Abstract: Face anti-spoofing is a relatively important part of the face recognition system, which has great significance for financial payment and access control systems. Aiming at the problems of unstable face alignment, complex lighting, and complex structure of face anti-spoofing detection network, a novel method is presented using a combination of convolutional neural network and brightness equalization. Firstly, multi-task convolutional neural network (MTCNN) based on the cascade of three convolutional neural networks (CNNs), P-net, R-net, and O-net are used to achieve accurate positioning of the face, and the detected face bounding box is cropped by a specified multiple, then brightness equalization is adopted to perform brightness compensation on different brightness areas of the face image. Finally, data features are extracted and classification is given by utilizing a 12-layer convolution neural network. Experiments of the proposed algorithm were carried out on CASIA-FASD. The results show that the classification accuracy is relatively high, and the half total error rate (HTER) reaches 1.02%. Key words: face anti-spoofing; MTCNN; brightness equalization; convolutional neural network Cite this article as: CAI Pei, QUAN Hui-min. Face anti-spoofing algorithm combined with CNN and brightness equalization [J]. Journal of Central South University, 2021, 28(1): 194−204. DOI: https://doi.org/10.1007/s11771-021- 4596-y.
1 Introduction
In recent years, the biometric technology based on face, fingerprint, iris and palm has attracted great attention, and face recognition technology is more easily accepted by users for its convenience and contactless with biometric devices. Face recognition and authentication systems have been widely used in mobile phones, computers, some registration systems and special monitoring systems and so on [1]. At present, there are many face recognition algorithms proposed. ZHANG [2] proposed to use scale invariant feature transform (SIFT) features under 3D meshes and MEHRASA [3] proposed supervised multimanifold method with locality preserving. However, these algorithms are
only one part in face recognition systems and most of them assume the input is genuine face image. But with the widespread use of the face recognition system, some illegal intruders can launch spoof face attacks against the systems with photos, videos and 3D face masks of genuine users. Since face recognition only recognizes the identity of the face, it can not prevent the attack of non-living face such as spoof face, which poses a great threat to the security of the system. The technology of face anti-spoofing detection is mainly to distinguish live face from spoof face such as false photos and videos, so as to prevent the spoof attack. As one security defense mechanism, face anti-spoofing plays a vital role in the face recognition systems, so it is very important to design a face anti-spoofing approach with high detection accuracy and strong
Foundation item: Project(61671204) supported by National Natural Science Foundation of China; Project(2016WK2001) supported by
Hunan Provincial Key R & D Plan, China Received date: 2020-02-03; Accepted date: 2020-06-25 Corresponding author: QUAN Hui-min, PhD, Associate Professor; Tel: +86-18684683401; E-mail: [email protected]; ORCID:
https://orcid.org/0000-0002-7887-394X
J. Cent. South Univ. (2021) 28: 194−204
195
generalization ability to help the face recognition and authentication system against malicious attacks. Face anti-spoofing approaches can be mainly classified into two types: inherent features based and learnable features based. Inherent features refer to the attributes of things themselves, such as texture, movement, 3D depth, and spectral reflection. MAATTA et al [4] used local binary pattern (LBP) to extract facial texture features, and obtained better results on the NUAA dataset [5]; de FREITAS et al [6] used local binary patterns from three orthogonal planes (LBP-TOP) to extract spatio-temporal texture feature, the experimental results on the replay-attack dataset [7] were better than the LBP method. KOLLREIDER et al [8] used lip movement classification and lip-reading for face anti-spoofing. These methods require the active cooperation of the user, the user’s experience is reduced and the detection time is longer, de MARSICO et al [9] proposed to use the 3D projective invariants for face anti-spoofing detection, which was merely effective for photo attacks without warping. PAVLIDIS et al [10]
utilized method based on multispectral reflection for face anti-spoofing, which selected proper working spectra to obtain the reflectance differences between live and spoof faces, but these features extracted by manual design methods are relatively single, it is easy to be affected by external light, and the method also has strict requirements for devices. Learnable features are based on deep learning, they are mainly learned automatically by training the input data and have strong generalization. YANG et al [11] used a convolutional neural network (CNN) to learn highly discriminative features, and used face images with different sizes of background as input data. But the face detector selected the Viola-jones of the opencv, which has the problem of inaccurate face alignment and detection. LIU et al [12] proposed the use of spatial and time information for face anti-spoofing. The spatial information is mainly the depth map feature information, which is extracted by training the depth map of the face and ground truth labels using CNN. The time information is mainly obtained by recurrent neural network (RNN), which is trained with the remote photo plethysmography (RPPG) signal extracted from the video. Good results are achieved within the dataset, but the RPPG signal is not stable enough and is susceptible
