File Sharing : Hash/Lookup Yossi Shasho (HW in last slide) • Based on Chord : A Scalable Peer-to-peer Lookup Service for Internet Applications • Partially based on The Impact of DHT Routing Geometry on Resilience and Proximity • Partially based on Building a Low-latency, Proximity-aware DHT- Based P2P Network http://www.computer.org/portal/web/csdl/doi/10.1109/KSE.2009.49 • Some slides liberally borrowed from: • Carnegie Melon Peer-2-Peer 15-411 1
Transcript
File Sharing : Hash/LookupYossi Shasho(HW in last slide)
• Based on Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications•Partially based on The Impact of DHT Routing Geometry on Resilience and Proximity• Partially based on Building a Low-latency, Proximity-aware DHT-Based P2P Network http://www.computer.org/portal/web/csdl/doi/10.1109/KSE.2009.49 • Some slides liberally borrowed from:
• Carnegie Melon Peer-2-Peer 15-411• Petar Maymounkov and David Mazières’ Kademlia Talk, New York University
– Distributed systems without any centralized control or hierarchical organization.
– Long list of applications:• Redundant storage• Permanence• Selection of nearby servers• Anonymity, search, authentication, hierarchical naming
and more
– Core operation in most p2p systems is efficient location of data items
2
Outline
3
4
Think Big
• /home/google/• One namespace, thousands of servers
– Map each key (=filename) to a value (=server)– Hash table? Think again
• What if a new server joins? server fails?• How to keep track of all servers?• What about redundancy? And proximity?• Not scalable, Centralized, Fault intolerant• Lots of new problems to come up…
5
6
DHT: Overview
• Abstraction: a distributed “hash-table” (DHT) data structure:– put(id, item);– item = get(id);
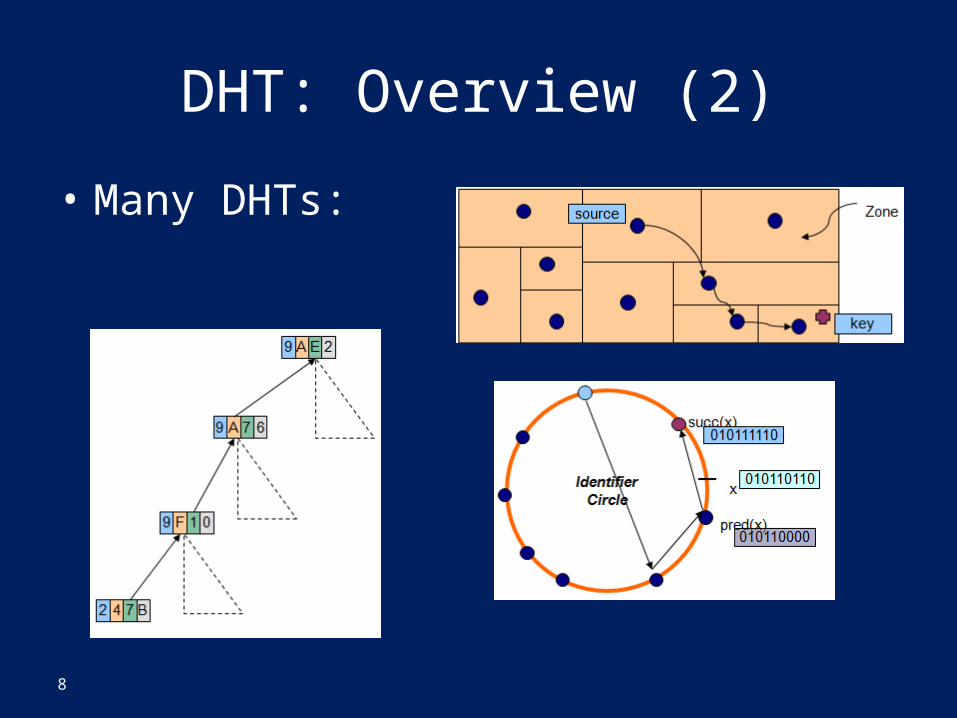
• Scalable, Decentralized, Fault Tolerant• Implementation: nodes in system form a
distributed data structure– Can be Ring, Tree, Hypercube, Skip List, Butterfly
Network, ...
