77
Applied Simulations, Inc. F2GPU: A General Fortran to GPU-Code Translator Rainald Löhner Applied Simulations, Inc. McLean, VA, USA www.appliedsimulations.com

Applied Simulations, Inc.
F2GPU: A General Fortran to GPU-Code Translator
Rainald Löhner
Applied Simulations, Inc.
McLean, VA, USA
www.appliedsimulations.com

Applied Simulations, Inc.
Outline
� General Observations
� GPUs
� F2GPU
� Translating Codes
� Examples and Timings
� Conclusions and Outlook

Applied Simulations, Inc.
General Observations

Applied Simulations, Inc.
Observations (1)� Capability More Important Than Speed
� Obvious, But Very Often Overlooked
� True to a Point (e.g. Hierarchical Design Setting)
� Engineering Codes Have Many Options� Important Differentiator
� Man-Years of Coding/Testing/Comparison to Experiments
� Mostly Scalar
� Geometrical Flexibility Crucial� All Commercial CFD Codes Use Unstructured Grids/Data Structures
� Over-Simplification Can Be Very Costly� Better Wait a Few Days for a Good Result Than an Hour for …
� Industry and Government Have Learned This Time and Again …

Applied Simulations, Inc.
Observations (2)� Problem Size Correlates With Physics
� Airplane Aerodynamics: Nr. of Gridpoints
Potential: 106, Euler: 108, RANS: 109, LES: 1010-1014, DNS: 1016
� Car Crash: Beam: 104, Shells: 106, Solids: 108
� Physical Complexity Increases Potential Load Imbalances� CFD: Chemical Reactions, Particles and Fluids, H-Ref, Remesh
� CSD: Contact, Rupture
� Multiphysics: Different Parallelization/Spatial Subdivisions
� Zalesak’s Uncertainty Principle Holds� Compute Speed * Results < Z
� Who Gets More Than 512 Procs 24/7/365 ?� Very Few, If Any, Even in 2012
� Many More in the Future (Perhaps: Energy Costs…)

Applied Simulations, Inc.
Characteristics of Successful Codes
� Do Not Solve `The World’; Just One Class of Problems� Commit to a Problem; Not to an Algorithm/Technique/…
� Physics: Complete� CFD: Turbulence, Cavitation, Moldfilling, Casting, Extrusion,
Food Processing, Biofluids, Non-Newtonian, …� CSD: Springback, Failure, Cracking, Rupture, Tearing, …
� Numerics: Basic� Just Enough (Hourglass, Upwinding, Stabilization, …)
� Benchmarks, QA� Link to Experiments� Long-Term Commitment� Documentation, Manuals, Training, …
� Institutional Memory (Long-Term Commitment)

Applied Simulations, Inc.
Codes: Going Forward
� Many Codes Written in F77/F90� I Can Hear the Sighs of Disbelief…
� If: Cost is in `Physics’/ Debugging/ Benchmarking
� If: Differentiation is in Options
� If: Codes Are Large (O(1-10 Mlines) Usual)
� � Codes Will Not Be Re-Written� Unless Factors of 1:100 Are Possible
� � Need An Automatic Way of Porting F77/F90 to GPUs

Applied Simulations, Inc.
GPUs

Applied Simulations, Inc.
GPUs: Caveats
� Transfer is Expensive� Do as Much as Possible on GPU
� GPU Works Well on: � Large Amounts of Data [But: Memory Limited]
� Simple Operations / Reuse of Registers [But: Registers Limited]
� � Very Similar to (Autotasking) Vector Machines
� GPU-Based Field Solvers Appearing in Literature

Applied Simulations, Inc.
GPUs: Porting Options (1)
� Option 1: Re-Write By Hand� Expensive (Millions of Lines of [Fortran] Code)
� Error Prone
� Multiple Versions of Same (?) Code
� Will Certainly Work
� Option 2: Compilers � Will Require Re-Vectorization of Large Parts of Codes
� MPI-Decade Spoiled Code-Writers
� Vector-Compilers: Could Only Go So Far
� Insertion of Directives Does Not Account for Placement of Arrays� Main Bottleneck of GPUs Not Addressed !

