45
Computer Science Exploring Hidden Networks: Applications, Algorithms and Measurements John Byers Department of Computer Science, Boston University

Computer Science
Exploring Hidden Networks:Applications, Algorithms and Measurements
John Byers
Department of Computer Science, Boston University

Given an underlying graph G whose vertices are known wholly or partially in advance edges are unknown in advance
Identify properties of the edge set via asequence of probes (samples). Application-specific probing Statistical vs. topological properties Exact vs. approximate guarantees Adaptive vs. non-adaptive sampling
Hidden Networks: What

Traditional science: study of “found” objects. Protein-protein interaction networks Metabolic networks Genome mapping
Emerging domain: study engineered artifacts,with scientific posture accorded to “found” objects. Internet topology: “map” is not known
Size, proprietary information, distributed Router-level topology vs. AS-level topology
Dynamic networks: up-to-date maps are infeasible tomaintain. Examples: P2P, overlays, large testbeds
Hidden Networks: Where

Compelling applications Existing approaches are “point solutions” Cross-cutting theory is not yet well developed Pitfalls/weaknesses not widely disseminated Impact of models:
better models may make for better algorithms principles inform probing process
Hidden Networks: Why

Traceroute exploration of many graphs yieldsheavy-tailed subnets [LBCX ’03, ACKM ’05]
Random subnets of scale-free graphs are notscale-free [Stumpf, Wiuf, May: PNAS 3/22/05] Parsimonious subgraph generation model:
Vertices selected uniformly at random. Edge (i, j) included iff both i and j selected.
Two examples of strong sampling bias.
Hidden Networks: Foundations

Outline
Motivating hidden graphs
Case study 1: Hidden graphs in genomesequencing applications.
Case study 2: Internet mapping studies.
Case study 3: Locating constrained, annotatedInternet subgraphs.
Discussion

Protein-protein interaction (PPI) networks; genomics. Nodes correspond to (known) chemicals. Edges correspond to observable chemical reactions. Probe: Combine an arbitrary subset S of chemicals. Binary probe QG (S):
0: non-existence of any edge within S 1: existence of at least one edge in S
Example: Genome sequencing of “contigs”: Model: at most one incident edge per node Goal: identify hidden matching efficiently.
Shotgun sequencing: parallelize probe process
Example: Interaction networks

[Grebinski, Kucherov ’97, ‘98]: Asymptotically optimalquery bounds for hidden Hamiltonian cycles.
[Beigel, Alon, Apaydin, Fortnow, Kasif ’01]:Asymptotically optimal query bounds for hiddenmatchings.
[Alon, Beigel, Kasif, Rudich, Sudakov ’02]: Nearly-tightupper and lower bounds on hidden matchings for bothdeterministic and randomized algorithms.
[Angluin, Chen ’04]: Learning hidden graphs in O(m logn) queries.
[Alon, Asodi ’04]: Learning hidden subgraphs. [Angluin, Chen ’04]: Learning hidden hypergraphs.
(Numerous experimental biology papers).
Querying hidden graphs

Matching Query
(Slides courtesy of Simon Kasif)

