104
Forensics and CS Philip Chan
| Date post: | 01-Jan-2016 |
| Category: |
Documents |
| Upload: | eugenia-summers |
| View: | 225 times |
| Download: | 0 times |

Forensics and CS
Philip Chan

CSI: Crime Scene Investigation
www.cbs.com/shows/csi/
high tech forensics tools
DNA profiling Use as evidence in court cases

DNA
Deoxyribonucleic Acid
Each person is unique in DNA (except for twins)
DNA samples can be collected at crime scenes
About .1% of human DNA varies from person to person

Forensics Analysis
Focus on loci (locations) of the DNA Values at the those loci (DNA profile) are
recorded for comparing DNA samples.

Forensics Analysis
Focus on loci (locations) of the DNA Values at the those loci (DNA profile) are
recorded for comparing DNA samples. Two DNA profiles from the same person have
matching values at all loci.

Forensics Analysis
Focus on loci (locations) of the DNA Values at the those loci (DNA profile) are
recorded for comparing DNA samples. Two DNA profiles from the same person have
matching values at all loci. More or fewer loci are more accurate in
identification? Tradeoffs?

Forensics Analysis
Focus on loci (locations) of the DNA Values at the those loci (DNA profile) are
recorded for comparing DNA samples. Two DNA profiles from the same person have
matching values at all loci. More or fewer loci are more accurate in
identification? Tradeoffs?
FBI uses 13 core loci http://www.cstl.nist.gov/biotech/strbase/fbicore.htm

We do not want to wrongly accuse someone How can we find out how likely another
person has the same DNA profile?

We do not want to wrongly accuse someone How can we find out how likely another
person has the same DNA profile?
How many people are in the world?

We do not want to wrongly accuse someone How can we find out how likely another
person has the same DNA profile?
How many people are in the world?
How low the probability needs to be so that a DNA profile is unique in the world?

We do not want to wrongly accuse someone How can we find out how likely another
person has the same DNA profile?
How many people are in the world?
How low the probability needs to be so that a DNA profile is unique in the world?
Low probability doesn’t mean impossible Just very unlikely

Review of basic probability
Joint probability of two independent events P(A,B) = ?

Review of basic probability
Joint probability of two independent events P(A,B) = P(A) * P(B)
Independent events mean knowing one event does not provide information about the other events
P(Die1=1, Die2=1) = P(Die1=1) * P(Die2=1) = 1/6 * 1/6 = 1/36.

Enumerating the events
1 2 3 4 5 6
1 1,1 1,2 …
2
3
4
5
6
36 events, each is equally likely, so 1/36

Joint probability
P(Die1=even, Die2=6) = ?

Joint probability
P(Die1=even, Die2=6) = 1/2 * 1/6 = 1/12
P(Die1=1, Die2=5, Die3=4) = ?

Joint probability
P(Die1=even, Die2=6) = 1/2 * 1/6 = 1/12
P(Die1=1, Die2=5, Die3=4) = (1/6)3 = 1/216

DNA profile probability
How to estimate?

DNA profile probability
How to estimate?
Assuming loci are independent P(Locus1=value1, Locus2=value2, ...) = P(Locus1=value1) * P(Locus2=value2) * ...

DNA profile probability
How to estimate?
Assuming loci are independent P(Locus1=value1, Locus2=value2, ...) = P(Locus1=value1) * P(Locus2=value2) * ...
How to estimate P(Locus1=value1)?

DNA profile probability
How to estimate?
Assuming loci are independent P(Locus1=value1, Locus2=value2, ...) = P(Locus1=value1) * P(Locus2=value2) * ...
How to estimate P(Locus1=value1)? a random sample of size N from the
population and find out how many people out of N have
value1 at Locus1

Database of DNA profiles
Id Locus1 Locus2 Locus3 … Locus13
A5212
A6921
…

Problem Formulation
Given A sample profile (e.g. collected from the crime
scene) A database of known profiles
Find The probability of the sample profile if it
matches a known profile in the database

Breaking Down the Problem
Find The probability of the sample profile if it matches a
known profile in the database
What are the subproblems?

