18
Feature Selection Focused within Error Clusters Sui-Yu Wang and Henry Baird Presented by Sui-Yu Wang
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | gisela-hinton |
| View: | 21 times |
| Download: | 1 times |

Feature Selection Focused within Error Clusters
Sui-Yu Wang and Henry Baird
Presented by Sui-Yu Wang

2
Feature Selection
• Given a set of n features, find a subset of k < n features that still performs well– Best k features chosen separately are usually not the best k
when chosen together (Elashoff et. al, 1967) – To select the optimal subset, one has to exhaustively search
through all k-elements subsets (Cover and Campenhout, 1977)
– Given limited number of training samples and features, finding the minimum subset of features without misclassifying any training sample is NP complete (Van Horn and Martinez, 1994)

3
Feature Selection
• Methods can be divided into three categories: wrappers, filters, and embedded methods. (Guyon and Elisseeff, 2003) – Filters: rank features according to various metrics– Wrappers: evaluate subset of features according to
given classifier– Embedded methods: similar to wrapper, but uses
non-exhaustive search methods
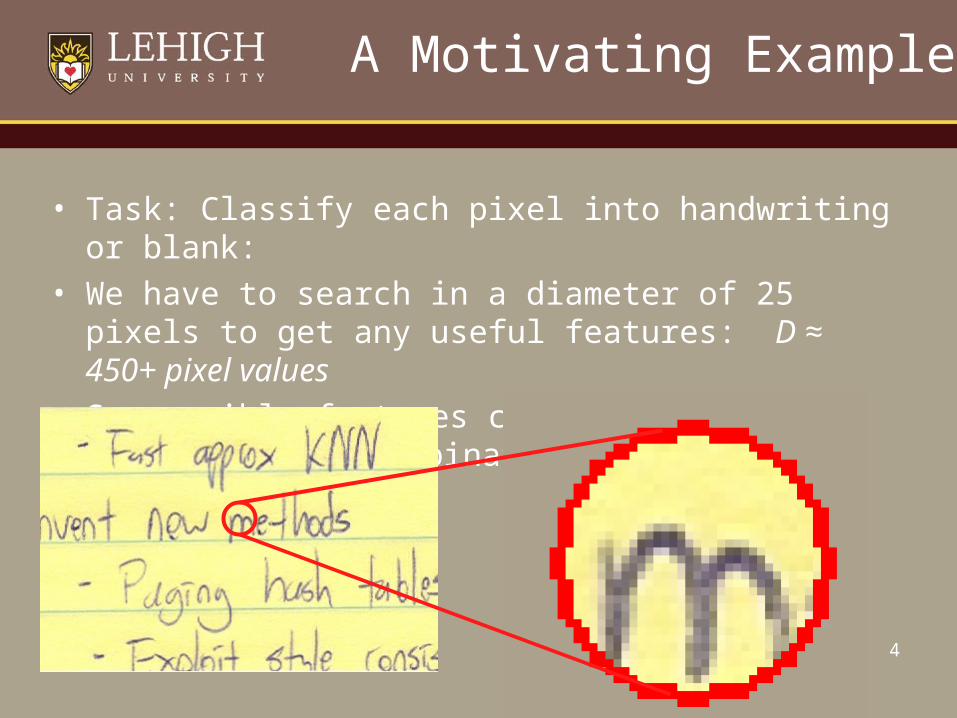
A Motivating Example
• Task: Classify each pixel into handwriting or blank:
• We have to search in a diameter of 25 pixels to get any useful features: D ≈ 450+ pixel values
• So possible features can be extremely numerous: any combination of 450 pixel values
4

5
Popular Method: PCA
Principal Components Analysis• PCA finds a small number of linear combinations of original
features
• PCA finds the dimension that represents the data best in a least square sense, but does not guarantee good separation of data (Pearson, 1901)
• Most algorithms employee PCA first then operate respective feature selection algorithm on the reduced set– Could throw away potentially interesting information

6
Our Research Strategy
• We want to find methods for guiding the search for a few strongly discriminating features.
• We adopt a greedy heuristic: constructing one feature at a time.
• We focus our search on cases where the current features fail.

