34
SnappyData Confidential – Do Not Distribute SnappyData Getting Spark ready for real-time, operational analytics www.snappydata.io Suds Menon Co-Founder SnappyData March 2016
| Date post: | 12-Apr-2017 |
| Category: |
Engineering |
| Upload: | airisdata |
| View: | 726 times |
| Download: | 2 times |

SnappyData Confidential – Do Not Distribute
SnappyData Getting Spark ready for real-time,
operational analytics
www.snappydata.io
Suds Menon Co-Founder SnappyData
March 2016

SnappyData Confidential – Do Not Distribute
Because Insights are perishable and degrade over time
The New Arms Race
www.snappydata.io
● Sift through data to get insights to improve your business
● What is your time to insights?
● What is your time to operationalizing insights?
DATA, THE NEW OIL

SnappyData Confidential – Do Not Distribute
Every enterprise today deals with these 4 kinds of data interactions
The Four Horsemen Of Data
www.snappydata.io
OLTP OLAP Streaming Machine Learning

SnappyData Confidential – Do Not Distribute
Who Are We? ● An EMC-Pivotal spinout focused on real time operational
analytics ● New Spark-based open source project started by Pivotal
GemFire founders+engineers
● Decades of in-memory data management experience
● Focus on real-time, operational analytics: Spark inside an OLTP+OLAP database
www.snappydata.io

SnappyData Confidential – Do Not Distribute
SnappyData At Cruising Altitude
Real time operational Analytics – TBs in memory
Single unified HA cluster: OLTP + OLAP + Stream for real-time analytics
Batch design, high throughput
RDB
Rows Txn
Columnar
API
Stream processing
ODBC, JDBC, REST
Spark - Scala, Java, Python, R
HDFS AQP
First commercial project on Approximate Query Processing(AQP)
MPP DB
Index

SnappyData Confidential – Do Not Distribute
SnappyData: A new approach
Single unified HA cluster: OLTP + OLAP + Stream for real-time analytics
Batch design, high throughput
Real-‐time design center -‐ Low latency, HA,
concurrent
Vision: Drastically reduce the cost and complexity in modern big data

SnappyData Confidential – Do Not Distribute
Huge community adoption, slip streaming into Hadoop momentum, great data integration platform
Why Spark? • Most events in life can be analyzed as micro batches • Blends streaming, interactive, and batch analytics • Appeals to Java, R, Python, Scala programmers • Rich set of transformations and libraries • RDD and fault tolerance without replication • Offers Spark SQL as a key capability
www.snappydata.io

SnappyData Confidential – Do Not Distribute
Spark is a compute framework that processes data, not an analytics database
Clearing Up Some Spark Myths
www.snappydata.io
● It is NOT a distributed in-memory database ○ It’s a computational framework with immutable caching
● It is NOT Highly Available ○ Fault tolerance is not the same as HA
● NOT well suited for real time, operational environments ○ Does not handle concurrency well ○ Does not share data very well either

SnappyData Confidential – Do Not Distribute
SnappyData & Lambda
SnappyData Focus
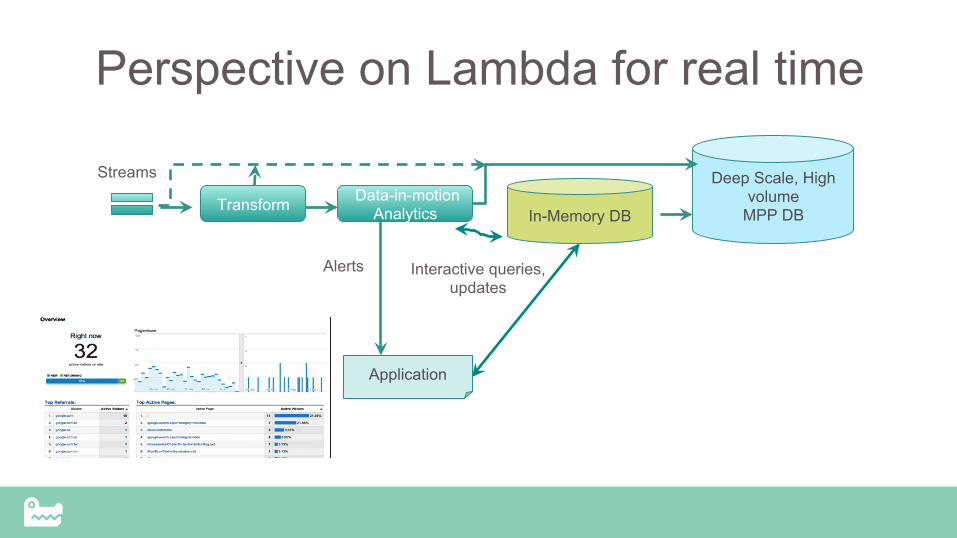
SnappyData Confidential – Do Not Distribute
Perspective on Lambda for real time
In-Memory DB
Interactive queries, updates
Deep Scale, High volume
MPP DB Transform Data-in-motion Analytics
Application
Streams
Alerts