Applied Simulations, Inc.
GPUs: Porting Options (2)
� Option 3: Translators/Scripts� Needs Inner Fine-Grained Parallel (Vectorized) Loops
� Needs Uniform Code/Loop Structure
� Lowest Number of Possible Errors (All/Nothing)
� Placement/Transfer Issue of Data (CPU/GPU) Addressed
� Single Code Version
� Can Keep Developing/Debugging on CPU
� Attempted by Several Groups Worldwide

Applied Simulations, Inc.
F2GPU

Applied Simulations, Inc.
F2GPU: Design Criteria
� Exploit Existing Fine-Grain Parallelism
� Take Every OMP Loop:� Identify Arrays and Define as `On GPU’
� Perform Inner Vector Loops on GPU
� Allow for User-Defined $gpu - Directives� Some (Small, Diagnostics) Arrays Should Stay on CPU
� Transfer To/From CPU/GPU Only What is Required
� Allow for User-Defined Ignore-Option� Difficult Subs Omitted by Translator
� Allows for Gradual Porting

Applied Simulations, Inc.
Avoid CPU / GPU Data Transfer (1)
� GPU/CPU: Separate Memory Spaces
� Transfer GPU/CPU: Extremely Slow� Bus Bandwidth < 10GB/s
� Internal CPU Bandwidth ~20-60 GB/s
� Internal GPU Bandwidth ~100-200 GB/s
� � Just Porting “Bottleneck Subroutines”�Replace One Bottleneck With Another (!)
� � All (!) Parallel Loops Must Run on GPU
� � Limit Data Transfer to Code Init/Shutdown

Applied Simulations, Inc.
Avoid CPU / GPU Data Transfer (2)
� F2GPU: Analyze Array Placement
� Warn User of Placement

Applied Simulations, Inc.
F2GPU (1)
� Generate GPU Code From Existing Fortran Code
� Original Code Must Expose Fine-Grain Parallelism� Assume Every OpenMP Loop as on GPU
� Allow for !$gpu parallel Directive for SubLoops/Conflicts
� Explicit Separation of Memory Spaces
� O(103) Lines of Python Script
� Uses FParser Package From F2PY Project (Open Source)
� Not Specialized for Any Particular Code� But Full-Performance, Automatic `GPU Compiler’ Unlikely

Applied Simulations, Inc.
F2GPU (2)
� Single F77/F90 + OpenMP Codebase
� No New Bugs
� Catches Old Bugs� Uninitialized Variables
� Nonsensical OpenMP Directives
� …
� No Performance Hit Due to Translation� Same Code As Produced By Experienced GPU Coder
� Not Specialized for Any Particular Code� But Not a Generic, Automatic Compiler

Applied Simulations, Inc.
F2GPU: Fine-Grain Parallelism
� Explicitly Defined via OpenMP in F77/F90� Simple Translation
� User-Defined Parallel Inner Loop via Directives� !$gpu parallel do
� Difficult Subs:� Array Compression: rcmpresp, icmpresp
� Prefix Sum: iadlinklistv
� Random Number Generation: rgaussrndv, rgrndv
� Custom Code Via Thrust Library

Applied Simulations, Inc.
F2GPU: Output Options
� Multiple Output Targets
� Fortran Code Analyzed/Represented Abstractly Using Objects
� Different Object Methods Can Output to Different Targets
� CUDA Target: Fully Supported
� OpenCL and CUDA Fortran: Incomplete
� Other Targets: Possible in Future

Applied Simulations, Inc.
F2GPU: MPI
� GPU Translator Fully Integrates with Existing MPI Parallelism
� CUDA/MPI: Orthogonal
� Each MPI Rank Processes a Sub-Domain� Coarse-Grain
� CUDA Threads in Sub-Domain (edges/points/elements)� Fine-Grain

Applied Simulations, Inc.
Translating Codes With F2GPU

Applied Simulations, Inc.
Translating Code With F2GPU (1)
� Start With Original Code: code.f, Makefile, …
� mkdir code_gpu
� From Makefile:� Get List of *.f/*.f90 Files
� Prepare `F2GPU Makefile’: Makef2gpu
� Until Translated (in code_gpu directory):� make convert
� � *.f90.cu Files
� Once Translated (in code_gpu directory):� make
� � Executable

