64
Evaluation of Offset Assignment Heuristics Johnny Huynh, Jose Nelson Amaral, Paul Berube University of Alberta, Canada Sid-Ahmed-Ali Touati Universite de Versailles, France
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 0 times |

Evaluation of Offset Assignment Heuristics
Johnny Huynh, Jose Nelson Amaral, Paul BerubeUniversity of Alberta, Canada
Sid-Ahmed-Ali TouatiUniversite de Versailles, France

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Background
• Digital Signal Processors (DSPs) have few general purpose registers
• Program variables kept in memory• Address Registers (AR) used to access
variables• After a variable is accessed, the AR can be
auto-incremented (or decremented) by one word in the same cycle.

Processor Model
• Texas Instruments TMS320C54X DSP family:• Accumulator-based DSP• 8 Address Registers• Initializing an address register requires 2 cycles of
overhead• Explicit address computations require 1 cycle of
overhead• Using auto-increment (or auto-decrement) has no
overhead.

Processor ModelExample: add ‘A’ and ‘B’, store in accumulator
$AR0 = &A
$ACC = *$AR0
$AR0 = $AR0 + 2
$ACC += *$AR0
$AR0 = &A$ACC = *$AR0++$ACC += *$AR0
Explicit address computationAuto-Increment
A C B A B C0x1000 0x1001 0x1002 0x1000 0x1001 0x1002

Processor ModelExample: add ‘A’ and ‘B’, store in accumulator
$AR0 = &A
$ACC = *$AR0
$AR0 = $AR0 + 2
$ACC += *$AR0
$AR0 = &A$ACC = *$AR0++$ACC += *$AR0
Explicit address computationAuto-Increment
A C B A B C0x1000 0x1001 0x1002 0x1000 0x1001 0x1002

The Offset-Assignment Problem
• Given k address registers and a basic block accessing n variables, find a memory layout that minimizes address-computation overhead.
• How should the variables be placed in memory?• Which register should access each variable?

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Traditional Approach to Offset AssignmentAccess
Sequence
Address RegisterAssignment
Sub-SequenceSub-Sequence Sub-Sequence
Sub-Layout
Simple OffsetAssignment
Sub-Layout
Simple OffsetAssignment
Sub-Layout
Simple OffsetAssignment
Basic BlockGenerate
Access Sequence
Address-ComputationOverhead
Address-CodeGeneration

Traditional Approach:Simple Offset Assignment (SOA)• In 1992, Bartley introduced the simplest form of the offset
assignment problem:
Given a single address register and basic block with n variables, find a memory layout that minimizes overhead.
• Equivalent to finding a maximum weight path cover (NP-complete)• Many researchers have proposed heuristics for this problem:
• Liao et. al. (1996)• Leupers and Marwedel (1996)• Sugino et. al. (1996)

Simple Offset Assignment (SOA)•Fix the access sequence
•Assume only one address register (k = 1)
•Find an ordering of variables in memory (memory layout) that has minimum overhead.
AB
D
FC
E
22
2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layout:

Simple Offset Assignment (SOA)• Create Access Graph G = (V, E)
• V = variables
• weight of edge is the frequency of consecutive accesses
• A path defines a memory layout -- Find the Maximum Weight Path Cover
• NP-Complete!
AB
D
FC
E
22
2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layout:

Simple Offset Assignment (SOA)• Create Access Graph G = (V, E)
• V = variables
• weight of edge is the frequency of consecutive accesses
• A path defines a memory layout -- Find the Maximum Weight Path Cover
• NP-Complete!
AB
D
FC
E
22
2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layout: d a f c e b

Traditional Approach:General Offset Assignment (GOA)• Problem presented by Liao et. al. in 1996.• Given k address registers, and a basic block with n variables, find
an assignment of variables to address registers that minimizes the total overhead of all registers.
• This problem formulation is more accurately described as Address-Register Assignment (ARA).
• Consists of SOA problems, and is at least NP-hard.• Many researchers have proposed heuristics for address-register
assignment:• Leupers and Marwedel (1996)• Sugino et. al. (1996)• Zhuang et. al. (2003)

General Offset Assignment (GOA)
• Fix the access sequence• Allow multiple address registers (k>1)• Find an ordering of variables in memory
(memory layout) that has minimum overhead.
• Assign each variable to an address register to form access sub-sequences.
AB
D
FC
E
22
2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Sub-sequence1: ‘a b c b c a’
Sub-sequence2: ‘d e f e f d’

General Offset Assignment (GOA)
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Sub-sequence1: ‘a b c b c a’
Sub-sequence2: ‘d e f e f d’
• Each sub-sequence can be viewed as an independent SOA problem.
• Solve each sub-sequence as independent SOA problems.
• More appropriate to call this problem the Address Register Assignment (ARA) problem.
• Requires solving SOA instances, so is at least NP-hard.

