Genes, Genes, Microarrays Microarrays and Motifs and Motifs Lecture 8 Lecture 8 CSC 2417/BCB 410 CSC 2417/BCB 410 Michael Brudno Michael Brudno Many slides from various Many slides from various sources, including T. sources, including T. Hughes (U. of T.), S. Hughes (U. of T.), S. Batzolgou (Stanford), Batzolgou (Stanford), Sanja Rogic (UBC), Sanja Rogic (UBC),
Transcript
Genes, Genes, MicroarraysMicroarrays and Motifsand Motifs
Lecture 8Lecture 8
CSC 2417/BCB 410 CSC 2417/BCB 410
Michael BrudnoMichael BrudnoMany slides from various Many slides from various sources, including T. Hughes sources, including T. Hughes (U. of T.), S. Batzolgou (U. of T.), S. Batzolgou (Stanford), Sanja Rogic (Stanford), Sanja Rogic (UBC), Manolis Kellis (MIT)(UBC), Manolis Kellis (MIT)
OutlineOutline
Intro to genes and motifsIntro to genes and motifs Identifying Gene StructuresIdentifying Gene Structures MicroarraysMicroarrays Identifying Regulatory ElementsIdentifying Regulatory Elements
Genes and MotifsGenes and Motifs
Cells respond to environmentCells respond to environmentCell responds toenvironment—various external messages
Genome is fixed – Cells are Genome is fixed – Cells are dynamicdynamic
A genome is staticA genome is static
Every cell in our body has a copy of same genomeEvery cell in our body has a copy of same genome
A cell is dynamicA cell is dynamic
Responds to external conditionsResponds to external conditions Most cells follow a Most cells follow a cell cyclecell cycle of division of division
Cells differentiate during developmentCells differentiate during development
Gene expression varies according to:Gene expression varies according to:
Cell typeCell type Cell cycleCell cycle External conditionsExternal conditions LocationLocation
slide credits: M. Kellis
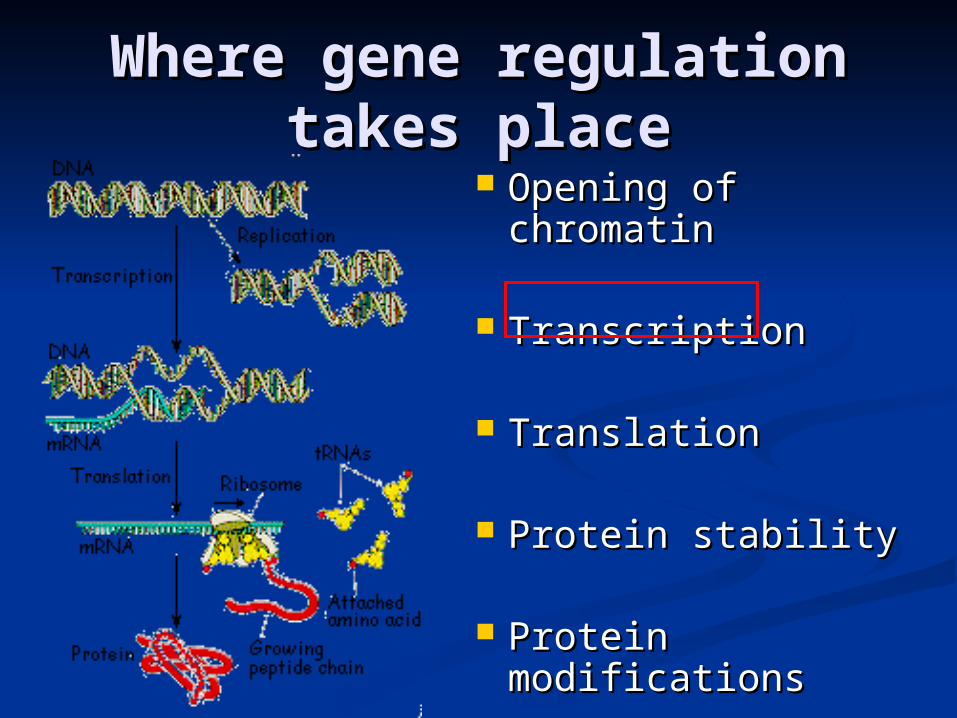
Where gene regulation takes Where gene regulation takes placeplace
Gene Finding: Different Gene Finding: Different ApproachesApproaches
Similarity-based methods (extrinsic)Similarity-based methods (extrinsic) - use similarity to - use similarity to
annotated sequencesannotated sequences::
proteinsproteins cDNAscDNAs ESTsESTs
Comparative genomicsComparative genomics - Aligning genomic sequences from - Aligning genomic sequences from different speciesdifferent species
Ab initioAb initio gene-finding (intrinsic) gene-finding (intrinsic)
Integrated approachesIntegrated approaches
Similarity-based methodsSimilarity-based methods Based on sequence conservation due to functional Based on sequence conservation due to functional
constraintsconstraints
Use local alignment tools (Smith-Waterman algo, Use local alignment tools (Smith-Waterman algo, BLAST, FASTA) to search protein, cDNA, and EST BLAST, FASTA) to search protein, cDNA, and EST databasesdatabases
Will not identify genes that code for proteins not Will not identify genes that code for proteins not already in databasesalready in databases
Limits of the regions of similarity not well definedLimits of the regions of similarity not well defined
Comparative GenomicsComparative Genomics
Based on the assumption that coding Based on the assumption that coding sequences are more conserved than non-sequences are more conserved than non-codingcoding
Alignment of homologous regionsAlignment of homologous regions
Difficult to define limits of higher similarityDifficult to define limits of higher similarity
Difficult to find optimal evolutionary distanceDifficult to find optimal evolutionary distance