7
DHT: Overview (2)
• Many DHTs:
8
DHT: Overview (3)
• Good properties: – Distributed construction/maintenance– Load-balanced with uniform identifiers– O(log n) hops / neighbors per node– Provides underlying network proximity
9
Consistent Hashing
• When adding rows (servers) to hash-table, we don’t want all keys to change their mappings
• When adding the Nth row, we want ~1/N of the keys to change their mappings.
• Is this achievable? Yes.
10
11
12
13
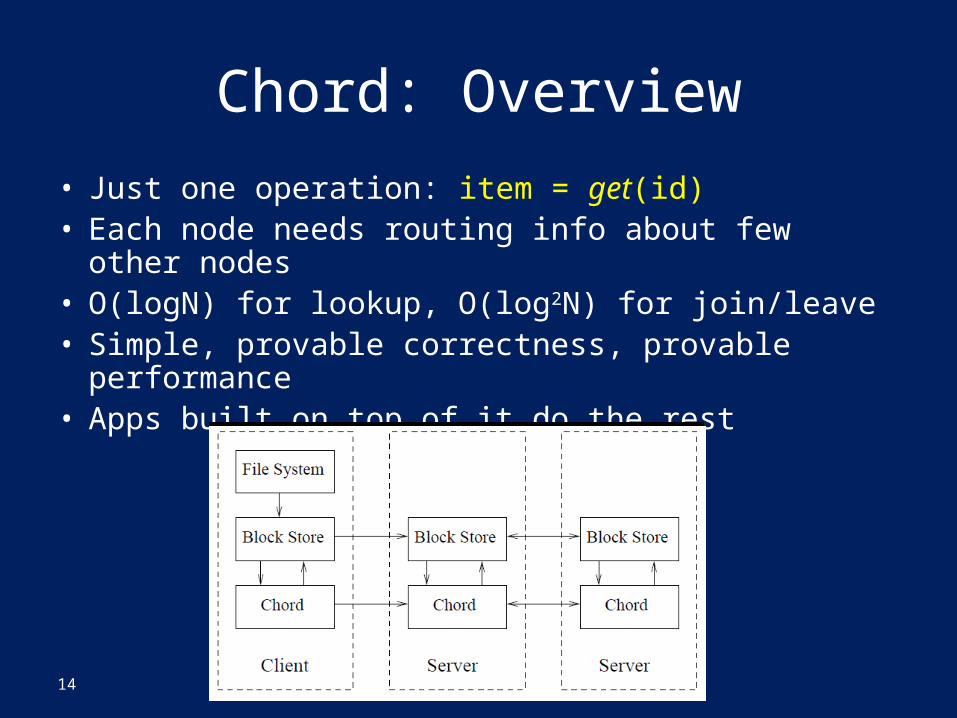
Chord: Overview
• Just one operation: item = get(id)• Each node needs routing info about few other nodes• O(logN) for lookup, O(log2N) for join/leave• Simple, provable correctness, provable performance• Apps built on top of it do the rest
14
Chord: Geometry
• Identifier space [1,N], example: binary strings• Keys (filenames) and values (server IPs)
on the same identifier space• Keys & values evenly distributed• Now, put this identifier space on a circle• Consistent Hashing:
A key is stored at its successor.
15
Chord: Geometry (2)
• A key is stored at its successor: node with next higher ID
16
N32
N90
N105
K80
K20
K5
Circular ID space
Key 5Node 105
• Get(5)=32• Get(20)=32• Get(80)=90• Who maps to 105? Nobody.