to illumination. ATOUM et al [13] proposed a face anti-spoofing method based on two-stream CNN, which mainly extracted local features from local face images and depth features from the whole face image, then judged according to the scores output by CNN. But the weights of the two streams were set to a fixed value and no more weight comparisons were made. For face anti-spoofing detection, many methods based on inherent features are better in specific situations, but not stable enough in complex environments, and most of them need extra cooperation of users. Those methods based on learnable features can learn more generalized features to withstand different types of attacks and distinguish between live faces and spoof faces, but most of them utilized Viola-jones as face detector, which has the shortcoming of unstable face alignment. Both methods are inadequate to deal with the effects of complex illumination, resulting in a reduced detection accuracy. In view of the problems of the above methods, we have made the following improvements. First, we designed a 12-layer end-to-end CNN for extracting features to ensure the integrity of facial features. Second, we utilized multi-task convolutional neural network (MTCNN) as face detector instead of traditional Viola-jones because MTCNN has better stability and accuracy in face detection, so that we improved the validity of the dataset. Third, we made use of brightness equalization to overcome the influence of complex illumination and improve the accuracy of detection. 2 Related works The tremendous success of CNN on ImageNet has attracted a large number of computer vision researchers to study the potential capabilities and applications of CNN. REHMAN et al [14] proposed a face anti-spoofing method based on end-to-end CNN named Network C. This method regards face anti-spoofing detection as a binary classification problem. Face data detected by the Viola-jones detector and the corresponding labels are input into Network C, to extract face features and train the classifier to give the classification. The network architecture of Network C is shown in Figure 1. Network C is composed of eight convolutional layers and three fully connected layers. At the same time, there are pooling layers after the first, second,
J. Cent. South Univ. (2021) 28: 194−204
196
Figure 1 Network C architecture
fourth, sixth and eighth convolutional layer. The output layer of the network uses softmax to complete classification. The convolutional layer consists of a group of convolution kernels, the convolution kernels divide the entire image into small blocks and work by convolution with a specific set of weights. This process of dividing the image into small blocks is helpful for extracting the locally related pixel values of the image, and the feature map is obtained by aggregating local information. Compared with the fully connected network, the weight sharing of convolution operation makes the parameters of the CNN more effective. Network C has eight convolutional layers, and the different convolutional layers contain different kernel sizes, mainly including 7×7, 5×5 and 3×3 convolution kernels. The activation function is mainly to make up for the lack of expression ability of the linear model, and adds nonlinearity to the network so that the network can understand more complex information. The activation function acts on the output of the convolutional layer, the common activation functions are sigmoid, tanh, Relu and so on. Relu has the advantage of overcoming gradient disappearance, which is superior to other activation functions. Therefore, Network C uses the Relu activation function after the convolutional layer and the fully connected layer. The operation of the pooling layer and the convolutional layer are basically the same, the difference is that the convolution kernel of the pooling layer takes only the maximum or average value of the corresponding position. The pooling operation summarizes the similar information near the receptive field and outputs the main response in a local area. The extracted features just need to retain approximate
distances from other features, the precise location is no longer important. Figure 2 shows the process of the maximum pooling operation by a filter with a step size of 2 and a kernel size of 2×2. The final output is the maximum value of each 2×2 region corresponding in the left feature map, and the feature map is compressed to 2×2. In Network C, the pooling layer is set behind the convolutional layer, and its kernel size is 2×2, the step size is 1, and the maximum pooling is used.