SnappyData Confidential – Do Not Distribute
RELEVANT USECASES
www.snappydata.io

SnappyData Confidential – Do Not Distribute
Use Case Patterns
• Stream ingestion database for spark Process streams, transform, real-time scoring, store, query
• In-memory database for apps Highly concurrent apps, SQL cache, OLTP + OLAP
• Analytic caching pattern Caching for Analytics over any “Big data” store (esp MPP) Federate query between samples and backend

SnappyData Confidential – Do Not Distribute
Typical Use Case Patterns
www.snappydata.io
• Market Surveillance Systems (Trading exchanges, Market makers)
• Real Time Scoring Systems (Product recommendations, real time offers)
• Telco Analytics (Location based services, Predictive analytics)
• Sensor Analytics (Real time alerting for parking management, lighting etc.)
• Ad analytics + Ad placement systems
• Combining structured and unstructured analytics (SQL + ML)
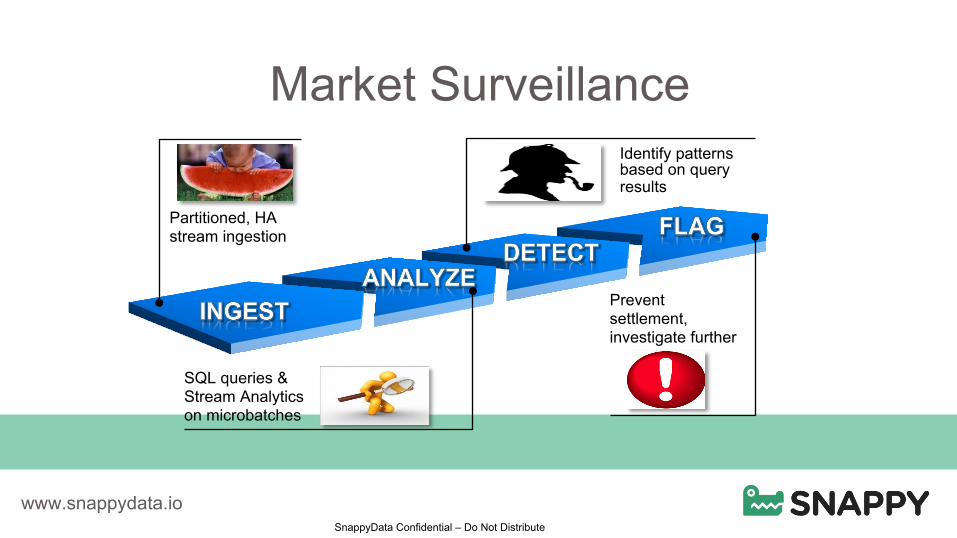
SnappyData Confidential – Do Not Distribute
Market Surveillance
www.snappydata.io
Identify patterns based on query results
Partitioned, HA stream ingestion
Prevent settlement, investigate further
SQL queries & Stream Analytics on microbatches
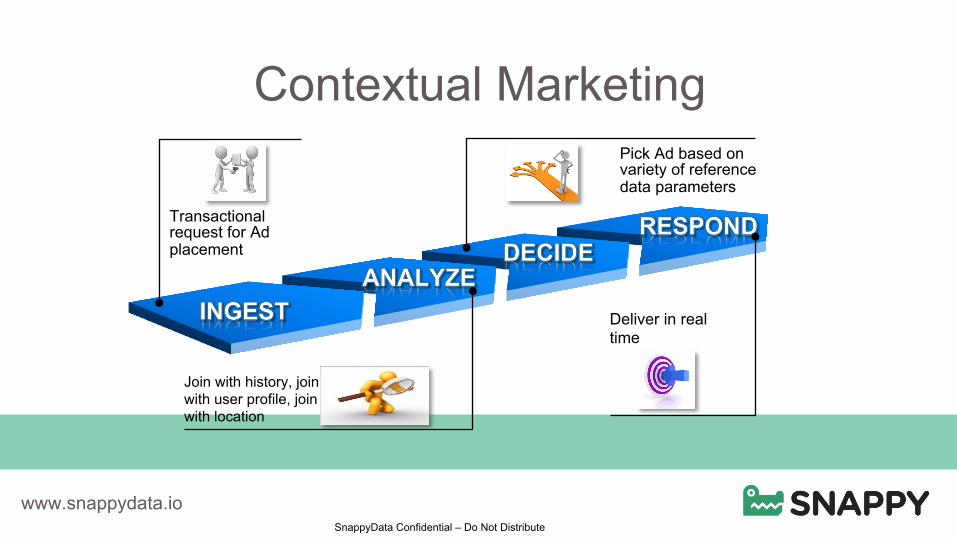
SnappyData Confidential – Do Not Distribute
Contextual Marketing
www.snappydata.io
Pick Ad based on variety of reference data parameters
Transactional request for Ad placement
Deliver in real time
Join with history, join with user profile, join with location

