Generating Image Captions using Generating Image Captions using Topic Focused Multi-document Topic Focused Multi-document Summarization Summarization Natural Language Processing Group Department of Computer Science Robert Gaizauskas and Ahmet Aker
Transcript
Generating Image Captions using Generating Image Captions using Topic Focused Multi-document SummarizationTopic Focused Multi-document Summarization
Natural Language Processing Group
Department of Computer Science
Robert Gaizauskas and Ahmet Aker
October 28, 2008 NLP Group Talk
OutlineOutline
The Vision: Automatic Image Caption Generation Background and Context
─ What should a caption contain?
─ Where do we start? – extracting toponyms
MDS-based approaches to automatic caption generation
1. Baseline: toponym-oriented MDS
2. Scene type-biased MDS
Evaluating image captions Conclusion/Discussion Postscript: Recent work …
October 28, 2008 NLP Group Talk
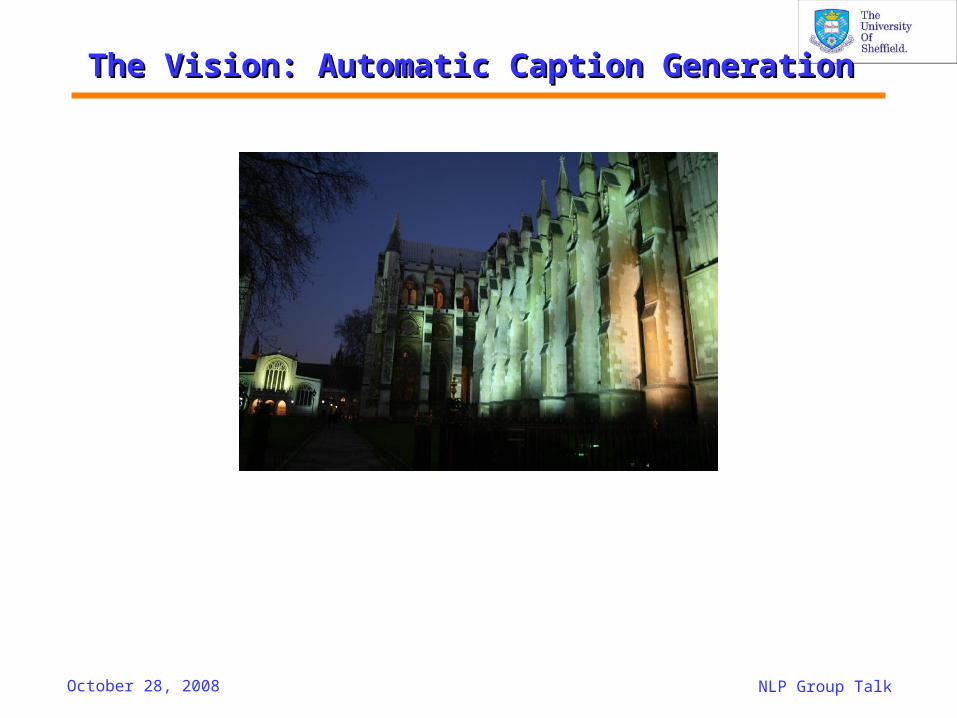
The Vision: The Vision: Automatic Caption GenerationAutomatic Caption Generation
October 28, 2008 NLP Group Talk
The Vision: The Vision: Automatic Caption GenerationAutomatic Caption Generation
Westminster Abbey
October 28, 2008 NLP Group Talk
The Vision: The Vision: Automatic Caption GenerationAutomatic Caption Generation
Westminster Abbey: Located in central London Westminster Abbey is one of the most beautiful churches in England. Westminster Abbey was commissioned by Edward the Confessor in 1050 AD. The Abbey has been expanded over the years and it’s most recent addition is the west front towers built in 1745. The Abbey houses the tombs of English monarchs and famous notables. Edward the Confessor and Queen Elizabeth I are entombed here. Near Edward the Confessor's tomb is the coronation chair, constructed in 1301 it is where English monarchs have been crowned since 1308. The Poet's Corner contains the tombs and memorials of England's literary greats. The Charter House built in the 13th century contains very interesting medieval tiles and stained glass. The Abbey is a must see sight when visiting London. (Source: Virtual Tourist)
Hungarian Parliament Building, Budapest, Pest, River Danube, Parliament, Urban centre, Tourist site, Flood plain, High land value
OutdoorsZero Faces
Parliament (Orszaghaz), Budapest The Parliament building on the left banks of Danube was built for a country three times larger than today's Hungary. Inspired by the London Parliament, this Hungary's largest building was conceived in 1896 by Imre Steindl but finished only in 1902, after the architect's death.
