Page 1
EXPLORING PRONUNCIATION ERRORS THROUGH A
SONG: A CASE STUDY OF 3RD YEAR STUDENTS,
THAMMASAT UNIVERSITY
BY
MISS PATTARAPORN MUANGPHRUEK
AN INDEPENDENT STUDY PAPER SUBMITTED IN PARTIAL
FULFILLMENT OF
THE REQUIREMENTS FOR THE DEGREE OF
MASTER OF ARTS IN
ENGLISH LANGUAGE TEACHING
LANGUAGE INSTITUTE
THAMMASAT UNIVERSITY
ACADEMIC YEAR 2017
COPYRIGHT OF THAMMASAT UNIVERSITY
Ref. code: 25605921042304OWQ
Page 2
EXPLORING PRONUNCIATION ERRORS THROUGH A
SONG: A CASE STUDY OF 3RD YEAR STUDENTS,
THAMMASAT UNIVERSITY
BY
MISS PATTARAPORN MUANGPHRUEK
AN INDEPENDENT STUDY PAPER SUBMITTED IN PARTIAL
FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE
OF MASTER OF ARTS IN
ENGLISH LANGUAGE TEACHING
LANGUAGE INSTITUTE
THAMMASAT UNIVERSITY
ACADEMIC YEAR 2017
COPYRIGHT OF THAMMASAT UNIVERSITY
Ref. code: 25605921042304OWQ
Page 4
(1)
Independent Study Paper Title EXPLORING PRONUNCIATION ERRORS
THROUGH A SONG: A CASE STUDY OF
3RD YEAR STUDENTS, THAMMASAT
UNIVERSITY
Author Miss Pattaraporn Muangphruek
Degree Master of Arts
Major Field/Faculty/University English Language Teaching
Language Institute
Thammasat University
Independent Study Paper Advisor Assistant Professor Watjana Suriyatham, Ed.D.
Academic Years 2017
ABSTRACT
The purpose of this study was to explore pronunciation errors on final consonant sounds
through the song and song lyrics “A Thousand Years” by Christina Perri. The
participants consisted of seven third-year students from Faculty of Innovation,
Thammasat University selected by convenience sampling. Through four phrases of
investigation: reading aloud the lyrics, participants pin-pointing the errors form first
reading while listening to the song, reading aloud the lyrics again and semi-structured
interview, the results showed that participants made pronunciation errors on fourteen
predicted final consonant sounds. They had the difficulty in pronouncing /θ/, /d/, /l/, /z/,
/v/, /nd/, /rt/ and /nt/ sounds and the formation of errors was the substitution of /d/ and
/θ/ with /t/, /z/ was substituted with /s/ and /v/ was substituted with /p/, and consonant
cluster tended to be omitted one of two sounds or both of them. Some of them revealed
that they already knew the rules for pronouncing the problematic final consonant
sounds when they were in an authentic situation but were unable to use them correctly.
Keywords: pronunciation errors, songs
Ref. code: 25605921042304OWQ
Page 5
(2)
ACKNOWLEDGEMENTS
It is a pleasure and great opportunity to express my deepest thankfulness to those who
made this independent study possible.
First of all, I am deeply grateful to my advisor, Assistant Professor Watjana Suriyatham,
Ed. D.; without her continuous guideline, assistance, optimism concerning this work,
and support, this study would hardly have been achieved.
Also, I would like to thank my participants; my relative and her friends, for their help
and cooperation in data collecting procedure for this research.
I would like to show my gratitude to all Ajarns, staff, and friends at the Language
Institute, Thammasat University for their kind support, encouragement and enthusiasm.
Also, I am very thankful to my friends and sisters who always gave me encouragement
during my two precious years.
I own my deepest gratitude to my family who gave me the support essential for studying
a master’s degree. I struggled at first but the support from my family was an aid to help
me pass this two tough years.
Lastly, I am so thankful I have been able to make MA life a success. It would be difficult
for me to continue studying in university for more than six consecutive years, I felt
down many times when my passion and motivation was running out, yet, I got up with
the great support and encouragement from people around me.
Miss Pattaraporn Muangphruek
Ref. code: 25605921042304OWQ
Page 6
(3)
TABLE OF CONTENTS
Page
ABSTRACT (1)
ACKNOWLEDGEMENTS (2)
LIST OF TABLES (6)
LIST OF FIGURES (7)
CHAPTER 1 INTRODUCTION 1
1.1 Rational and background of the study 1
1.2 Objectives of the study 3
1.3 Research questions 3
1.4 Significant of the study 3
1.5 Scope of the study 3
1.6 Limitation of the study 4
1.7 Organization of the study 4
1.8 Definition of terms 4
CHAPTER 2 REVIEW OF LITERATURE 6
2.1 Pronunciation 6
2.1.1 Final sounds' pronuniation issues by Thai learners 7
2.1.1.1 Final consonants 7
(1) The omission of final sounds 8
(2) The substitution of final sounds 8
2.1.1.2 Consonant clusters 8
2.1.2 The causes of pronunciation problems 9
Ref. code: 25605921042304OWQ
Page 7
(4)
2.1.2.1 L1 interference 9
2.1.2.2 Exposure of L2 sounds 9
2.1.2.3 Age and Critical Period Hypothesis (CPH) 10
2.1.2.4 Pronunciation teaching in EFL classroom 10
2.2 The use of songs 11
2.2.1 The advantages of using songs in English classrooms 11
2.2.2 The advantages of using songs on pronunciation 12
2.3 The selection of song 13
2.4 Relevant studies 13
CHAPTER 3 RESEARCH METHODOLOGY 15
3.1 Research design 15
3.2 Participants 15
3.3 Instruments 15
3.4 Data collection 16
3.5 Data analysis 16
3.5.1 The result from reading aloud test 16
3.5.2 The interview of participants 17
CHAPTER 4 FINDINGS AND DISCUSSION 18
4.1 Word Count 18
4.2 The participants’ pronunciation errors (Production) 19
4.3 The perception of participants on the pronunciation errors 21
4.4 The interview results 24
CHAPTER 5 CONCLUSIONS AND RECOMMENDATIONS 30
REFERENCES 32
Ref. code: 25605921042304OWQ
Page 8
(5)
APPENDICES 36
APPENDIX A 37
APPENDIX B 39
APPENDIX C 40
APPENDIX D 46
APPENDIX E 52
BIOGRAPHY 53
Ref. code: 25605921042304OWQ
Page 9
(6)
LIST OF TABLES
Tables Page
1. The word list that were predicted that participants might
create pronunciation errors
18
2. Number of errors with final sounds made by each participant
19
3. The list of frequent words of pronunciation errors
20
Ref. code: 25605921042304OWQ
Page 10
(7)
LIST OF FIGURES
Figures Page
1. The comparison of the number of pronunciation errors in
the 1st production (marked by researcher) and the perception
(marked by participants)
22
2. The comparison of the number of pronunciation errors
between the 1st and 2nd production (marked by researcher)
24
Ref. code: 25605921042304OWQ
Page 11
1
CHAPTER I
INTRODUCTION
1.1 Rationale and Background of Study
As a Thai student, I have been learning English as a foreign language for years,
and I cannot deny that my pronunciation does not quite reach native-like level since
English is uncommonly spoken in Thailand and I rarely speak and practice English in
my daily life. I have found that songs are useful tools to learn and practice the ways to
speak words correctly and smoothly. Most of Thai English speakers lack ability to
pronounce the words in suprasegmental units as there are some features of intonation,
stress and rhythm which do not exist in Thai. However, in order to successfully achieve
communicative competence and create intelligible pronunciation, segment units,
consonants and vowels should be a significant focus. Without understanding
consonants and vowels, speakers might not be able to pronounce target words.
I found that people who are interested in a particular song will keep repeating
listening to the song and practice – imitate – the way the song is sung with correct
pronunciation as much as possible in every single word. On the other hand, if the song
is not in their interest they will just listen to it and ignore how the lyrics sound or how
they are pronounced.
This paper aims to examine pronunciation problems with final sounds by using
the song lyrics “A Thousand Years” by Christina Perri and investigate whether songs
can raise learner’s awareness to notice the errors that they have been making while
reading aloud. According to the lyrics, I have predicted pronunciation errors of final
sounds that will be made by the participants and categorized them into eight sounds as
follows: /v/, /z/, /s/, /l/, /θ/, /t/, /d/, and /k/ and consonant clusters.
Robert Lado (1957) described the relevant obstacles in a statement on
pronunciation and second/foreign language learners as:
“…if we now place two speakers of different language
facing each other in a similar diagram, when each
listener hears an utterance in a foreign language he is
Ref. code: 25605921042304OWQ
Page 12
2
learning, his set of native language habits cannot be
eliminated at will, and he hears units of sounds, words,
phrases and sentences that are those of his own
language, that is he distorts what he hears. Similarly,
when he attempts to speak in a foreign language, he
transfers the entire sound system of his native language
to the foreign language.”
To be proficient in the standard pronunciation and able to accurately distinguish
different kinds of pronunciation are the significant objectives for learners in order that
they can correct their own pronunciation errors (Ellis, 1994). Intelligible pronunciation
allows us to understand worldwide English. Even though English in different countries
is pronounced differently, the similarity in pronunciation (including intonation and
stress) should be close or sufficiently alike in the same words or sentences in any accent
to be comprehensible.
