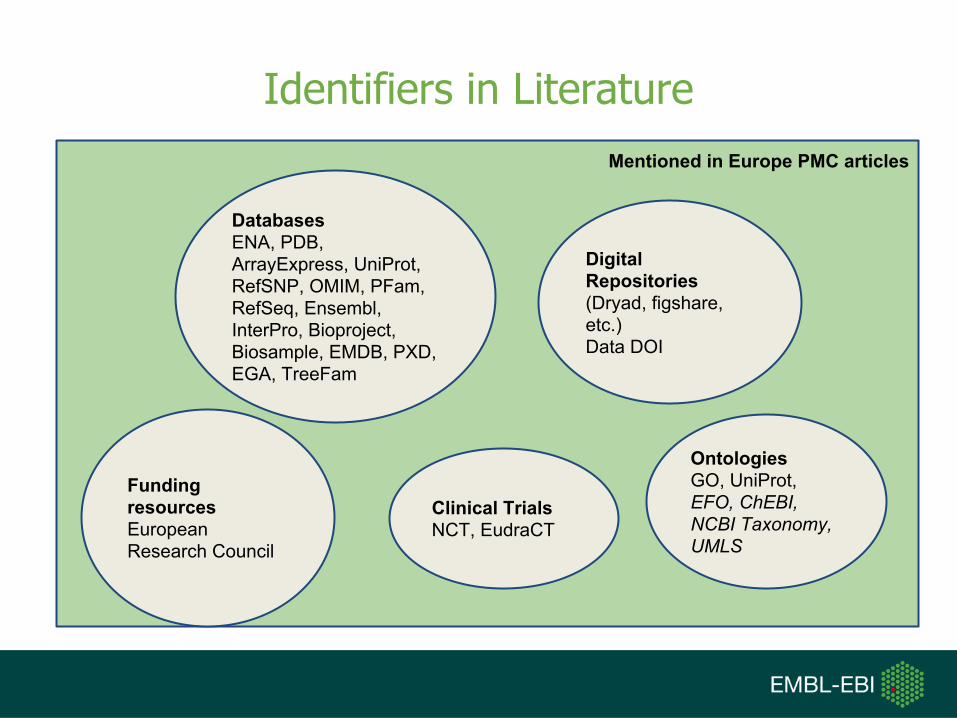
Mentioned in Europe PMC articles
Identifiers in Literature
DatabasesENA, PDB, ArrayExpress, UniProt, RefSNP, OMIM, PFam, RefSeq, Ensembl, InterPro, Bioproject, Biosample, EMDB, PXD, EGA, TreeFam
Funding resourcesEuropean Research Council
OntologiesGO, UniProt, EFO, ChEBI, NCBI Taxonomy, UMLS
Clinical TrialsNCT, EudraCT
Digital Repositories (Dryad, figshare, etc.)Data DOI
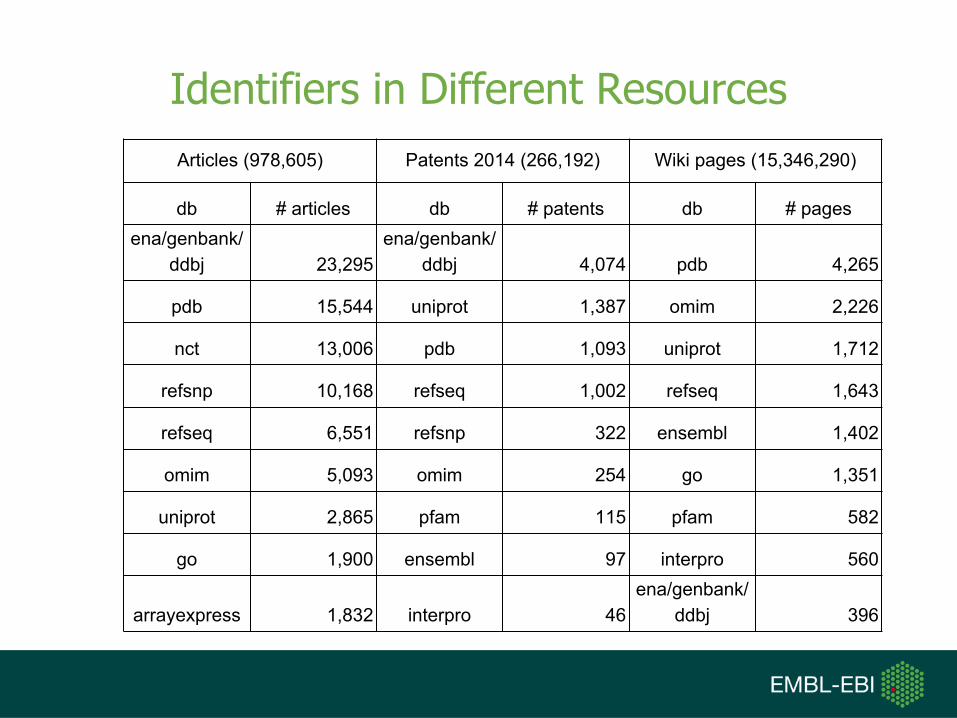
Identifiers in Different ResourcesArticles (978,605) Patents 2014 (266,192) Wiki pages (15,346,290)
db # articles db # patents db # pagesena/genbank/
ddbj 23,295ena/genbank/
ddbj 4,074 pdb 4,265
pdb 15,544 uniprot 1,387 omim 2,226
nct 13,006 pdb 1,093 uniprot 1,712
refsnp 10,168 refseq 1,002 refseq 1,643
refseq 6,551 refsnp 322 ensembl 1,402
omim 5,093 omim 254 go 1,351
uniprot 2,865 pfam 115 pfam 582
go 1,900 ensembl 97 interpro 560
arrayexpress 1,832 interpro 46ena/genbank/
ddbj 396