SnappyData Confidential – Do Not Distribute
Location Based Telco Services
www.snappydata.io
Geo Fencing Mobile Marketing Network Analytics
● INGEST, CORRELATE, JOIN WITH HISTORICAL DATA, RESPOND

SnappyData Confidential – Do Not Distribute
Spark Architecture
Driver
Cluster Manager (YARN, Mesos,
Standalone)
Worker Worker
Worker
Executor

SnappyData Confidential – Do Not Distribute
REST API for Job
Submission
Worker Worker
Worker Data Server
Executor Cluster
Manager (YARN, Mesos,
Standalone)
Data Server
Executor
Snappy Infused Spark Architecture
JDBC Clients
ODBC Clients
Job Server Lead Node Lead Node

SnappyData Confidential – Do Not Distribute
Core Components Of SnappyData
SnappyData Confidential – Do Not Distribute
Synergistic with BDS & CF
Spark Based Snappy Core HAWQ/GreenPlum

SnappyData Confidential – Do Not Distribute
Colocated row/column Tables in Spark
Row Table
Column Table
Spark Executor TASK
Spark Block Manager
Stream processing
Row Table
Column Table
Spark Executor TASK
Spark Block Manager
Stream processing
Row Table
Column Table
Spark Executor TASK
Spark Block Manager
Stream processing
● Spark Executors are long lived and shared across multiple apps ● Gem Memory Mgr and Spark Block Mgr integrated
SnappyData Confidential – Do Not Distribute
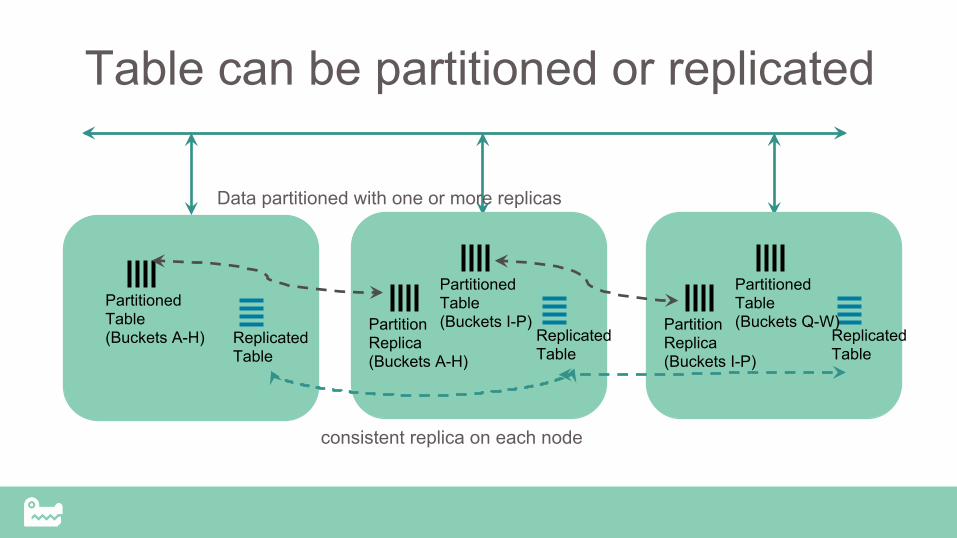
Table can be partitioned or replicated
Replicated Table
Partitioned Table (Buckets A-H) Replicated
Table
Partitioned Table (Buckets I-P)
consistent replica on each node
Partition Replica (Buckets A-H)
Replicated Table
Partitioned Table (Buckets Q-W) Partition
Replica (Buckets I-P)
Data partitioned with one or more replicas

SnappyData Confidential – Do Not Distribute
Linearly scale with shared partitions
Spark Executor
Spark Executor
Kafka queue
Subscriber N-Z
Subscriber A-M
Subscriber A-M Ref data
Linearly scale with partition pruning Input queue, Stream, IMDB, Output queue all share the same partitioning strategy

SnappyData Confidential – Do Not Distribute
Point access, updates, fast writes
● Row tables with PKs are distributed HashMaps ○ with secondary indexes
● Support for transactional semantics ○ read_committed, repeatable_read
● Support for scalable high write rates ○ streaming data goes through stages ○ queue streams, intermediate storage (Delta row buffer),
immutable compressed columns

