24
Experience with Site Functional Tests Piotr Nyczyk CERN IT/GD WLCG Service Workshop Mumbai, 10-12 February 2006
| Date post: | 26-Dec-2015 |
| Category: |
Documents |
| Upload: | derek-freeman |
| View: | 243 times |
| Download: | 24 times |

Experience with Site Functional Tests
Piotr Nyczyk
CERN IT/GD
WLCG Service Workshop
Mumbai, 10-12 February 2006

Experience with SFT, Mumbai, 10-12 February 2006 2
Outline
• Introduction• Brief history• Current status• Data schema• Site availability metric (prototype)• Experience• On-going development• Conclusions

Experience with SFT, Mumbai, 10-12 February 2006 3
Introduction
• Motivation: local site level monitoring is not enough– depends on site configuration, decisions,
etc. (lack of uniform view for all sites)
– cannot be fully trusted (!)
– usually focused on low-level details (daemons, disk space) and not on usability of the service itself
• Solution: need for high-level, service oriented monitoring (probing) to see if the grid is really usable
• What is SFT?– “agent” or test job sent to all sites (CEs)
on regular basis (every 3 hours)
– set of tests for different aspects of functionality
– high level - service or functionality oriented

Experience with SFT, Mumbai, 10-12 February 2006 4
SFT history
• Initial situation: – August 2004 - about 60 sites
– Grid split in 2 “zones”: • TestZone - new sites
• Production - tested and stable sites
• TestZone Tests (tztests) - predecessor of SFT– bash script test job based on manual tests from LCG release
notes: broker info, env. variables, software version, CA RPMs version, edg-rm operations, ...
– set of scripts to submit test job to all sites and retrieve outputs
– outputs stored in the directory structure on disk (CERN AFS): key-value pairs + text log
– simple CGI script to generate web report (sites/tests matrix)

Experience with SFT, Mumbai, 10-12 February 2006 5
SFT history (cont.)• TZTests -> SFT - just change of name, reason: no TestZone any
more
• Gradual improvements: new tests (R-GMA, ...), stability (detection of RB failures), scheduled maintenance, etc. - pragmatic approach - detection of most “painful” errors
• But all the time in operations! - Immediate deployment
• Integration (user interface level) with GStat
• Next step: SFT->SFT2– used until now
– whole framework rewritten almost from scratch
• Most important changes: – MySQL and R-GMA instead of directory structure for storage
– tests executed in parallel
– publishing results using asynchronous web service
– additional dimension: VO - possibility of VO specific tests (example: dirac installation test by LHCb)

Experience with SFT, Mumbai, 10-12 February 2006 6
Current status of SFT
• About 20 tests:– General: Software Version, CA certs version, CSH, BrokerInfo, R-
GMA (+ secure conn.), Apel
– Replica management (lcg-utils+RLS): infosys, copyAndRegister, copy, replicate, 3rd party replication, delete + similar set using LFC
– Security tests (separate restricted zone): CRL validity
• “Official” test jobs submitted in dteam VO (high priority queue) every 3 hours
• On demand submissions when necessary (SFT Admin page in Poznan)
• VO specific submissions - example: LHCb, dirac installation test
• Prototype CE availability metric aggregated on site, region, grid level