Using Comparative Using Comparative Information Information
Hox cluster is an example where everything is conservedHox cluster is an example where everything is conserved
Patterns of ConservationPatterns of Conservation
30% 1.3%
0.14%
58%14%
10.2%
Genes Intergenic
Mutations Gaps Frameshifts
Separation
2-fold10-fold75-fold
Summary for Extrinsic Summary for Extrinsic ApproachesApproaches
Strengths:Strengths:
Rely on accumulated pre-existing Rely on accumulated pre-existing biological data, thus should produce biological data, thus should produce biologically relevant predictionsbiologically relevant predictions
Weaknesses:Weaknesses:
Limited to pre-existing biological dataLimited to pre-existing biological data Errors in databasesErrors in databases Difficult to find limits of similarityDifficult to find limits of similarity
Ab initioAb initio Gene Finding, Gene Finding, Part 1Part 1
Input:Input: A DNA string over the alphabet A DNA string over the alphabet {A,C,G,T}{A,C,G,T}
Output:Output: An annotation of the string An annotation of the string showing for every nucleotide showing for every nucleotide whether it is coding or notwhether it is coding or not
AAAGC ATG CAT TTA ACG A GT GCATC AG GA CTC CAT ACG TAA TGCCG
Gene finder
Ab initioAb initio Gene Finding, Gene Finding, Part 2Part 2
Using only sequence informationUsing only sequence information
Identifying only coding exons of Identifying only coding exons of protein-coding genes (transcription protein-coding genes (transcription start site, 5start site, 5’’ and 3 and 3’’ UTRs are UTRs are ignored)ignored)
Integrates coding statistics with Integrates coding statistics with signal detectionsignal detection
Coding Statistics, Part 1Coding Statistics, Part 1
Unequal usage of codons in the coding Unequal usage of codons in the coding regions is a universal feature of the genomesregions is a universal feature of the genomes uneven usage of amino acids in existing proteinsuneven usage of amino acids in existing proteins uneven usage of synonymous codonsuneven usage of synonymous codons
We can use this feature to differentiate We can use this feature to differentiate between coding and non-coding regions of the between coding and non-coding regions of the genomegenome
Coding statistics - a function that for a given Coding statistics - a function that for a given DNA sequence computes a likelihood that the DNA sequence computes a likelihood that the sequence is coding for a proteinsequence is coding for a protein
Coding Statistics, Part 2Coding Statistics, Part 2
Many different onesMany different ones
codon usagecodon usage hexamer usagehexamer usage GC contentGC content compositional bias between codon compositional bias between codon
An Example of Coding Statistics, An Example of Coding Statistics,
Part 1 Part 1
Signal Sensors, Part 1Signal Sensors, Part 1 Signal – a string of DNA recognized by the cellular Signal – a string of DNA recognized by the cellular
machinerymachinery
Signal Sensors, Part 2Signal Sensors, Part 2
Various pattern recognition method are Various pattern recognition method are used for identification of these signals:used for identification of these signals:
Expressed Sequence (cDNA) or protein Expressed Sequence (cDNA) or protein sequence available?sequence available? Yes Yes Spliced alignment Spliced alignment
No No Integrated gene prediction Integrated gene prediction Informant genome(s) available?Informant genome(s) available?
