Evaluating the stability of SIFT keypoints across cameras Max Van Kleek Agent-based Intelligent Reactive Environments MIT CSAIL [email protected]ABSTRACT Object identification using Scale-Invariant Feature Transform (SIFT) keypoints requires stable keypoint signatures that can be reliably reproduced across variations in lighting, viewing angle, as well as camera imaging characteristics. While re- producibility has been demonstrated under various lighting and viewing angles elsewhere, this work performs an empir- ical evaluation of the reproducibility of SIFT keypoints and the stability of their corresponding feature signatures across a variety of camera configurations within a controlled light- ing and scene arrangement. INTRODUCTION The general problem of object recognition has been an im- portant goal of the machine vision research field since its inception. Over the past decade, with the progressive devel- opment of lower-cost, high-performing computers that re- quire less power and occupy less physical space, along with advancements that have yielded lower-cost and smaller cam- eras, it has become feasible to implement vision-based sys- tems and embed them nearly everywhere, to provide peo- ple practical assistance on a wider variety of tasks than ever previously feasible. At the same time, these applications have placed new demands on vision algorithms to perform robustly and to recognize a larger variety of objects in a wider variety of lighting and scene conditions with the same or greater reliability than previously demonstrated, using a greater variety of imaging technologies. Similar exponential advances in communications technology, in particular low- cost, high-bandwidth, and wireless networking has made it possible for applications requiring the use of multiple com- puters distributed physically or with distributed resources to more easily coordinate and solve particular tasks. As these applications become increasingly pervsaive, cer- tain robustness to variations in imaging devices will also be- come a necessity. For example, vision-enabled applications intended for home use or for their mobile handset will need to use whatever commodity image capture hardware is al- ready available on users’ PCs or cell phones, respectively. Likewise, distributed vision applications may need to pull image data from multiple heterogeneous imaging devices. This paper presents an evaluation of a popular object recog- nition technique across a number of popular commodity im- age capture devices that are readily available today. BACKGROUND One particular technique that has recently gained attention due to successful demonstrations of being applied to rec- ognizing both object instances [2] and identifying objects’ classes [1] is the use of robust local feature descriptors. Tech- niques that involve local features first identify a small set of salient keypoints which are likely to capture interesting in- formation in an image about an object, analyzing the statis- tics around these keypoints and associating the set with a particular object. Then, the object may be identified given any new image, by locating and matching up corresponding keypoints from those previously associated with objects. In particular, the Scale Invariant Feature Transform (SIFT), proposed by David Lowe, selects candidate keypoints by searching images at multiple scales for points that are likely to be highly localizable, and then labels each keypoint using a signature derived from gradients around the keypoint. By then associating sets of these keypoints and accompanying signatures with the object, the object can later be identified by merely identifying the corresponding same set of key- points and features in a new image. The single most important characteristic of these keypoints and signatures to enable reliable object recognition is the re- producibility of the keypoints across a variety of image vari- ations that are likely to affect how an object is perceived. That is, the criterion about whether to choose a particular keypoint should related to how likely to be able to be de- tected and consistently identified in future images under vari- ations in lighting, viewing angle/object orientation, lens dis- tortion, and image noise. Lowe empirically analyzed the sensitivity of the SIFT keypoints to object rotation, particu- larly off-axis to the image plane in a recent paper [2]. Miko- lajczyk et al. examined SIFT keypoint performance along changes in lighting direction and intensity [3]. However, lit- tle work has previously surrounded keypoint reproducibility across variations in cameras, across either physical imaging characteristics, such as lens, aperture and imager configura- tion, or performance characteristics of the imager, such as sensitivity, resolution and noise level. This work attempts to provide initial insight into SIFT performance across a range 1
Transcript
Evaluating the stability of SIFT keypoints across cameras
Max Van KleekAgent-based Intelligent Reactive Environments
ABSTRACTObject identification using Scale-Invariant Feature Transform(SIFT) keypoints requires stable keypoint signatures that canbe reliably reproduced across variations in lighting, viewingangle, as well as camera imaging characteristics. While re-producibility has been demonstrated under various lightingand viewing angles elsewhere, this work performs an empir-ical evaluation of the reproducibility of SIFT keypoints andthe stability of their corresponding feature signatures acrossa variety of camera configurations within a controlled light-ing and scene arrangement.