Matching Query

Matching Query
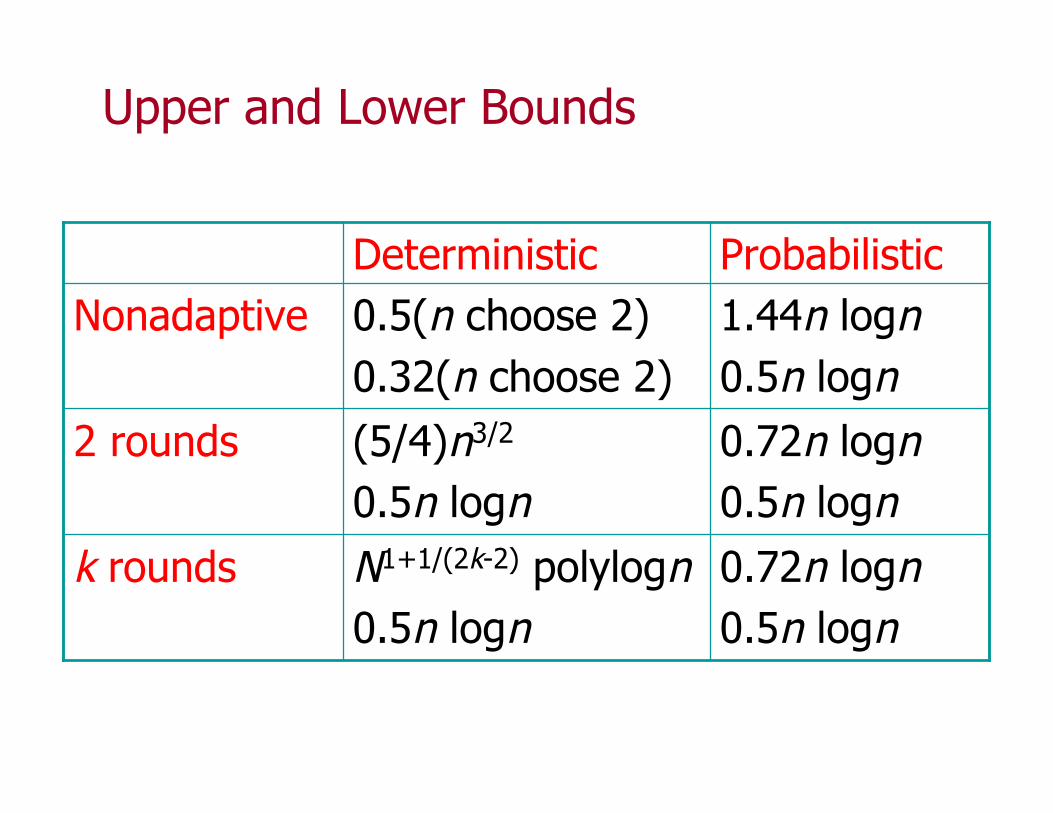
Upper and Lower Bounds
0.72n logn0.5n logn
N1+1/(2k-2) polylogn0.5n logn
k rounds
0.72n logn0.5n logn
(5/4)n3/2
0.5n logn2 rounds
1.44n logn0.5n logn
0.5(n choose 2)0.32(n choose 2)
NonadaptiveProbabilisticDeterministic

1- or 2-Round Probabilistic Algorithm
1. Form O(n logn) tubes of size O(√n) independentlyat random. Test each tube to see if it contains anedge.
1a. For each pair {u,v}, see if {u,v} is contained in atube that tested negative in step 1. If so, {u,v} isa nonedge.
1b. For each pair {p,q}, see if {p,q} is contained in atube that tested positive in step 1 but in whichevery other pair was determined to be a nonedgein step 1a. If so, {p,q} is an edge.
2. Test all pairs whose status is still unknown.

Probabilistic Algorithms (optimizing constants)
Procedure RPP (random projective plane) Assume n = p 2 + p + 1 Randomly permute all n vertices and identify them
with the points of the projective plane P of orderp.
Perform one test for each line in P.Fix {x,y}. {x,y} belongs to a unique line in P. The
probability that that line contains no matchededge (except perhaps {x,y} itself) is ≈ e-1/2.

2-rounds, 0.74n logn tests, 0-sided error
Perform procedure RPP d logn timesindependently in parallel.
The probability that every line containing{x,y} contains an edge (besides {x,y}) is atmost π(d) ≈ ((1-e-1/2)d logn.
Choosing d ≈ 0.74, π(d) ≤ 1/n. The remaining edges (at most n/2 onaverage) are tested in round 2.