Applied Simulations, Inc.
Translating Code With F2GPU (2)
� Errors Detected� Incorrect Number of Arguments in Calls
� Incorrect Arguments Type in Calls
� Incorrect OpenMP Arguments (local)
� Problems Detected� GPU Arrays Accessed in Scalar/CPU Loop
� CPU Arrays Accessed in Vector/GPU Loop
� � Force User to Place !$gpu gpu2cpu / cpu2gpu Directive

Applied Simulations, Inc.
Running Codes With F2GPU

Applied Simulations, Inc.
Running Code With F2GPU (1)
� Debug/Production Options
� Debug Option� Alert User to CPU to GPU and GPU to CPU Transfer
� Essential to Obtain GPU Performance

Applied Simulations, Inc.
FEFLO On GPUs

Applied Simulations, Inc.
FEFLO: Examples…

Applied Simulations, Inc.
FEFLO (1)� Physics
� Compressible and Incompressible Flow� Many EOS� Turbulence Models� Chemical Reactions� Dilute Particle Phases� Adjoints
� Numerics� 1-Element Type Code� Edge-Based Solvers (Upwind, Riemann, Limiters, …)� Explicit and Implicit Timestepping� Iterative Solvers (DPCG/GMRES, LU-SGS, Deflated, Linelets, ..)� Optimized for Vector, SMP and DMP (Domain Decomposer)

Applied Simulations, Inc.
FEFLO (2)� Engineering
� Periodic BC� Embedded/Immersed Bodies� Overlapping Grids� Body/Surface/Mesh Motion Modules� Link to CSD/CTD/Control/… Codes� Link to Optimization Packages
� Statistics (05/2012) for Physics Modules� O(1.20) Mlines of F77 Code� O(6.70) KSubs� O(650) Egde-Loops With Sub-Subroutine Calls
� Typical `Legacy Code’

Applied Simulations, Inc.
FEFLO (3)� Coding:
� Well-Organized, Consistent (Same Names, Same Loops, …)
� Uses Simple, Explicit Subset of F77/F90
� Parallelized (OMP, MPI) + Vectorized

Applied Simulations, Inc.
FEFLO: ON GPUs
� 12/2012: O(3.8KSubs Ported) [Running Entirely on GPU]
� Comp: locfct.f, rukucomp.f, lusgscomp.f (Ideal Gas)
� Inco: incosubs.f, vectruku.f, vectlusgs.f, projecsubs.f
� Scalars: scalfct.f, scalruku.f, scallusgs.f, vofsubs.f
� Preconditioners: linelets.f
� Lagrangian Particles: lagparts.f
� Moving Body Options: alemesh.f, alebody.f
� Turbulence Models: smago, wale, kepsilon, …
� Radiation Transport
� Adjoints, …