The problems of English pronunciation as a target language for Thai learners
are caused by the influence and interference of Thai as a native language. “Error” is
defined as a piece of written or spoken language produced in second/foreign language
where a native speaker or language expert can detect deficiency or incompleteness.
Error refers to three main sub-types: vocabulary errors, grammatical errors and
pragmatic errors (The Royal Institute, 2010). Bason (1988) mentioned that errors
decrease intelligible pronunciation. The lack of being able to be proficient in
pronunciation creates a big gap between English learners and other English speakers,
especially native speakers. The gap has to be reduced or removed in order to create
intelligibility.
Lo & Li (1998) mentioned that songs play a key role in activating English
learning for students. The use of songs has been around in language learning classrooms
for a long time. According to Levman (2000) and Thomas (1995) (as cited in Bannan
(2012)), music and language has been connected together in academic matters since the
eighteenth century. The use of music and song lyrics in language acquisition can benefit
both linguistic features and the motivational interest in learners as many scholars have
been arguing for so long. (Bartle, 1962; Richard, 1969; Jolly, 1975).
Ref. code: 25605921042304OWQ
Page 13
3
Song has a common nature that can provide a productive and non-threatening
atmosphere in the class for both teacher and students. Song decreases students’ stress
and anxiety; not only does it lower affective filters, but it also creates effectiveness in
language acquisition (York, 2011). Furthermore, songs are considered a powerful
teaching instrument that can be applied with learners in several ways. Besides the basic
skills, listening, speaking, reading and writing, sentence patterns, vocabulary, rhythm,
word functions and pronunciation can be developed by songs. Murphy (1992) stated
the advantage of music and songs in language learning was that songs could be assistant
materials to improve human speech development; it can be said that it is easier to sing
language than to speak it.
1.2 Objectives of the Study:
To identify the problematic sounds in final consonants for the participants who
were not majoring in English.
To investigate whether the participants could notice their English pronunciation
errors with final sounds through a song.
1.3 Research Questions:
1. What are the learners’ pronunciation errors in final sounds?
2. Are learners able to notice their English pronunciation errors in final sounds
through a song?
1.4 Significance of the Study:
1. To examine pronunciation problems with final sounds by using the song
lyrics “A Thousand Years” by Christina Perri
2. To investigate whether song can raise learner’s awareness to notice the
errors that they have been making while reading aloud.
1.5 Scope of the Study:
As the participants were students in a Thai major, they had not learned about
phonetics or how words are pronounced before, so, it was difficult for them to classify
the words in different features and pronounce each word correctly.
Ref. code: 25605921042304OWQ
Page 14
4
1.6 Limitations of the Study:
This study only focuses on problematic final consonant sounds. Other parts such
as vowels and initial consonants are not emphasized. Moreover, there is no supra-
segmental unit analysis, such as investigation of intonation, stress, rhythm etc.
Due to the limits of resources and time, the participants numbered only seven
students; all of them were voluntary. It was difficult for the researcher, who is not
working as a teacher, to gain many participants. Additionally, the song that was used
as an instrument was the only song due to the limited time available for meeting each
participant. Also, the song “A Thousand Years” does not contain all the target final
problematic sounds where Thai learners will produce errors. The results of this study
might not be generalized.
1.7 Organization of the Study:
This study of exploring pronunciation errors through a song, a case study of 3rd
year students, Thammasat University, is distributed into five chapters.
Chapter I covers rationale and background, objectives, research questions,
significance, and scope of the study and definitions of terms.
Chapter II reviews the relevant academic literature and relevant research.
Chapter III illustrates the methods used in the study, which includes subjects,
materials, procedures and data analysis.
Chapter IV shows the data gathered from reading aloud production and
perception through a song, and interviewing to investigate pronunciation errors, and
the discussion of the results.
Chapter V presents a summary of the study, conclusions and recommendations
for further study.
1.8 Definition of Terms
1. Errors: the flawed side of learner speech or writing
2. Pronunciation errors: an omission or substitution of other sounds into
target final sounds
3. Segmental: the aspects in phonetics primarily refer to an individual unit
that can be identified, such as consonants and vowels
Ref. code: 25605921042304OWQ
Page 15
5
4. Suprasegmental: the aspects of speech beyond the level of the individual
unit: rhythm, stress and intonation
5. Final consonant: the final speech sound produced with a significant
compression of the airflow in the oral tract
6. Final consonant clusters: the combination of two or more consonants
together occurring in the final part of words. e.g., last, final, consonants
Ref. code: 25605921042304OWQ
Page 16
6
CHAPTER II
REVIEW OF LITERATURE
2.1 Pronunciation
Pronunciation is the production of sounds in order to create meaning. Its
functions contain 2 main features: segmental and suprasegmental aspects. Segmental
unit refers to the particular sound of a language, while suprasegmental unit concerns
intonation, phrasing, stress, timing and rhythm (AMEP, 2002). The message can be
clearly conveyed if speakers have a good pronunciation, even though there are some
parts, such as grammar or vocabulary, broken. Dalton & Seidlhofer (1994) listed the
significance of pronunciation in two senses: first, it is used as “part of a code of
particular language” and second, it is used to “achieve meaning in context of use”.
In order to create intelligible pronunciation, both main features should be
combined together when speaking, though these two units are taught separately. It is
significant for teachers to know how these two aspects differ in terms of theory and
practice, in contrast, learners should necessarily be concerned more with practical
activity.
There are five basic components of pronunciation: intonation, stress and
rhythm, vowels, consonants, and voiced and voiceless production.
1. Intonation: Intonation is the way a voice goes up and down in pitch when we
are speaking, and the rise and fall of our voice as we speak.
2. Stress and rhythm: Stress refers to certain syllables of energy or effort that
are pronounced by English speakers and signals significant matter in a
sentence. Rhythm refers to the regular strong stress or syllables in a sentence
that is created.
3. Vowels: A vowel is a speech sound produced by humans when the breath
flows out through the mouth without being blocked by the teeth, tongue, or
lips. There are 5 vowels in English (a, e, i, o, u). The combination of vowels
in English is called diphthongs.
4. Consonants: Consonant is defined as a part of speech and a sound that is
articulated with complete or partial closure of the upper vocal track.
Ref. code: 25605921042304OWQ
Page 17
7
5. Voiced and Voiceless: English sounds are either voiced or voiceless. All
vowels in English are voiced while some consonants are voiced or voiceless.
Generally, it seems to be a traditional method to emphasize and focus on
segments which are obvious and where it is easier to notice the errors (AMEP, 2002).
Burns (2003) stated that a word is created by consonants and vowels combined, and its
sound is made up of phonemes. Phonemes are key sounds, and the meaning of the word
can change when the word is pronounced incorrectly. Nevertheless, this study will
mainly focus on segmental features due to the fact that the researcher is able to detect
any particular mispronounced sounds with ease and measure student error; intonation,
stress and connected speech are also determined as a secondary factor.
2.1.1 Final Sound Pronunciation Issues for Thai Learners
2.1.1.1 Final Consonants
According to the focus of study, the pronunciation issues will emphasize only
segmental features: consonants. Researchers have indicated the pronunciation issues
produced by Thai learners cover segmental aspects in many different cases. One of the
most important problems is the final consonants; they cause Thai pronunciation
problems as there are only eight consonants that Thais are able to pronounce in the final
position: /n/, /m/, /ŋ/, /p/, /b/, /d/, /t/, /k/, /j/, /w/ (McKenzie-Brown, 2006). The
voiceless consonant sounds /p, t, k/ are produced with a puff of air called aspiration.
These sounds are likely to be problematic for Thai speakers as they pronounce them
unclearly at the end. It can be said that the sounds are not emphasized when
pronouncing words which probably causes the problems when other types of error are
made at the same time and it is important in terms of conveying target messages
correctly.
Wei & Zhou (2002) stated the major pronunciation problems with consonants
produced by Thai learners are omitted final consonant sounds, consonant clusters, /r/
and /l/ sounds, /θ/ and /ð/ sounds, /v/ sounds, /s/ and /z/ sound and /ʒ/ sound. In addition,
“The Pronunciation of English Final Consonant Clusters by Thai Students” research by
Mano-im (1999) showed that learners tended to mispronounce some sounds by deleting
one of two sounds, replacing one or both sounds, removing one sound and substituting
with another sound, or adding an extra sound.
Ref. code: 25605921042304OWQ
Page 18
8
Also, when focusing on sound errors, Thais seem to have great problems
pronouncing some consonants, especially when they occur in the final position, (Swan
& Smith, 2001). They mentioned that final sounds are systematically substituted for
other sounds.
According to many studies on Thai learners’ pronunciation problems, the
pronunciation issues on final sounds can be considered in two aspects, the omission and
the substitution of final sounds.
1.) The Omission of Final Sounds
Thai learners tend to omit consonant sounds occurring at the end of words. It is
obviously seen when the words end with /s/, /z/, /t/, /d/, /f/, /v/, /ð/, /θ/ or /dʒ/ sounds.
This is due to the fact that Thai has no ending fricative and plosive sounds.