Highly structured hidden graph Clean abstraction Flexible probing process Amenable to randomization, parallelization Practically useful
Modeling and algorithms success

Outline
Motivating hidden graphs
Case study 1: Hidden matchings in genomesequencing.
Case study 2: Internet mapping studies.
Case study 3: Locating constrained, annotatedInternet subgraphs.
Discussion

Internet mapping efforts
Goal: Discover the Internet router-level topology• Vertices represent routers.• Edges connect routers that are one IP hop apart.
Measurement Primitive: tracerouteReports the IP path from A to B.
source destination
212.12.5.77
212.12.58.3 163.55.221.98
163.55.1.41163.55.1.10

• k sources: Few activesources, strategicallylocated.
• m destinations: Manypassive destinations,globally dispersed.
• Union of manytraceroute paths.
(k,m)-traceroute study
Most experimental traceroute studies[Pansiot et al ’98, Govindan et al ’00, Broido et al ’01-’05, etc.]
Destinations
Sources

Choose k sources and m destinations at random. Consider the subgraph G’ = (V’, E’) induced by routes from
R between all (source, dest) pairs. How do expected values of |V’| and |E’| scale as a function
of k and m for various graph models? One special case for k = 1 well understood.
Chuang-Sirbu multicast scaling law: |E’| ~ m 0.8
Analysis in [Phillips et al ’99, van Mieghem et al ’02] Formulations for general k are open.
Also of interest: quantification of marginal utility of addingk+1 ’st source or destination [BBBC ’01].
Non-Adaptive Scaling Laws

A thought experiment
Idea: Simulate topology measurements on a random graph.
1. Generate a sparse Erdös-Rényi random graph, G=(V,E).Each edge present independently with probability pAssign weights: w(e) = 1 + ε , where ε in
2. Pick k unique source nodes, uniformly at random
3. Pick m unique destination nodes, uniformly at random
4. Simulate traceroute from k sources to m destinations, i.e.learn shortest paths between k sources and m destinations.
5. Let Ĝ be union of shortest paths.
Ask: How does Ĝ compare with G ?
!"
#$%
& '
||
1,||
1
VV

Ĝ is a biased sample of G that looks heavy-tailedAre heavy tails a measurement artifact?
MeasuredGraph, Ĝ
Underlying Random Graph, G
Underlying Graph: N=100000, p=0.00015Measured Graph: k=3, m=1000
log(Degree)
log(
Pr[X
>x])

Are nodes sampled unevenly?
• Conjecture:Shortest path routing favorshigher degree nodes nodes sampled unevenly
• Validation:Examine true degrees ofnodes in measured graph, Ĝ.
Expect true degrees of nodesin Ĝ to be higher thandegrees of nodes in G, onaverage.
True Degrees of nodes in Ĝ
Degrees of all nodes in G
Measured Graph:k=5,m=1000
• Conclusion: Difference between true degrees of Ĝ and degrees of G is insignificant; dismiss conjecture.

Are edges sampled unevenly?
• Conjecture:Edges selected incident to anode in Ĝ not proportional totrue degree.
• Validation:For each node in Ĝ, plot truedegree vs. measured degree.
If unbiased, ratio of true tomeasured degree should beconstant. Points clusteredaround y=cx line (c<1).
• Conclusion: Edges incident to a node are sampled disproportionately; supports conjecture.
Obs
erve
d D
egre
e
True Degree

What does this suggest?
Summary:
Edges are sampled unevenlyby (k,m)-traceroute methods.
Edges close to the source aresampled more often thanedges further away.
Intuitive Picture:
Neighborhood near sources is well explored, but visibility of edges declines sharply with hop distance from sources.
Hop1lo
g(Pr
[X>x
])
log(Degree)
Hop2
Hop3
Underlying Graph
Measured Graph
Hop4

Statistical Test #1
2
)1(2
)1(
)1(]Pr[
v
ek !
"
#$%
&
+<>
+
+
'
''
'
Cut vertex set in half: N (near) and F (far), by distance from nearest source.Let v : (0.01) |V|
k : fraction of v that lies in N
Can bound likelihood k deviates from 1/2 using Chernoff bounds:
H0C1
Reject hypothesis with confidence 1-α if:
2
)1()1(
v
e
!"
#$%
&
+'
+(
(
()
C1: Are the highest-degree nodes near the source?If so, then consistent with bias.
The 1% highest degree nodes occur at random with distance to nearest source.

Statistical Test #2
Partition vertices across median distance: N (near) and F (far)
Compare degree distribution of nodes in N and F, using theChi-Square Test:
!=
"=l
i
iiiEEO
1
22 /)(#
where O and E are observed and expected degree frequencies and l ishistogram bin size.
Reject hypothesis with confidence 1-α if:
H0C2
2
]1,[
2
!>l"##
C2: Is the degree distribution of nodes near the source different fromthose further away? If so, consistent with bias.
Chi Square Test succeeds on degree distribution for nodes near the source and far from the source.