Applied Simulations, Inc.
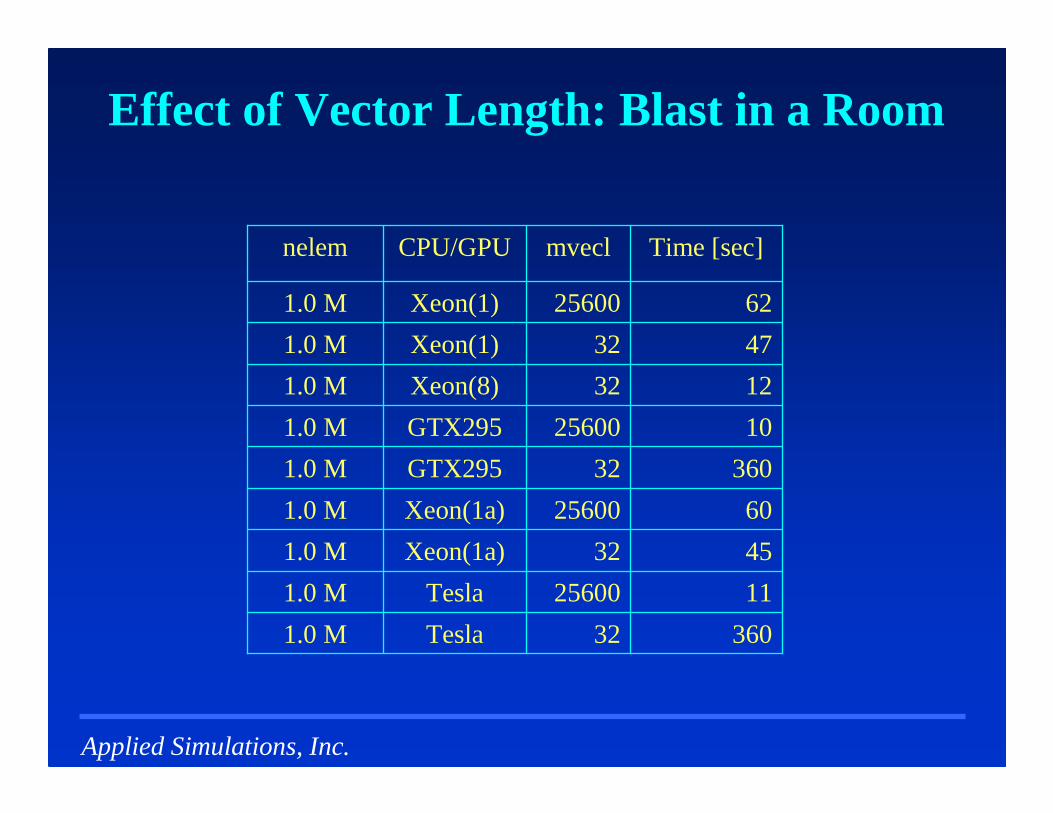
Effect of Vector Length: Blast in a Room
� Compressible Euler� Ideal Gas Equation of State
� Flux-Corrected Transport
� 1 Mels
� 60 Time Steps� Double Precision
Applied Simulations, Inc.
Effect of Vector Length: Blast in a Room
4732Xeon(1)1.0 M
6225600Xeon(1)1.0 M
1232Xeon(8)1.0 M
1025600GTX2951.0 M
36032GTX2951.0 M
Time [sec]mveclCPU/GPUnelem
6025600Xeon(1a)1.0 M
4532Xeon(1a)1.0 M
36032Tesla1.0 M
1125600Tesla1.0 M

Applied Simulations, Inc.
Effect of Vector Length: Blast in a Room
4732Xeon(1)1.0 M
6225600Xeon(1)1.0 M
1232Xeon(8)1.0 M
1025600GTX2951.0 M
36032GTX2951.0 M
Time [sec]mveclCPU/GPUnelem
6025600Xeon(1a)1.0 M
4532Xeon(1a)1.0 M
36032Tesla1.0 M
1125600Tesla1.0 M

Applied Simulations, Inc.
Effect of Renumbering: Blast In Cube
� Compressible Euler
� Ideal Gas EOS
� Explicit FEM-FCT
� Initialization From 1-D File
� 1.0 Mels
� Run for 500 Steps
� Cartesian Point Distribution � Test Renumbering Options

Applied Simulations, Inc.
Blast In Cube

Applied Simulations, Inc.
Blast in a Cube
2.23
2.23
2.40
2.71
2.71
-
fact_1
2.30
5.24
6.25
8.36
8.36
-
fact_2
39
43
42
46
45
280
Time [sec]
6.2242572BINGTX295
1.0032BINXeon (1)
6.0942572ADVGTX295
6.6742572GPU1GTX295
6.5129800GPUDGTX295
Speedupmveclnrenunelem
7.1842572BINDGTX295

Applied Simulations, Inc.
Blast in a Room
� Compressible Euler� Ideal Gas Equation of State
� Flux-Corrected Transport
� 4 Mels
� 300 Time Steps� Double Precision
304884151Tesla M2050
Number of Domains
191
315
1
102
136
2
15
59
68
4CPU/GPU
8
Xeon X5670 (6) 36
Xeon X5670 (12) 33
Tesla M2050 2Mels 11

Applied Simulations, Inc.
Blast in a Room
� Compressible Euler� Ideal Gas Equation of State
� Flux-Corrected Transport
� 4 Mels
� 300 Time Steps� Double Precision
304884151Tesla M2050
Number of Domains
191
315
1
102
136
2
15
59
68
4CPU/GPU
8
Xeon X5670 (6) 36
Xeon X5670 (12) 33
Tesla M2050 2Mels 11

Applied Simulations, Inc.
Maximal Throughput
� Data Transfer Per Edge-Loop:
� ndata = nedge·nrealed = 7·nrealed·npoin [real*8, i.e. 64bits]
� � = 56·nrealed·bytes/pt
� Assume 150 Gbytes/sec, i.e. 0.67·10-11 sec/byte
� � Time Per Point Per Edge-Loop
� tppdata= 56·nrealed bytes/pt ·0.67·10-11 sec/byte
� tppdata= 38·nrealed·10-11 sec/pt