Impressive neo-gothic turrets and arches stretch for over 250 metres along the Danube embankment.The building comprises of 691 rooms, immense halls and over 12.5 miles of corridors, has a central dome of 96-metres (precisely the same height as that of Szent István Basilica). (Source:Virtual Tourist)
Hungarian Parliament Building, Budapest, Pest, River Danube, Parliament, Urban centre, Tourist site, Flood plain, High land value
OutdoorsZero Faces
Parliament (Orszaghaz), Budapest The Parliament building on the left banks of Danube was built for a country three times larger than today's Hungary. Inspired by the London Parliament, this Hungary's largest building was conceived in 1896 by Imre Steindl but finished only in 1902, after the architect's death.
Impressive neo-gothic turrets and arches stretch for over 250 metres along the Danube embankment.The building comprises of 691 rooms, immense halls and over 12.5 miles of corridors, has a central dome of 96-metres (precisely the same height as that of Szent István Basilica). (Source: Virtual Tourist)
Creating captions─ Labelling those pesky holiday snaps
─ Professional image library/collection curators
Retrieval over indexed image collections. Of interest to─ Writers seeking illustrations
Journalists
Academics
Educators
─ Professional image stockists – those selling images who want them to be found by clients
October 28, 2008 NLP Group Talk
OutlineOutline
The Vision: Generating Captions Automatically Background and Context
─ What should a caption contain?
─ Where do we start? – extracting toponyms
MDS-based approaches to automatic caption generation
1. Baseline: toponym-oriented MDS
2. Scene type-biased MDS
Evaluating image captions Conclusion/Discussion
October 28, 2008 NLP Group Talk
What Should a Caption Contain?What Should a Caption Contain?
To answer this question need to consider who captions are for Many possible users of images, e.g.
─ Professional photographers – may want image metadata in caption, such as camera type and settings, time of day, etc.
─ Tourists – may want information about opening hours, directions, attractions
─ Historians – may information about how human built landscape came about or what events have transpired at this location
─ Students of architecture – may want information about styles, influences, materials
─ Geologists … A list of requests to image librarians in educational institutions
“Follies and Grottoes; Pearl Harbor; The Passion and Resurrection in visual terms; Cézanne and the influence of Cubism; Working class housing; Concrete finishes; Bauhaus; Ambiguity - pictures to illustrate the theme.” (Bradfield, 1976)
October 28, 2008 NLP Group Talk
What Should a Caption Contain?What Should a Caption Contain?
An influential approach to analyzing picture content is that developed by Sara Shatford in her paper: “Analyzing the Subject of a Picture: A Theoretical Approach” Cataloging & Classification Quarterly, Vol. 6(3).1986.
She proposes
“a theoretical basis for identifying and classifying the kinds of subjects a picture may have, using previously developed principles of cataloging and classification, and concepts taken from the philosophy of art, from meaning in language, and from visual perception”
with a view to providing
“a means for evaluating, adapting, and applying presently existing indexing languages, or for devising new languages for pictorial materials”
October 28, 2008 NLP Group Talk
What Should a Caption Contain?: Shatford’s ApproachWhat Should a Caption Contain?: Shatford’s Approach
Builds on art historian Erwin Panofsky’s theory of three levels of meaning in a work of art to propose subjects be categorised as─ Generic-of (generic description of objects/actions in picture)
─ Specific-of (identification of specific named objects, persons, locations in picture)
─ About (emotions, abstract concepts)
Example:
Generic-of: woman holding slain man Specific-of: Mary holding crucified Jesus About: pity, suffering, man’s inhumanity
October 28, 2008 NLP Group Talk
What Should a Caption Contain?: Shatford’s ApproachWhat Should a Caption Contain?: Shatford’s Approach
Builds on art historian Erwin Panofsky’s theory of three levels of meaning in a work of art to propose subjects be categorised as─ Generic-of (generic description of objects/actions in picture)
─ Specific-of (identification of specific named objects, persons, locations in picture)
What Should a Caption Contain?: Shatford’s ApproachWhat Should a Caption Contain?: Shatford’s Approach
Shatford proposes that four facets of image subjects may be described in each of these three categories
─ Who
─ What
─ Where
─ When
Together this 3 category x 4 facet categorisation yields what has become known as the Shatford-Panoskfy matrix for characterising the contents of an image
October 28, 2008 NLP Group Talk
Panofsky-Shatford matrixPanofsky-Shatford matrix
Facets Specific Of Generic Of AboutWho? Individually named
persons, animals, thingsKinds of persons, animals, things
Mythical beings, abstraction manifested or symbolised by objects or beings
What? Individually named events
Actions, conditions Emotions, abstractions manifested by actions
Where? Individually named geographic locations
Kind of place geographic or architectural
Places symbolised, abstractions manifest by locale
When? Linear time; dates or periods
Cyclical time; seasons, time of day
Emotions or abstraction symbolised by or manifest by
October 28, 2008 NLP Group Talk
Panofsky-Shatford matrix: The TRIPOD FocusPanofsky-Shatford matrix: The TRIPOD Focus
Facets Specific Of Generic Of AboutWho? Individually named
persons, animals, things
Kinds of persons, animals, things
Mythical beings, abstraction manifested or symbolised by objects or beings
What? Individually named events
Actions, conditions Emotions, abstractions manifested by actions
Where? Individually named geographic locations
Kind of place geographic or architectural
Places symbolised, abstractions manifest by locale
When? Linear time; dates or periods
Cyclical time; seasons, time of day
Emotions or abstraction symbolised by or manifest by
October 28, 2008 NLP Group Talk
Where do we start?Where do we start?