Testing C1
H0C1 The 1% highest degree nodes occur at random with distance
to source.
Pansiot-Grad: 93% of the highest degree nodes are in NMercator: 90% of the highest degree nodes are in NSkitter: 84% of the highest degree nodes are in N

Testing C2H0
C2
Pansiot-Grad Mercator Skitter
log(
Pr[X
>x])
log(Degree)
Near
Far
All
Near
Far
All
Near
Far
All

Several possible explanations
• Degree distribution is distance-independent, butsampling is biased.
• Degree distribution is distance-dependent, and nodesfurther from the source really do have below-averagedegree.
• Others?
In practice, it appears to be a combination of factors.

Other traceroute questions
Suppose you had the ability to conduct adaptivemeasurements (recently feasible, e.g. scriptroute). How to maximize edge coverage on a fixed
measurement budget? Traceroute @ home (SIGMETRICS ’05) DIMES (www.netdimes.org)
“AS-level traceroute” [SIGCOMM ’03] Leverage to probe a hidden multigraph?

Unknown hidden graph Unclean abstraction Awkward, inflexible probing process
probes interdependent on underlying graph Amenable to parallelization Power of adaptation not yet known
Modeling and algorithms: mixed bag

Outline
Motivating hidden graphs
Case study 1: Hidden matchings in genomesequencing.
Case study 2: Internet mapping studies.
Case study 3: Locating constrained, annotatedInternet subgraphs.
Discussion

Simulation “Blank slate” for crafting experiments Fine-grained control, specifying all details No external surprises, not especially realistic
Emulation All the benefits of simulation, plus: running real protocols on real systems
Internet experimentation Even more realistic Much harder to set up, control experiments
Experimental Methodologies

Our question:Can we bridge over some of the attractive features of
simulation and emulation into wide-area testbed oroverlay experimentation?
Towards an answer: Which services would be useful? Outline design of a set of interesting services. This case study:
specify parameters of an experiment on a blank slate locate one or more sub-topologies matching specification
Controlled Internet Experimentation

User specifies an envisioned target topology T edges and bounds on their attributes or more interesting: only path attributes (RTTs)
Then, given an overlay network G whose: vertices are known in advance and whose paths have measurable, multi-dimensional
attributes not known in advance
Conduct a set of adaptive probes to: locate a hidden instance (feasible embedding) of
T into G respecting constraints. more generally: sample from feasible embeddings
Annotated topologies: problem statement

Specifying Topologies
N nodes in testbed, k nodes in specification k x k constraint matrix C = {ci,j} Entry ci,j constrains the end-to-end path
between embedding of virtual nodes i and j. For example, place bounds on RTTs:
ci,j = [li,j, hi,j] represents lower and upper bounds on target RTT.
Constraints can be multi-dimensional. Constraints can also be placed on nodes. More complex specifications possible...

Feasible Embeddings
Def’n: A feasible embedding is a mapping f suchthat for all i, j where f(i) = x and f(j) = y:
li,j ≤ d (x, y) ≤ hi,j
Do not need to know d (x, y) exactly, only thatli,j ≤ l’(x, y) ≤ d (x, y) ≤ h’ (x, y) ≤ hi,j
Key point: Testbed need not be exhaustivelycharacterized, only sufficiently well to embed.

Hardness
Finding an embedding is as hard as subgraphisomorphism (NP-complete)
Counting or sampling from set of feasibleembeddings is #P-hard.
Approximation algorithms are not muchbetter.

Current Best-Practice
Brute force search [CBM ’03, HotNets-II]. No joke. Situation is not quite as dire as it sounds.
Several methods for pruning the search tree. Adaptive measurement heuristics. Many (almost all?) user problem instances not near
boundary of solubility and insolubility.
Prototype service on PlanetLab Off-line searches up to thousands of nodes. On-line searches up to hundreds of nodes.