Yes Yes Dual or n-genome Dual or n-genome de novode novo predictors: predictors: SGP2, Twinscan, NSCAN, SGP2, Twinscan, NSCAN, (Genomescan – same or cross genome protein (Genomescan – same or cross genome protein
blastx)blastx) No No ab initioab initio predictors predictors
Many newer gene predictors can run in Many newer gene predictors can run in multiple modes depending on the multiple modes depending on the evidence available.evidence available.
MicroarraysMicroarrays
MicroarrayMicroarray
Measure the level of mRNA messages Measure the level of mRNA messages in a cellin a cell
DN
A 1
DN
A 3
DN
A 5
DN
A 6
DN
A 4
DN
A 2
cDNA 4
cDNA 6
Hybridize Gen
e 1
Gen
e 3
Gen
e 5
Gen
e 6
Gen
e 4
Gen
e 2
MeasureRNA 4
RNA 6
RT
slide credits: M. Kellis
controltreatment
(drug, mutation)
updownunchangednot present
x y z
xx
x
xx
yy
yy
zz z
cDNA pools
Typical use of cDNA Microarrays:“Internal” normalization using two colors
Alternative Splicing Alternative Splicing MicroarrayMicroarray
Measure the Measure the expression of the expression of the various probesvarious probes
Infer the Infer the expression of the expression of the different splice different splice forms from the forms from the ratio of the ratio of the inclusion and inclusion and exclusion isoformexclusion isoform
Picture taken from:
J. Calarco et al. Genes and Dev. 21, 2963-2975
“cDNA microarrays” are essentially dot-blots on glass slides
• This slide was made with 16 pins• 4.5 mm pin spacing matches 384-well plates (16 x 24)• Done with robotics• Slides usually coated with poly-lysine• Spots are usually 100-150 microns• Spot spacing is usually 200-300 microns.• Slides are 25 x 75 mm• Easy to deposit 20K spots/slide
0.45 mm
Microarray expression profiling by 2-color assay (“cDNA arrays”)
Array: PCR products6250 yeast ORFs
hybridized cDNAs:green = controlred = experiment