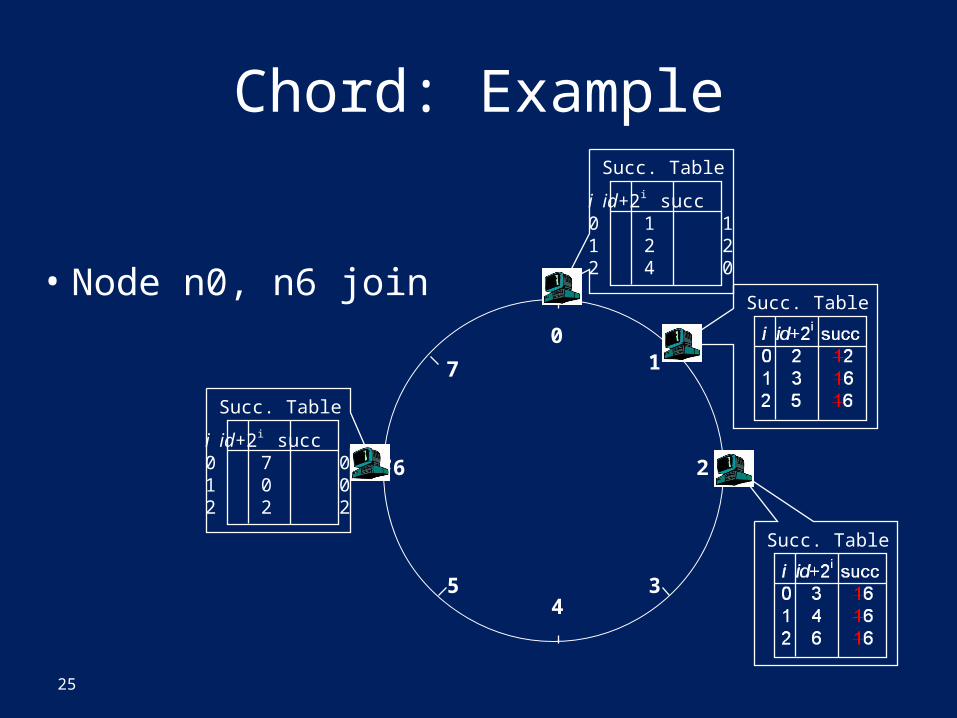
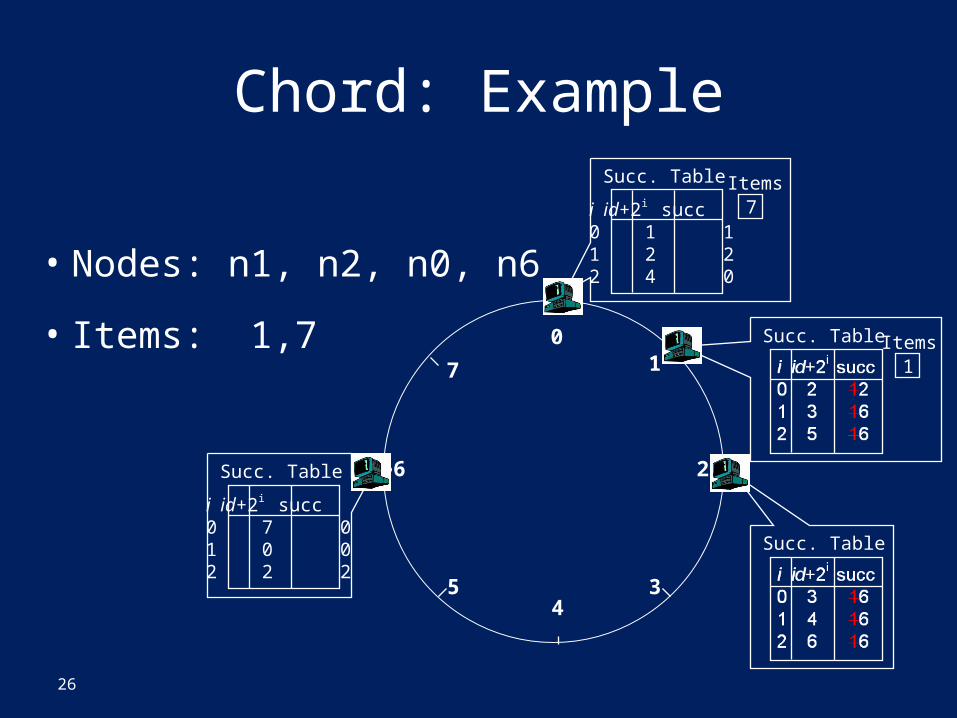
Chord: Back to Consistent Hashing• “When adding the Nth row, we want ~1/N of the keys to
change their mappings.” (The problem, a few slides back)
17
N32
N90
N105
K80
K20
K5
Circular ID space
Key 5Node 105
• Get(5)=32• Get(20)=32• Get(80)=90• Who maps to 105? Nobody.