Applied Simulations, Inc.
Maximal Throughput: FEM -FCT
� For: tppdata= 38 ·nrealed·10-11 sec/pt :
� � FEMFCT: 0.950 ·10-7 sec/pt/step
� Measured: 6.920 ·10-7 sec/pt/step
5121unknoGetDt
222
30
30
30
60
30
30
nreal_ia
31unkno, rhsLow-Ord
51unkno, rhsLapLoe AV
1
1
2
1
# Calls
28Total
2rhsFinal du
2unkno, fluxlimiting
6unkno, rhsConsMass
5unkno, rhsTayGal
nreal_daTransferSub

Applied Simulations, Inc.
Blast in a Room
� Compressible Euler� Ideal Gas Equation of State
� Flux-Corrected Transport
� 4 Mels
� 300 Time Steps� Double Precision
304884151Tesla M2050
Number of Domains
191
315
1
102
136
2
15
59
68
4CPU/GPU
8
Xeon X5670 (6) 36
Xeon X5670 (12) 33
Tesla M2050 2Mels 11
= 6.92 ·10-7 sec/pt/step
Applied Simulations, Inc.
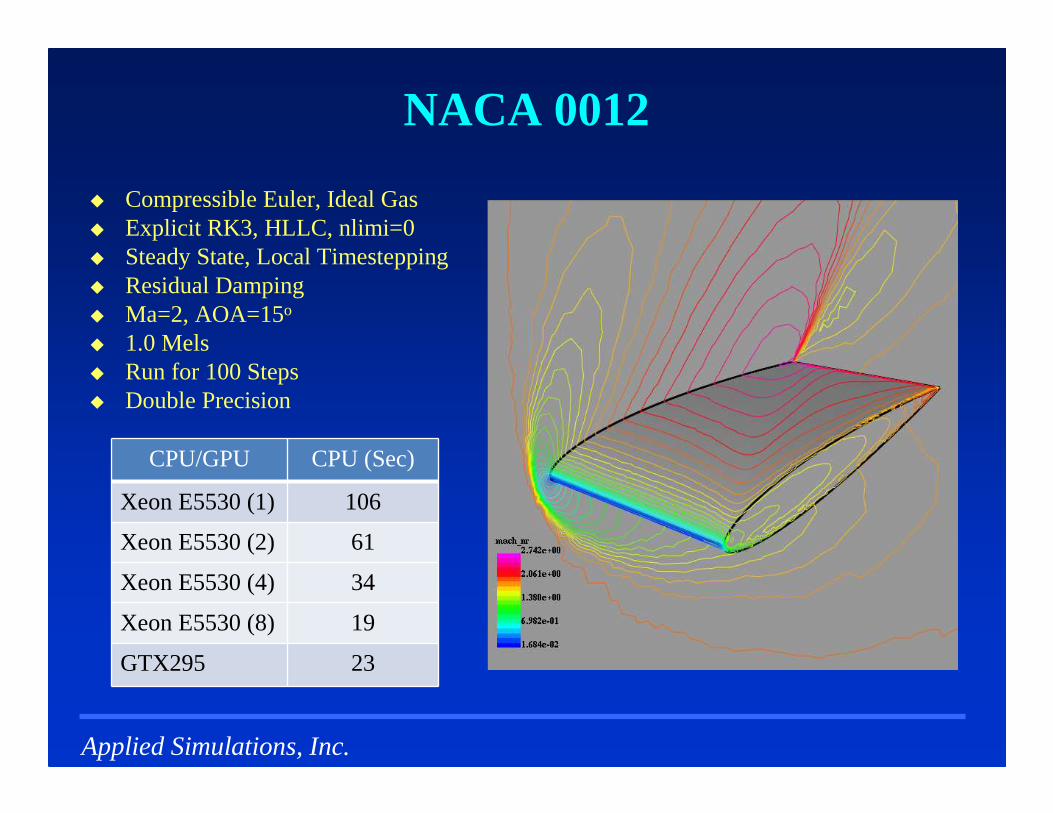
NACA 0012
� Compressible Euler, Ideal Gas� Explicit RK3, HLLC, nlimi=0� Steady State, Local Timestepping� Residual Damping � Ma=2, AOA=15o
� 1.0 Mels� Run for 100 Steps� Double Precision
34Xeon E5530 (4)
61Xeon E5530 (2)
19Xeon E5530 (8)
23GTX295
CPU (Sec)
106
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
NACA 0012� Compressible Euler, Ideal Gas� Explicit RK3, HLLC, nlimi=0� Steady State, Local Timestepping� Residual Damping � Ma=2, AOA=15o
� 1.0 Mels� Run for 100 Steps� Double Precision
34Xeon E5530 (4)
61Xeon E5530 (2)
19Xeon E5530 (8)
23GTX295
CPU (Sec)
106
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
OneraM6� Compressible Euler, Steady State � Ideal Gas EOS � Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping� Ma=0.84, AOA=3.06o
� 0.955 Mels� 50 Time Steps� Double Precision
43Xeon E5530 (4)
76Xeon E5530 (2)
32Xeon E5530 (6)
36Tesla C2070
CPU (Sec)
142
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
OneraM6� Compressible Euler, Steady State � Ideal Gas EOS � Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping� Ma=0.84, AOA=3.06o
� 0.955 Mels� 50 Time Steps� Double Precision
43Xeon E5530 (4)
76Xeon E5530 (2)
32Xeon E5530 (6)
36Tesla C2070
CPU (Sec)
142
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Turbine Blade� Compressible Euler, Steady State � Ideal Gas EOS� Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping, Periodic BC� Ma=0.84, AOA=3.06o
� 1.442 Mels� 100 Time Steps� Double Precision
107Xeon E5530 (4)
204Xeon E5530 (2)
78Xeon E5530 (6)
80Tesla C2070