Figure 2 Max pooling process
The fully connected layer is usually used for classification task at the end of the network. Unlike the pooling layer and the convolutional layer, it is a global operation, the output of the previous layer is used as input for global analysis, then the selected features are combined nonlinearly as output. In Network C, the fully connected layers are distributed in the last three layers of the network. The dimension of the first two fully connected layers is 128, and the size of the last one is 2. The last fully connected layer is the output layer of Network C, which uses softmax function to convert the input image to the probability distribution of different categories. Network C and Viola-jones face detector are combined on the CASIA-FASD dataset to perform face anti-spoofing experiments, and the
J. Cent. South Univ. (2021) 28: 194−204
197
classification accuracy rate reaches 92.77%, proving that Network C has certain advantages in extracting face features. However, due to the instability of face alignment in the detection of Viola-jones face detector, considering the depth and the amount of parameters of the network, this paper made further improvements on this basis, MTCNN network is adopted as a face detector instead of Viola-jones, two 3×3 convolution kernels are used to replace a 5×5 convolution kernel in Network C, which reduces the amount of parameters and increases the network depth. 3 Proposed approach The main purpose of using CNN is to capture the discriminative and generalized features from the face data, and output the live and spoof probability for the input face. Face anti-spoofing process framework is shown in Figure 3. Firstly, the video frames are input and detected by the MTCNN face detector, MTCNN filters out pictures containing faces, then the selected face pictures are cropped according to the regulations and processed through brightness equalization to weaken the influence of complex illumination. Finally, features are captured using the proposed CNN network and the corresponding probabilities and categories are determined by softmax. 3.1 MTCNN face-detector Before face data are input into the CNN network, it is necessary to perform face detection to detect whether a face exists in the photo. In most previous face anti-spoofing, the Viola-jones
detector [15] was mainly used as a face detector, the principle is to train the cascaded AdaBoost classifier by using simple Haar features, to exhaust the possible face areas through a sliding window, and to send these areas to the classifier to classify faces and non-faces. The four rectangular features used by Voila-jones are shown in Figure 4. The value of the Haar feature equals the difference between the image pixel values of the white area and that of black area in the rectangular area. However, in some extreme cases, the Viola-jones detector is not able to perform face alignment well, resulting in a decrease of face detection accuracy and incomplete faces in the cropped photos. MTCNN can align faces effectively and detect faces accurately [16]. Therefore, this paper uses MTCNN as a new face detector. MTCNN maintains good performance while reducing the number of subnets and the amount of computation by training three complementary tasks: bounding box regression, keypoint regression, and face partial classification. The workflow of MTCNN is shown in Figure 5. At the input layer, the image pyramid is used to scale the initial image, then P-Net is used to generate a large number of candidate boxes. After that, the R-Net is used for the first selection and bounding boxes regression, and most negative examples are excluded. Finally, the O-Net network with higher network complexity and detection accuracy is used to discriminate the remaining target bounding boxes and perform bounding boxes regression to ensure the accuracy of face detection. The network structures of P-net, R-Net and O-net are shown in Figure 6.
Figure 3 Process framework for face anti-spoofing
Figure 4 Four rectangular features used by Viola-jones
J. Cent. South Univ. (2021) 28: 194−204
198
Figure 5 MTCNN workflow diagram
After using MTCNN for face detection, in order to preserve the edge part of the media other than the face in the image, it helps to recognize whether the face comes from a medium such as a photo or video, the bounding boxes of the detection output are enlarged to the original 3 times and cropped to 240×240 size.