Breaking Down the Problem
Find The probability of the sample profile if it matches a
known profile in the database
What are the subproblems? Subproblem 1
Find whether the sample profile matches 1a: ? 1b: ?
Subproblem 2 Calculate the probability of the profile

Breaking Down the Problem
Find The probability of the sample profile if it matches a
known profile in the database
What are the subproblems? Subproblem 1
Find whether the sample profile matches 1a: check entries in the database
1b: check loci in each entry
Subproblem 2 Calculate the probability of the profile

Simpler Problem for 1a (very common) Given
an array of integers (e.g. student IDs) an integer (e.g. an ID)
Find whether the integer is in the array
(e.g. whether you can enter your dorm)
int[] directory; // student id’sint id; // to be found
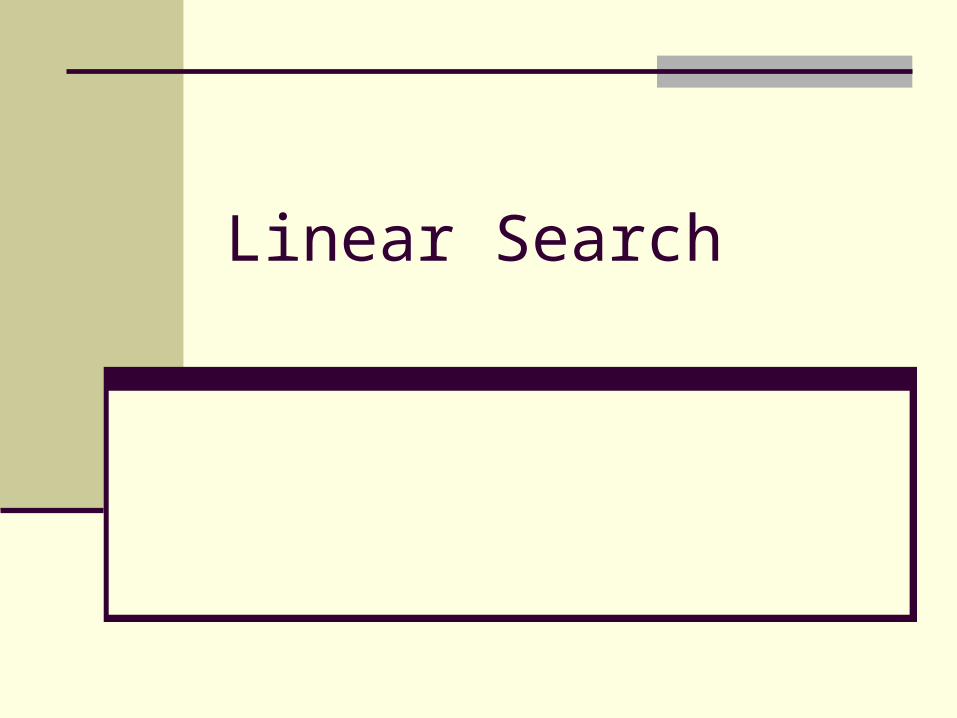
Linear Search

Linear/Sequential Search
Check one by one Stop if you find it Stop if you run out of items to check
Not found

Number of Checks (speed of algorithm) Consider N items in the array
Best-case scenario When does it occur? How many checks?

Number of Checks (speed of algorithm) Consider N items in the array
Best-case scenario When does it occur? How many checks? First item;1 check
Worst-case scenario When does it occur? How many checks?

Number of Checks (speed of algorithm) Consider N items in the array
Best-case scenario When does it occur? How many checks? First item;1 check
Worst-case scenario When does it occur? How many checks? Last item or not there; N checks
Average-case scenario Average of all cases (1 + 2 + … + N) / N = [N(N+1)/2] / N = (N+1)/2

Matching DNA profiles
Each profile has 13 loci Do we always need to check all 13 loci to
decide if a match occurs or not?

Can we do better? Faster algorithm? What if the array is sorted, items are in an
order E.g. a phone book

Binary Search

Binary Search
1. Check the item at midpoint
2. If found, done
3. Otherwise, eliminate half and repeat 1 and 2

Breaking down the problem
While more items and not found in the mid point What are the two subproblems?

