124 IEEE TRANSACTIONS ON NANOBIOSCIENCE, VOL. 13, NO. 2, JUNE 2014
Genealogical-Based Method for Multiple OntologySelf-Extension in MeSHYu-Wen Guo, Yi-Tsung Tang, and Hung-Yu Kao
Abstract—During the last decade, the advent of Ontologies usedfor biomedical annotation has had a deep impact on life science.MeSH is a well-known Ontology for the purpose of indexingjournal articles in PubMed, improving literature searching onmulti-domain topics. Since the explosion of data growth in recentyears, there are new terms, concepts that weed through the oldand bring forth the new. Automatically extending sets of existingterms will enable bio-curators to systematically improve text-based ontologies level by level. However, most of the relatedtechniques which apply symbolic patterns based on a literaturecorpus tend to focus on more general but not specific partsof the ontology. Therefore, in this work, we present a novelmethod for utilizing genealogical information from Ontology itselfto find suitable siblings for ontology extension. Based on thebreadth and depth dimensions, the sibling generation stage andpruning strategy are proposed in our approach. As a result, on theaverage, the precision of the genealogical-based method achieved0.5, with the best 0.83 performance of category “Organisms.” Wealso achieve average precision 0.69 of 229 new terms in MeSH2013 version.
Index Terms—Genealogical-based method, MeSH ontology, on-tology self-extension.
I. INTRODUCTION
D URING THE last decade, the advent of controlled vo-cabularies used for biomedical annotation has had a deep
impact on life science. Howe et al. [14], [30] indicate thatmany successful vocabularies have been taken up by biologiststhemselves as a means to consistently annotate features fromgenotype to phenotype. A single data type might not be pow-erful enough to predict the disease causing genes accuratelywhile the use of several complementary data sources allowmuch more accurate predictions. Therefore, the controlledvocabulary is a prerequisite for the analysis of high-throughputscreen and the cross-referencing between databases of differentmodel organisms and the heterogeneous data [7], [29]. Z. Xianget al. [1], [12], [28] show that biomedical ontologies can beused to significantly improve literature searching on multiple
Manuscript received April 06, 2014; accepted April 06, 2014. Date of currentversion May 29, 2014. Asterisk indicates corresponding author.Y.-W. Guo is with the Institute ofMedical Informatics, National Cheng Kung
University, 701 Tainan, Taiwan (e-mail: [email protected]).Y.-T. Tang is with the da Vinci Innovation Laboratory/Core Technology
Center (CTC), ASUSTeK COMPUTER INC., 112529 Taipei, Taiwan (e-mail:[email protected]).*H.-Y. Kao is with the Department of Computer Science and Information
Engineering, National Cheng Kung University, 701 Tainan, Taiwan (e-mail:[email protected]).Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org.Digital Object Identifier 10.1109/TNB.2014.2320413
Fig. 1. The number of articles in PubMed from 1980 to 2012.
domains. Take MeSH (Medical Subject Heading)1 as a suc-cessful example, it’s an ontology which maintains good qualityof literature searching in PubMed. MeSH serves as a controlledvocabulary which its purpose is to index journal articles inPubMed for improving semantically related search results. Forinstance, MeSH can efficiently helps query expansion [16],[17] for literature searching and has been reported that it isbeneficial for the precision of the retrieved results.On the other hand, the field of biomedicine has seen a data
explosion recently. For instance, Fig. 1 shows that PubMedhas almost tripled its growth rate in the past 10 years. Newconcepts are constantly emerging while old concepts are in astate of flux [5], [14]. Leading to the modification of the usageof terminology2. Therefore, to keep up with this changing in-formation, ontologies must be revised and existing terms needto be enriched with definitions, cross-references and additionalproperties.However, maintaining ontologies is often a slow, tedious, and
error-prone process [3], [6]. For example, the National Libraryof Medicine has paid approximately $6 million per year for theongoing development of SNOMED-CT since 2007, after an ini-tial investment of $32.4 million in 20033. Since ontologies aremanually curated, curators must read considerable articles todecide which old term needs to be revised and the locationsthat suit the new adding terms. For example, an interest in onespecies of a given genus, may lead to interest in some otherspecies or even that entire genus4.To mitigate this costly process, text mining can be employed
to enhance the efficiency of ontology revising in a semi-auto-mated or automated fashion. Among the variety of ontology
GUO et al.: GENEALOGICAL-BASED METHOD FOR MULTIPLE ONTOLOGY SELF-EXTENSION IN MESH 125
Fig. 2. Sibling generation example.
learning methods proposed in the past, mainly symbolic basedrelationship extraction methods based on the literature corpusare proposed [15]. However, based on a given literature corpus,the symbolic based approaches tend to focus on more generalbut not specific part of the ontology due to some common char-acteristics as follows:• Low recall of the symbolic based approaches. For ex-ample, out of 8.6 million words in the encyclopedia,Hearst [13] obtain 7076 sentences that contain the pat-tern “such as” from which only 330 unique parent-childrelationships were identified.