General Offset Assignment (GOA)
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
• Each sub-sequence can be viewed as an independent SOA problem.
• Solve each sub-sequence as independent SOA problems.
• More appropriate to call this problem the Address Register Assignment (ARA) problem.
• Requires solving SOA instances, so is at least NP-hard.

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1

Address-Code Generation
• Recall that variables are assigned to address registers.
• There is nothing left to decide – each address register has a defined sequence of accesses.
• Imposes a restriction that all access to a variable is done by a single address register.
AB
D
FC
E2
2
Ex.
Access Sequence: ‘a d b e c f b e c f a d’
Memory Layouts: a b c d e f
AR0 AR1
*Requires Explicit Address Computations

‘a d b e c f b e c f a d’
‘a b c b c a’ ‘d e f e f d’
[a, b, c] [d, e, f]
Simple OffsetAssignment
Simple OffsetAssignment
Address Register Assignment
Sub-sequence and memory layout accessed by AR0
Sub-sequence and memory layout accessed by AR1
Traditional Approach to Offset Assignment

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Optimal Address-Code Generation
• Given a fixed access sequence and memory layout, it is possible to generate optimal addressing-code in polynomial time:
• Minimum-Cost Circulation (Gebotys, 1997)
• Minimum-Weight Perfect Matching (Udayanarayanan, 2000)

Optimal Address-Code Generation•Build a network-flow graph
•Vertices represent variable accesses
•For each access ai that occurs before another aj, there is an edge (ai,aj) (not all shown the graph).
•Edges represent an opportunity for a register to access variables.
•Each unit flow represents the accesses performed by an address register.
•Optimal Address-Code is found by finding a minimum-cost circulation.
Acc
ess
Se
qu
en
ce
Memory Layout
FEDACBAR2
AR1
D
A
F
C
E
B
F
C
E
B
D
A
a3
a5
a7
a9
a11
a12
a1
a2
a4
a6
a8
a10
S
T Capacity = number of ARs
Cost = initialization overhead
Outbound edges from S
Cost = 0
Inbound edges to T
Cost = 0
Edge costs
Dependent on distance
Between variables accessed
All vertices require
one unit of flow

Traditional Approach to Offset AssignmentAccess
Sequence
Address RegisterAssignment
Sub-Sequence
Sub-Layout
Simple OffsetAssignment
Address-ComputationOverhead
Address-CodeGeneration
Sub-Sequence
Sub-Layout
Simple OffsetAssignment
Sub-Sequence
Sub-Layout
Simple OffsetAssignment
NP-Hard
NP-Complete
Solved, but not used!

Memory Layout Permutations (MLP)• Since optimal address-code generation
algorithms exist, they can be applied after a memory layout is formed (by traditional approaches).
• However, the traditional approach generates multiple sub-layouts that were originally assumed to be independent.
• How is a single memory layout formed from a set of sub-layouts?

Memory Layout Permutations
• Let Mi be a memory sub-layout.
• Let Mir be the reciprocal of Mi
• Given an access sequence and m memory sub-layouts, arrange {(M1|M1
r),…,(Mm|Mmr)}, such
that overhead is minimum when the sub-layouts are placed contiguously in memory.
spermuation unique 2
)2)(!( are therelayouts,-sub ''given
mmm

Memory Layout Permutations
Example:
‘a d b e c f b e c f a d’
‘a b c b c a’ ‘d e f e f d’
{a, b, c} {d, e, f}
[a, b, c, d, e, f], [f, e, d, c, b, a][c, b, a, d, e, f], [f, e, d, a, b, c][a, b, c, f, e, d], [d, e, f, c, b, a][c, b, a, f, e, d], [d, e, f, a, b, c]
Simple OffsetAssignment
Simple OffsetAssignment
Address Register Assignment
Memory Layout Permutations
This is an optimal address register assignment
These are optimal simple offset assignments
All possible Memory Layout Permutations (all have cost > 4)
Optimal Layout: {b, c, a, d, e, f} with cost = 4 is not found

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Experimental MethodologyEvaluating the Solution Space
• Testcases are DSP code kernels from the UTDSP benchmark suite.
• Use gcc to obtain access sequences.• The quality of a memory layout is evaluated
using the minimum-cost circulation technique.• The entire solution space is found for each
access sequence, to be used as a point of reference.
Basic Block
Compile with gcc
AccessSequence
Distribution of Overheads
1
10
100
1000
10000
100000
1000000
5 6 7 8 9 10 11 12 13
Overhead (Cycles)
Frequency (Layouts)
Compute Overhead of All Layouts using Minimum-Cost FlowKernel Accesses Variables Possible #
of layouts
iir_arr 21 8 20,160
iir_arr_swp 33 12 239,500,800
latnrm_arr_swp 30 10 1,824,400
latnrm_ptr 30 10 1,824,400
latnrm_ptr_swp 30 10 1,824,400