Breaking down the problem
While more items and not found in the mid point Eliminate half of the items Determine the mid point

Number of checks (Speed of algorithm) Best-case scenario
When does it occur? How many checks?

Number of checks (Speed of algorithm) Best-case scenario
When does it occur? How many checks? In the middle; 1 check

Number of checks (Speed of algorithm) Best-case scenario
When does it occur? How many checks? In the middle; 1 check
Worst-case scenario When does it occur? How many checks?

Number of checks (Speed of algorithm) Best-case scenario
When does it occur? How many checks? In the middle; 1 check
Worst-case scenario When does it occur? How many checks? Dividing into two halves, half has only one
item ? checks

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1
= [ [ T(N/8) + 1] + 1] + 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1
= [ [ T(N/8) + 1] + 1] + 1
= … any pattern?

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1
= [ [ T(N/8) + 1] + 1] + 1
= …
= T(N/2k) + k

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1
= [ [ T(N/8) + 1] + 1] + 1
= …
= T(N/2k) + k
N/2k gets smaller and eventually becomes 1

Number of checks (Speed of algorithm)T(1) = 1
T(N) = T(N/2) + 1
= [ T(N/4) + 1 ] + 1
= [ [ T(N/8) + 1] + 1] + 1
= …
= T(N/2k) + k
N/2k gets smaller and eventually becomes 1 solve for k

Number of Checks (Speed of Algorithm) N/2k = 1
N = 2k
k = ?

Number of Checks (Speed of Algorithm) N/2k = 1
N = 2k
k = log2N

Number of Checks (Speed of Algorithm) N/2k = 1
N = 2k
k = log2N
T(N) = T(N/2k) + k
= T(1) + log2N
= ? + log2N

Number of Checks (Speed of Algorithm) N/2k = 1
N = 2k
k = log2N
T(N) = T(N/2k) + k
= T(1) + log2N
= 1 + log2N

N (Linear search) vs log N + 1 (Binary search)
N
100 7.6
1,000 11.0
10,000 14.3
100,000 17.6
1,000,000 20.9
10,000,000 24.3
100,000,000 27.6

Before using Binary Search
The array needs to be sorted (in order)

Sorting

Sorting (arranging the items in adesired order) How is the phone book arranged?
Why? Why not arranged by numbers?

Sorting (arranging the items in adesired order) How is the phone book arranged?
Why? Why not arranged by numbers?
Order Alphabetical Low to high numbers DNA profile with 13 loci?

Sorting
Imagine you have a thousand numbers in an array
How would you systemically sort them?

Selection Sort (ascending)
Find/select the smallest item Swap the smallest item with the first item

Selection Sort (ascending)
Find/select the smallest item Swap the smallest item with the first item Find/select the second smallest item Swap the second smallest item with the
second item …