• The specific parent-child relationships often have smallnumber of related articles. The specific term on a lowerlevel in ontology has a fewer number of related articlescompared to the general term which on higher level. Asmall corpus worsens the recall using symbolic-based re-lationship extraction methods.
• The long context distance between specific parent term andchild term. Taking high-level terms “scapula” and “glenoidcavity” for instance, which level equals to 5 and 6 respec-tively. The context distance between parent term “scapula”and child term “glenoid cavity” is about 30 to 50 unit ofwords in the search result, leading to the hardness of pat-tern extraction.
Therefore, we expect that if there is a self-extension methodwhich can provide easily accessible and precise information forconcepts without using literature corpus. We have found thatthere is rich and useful information existing in ontology on hand.For example, in MeSH ontology, there are more than 53% termsappearing on more than one location while different locationshave diverse meanings. This gives us the opportunities to utilizethe information from existing ontology for revision.In this article, we focus on the subject main headings to gen-
erate the siblings of a given seed term by extending the hi-erarchical (parent-child) relationships. For example, as shownin Fig. 2, an ontology that already includes the term “Aceto-bacter” (which is_a “Acetobacteraceae”) could be extended to“Acidiphilium,” “Gluconacetobacter,” and “Gluconobacter” byautomatically proposing more terms with the same parent term.In our approach, we present a self-extension method to find
suitable siblings of seed term, using the genealogical informa-tion which describing the family of a concept. For an instance, toa term “apple,” if we know that “mango” and “orange” is the sib-ling information of “apple,” then we can infer that “apple” maybe a kind of fruit. As another example, if we know “smartphone”is a parent term of “apple,” then we can conclude that “apple”may be similar to “iPhone.” Therefore, the Genealogy of on-
Fig. 3. The genealogical dimensions of a concept.
tology such as breadth dimension and depth dimension are uti-lized in our method. An example is shown in Fig. 3, for breadthdimension, it characterizes the “broadness “of a concept, indi-cating the range of topics it covers, for instance, “smartphone”covers the concept “apple.” On the other hand, the depth dimen-sion characterizes the “categorization” of a concept, a conceptwith distinct ancestors will has diverse meanings. For instance,the concept “apple” will have different meanings if it belongs to“smartphone” and “fruit.” Here, based on the breadth and depthdimensions, a genealogical-based model is proposed for the sib-ling prediction.The rest of this paper is organized as follows. Section II is
a review of the related works. Section III describes the mainidea and methodology for our approach. Then, the results andanalyses are presented following Section IV. Finally, con-clusions and discussions are made for the result and furtherresearch.
II. RELATED WORK
A. MeSH Ontology
MeSH Ontology is a comprehensive controlled vocabularyfor the purpose of indexing journal articles in PubMed. Thereare four major components5 to the MeSH ontology: SubjectMain Headings (MHs), subheadings, Supplementary ConceptRecords (SCRs), and entry terms. Subject MHs are the majorcomponent of MeSH ontology. In MEDLINE/PubMed, everyjournal article is indexed with about 10 to 20 subject headingsmanually, with some of them designated as major and markedwith an asterisk, indicating the article’s major topics. There are26 853 MHs in MeSH 2013. In this article, we focus on theMH part which is the major and basic component in MeSH On-tology. MHs are arranged by parent-child relationships in a hi-erarchical tree structure that permits searching at various levelsof specificity6. At the most general level is very broad head-ings such as “Anatomy” or “Mental Disorders.” More specificheadings are found at more narrow levels of the twelve-level hi-erarchy, such as “Ankle” and “Conduct Disorder.” A MH mayappear at several locations in the hierarchical tree and every lo-cation has a unique systematic concept. Furthermore, MH con-tains 16 categories: A) Anatomy, B) Organisms, C) Diseases, D)
5MeSH Record Types : http://www.nlm.nih.gov/mesh/intro_record_types.html6Relationships in MeSH : http://www.nlm.nih.gov/mesh/meshrels.html
126 IEEE TRANSACTIONS ON NANOBIOSCIENCE, VOL. 13, NO. 2, JUNE 2014
Chemical and Drugs, E) Analytical, Diagnostic and TherapeuticTechniques and Equipment, F) Psychiatry and Psychology, G)Biological Sciences, H) Physical Sciences, I) Anthropology, Ed-ucation, Sociology and Social Phenomena, J) Technology andFood and Beverages, K) Humanities, L) Information Science,M) Persons, N) Health Care, V) Publication Characteristics, andZ) Geographic Locations. Each category has different numberof MHs, locations and levels. By the way, because categories M,V, Z are not thoroughly biomedical-related, so we ignore themin our work.