As a starting point we assume minimally that for each picture we have─ Geo-coordinates
─ Compass direction of camera lens
Optionally we may have─ Some primitive image content analysis
Faces? yes or no
Indoors or Outdoors?
Edge detection
─ Existing caption with toponyms
We also have geographical data resources─ Topographic database – given a grid reference supplies toponyms within a given
area
─ Land use database – given an area describes land use in terms of 16 categories
We do not consider these issues further here – assume can derive a list of toponyms for every geo-referenced image
October 28, 2008 NLP Group Talk
OutlineOutline
The Vision: Generating Captions Automatically Background and Context
─ What should a caption contain?
─ Where do we start? – extracting toponyms
MDS-based approaches to automatic caption generation
1. Baseline: toponym-oriented MDS
2. Scene type-biased MDS
Evaluating image captions Conclusion/Discussion
October 28, 2008 NLP Group Talk
Toponym-oriented MDSToponym-oriented MDS
Baseline approach to caption generation:─ Use toponyms extracted in pre-processing as web query
─ Form cluster of top n documents returned from web search
─ Run an MDS system over the cluster to produce m sentence summary for use as caption
─ Variants:
Generic summary
Query-biased summary, again using toponyms as query
October 28, 2008 NLP Group Talk
WEB SEARCH
Westminster Abbey, London, UK
MapPoint Service
Web Documents
GenericSummary
Query-based Summary
SUMMA
Westminster Abbey is a living Church, part of the Church of England: More. The church is one of the most famous in Britain and is one of London's most visited tourist attractions. It has…
LatitudeLongitudeDirection
?
Toponym-oriented MDSToponym-oriented MDS
October 28, 2008 NLP Group Talk
Scene type-biased MDSScene type-biased MDS
Results of Toponym-oriented MDS promising, but can we do better?
Intuition: In describing scenes or objects of a particular type, people tend to supply values for a ‘typical’ set of attributes for that type
─ I.e. a ‘template’ or ‘schema’ or ‘prototype’ for type exists and descriptions tend to fill in or supply details for part of this template
─ E.g. descriptions of churches typically include details such as
When built
Who commissioned or caused it to be built
Architectural style
Famous people buried therein
Can we use this intuition to guide the construction of summaries?
October 28, 2008 NLP Group Talk
Scene type-biased MDS: A First TakeScene type-biased MDS: A First Take
The approach involves off-line and on-line processing Offline:
Given a collection of photos with geo-coordinates and compass info─ Construct a scene type taxonomy─ Assemble scene type-specific text corpora─ Derive scene-type models from the type-specific corpora
Online:
Given a new photo with geo-coordinates and compass info─ Identify scene type of photo─ Retrieve relevant documents from web─ Use scene-type models to create multi-document summaries from web
documents
October 28, 2008 NLP Group Talk
Scene Type Identification + Taxonomy CreationScene Type Identification + Taxonomy Creation
ToponymExtraction
Photo Collectionw. geo-coordinates + compass
Main toponym assignment
Topo-graphic
DB
Land Use Data
Get Wikipedia article
Extract scene type
Annotate photos with scene type
Update scene type taxonomy
Scene type-biased MDSScene type-biased MDS
Scene Type Taxonomy
Wikipedia
October 28, 2008 NLP Group Talk
Scene Type Identification + Taxonomy CreationScene Type Identification + Taxonomy Creation
ToponymExtraction
Photo Collectionw. geo-coordinates + compass
Main toponym assignment
Topo-graphic
DB
Land Use Data
Get Wikipedia article
Extract scene type
Annotate photos with scene type
Update scene type taxonomy
Scene type-biased MDSScene type-biased MDS
Scene Type Taxonomy
Wikipedia
October 28, 2008 NLP Group Talk
Extracting Scene TypeExtracting Scene Type
Scene type extracted by processing 1st paragraph of Wikipedia text and1 Splitting into sentences and POS tagging
2 Looking for “isa” patterns using
the automaton
3 Discarding from beginning of sentence to end of “isa” pattern match
4 Searching right for first noun and
then matching nominal patterns with
5 Retaining the text which is the last sequence of nouns as the type
Scene type-biased MDSScene type-biased MDS
the
n poss
adjand
/or
adj
adj
n
adjn
is/are one of world’s
the
greatest/ta
llest/bigg
est/most/
largest
greatest/tallest/biggest/
most/largest
a/an world’s
October 28, 2008 NLP Group Talk
Extracting Scene Type: ExampleExtracting Scene Type: Example
The Collegiate Church of St Peter at Westminster, which is almost always referred to by its original name of Westminster Abbey, is a large, mainly Gothic church, in Westminster, London, just to the west of the Palace of Westminster.