SnappyData Confidential – Do Not Distribute
SQL And Spark API Support

SnappyData Confidential – Do Not Distribute
Full Spark Compatibility ● Any table is also visible as a DataFrame
● Any RDD[T]/DataFrame can be stored in SnappyData tables
● Tables appear like any JDBC sourced table ○ But, in executor memory by default
● Addtional API for updates, inserts, deletes //Save a dataFrame using the spark context …
context.createExternalTable(”T1", "ROW", myDataFrame.schema, props ); //save using DataFrame API dataDF.write.format("ROW").mode(SaveMode.Append).options(props).saveAsTable(”T1");

SnappyData Confidential – Do Not Distribute
Can we use Statistical methods to shrink data? • It is not always possible to store all the data Many applications (telecoms, ISPs, search engines) can’t keep everything
• It is inconvenient to work with data in full
• It is faster to work with a compact summary Better to explore data on a laptop than a cluster
Ref: Graham Cormode - Sampling for Big Data
Can we use statistical techniques to understand data, synthesize something relatively small but still answer Analytical queries?

SnappyData Confidential – Do Not Distribute
Key feature: Synopses Data ● Maintain stratified samples
○ Intelligent sampling to keep error bounds low
● Probabilistic data ○ TopK for time series (using time aggregation CMS, item
aggregation) ○ Histograms, HyperLogLog, Bloom Filters, Wavelets
CREATE SAMPLE TABLE sample-table-name USING columnar OPTIONS (
BASETABLE ‘table_name’ // source column table or stream table [ SAMPLINGMETHOD "stratified | uniform" ] STRATA name ( QCS (“comma-separated-column-names”) [ FRACTION “frac” ] ),+ // one or more QCS
SnappyData Confidential – Do Not Distribute
www.snappydata.io
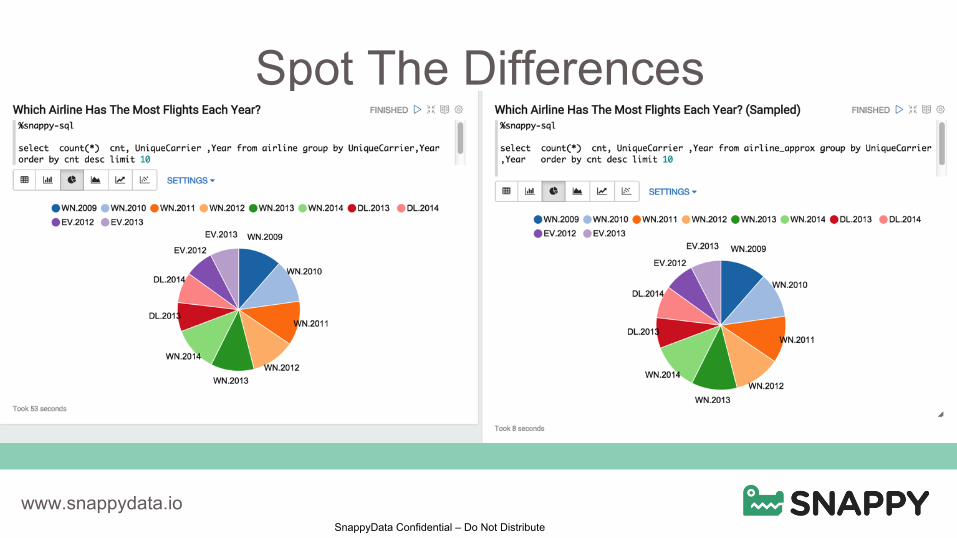
Spot The Differences

SnappyData Confidential – Do Not Distribute
Performance – Spark vs Snappy (TPC-H)
See ACM Sigmod 2016 paper for details Available on snappydata.io blogs

SnappyData Confidential – Do Not Distribute
Performance – Snappy vs in-memoryDB (YCSB)

SnappyData Confidential – Do Not Distribute
Unified OLAP/OLTP streaming w/ Spark
● Far fewer resources: TB problem becomes GB. ○ CPU contention drops
● Far less complex ○ single cluster for stream ingestion, continuous queries, interactive
queries and machine learning
● Much faster ○ compressed data managed in distributed memory in columnar
form reduces volume and is much more responsive
SnappyData Confidential – Do Not Distribute
www.snappydata.io
SnappyData is Open Source ● Beta will be on github before January. We are looking for
contributors!
● Learn more & register for beta: www.snappydata.io
● Connect: ○ twitter: www.twitter.com/snappydata ○ facebook: www.facebook.com/snappydata ○ linkedin: www.linkedin.com/snappydata ○ slack: http://snappydata-slackin.herokuapp.com ○ IRC: irc.freenode.net #snappydata

SnappyData Confidential – Do Not Distribute
Q&A
www.snappydata.io

