Experience with SFT, Mumbai, 10-12 February 2006 7
SFT report

Experience with SFT, Mumbai, 10-12 February 2006 8
SFT workflow
• Tests are performed on/from 1 WN
• Results are related to a single CE
• Only “default” nodes of other types are tested (SE, MON, ...)
Experience with SFT, Mumbai, 10-12 February 2006 9
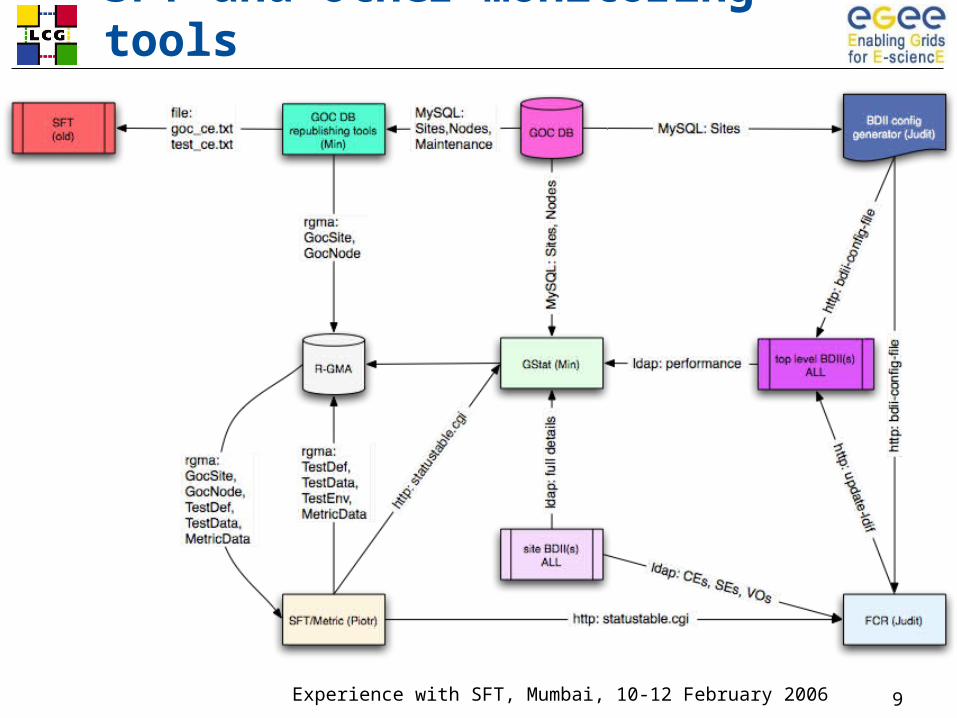
SFT and other monitoring tools
Experience with SFT, Mumbai, 10-12 February 2006 10
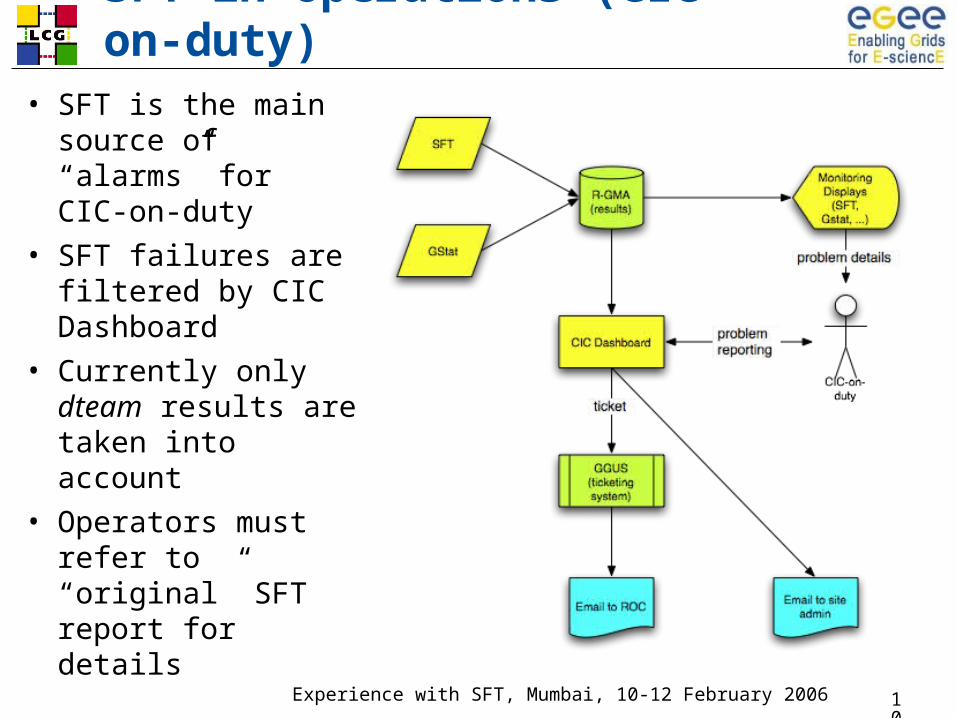
SFT in operations (CIC-on-duty)
• SFT is the main source of “alarms” for CIC-on-duty
• SFT failures are filtered by CIC Dashboard
• Currently only dteam results are taken into account
• Operators must refer to “original” SFT report for details

Experience with SFT, Mumbai, 10-12 February 2006 11
SFT in operations (cont.)