N50
N15
18
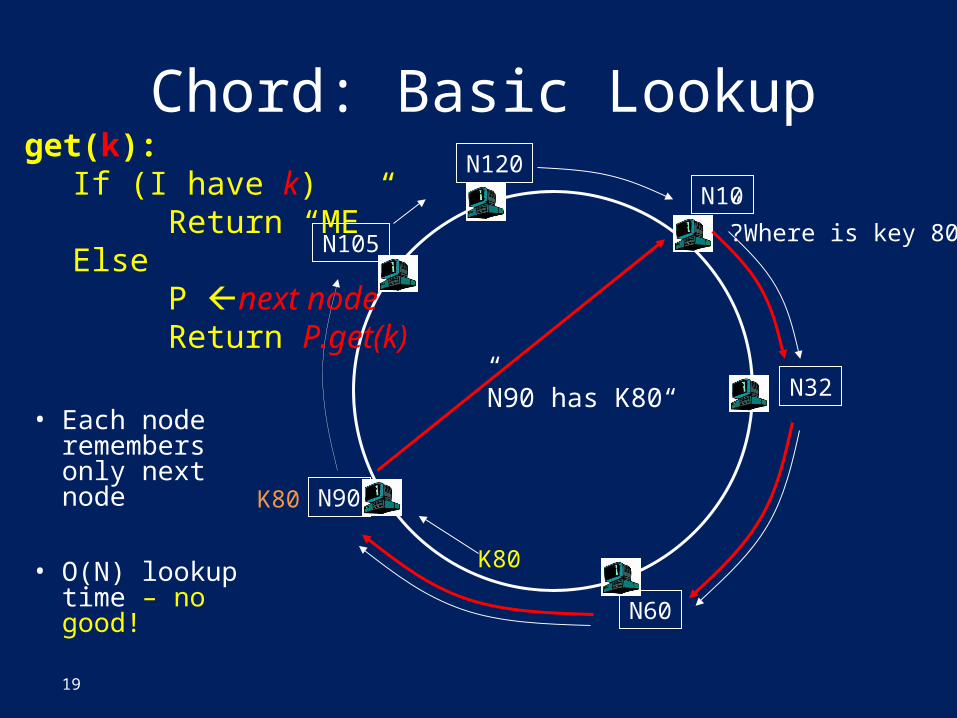
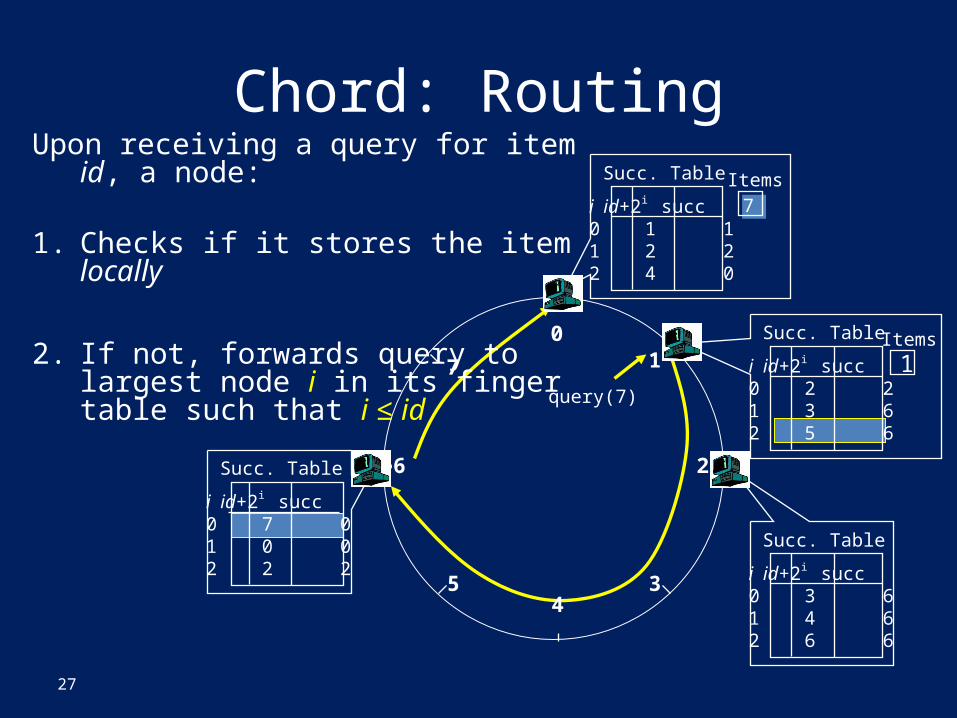
Chord: Basic Lookup
19
N32
N90
N105
N60
N10N120
K80
“Where is key 80”?
“N90 has K80”
K80
• Each node remembers only next node
• O(N) lookup time – no good!
get(k):If (I have k) Return “ME”Else P next node Return P.get(k)
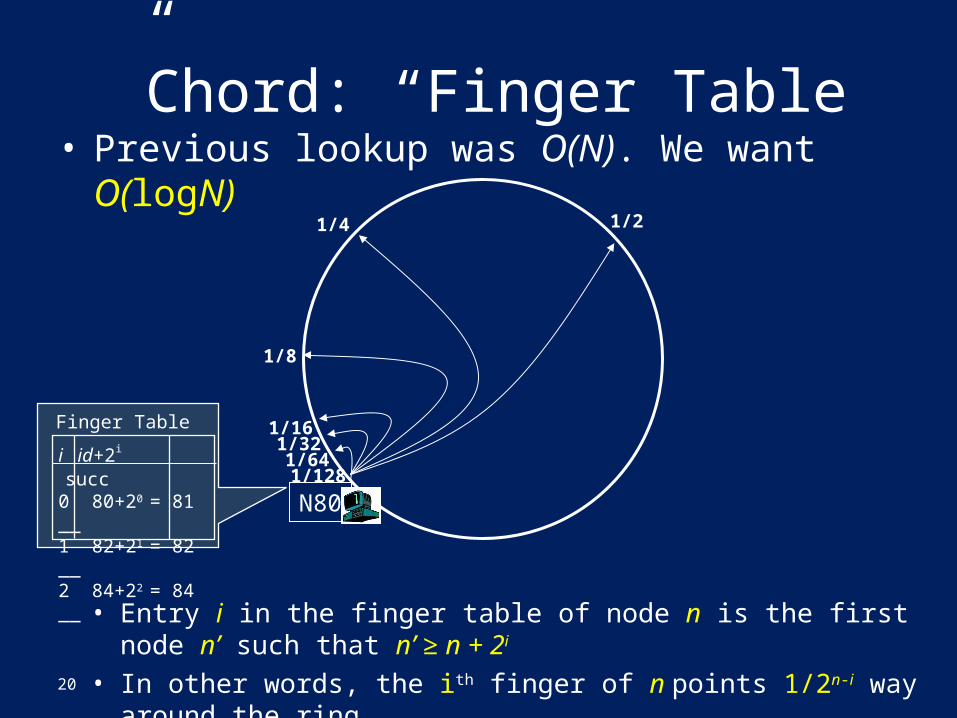
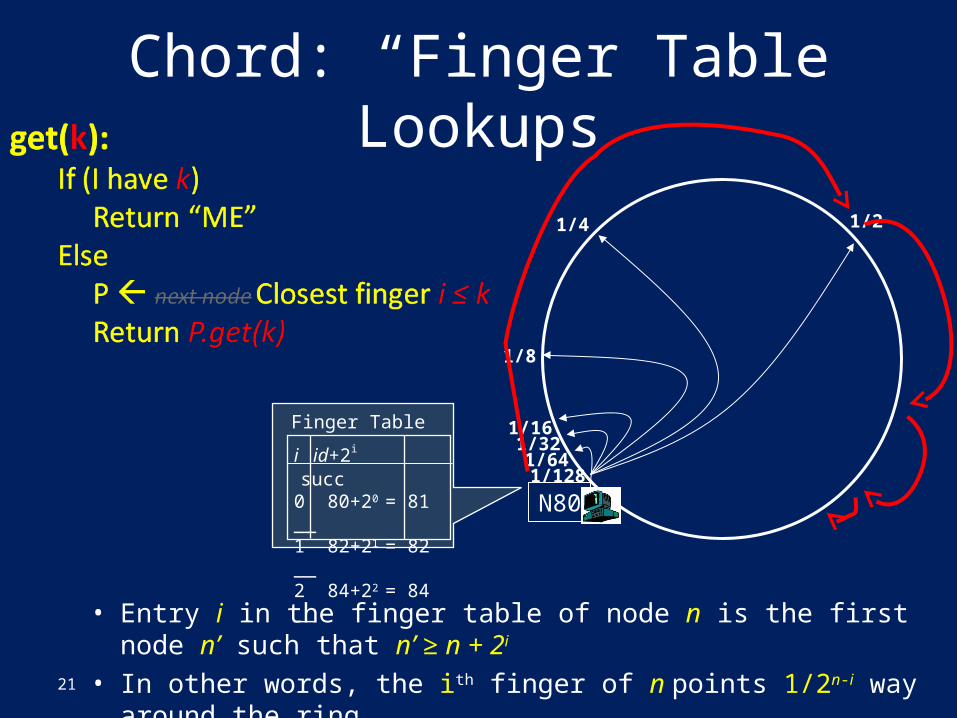
Chord: “Finger Table”• Previous lookup was O(N). We want O(logN)
20
N80
1/21/4
1/8
1/161/321/641/128