2.) The Substitution of Final Sounds
Thai learners tend to replace some final sounds with a small class of unreleased
consonants. Researchers have also found that the formation of the final consonants
substitution in Thai speakers are quite systematic in three ways:
1. The /s/, /z/, /d/, /ð/, /θ/, /ʒ/, /ʃ/, /tʃ/, /dʒ/ are pronounced as a /t/ sound.
2. The /v/ and /f/ seem to be substituted with a /p/ sound
3. The /l/ is replaced with an /n/ sound.
2.1.1.2 Consonant clusters
Unlike English, clusters in Thai occur when two or more consonant sounds have
an intervening vowel between. Many non-native speakers (Chinese, Thai, etc.),
therefore, have difficulty in pronouncing some English words; for example, spade,
sixth, and risked. However, when it comes to the final sounds, it seems to be more
difficult as Thai does not have final consonant clusters; consequently, some consonants
in these clusters can either be substituted or omitted. In this way, learners tend to
mispronounce some sounds by deleting one of two sounds, replacing one or both
sounds, removing one sound and substituting with another sound, or adding an extra
sound into final target sounds.
Ref. code: 25605921042304OWQ
Page 19
9
2.1.2 The Causes of Pronunciation Problems
2.1.2.1 L1 Interference
Dulay, Burt, and Krashen (1982:101) accounted for the influence from L1, or
language transfer, as “the use of past knowledge and experience in new situation” (cited
in Phintuyothin, 2011). Language transfer is one of the most important and
distinguishable characteristics in learning second language, to illustrate, the
dissimilarity in pronouncing the English word “have” by German and French native
speakers (Archibald, 1998: 2).
L1 transfer created the Contrastive Analysis Hypothesis (CAH), a theory
proposed by Robert Lado (1957). CAH aims to predict L2 learners’ problems and
describe the differences or similarity of L1 and L2 linguistic systems thoroughly
(Saville-Troike, 2006:34). Celce-Murcia et al., (2010:22) stated that L2 acquisition is
penetrated by L1 if the target language differentiates or non-exists in L1. The result,
therefore, creates two kinds of transfer: positive transfer and negative transfer.
According to the theory of Wardhaugh (1983), CAH can predict learners’
difficulties and deliver appropriate language instruction promptly. He stated the CAH
in two conditions: a strong version and a weak version. A strong version of CAH
purposes to predict errors while a weak version goal is to explain the errors after the
fact. Besides, there is a moderate version of CAH which is disputed that it is easier for
learners to learn the difference of L1 and L2 than the similarity (Oller and Ziahosseiny
1970, as cited in Major 2008). According to many studies, Major (2008) concluded that
“the larger the differences are, the more easily they tend to be noticed; therefore,
learning is more likely to take place”.
The CAH has an effect in L2 pronunciation texts and pedagogical guides
(Edwards and Zampini, 2008). The language transfer characteristic, particularly
negative transfer, has evidence explaining foreign accents, particularly in the
pronunciation acquisition of typical segmental units such as aspiration and voicing, and
of suprasegmental units such as intonation and rhythm (Celce-Murcia et al., 2010).
2.1.2.2 Exposure of L2 sounds
Practicing is one of the main factors that improves L2 pronunciation
intelligibility; the insufficiency of drills leads to lack of success in acquiring native-like
Ref. code: 25605921042304OWQ
Page 20
10
accent and strengthens the mother language phonology (Khamkhien, 2010). The review
study of Khamkhien, as shown in Siriwisut (1994) and Serttikul (2005), states
“Learners’ pronunciation ability is affected by the amount of exposure to the target
language in their daily lives” (cited in Phintuyothin, 2011). These studies imply that the
more learners are exposed to target language or L2, the more they avoid interference
by L1 pronunciation; consequently, good pronunciation is the result of that.
Exposure to the target language is described by Krashen’s theories (1982): “The
Input Hypothesis” stated that “learners acquire language implicitly through a large
amount of exposure to language input that is a little bit beyond the learner’s current
level yet still comprehensible to the learner” (cited in Phintuyothin, 2011). He also
believes that if learners are exposed to the target language input adequately, the
acquisition will come naturally.
2.1.2.3 Age and Critical Period Hypothesis (CPH)
Age is one of the factors that has a huge impact on native-like pronunciation. A
lot of previous research has illustrated that learners who start to learn L2 at the young
age, in the environment of L2 is normally used and spoken, tend to be more native-like
than those who start at adult age (Flege et al., 1995; Piske et al., 2001; Abu-Rabaia &
Illiyan, 2011 cited in Phinuyothin, 2011). The study of Cenoz (2003) and Munoz (2007)
has shown that learners for whom the exposure of L2 starts at the age of two tend to
outperform the learners who start at the age of four to eight in terms of English
proficiency.
2.1.2.4 Pronunciation Teaching in EFL Classroom
Murphy J. (2003) described the trend of teaching pronunciation from the past
to present in three orientations, listen-and-repeat method, giving more emphasis to
explicit pronunciation teaching, and using authentic material respectively.
“Listen carefully and repeat what I say” (1940s–1950s). Learners had to
duplicate what the teacher said; they listened and memorized then repeated.
Pronunciation was not taught explicitly; learners had to learn by imitating what they
learnt.
Ref. code: 25605921042304OWQ
Page 21
11
“Let’s analyze these sounds closely to figure out how to produce them more
clearly” (1960s–1970s). The pronunciation was taught explicitly in this era; students
would learn about the features of the sound system or phonetic symbols in L2 with the
aid of visual and audio materials.
“Let’s start using these sounds in activities as soon as we can while I produce
cues and feedback on how well you’re doing” (1980s–present). This approach aims to
emphasize interactive activities in actual classrooms after learners receive an
explanation of the construction of sounds in order to use target language successfully,
with authentic tools in real-world contexts.
The use of songs is a genuine material for learners as it provides interactive
activity and implicit pronunciation teaching. The use of English songs engages top-
down processing – looking from broad meaning of the language input and then
narrowing to small details, by which implicit knowledge is delivered, at first through
the exposure to English songs.
2.2 The Use of Songs
The use of songs has been employed in language learning classrooms for a long
time as songs play a key role in activating English learning for students (Lo & Li, 1998).
It is not a modern trend applying songs and music to English language learning; the use
of music and song lyrics in language acquisition, as many scholars have been arguing
for so long, can benefit in both linguistic features and the motivational interest of
learners. (Bartle, 1962; Richard, 1969; Jolly, 1975).
2.2.1 The Advantages of Using Songs in English Classroom
According to Lo & Li (1998), song plays a significant role in activating English
learning for students. The use of songs has been evident in language learning
classrooms for a long time. Researchers have been conducting research supporting the
use of songs in English language classroom. Applying songs in SLA has become
popular among English teachers; thea number of investigations about songs in language
teaching has rapidly grown in recent years (Wallace, 1994; Schon, et al., 2008).
Furthermore, the advantages of using songs in the classroom were outlined by
York (2011), stating that song has its common nature that can provide a productive and
Ref. code: 25605921042304OWQ
Page 22
12
non-threatening atmosphere in the class for both teacher and students. Song decreases
students’ stress and anxiety; it not only lowers the affective filter but also creates
effectiveness in language acquisition.
Listening to music has an effect on vocabulary. The importance of this
connection is proved by a number of research studies about the correlation. Rhythm,
melody and lyrics seem to be the principle factors that draw listener attention (Fonseca-
Mora et al. 2011).
2.2.2 The Advantages of Using Songs on Pronunciation
It seems that motivation produces effects on English learners’ pronunciation
when it comes to learning English by songs. There are studies which show that songs
are involved in learning motivation and learning performance in English language
classrooms (Bake, 2007; Luo 2008). Consequently, it seems that motivation has effects
on English learners’ pronunciation when it comes to learning English by songs.
Additionally, Nicoleta (2015) stated that songs are a tool for accessing different kinds
of English: Standard English – the English which is used in most EFL classroom,
British English (BrE) and American English (AmE). Different kinds of English have
their own accents and pronunciation styles and it is hard for students to understand all
those types of English by just learning from the classroom, so music and songs help
them understand, then they can satisfactorily communicate. Being native like is not the
most important aspect in communication; to be able to communicate and pronounce
target language correctly is.
Not only the songs, but the use of song lyrics, can also be an aid to assist learners
in pronouncing final consonant sounds. Lin, Fan, & Chen (1995) illustrated that
teachers could use the lyrics of some popular songs and let students read aloud in order
to practice final consonant sounds. They gave an example of their classroom in which
students tended to either omit final consonants or hardly pronounce them - they
pronounced ‘studen’ instead of ‘student’. Students then listened to songs to notice how
the word is actually pronounced.
Ref. code: 25605921042304OWQ
Page 23
13
2.3 The Selection of the Song
Songs allow students and teachers a valuable opportunity to practice English
pronunciation in many different features. The songs used in a classroom should be
carefully selected according to the level of proficiency, which is very significant.
Kristen (2001) mentioned that “Students are often strongly motivated to learn the lyrics
of a new pop song or an old favorite they have heard and never understood, so their
choices for classroom music should not be overlooked.”
The song “A Thousand Years” has quite clear pronunciation of each word in both initial
and final sounds. The final consonant sounds, which are problematic for Thai speakers,
are fully pronounced, for example, in the words heart, beats, fast, promises, brave,
afraid, believed and breath – the song pronounces with clearly endings /t/, /ts/, /st/, /z/,
/v/, /d/, /d/, and /θ/ sounds respectively.
2.4 Relevant Studies
There is no exactly relevant study about using a song for identifying
pronunciation errors without drilling in the classroom. A lesson plan and instructions
are the majority tools in many studies to seek out learners’ pronunciation errors, as well
as to improve the errors. Numerous studies have substantiated the progress of students
by giving them pre-test and post-test, then the scores will be compared and summarized
as to whether students improve their pronunciation through songs.