Experience with SFT, Mumbai, 10-12 February 2006 12
Data schema - concept
• Designed for MySQL/R-GMA
• Initial goal: uniform schema for SFT, GStat and any future tests/sensors - flexibility
• Dimensions:– context (VO) - added later - who?
– sensor (testName) - what?
– place (nodeName) - where?
– time (timestamp/MeasurementDate,Time) - when?
• 3 levels of details for results:– status - severity: OK, INFO, NOTE, WARNING, ERROR, CRITICAL
– summaryData: simple textual information or value
– detailedData: details of test process (log) - for troubleshooting
• Possibility of adding new sensors/tests dynamically (discovery)

Experience with SFT, Mumbai, 10-12 February 2006 13
Data schema - tables
• TestDef - test definitions (added/updated dynamically):– key: testName (naming convention, example: sft-job, gstat-
GIISQuery)
– for users: testTitile, friendlyName, testHelp (URL)
– for tools: unit, dataType (not used by SFT)
• TestData - results (all in one table):– VO
– testName
– nodeName
– envID (additional information on test session)
– status
– summaryData
– detailedData - in SFT URL pointing to LOG file (static HTML)
– timestamp

Experience with SFT, Mumbai, 10-12 February 2006 14
Data schema - tables (cont.)
• TestEnv - additional information about test session:– key: session ID - unique, generated for a single
session (every 3 hours)– name,value pairs– published by the framework after “environment” tests
and before actual test job submissions– example: sft-RB, sft-central-SE