Assembling scene type-specific corporaAssembling scene type-specific corpora
Guiding intuition is: given object/scene type of image, can use prior knowledge of that object/scene type to help construct summary
One source of prior knowledge for each type is texts that describe objects/scenes of that type
Proposal: for each object/scene type build a corpus of texts describing objects/scenes of that type
Such corpora could then be used in a variety of ways─ To build language models that are specific to given object/scene types─ To induce IE style templates for object/scene types
Assembling scene type-specific corpora (1)Assembling scene type-specific corpora (1)
Scene type-biased MDSScene type-biased MDS
Get Wikipedia article
Extract scene type
Wikipedia
Add first para to corpus
Scene TypeCorpus Collection
Scene Type 1 Scene Type 2 Scene Type 3
October 28, 2008 NLP Group Talk
Assembling scene type-specific corpora (2)Assembling scene type-specific corpora (2)
Scene type-biased MDSScene type-biased MDS
Get Wikipedia article
Extract scene type
Wikipedia
…Country: UkraineCountry: United Kingdom ... City: London … Attraction: London Eye Attraction: Westminster Abbey Caption 1 … Caption n … City: Manchester Attraction: Old Trafford … ……
Add captions to corpus
Caption Dump
Scene TypeCorpus Collection
Scene Type 1 Scene Type 2 Scene Type 3
October 28, 2008 NLP Group Talk
Deriving scene-type models from text corporaDeriving scene-type models from text corpora
Various scene-type models could be derived from scene-specific text corpora
A simple/basic place to start is with simple n-gram models -- we explore unigram and bigram models
For each type-specific corpus (e.g. the church corpus)─ Compute and store frequency of each unigram/bigram in the corpus
─ Compute and store the frequency of the maximally frequent unigram/bigram in the corpus (for normalizing frequencies later)
Scene type-biased MDSScene type-biased MDS
October 28, 2008 NLP Group Talk
Scene type-biased MDS: A First TakeScene type-biased MDS: A First Take
The approach involves off-line and on-line processing Offline:
Given a collection of photos with geo-coordinates and compass info─ Construct a scene type taxonomy─ Assemble scene type-specific text corpora─ Derive scene-type models from the type-specific corpora
Online:
Given a new photo with geo-coordinates and compass info─ Identify scene type of photo─ Retrieve relevant documents from web─ Use scene-type models to create multi-document summaries from web
documents
Scene type-biased MDSScene type-biased MDS
October 28, 2008 NLP Group Talk
Captioning a New ImageCaptioning a New Image
1. Retrieve scene type of new image as described for the off-line system above geo-coordinate + compass information used to derive toponyms Principal toponym identified Wikipedia article retrieved for this toponym Wikipedia article processed to extract scene type
2. Retrieve documents from web using principal toponym Top n documents selected and processed to ‘clean’ them for MDS
3. Create scene-biased multi-document summaries from cleaned web documents
Scene type-biased MDSScene type-biased MDS
October 28, 2008 NLP Group Talk
Captioning a New ImageCaptioning a New Image
1. Retrieve scene type of new image as described for the off-line system above geo-coordinate + compass information used to derive toponyms Principal toponym identified Wikipedia article retrieved for this toponym Wikipedia article processed to extract scene type
2. Retrieve documents from web using principal toponym Top n documents selected and processed to ‘clean’ them for MDS
3. Create scene-biased multi-document summaries from cleaned web documents
Query-based MDS algorithm adds similarity of sentence to query as a feature:
─ Preprocess documents in MD cluster C by splitting into sentences, tokenizing, lemmatizing and POS tagging
─ For each sentence s from document D in cluster C compute a tf.idf vector representation s of s
compute s’s position in D (f1)─ Compute centroid c of the vector representations of all sentences in C─ Compute a tf.idf vector representation q of query─ For each sentence s in cluster C
compute cosine similarity of s and c (f2) compute cosine similarity of s and q (f3) compute a sentence score for s which is a weighted
combination of the features
─ Rank sentences by sentence score─ Add sentences to summary in order of rank until summary length limit,
discarding sentences that are above a similarity threshold with a previously included sentence
Model-biased MDS algorithm works as follows:─ Preprocess documents in MD cluster C by splitting into sentences,
tokenizing, lemmatizing and POS tagging─ For each sentence s from document D in cluster C
compute a tf.idf vector representation s of s
compute s’s position in D (f1)─ Compute centroid c of the vector representations of all sentences in C─ Compute a tf.idf vector representation q of query─ For each sentence s in cluster C
compute cosine similarity of s and c (f2) compute cosine similarity of s and q (f3) compute ModelSimScore(s,M) (f4) compute a sentence score for s which is a weighted combination
of the features
─ Rank sentences by sentence score─ Add sentences to summary in order of rank until summary length limit,
discarding sentences that are above a similarity threshold with a previously included sentence
Scene type-biased MDSScene type-biased MDS
Preprocessing
Feature Extraction
SentenceScoring andSelection
€
SentenceScore = wi
i
∑ f i
October 28, 2008 NLP Group Talk
OutlineOutline
The Vision: Generating Captions Automatically Background and Context
─ What should a caption contain?