Example
6 7 2 5 1

Example
6 7 2 5 1

Example
6 7 2 5 1
1 7 2 5 6

Example
6 7 2 5 1
1 7 2 5 6
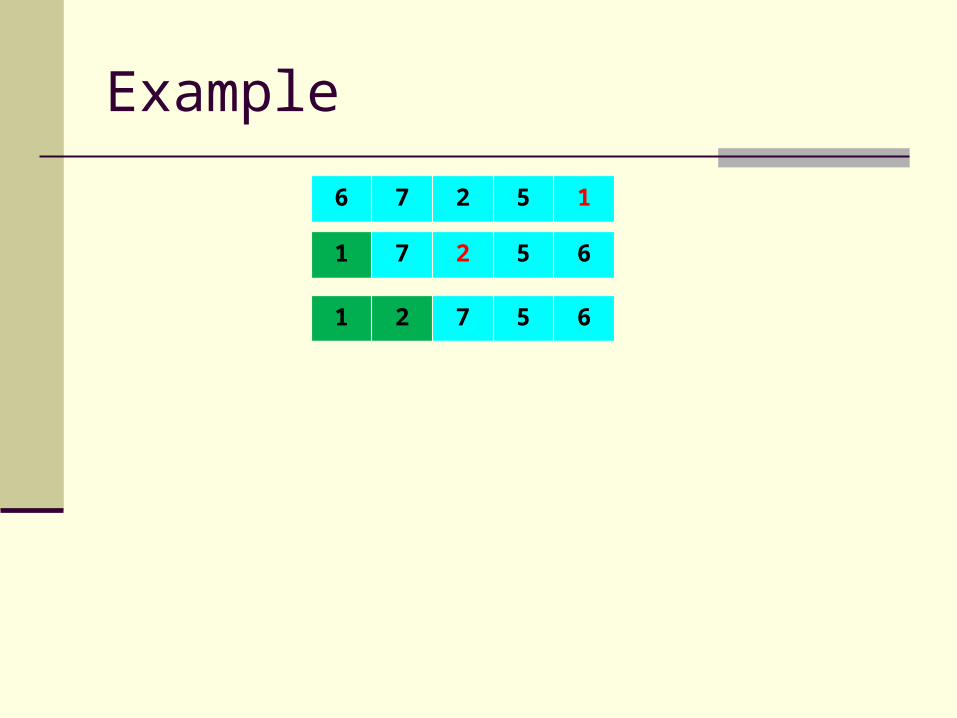
Example
6 7 2 5 1
1 7 2 5 6
1 2 7 5 6
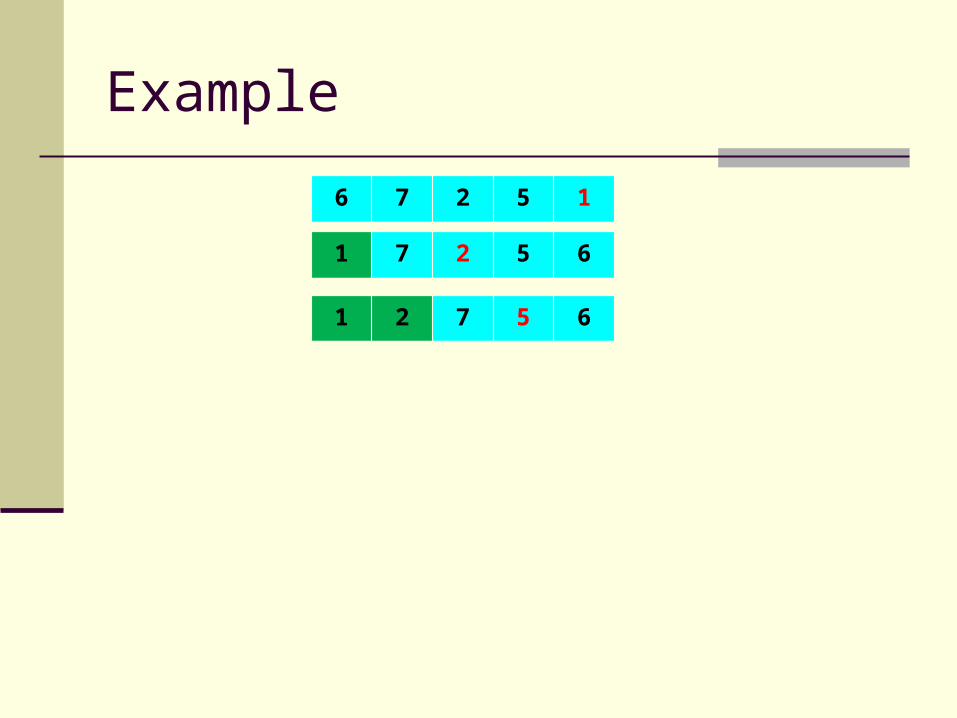
Example
6 7 2 5 1
1 7 2 5 6
1 2 7 5 6

Example
6 7 2 5 1
1 7 2 5 6
1 2 7 5 6
1 2 5 7 6

Example
6 7 2 5 1
1 7 2 5 6
1 2 7 5 6
1 2 5 7 6

Example
6 7 2 5 1
1 7 2 5 6
1 2 7 5 6
1 2 5 7 6
1 2 5 6 7

Breaking down the problem
Get all the items in ascending order Get one item at the wanted position/index
What are the two subproblems?