• Entry i in the finger table of node n is the first node n’ such that n’ ≥ n + 2i
• In other words, the ith finger of n points 1/2n-i way around the ring
1. Clients A & B handshake2. A: “I have DHT, its on port X”3. B: ping port X of A4. B gets a reply => start adjusting - nodes, rows…
37
Kademlia (KAD)
• Distance between A and B is A XOR B• Nodes are treated as leafs in binary tree• Node’s position in A’s tree is determined by the
longest postfix it shares with A– A’s ID: 010010101– B’s ID: 101000101
38
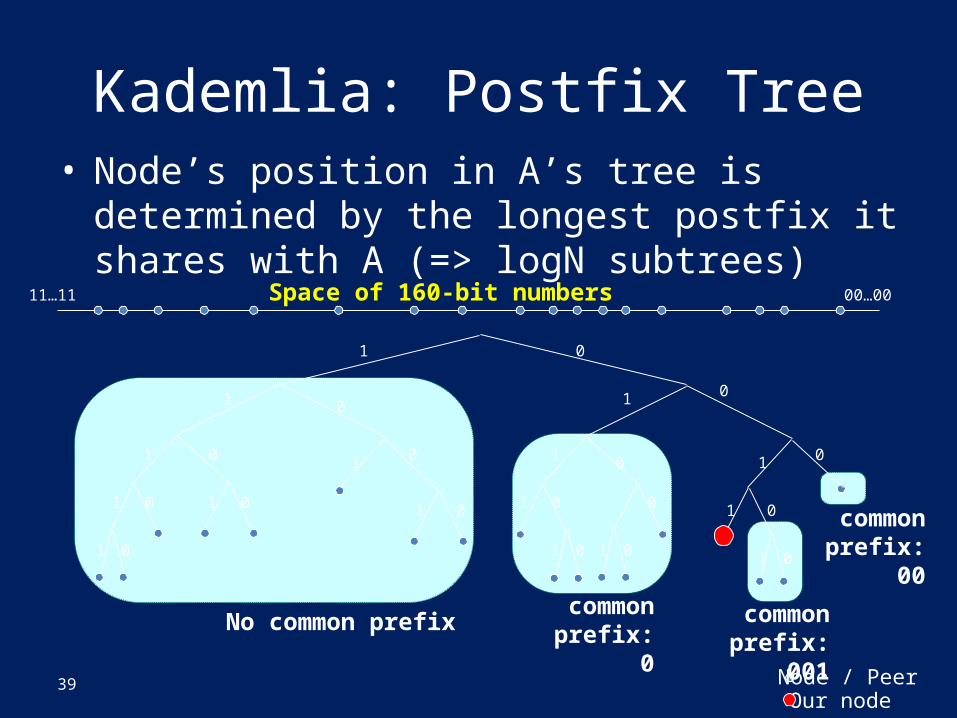
Kademlia: Postfix Tree• Node’s position in A’s tree is determined by the
longest postfix it shares with A (=> logN subtrees)
39 Node / PeerOur node
common prefix: 001
common prefix: 00
common prefix: 0No common prefix
11…11 00…00
1
1
1
1
1
1
11 1
1 1
1
1
11
1
0
0
0
0
0
0
0
0
0
0
0 0
0
0
0
0
0
Space of 160-bit numbers
Kademlia: Lookup
40
11…11 00…00
1
1
1
1
1
1
11 1
1 1
1
1
11
1
0
0
0
0
0
0
0
0
0
0
0 0
0
0
0
0
0