─ Where do we start? – extracting toponyms
MDS-based approaches to automatic caption generation
How to evaluate image captions is not obvious Can consider distinction between extrinsic and intrinsic evaluation
(Spark-Jones and Galliers, 1996). Extrinsic evaluation assesses utility of system in some wider task
context─ So could, e.g., see whether automatically generated captions lead to
improved scores in some image retrieval task Intrinsic evaluation assesses the correctness of system output in
relation to the objectives of the system ─ For summaries and translations this is usually done in terms of
Quality criteria, e.g. coherence + cohesion, readability, grammaticality
Proximity to a model summary/translation TRIPOD hopes to carry out extrinsic evaluations eventually For now we focus on intrinsic evaluation using model captions
How do we get model captions?─ Can give users documents pertaining to test image and ask them to
select relevant content
Pros: simulates system scenario
Cons: significant effort
─ Can use existing captions associated with similar images
Pros: easy to get for well-known scenes
Cons: variable in quality, length and purpose
Here we use Virtual Tourist captions as models to assess whether model-biased captions offer improvements
October 28, 2008 NLP Group Talk
Experimental SetupExperimental Setup
Image collection contains 417 images from sites in the UK─ 274 urban areas
─ 173 rural areas
─ Each image has geo-coordinates and compass information
For each image ─ principal toponym is determined semi-automatically (at present) using MapPoint
─ scene type is determined as described above
─ Two clusters of 10 and 15 web documents (the latter a superset of the former) are retrieved using the principal toponym as query
─ 6 captions are created running the MDS system
on either the 10 or 15 document cluster
using either no model, the unigram model or the bigram model
─ An evaluation set of 6 model captions per image is created from Virtual Tourist by identifying captions for the principal toponym and selecting those whose length is approximately the same as the target caption length (~175 words)
October 28, 2008 NLP Group Talk
Experimental ResultsExperimental Results
Note 1: bigram model outperforms other settings Note 2: increasing cluster size reduces scores
The Greenwich Millennium Village is a new urban regeneration development to the south of the Dome. It is next to North Greenwich tube station, about 3 miles (4.8 km) east from the Greenwich town centre, north west of Charlton. It is a bus ride away from Greenwich town centre and was built for the now-closed Millennium Dome. It was founded in 1640 by the New Haven colony agents Robert Feaks and Captain Daniel Patrick, who purchased land from the Siwanoy Indians for 25 English coats, and it was named for Greenwich, England. Greenwich is situated about 4 miles east of Central London by the River Thames. It became known as East Greenwich to distinguish it from West Greenwich or Deptford Strond, the part of Deptford adjacent to the Thames, but the use of East Greenwich to mean the whole of the town of Greenwich died out in the 19th century. The Greenwich became the Royal Naval College in 1869, and recently the Univer- sity of Greenwich and Trinity College of Music have moved in.
The observatory is the site of 0 meridian. The Royal Greenwich Observatory is located in Greenwich and the Prime Meridian passes through the building. Greenwich Mean Time was at one time based on the time observations made at the Royal Greenwich Observatory, before being superseded by Coordinated Universal Time. While Greenwich no longer hosts a working astronomical observatory, a ball still drops daily to mark the exact moment of noon (UTC) 1pm (13:00)(BST), and there is a good museum of astronomical and navigational tools. The observatory is situated in Greenwich Park, which used to be the grounds of the Royal Palace of Placentia. At the bottom of the park is the National Maritime Museum which also includes the Queen’s House, designed by Inigo Jones. It is free to visit all these buildings. Greenwich also features the world’s only museum dedicated to fans, the Fan Museum, in a Georgian townhouse at 10?12 Croom’s Hill (fee payable). Also on Croom’s Hill, on the corner of the junction with Nevada Street is Greenwich Theatre, formerly Crowder’s Music Hall.