The study of Farmand Z. & Pourgharib B. (2013) explored whether using
English songs can increase students’ motivation in learning English and EFL learner’s
pronunciation. The study was done on 30 EFL students, intermediate level, in an
English Institute of Mazandaran, Iran. The research was conducted with two groups,
control group and experimental group, with pre- and post-test experimental design. The
pre-test evaluated reading and pronunciation ability that was picked from vocabulary
words in the songs for both groups. The experimental group received different types of
English song teaching for eight sessions, fifteen minutes each, and the effect on
pronunciation was investigated after the instruction. Results showed that the use of
English songs had impact on language learners’ pronunciation, and it improved oral
production.
Ref. code: 25605921042304OWQ
Page 24
14
Pimwan (2012) investigated “The Effect of Teaching English Pronunciation
through Songs of Prathomsuksa 4 Students at Watratchaphatigaram School” with
twenty-two participants. The focus of the study was on the final sounds of /k/, /g/, /l/,
/r/, /s/, /z/, /t, /d/. The research instruments were pre- and post- pronunciation tests and
10 lesson plans. The data was analyzed using the SPSS program, by mean, standard
deviation and t-test dependent. The results exposed the differences in learners’ English
proficiency ability and levels. She concluded that participants were able to pronounce
the final consonant more accurately after learning English through songs.
In the study of Stanculea (2015) the usage of songs in different aspects of
pronunciation such as using songs to focus on sounds, particular sounds and minimal
pairs, words and connected speech was investigated. The researcher believed that the
syllabus does not include pronunciation features teaching like songs do and little
emphasis is put on teaching pronunciation in English language classrooms. The
communicative approach to language teaching encourages the acquisition of these
aspects of the language rather than their learning.
Ref. code: 25605921042304OWQ
Page 25
15
CHAPTER III
METHODOLOGY
3.1 Research Design
The strategy employed in this study is a case study; the aim of study is to explore
the pronunciation errors of final sounds by applying song to the research in order that
learners are able to notice their pronunciation errors.
3.2 Participants
As the participants were limited in number and voluntary, the sampling was
only seven learners; all of them agreed to take part in this study by signing a consent
form. They were 3rd-year students in the Faculty of Innovation, Thammasat University
(Thai Program). Their ages were about twenty to twenty-one years old. They had
studied basic English courses for specific purposes such as communicative skills and
cultural management, which approximates their level as intermediate. They were
systematically selected to investigate the errors made by each person. They received
the same activity and treatment during the investigation.
3.3 Instruments
To be able to answer the research questions, three instruments were utilized:
The first was “A Thousand Years” song lyrics which was a tool to identify
learners’ pronunciation errors. The lyrics mainly contain eight problematic sounds of
final consonants: /v/, /z/, /s/, /l/, /θ/, /t/, /d/, and /k/ and consonant clusters /nd, rt, st/.
The second instrument was the audio of the song “A Thousand Years”. The
song was played twice to the participants to see whether they could notice the
problematic sounds that they produced in the first reading.
The third instrument was a semi-structured interview. The interview comprised
open-ended and closed-ended questions and was divided into two parts: background
and personal information of the participants and the questions related to songs and
pronunciation.
Ref. code: 25605921042304OWQ
Page 26
16
3.4 Data Collection
The song lyrics were given to each participant to read aloud; the data collection
was taken in four phases as follows:
Error Investigation: Participants read aloud the lyrics; this procedure was
audio recorded. The researcher then marked the final sound errors from their reading
of the lyrics, with each word separated into a table that showed where the participants
had pronunciation problems.
Final Sound Errors’ Perception: Participants listened to the song “A
Thousand Years” twice. They then indicated the sounds that they thought were
problematic from their first reading pronunciation by highlighting the words in the
lyrics paper.
Errors Investigation Summary: Participants read aloud the lyrics after
listening to the song twice (audio recorded). The researcher then marked the final sound
errors that either occurred or were corrected in the second reading aloud.
Semi-structured Interview: The interview was conducted at the end of the data
collecting process to gain more reliable and practical information about participants’
pronunciation errors and the use of songs.
The pronunciation problem sounds that were recorded were categorized under
the guidance of phonemic transcription in the Cambridge English Pronouncing
Dictionary. The recording was replayed many times and the pronunciation errors of the
final sounds noted.
3.5 Data Analysis
So that the two research questions were able to be answered, the results were
evaluated into two parts as follows:
1) The Results from Reading Aloud Test
In this part the results were carefully investigated and transcribed into three
main aspects: 1.1 The pronunciation errors on final sounds that learners made before listening
to the song, which were marked by the researcher.
Ref. code: 25605921042304OWQ
Page 27
17
1.2. The pronunciation errors on final sounds that learners noticed that they had
made in the first reading aloud, which were marked by learners themselves while
listening to the song twice.
1.3. The pronunciation errors on final sounds that learners made after listening
to the song, which were marked by the researcher.
Consequently, the results were compared in order to evaluate whether song
could be a tool to enhance their notice of pronunciation errors, and whether participants
were able to correct their errors.
The problematic sounds that were made by the subjects before listening to the
song (1st production) were indicated as pronunciation errors. Based on the theories
relating to pronunciation errors in Thai EFL, the causes of the errors were diagnosed in
two ways:
1. Final sounds were omitted or unpronounced.
2. Final sounds were substituted with other sounds.
2) The Interview of Participants
This interview was intended to find out participant’s perception of error making,
their own errors in pronunciation that they usually made, as well as the causes of error
making. Also, the advantages of using song for error identification and teaching
pronunciation was discussed. This interview took place in a very informal and relaxed
atmosphere, thus the students could share their opinions openly and freely.
Ref. code: 25605921042304OWQ
Page 28
18
CHAPTER IV
FINDINGS AND DISCUSSION
The previous chapter outlined the introduction, the review of literature and
methodology. This chapter describes the results of the study based on the data collected
from seven learners from the Faculty of Innovation, Thammasat University.
In order to answer research questions, the results of the analyzed data are
divided into two parts: pronunciation errors made by participants and the comparison
between the errors production and perception.
4.1 Word Count
There are seventy-four words in total in the song lyrics “A Thousand Years”
(Appendix E). The number of word summary includes vocabulary words such as,
nouns, pronouns, verbs, preposition, adjectives, adverbs, etc., however, articles and
duplicate words were excluded from the number counted.
Thirty out of seventy-four words were predicted as final sounds pronunciation
errors which participants might have made during the reading aloud.
afraid loved don't breath take front
all promises doubt brought this goes
beats stand fall colors will have
believed step fast died years heart
brave still find love let I’ll
Table 1: The word list that were predicted that participants might create pronunciation
errors
The final sounds of those predicted words comprise of fourteen sounds; ten final
consonant sounds: /d, l, s, z, d, t, p, v, k, θ/ and four final consonant clusters: /nd, rt, st,
nt/. The predicted final sounds were selected from various previous studies on the
sounds that are problematic among Thai learners.
Ref. code: 25605921042304OWQ
Page 29
19
4.2 The Participants’ Pronunciation Errors (Production)
The number of pronunciation errors made by each participant, most frequent
errors that are made by participants and final consonant sound and consonant cluster
that cause participant errors are illustrated in this part.
The identification of pronunciation errors, which were made while reading the
lyrics aloud, was diagnosed into two major problems as indicated in chapter three: the
omission of final consonant sounds and the replacement of other sounds for target final
sounds; both were counted as pronunciation errors.
The number of the problematic sounds that were not pronounced correctly by
each participant are represented in the table below:
P1 P2 P3 P4 P5 P6 P7
/θ/ 1 1 1 1 1 1 1
/d/ 4 4 3 3 2 5 3
/l/ 1 3 3 2 2 2 1
/z/ 3 2 2 2 1 3 1
/s/ 1 1 1 1 0 1 0
/v/ 2 1 0 0 0 1 1
/t/ 1 1 0 1 0 3 2
/rt/ 1 1 1 1 0 1 0
/st/ 1 1 0 0 0 1 0
/nd/ 2 2 2 2 0 1 2
/nt/ 1 1 1 1 0 1 0
Total 18 18 14 14 6 20 11
Table 2: Number of errors with final sounds made by each participant
The number of errors made by participants was between six to twenty, the
average was about fifteen errors. The numbers are quite comparable since their level of
English proficiency was similar. However, there was one participant who outperformed
the others. While twenty was the highest number that the participants made in errors on
Ref. code: 25605921042304OWQ
Page 30
20
final sounds, the least was only six, so the gap between the highest and the least error
making is quite big.
Of the pronunciation errors analysis in the song lyrics, unfortunately, the lyrics
contain only seven problematic final consonant sounds: /θ, d, l, z, s, v, t/ and four final
consonant clusters: /nd, rt, st, nt/. The results from the seven participants displayed that
the pronunciation errors on final sounds had been discovered in twenty-five words:
breath, loved, died, fall, find, goes, promises, afraid, take, believed, doubt, front, heart,
stand, all, beats, brought, I’ll, let, love, fast, years, brave, but and don’t. The errors were
diagnosed in detail for every participant (see appendix B).