B. Related Work for Parent-Child Relationship Generation
Generally speaking, text mining techniques for ontology ex-tension can be categorized into the symbolic based approach andthe statistical based approach based on a given corpus [15]. Inthis section we briefly review the related work as follows.The symbolic based approach utilizes lexico-syntactic pattern
(LSP) and linguistic information to extract information fromtext. Hearst [13] simply uses the simple pattern “such as” to ex-tract parent-child relationships, but acknowledged low recall asan inherent problemwith this method. Caraballo [8] consider thecoordination structure of nouns, such as conjunction and appos-itives to extract parent-child relationships. Cederberg and Wid-dows [9] based on two above-mentioned methods, they used agraph-based model of noun-noun similarity to infer more candi-date relationships from coordination structures. Rindflesch et al.[23] use structured domain knowledge such as the SPECIALISTlexicon and UMLS semantic network to capture semantic as-sociations in free-text biomedical documents. Riloff [22] fur-ther uses a bootstrappingmethod for generating LSPs iterativelyfrom untagged text. For utilizing the linguistic information, Ve-lardi [25] used the head matching heuristic rule for child termdiscovery. Morin et al. [6], [19] tried to add parent-child re-lationships by modifier information, mapping one word termsto multi-word terms. Recently, Wächter T. and Schroeder M[27] developed the Dresden Ontology Generator for DirectedAcyclic Graphs (DOG4DAG) [26], a system which supports thecreation and extension of ontologies by semi-automatically gen-erating terms, definitions and parent child relationships from atext corpus. It generates terms by identifying statistically sig-nificant noun phrases in text. DOG4DAG is seamlessly inte-grated into OBO-Edit [10]. In 2012, they [11] further propose amethod to extend theMeSH ontology by discovering new terms.They extract siblings by exploiting the structure of HTML doc-uments and some simple patterns. On the other hand, the sta-tistical based approaches often employ different linguistic prin-ciples and features for statistical measurements to extract se-mantic information. Alterovitz et al. [4], [21], [24] uses infor-mation theory [18] to automatically organize the structure ofontoogy and optimize the distribution of the information withinit. Agirre [2] view the parent-child relationship extraction as aclassification problem and employ the topic signature to find theclosest candidate to seed.
III. METHOD
In MeSH ontology, there are about 53% terms that appearrepeatedly among categories. Moreover, MHs that appear re-peatedly in the ontology are mainly distributed on level 4 to 12.
Fig. 4. Overview of the sibling generation and ranking pipeline.
Otherwise, for the most part of the MHs which appear once inthe ontology are distributed on level 1 to 5. This tells us that theMHs that appear repeatedly in the ontology are more specificthan that of appear once. Therefore, we start with the MH thatappeared repeatedly in MeSH ontology as our seed team andpropose our method.
A. The Genealogical Dimensions of Ontology for ModelingConcepts
For ontology, it mainly symbolizes a concept by two ge-nealogical dimensions: the breadth dimension and the depthdimension. The breadth dimension indicates the range of topicsit covers. On the other hand, the depth dimension characterizesthe “categorization” of a concept, a concept with distinct an-cestors will has diverse meanings. In this paper, we utilize thesibling and parent information to model a concept. The siblinginformation represents the breadth of a concept while parentinformation represents the depth.
B. Genealogical-Based Method
Based on the breadth and depth dimension of a concept, wepropose the genealogical-based method for Ontology Self-ex-tension without using literature corpus. The pipeline of our ap-proach is as Fig. 4. First, given a seed term that appears repeat-edly in the ontology. Next, we utilize the genealogical-basedmodel for the sibling prediction. On the earlier stage, we applythe breadth-based sibling generation to generate candidate sib-lings. On the later stage, pruning strategy is designed for rankingand filtering the candidate sibling list. Finally, a candidate sib-ling list is produced.1) Sibling Generation(SG): From our observation of the
node that has repeated MHs, 88.9% nodes are sibling terms andonly 25.2% nodes are parent terms. This tells us that the breadthof the concept provides more extensive information comparedto the depth. In this way, we start with breadth-based SG.An intuitive method is applied that we obtain candidate sib-
lings by searched seed child term which occurs on other loca-tions. For example, let denote the parent-child pair withparent term and child term , and
. indicates a child term on location
GUO et al.: GENEALOGICAL-BASED METHOD FOR MULTIPLE ONTOLOGY SELF-EXTENSION IN MESH 127
Fig. 5. Breadth-based sibling generation.