Virtual Tourist Model-biased summary
October 28, 2008 NLP Group Talk
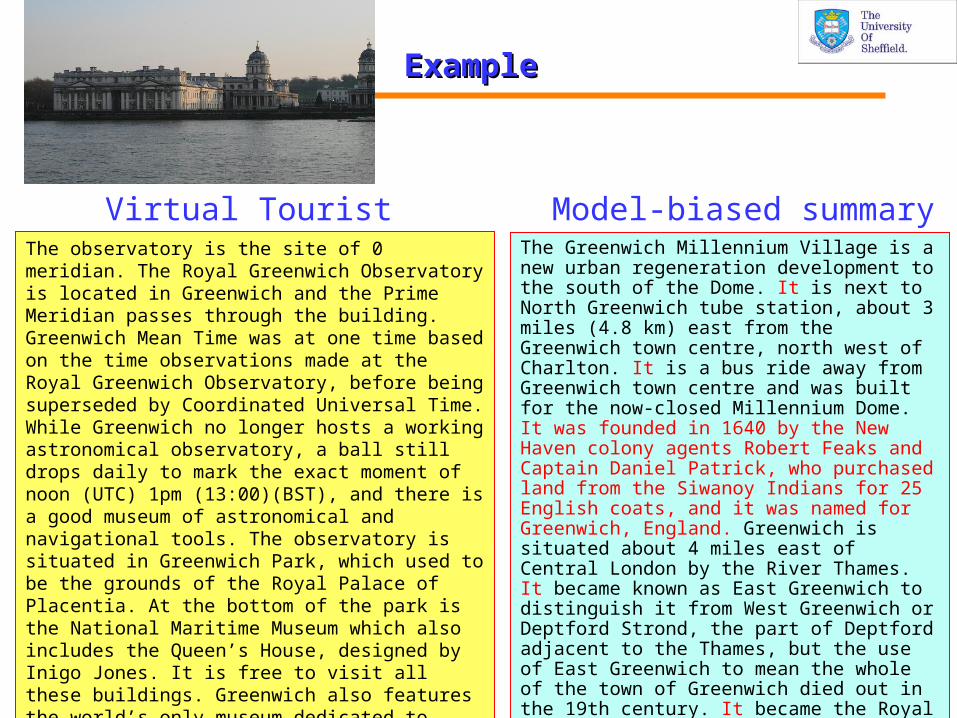
ExampleExample
The Greenwich Millennium Village is a new urban regeneration development to the south of the Dome. It is next to North Greenwich tube station, about 3 miles (4.8 km) east from the Greenwich town centre, north west of Charlton. It is a bus ride away from Greenwich town centre and was built for the now-closed Millennium Dome. It was founded in 1640 by the New Haven colony agents Robert Feaks and Captain Daniel Patrick, who purchased land from the Siwanoy Indians for 25 English coats, and it was named for Greenwich, England. Greenwich is situated about 4 miles east of Central London by the River Thames. It became known as East Greenwich to distinguish it from West Greenwich or Deptford Strond, the part of Deptford adjacent to the Thames, but the use of East Greenwich to mean the whole of the town of Greenwich died out in the 19th century. It became the Royal Naval College in 1869, and recently the University of Greenwich and Trinity College of Music have moved in.
The observatory is the site of 0 meridian. The Royal Greenwich Observatory is located in Greenwich and the Prime Meridian passes through the building. Greenwich Mean Time was at one time based on the time observations made at the Royal Greenwich Observatory, before being superseded by Coordinated Universal Time. While Greenwich no longer hosts a working astronomical observatory, a ball still drops daily to mark the exact moment of noon (UTC) 1pm (13:00)(BST), and there is a good museum of astronomical and navigational tools. The observatory is situated in Greenwich Park, which used to be the grounds of the Royal Palace of Placentia. At the bottom of the park is the National Maritime Museum which also includes the Queen’s House, designed by Inigo Jones. It is free to visit all these buildings. Greenwich also features the world’s only museum dedicated to fans, the Fan Museum, in a Georgian townhouse at 10?12 Croom’s Hill (fee payable). Also on Croom’s Hill, on the corner of the junction with Nevada Street is Greenwich Theatre, formerly Crowder’s Music Hall.
Virtual Tourist Model-biased summary
October 28, 2008 NLP Group Talk
ExampleExample
The Greenwich Millennium Village is a new urban regeneration development to the south of the Dome. It is next to North Greenwich tube station, about 3 miles (4.8 km) east from the Greenwich town centre, north west of Charlton. It is a bus ride away from Greenwich town centre and was built for the now-closed Millennium Dome. It was founded in 1640 by the New Haven colony agents Robert Feaks and Captain Daniel Patrick, who purchased land from the Siwanoy Indians for 25 English coats, and it was named for Greenwich, England. Greenwich is situated about 4 miles east of Central London by the River Thames. It became known as East Greenwich to distinguish it from West Greenwich or Deptford Strond, the part of Deptford adjacent to the Thames, but the use of East Greenwich to mean the whole of the town of Greenwich died out in the 19th century. It became the Royal Naval College in 1869, and recently the University of Greenwich and Trinity College of Music have moved in.