*Schena et al., 1995
Looking at data from a single experiment
3-AT vs.No drug
wild-type vs.wild-type
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Log10
(Intensity)
Log 1
0(Exp
ress
ion
Rat
io)
Slides: 11120c01 -11121c01
P-value < 0.01
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
P-value < 0.01
Log10
(Intensity)
Log 1
0(Exp
ress
ion
Rat
io)
Slides: 11857c01 -11858c01
log10(average intensity)
-2 -1 0 1 2
log 1
0(r
atio
)lo
g 10(r
atio
)
2
1
0
-1
-2
-2 -1 0 1 2
2
1
0
-1
-2
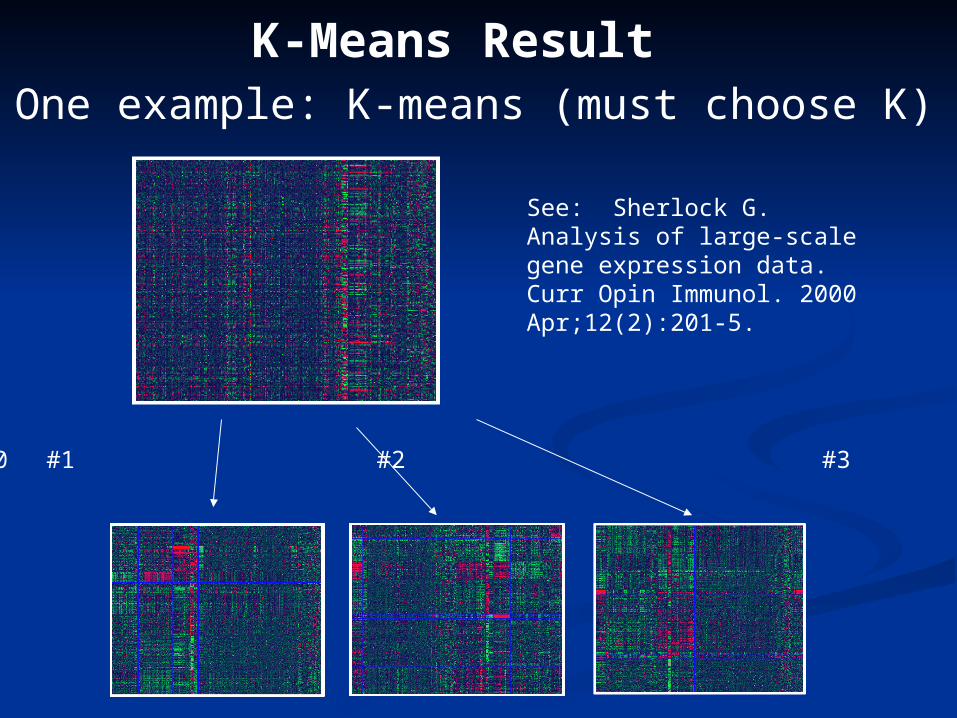
Clustering AlgorithmsClustering Algorithms
b
ed
f
a
c
h
ga b d e f g hc
• K-meansb
ed
f
a
c
h
gc1
c2
c3a b g hcd e f
• Hierarchical
slide credits: M. Kellis
Hierarchical clusteringHierarchical clustering
Bottom-up algorithm:Bottom-up algorithm: Initialization: each point in a Initialization: each point in a
separate clusterseparate cluster At each step:At each step:
Choose the pair of Choose the pair of closest closest clustersclusters
MergeMerge The exact behavior of the The exact behavior of the
algorithm depends on how we algorithm depends on how we define the define the distance CD(X,Y)distance CD(X,Y) between clusters X and Ybetween clusters X and Y
Avoids the problem of Avoids the problem of specifying the number of specifying the number of clustersclusters
b
ed
f
a
c
h
g
slide credits: M. Kellis
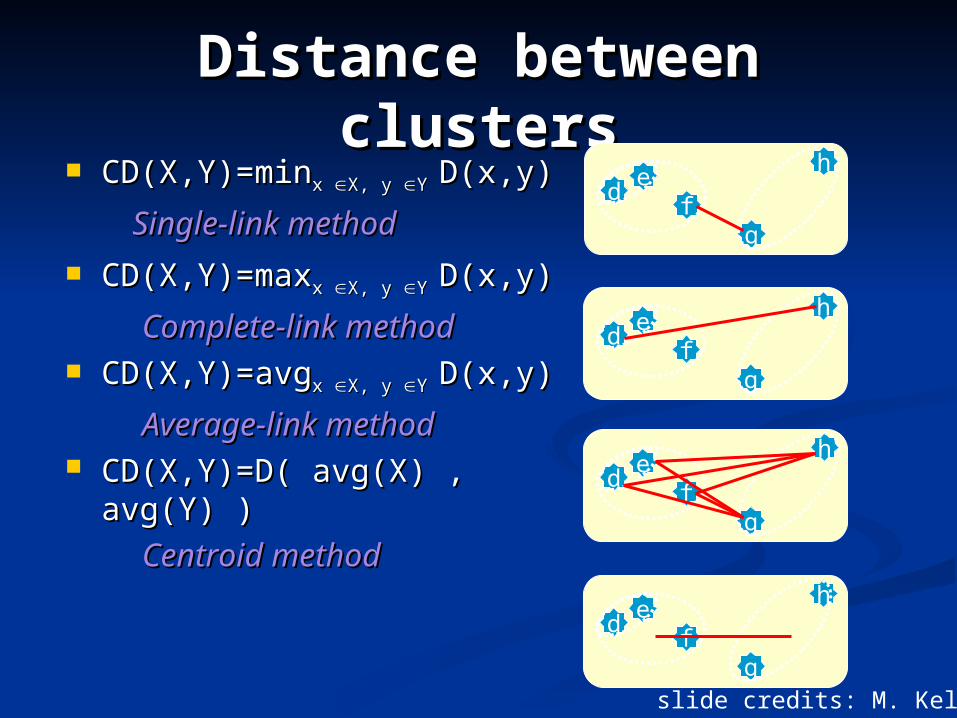
Distance between Distance between clustersclusters
CD(X,Y)=minCD(X,Y)=minx x X, y X, y Y Y D(x,y)D(x,y)
Single-link methodSingle-link method
CD(X,Y)=maxCD(X,Y)=maxx x X, y X, y Y Y D(x,y)D(x,y)
Complete-link methodComplete-link method CD(X,Y)=avgCD(X,Y)=avgx x X, y X, y Y Y D(x,y)D(x,y)
Compute best clusters for given centersCompute best clusters for given centers → → Attach each point to the closest Attach each point to the closest