Fig. 6. Depth-based sibling generation.
. As shown in Fig. 5, given a seed term , we find a set ofby and .
2) Pruning Strategy:Pruning Strategy_1: After the stage of sibling generation,
we are concerned about the precision of the candidate siblinglist. Here, we initially utilize the information from the parentterm of seed to filter the candidate siblings from breadth-basedSG. The pruning strategy_1 is described as follow. First, wepropose a depth-based SG which generates candidate siblingsby parent information.We obtain candidate siblings by searchedthe parent of seedwhich occurs on other tree numbers. As shownin Fig. 6, given a seed term and its parent term , we finda set of by and .Finally, we intersect the candidates from depth-based SG andbreadth-based SG.
Pruning Strategy_2: Furthermore, we address a breadth-based and depth-based pruning strategy which based on ge-nealogical dimensions of ontology as follows.
Breadth-Based Pruning: From the point of view of breadthdimension in ontology, we consider that the “meaning” of acandidate which only has the sibling relationship with seed ismore similar to the seed. Therefore, a candidate should haveless strength with seed term if it has different siblings on theother locations in comparison to candidate list. Based on thisargument, a breadth-based pruning way is proposed. An ex-ample is exhibited in Fig. 7. First, for candidate sibling , wesearch all the location of , . And the sibling of eachare then merged by removing redundant terms. Then we get aset of . Second, we charac-terize the strength between seed term and by utilized Jac-card similarity coefficient. As (1), we calculate the similaritybetween and the candidate sibling set of , where
. Besides, candidate hasthe highest strength with seed term because it doesn’t have any
Fig. 7. Pruning strategy_2.
diverse siblings on the other locations compared to candidatelist.
(1)
Depth-Based Pruning: In view of the depth dimension inontology, for two concepts, their meanings will be diverse whenthey have different parent terms. Otherwise, they will be sim-ilar by having same parent terms. But in MeSH, only 25.2%nodes which have repeated MHs are parent, the way to mea-sure the similarity of two concepts that we discussed abovewill result in exactly the same similarity value. To tackle thisproblem, some authors [3], [20] applied edge-counting mea-sures to the ontology such as SNOMED CT. Here, an intu-itive edge-counting of depth-based pruning way is addressed byapplying the parent term of seed and the parent term of can-didate. If a seed term and a candidate have the same parentterm, then we set the similarity value equals to 1, otherwise,an edge-counting measure is utilized. An example is exhibitedin Fig. 7.
(2)
For candidate sibling , we search , the term of appear onthe location . Then we get a set of .Second, we characterize the similarity between seed termand by employed the shortest path between and
.
IV. EXPERIMENTS
A. Evaluation Criterions
For the purpose of evaluation, we investigate the micro-av-erage precision (3), recall (4) and F-measure (5) to evaluate ourperformance of the seeds.
(3)
128 IEEE TRANSACTIONS ON NANOBIOSCIENCE, VOL. 13, NO. 2, JUNE 2014
Fig. 8. Four groups of the F-measure of breadth-based SG.