CPU (Sec)
394
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Turbine Blade� Compressible Euler, Steady State � Ideal Gas EOS� Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping, Periodic BC� Ma=0.84, AOA=3.06o
� 1.442 Mels� 100 Time Steps� Double Precision
107Xeon E5530 (4)
204Xeon E5530 (2)
78Xeon E5530 (6)
80Tesla C2070
CPU (Sec)
394
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Supersonic Inlet� CompressibleEuler, Steady State � Ideal Gas EOS � Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping� Ma=3.00� 2.08 Mels� 50 Time Steps� Double Precision
70Xeon E5530 (4)
129Xeon E5530 (2)
51Xeon E5530 (6)
42Tesla C2070
CPU (Sec)
252
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Supersonic Inlet� CompressibleEuler, Steady State � Ideal Gas EOS � Implicit LU-SGS , HLLC, nlimi=2� Local Timestepping� Ma=3.00� 2.08 Mels� 50 Time Steps� Double Precision
70Xeon E5530 (4)
129Xeon E5530 (2)
51Xeon E5530 (6)
42Tesla C2070
CPU (Sec)
252
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
NACA 0012� Incompressible Euler� Advection: Explicit RK3, Roe,
nlimi=2� Pressure: Poisson (Projection),
DPCG [Scalar Products] � Steady State, Local Timestepping� AOA=15o
� 0.6 Mels� Run for 100 Steps� Double Precision
24Xeon E5530 (4)
40Xeon E5530 (2)
15Xeon E5530 (8)
31GTX295
CPU (Sec)
80
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
NACA 0012� Incompressible Euler� Advection: Explicit RK3, Roe,
nlimi=2� Pressure: Poisson (Projection),
DPCG [Scalar Products] � Steady State, Local Timestepping� AOA=15o
� 0.6 Mels� Run for 100 Steps� Double Precision
24Xeon E5530 (4)
40Xeon E5530 (2)
15Xeon E5530 (8)
31GTX295
CPU (Sec)
80
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Pipe
� Steady-State Incompressible Navier-Stokes + Heat Transfer
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 4.0 Mels� 100 Time Steps� Double Precision
183371456Tesla M2050
Number of Domains
662
1105
1
336
684
2
152
212
4CPU/GPU
8
Xeon X5670 (6) 112
Xeon X5670 (12) 75

Applied Simulations, Inc.
Pipe
� Steady-State Incompressible Navier-Stokes + Heat Transfer
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 4.0 Mels� 100 Time Steps� Double Precision
183371456Tesla M2050
Number of Domains
662
1105
1
336
684
2
152
212
4CPU/GPU
8
Xeon X5670 (6) 112
Xeon X5670 (12) 75