INTRODUCTIONThe general problem of object recognition has been an im-portant goal of the machine vision research field since itsinception. Over the past decade, with the progressive devel-opment of lower-cost, high-performing computers that re-quire less power and occupy less physical space, along withadvancements that have yielded lower-cost and smaller cam-eras, it has become feasible to implement vision-based sys-tems and embed them nearly everywhere, to provide peo-ple practical assistance on a wider variety of tasks than everpreviously feasible. At the same time, these applicationshave placed new demands on vision algorithms to performrobustly and to recognize a larger variety of objects in awider variety of lighting and scene conditions with the sameor greater reliability than previously demonstrated, using agreater variety of imaging technologies. Similar exponentialadvances in communications technology, in particular low-cost, high-bandwidth, and wireless networking has made itpossible for applications requiring the use of multiple com-puters distributed physically or with distributed resources tomore easily coordinate and solve particular tasks.
As these applications become increasingly pervsaive, cer-tain robustness to variations in imaging devices will also be-come a necessity. For example, vision-enabled applicationsintended for home use or for their mobile handset will needto use whatever commodity image capture hardware is al-ready available on users’ PCs or cell phones, respectively.
Likewise, distributed vision applications may need to pullimage data from multiple heterogeneous imaging devices.This paper presents an evaluation of a popular object recog-nition technique across a number of popular commodity im-age capture devices that are readily available today.
BACKGROUNDOne particular technique that has recently gained attentiondue to successful demonstrations of being applied to rec-ognizing both object instances [2] and identifying objects’classes [1] is the use of robust local feature descriptors. Tech-niques that involve local features first identify a small set ofsalient keypoints which are likely to capture interesting in-formation in an image about an object, analyzing the statis-tics around these keypoints and associating the set with aparticular object. Then, the object may be identified givenany new image, by locating and matching up correspondingkeypoints from those previously associated with objects.
In particular, the Scale Invariant Feature Transform (SIFT),proposed by David Lowe, selects candidate keypoints bysearching images at multiple scales for points that are likelyto be highly localizable, and then labels each keypoint usinga signature derived from gradients around the keypoint. Bythen associating sets of these keypoints and accompanyingsignatures with the object, the object can later be identifiedby merely identifying the corresponding same set of key-points and features in a new image.
The single most important characteristic of these keypointsand signatures to enable reliable object recognition is the re-producibility of the keypoints across a variety of image vari-ations that are likely to affect how an object is perceived.That is, the criterion about whether to choose a particularkeypoint should related to how likely to be able to be de-tected and consistently identified in future images under vari-ations in lighting, viewing angle/object orientation, lens dis-tortion, and image noise. Lowe empirically analyzed thesensitivity of the SIFT keypoints to object rotation, particu-larly off-axis to the image plane in a recent paper [2]. Miko-lajczyk et al. examined SIFT keypoint performance alongchanges in lighting direction and intensity [3]. However, lit-tle work has previously surrounded keypoint reproducibilityacross variations in cameras, across either physical imagingcharacteristics, such as lens, aperture and imager configura-tion, or performance characteristics of the imager, such assensitivity, resolution and noise level. This work attempts toprovide initial insight into SIFT performance across a range
1
Model DetectorType
Interface and Price
Logitech QuickCamExpress
CMOS,352x288
USB, 24-bit Color($15 USD)
Logitech QuickCamPro 3000
CCD,640x480
USB, 24-bit Color($50 USD)
Sony EVI-D30 CCD,NTSC
S-Video, digitizedusing Pinnacle Mi-cro DV capture de-vice ($959 USD)
Nikon Coolpix 990 CCD,2048x1536
Digital still cam-era ( $500 USD)
Table 1. Cameras used and their specifications
of cameras through a series of experiments.
EXPERIMENT
SetupTo determine the reproducibility of SIFT keypoints and asso-ciated signatures across variations of camera type, four cam-eras were selected, that varied widely in type, approximatemarket price, and specifications. As can be seen in Table ,cameras included two widely available low-end USB web-cams, to an analog S-Video NTSC video camera digitizedinto DV, to a high-end consumer-grade digital still camera.Images were either directly captured into 320x240 resolution(for the webcams), or downsampled after being captured atthe devices’ native resolution.