(4)
(5)
B. Results
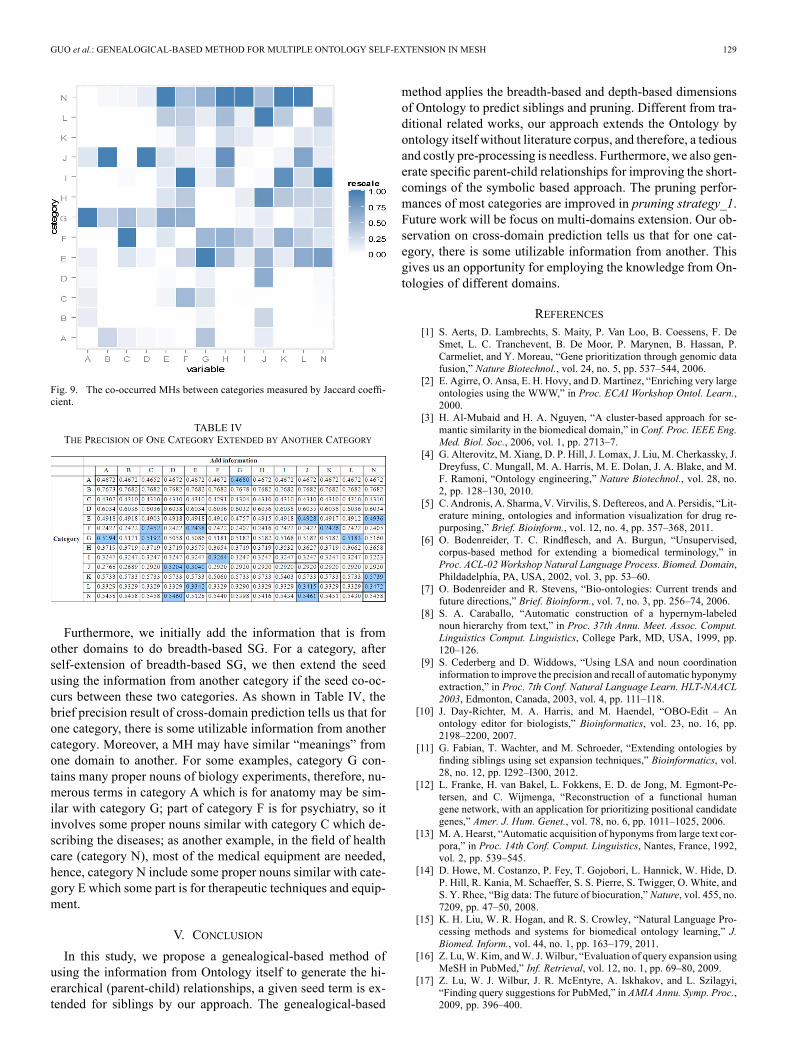
Fig. 8 shows that the performance of breadth-based SG can besimply divided into four groups: First, for category B, breadthinformation of the concept is useful. Second, for category A, C,D, E, G, N, breadth information provides benefit to half of thetarget. Third, for category K, the performance is more moderateof the target.On the other hand, for the Pruning strategy_1, the perfor-
mance doesn’t receive more benefits from depth-based SGfiltering. Here, we analyze the result and found some reasonsas follows: first, in the true positive cases, the prediction ofbreadth-based SG is the subset of depth-based SG. Second, inthe false negative cases, most of the parent term of seed onlyappear once in ontology or it’s a leaf when it occurs on otherlocations, so there is no any information from the parent. Inconclusion, the improvement from depth-based SG filtering islimited.To make comparisons, we list the results of each method and
our approaches that calculated by precision, recall and F-mea-sure. Table I shows the precision of each method, the pruningstrategy_1 performed the best performance that achieved 0.50on the average. This indicates that the parent term brings usefulinformation. Furthermore, for category B, F, J, we have im-proved the prediction by pruning strategy_2, with the best 0.83performance of category “Organisms.” Otherwise, as shown inTable II, because our pruning strategy is for the purpose of
TABLE ITHE PRECISION OF EACH CATEGORY
TABLE IITHE RECALL OF EACH CATEGORY
TABLE IIITHE AVERAGE PERFORMANCE OF EACH METHOD TO NEWMHS IN MESH 2013
improving the precision, we got the lower recall of pruningstrategy_1 and pruning strategy_2.On the other hand, we further analyze the new term of MeSH
ontology 2013 version. Out of 405 new MHs in 2013 version,there are 229 terms appear repeatedly which to be our seed termsand test targets. As shown in Table III, on the average, pruningstrategy_1 get the best performance of precision and F-measure.This said that our method is useful to new term extension inontology.To investigate whether the information from other domains
could be accessed and increase the performance of predictions,we firstly analyze the global distribution of MH in MeSH On-tology to see the commonness between each two categories. Thecommon information between two categories is calculated byco-occur MHs through Jaccard coefficient. We initially set thevalue of a category to itself equal to zero for manifesting theothers. As shown in Fig. 9, for some categories, the common-ness between them is very clear, e.g., categories A and G.
