32
| Date post: | 12-Apr-2017 |
| Category: |
Technology |
| Upload: | mate-szalay-beko |
| View: | 47 times |
| Download: | 0 times |


Hello!I am Mate Szalay-BekoLead Software Engineer at Epam [email protected]
Background: Java, Bioinformatics, Bigdata

2015 2016
Meetup Members
2015 2016
DevelopersContributing
v2.0
New Versions225K
66K
600
1100
v1.6 v2.1

× Remains highly compatible with 1.x× Builds on key lessons and simplifies API× 2000 patches from 280 contributors
× Main features:× Structured API improvements (DataFrame, Dataset, SQL)
× Whole-stage code generation× Structured Streaming

Rapid Spark
- Optimizations- Evolving APIs- Evolving vision

Batch APIs
× SparkCore / RDD× SparkSQL / DataFrames× DataSets
on multiple languages...Scala / Java / Python / .NET / ...
Streaming APIs
× DStream× Structured Streams

Rating
• Movie Title
• Movie Year
• Number of votes
• Rating value
• Rating distribution
Actors
• Name
• Movie Title
• Movie Year
Actresses
• Name
• Movie Title
• Movie Year
Actors
• Name
• Movie Title
• Movie Year
Actors
• Name
• Movie Title
• Movie Year
Actors
• Name
• Movie Title
• Movie Year
Actresses
• Name
• Movie Title
• Movie Year
Actresses
• Name
• Movie Title
• Movie Year
Actresses
• Name
• Movie Title
• Movie Year
Batch use-case: average rate per actorStream use-case: rating calculation based on vote events*
https://github.com/symat/spark-api-comparison

Spark Core„the assembly of spark”
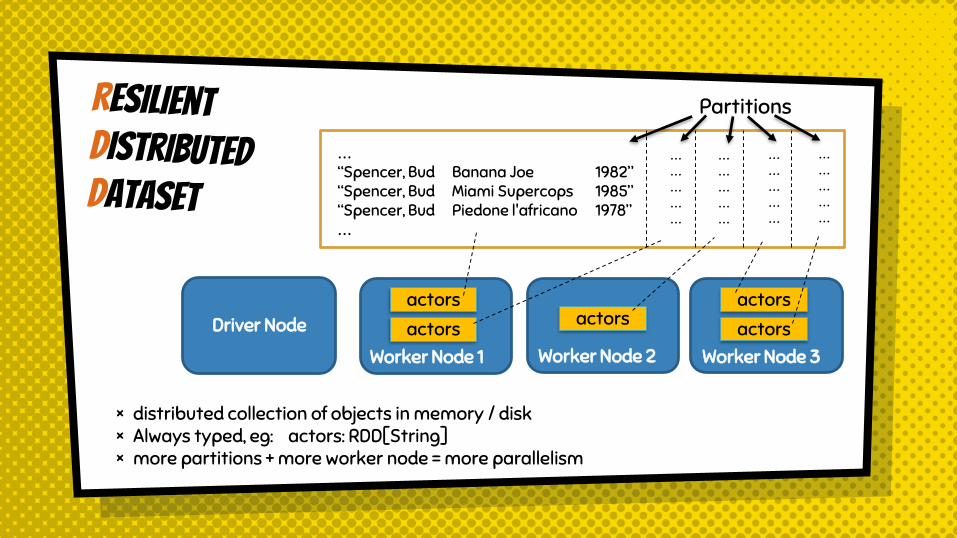
Driver Node
…“Spencer, Bud Banana Joe 1982”“Spencer, Bud Miami Supercops 1985”“Spencer, Bud Piedone l'africano 1978”…
……………
……………
……………
……………
actors
Partitions
actorsWorker Node 1
actors
actorsWorker Node 3
actors
Worker Node 2
× distributed collection of objects in memory / disk× Always typed, eg: actors: RDD[String]× more partitions + more worker node = more parallelism

RDD
code

DAG execution model: × Nodes: RDDs× Links: RDD->RDD transformation or actions× Lazy compilation
Each RDD: × Data× Dependencies× Partitions (with optional locality info)× Compute function: Partition => Iterator[T]× Type fixed in compile time