3.2 Brightness equalization Considering the impact of complex lighting on face detection, the brightness equalization is applied to process the cropped face image before training the data. The brightness equalization [17] process includes: divide the background brightness of the image into blocks and dynamically adjusting them, so that the adjusted background brightness is approximately at the same level, and then use the global threshold for segmentation. Assuming that the gray level of an M×N image is (0, …, L), the average brightness can be represented as:
1 1
0 0av
( , )M N
i j
p i j
LumM N
(1)
where p(i, j) is the pixel brightness value with coordinates of (i, j) in the image. If a subblock of size m×n is used to block the target image, the mean brightness of each subblock is:
1 1
0 0av-bm
( , )M N
i j
p i j
Lumm n
(2)
Figure 6 Network structures of P-Net, R-Net, and O-Net
J. Cent. South Univ. (2021) 28: 194−204
199
The difference between the mean brightness of the subblock and that of the whole graph is lum av-bm av ,Lum Lum it is easy to see that Δlum of the high brightness subblock is positive and Δlum of the low brightness subblock is negative. In order to equalize the brightness of the whole image, the brightness of each subblock in the image should be adjusted, the attenuation processing is performed on the subblocks with positive Δlum, and the enhancement processing is performed on the subblocks with negative Δlum. Because the local threshold segmentation method is defective, the subblock matrix is interpolated according to Δlum instead of adding or subtracting the same adjustment value for each subblock, so that it extends to the entire original image size, and the adjustment value between the adjacent subblocks changes relatively smoothly, then the brightness value of the target image pixel is used to make difference with the interpolated Δlum matrix, and the brightness of each subblock pixel is adjusted to fit the entire brightness range according to the minimum and maximum brightness in the target image, which achieves the brightness adjustment of the entire image. Images processed with brightness equalization are shown in Figure 7. The upper line is a fake face and its corresponding brightness equalization processing, and the lower line is a real face and its corresponding brightness equalization processing.
Figure 7 Image processed with brightness equalization
3.3 Proposed CNN network model Considering the network depth and the computation of the network, two convolution kernels of 3×3 are utilized to substitute the convolution kernel of 5×5 at the second layer of
Network C proposed by REHMAN et al [14]. Figure 8 explains the principle of replacing a 5×5 convolution kernel with 3×3 small convolution kernels, when stride=1, the 5×5 matrix is convolved into 3×3 through one 3×3 convolution kernel, and then becomes 1×1 through one 3×3 convolution kernel again, that is, after two 3×3 convolutions, the data source corresponding to one value is a 5×5 coverage area. Therefore, replacing a 5×5 convolution kernel with two 3×3 convolution kernels ensures that the depth of the network is improved and the computation amount is reduced while having the same receptive field. Moreover, there is an activation function between the two 3×3 convolution kernels, which increases the nonlinearity of the network and prevents over- fitting.
Figure 8 Mini-network replacing 5×5 convolutions
In order to extract the facial features effectively, a 12-layer CNN is designed in this paper as shown in Figure 9, it is modified on the basis of Network C. The first layer adopts 7×7 convolution kernel to obtain rough contour features through the larger receptive field. In the next 8 layers, 3×3 convolution kernel is used to obtain fine texture features. The last three layers are fully connected layers. The first layer, the third layer, the fifth layer, the seventh layer and the ninth layer are respectively connected with pooling layer to achieve the purpose of dimension reduction and parameters compression. The kernel size of the pooling layer is 2×2. Each pooling layer is followed by a random dropout layer (dropout=0.5) to prevent over-fitting. All convolutional layers and the first two fully connected layers use Relu as the excitation function, the last softmax classifier is used for binary classification. The output layer, which receives the face features extracted by the network, outputs the probabili ty of the live and spoof categories
J. Cent. South Univ. (2021) 28: 194−204
200
Figure 9 Architecture of proposed CNN network
corresponding to the face samples. The process can be defined as:
( ( )), ( )ly CNN Z l Z (3) where Zl represents the input picture, CNN(Zl) represents the image features extracted by the CNN network, σ represents the softmax function, y represents the probability of the output. The definition of the softmax function is shown in formula (4), where N represents the number of categories. Since face anti-spoofing is a binary classification problem, N is 2.