Publishing Identifiers on RDF
● Goals○ More connectivity○ More provenance for each linking
■ PMCID, sentence, section label, etc.○ Links to share and comment (e.g., hypothes.is)
● Challenges:○ How to model? Web Annotation Data Model.○ dealing with nearly a billion annotations generated
automatically in a large scale

Web Annotation Data Model
● Built on the top on RDF● Annotations as resources● To provide a standard description mechanism for
sharing annotations between systems● For more general purpose use
○ Not only for text mining○ For example, YouTube video comments (by people),
image annotation, etc.○ W3C Working Draft

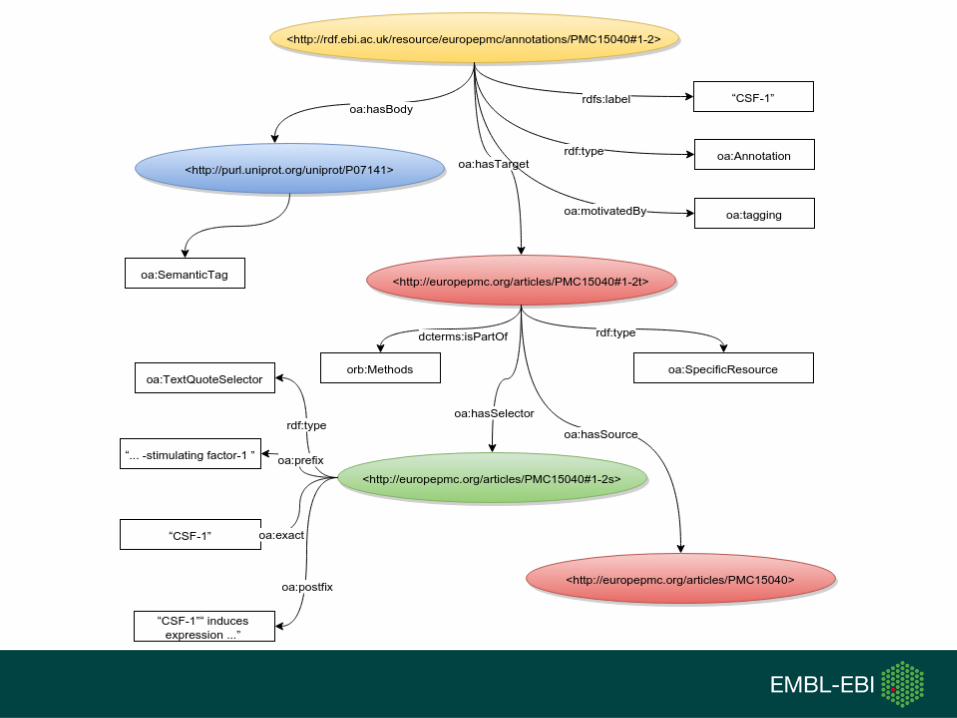
Core Annotation Framework
● Typically an Annotation has a single Body, which is the comment or other descriptive resource, and a single Target that the Body is somehow "about".
● The Body provides the information which is annotating the Target.
● This "aboutness" may be further clarified or extended to notions such as classifying or identifying.