GUO et al.: GENEALOGICAL-BASED METHOD FOR MULTIPLE ONTOLOGY SELF-EXTENSION IN MESH 129
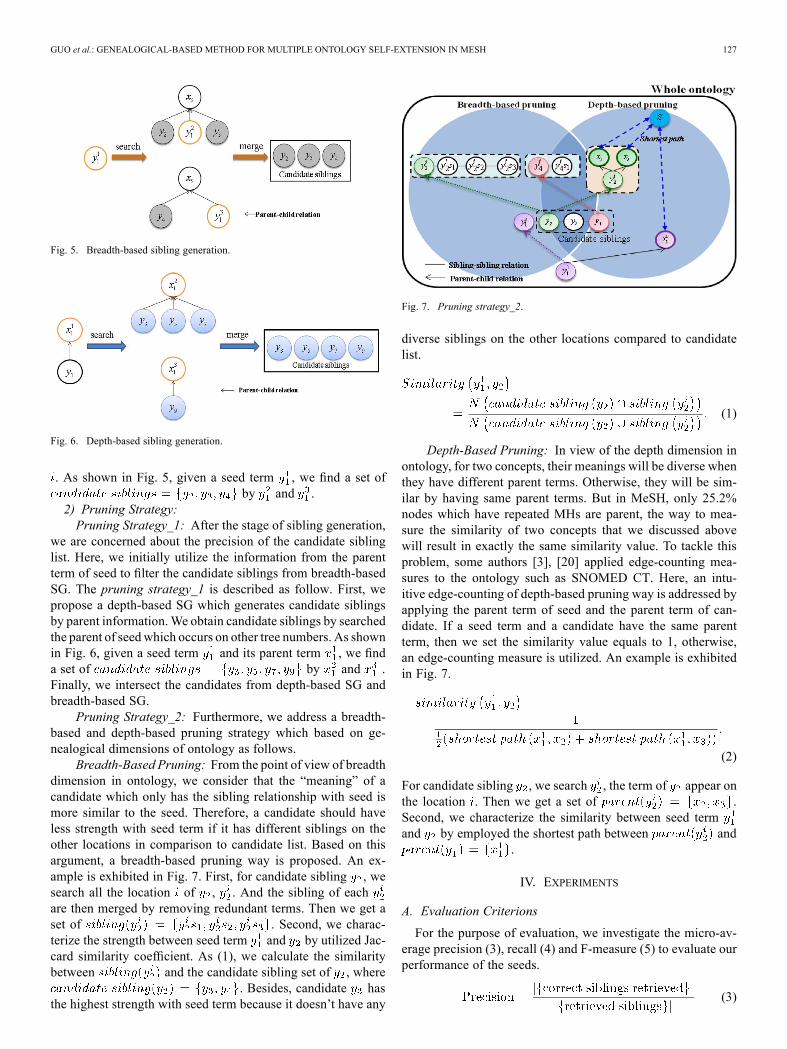
Fig. 9. The co-occurred MHs between categories measured by Jaccard coeffi-cient.
TABLE IVTHE PRECISION OF ONE CATEGORY EXTENDED BY ANOTHER CATEGORY
Furthermore, we initially add the information that is fromother domains to do breadth-based SG. For a category, afterself-extension of breadth-based SG, we then extend the seedusing the information from another category if the seed co-oc-curs between these two categories. As shown in Table IV, thebrief precision result of cross-domain prediction tells us that forone category, there is some utilizable information from anothercategory. Moreover, a MH may have similar “meanings” fromone domain to another. For some examples, category G con-tains many proper nouns of biology experiments, therefore, nu-merous terms in category A which is for anatomy may be sim-ilar with category G; part of category F is for psychiatry, so itinvolves some proper nouns similar with category C which de-scribing the diseases; as another example, in the field of healthcare (category N), most of the medical equipment are needed,hence, category N include some proper nouns similar with cate-gory E which some part is for therapeutic techniques and equip-ment.
V. CONCLUSION
In this study, we propose a genealogical-based method ofusing the information from Ontology itself to generate the hi-erarchical (parent-child) relationships, a given seed term is ex-tended for siblings by our approach. The genealogical-based
method applies the breadth-based and depth-based dimensionsof Ontology to predict siblings and pruning. Different from tra-ditional related works, our approach extends the Ontology byontology itself without literature corpus, and therefore, a tediousand costly pre-processing is needless. Furthermore, we also gen-erate specific parent-child relationships for improving the short-comings of the symbolic based approach. The pruning perfor-mances of most categories are improved in pruning strategy_1.Future work will be focus on multi-domains extension. Our ob-servation on cross-domain prediction tells us that for one cat-egory, there is some utilizable information from another. Thisgives us an opportunity for employing the knowledge from On-tologies of different domains.
REFERENCES[1] S. Aerts, D. Lambrechts, S. Maity, P. Van Loo, B. Coessens, F. De
Smet, L. C. Tranchevent, B. De Moor, P. Marynen, B. Hassan, P.Carmeliet, and Y. Moreau, “Gene prioritization through genomic datafusion,” Nature Biotechnol., vol. 24, no. 5, pp. 537–544, 2006.