•Consider a query for ID 111010… initiated by node 0011100…
Node / PeerOur node
Kademlia: K-Buckets11…11 00…00
1
1
1
1
1
1
11 1
1 1
1
1
11
1
0
0
0
0
0
0
0
0
0
0
0 0
0
0
0
0
0
`
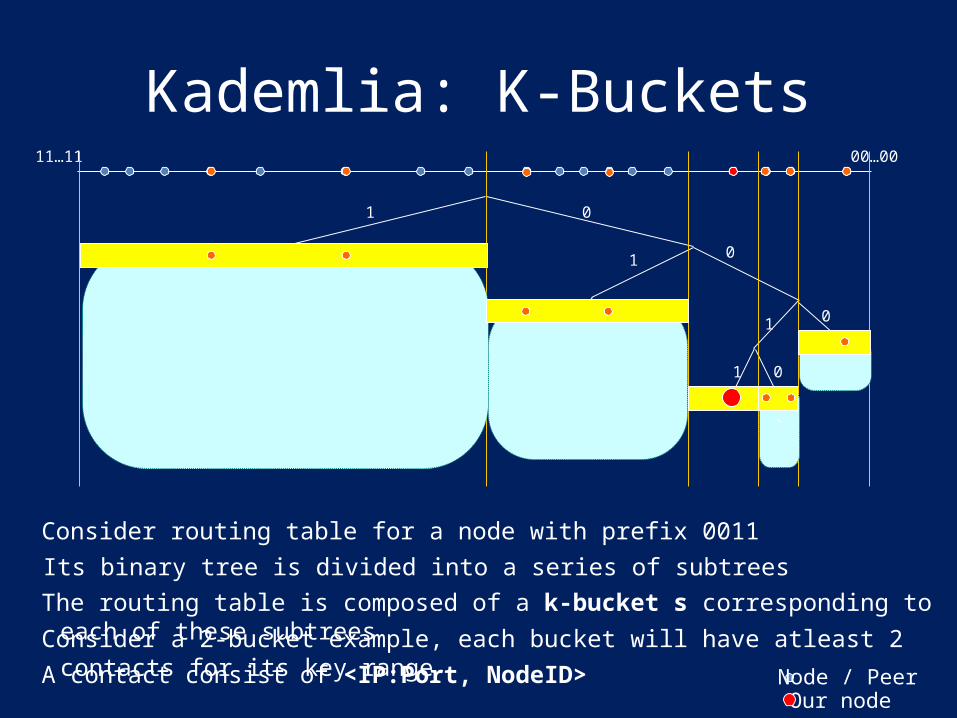
Its binary tree is divided into a series of subtreesConsider routing table for a node with prefix 0011
A contact consist of <IP:Port, NodeID>
The routing table is composed of a k-bucket s corresponding to each of these subtreesConsider a 2-bucket example, each bucket will have atleast 2 contacts for its key range