Current Best-Practice (cont.)
Good news: many of the hardness results arebased on (unrealistic?) modeling assumptions
Bad news: better models for annotatedtopologies are notably absent
Why? Measurements that might assist in model-building
are just getting underway. Capturing the practical issues in a parsimonious
model is a formidable challenge.

Hidden graph is dynamic Abstraction is reasonably clean Combinatorial optimization issues may pose
thorny problems for analysis Model-based approaches could help
Modeling and algorithms:virgin territory

Numerous hidden graphs in science; moreemerging as engineered artifacts.
Principled measurement/modeling/validationwill be needed.
Forums for discussion and dissemination ofideas across disciplines will help.
Takeaway messages

[AA 04] N. Alon and V. Asodi, “Learning a hidden subgraph,” Proc. of 31st ICALP, 2004. [AC 04] D. Angluin and J. Chen, “Learning a hidden graph using O(log n) queries per
edge,” COLT 2004. [ABK+ 02] N. Alon, R. Beigel, S. Kasif, S. Rudich and B. Sudakov, “Learning a hidden
matching: Combinatorial identification of hidden matchings with applications to wholegeonme sequencing”, SIAM Journal on Computing, 2004.
[ACKM 05] D. Achlioptas, A. Clauset, D. Kempe and C. Moore, “On the bias oftraceroute sampling,” Proc. of ACM STOC 2005.
[BAA+ 01] R. Beigel, N. Alon, S. Apaydin, L. Fortnow and S. Kasif, “An optimalprocedure for gap closing in whole genome shotgun sequencing,” Proc. of ACMRECOMB 2001.
[BBBC 01] P. Barford, A. Bestavros, J. Byers and M. Crovella, “On the marginal utilityof network topology measurements,” Proc. of 1st ACM SIGCOMM InternetMeasurement Workshop, 2001.
[BC 01 (Skitter)] A. Broido and K. Claffy, “Connectivity of IP graphs,” Proc. of SPIEITCom, August 2001.
[CBM 03] J. Considine, J. Byers and K. Mayer-Patel, “A constraint satisfaction approachto testbed embedding services,” Proc. of ACM HotNets Workshop, 2003.
[DIMES] The DIMES project. www.netdimes.org. [DRFC 05] B. Donnet, P. Raoult, T. Friedman, and M. Crovella, “Efficient algorithms for
large-scale topology discovery,” to appear in Proc. of ACM SIGMETRICS, 2005. [FFF 99] M. Faloutsos, P. Faloutsos and C. Faloutsos, “On power-law relationships of
the Internet topology,” Proc. of ACM SIGCOMM ’99.
References cited (p. 1 of 2)

[GK 98] V. Grebinski and G. Kucherov, “Reconstructing a Hamiltonian cycle byquerying the graph: Application to DNA physical mapping,” Discrete Applied Math. 88(1998).
[GT 00 (Mercator)] R. Govindan and H. Tangmunarunkit, “Heuristics for Internet mapdiscovery,” Proc. of IEEE INFOCOM 2000.
[LBCX 03] A. Lakhina, J. Byers, M. Crovella and P. Xie, “Sampling biases in IP topologymeasurements,” Proc. of IEEE INFOCOM 2003.
[MHH 01] P. van Mieghem, G. Hooghiemstra, R. van der Hofstad, “On the efficiency ofmulticast,” IEEE/ACM Transactions on Networking, May 2001.
[PG 98] J. Pansiot and D. Grad, “On routes and multicast trees in the Internet,” ACMComputer Communications Review, 28(1), 1998.
[PST 99] G. Philips, S. Shenker and H. Tangmunarunkit, “Scaling of multicast trees:comments on the Chuang-Sirbu scaling law,” Proc. Of ACM SIGCOMM ’99.
[SMW 02] N. Spring, R. Mahajan and D. Wetherall, “Measuring ISP topologies withRocketfuel,”, Proc. of ACM SIGCOMM 2002.
[SWM 05] M. Stumpf, C. Wiuf and R. May, “Subnets of scale-free networks are notscale-free: Sampling properties of networks,” PNAS 102(12), March 22, 2005.
References cited

