Each camera was taken and mounted on a tripod in an iden-tical fashion at a fixed location in a room. Five incandescentlights were placed behind the camera, which was pointed atthe subject at a distance of 12 feet (for the human subject)and 3 feet (for the toy robot). The pictures of the subjectof each of the images were taken against a white wall in thelaboratory. For each of the four cameras and the two con-ditions (human and toy robot), 16 images were taken: 10 ofbackground without a subject (for background subtraction),2 with the subject/object facing front in the center of the im-age, and 1 each with the subject/object facing approximately25 and 45 degrees away from frontal-parallel to the left of thecamera, 1 each of the subject/object facing approximately 25and 45 degrees away from frontal-parallel to the right of thecamera, respectively. Samples of the frontal-parallel posefor each camera are shown in figure 1.
ProcedurePrior to SIFT keypoint detection, images from each cam-era were batch-loaded, and converted to greyscale by av-eraging the red, green and blue pixel intensities for eachpixel. Background images were separated from the rest.Contrast stretching was then performed across the whole setuniformly, by taking the minimum and maximum pixel in-tensities across all images and scaling the intermediate val-ues to occupy the whole range.
Background elimination
Figure 1. Front pose for human subject using (clockwisefrom the top-left): qcexpress, qc pro, nikon coolpix, andSony NTSC.
Figure 2. Background elimination (left), mask generatedby dilation with a disk of r = 5 pixels (right)
To compute a background model, the mean and variance foreach pixel was computed across the background images. Tosegment foreground from background then, each pixel in theremaining images of the set were compared against a normaldistribution centered at the corresponding mean and with thecorresponding covariance of the pixel in model. Pixels thatwere less likely than a threshold value (ε = 0.1) accord-ing to this model were labeled as foreground; otherwise thepixel was labeled as background. An example of runningthis algorithm on an image can be seen in Figure 2. As canbe seen by the image on the left, our background elimina-tion procedure occasionally left holes where the foregroundapproached the color of the white wall. To ”fill in” theseoccasional mistakes, the mask was dilated with a disk struc-turing element of radius 5 pixels. This effectively completedthe regions for all of our test images, as can be seen by theresulting mask on the right.
Keypoint identificationCandidate keypoints were selected by searching a difference-of-gaussian (DoG) pyramid an octave at a time, selecting lo-cal maxima that have an intensity above a threshold (t =0.08). To filter out edges, the Hessian was computed fromimage gradients at the candidate keypoint, and was rejectedif ratio of eigenvalues of the Hessian is too large (R = 10).Candidates that fell outside the foreground mask (computed
2
from the background model, above) were also eliminated, topreserve only keypoints that pertain to the foreground.
SIFT feature extractionSIFT features were computed by first finding thekeypointorientation, which consisted of the dominant gradient overa window (size=16x16) centered at that keypoint. All possi-ble gradient orientations during this process were discretizedinto a discrete set of N orientations (N = 16). Magnitudesof gradients of pixels within the window were weighted by a2D gaussian of covarianceσ, (whereσ was assigned as halfthe width of the descriptor window), centered over the key-point and summed. The orientation assigned to the keypointwas then this overall weighted sum direction, discretized tothe nearest bin.
After the keypoint orientation was assigned for a particularkeypoint, the window for that keypoint was divided intoqequally sized regions. A weighted histogram count of orien-tations was performed for each of these regions separately,taking the keypoint orientation as orientation 0. The resultsof this histogram count were then concatenated on the restof the histogram counts, to form the SIFT feature vector ofthis keypoint, a single large vector of counts of sizeN ∗ q.