( )
( )
e( ( ))=
e
l
l
CNN Z
l CNN ZN
CNN Z
(4)
4 Experiments To verify the performance of the proposed method, this section mainly analyzed two aspects: 1) the influence of model architecture, face detector and brightness equalization on the performance of the algorithms; 2) the performance contrast with some existing algorithms. The following will introduce experimental data and environmental setting, evaluation indicators and experimental analysis. 4.1 Experimental setting In the experiment, firstly the frame images are obtained by opencv’s own video framing function, and the MTCNN face detector in Section 3.1 is used to detect the regions of the face in the frame images, the regions are expanded to three times of the original size and cropped to 240×240. Then the cropped pictures are compensated by using the brightness equalization algorithm and they are resized to 96×96. For feature extraction, the data
are divided into two categories: live face and spoof face, and the corresponding labels are set for the two types of data. During the training stage, the whole network uses Adam method to optimize the parameters, the learning rate is initially set to 0.01 at the beginning of the 100 epochs, then decays at a rate of 0.1, the number of iterations during training is 4000 and the batch_size is set to 16. Batch_size samples are randomly selected from the training set, and their corresponding pictures and labels are input into the proposed CNN network to train the network model. CASIA-FASD database [18] is utilized for our experiments. The database has 50 subjects and is divided into two subsets: the training set (20 subjects) and the testing set (30 subjects). For each subject, the database provides 12 videos containing three real faces and nine fake faces. Each video is given three image qualities: low resolution (L), normal resolution (N), high resolution (H). There are three types of attacks including warped photo attack, cut photo attack and video attack for each subject in the database. The experiments were carried under Windows environment, using the python language, tensorflow-CPU platform and some related library functions of opencv. 4.2 Evaluation indicators In order to evaluate the performance of the proposed method, this paper uses accuracy (ACC) and half total error rate (HTER) as evaluation indicators, which are defined as follows:
=TP TN
ACCTP FN FP TN
(5)
=FP
FARFP TN
(6)
J. Cent. South Univ. (2021) 28: 194−204
201
=FN
FRRTP FN
(7)
= 100%2
FAR FRRHTER
(8)
where TP is the number that positive samples are predicted as positive samples; FN is the number that positive samples are predicted as negative samples; FP is the number that negative samples are predicted as positive samples; TN is the number that negative samples are predicted as negative samples; ACC is the accuracy rate, which is the proportion of all correctly predicted samples to the total samples; FAR is false acceptance rate, which is the proportion of negative samples that are mispredicted to all negative samples; FRR is false rejection rate, which is the proportion of positive samples that are incorrectly predicted to all positive samples; HTER is half total error rate, that is, the average of FAR and FRR, which can effectively evaluate the classification results of the face anti-spoofing algorithm. 