centercenter Compute best centers for given clustersCompute best centers for given clusters → → Choose the centroid of points in Choose the centroid of points in
clustercluster Until the changes in COST are Until the changes in COST are ““smallsmall””
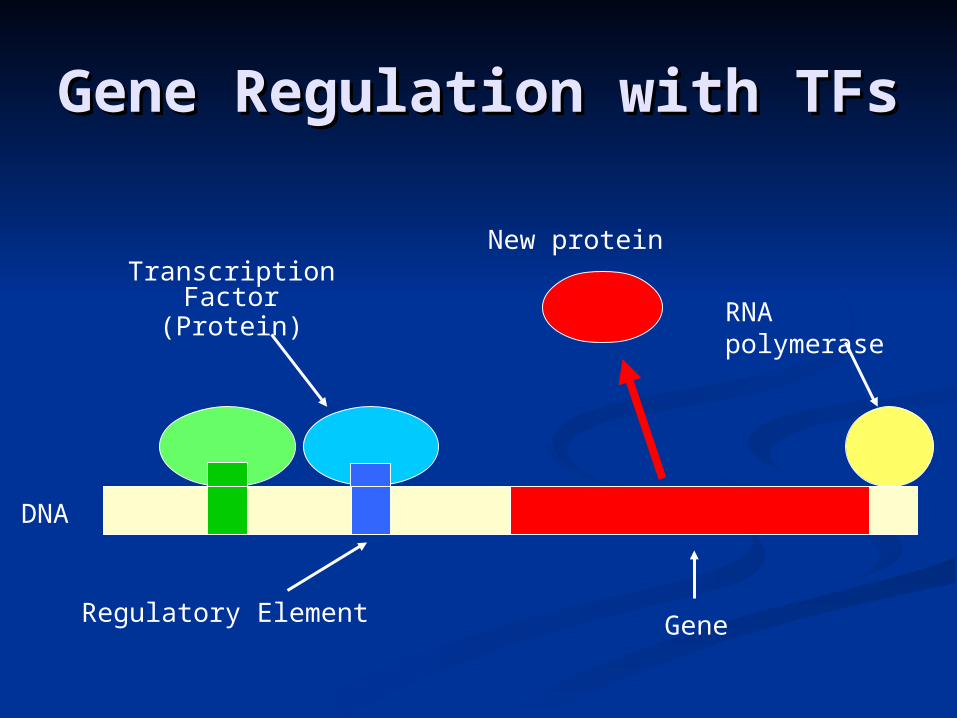
Genes are turned on or off by regulatory Genes are turned on or off by regulatory proteinsproteins
These proteins bind to upstream regulatory These proteins bind to upstream regulatory regions of genes to either attract or block an regions of genes to either attract or block an RNA polymeraseRNA polymerase
Regulatory protein (TF) binds to a short DNA Regulatory protein (TF) binds to a short DNA sequence called a motif (TFBS)sequence called a motif (TFBS)
So finding the same motif in multiple genesSo finding the same motif in multiple genes’’ regulatory regions suggests a regulatory regulatory regions suggests a regulatory relationship amongst those genesrelationship amongst those genes
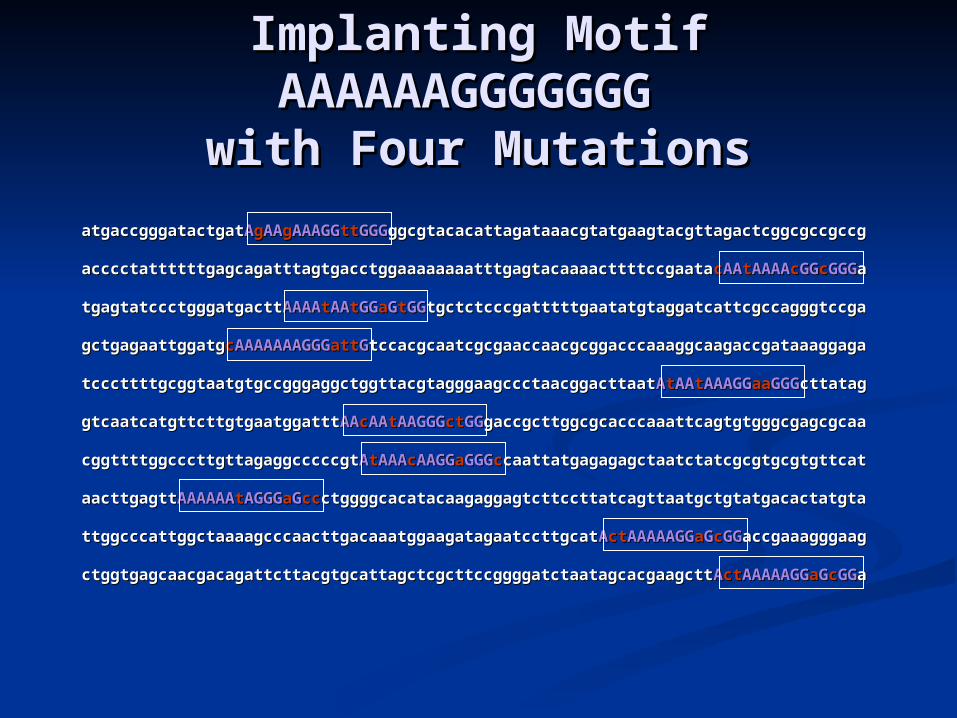
For W = any K-long word occurring in some xFor W = any K-long word occurring in some x ii
Find d( W, S )Find d( W, S )
ReportReport W* = argmin( d( W, S ) ) W* = argmin( d( W, S ) )or, or, ReportReport a local improvement of W a local improvement of W**
Running time: O( K NRunning time: O( K N22 ) )
Advantage:Advantage: TimeTime
Disadvantage:Disadvantage: If the true motif is weak and does not occur in If the true motif is weak and does not occur in datadata
then a random motif may score better than any then a random motif may score better than any instance of true motif instance of true motif
Consensus splice sitesConsensus splice sites
Donor: 7.9 bitsAcceptor: 9.4 bits
Example of Consensus Example of Consensus SequenceSequence