Breaking down the problem
Get all the items in ascending order Get one item at the wanted position/index
Find the smallest item

Breaking down the problem
Get all the items in ascending order Get one item at the wanted position/index
1. Find the smallest item
2. Swap the smallest item with the item at the wanted position

Algorithm Summary (Selection Sort) For each “desired” position
Between the “desired” position and the end Find the smallest item
Swap the smallest item with the item at the “desired” position

Number of comparisons (Speed of Algorithm) Consider counting
Number of comparisons between array items

Number of comparisons (Speed of Algorithm) Consider counting
Number of comparisons between array items Best-case scenario (least # of comparisons)
When does it occur? How many comparisons?

Number of comparisons (Speed of Algorithm) Consider counting
Number of comparisons between array items Best-case scenario (least # of comparisons)
When does it occur? How many comparisons?
Worst-case scenario (most # of comparisons) When does it occur? How many
comparisons?

Number of comparisons (Speed of Algorithm) Consider counting
Number of comparisons between array items Best-case scenario (least # of comparisons)
When does it occur? How many comparisons?
Worst-case scenario (most # of comparisons) When does it occur? How many
comparisons? Same number of comparisons
For all cases (ie best case = worst case)

Number of comparisons (Speed of Algorithm) To find the smallest item
How many comparisons?

Number of comparisons (Speed of Algorithm) To find the smallest item
How many comparisons? N-1
To find the second smallest item How many comparisons?

Number of comparisons (Speed of Algorithm) To find the smallest item
How many comparisons? N-1
To find the second smallest item How many comparisons? N-2
… Total # of comparisons?

Number of comparisons (Speed of Algorithm) To find the smallest item
How many comparisons? N-1
To find the second smallest item How many comparisons? N-2
… Total # of comparisons
(N-1) + (N-2) + … + 1

Number of comparisons (Speed of Algorithm) To find the smallest item
How many comparisons? N-1
To find the second smallest item How many comparisons? N-2
… Total # of comparisons
(N-1) + (N-2) + … + 1 N(N-1)/2 = (N2 – N)/2

Selection Sort
Not the fastest sorting algorithm Learn faster algorithms in more advanced
courses.

Revisiting Binary Search

Binary Search
While more items and not found in the mid point1. Eliminate half of the items
2. Determine the mid point

Eliminate half of the array
How to specify the focus region? Hint: index/position

Eliminate half of the array
How to specify the focus region? Hint: index/position
Start and end
How to determine if the region has items (is not empty)? with start and end

How to determine if the region has items (is not empty)? with start and end
Start <= end

How do we adjust start and end?

How do we adjust start and end?
What are the two different cases?

How do we adjust start and end?
What are the two different cases? Item is before the middle item
Item is after the middle item

How do we adjust start and end?
What are the two different cases? Item is before the middle item
Start: End:
Item is after the middle item

How do we adjust start and end?
What are the two different cases? Item is before the middle item
Start: no change End: position before the mid point
Item is after the middle item

How do we adjust start and end?
What are the two different cases? Item is before the middle item
Start: no change End: position before the mid point
Item is after the middle item Start: End:

How do we adjust start and end?
What are the two different cases? Item is before the middle item
Start: no change End: position before the mid point
Item is after the middle item Start: position after the mid point End: no change

How to determine the mid point?
with start and end?

How to determine the mid point?
with start and end (start + end) / 2
Integer division will eliminate the fractional part

Algorithm Summary
1. Initialize start, end, and mid point (I)
2. While region has items and item is not at the mid point ( C )a) Eliminate half of the items by adjusting start
or end (U)
b) Update the mid point (U)
3. If region has items Position is mid point
else Position is -1

Overall Summary

Overall Summary
DNA samples from crime scene Identify people using known DNA profiles
If there is a match estimate probability of DNA profile
Matching a sample to known DNA profiles Linear/sequential search [N checks] Binary search [log2N + 1 checks]
Faster but needs sorted data/profiles Selection Sort [(N2 – N)/2 comparisons]

