7
Formalities
• We assume a two class problem• The original sample space is , D is huge• We are given d << D hand-crafted features, all
samples are projected into this feature space by feature extractor . We may lose information during the process
• If there is any discriminating information in the sample space but not in the feature space , it is must be in the null space

8
Finding the Null Space
• If is linear, the null space can be computed by linear algebra methods
• Given , a singular value decomposition, or SVD, can be used to find the set of vectors spanning the null space of :– can be factorized as where
and are orthogonal matrices
– And
€
f d
€
f d

9
Finding the Next Feature
• Samples that fall at the same point in are not discriminated by the current feature set
• Samples that lie in tight clusters in are only weakly discriminated by the current feature set
• A tight cluster of errors of both classes indicates cases where the current feature set fails completely
• Therefore, we use these tight clusters to guide the forward search for new features
• Once we have projected samples from the tight error cluster into the null space, we find a hyperplane that best separates the data, and calculate a given sample x’s distance to this hyperplane, , as the new feature
DR
€
Rd

10
Operate on Points in the Null Space
• There are many ways to projects points in the sample space into the null space of , – The orthogonal projection onto a particular
subspace is unique– Let where is an
orthonormal basis for the subspace . Then

11
dD RR −

12
Outline of the Algorithm
RepeatDraw enough samples to train a classifierDraw enough samples to build a test setFind clusters of errors in Repeat
Choose a tight cluster with both types of errorsDraw enough samples to populate this cluster (if necessary)Project the cluster into the null spaceFind a separating hyperplane in the null space with normal vector that best separates the samples in this clusterConstruct a new feature and examine its performance
Until the feature lowers the error rate sufficiently
Until the error rate is satisfactory to the user
€
rw
€
Rd
13
Experiments
• Experiments were conducted on a document image content extraction problem– Each image pixel is treated as a sample– The task is to classify each sample into handwriting or
machine print– Possible features are extracted from a 2525 pixel square,
D=625

14
Experimental Results
HW MP PH BL
15
Experiments
• We divide the data into three sets: training set, discovery set, and test set.– The training set consists of 4,469,740 MP samples and
943,178 HW samples– The feature discovery set consists of 4,980,418 MP and
1,496,949 HW samples– The test set consists of 816,673 MP samples and 649,113
HW samples
16
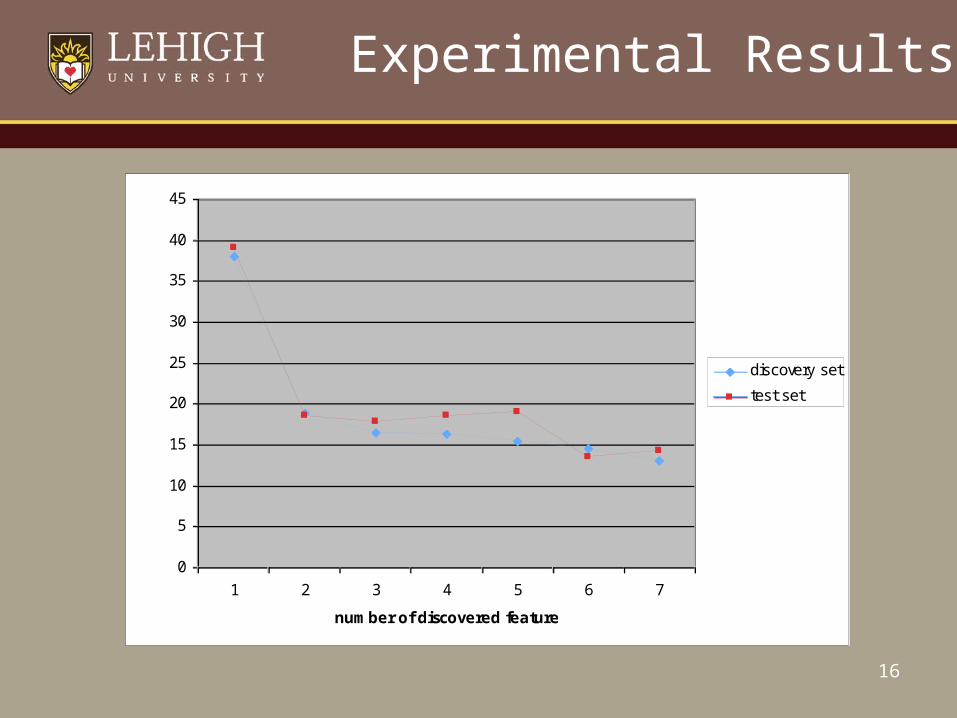
Experimental Results
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7
number of discovered feature
error rate
discovery set
test set

17
Which Cluster is Best?
• Experiments suggest that tight balanced clusters are bestCluster 1 2 3 4 5
error rate 14.4 15.5 15.6 13.5 14.8
Balance 90 60 51 52 65
Tightness 83 90 83 70 80

18
Future Work
• Apply the method to other problems• Continue the experiment to see how low the error can
drop• Analyze cluster statistics to establish rules for
selecting better cluster candidate• Try other hyperplane-finding methods• Establish theoretical framework as to when this
approach is guaranteed to work and when it fails

