Applied Simulations, Inc.
Dispersion in City
� Transient Incompressible Navier-Stokes + Scalar Transport
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 4.0 Mels� 100 Time Steps� Double Precision
442Xeon E5530 (4)
-Xeon E5530 (2)
336Xeon E5530 (6)
356Tesla C2070
CPU (Sec)
-
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dispersion in City
� Transient Incompressible Navier-Stokes + Scalar Transport
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 4.0 Mels� 100 Time Steps� Double Precision
442Xeon E5530 (4)
-Xeon E5530 (2)
336Xeon E5530 (6)
356Tesla C2070
CPU (Sec)
-
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dispersion in Metro Station
� Transient Incompressible Navier-Stokes + Scalar Transport
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products) [800 Iter]� 3.95 Mels� 10 Time Steps� Double Precision
108Xeon E5530 (4)
191Xeon E5530 (2)
96Xeon E5530 (6)
115Tesla C2070
CPU (Sec)
375
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dispersion in Metro Station
� Transient Incompressible Navier-Stokes + Scalar Transport
� Advection: Roe solver� Pressure: Poisson (Projection),
DPCG(Scalar Products) [800 Iter]� 3.95 Mels� 10 Time Steps� Double Precision
108Xeon E5530 (4)
191Xeon E5530 (2)
96Xeon E5530 (6)
115Tesla C2070
CPU (Sec)
375
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Artery
� Steady-State Incompressible NS� Advection: Roe, LU-SGS, Implicit� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 1.0 Mels� 200 Time Steps� Double Precision
161Xeon E5530 (4)
255Xeon E5530 (2)
105Xeon E5530 (6)
172Tesla C2070
CPU (Sec)
465
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Artery
� Steady-State Incompressible NS� Advection: Roe, LU-SGS, Implicit� Pressure: Poisson (Projection),
DPCG(Scalar Products)� 1.0 Mels� 200 Time Steps� Double Precision
161Xeon E5530 (4)
255Xeon E5530 (2)
105Xeon E5530 (6)
172Tesla C2070
CPU (Sec)
465
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Cylinder, Re=190
� Transient Incompressible Navier-Stokes
� Adv: Roe, RK2�� LineletLinelet Preconditioning (Visc,P)� 7198 (13),954 (14),27(15)
� 1.23 Mels� 50 Time Steps� Double Precision
69Xeon E5530 (4)
107Xeon E5530 (2)
53Xeon E5530 (6)
75Tesla C2070
CPU (Sec)
205
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Cylinder, Re=190
� Transient Incompressible Navier-Stokes
� Adv: Roe, RK2�� LineletLinelet Preconditioning (Visc,P)� 7198 (13),954 (14),27(15)
� 1.23 Mels� 50 Time Steps� Double Precision
69Xeon E5530 (4)
107Xeon E5530 (2)
53Xeon E5530 (6)
75Tesla C2070
CPU (Sec)
205
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Cylinder, Re=190
� Transient Incompressible Navier-Stokes
� Adv: Roe, RK3�� LineletLinelet Preconditioning (Visc,P)� 1(3), 16,588 (12), 30(15)
� 3.11 Mels� 50 Time Steps� Double Precision
190Xeon E5530 (4)
284Xeon E5530 (2)
150Xeon E5530 (6)
150Tesla C2070
CPU (Sec)
528
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Cylinder, Re=190
� Transient Incompressible Navier-Stokes
� Adv: Roe, RK3�� LineletLinelet Preconditioning (Visc,P)� 1(3), 16,588 (12), 30(15)
� 3.11 Mels� 50 Time Steps� Double Precision
190Xeon E5530 (4)
284Xeon E5530 (2)
150Xeon E5530 (6)
150Tesla C2070
CPU (Sec)
528
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dam Break
� Transient Incompressible Navier-Stokes
� VOF for Free Surface
� 1.0 Mels
� 100 Time Steps
� Double Precision
56Xeon E5530 (4)
85Xeon E5530 (2)
46Xeon E5530 (6)
41Tesla M2050
CPU (Sec)
145
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dam Break
� Transient Incompressible Navier-Stokes
� VOF for Free Surface
� 1.0 Mels
� 100 Time Steps
� Double Precision
56Xeon E5530 (4)
85Xeon E5530 (2)
46Xeon E5530 (6)
41Tesla M2050
CPU (Sec)
145
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Dam Break
� Transient Incompressible Navier-Stokes
� VOF for Free Surface
� 4.0 Mels
� 100 Time Steps
� Double Precision
6885125-Tesla M2050
Number of Domains
-
195
1
77
110
2
48
64
4CPU/GPU
8
Xeon X5670 (6) 46
Xeon X5670 (12) 36