In the reading aloud test, the top pronunciation errors made were /θ/, /d/, /l/, /z/
and /v/ sounds. The formation in making the errors was quite similar for each
participant, i.e., the substitution of /d/ and /θ/ with /t/, /z/ was substituted with voiceless
sounds /s/ and /v/ was substituted with /p/. Consonant clusters tended to be omitted one
of two final sounds or both of them as there is no existence in Thai’s final consonants.
Table 1 depicts the words from song lyrics that were mispronounced by the participants
from the reading aloud.
The frequency
of the errors
(participants)
Words that
are Wrongly
pronounced
Correct Final
Consonant Sounds
Incorrect Final Consonant
Sounds
7 participants breath /θ/ substitution with /t/ or /d/
loved /d/ omission of /d/
6 participants
died /d/ omission of /d/
fall /l/ omission of /l/
find /nd/ omission of both /n/ and /d/
goes /z/ substitution with /s/
promises /z/ substitution with /s/
afraid /d/ substitution with /t/ or /s/
5 participants
believed /d/ omission of /d/
doubt /t/ omission of /t/
front /nt/ omission of /t/
Ref. code: 25605921042304OWQ
Page 31
21
Table 3: The list of frequent words of pronunciation errors (most to least)
From the data above, it shows that the participants had difficulty in pronouncing
words in -ed form, such as in the words ‘believed’ and ‘loved’. They tended to omit the
final /d/ sound when making the utterance of the words. Likewise, none of the
participant could pronounce the word ‘breath’ correctly. ‘Breath’ is pronounced with
final /θ/ which is one of the most difficult sounds for Thai speakers since Thai has no
dental sound, so that the sound is mostly substituted with /t/ or /d/.
Regarding the pronunciation problem that was predicted (by Smyth, 2001; Wei
& Zhou, 2002) /l/ is altered and pronounced as /n/ when it comes to appear in a final
position. Nonetheless, the investigation from seven participants in this research found
that they tended to omit the /l/ sound instead of substituting with /n/, for example, ‘fall’
/fɔl/ has been pronounced without /l/ as /fɔ/, ‘all’ /ɔl/ has been pronounced as only
vowel sound /ɔ/ and I’ll /aɪl/ is reduced to /aɪ/ with no /l/.
4.3 The Perception of Participants on the Pronunciation Errors
Here perception means the opinions from participants on vocabulary where they
made pronunciation errors comparing to what they have been listening to. The
production is the actual pronunciation errors that participants created while reading
aloud the song lyrics; the production was recorded by the researcher in both 1st and 2nd
reading aloud.
heart /rt/ omission of /r/
stand /nd/ omission of /d/
4 participants
all /l/ omission of /l/
beats /s/ omission of /s/
I’ll /l/ omission of /l/
3 participants love /v/ substitution with /p/
2 participants fast /st/ omission of /t/
years /z/ substitution with /s/
1 participant brave /v/ substitution with /p/
don’t /t/ omission of /t/
Ref. code: 25605921042304OWQ
Page 32
22
The participants were assigned to highlight the pronunciation errors that they
made in the first listening while they were listening to the song “A thousand years”
twice. The results of the participants’ perception were thoroughly analyzed to see
whether song can be a tool to raise their notice of pronunciation mistakes. However,
none of the participant was capable of identifying all of the pronunciation errors they
had made. Yet, some of the errors such as in the words beats, brave and promises, are
easily noticed according to the song that clearly pronounces these words.
In the 2nd reading aloud test, after listening to the song, participants were able
to correct their mistakes from the highlighted lyrics sheet. Some of them could correct
the errors that were clearly and explicitly heard from the song such as in the word love.
The comparison of the number of pronunciation errors made between the 1st and 2nd
production and the perception is illustrated in chart two.
Chart 1: The comparison of the number of pronunciation errors in the 1st
production (marked by researcher) and the perception (marked by participants)
According to the chart, it is clearly seen that there was one participant
(participant 7) who picked up their pronunciation errors in the number that was close
to their authentic errors production, while the others managed a perception lower than
a half of their genuine errors. The tendency shows that participants who made a large
number of pronunciation errors tended to be able to have the awareness in noticing
more mistakes that the person who created less errors.
18 17
14 14
6
21
11
5
8
4 5
1
79
0
5
10
15
20
25
Participant1
Participant2
Participant3
Participant4
Participant5
Participant6
Participant7
Pre-listening (1st Production) While listerning (Perception)
Ref. code: 25605921042304OWQ
Page 33
23
While the perceptions of participants on their own pronunciation errors are
obviously different from the productions in the first reading aloud, the number of errors
that participants were able to notice is astonishingly low. However, if we look into
details, the comparison table of words that they noticed (in Appendix D) shows that
‘breath’, ‘promises’, ‘doubt’, and ‘believed’ are easily noticeable in terms of final
sound errors. Six out of seven participants marked that ‘breath’ was one of the errors
they created.
Meanwhile, there were some vocabulary words that they did not literally make
pronunciation errors on as final sounds but were marked as errors. The most remarkable
ones are ‘brave’ and ‘take’; participants did not realize that they had already created
correct target final sounds in the first reading aloud.
On the other hand, ‘brought', and ‘thousand’ were highlighted as errors but not
on the focus of final sounds, since the researcher did not assign to participants at first
that the focus of study was only on the final sounds, due to the fact that the findings can
create diversity in pronunciation errors in other focused features. Therefore, three of
the participants underlined irrelevant target sounds. In this case, the problem is that they
did not know how exactly the words are pronounced; they made pronunciation errors
on the vowels in ‘brought’ and the initial consonant in ‘thousand’.
After participants listened to the song and made their decisions on the error
perception by themselves, they were asked to read the lyrics aloud again to investigate
whether they could correct the errors that they had made in the first reading aloud. The
number of pronunciation errors in the 2nd reading aloud and the comparison between
1st and 2nd readings aloud are illustrated in the chart below.
Ref. code: 25605921042304OWQ
Page 34
24
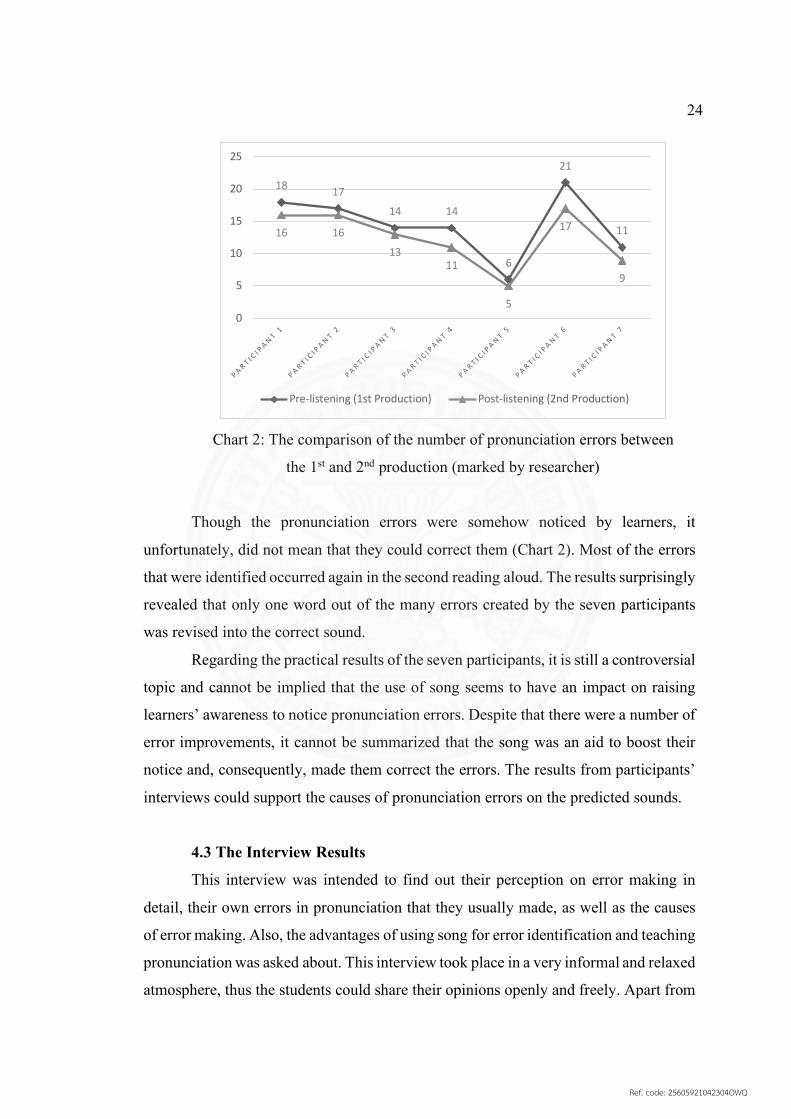
Chart 2: The comparison of the number of pronunciation errors between
the 1st and 2nd production (marked by researcher)
Though the pronunciation errors were somehow noticed by learners, it
unfortunately, did not mean that they could correct them (Chart 2). Most of the errors
that were identified occurred again in the second reading aloud. The results surprisingly
revealed that only one word out of the many errors created by the seven participants
was revised into the correct sound.
Regarding the practical results of the seven participants, it is still a controversial
topic and cannot be implied that the use of song seems to have an impact on raising
learners’ awareness to notice pronunciation errors. Despite that there were a number of
error improvements, it cannot be summarized that the song was an aid to boost their
notice and, consequently, made them correct the errors. The results from participants’
interviews could support the causes of pronunciation errors on the predicted sounds.