× maximize data-locality× don’t store inner steps in HDFS× auto-collapsing
narrow transformations× picking best join algorithm× reliable + cache friendly× spark shell
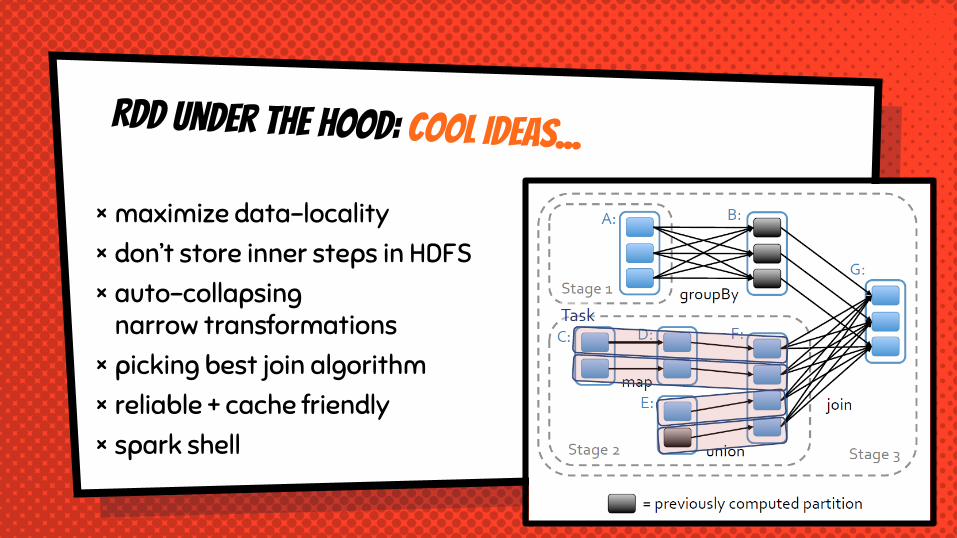
× maximize data-locality× don’t store inner steps in HDFS× auto-collapsing
narrow transformations× picking best join algorithm× reliable + cache friendly× spark shell

× Low level
Nice API, but...
a little low level


× Low level× Serialization / memory problems (eg. on shuffle phases)
× data items are just „jvm obejcts”, can have super classes, states, ... × data must be deserialized, storing on heap, GC, ...× Kyro serialization
× Python performance problems× Limited optimization on cross-operation steps
Nice API, but...
a little low level

Spark SQL„NoSQL? No! SQL!”
HAHA!
SQL?

SQL
code

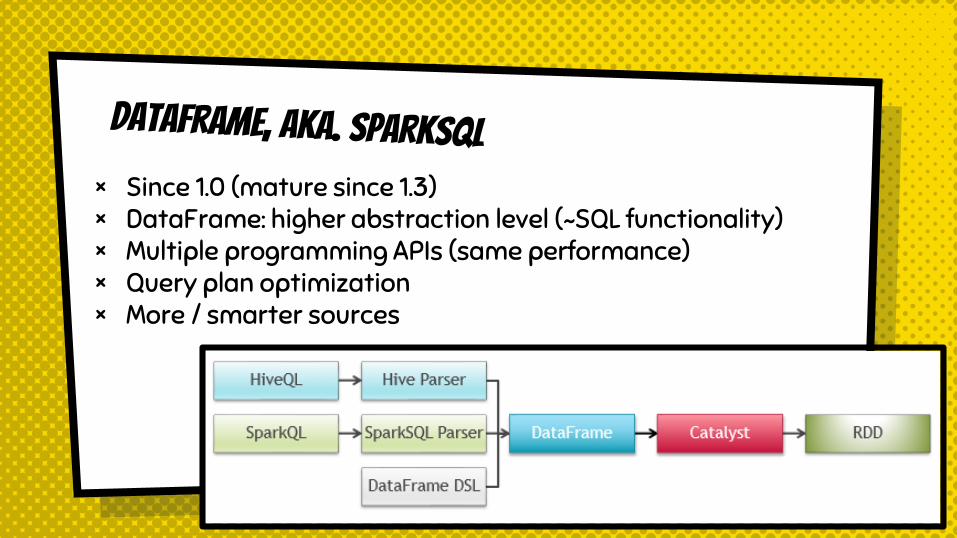
× Since 1.0 (mature since 1.3)× DataFrame: higher abstraction level (~SQL functionality)× Multiple programming APIs (same performance)× Query plan optimization× More / smarter sources

DataFrame
code


× Each transformation generates DataFrame (~= RDBMS table)× Schema inference (columns with basic types)× But losing type safety on compilation level
rdd.map(x => (x.dept, (x.age, 1)))
.reduceByKey { case (x,y) => (x._1+y._1, x._2+y._2) }
.mapValues { case (x,y) => x / y }
df.groupBy(“dept”))
.avg(“age”)
RDD
DataFrame SQL
sqlContext.sql(“SELECT avg(age)” +
“FROM people GROUP BY dept”)
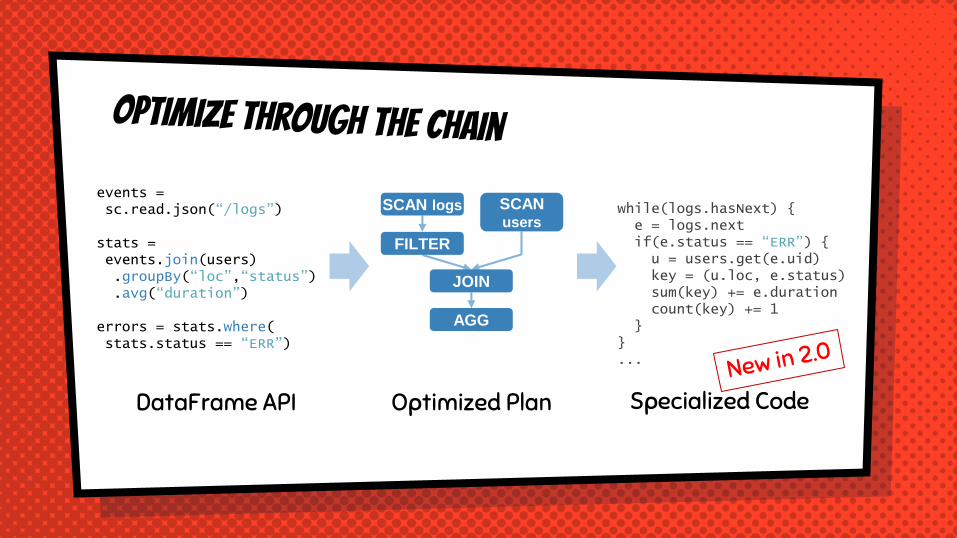
events =sc.read.json(“/logs”)
stats =events.join(users).groupBy(“loc”,“status”).avg(“duration”)
errors = stats.where(stats.status == “ERR”)
DataFrame API Optimized Plan Specialized Code
SCAN logs SCANusers
JOIN
AGG
FILTER
while(logs.hasNext) {e = logs.nextif(e.status == “ERR”) {u = users.get(e.uid)key = (u.loc, e.status)sum(key) += e.durationcount(key) += 1
}}...