The observatory is the site of 0 meridian. The Royal Greenwich Observatory is located in Greenwich and the Prime Meridian passes through the building. Greenwich Mean Time was at one time based on the time observations made at the Royal Greenwich Observatory, before being superseded by Coordinated Universal Time. While Greenwich no longer hosts a working astronomical observatory, a ball still drops daily to mark the exact moment of noon (UTC) 1pm (13:00)(BST), and there is a good museum of astronomical and navigational tools. The observatory is situated in Greenwich Park, which used to be the grounds of the Royal Palace of Placentia. At the bottom of the park is the National Maritime Museum which also includes the Queen’s House, designed by Inigo Jones. It is free to visit all these buildings. Greenwich also features the world’s only museum dedicated to fans, the Fan Museum, in a Georgian townhouse at 10?12 Croom’s Hill (fee payable). Also on Croom’s Hill, on the corner of the junction with Nevada Street is Greenwich Theatre, formerly Crowder’s Music Hall.
Virtual Tourist Model-biased summary
October 28, 2008 NLP Group Talk
OutlineOutline
The Vision: Generating Captions Automatically Background and Context
─ What should a caption contain?
─ Where do we start? – extracting toponyms
MDS-based approaches to automatic caption generation
1. Baseline: toponym-oriented MDS
2. Scene type-biased MDS
Evaluating image captions Conclusion/Discussion
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Conclusion/DiscussionConclusion/Discussion
Contributions: ─ Introduced the task of automatic caption generation from toponyms
─ Described a system architecture for carrying out this task which incorporates MDS technologies
─ Introduced the idea of scene-type biased summaries as a way of focusing caption content
─ Described one approach to determining scene-type from toponyms based on shallow parsing of Wikipedia entries
─ Described one approach to building scene-type specific corpora to inform creation scene-type specific models to be used in MDS
─ Described one approach to building scene-type specific models from scene-type specific corpora and their application in a weighted feature-based sentence extraction MDS system
─ Discussed potential approaches to evaluating image captions
─ Presented an initial empirical study which confirms the utility of simple language model scene type biased summaries for image captioning
October 28, 2008 NLP Group Talk
Future WorkFuture Work
Investigate alternate ways of determining scene type─ Refine parsing of Wikipedia entries
─ Look beyond Wikipedia to ‘rest of web’ for toponyms without Wikipedia entries
Investigate alternate ways of assembling scene type specific corpora─ Use Wikipedia texts instead of Virtual Tourist texts
─ Use Wikipedia categorization scheme
Investigate alternate ways of building/using scene type specific models from corpora
─ Consider replacing entity types in texts with semantic class tags -- e.g. 1732 DATE, Gordon Brown PERSON
─ Consider ways of inducing IE-style templates from scene type specific corpora, e.g. the ADIOS algorithm of Solan et al. (2005)
October 28, 2008 NLP Group Talk
Future Work (cont)Future Work (cont)
Improve the MDS system─ Consider learning weights for the linear feature combination so as to
optimize scoring against model summaries
─ Consider additional features for inclusion in the sentence scoring function, e.g.
sentence begins with toponym
toponym is subject of sentence
─ Consider ways of making output more fluent, e.g. anaphora expansion/introduction
October 28, 2008 NLP Group Talk
Postscript: Recent WorkPostscript: Recent Work
Recent work has explored some of these directions and includes:─ Evaluating against further baselines
─ Using corpora built from Wikipedia as well as Virtual Tourist
─ Building models generalised over NE types
─ Statistical significance testing of results
─ Optimising weights in summarizer’s linear weighting formula
October 28, 2008 NLP Group Talk
Experimental SetupExperimental Setup
Image collection contains 417 images from sites in the UK─ 274 urban areas
─ 173 rural areas
─ Each image has geo-coordinates and compass information
For each image ─ principal toponym is determined semi-automatically (at present) using MapPoint
─ scene type is determined as described above
─ A cluster of 10 web documents are retrieved using the principal toponym as query
─ 11 captions are created running the MDS system
on the 10 document cluster
using either no model, the unigram model, the bigram model or the generalized form of both models
─ An evaluation set of 4 model captions per image is created from Virtual Tourist by identifying captions for the principal toponym and selecting those whose length is approximately the same as the target caption length (~175 words)
─ Only 170/417 images are included in the evaluation
Both Wikipedia baseline and query-based summaries score significantly higher than the top retrieved document baseline.
Wikipedia baseline scores are higher than the query-based ones, the differences are not significant for R2 and moderately significant for RSU4.