4.3 The Interview Results
This interview was intended to find out their perception on error making in
detail, their own errors in pronunciation that they usually made, as well as the causes
of error making. Also, the advantages of using song for error identification and teaching
pronunciation was asked about. This interview took place in a very informal and relaxed
atmosphere, thus the students could share their opinions openly and freely. Apart from
18 17
14 14
6
21
1116 16
1311
5
17
9
0
5
10
15
20
25
P A R T I CI P
A N T 1
P A R T I CI P
A N T 2
P A R T I CI P
A N T 3
P A R T I CI P
A N T 4
P A R T I CI P
A N T 5
P A R T I CI P
A N T 6
P A R T I CI P
A N T 7
Pre-listening (1st Production) Post-listening (2nd Production)
Ref. code: 25605921042304OWQ
Page 35
25
the personal information questions, six close-ended questions were asked to the
participants, with sub-questions that allowed them to display their views and attitudes
towards the topics.
1. Do you like listening to English songs?
1.1 how often?
All of the participants were fond of listening to music. When asking about their
preferences about listening to English songs, most of them preferred listening to
popular English songs in particular periods, or those that were in hit charts, as well as
listening to Thai songs. Whereas there was a person (who made the most pronunciation
errors on the task) that did not normally listen to English songs and the participant who
outperformed others normally listened to English songs rather than Thai songs.
2. Do you notice that you have made pronunciation errors after listening
to the song?
2.1 What words do you make errors on?
All of them noticed that they had made errors and were able to describe some
errors. They could notice the errors in the words promises and breath clearly. Some of
them noticed the errors in final -ed sounds and knew that they omitted them while
reading aloud the song lyrics. They also stated that most of the vocabulary words in the
song had quite clear pronunciation at ending sounds. Also, some of them had known
the song before; they could sing it right away after seeing the lyrics.
Extract 1:
P4: I equally listen to Thai and English songs, especially, the songs which
were popular in each period of time or were on the charts.
P5: I often listen to English songs, I am fond of them.
P6: I barely listen to English songs, I just listen to them when they have
been played by my friends.
Ref. code: 25605921042304OWQ
Page 36
26
3. Do you know how th, -ed, -es, and v are pronounced? How?
All of them knewthe rules and the ways of pronouncing th, -ed, -es, and v before.
The participants that made the errors in those ending sounds stated that they had
forgotten the rules when it came to the authentic situation and were unable to use them
correctly. They also demonstrated how these sounds should be pronounced.
4. Is it possible for a person who has never known how to pronounce to
pronounce it correctly?
Five of the participants agreed that people who have never known the ways to
pronounce those words would not be able to make them correct, while two participants
suggested that there could be a reason that they somehow pronounce the words
correctly, such as they imitate the lyrics or they fortunately pronounce them correctly.
Extract 2:
P2: I knew that I must have made some errors during reading aloud.
P3: I noticed that I cannot pronounce the word breath.
P6: I mostly cut the final -ed sounds when pronouncing words.
Extract 3:
P2: I have studied the rules of using -ed and -es since the young age but I
forget to use it when it comes to real situation.
P3: I knew that th and v are pronounced with the movement of my mouth
and tongue but I get used to pronouncing in Thai way.
Extract 4:
P1: I do not think s/he can do it. S/he might pronounce it closely to how it is
actually pronounced, but there could be some mistakes on the place of
articulation as in [th] sound.
P3: It could be possible. I think they could imitate from the songs, even
though they have never known how some words are pronounced.
P5:
P6:
Ref. code: 25605921042304OWQ
Page 37
27
5. Does listening to music help you pronounce words correctly?
Most of the participants did not express an agreement on whether it could help
or not; they said that it depends on the songs and the focused sounds. They said that
songs could help them to have better pronunciation, but not in the particular words
because songs have intonation, contraction between sounds and reduction of some
sounds. They also stated that if they kept repeating listening to one song it might help;
but when it comes to another context usage, they could forget how to pronounce and
made the mistakes again.
6. Do you prefer learning pronunciation explicitly by teacher/native
speaker or teaching through songs? Why?
Five of seven participants thought that learning English explicitly will help them
in learning pronunciation rather than songs. One gave the reasons that songs have
complex lyrics and structures, and the ways songs pronounce each word is inconsistent
according to each song. One participant said that he preferred listening to the song and
following the lyrics because of its memorable lyrics and rhyme, while the other one
said that he liked both of them equally because they provide different kinds of
pronunciation teaching.
Extract 5:
P1: It could help in some particular words.
P4: I think it helps when I keep listening to one song and I will have better
pronunciation for the words that are in that song.
P6: It helps me sometimes but I can rarely apply it to a conversation in my
daily life.
Ref. code: 25605921042304OWQ
Page 38
28
6.1 What is better in pronouncing each single word, teacher or songs?
Teacher Songs
No. of participants 6 1
6.2 What is better learning motivation, teacher or songs?
Teacher Songs
No. of participants 5 2
According to the interview, many other factors such as level of English
proficiency, motivation, the familiarity with the songs and vocabulary words and the
atmosphere are also the key influences to learners’ success.
The English level proficiency has the most impact in the production of corrected
pronunciation. Once learners are proficient in the standard pronunciation and able to
accurately distinguish different kinds of pronunciation they will decrease pronunciation
errors and create intelligible pronunciation.
Not only the level of proficiency affects the number of errors, but motivational
interest is another relating factor that increases learners’ productivity in pronouncing
the target final sounds correctly. As Gardner (1993) emphasized, the more learners have
motivation, the more learners tend to enjoy the language learning and lessons; therefore,
the knowledge gained is greater.
Extract 6:
P3: I think that they are different, it depends on what are you going to focus
on in the lesson, the explicit teaching might be proper to get accuracy while
using songs is better for fluency.
P5: Songs have the complex lyrics and structures, and the ways songs
pronounce each word is inconsistent according to each song, so it is easier
to learn English explicitly with teacher.
P7: I like learning English by songs; I got a lot of vocabulary words from
listening to English songs.
Ref. code: 25605921042304OWQ
Page 39
29
The familiarity with song and lyrics also has an impact on the pronunciation.
As the song “A thousand years” was quite popular in recent years, some participants
had already known the song and the way some words are pronounced, thus they were
able to pronounce some words better that other participants.
Positive attitude has the key role in effective learning atmosphere. At the same
time, songs have the power and influence in creating a non-threatening atmosphere,
relieving not only physical but also mental conditions (Ghanbari, 2014).
Ref. code: 25605921042304OWQ
Page 40
30
CHAPTER V
CONCLUSIONS AND RECOMMENDATIONS
The study shows that pronunciation errors of final sounds that are made by the
participants have been distinguished into two main types: omission and substitution.
There are twenty-five problematic words in the song “A Thousand Years – Christina
Perri” where participants made pronunciation errors on final sounds; ending consonants
of /θ, t, d, z, v/ tended to create the most problematic pronunciation. The limitation of
final consonants, because Thai only has eight finals /n/, /m/, /ŋ/, /p/, /b/, /d/, /t/, /k/, /j/,
/w/, is one of the significant objects that caused errors to have been produced, and also,
the lack of Thai final consonant clusters blocked the ability to pronounce in English all
the target final consonants in the vocabulary words.
When it comes to the perception of pronunciation errors made by each
participant, the participants were able to identify some errors by themselves while they
were listening to the song twice. The findings indicate a tendency for a surprisingly low
rate of the errors that they are able to notice. Similarly, the production in the second
reading aloud did not produce satisfactory performance in the number of noticeable
improvements from the first reading.
As the results of this practical research and interview indicate, the use of songs
in this research was unable to improve participants’ errors, as well as their notice of
pronunciation errors. The factors that affect the inefficient outcome comprise level of
English proficiency, motivation, the familiarity with the songs and vocabulary words,
and the atmosphere when they are exposed to the song. However, songs are still an
effective tool to increase learners’ motivation and activate their willingness to learn
pronunciation rather than learning by traditional methods.
The results of the study, nevertheless, should be more advised and concerned
since there are many limitations. First, there is a need to be more specific in sounds and
vocabularies identification in order for Thai learners to evaluate as many final
pronunciation sounds as possible and the song “A Thousand Years” does not contain
all the target sounds that have been researched as final problematic sounds. Second, the
study only focused on problematic final consonant sounds; other parts such as vowels
Ref. code: 25605921042304OWQ
Page 41
31
and initial consonants were not emphasized. Moreover, there was no supra-segmental
unit investigation, such as looking at intonation, stress, rhythm etc. Other skills, e.g.
vocabulary and reading comprehension, might be affected by songs as well. Finally,
there should be more variety of the instruments utilized in error identification in order
to create research reliability and practical information; the usage of one song
individually is inadequate in pronunciation error identification. Further studies could
take more concern over the variables which were excluded in this research.
Ref. code: 25605921042304OWQ
Page 42
32
REFERENCES
Abu-Rabia, S., & Iliyan, S. (2011). Factors affecting accent acquisition: The case of
Russian immigrants in Israel. Retrieved August 2011, from
http://www.readingmatrix.com/articles/april_2011/aburabia_iliyan.pdf
AMEP Research Centre. (2002). Fact sheet-What is pronunciation? Retrieved from
http://www.nceltr.mq.edu.au/pdamep
Archibald, J. (1998). Second Language Phonology. Amsterdam: John Benjamins.