DataSet„best from both world”

DataSet
code


× Since 1.6, but mature since 2.0× Combine RDD and DataFrame approaches× New DSL, still abstract but type-safe
× operate on domain objects with compiled lambda functions× schema and complex SQL operations (join/aggregation)× all the optimizations, smart sources and code generation
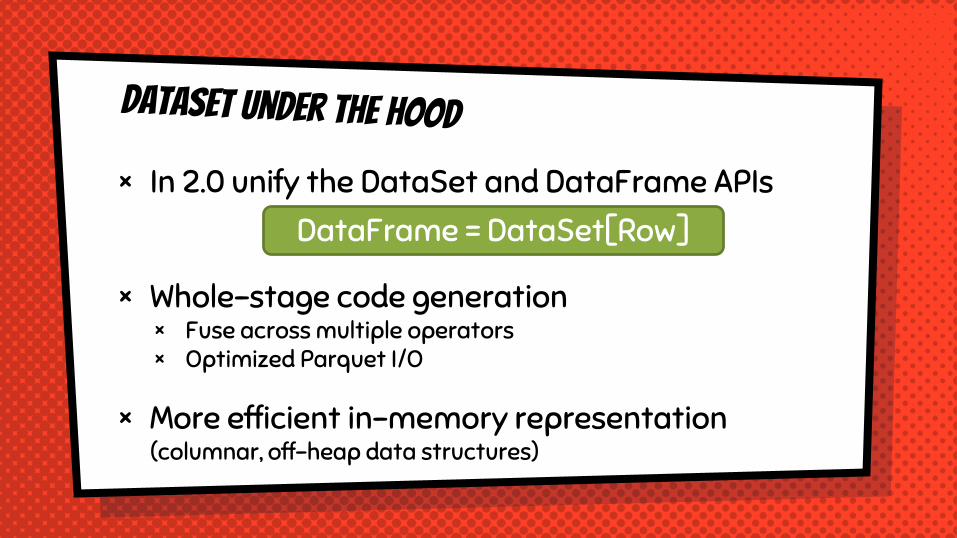
× In 2.0 unify the DataSet and DataFrame APIs
× Whole-stage code generation× Fuse across multiple operators× Optimized Parquet I/O
× More efficient in-memory representation(columnar, off-heap data structures)
DataFrame = DataSet[Row]


number of movie-actor pairs: 36373546
number of movie-rating pairs: 250
+--------------------+-----------------+--------------+
| name| avg(rating)|numberOfMovies|
+--------------------+-----------------+--------------+
| Rhys-Davies, John|8.671428407941546| 14|
| Bloom, Orlando|8.666666507720947| 12|
| Serkis, Andy|8.657142775399345| 14|
| Wood, Elijah (I)|8.614285605294365| 14|
| Weaving, Hugo|8.599999972752162| 14|
| Caine, Michael (I)|8.485714094979423| 14|
| Freeman, Morgan (I)|8.474999904632568| 16|
| Pacino, Al (I)| 8.46666669845581| 12|
| Jones, James Earl|8.442857197352819| 14|
| Bale, Christian|8.399999777475992| 12|
| Ford, Harrison (I)|8.387500047683716| 16|
| De Niro, Robert|8.387499928474426| 16|
| Ermey, R. Lee|8.383333524068197| 12|
| Hanks, Tom|8.383333365122477| 12|
| Chaplin, Charles|8.383333206176758| 12|
| Burnyeat, Luke|8.371428625924247| 14|
| Pitt, Brad|8.350000222524008| 12|

THANKS!Any questions?You can find me at [email protected]
https://github.com/symat/spark-api-comparison







![pages Research Report - dominoweb.draco.res.ibm.com · Spark SQL [12] is a major component in Spark, and it bridges relational processing and procedural processing with Spark APIs.](https://static.documents.pub/doc/80x56/5fd83e9b5214682ebd2fb978/pages-research-report-spark-sql-12-is-a-major-component-in-spark-and-it-bridges.jpg)