Node / PeerOur node
Summary
42
1. The Problem
2. Distributed hash tables
(DHT)
3. Chord: a DHT scheme• Geometry• Lookup• Node Joins• Performance
4. Extras
Homework
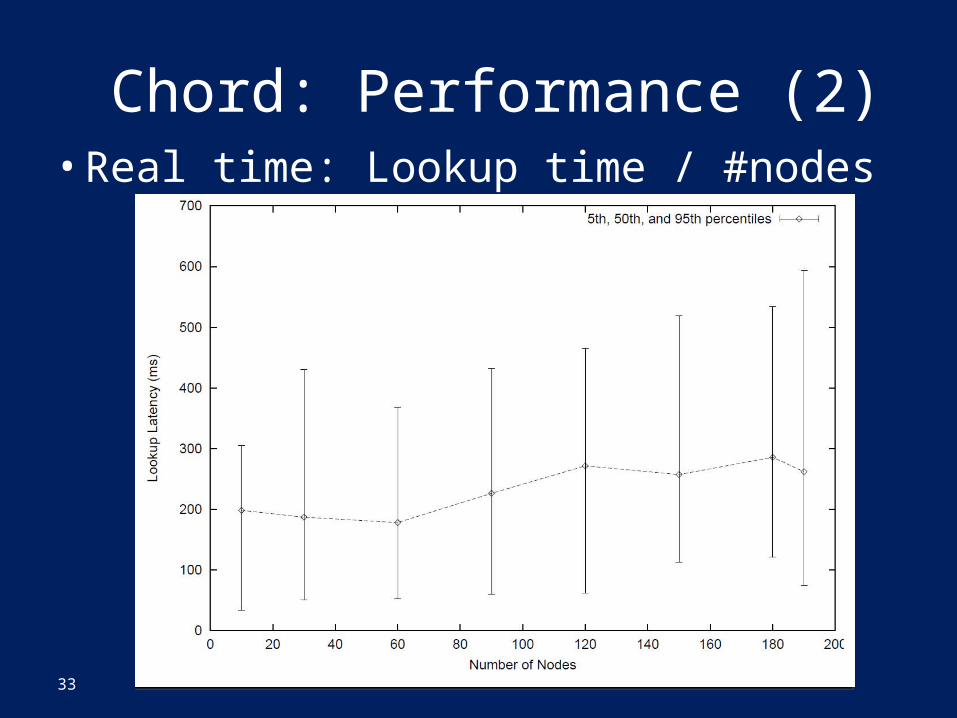
• Load balance is achieved when all Servers in the Chord network are responsible for (roughly) the same amount of keys
• Still, with some probability, one server can be responsible for significantly more keys
• How can we lower the upper bound to the number of keys assigned to a server?