Bannan, N. (2012). Music, Language, and Human Evolution. Oxford: Oxford
University Press.
Bartle, G. (1962). Music in the language classroom. Canadian Modern Language
Review, Fall, 11-14.
Bason, S. H. (1988). Paterns of Pronunciation Errors in English by Native Japanese
and Hebrew Speakers: Interference and Simplification Process. Bloomington:
Indiana University Linguistics Club.
Burns, A. (2003). Clearly Speaking: Pronunciation in Action for Teachers. Macquarie
University.
Celce-Murcia, M., Brinton, D., Goodwin, J., & Grinner, B. (2010). Teaching
Pronunciation: A course and reference guide (Vol. 2nd edition ). New York:
Cambridge University Press.
Cenoz, J. (2003). The influence of age on the acquisition of English: general
proficiency, attitudes and code-mixing. In M. P. Mayo, & M. L. (eds.)..
Dalton, C., & Seidlhofer, B. (1994). Pronunciation. Oxford: Oxford University Press.
Dulay, H., Burt, M., & Krashen, S. (1982). Language Two. New York: Oxford
University Press.
Edwards, J. G., & Zampini, M. L. (2008). Introduction. In J. G. Edwards, & M. L.
Zampini, Phonology and second language acquisition (pp. 1-11). Amsterdam:
J. Benjamins Publishing.
Ellis, R. (1994). The study of second language acquisition. Oxford: Oxford University
Press.
Ref. code: 25605921042304OWQ
Page 43
33
Farmand, Z., & Pourgharib, B. (2013). The Effect of English Songs on English
Learners Pronunciation. International Journal of Basic Sciences & Applied
Research, 2(9), 840-846.
Flege, J. E., Munro, M. J., & MacKay, I. (1995). Effects of age of second- language
learning on the production of English consonants. Retrieved July 2011, from
http://dx.doi.org/10.1016/0167-6393(94)00044-B
Fonseca-Mora, M., Toscano-Fuentes, C., & Wermke, K. (2011). Melodies that help:
The relation between language aptitude and musical intelligence. Anglistik
International Journal of English Studie, 22(1), 101-118.
Gardner, H. (1993). Frames of mind: The theory of multiple intelligences. (Vol. 6th
edition). New York: NY: BasicBooks.
Ghanbari, F. (2014). The Effects of English Songs on Young Learners' Listening
Comprehension and Pronunciation. International Journal of Language
Learning and Applied Linguistics World (IJLLALW), 6(3), 337-345.
Jolly, Y. (1975). The Use of Songs in Teaching Foreign Languages. The Modern
Language Journal, 59(1,2), 11-14.
Khamkhien, A. (2010). Thai learners’ English pronunciation competence: Lesson
learned from word stress assignment. Retrieved March 2013, from doi:
10.4304/jltr.1.6.757-764
Krashen, S. (1992). Principles and practice in second language acquisition. Retrieved
October 2010, from
http://www.sdkrashen.com/Principles_and_Practice/Principles
_and_Practice.pdf
Lado, R. (1957). Linguistics across Cultures, Applied Linguistics for Language
Teachers. University of Michigan Press.
Lems, K. (2001). Using Music in the Adult ESL Classroom. Washington DC: National
Clearing House for ESL Literacy Edication. Retrieved from Eric Digest.
Lin, H.-P., Fan, C.-Y., & Chen, C.-F. (1995). Teaching Pronunciation in the Learner-
Centered Classroom. The TEFL Conference 12th (p. 15p). Taichung: ERIC.
Lo, R., & Li, H. C. (1998). Songs enhance learner involvement. English Teaching
Forum, 36, 8-11.
Ref. code: 25605921042304OWQ
Page 44
34
Major, R. C. (2008). Transfer in second language phonology. In J. G. Edwards, & M.
L. Zampini (eds.), Phonology and second language acquisition (pp. 63-84).
Amsterdam: J. Benjamins Publishing.
Mano-im, R. (1999). The pronunciation of English final consonant clusters by Thais.
Bangkok: M.A. Thesis, Chulalongkorn University.
McKenzie-Brown, P. (2006). Language matters: A study in Thai. Retrieved
November 2007, from http://languageinstinct.blogspot.com/
Munoz, C. (2007). Studying Abroad as Foreign Language Practice. In R. Dekeyser
(ed.), Practice in a Second Language: Perspectives from Applied Linguistics
and Cognitive Psychology (pp. 208-226). Cambridge: Cambridge University
Press.
Murphy, J. (2003). Pronunciation. In D. N. (ed.), Practical English language
teaching. New York: McGraw Hill.
Murphy, T. (1992). Music and Song. Oxford: Oxford University Press.
Nakin, P., & Inpin, B. (2017). English Consonant Pronunciation Problems of EFL
Students : A Survey of EFL Students at Mae Fah Luang University. The 6th
Burapha University International Conference.
Oller, J. W., & Ziahosseiny, S. (1970). The contrastive analysis hypothesis and
spelling errors. Language Learning, 20, 183-189.
Panseetong, K. (1996). A development of practice packages on the vowels and
consonants in English word pronunciation skill for prathom suksa six
students. Unpublished master’s thesis. Chulalongkorn University, Graduated
School, Department of Elementary Education.
Phinuyothin, P. (2011). The use of English songs to improve the pronunciation of
problematic English consonant sounds for Thai learners. Bangkok:
Chulalonkorn University Thesis.
Pimwan, K. (2012). The effect of teaching English pronunciation through songs of
Prathomsuksa 4 students at Watratchaphatigaram school. Bangkok:
Srinakharinwirot University Thesis.
Piske, T., MacKay, I., & Flege, J. E. (2001). Factors affecting degree of foreign
accent in an L2: A review. Retrieved February 2011, from
http://www.clas.ufl.edu/users/jharns/Piske_MacKay_Flege_2001.pdf
Ref. code: 25605921042304OWQ
Page 45
35
Richard, J. (1969). Songs in Language Learning. TESOL Quarterly, 3(2), 161-174.
Saville-Troike, M. (2006). Introducing second language acquisition. Cambridge:
Cambridge University Press.
Schön, D. B. (2008). Songs as an aid for language acquisition. Cognition, 106(2),
975-983.
Swan, M., & Smith, B. (2001). Learner English (Vol. second edition). Cambridge:
Cambridge University Press.
The Royal Institute. (2010). Lexical in Linguistics Dictionary (Applied Linguistics).
Bangkok: The Royal Institute.
Troike, M. S. (2006). Introducing Second Language Acquisition. Cambridge:
Cambridge University Press.
Wallace, W. (1986). Memory for music: Effect of melody on recall of text. Learning,
Memory, and Cognition, 20(6), 1471-1485.
Wardhaugh, R. (1983). ), Second language learning: Contrastive analysis, error
analysis, and related aspects. In B. W. Robinett, & J. Schachter. (eds), The
contrastive analysis hypothesis (pp. 7-19). Ann Arbor: The University of
Michigan Press.
Wei, Y., & Zhou, Y. (2002). Insights into English pronunciation problems of Thai
students. Paper presented at the eighth annual meeting of the Quadruple
Helix, 12p.
York, J. (2011). Music and MEXT: How songs can help primary school. English
teachers teach and their students learn. The Language Teacher, 6(3), 250-261.
Ref. code: 25605921042304OWQ
Page 46
36
APPENDICES
Ref. code: 25605921042304OWQ
Page 47
37
APPENDIX A
SONG LYRICS
A Thousand Years – Christina Perri
Heart beats fast
Colors and promises
How to be brave
How can I love when I'm afraid to fall
But watching you stand alone
All of my doubt, suddenly goes away somehow
One step closer
I have died everyday, waiting for you
Darling, don't be afraid, I have loved you for a thousand years
I'll love you for a thousand more
Time stands still
Beauty in all she is
I will be brave
I will not let anything, take away
What's standing in front of me
Every breath, every hour has come to this
One step closer
I have died everyday, waiting for you
Darling, don't be afraid, I have loved you for a thousand years
I'll love you for a thousand more
And all along I believed, I would find you
Time has brought your heart to me,
I have loved you for a thousand years
I'll love you for a thousand more
One step closer
One step closer
Ref. code: 25605921042304OWQ
Page 48
38
I have died everyday, waiting for you
Darling, don't be afraid, I have loved you for a thousand years
I'll love you for a thousand more
And all along I believed, I would find you
Time has brought your heart to me, I have loved you for a thousand years
I'll love you for a thousand more
Ref. code: 25605921042304OWQ
Page 49
39
APPENDIX B
SEMI-STRUCTURED INTERVIEW QUESTIONS
Part I: Demographic
Part II: The Attitude towards Pronunciation Errors and The Use of Songs in
Language Classroom
Demographic
1. How old are you?
2. Have you ever taken English courses outside classroom?
3. How would you rate your level of English proficiency?
Information about Participants’ Pronunciation Errors and The Use of Songs
4. Do you like listening to English songs?
5.1 How often?
5. Do you notice that you have made pronunciation error after listening to the
song?
5.1 What words do you make errors on?
6. Do you know how th, -ed, -es, and v are pronounced? How?
7. Is it possible for a person who has never known how to pronounce pronounces
it correctly?
8. Does listening to music help you pronounce words correctly?
9. Do you prefer teaching pronunciation explicitly by teacher/native speaker or
teaching through songs? Why?