• Additional tables (not used really):– TestDefRelation - relations between tests (supertests,
subtests)– TestDataRelation - relations between results: if failure
of one test affects other tests
Experience with SFT, Mumbai, 10-12 February 2006 15
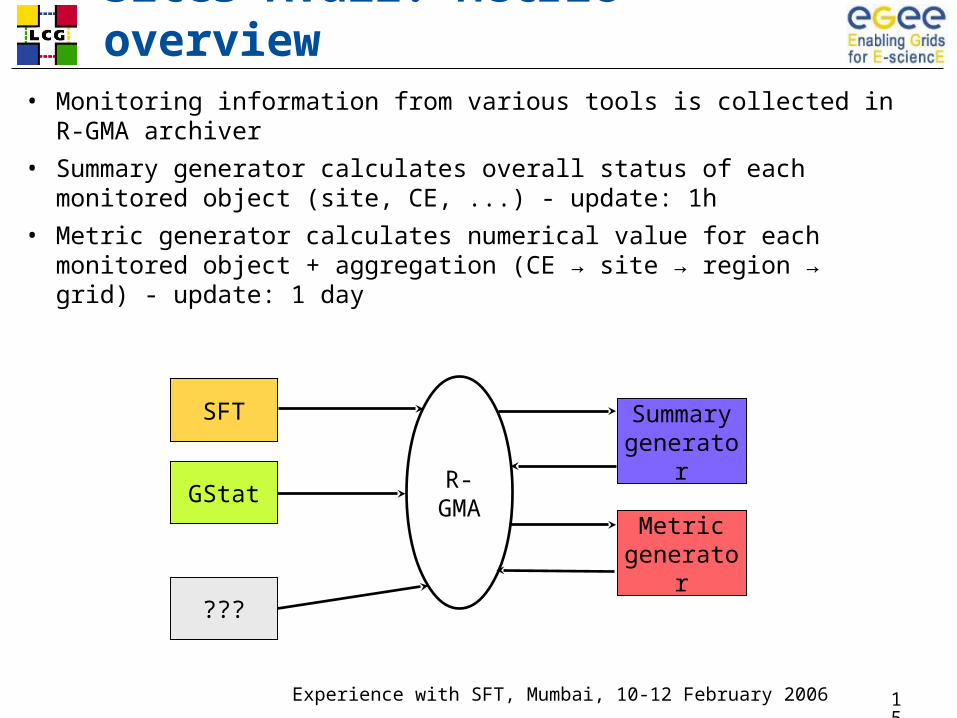
Sites Avail. Metric - overview• Monitoring information from various tools is collected in R-GMA
archiver
• Summary generator calculates overall status of each monitored object (site, CE, ...) - update: 1h
• Metric generator calculates numerical value for each monitored object + aggregation (CE → site → region → grid) - update: 1 day
SFT
GStat
???
R-GMA
Summary generator
Metric generator
Experience with SFT, Mumbai, 10-12 February 2006 16
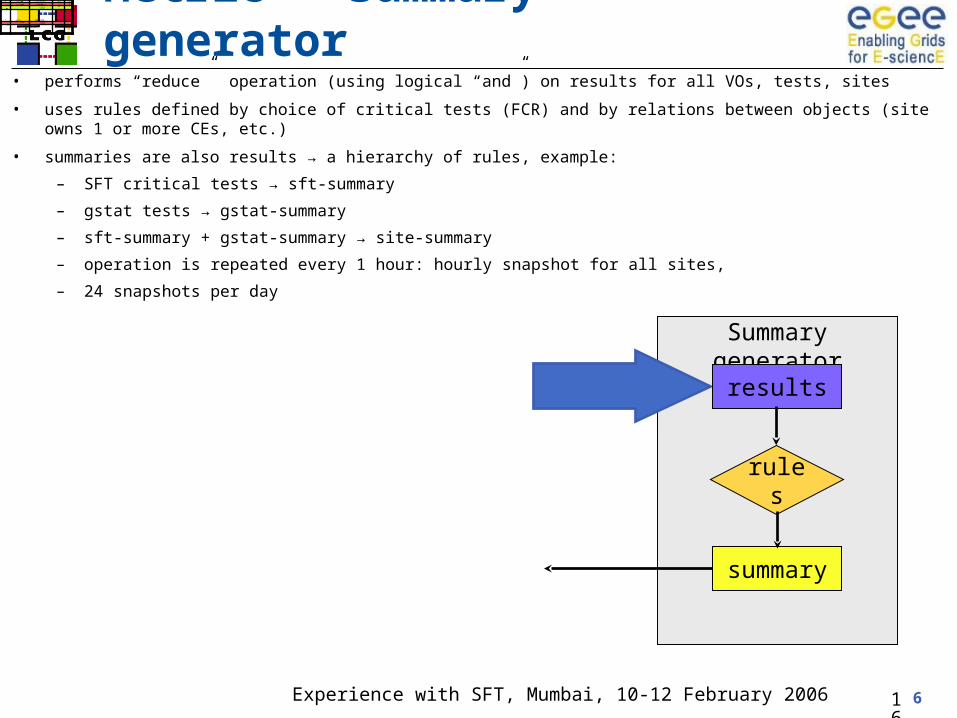
Metric - summary generator• performs “reduce” operation (using logical “and”) on results for all VOs, tests, sites
• uses rules defined by choice of critical tests (FCR) and by relations between objects (site owns 1 or more CEs, etc.)
• summaries are also results → a hierarchy of rules, example:
– SFT critical tests → sft-summary
– gstat tests → gstat-summary
– sft-summary + gstat-summary → site-summary
– operation is repeated every 1 hour: hourly snapshot for all sites,
– 24 snapshots per day
6
Summary generator
VO
testName
nodeName
status
time
dteam
sft-job ce1.badsite.org
ERROR
T1-
gstat-GIIS
BADSITE-LCG2
OK
T2
.
.
.
.
.
.
.
.
.
.
.
.
dteam
site-summary
BADSITE-LCG2
ERROR
T3
.
.
.
.
.
.
.
.
.
.
.
.
results
rules
summary