Applied Simulations, Inc.
Dam Break
� Transient Incompressible Navier-Stokes
� VOF for Free Surface
� 4.0 Mels
� 100 Time Steps
� Double Precision
6885125-Tesla M2050
Number of Domains
-
195
1
77
110
2
48
64
4CPU/GPU
8
Xeon X5670 (6) 46
Xeon X5670 (12) 36

Applied Simulations, Inc.
Blast in Room With Dilute Material� Compressible Euler, Ideal GAS
EOS
� FEM-FCT (Explicit)
� 4.0 Mels
� 93Kparts
� Run for 60 Steps
� Double Precision
113Xeon E5530 (4)
178Xeon E5530 (2)
68Xeon E5530 (8)
49GTX295
CPU (Sec)
305
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Blast in Room With Dilute Material� Compressible Euler, Ideal GAS
EOS
� FEM-FCT (Explicit)
� 4.0 Mels
� 93Kparts
� Run for 60 Steps
� Double Precision
113Xeon E5530 (4)
178Xeon E5530 (2)
68Xeon E5530 (8)
49GTX295
CPU (Sec)
305
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Blast in Room With Dilute Material

Applied Simulations, Inc.
FEHEAT On GPUs

Applied Simulations, Inc.
FEHEAT (1)� Physics
� Heat Conduction
� Tensor Conductivity
� Nonlinear Conductivity
� Nonlinear Source Terms
� Numerics� 3-Element Type Code
� Bar (Edge), Shell (Triangle), Solid (Tetrahedron)
� Finite Element Formulation (Element Loops)
� Implicit Timestepping
� Iterative Solvers (DPCG/GMRES, ..)
� Optimized for Vector and SMP

Applied Simulations, Inc.
FEHEAT (2)� Engineering
� Nonlinear BC (Convection, Radiation, …)
� Link to CSD/CTD/Control/… Codes
� Link to Optimization Packages
� Statistics (05/2012) for Physics Modules� O(16.5) Klines of F77 Code
� O(0.20) KSubs
� Coding:� Well-Organized, Consistent (Same Names, Same Loops, …)
� Uses Simple, Explicit Subset of F77/F90
� Parallelized (OMP) + Vectorized
� Typical `Legacy Code’

Applied Simulations, Inc.
Cube
� Transient Heat Conduction
� 3.87 Mels
� 10 Time Steps
� Double Precision
17Xeon E5530 (4)
30Xeon E5530 (2)
13Xeon E5530 (8)
13Tesla C2070
CPU (Sec)
54
CPU/GPU
Xeon E5530 (1)

Applied Simulations, Inc.
Conclusions and Outlook (1)
� GPUs Here to Stay� Need Large Vector Lengths to Achieve Performance �
� Porting Will Pose Challenging Task for Many Legacy Codes
� Translators Such as F2GPU Offer Ability to:� Continue Development In Original Language Unhindered
� Incorporate Expert GPU Programming Skills Without Re-Write
� Evolve With Changing Standards
� GPUs: Transfer CPU/GPU Slow � All Code on GPU �� Memory Limits Applicability
� Use Usual MPI Domain Decomposition for Large Problems

Applied Simulations, Inc.
Conclusions and Outlook (2)
� Results Obtained To Date� Speedup: 1:4-1:16 in Double Precision [Tesla/Xeon 1-Core]
� Run on Several Graphics Cards [Tesla/Geforce]
� GPUs: Transfer Rate on GPU Slow [200 Gbytes/sec]� Limits Performance
� Attempt to Use/Re-Use Shared Memory [2 Tbytes/sec] ?
� Rethink Vectorization/Colouring Mapping to GPU [Coalescing]
� F2GPU: Looking for Codes…

