obtained by choosing the most frequent base at each position of obtained by choosing the most frequent base at each position of the multiple alignment of subsequences of interestthe multiple alignment of subsequences of interest
Leads to loss of information and can produce Leads to loss of information and can produce many false positive or false negative predictionsmany false positive or false negative predictions
TATAAT
TATRNT
MELONMANGOHONEYSWEETCOOKY
MONEY
Sequence LogosSequence Logos
TGGGGGATGGGGGA
TGAGAGATGAGAGA
TGGGGGATGGGGGA
TGAGAGATGAGAGA
TGAGGGATGAGGGA
Characteristics of Characteristics of Regulatory MotifsRegulatory Motifs
TinyTiny
Highly VariableHighly Variable
~Constant Size~Constant Size Because a constant-size Because a constant-size
1 2 3 4 5 6 7 8 9 10 11 12 13 141 G A C C A A A T A A G G C A2 G A C C A A A T A A G G C A3 T G A C T A T A A A A G G A4 T G A C T A T A A A A G G A5 T G C C A A A A G T G G T C6 C A A C T A T C T T G G G C7 C A A C T A T C T T G G G C8 C T C C T T A C A T G G G C
T T G C A T A A G T A G T C.45 -.66 .79 1.66 .45 -.66 .79 .45 -.66 .79 .0 1.68 -.66 .79
Score for New Sequence
Sequence Logo & Information content
Motifs in Biological Sequences
(R,l)
1
K
A=(a1,..,aK) – positions of the windows
Priors A has uniform prior
j has Dirichlet(N0) prior – base frequency in genome. N0 is pseudocounts
0.0 1.0
=(1,A,…,w,T) probability of different bases in the window
0=(A,..,T) – background frequencies of nucleotides.
Natural Extensions to Basic ModelCorrelated in Nucleotide Occurrence in Motif: Modeling within-motif dependence for transcription factor binding site predictions. Bioinformatics, 6, 909-916.
Regulatory Modules:De novo cis-regulatory module elicitation for eukaryotic genomes. Proc Nat’l Acad Sci USA, 102, 7079-84
M1
M2
M3
Stop
Start
Gene AGene B
Insertion-Deletion
BALSA: Bayesian algorithm for local sequence alignment Nucl. Acids Res., 30 1268-77.