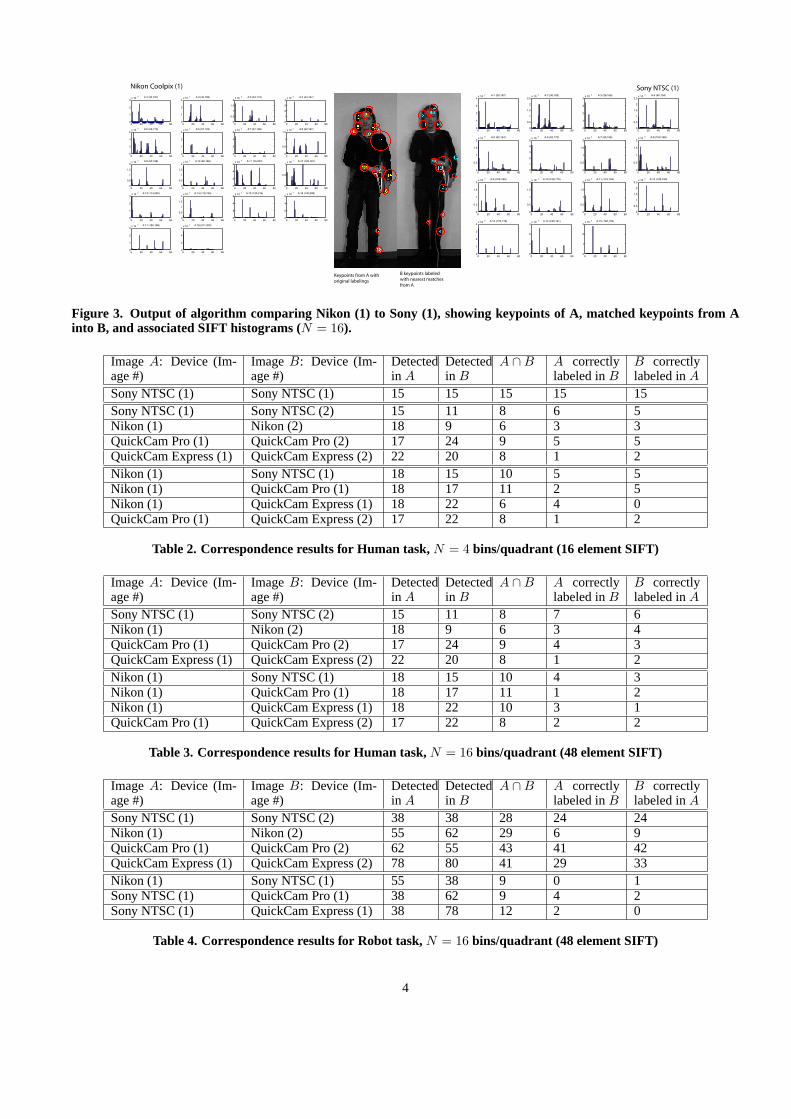
Keypoint matchingAfter the keypoints and feature vectors were computed fortwo images, we determined how many keypoints were re-produced from one image to the next by matching SIFT fea-ture vectors between images. For each of the keypoints inthe first image,A, we found the SIFT keypoint in the sec-ond image,B, whose feature vector wasmost similar(in aEuclidean distance sense) to that of the keypoint inA, andassigned the keypoint inA, B’s label. Then, these keypointswere labeled and plotted with their associated histograms,and compared visually as can be seen in Figure 3. To seehow keypoints in A corresponded to those back in B, then,the process was repeated back by taking every keypoint in Band finding its nearest neighbor in A.
RESULTSIn order to evaluate the performance of our version of thealgorithm, the algorithm was run on pairs of images (whichwe will call A andB) from our set. Each pair produced fourimages: keypoints inA labeled with their original labels,keypoints inA labeled with the labels of their closest coun-terparts fromB, keypoints inB labeled with their originallabels, and keypoints inB labeled with their closest counter-parts fromA. They keypoints inA with their original label-ings were then compared with keypoints inB labeled withtheir closest counterparts inA, and vice-versa. This outputwas manually analyzed for five different counts: (1) numberof keypoints detected inA, (2) number of keypoints detectedin B, (3) intersection of keypoints detected inA with thosedetected inB (4) number of keypoints fromA that were de-tected inB and correctly labeled, (5) number of keypointsin B that were detected inA and corrrectly labeled. Thesecorrespond to columns 3-7 of Table 2.
To first determine a baseline of how well our algorithm func-
tioned, we first studied the reproducibility of keypoints amongpairs of images taken with the same camera. The results canbe seen for each camera on the top half of Table 2. Then,we studied cross-camera reproducibility for certain combi-nations of cameras, as can be seen in the second section ofthe table. The experiments were then repeated with a largervalue of gradient bins, this timeN = 16, yielding a totalSIFT vector size of 48. Results from this second set of ex-periments are available in Table 3.
The off-axis rotation images (of both 25 and 45 degrees)yielded no keypoint reproducibility, and therefore labelingperformance could not be compared. Due to time constraints,further analysis of the off-axis images were left for futurework.