9.1 What is better in pronouncing each single word? Teacher or songs?
9.2 What is better learning motivation? Teacher or songs?
Ref. code: 25605921042304OWQ
Page 50
40
APPENDIX C
PRONUNCIATION ERRORS BEFORE LISTENING TO THE
SONG “A THOUSAND YEARS” MADE BY EACH PARTICIPANT
Participant 1
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. heart /rt/ omission of /r/
2. beats /ts/ omission of /t/
3. fast /st/ omission of /t/
4. promises /z/ substitution with /s/
5. brave /v/ substitution with /p/
6. love /v/ substitution with /v/
7. fall /l/ omission of /l/
8. stand /nd/ omission of /d/
9. goes /z/ substitution with /s/
10. doubt /t/ omission of /t/
11. afraid /d/ substitution with /t/
12. died /d/ omission of /d/
13. loved /vd/ substitution /v/ with /p/,
omission of /d/
14. years /z/ omission of /z/
15. front /nt/ omission of /t/
16. breath / θ/ substitution with /t/
17. believed /vd/ substitution /v/ with /p/,
omission of /d/
18. find /nd/ omission of both /n/ and
/d/
Ref. code: 25605921042304OWQ
Page 51
41
Participant 2
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. heart /rt/ omission of /r/
2. beats /ts/ omission of /t/
3. fast /st/ omission of /t/
4. promises /z/ substitution with /s/
5. love /v/ substitution with /p/
6. afraid /d/ substitution with /s/
7. fall /l/ omission of /l/
8. stand /nd/ omission of /d/
9. all /l/ omission of /l/
10. doubt /t/ omission of /t/
11. goes /z/ substitution with /s/
12. died /d/ omission of /d/
13. loved /vd/ substitution /v/ with /p/,
omission of /d/
14. I’ll /l/ omission of /l/
15. front /nt/ omission of /t/
16. breath /θ/ substitution with /d/
17. believed /vd/ substitution /v/ with /p/,
omission of /d/
18. find /nd/ omission of both /n/ and
/d/
Ref. code: 25605921042304OWQ
Page 52
42
Participant 3
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. heart /rt/ omission of /r/
2. promises /z/ substitution with /s/
3. afraid /d/ substitution with /s/
4. fall /l/ omission of /l/
5. stand /nd/ omission of /d/
6. all /l/ omission of /l/
7. goes /z/ substitution with /s/
8. died /d/ omission of /t/
9. loved /vd/ substitution /v/ with /p/,
omission of /d/
10. I’ll /l/ omission of /l/
11. front /nt/ omission of /t/
12. breath /θ/ substitution with /d/
13. believed /vd/ substitution /v/ with /p/,
/d/ with /t/
14. find /nd/ omission of both /n/ and
/d/
Participant 4
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. heart /rt/ omission of /r/
2. beats /ts/ substitution /t/ with /d/
3. Promises /z/ substitution with /s/
Ref. code: 25605921042304OWQ
Page 53
43
4. Fall /l/ omission of /l/
5. stand /nd/ omission of /d/
6. doubt /t/ omission of /t/
7. goes /z/ substitution with /s/
8. died /d/ omission of /d/
9. afraid /d/ substitution with /t/
10. loved /vd/ substitution /v/ with /p/,
omission of /d/
11. all /l/ omission of /l/
12. front /nt/ omission of /t/
13. breath /θ/ substitution with /t/
14. find /nd/ omission of both /n/ and
/d/
Participant 5
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. Promises /z/ substitution with /s/
2. fall /l/ omission of /l/
3. loved /d/ substitution with /t/
4. all /l/ omission of /l/
5. breath /θ/ substitution with /t/
6. believed /d/ substitution with /t/
Ref. code: 25605921042304OWQ
Page 54
44
Participant 6
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. heart /rt/ omission of /r/
2. beats /ts/ omission of /t/ and /s/
and substitution with /p/
3. fast /st/ omission of /t/
4. promises /z/ omission of /z/
5. love /v/ substitution with /p/
6. afraid /d/ substitution with /s/
7. fall /l/ omission of /l/
8. doubt /t/ omission of /t/
9. goes /z/ omission of /s/
10. died /d/ omission of /d/
11. don’t /t/ omission of /t/
12. afraid /d/ substitution with /t/
13. loved /vd/ substitution /v/ with /p/,
omission of /d/
14. years /z/ omission of /z/
15. I’ll /l/ omission of /l/
16. let /t/ substitution with /s/
17. front /nt/ omission of /t/
18. breath /θ/ substitution with /d/
19. believed /vd/ substitution /v/ with /p/,
omission of /d/
20. find /nd/ omission of both /n/ and
/d/
Ref. code: 25605921042304OWQ
Page 55
45
Participant 7
No.
Words Pronounced
Wrongly in 1st Reading
Aloud
Correct Final
Consonant Sounds
Incorrect Final
Consonant Sounds
1. love /v/ omission of /v/
2. afraid /d/ substitution with /t/ or
/s/
3. stand /nd/ omission of /d/
4. doubt /t/ omission of /t/
5. goes /z/ substitution with /s/
6. died /d/ omission of /d/
7. loved /d/ omission of /d/
8. I’ll /l/ omission of /l/
9. breath /θ/ substitution with /d/
10. heart /t/ substitution with /d/
11. find /nd/ omission of both /n/ and
/d/
Ref. code: 25605921042304OWQ
Page 56
46
APPENDIX D
THE COMPARISON OF WORDS PRONOUNCED WRONGLY IN
READING ALOUD BETWEEN THE 1ST AND 2ND PRODUCTION
AND THE PARTICIPANT’S PERCEPTION.
Participant 1
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
heart - heart
beats - beats
fast - fast
promises promises -
brave brave brave
love - love
fall - fall
stand - stand
goes goes goes
doubt - doubt
afraid - -
died - died
loved - loved
- thousand -
years - years
front - front
breath breath breath
believed - believed
find - find
Ref. code: 25605921042304OWQ
Page 57
47
Participant 2
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
heart - heart
beats - beats
fast - fast
promises promises promises
- brave -
love - -
fall - fall
stand - stand
all - all
doubt doubt doubt
goes - goes
died - died
loved loved loved
I’ll I’ll I’ll
- take -
front - front
breath breath breath
believed believed believed
find - find
- brought -
Ref. code: 25605921042304OWQ
Page 58
48
Participant 3
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
heart heart heart
promises - promises
- brave -
afraid - afraid
fall - fall
stand - stand
all - -
goes - goes
died died died
loved - loved
I’ll - I’ll
front - front
breath breath breath
believed believed believed
- brought -
find - find
Participant 4
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
heart heart heart
beats - beats
Ref. code: 25605921042304OWQ
Page 59
49
promises - promises
- brave -
fall - fall
stand - -
doubt doubt doubt
goes goes goes
died - -
- don't -
afraid - -
loved loved loved
all - all
front front front
breath - breath
find - find
Participant 5
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
promises promises promises
fall - -
loved - Loved
all - All
breath - Breath
believed - believed
Ref. code: 25605921042304OWQ
Page 60
50
Participant 6
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
heart - -
beats beats beats
fast - fast
promises promises promises
love - love
afraid - -
fall - fall
doubt doubt doubt
goes - goes
died - died
don’t - -
afraid - afraid
loved loved loved
years - years
I’ll I’ll I’ll
let - let
Front - front
breath breath breath
believed - believed
find - find
- brought -
Ref. code: 25605921042304OWQ
Page 61
51
Participant 7
Words Pronounced
Wrongly in Reading
Aloud before Listening
(1st Production)
Words Pronounced
Wrongly in Reading
Aloud while Listening
(Perception)
Words Pronounced
Wrongly in Reading
Aloud after Listening
(2nd Production)
love - -
afraid - afraid
stand - stand
doubt - doubt
goes goes goes
died - -
loved loved loved
I’ll I’ll I’ll
breath - breath
- believed -
brought brought -
heart - heart
find - find
Ref. code: 25605921042304OWQ
Page 62
52
APPENDIX E
THE WORD IN LISTS IN “A THOUSAND YEARS” SONG
1. afraid 21. day 41. in 61. take
2. all 22. died 42. is 62. this
3. alone 23. don't 43. let 63. thousand
4. along 24. doubt 44. love 64. time
5. and 25. every 45. loved 65. to
6. anything 26. everyday 46. me 66. waiting
7. away 27. fall 47. more 67. watching
8. be 28. fast 48. my 68. what's
9. beats 29. find 49. not 69. when
10. beauty 30. for 50. of 70. will
11. believed 31. front 51. one 71. would
12. brave 32. goes 52. promises 72. years
13. breath 33. has 53. she 73. you
14. brought 34. have 54. somehow 74. your
15. but 35. heart 55. stand
16. can 36. hour 56. standing
17. closer 37. how 57. stands
18. colors 38. i 58. step
19. come 39. i'll 59. still
20. darling 40. i'm 60. suddenly
Ref. code: 25605921042304OWQ
Page 63
53
BIOGRAPHY
Name Miss Pattaraporn Muangphruek
Date of Birth
Place of Birth
Address
March 7, 1994
Surat Thani, Thailand
618/739 Boromrajchachonnanee Road, Bang
Bamru, Bang Plat, Bangkok
Educational Attainment
Work Experiences
2012– 2015 Bachelor of Arts (Business English),
Faculty of Humanities and Social Sciences,
Khon Kaen University
Freelance Proofreading and Copy-Editing
Ref. code: 25605921042304OWQ