Wikipedia baseline summaries have the best coverage of the content in our model captions, but the query-based summaries perform nearly as well.
*** = p < .0001, ** = p < .001, * = p < .0167 and no star indicates non-significance.
Recall FirstDoc Wiki queryBased FirstDoc<Wiki FirstDoc<queryBased Wiki>queryBased
R2 .047 .074 .070 -6.82*** -7.81*** -1.84
RSU4 .085 .126 .123 -7.75*** -8.42*** -3.14**
Baselines
October 28, 2008 NLP Group Talk
Experimental Results-Language Model summariesExperimental Results-Language Model summaries
Recall VirtualTourist
Wiki Merge VirtualTourist<Wiki
VirtualTourist<Merge Wiki>Merge
R2 .071 .073 .073 -1.35 .46 -.85
RSU4 .122 .125 .124 -.57 -1.9 -.75
Recall VirtualTourist
Wiki Merge VirtualTourist<Wiki
VirtualTourist<Merge Wiki>Merge
R2 .072 .074 .073 -4.19*** -4.21*** -.73
RSU4 .125 .125 .124 -1.95 -2.53* -.53
Unigram
Bigram
October 28, 2008 NLP Group Talk
Experimental Results-Language Model summariesExperimental Results-Language Model summaries
Higher scores with Wikipedia models in Unigram summaries. However, the differences are not significant,
─ indicating that using Wikipedia as a corpus only moderately improves the quality of the
summaries. For the bigram models Wikipedia language model-biased summaries
yield ROUGE 2 scores higher and ROUGE SU4 scores equal to those obtained using the Virtualtourist and merged models.
─ These inconsistent results indicate that it is not clear if Wikipedia language models indeed improve the ROUGE scores
Wikipedia bigram models have significantly higher ROUGE scores than the query-based summaries (R2: z=-6.37, p<.0001; RSU4: z=-5, p<.0001).
When compared to Wikipedia baseline summaries the ROUGE scores of Wikipedia bi-gram models are equal for R2 and not significantly lower for RSU4 (z=-1.99, p=.05).
October 28, 2008 NLP Group Talk
Experimental Results-General Language Model summariesExperimental Results-General Language Model summaries
Recall VirtualTourist
Wiki Merge VirtualTourist<Wiki
VirtualTourist<Merge Wiki>Merge
R2 .077 .070 .072 -5.35*** -4.23*** -2.76**
RSU4 .132 .123 .124 -7.19*** -7.59*** -1.78
Recall VirtualTourist
Wiki Merge VirtualTourist<Wiki
VirtualTourist<Merge Wiki>Merge
R2 .079 .067 .071 -5.99*** -4.61*** -2.47*
RSU4 .133 .122 .125 -7.81*** -6.61*** -.82
Unigram General
Bigram General
October 28, 2008 NLP Group Talk
Experimental Results-General Language Model summariesExperimental Results-General Language Model summaries
ROUGE scores for Wikipedia-based and merged language models decrease when general language models are used compared to non-general language models
Virtualtourist captions improve over non-general language models. When compared, for instance, to Wikipedia bi-gram language models that were the best among non-general models, the results show a significant improvement (R2: z=-4.33, p<.0001; RSU4: z=-8.02, p<.0001).
Compared to general models based on Wikipedia articles and merged texts both Virtualtourist unigram and bi-gram language models perform consistently significantly better.
Bi-gram Virtualtourist general models are significantly better than uni-gram ones (R2: z=-4.28, p< :0001; RSU4: z=-4.57, p<.0001).
Virtualtourist bi-gram models score also significantly higher than query-based summaries (R2: z=-5.86, p<.0001; RSU4: z=-8.26, .0001) and Wikipedia baseline summaries (R2: z=-2.61, p<.01; RSU4 z=-3.02, p<.01).
These results show that language-model biased summaries lead to significant improvement in content coverage between the automatically generated summaries and the model ones relative to query-based summaries without language model bias.
─ Query-based summarizer takes relevant sentences according to the query given to it and does not take into more general consideration the information typically provided for the object type.
─ Our language models are one way of capturing “shared interests about some particular object types”.
─ The results suggest that when these shared interests are used to bias the summarizer, the quality of the summaries or image captions improves.
Using semantic categories derived from named entity recognition instead of specific words to build models can further improve the quality of the summaries.
─ Improvement seems to be dependent on the corpus from which such general models are derived.
October 28, 2008 NLP Group Talk
AcknowledgementsAcknowledgements
Thanks to all our TRIPOD partners, especially
─ Mark Sanderson, Emma Barker and Xin Fan, Sheffield
─ Ross Purves, Alistair Edwardes, Martin Tomko, Zurich
─ Gareth Jones, Andrew Salway, Dublin
for discussions informing the content of this talk