4.3 Experiment verification Face anti-spoofing as a two-classification problem, is mainly to determine whether an input face image is live or spoof. The paper utilizes BSRS-єPS Sec-1E (BS random samples-єPS sub- epochs count-1 epoch) approach proposed by REHMAN et al [14] as the training strategy. To verify the performance of the proposed network, the comparison experiments were carried out on Network C and proposed CNN network, adopting Viola-jones as the face detector, using CASIA-FASD as the experimental dataset. Experiments are divided into two groups, the first group uses Network C as a feature extraction network and Viola-jones as a face detector, and the second group uses proposed CNN as a feature extraction network and Viola-jones as a face detector. The results are shown in Table 1. Through the analysis of experimental results, the accuracy rate of the proposed CNN network reaches 93.25%, and the accuracy rate of Network Table 1 Evaluation results of Network C and proposed
CNN
Method ACC/% HTER/%
Network C+Viola-jones 92.77 11.8
Proposed CNN+Viola-jones 93.25 8.23
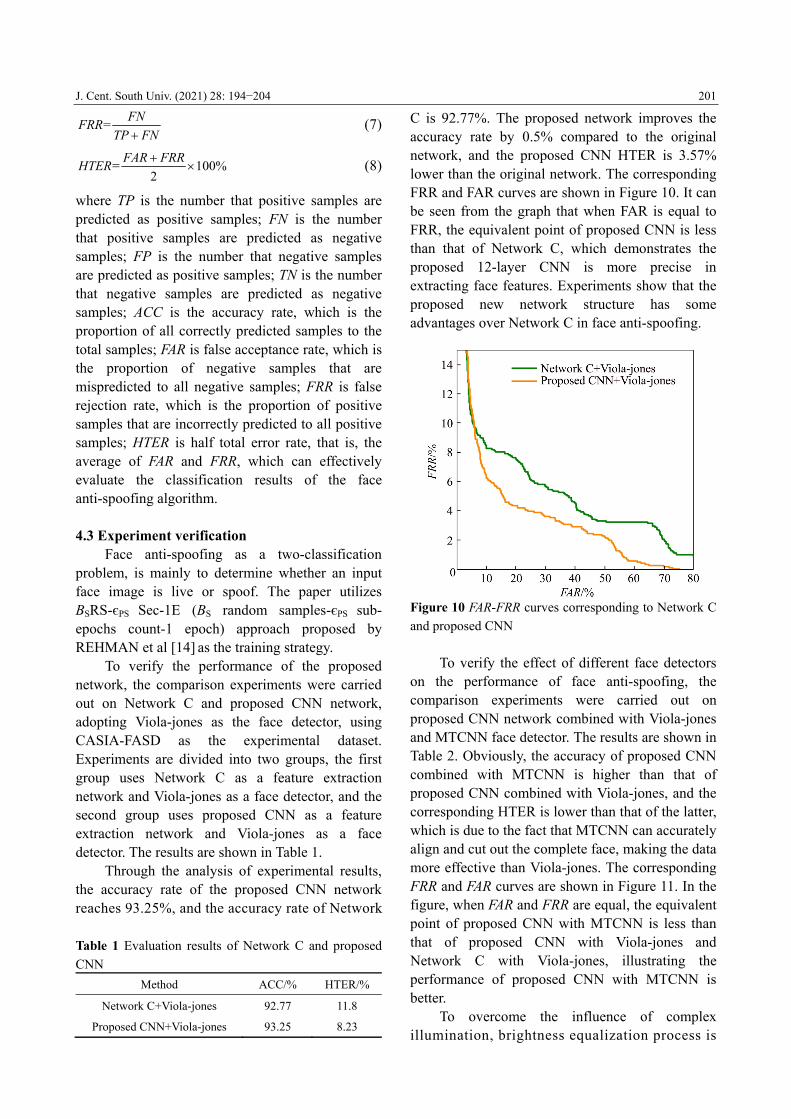
C is 92.77%. The proposed network improves the accuracy rate by 0.5% compared to the original network, and the proposed CNN HTER is 3.57% lower than the original network. The corresponding FRR and FAR curves are shown in Figure 10. It can be seen from the graph that when FAR is equal to FRR, the equivalent point of proposed CNN is less than that of Network C, which demonstrates the proposed 12-layer CNN is more precise in extracting face features. Experiments show that the proposed new network structure has some advantages over Network C in face anti-spoofing.
Figure 10 FAR-FRR curves corresponding to Network C
and proposed CNN
To verify the effect of different face detectors on the performance of face anti-spoofing, the comparison experiments were carried out on proposed CNN network combined with Viola-jones and MTCNN face detector. The results are shown in Table 2. Obviously, the accuracy of proposed CNN combined with MTCNN is higher than that of proposed CNN combined with Viola-jones, and the corresponding HTER is lower than that of the latter, which is due to the fact that MTCNN can accurately align and cut out the complete face, making the data more effective than Viola-jones. The corresponding FRR and FAR curves are shown in Figure 11. In the figure, when FAR and FRR are equal, the equivalent point of proposed CNN with MTCNN is less than that of proposed CNN with Viola-jones and Network C with Viola-jones, illustrating the performance of proposed CNN with MTCNN is better. To overcome the influence of complex illumination, brightness equalization process is
J. Cent. South Univ. (2021) 28: 194−204
202
Table 2 Evaluation results of face anti-spoofing
detection with different face detectors
Method ACC/% HTER/%
Network C+Viola-jones 92.77 11.8
Proposed CNN+Viola-jones 93.25 8.23
Proposed CNN+ MTCNN 96.11 5.34
Figure 11 FAR−FRR curves corresponding to MTCNN
and Viola-jones
proposed in this paper. Here, Network C and proposed CNN are used for comparison experiments, in which MTCNN is used as the face detector and brightness equalization is added. Experiments are divided into four groups, the first group is carried out on Network C and Viola-jones, without brightness equalization, the second group is proposed CNN and MTCNN, without brightness equalization, the third group is carried out on Network C and MTCNN, with brightness equalization, the fourth group is carried out on proposed CNN and MTCNN, with brightness equalization. The results are shown in Table 3, where light represents the brightness equalization. Table 3 shows that the accuracy achieves to 97.7% and the HTER achieves to 3.6% in the experiments based on Network C and MTCNN combined with brightness equalization, the accuracy achieves to 99.32% and the HTER achieves to 1.02% in the experiments based on the combination of proposed CNN and MTCNN with the brightness equalization process. The experimental results proved that the brightness equalization can effectively reduce the influence of complex illumination. The corresponding FAR−FRR curves are shown in Figure 12, it shows that the equivalent