[2] E. Agirre, O. Ansa, E. H. Hovy, and D.Martinez, “Enriching very largeontologies using the WWW,” in Proc. ECAI Workshop Ontol. Learn.,2000.
[3] H. Al-Mubaid and H. A. Nguyen, “A cluster-based approach for se-mantic similarity in the biomedical domain,” in Conf. Proc. IEEE Eng.Med. Biol. Soc., 2006, vol. 1, pp. 2713–7.
[4] G. Alterovitz, M. Xiang, D. P. Hill, J. Lomax, J. Liu, M. Cherkassky, J.Dreyfuss, C. Mungall, M. A. Harris, M. E. Dolan, J. A. Blake, and M.F. Ramoni, “Ontology engineering,” Nature Biotechnol., vol. 28, no.2, pp. 128–130, 2010.
[5] C. Andronis, A. Sharma, V. Virvilis, S. Deftereos, and A. Persidis, “Lit-erature mining, ontologies and information visualization for drug re-purposing,” Brief. Bioinform., vol. 12, no. 4, pp. 357–368, 2011.
[6] O. Bodenreider, T. C. Rindflesch, and A. Burgun, “Unsupervised,corpus-based method for extending a biomedical terminology,” inProc. ACL-02 Workshop Natural Language Process. Biomed. Domain,Phildadelphia, PA, USA, 2002, vol. 3, pp. 53–60.
[7] O. Bodenreider and R. Stevens, “Bio-ontologies: Current trends andfuture directions,” Brief. Bioinform., vol. 7, no. 3, pp. 256–74, 2006.
[8] S. A. Caraballo, “Automatic construction of a hypernym-labelednoun hierarchy from text,” in Proc. 37th Annu. Meet. Assoc. Comput.Linguistics Comput. Linguistics, College Park, MD, USA, 1999, pp.120–126.
[9] S. Cederberg and D. Widdows, “Using LSA and noun coordinationinformation to improve the precision and recall of automatic hyponymyextraction,” in Proc. 7th Conf. Natural Language Learn. HLT-NAACL2003, Edmonton, Canada, 2003, vol. 4, pp. 111–118.
[10] J. Day-Richter, M. A. Harris, and M. Haendel, “OBO-Edit – Anontology editor for biologists,” Bioinformatics, vol. 23, no. 16, pp.2198–2200, 2007.
[11] G. Fabian, T. Wachter, and M. Schroeder, “Extending ontologies byfinding siblings using set expansion techniques,” Bioinformatics, vol.28, no. 12, pp. I292–I300, 2012.
[12] L. Franke, H. van Bakel, L. Fokkens, E. D. de Jong, M. Egmont-Pe-tersen, and C. Wijmenga, “Reconstruction of a functional humangene network, with an application for prioritizing positional candidategenes,” Amer. J. Hum. Genet., vol. 78, no. 6, pp. 1011–1025, 2006.
[13] M. A. Hearst, “Automatic acquisition of hyponyms from large text cor-pora,” in Proc. 14th Conf. Comput. Linguistics, Nantes, France, 1992,vol. 2, pp. 539–545.
[14] D. Howe, M. Costanzo, P. Fey, T. Gojobori, L. Hannick, W. Hide, D.P. Hill, R. Kania, M. Schaeffer, S. S. Pierre, S. Twigger, O. White, andS. Y. Rhee, “Big data: The future of biocuration,” Nature, vol. 455, no.7209, pp. 47–50, 2008.
[15] K. H. Liu, W. R. Hogan, and R. S. Crowley, “Natural Language Pro-cessing methods and systems for biomedical ontology learning,” J.Biomed. Inform., vol. 44, no. 1, pp. 163–179, 2011.
[16] Z. Lu,W. Kim, andW. J.Wilbur, “Evaluation of query expansion usingMeSH in PubMed,” Inf. Retrieval, vol. 12, no. 1, pp. 69–80, 2009.
[17] Z. Lu, W. J. Wilbur, J. R. McEntyre, A. Iskhakov, and L. Szilagyi,“Finding query suggestions for PubMed,” in AMIA Annu. Symp. Proc.,2009, pp. 396–400.
130 IEEE TRANSACTIONS ON NANOBIOSCIENCE, VOL. 13, NO. 2, JUNE 2014
[18] D. J. C. MacKay, Information Theory, Inference and Learning Algo-rithms. Cambridge, U.K.: Cambridge Univ. Press, 2002.
[19] E. J. Morin and Christian, “Automatic acquisition and expansion ofhypernym links,” Comput. Humanities, vol. 38, no. 4, p. 363, Nov.2004.