Text-Mining RDF Service
● Running on EBI RDF Platform● Stores 1,563,241,810 triples text-mined from 400,746
Open Access articles in Europe PubMed Central.● Provides
○ for each article, all the annotations linking to ontologies/databases
○ with contexts:■ sentences■ section information

Use Case for Database Curation
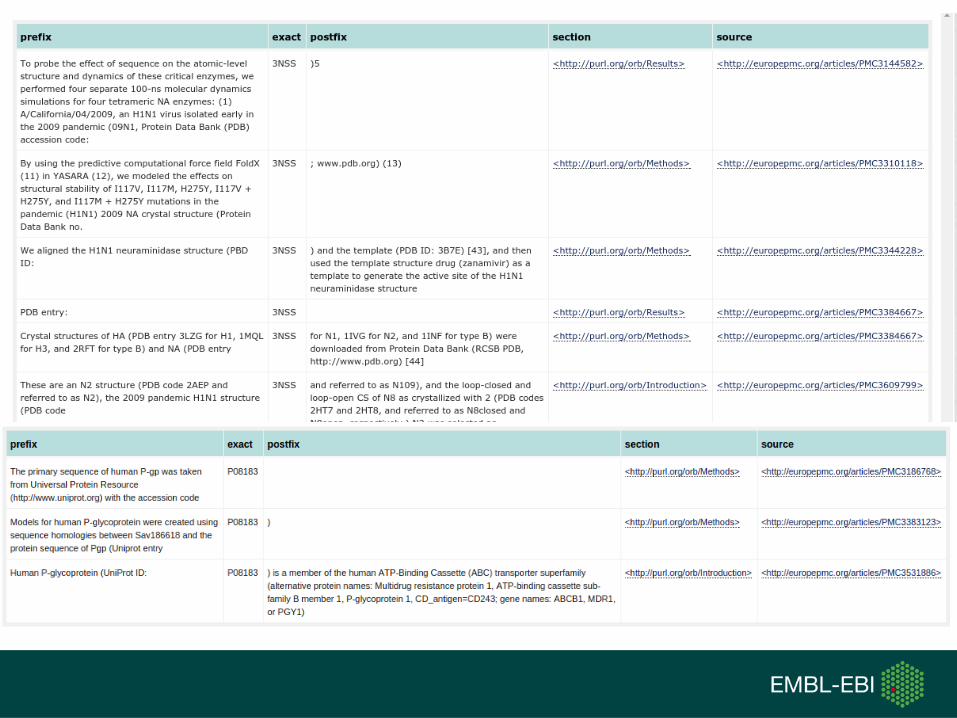
● Given an database identifier, provides sentence-level information for database curation.○ Show all the articles where a PDB accession number
3NSS is mentioned.○ Show all the annotations with each its label in
PMC3382907.○ Show all the articles where inflammatory bowel
disease (C0021390) is mentioned.● http://wwwdev.ebi.ac.uk/rdf/services/textmining/sparql

Plans for BioHackathon 2015
● Integration with other SPAQL endpoints
● Interoperability with other formats used in text-mining community○ e.g., BioC, UIMA
● Produce more links on RDF

References
Europe PMC Consortium. Europe PMC: a full-text literature database for the life sciences and platform for innovation. Nucleic Acids Res. 2015 Jan;43(Database issue) D1042-8. doi:10.1093/nar/gku1061. PMID: 25378340; PMCID: PMC4383902.
Kafkas Ş, Kim JH, McEntyre JR. Database citation in full text biomedical articles. PLoS One. 2013;8(5) e63184. doi:10.1371/journal.pone.0063184. PMID: 23734176; PMCID: PMC3667078.
Juty N, Le Novère N, Laibe C. Identifiers.org and MIRIAM Registry: community resources to provide persistent identification. Nucleic Acids Res. 2012 Jan;40(Database issue) D580-6. doi:10.1093/nar/gkr1097. PMID: 22140103; PMCID: PMC3245029.

