DISCUSSIONWe must be careful about drawing any broad conclusionsabout the performance of SIFT, given the results of our ex-periment, for a number of reasons. First, due to time andresource constraints, the number of images we were able toexperiment with per camera was extremely small. Second,we used only two subjects in our experiment, a human formwearing black clothing, whose posture was slightly differenteach time, and a bright, plastic toy robot which remainedperfectly rigid and motionless between conditions. This isnot, by any means, anywhere near representative of the broadpotential uses of local feature descriptors. Third, there are alarge number of parameters that need to be set in the SIFTalgorithm. Although we attempted to set all the parametersto “sensible” settings, either by using the same values de-scribed by Lowe, or by guessing a value, we were not ableto, due to time constraints, tune each of the parameters toexplore how performance would be affected. These param-eters included the keypoint window size, gaussian windowweight covariance, number of gradient bins, DoG pyramidstep-size, DoG pyramid levels, edge detection threshold, andinitial image blurring amount. Finally as will be describedin future work, we did not have time to evaluate the per-formance of several of the enhancements to the algorithm,suggested by Lowe.
However, if we compare the performance of our naive imple-mentation of SIFT across our experimental conditions, wemay come up with several hypotheses that may make use-ful predictive heuristics for practically implementing objectrecognition systems using SIFT. Our first observation wasthat keypoint detection and label matching performed verydifferently. Label matching was consistently higher (if weconsider number of matches / number of keypoints repro-duced) in same-camera experiments than between differentcameras. However, this trend was not observed with justkeypoint reproduction, which worked approximately equallywell in within-camera and between-camera condition. Infact, particularly for the series of experiments withN = 16,between-camera keypoint reproduction was generally higherthan between-cameras! However, since the number of im-ages is so small, this is not a significant result. On the within-same-camera human task withN = 4, an average of 49% ofkeypoints were reproduced within camera, and out of those
3
0 20 40 60 800
1
2
3x 10 3 A:1 (34,187)
0 20 40 60 800
1
2
3x 10 3 A:2 (40,183)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:3 (43,173)
0 20 40 60 800
1
2
3
4x 10 3 A:4 (54,197)
0 20 40 60 800
2
4
6x 10 4 A:5 (56,173)
0 20 40 60 800
1
2
3x 10 3 A:6 (57,193)
0 20 40 60 800
2
4
6x 10 3 A:7 (61,198)
0 20 40 60 800
0.5
1
1.5x 10 3 A:8 (62,167)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:9 (62,168)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:10 (65,186)
0 20 40 60 800
2
4
6x 10 4 A:11 (74,202)
0 20 40 60 800
0.5
1x 10 3 A:12 (109,181)
0 20 40 60 800
1
2
3x 10 3 A:13 (114,200)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:14 (116,194)
0 20 40 60 800
2
4
6x 10 3 A:15 (120,214)
0 20 40 60 800
2
4
6x 10 3 A:16 (140,208)
0 20 40 60 800
1
2
3x 10 3 A:17 (192,198)
0 20 40 60 800
2
4
6x 10 3 A:18 (217,200)
0 20 40 60 800
1
2
3
4x 10 3 A:1 (30,167)
0 20 40 60 800
0.5
1
1.5
2
2.5x 10 3 A:2 (36,163)
0 20 40 60 800
1
2
3
4x 10 3 A:3 (36,166)
0 20 40 60 800
0.5
1
1.5
2
2.5x 10 3 A:4 (40,154)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:5 (52,154)
0 20 40 60 800
1
2
3
4
5x 10 3 A:6 (52,173)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:7 (95,196)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:8 (100,168)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:9 (104,180)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:10 (109,175)
0 20 40 60 800
0.5
1
1.5
2x 10 3 A:11 (119,194)
0 20 40 60 800
0.5
1
1.5
2
2.5x 10 3 A:12 (135,180)
0 20 40 60 800
1
2
3
4x 10 3 A:13 (170,179)
0 20 40 60 800
1
2
3x 10 3 A:14 (180,161)
0 20 40 60 800
1
2
3x 10 3 A:15 (192,176)
Nikon Coolpix (1) Sony NTSC (1)
B keypoints labeledwith nearest matchesfrom A
Keypoints from A withoriginal labelings
Figure 3. Output of algorithm comparing Nikon (1) to Sony (1), showing keypoints of A, matched keypoints from Ainto B, and associated SIFT histograms (N = 16).
Table 4. Correspondence results for Robot task,N = 16 bins/quadrant (48 element SIFT)
4
Figure 4. Toy robot detection results comparing Sony NTSC Camera and matched keypoints from QuickCam Pro
reproduced keypoints, on average 48% were recovered. Be-tween cameras, 49% of the original keypoints were recov-ered, and out of those an average of 33% were properly la-beled. ForN = 16 within-cameras yielded a 49.3% cor-rect assignment, whereas between cameras was significantlyworse, 23.4%. In the robot condition, same-camera task,with N = 16, an average of 62.3% were recovered, andout of those 70% were recovered. However, in the between-camera task, reproducibility was much lower at 20%, out ofwhich an average of only 16 % were properly labeled.