[20] T. Pedersen, S. V. S. Pakhomov, S. Patwardhan, and C. G. Chute,“Measures of semantic similarity and relatedness in the biomedical do-main,” J. Biomed. Inform., vol. 40, no. 3, pp. 288–299, 2007.
[21] K.-S. C. Pum-Mo Ryu, “Measuring the specificity of terms for au-tomatic hierarchy construction,” in Proc. Workshop Ontol. LearningPopulation 16th Gen. Eur. Conf. Artif. Intell., Valencia, Spain, 2004.
[22] E. Riloff, “Automatically generating extraction patterns from untaggedtext,” in Proc. 13th National Conf. Artif. Intell./8th Innov. Appl. Artif.Intell. Conf., 1996, vol. 1 and 2, pp. 1044–1049.
[23] T. C. Rindflesch, J. V. Rajan, and L. Hunter, “Extracting molecularbinding relationships from biomedical text,” in Proc. 6th Appl. Nat-ural Language Process. Conf./1st Meet. North Amer. Chapter Assoc.Comput. Linguistics, Proc. Conf. and Proc. Anlp-Naacl 2000 StudentRes. Workshop, 2000, pp. 188–195.
[24] D. Sanchez and M. Batet, “Semantic similarity estimation in thebiomedical domain: An ontology-based information-theoretic per-spective,” J. Biomed. Inform., vol. 44, no. 5, pp. 749–759, 2011.
[25] P. Velardi, R. Navigli, A. Cucchiarelli, and F. Neri, “Evaluation ofOntoLearn, a methodology for automatic population of domain on-tologies,” in Ontology Learning from Text: Methods, Applications andEvaluation, P. Buitelaar, P. Cimiano, and B. Magnini, Eds. Ams-terdam, The Netherlands: IOS Press, 2006.
[26] T. Wächter, G. Fabian, and M. Schroeder, “DOG4DAG: Semi-auto-mated ontology generation in OBO-Edit and Protégé,”in Proc. 4th Int. Workshop Semantic Web Appl. Tools Life Sci., London,U.K., 2012, pp. 119–120.
[27] T. Wachter and M. Schroeder, “Semi-automated ontology generationwithin OBO-Edit,” Bioinformatics, vol. 26, no. 12, pp. i88–i96,2010.
[28] Z. Xiang and H. Yongqun, “Improvement of PubMed literaturesearching using biomedical ontology,” in Proc. Int. Conf. Biomed.Ontol., Jul. 25, 2009.
[29] L. Yao, A. Divoli, I. Mayzus, J. A. Evans, and A. Rzhetsky, “Bench-marking ontologies: Bigger or better?,” PLoS Comput. Biol., vol. 7, no.1, p. e1001055, 2011.
[30] A. Zouaq and R. Nkambou, “A survey of domain ontology engineering:Methods and tools,” Adv. Intell. Tutoring Syst., vol. 308, pp. 103–119,2010.
Yu-Wen Guo received the M.S. degree in computerscience at the Institute of Medical Informatics at theNational Cheng-Kung University, Taiwan, in 2013.She is now a Software Engineer in the informationsystem office of Chi Mei Medical Center, Taiwan.
Yi-Tsung Tang received his Ph.D. degree in com-puter science and information engineering at theNational Cheng-Kung University, Taiwan, in 2012.He was a Postdoctoral Fellow of Computer Sci-ence and Information Engineering at the NationalCheng-Kung University from 2012 to 2013. He iscurrently a Software R&D Engineer at ASUSTekCOMPUTER INC., Taiwan. He joined the da VinciInnovation Laboratory, Advanced Technology Di-vision. His research interests include data mining,bioinformatics, intelligent agents, and natural lan-
guage processing.
Hung-Yu Kao (M’07) received his B.S. and M.S.degrees in Computer Science from the NationalTsing Hua University, Hsinchu, Taiwan, in 1994and 1996, respectively. In July 2003, he receivedhis Ph.D. degree from the Electrical EngineeringDepartment, National Taiwan University, Taipei,Taiwan. He was a Postdoctoral Fellow of the Insti-tute of Information Science (IIS), Academia Sinica,from 2003 to 2004. Dr. Kao is currently an AssociateProfessor of Computer Science and InformationEngineering at the National Cheng Kung University,
Taiwan. His research interests include web information retrieval/extraction,search engine, knowledge management, data mining, social network analysisand bioinformatics. He has published more than 60 research papers in refereedinternational journals and conference proceedings. He is a member of ACM.