Experience with SFT, Mumbai, 10-12 February 2006 17
Metric - calculation
• Sites availability:– for each site: 24 summaries per day, each has two possible values 0 -
ERROR or 1 - OK
– summary values integrated (averaged) for the whole day ⇒• 0 - site was failing tests for the whole day
• 0.75 - site was passing tests for 18 hours and failing for 6 hours
• 1 - site was OK for the whole day
– metric values for sites in a single region are added together to calculate the values for the whole region
– metric values of all regions are summed to get overall metric for the grid
• CPUs availability– similar process, but: site value is multiplied by the number of CPUs in that
site (published in the information system)
– example: site A has 1000 CPUs but the daily site availability metric was 0.80 CPUs availability metric is 800⇒
– interpretation: How many cpus were effectively provided by a site/region/grid during the day?

Experience with SFT, Mumbai, 10-12 February 2006 18
Metric - calculation (cont.)
• Long term metrics:– metric results are archived in R-GMA table (MetricData)– weekly, monthly, quarterly metric is calculated by
averaging daily metric for site/region/grid
• Potential CPUs availability metric:– indicates how many CPUs could be provided by the
site/region/grid if all tests were always passed– is calculated by taking 1 as the value of site availability
metric for all sites

Experience with SFT, Mumbai, 10-12 February 2006 19
Metric - graphs

Experience with SFT, Mumbai, 10-12 February 2006 20
SFT Experience• Reliability:
– occasional failures - once ~2 months: disk full, hardware failure
– intervention time - around 1 day (time to fix)
– BUT! Plans for replicated service (CNAF), local monitoring support (CERN-FIO) and moving to more suitable hardware
• Scalability:– most problems caused by MySQL/R-GMA performance and data
schema - max.1 month of full history is possible
– history queries most expensive - slow response
• Security:– no publishing security at the moment: anyone can potentially
publish any results
– certificate based authentication for reports access
– BUT! No serious incidents observed - few cases of corrupted data due to testers mistakes

Experience with SFT, Mumbai, 10-12 February 2006 21
SFT Experience
• Maintenance:– Main services running at CERN
– SFT Admin Page for on demand tests submission running in Poznan (RB at CNAF, integration with CIC Portal, Lyon)
– about 3 people at CERN taking care of main SFT Server and Client
– additional clients maintained by VOs and ROCs
• Usefulness:– main source of information for CIC-on-duty operations
– CE monitoring only, but helpful in detection of problems with other services (R-GMA, SEs, file catalogs)
– used by ROCs for initial sites certification process (on-demand submission to uncertified sites) - but not software certification!!!

Experience with SFT, Mumbai, 10-12 February 2006 22
On-going development• Goals:
– extend for other services and metrics
– move to production quality: Oracle DB, dedicated hardware, better scalability
• First steps:– refined data schema - just minor changes: naming convention,
additional attributes (dataThreshold, etc.) - DONE
– hardware/software decisions: Oracle DB, dedicated mid-range servers, programming languages - DONE
• Parallel development:– service sensors - distributed
– extended framework (SAME/SFT) - CERN, Lyon
– data storage and processing - CERN, GridView team
– visualisation (metrics, operator’s display) - CERN, GridView team, Lyon

Experience with SFT, Mumbai, 10-12 February 2006 23
On-going development (cont.)
• Some guidelines:– small steps, immediately in production– concentrate on concept and not on producing world-
most-complex-software with thousands lines of code
– better rewrite from scratch than make it even more obscure by trying to fix it
• SFT was rewritten several times - now it’s next iteration!

Experience with SFT, Mumbai, 10-12 February 2006 24
Conclusions
• Currently only Computing Elements are really monitored - other services indirectly
• Basic concept unchanged for 1.5 year now• Data schema flexible enough to serve for
monitoring of other services• No serious scalability problems observed• More and more people actively involved in
SAME/SFT development

