The differences between the human and robot experimentsare likely due to a number of factors. First, since the robotwas completely rigid, unlike the human, its appearance changedlittle between shots with the same camera. This is likely toexplain the extremely high reproducibility rate and labelingaccuracy in the within-camera experiment. It was somewhatperplexing why the labelings nor the reproducibility rate be-tween the identical-looking shots using the same camera wasnot 100%, as we might expect. Whether this is due to animperceptible shifting of the camera, or some similarly im-perceptible difference with how the camera imaged the twoinstances, there was no way to tell within our experiment.However, between cameras, we saw a decrease in both re-producbility and in labeling, compared to the human. Thereare several explanations for why the labelling is more chal-lenging in the robot condition. First, there are many morekeypoints, and therefore it is inherently more challenging(less likely) to randomly choose the right keypoint. But moresignificant is the effect of an abundance of keypoints withsimilar statistics. There are many keypoints that correspondto locations on the robot that look like other locations: suchas the arms and the knees. Another difference between therobot task and the human task was that the robot task wassignificantly positively impacted by changing the number ofgradient bins fromN = 4 to N = 16. (There was no correctlabeling on the robot task withN = 4.) By contrast, the per-formance on reproducing keypoints for the human subjectfared slightly worse with larger N.
FUTURE WORK
The simple implementation of SIFT we used for these exper-iments did not contain any of the keypoint management thatwas recommended by Lowe [2]. Namely, for each keypointdetected, this implementation naively created a new SIFTkeypoint with accompanying signature, without comparingthe similarity of the new keypoint to existing keypoints inour set. For objects that are likely to have recurring, sim-ilar looking regions (for example, the robot’s knees), thesekeypoints should all be assigned the same label. Since therobot had many regions of similar appearance, this is themost likely cause of the low reproducibility observed in thebetween-camera robot condition. This sort of merging couldbe done during the detection, or by clustering the SIFT vec-tors post-hoc, using an algorithm such ask-means.
The other recommendation made by Lowe dealt with choos-ing the primary orientation for the keypoint. If the initialweighted voting for the primary orientation of the keypointwas close to a tie, Lowe’s improvement created multiple key-points with the various orientations that yielded the tie. Thisindeed seems like a wise choice, to reduce the susceptibilityof choice of keypoint direction to noise.
CONCLUSIONThis study demonstrated that although SIFT keypoint repro-ducibility and signature correspondence were sensitive tocamera variations, correspondence was still possible. Dueto the generally low reproducibility of keypoints, it may benecessary for applications to build robust models and rely onmany redundant keypoints. Lowe has demonstrated that ob-ject recognition for certain applications may be possible byidentifying as few as 3 keypoints on an image
Another interesting result was there was no clear “winner”,with respect to which single camera performed the best inour experiment. The CMOS sensor based camera, the Quick-Cam express, consistently underperformed the rest, whichwere CCD based cameras. Since most digital cameras em-bedded in mobile devices are CMOS-based, this may haveimportant implications regarding the use of SIFT-based vi-sion algorithms on these devices.
5
ACKNOWLEDGEMENTSI would like to thank Bill Freeman and Xiaoxu Ma and mycolleagues in 6.869 for an extremely fun and memorableclass.
RESOURCESThe code and data set for this paper may be downloaded athttp://people.csail.mit.edu/˜emax/6.869/scift . Please contact the author with any questions orcomments.
REFERENCES1. S. Helmer and D. G. Lowe. Object recognition with
many local features.Workshop on Generative ModelBased Vision, 2004.
2. D. G. Lowe. Distinctive features from scale-invariantkeypoints.International Journal of Computer Vision,2004.
3. K. Mikolajczyk and C. Schmid. A performanceevaluation of local descriptors.Computer Vision andPattern Recognition, 2003.











![MSCOCO Keypoints Challenge 2017 - cocodataset.orgpresentations.cocodataset.org/COCO17-Keypoints-Megvii.pdfIs Hourglass good for COCO keypoint ResNet-FPN-like[1]network works better](https://static.documents.pub/doc/80x56/5f18bc4e82aff242ab772479/mscoco-keypoints-challenge-2017-is-hourglass-good-for-coco-keypoint-resnet-fpn-like1network.jpg)