Experimental MethodologyEvaluating Current Heuristics
• Identified and implemented three Address-Register Assignment heuristic algorithms:
• Leupers• Sugino• Zhuang
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Experimental MethodologyEvaluating Current Heuristics
• Identified and implemented five Simple Offset Assignment heuristic algorithms:
• Liao• Leupers• ALOMA• Order-First Use (OFU)• Branch and Bound (B&B)
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Experimental MethodologyEvaluating Current Heuristics
• Each combination of ARA and SOA algorithm generates a set of sub-layouts.
• All possible memory layout permutations are generated, forming a set of memory layouts.
• Each memory layout is evaluated using the Minimum-Cost Circulation technique.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Results
• The 15 combinations of algorithms produce 15 distributions overhead values.
• The distributions are aggregated into one distribution.
• The aggregate distributions represent the solution space of all current algorithms.

Results
• Memory layouts have a significant impact on overhead.
• Some layouts have 100% higher overhead than the minimum.
• Over 99% of all layouts have an overhead that is 50% higher than the minimum.

Results
• Memory layouts produced by traditional approaches have a large range of possible overhead values -- sometimes the same as the entire solution space itself.
• In some cases, no combination of ARA and SOA heuristics can produce an optimal layout.

Results
• Memory layouts produced by traditional approaches have a large range of possible overhead values -- sometimes the same as the entire solution space itself.
• In some cases, no combination of ARA and SOA heuristics can produce an optimal layout.

Distribution of Overhead ValuesTestcase: iir_arr_swp -- infinite impulse response filter
Overhead (cycles) Exhaustive Algorithmic
6 144 0
7 19557 72
8 1514917 2240
9 21757157 6516
10 90478895 10496
11 104101226 2565
12 21628904 0
Average Overhead 10.51 9.6

1
10
100
1000
10000
100000
1000000
10000000
100000000
1000000000
6 7 8 9 10 11 12
Overhead (cycles)
Frequency
Exhaustive Solution SpaceTestcase: iir_arr_swp -- infinite impulse response filter

Algorithmic Solution SpaceTestcase: iir_arr_swp -- infinite impulse response filter
0
2000
4000
6000
8000
10000
12000
6 7 8 9 10 11 12
Overhead (cycles)
Frequency

Efficiency of SOA Algorithms
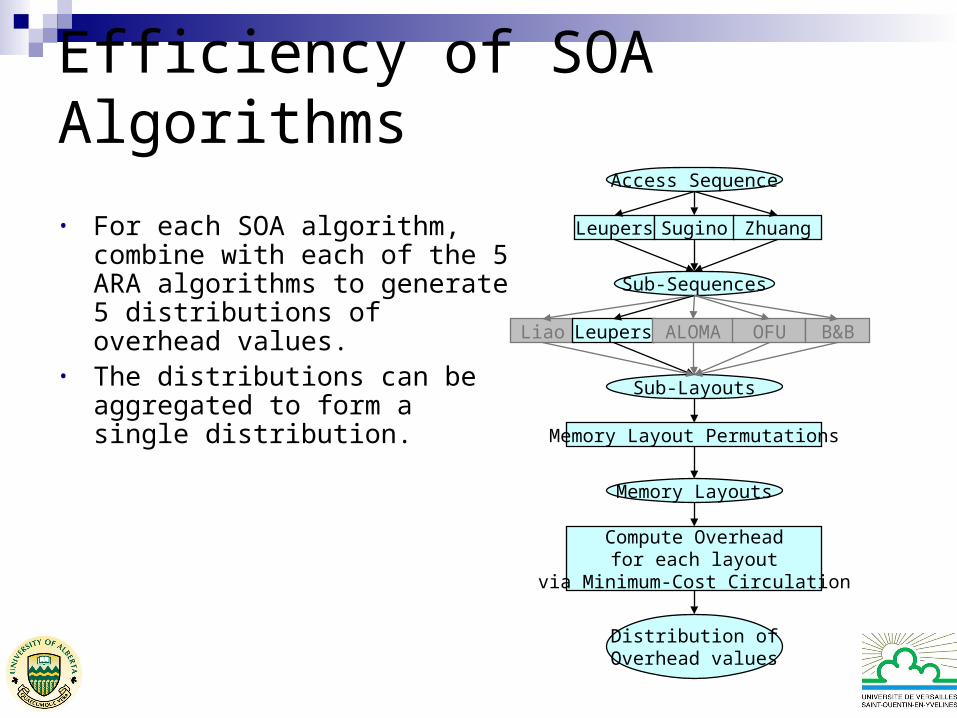
• For each SOA algorithm, combine with each of the 5 ARA algorithms to generate 5 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values
Efficiency of SOA Algorithms
• For each SOA algorithm, combine with each of the 5 ARA algorithms to generate 5 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of SOA Algorithms
• For each SOA algorithm, combine with each of the 5 ARA algorithms to generate 5 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of SOA Algorithms
• For each SOA algorithm, combine with each of the 5 ARA algorithms to generate 5 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of SOA Algorithms
• For each SOA algorithm, combine with each of the 5 ARA algorithms to generate 5 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Overhead (cycles) Liao Leupers Sugino B&B OFU
6 0 0 0 0 0
7 6 6 10 6 44
8 293 293 357 293 1004
9 960 960 1187 960 2448
10 2154 2154 2124 2154 1910
11 619 619 354 619 354
12 0 0 0 0 0
Efficiency of SOA AlgorithmsTestcase: iir_arr_swp -- infinite impulse response filter