Table 3 Evaluation results of face anti-spoofing
detection with brightness equalization
Method ACC/% HTER/%
Network C+Viola-jones 92.77 11.8
Proposed CNN+MTCNN 96.11 5.34
Network C++MTCNN (light) 97.70 3.60
Proposed CNN+MTCNN (light) 99.32 1.02
Figure 12 FAR−FRR curves corresponding to presence
or absence of brightness equalization
point of the fourth group experiments is the smallest in the four groups, which demonstrates the proposed algorithm is more effective. Comparing the proposed method with the current CNN based and other traditional methods, the results are shown in Table 4. From the table, we can see that the proposed method has the smallest HTER, which shows: 1) the use of MTCNN increases the validity of the dataset; 2) the use of a deeper network helps to extract deep level features; 3) the use of a brightness equalization algorithm he lps the ne twork learn more in format ion Table 4 HTER comparison of algorithms on CASIA-
FASD
Method CASIA-FASD(test) HTER/%
LSTM+CNN [19] 5.93
LCNN [11] 4.64
DPCNN [20] 4.5
3DCNN [21] 11.34
LBP-TOP [6] 23.75
LBP [6] 23.19
Correlation [6] 30.33
Proposed 1.02
J. Cent. South Univ. (2021) 28: 194−204
203
about the face and weaken the influence of the surrounding environment on the face. 5 Conclusions A novel approach is presented to cope with face anti-spoofing. We designed a simple CNN network model, which makes full use of the learning ability and generalization ability of the neural network to learn the face differences of live and spoof faces. We chose MTCNN as the face detector to improve the accuracy of face detection, and added brightness equalization process in the method to reduce the influence of illumination. Experimental results show the proposed method achieves the recognition accuracy rate of 99.3% and HTER of 1.02% on CASIA-FASD database. It indicates that the proposed approach can be comparable to some existing face anti-spoofing algorithms and even outperforms some of them. In the future, we will test our proposed method on other datasets including more spoof types to give better recognition effect.
Contributors CAI Pei provided the concept, established the models and analyzed experimental results. QUAN Hui-min wrote the initial draft of the manuscript. Both authors replied to reviewers’ comments and revised the final version. Conflict of interest CAI Pei and QUAN Hui-min declare that they have no conflict of interest.
References [1] RAMACHANDRA R, BUSCH C. Presentation attack
detection methods for face recognition systems: A
comprehensive survey [J]. ACM Computing Surveys
(CSUR), 2017, 50(1): 1−37. DOI: 10.1145/3038924.
[2] ZHANG C, GU Y, HU K, WANG Y G. Face recognition
using SIFT features under 3D meshes [J]. Journal of Central
South University, 2015, 22(5): 1817−1825. DOI: 10.1007/
s11771-015-2700-x.
[3] MEHRASA N, ALI A, HOMAYUN M. A supervised
multimanifold method with locality preserving for face
recognition using single sample per person [J]. Journal of
Central South University, 2017, 24(12): 2853−2861. DOI:
10.1007/s11771-017-3700-9.
[4] MAATTA J, HADID A, PIEKIKAINEN M. Face spoofing
detection from single images using micro-texture analysis
[C]// 2011 International Joint Conference on Biometrics