Efficiency of SOA AlgorithmsTestcase: iir_arr_swp -- infinite impulse response filter
0
500
1000
1500
2000
2500
3000
6 7 8 9 10 11
Overhead (cycles)
Fre
qu
en
cy
Liao
Leupers
Sugino
BNB
OFU

Efficiency of ARA Algorithms
• For each ARA algorithm, combine with each of the 3 SOA algorithms to generate 3 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of ARA Algorithms
• For each ARA algorithm, combine with each of the 3 SOA algorithms to generate 3 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of ARA Algorithms
• For each ARA algorithm, combine with each of the 3 SOA algorithms to generate 3 distributions of overhead values.
• The distributions can be aggregated to form a single distribution.
Leupers Sugino Zhuang
Liao Leupers ALOMA OFU B&B
Access Sequence
Sub-Sequences
Sub-Layouts
Memory Layout Permutations
Memory Layouts
Compute Overheadfor each layout
via Minimum-Cost Circulation
Distribution ofOverhead values

Efficiency of ARA AlgorithmsTestcase: iir_arr_swp -- infinite impulse response filter
Overhead (cycles) Leupers Sugino Zhuang
6 0 0 0
7 2 61 9
8 204 1483 553
9 2089 1018 3408
10 4740 126 5630
11 2565 0 0
12 0 0 0

Efficiency of ARA AlgorithmsTestcase: iir_arr_swp -- infinite impulse response filter
0
1000
2000
3000
4000
5000
6000
6 7 8 9 10 11 12
Overhead (Cycles)
Fre
qu
ency Leupers
Sugino
Zhuang

Evaluating Offset Assignment Algorithms• There is low variability between SOA algorithms -- may
be attributed to small problem sizes.• The choice of ARA algorithm has more impact on
overhead. Much of the variability attributed to the different number of address registers used.
• For all combinations of SOA and ARA algorithms, the permutation of sub-layouts affects the overhead.

Outline
• Background• Traditional Approach to Offset Assignment
• Simple Offset Assignment• Address-Register Assignment
• Improving the Problem Model• Optimal Address-Code Generation• Memory Layout Permutations
• Evaluating Current Heuristics• Methodology• Results
• Conclusions and Future Work

Conclusions
• The objective is to minimize address-computation overhead.
• Given a fixed access sequence and memory layout, the minimum-cost circulation (MCC) technique can minimize overhead.
• Offset assignment algorithms should be evaluated with MCC.
• Offset assignment still has a significant impact on overhead.
• To be effective, current offset assignment algorithms (ARA,SOA) must address the Memory Layout Permutation problem.

Future Work
• A new algorithm is needed to generate memory layouts that will minimize overhead as computed by the Minimum-Cost Flow technique.
• Address-computation overhead must be minimized for loop bodies and for variables that are live between basic blocks and procedures.

References
• Gebotys, C.: DSP address optimization using a minimum cost circulation technique. Proceedings of the 1997 IEEE/ACM International Conference on Computer-Aided Design. 100-103.
• Leupers, R., Marwedel, P.: Algorithms for address assignment in DSP code generation. Proceedins of the 1996 IEEE/ACM International Conference on Computer-Aided Design. 109-112.
• Liao, S., Devadas, S., Keutzer, K., Tjiang, S., Wang, A.: Storage assignment to decrease code size. ACM Transactions of Programming Languages and Systems 18(3) (1996). 235-253.
• Sugino, N., Iimuro, S., Nishihara, A., Jujii, N.: DSP code optimization utilizing memory addressing operation. IEICE Transaction Fundamentals 8 (1996). 1217-1223.
• Zhuang, X., Lau, C., Pande, S.: Storage assignment optimizations through variable coalescence for embedded processors. Proceedings of the 2003 ACM SIGPLAN Conference on Language, Compiler, and Tools for Embedded Systems. 220-231.
• Bartley, D.H.: Optimizing stack frame accesses for processors with restricted addressing modes. Software – Practice & Experience 22(2) (2001). 158-172.

Questions?

















