54
GPU Programming and SMAC Case Study Zhengjie Lu Master Student of Electronic Group Electrical Engineering Technische Universiteit Eindhoven, NL
| Date post: | 15-Aug-2015 |
| Category: |
Documents |
| Upload: | zhengjie-lu |
| View: | 18 times |
| Download: | 1 times |

GPU Programming and SMAC Case Study
Zhengjie Lu
Master Student of Electronic Group
Electrical Engineering
Technische Universiteit Eindhoven, NL

Contents
Part 1: GPU Programming1.1 NVIDIA GPU Hardware
1.2 NVIDIA CUDA Programming
1.3 Programming Environment
Part 2: SMAC Case Study2.1 SMAC Introduction
2.2 SMAC Mapping
2.3 Experiment & Analysis
Part 3: Conclusion & Future Development

Concepts
1. GPU• Graphic processing unit or graphic card• Chip vendor: NVIDIA and ATI
2. CUDA Programming• “Compute Unified Device Architecture”• Support by NVIDIA
3. SMAC Application• “Simplified Method for Atmosphere Correction”
PAGE 36/28/15

Part 1: GPU Programming
/ name of department PAGE 46/28/15

1.1 NVIDIA GPU Hardware
• What does NVIDA GPU look like?
/ name of department PAGE 56/28/15

1.1 NVIDIA GPU Hardware
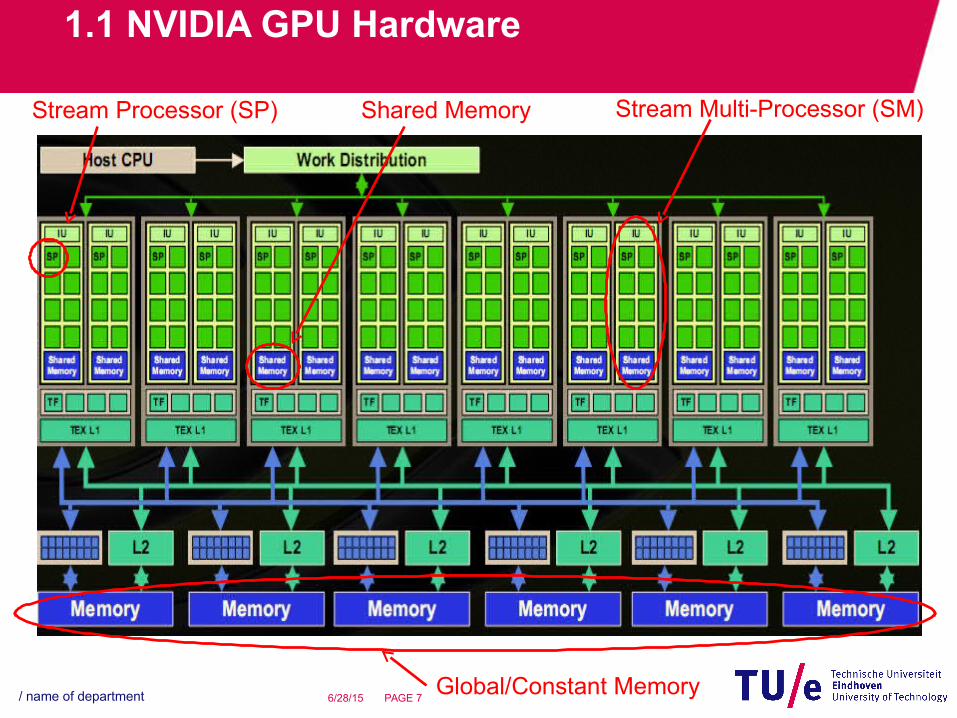
• Example: NVIDIA 8-Series GPU− 128 stream processors (SPs): 1.35GHz per processor− 16 shared memories: shared by every 8 SPs, small
but fast.− 1 global memory: shared by 128 SPs, slow but large.− 1 constant memory: shared by 128 SPs, small but
fast.
/ name of department PAGE 66/28/15
1.1 NVIDIA GPU Hardware
/ name of department PAGE 76/28/15
Stream Processor (SP) Shared Memory
Global/Constant Memory
Stream Multi-Processor (SM)
1.1 NVIDIA GPU Hardware
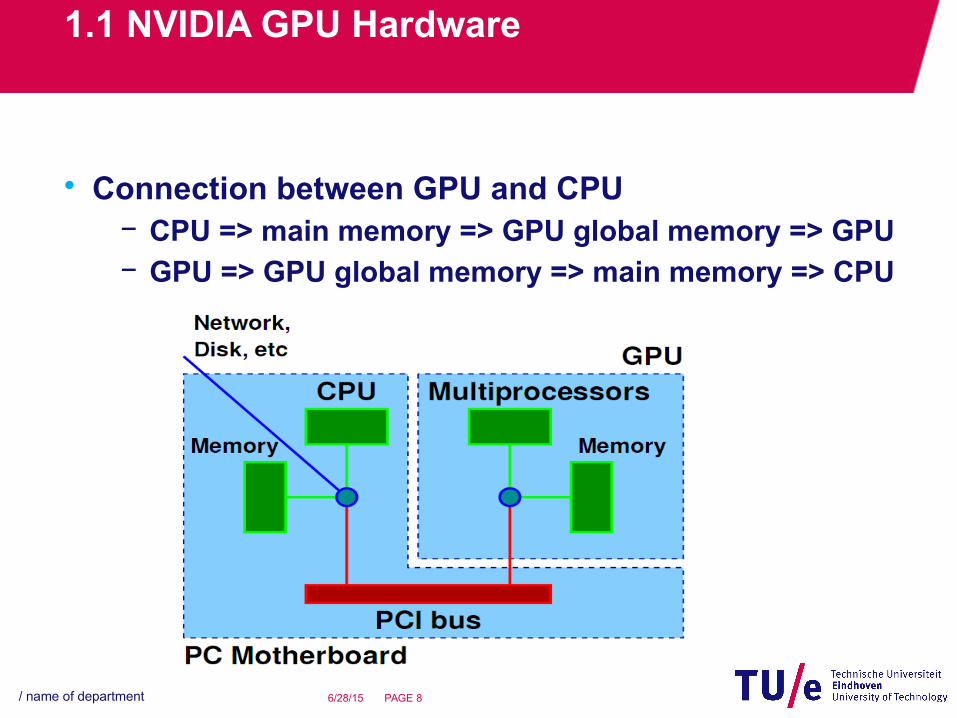
• Connection between GPU and CPU− CPU => main memory => GPU global memory => GPU− GPU => GPU global memory => main memory => CPU
/ name of department PAGE 86/28/15

1.1 NVIDIA GPU Hardware
• Hardware summary:− Multi-threading is supported physically with the SPs.
− SPs inside a SM communicate with each other through the shared memory.
− SMs communicate with each other through the global memory.
− GPU and CPU communicate with each other through their memories: global memory main memory
/ name of department PAGE 96/28/15
1.2 NVIDIA CUDA Programming
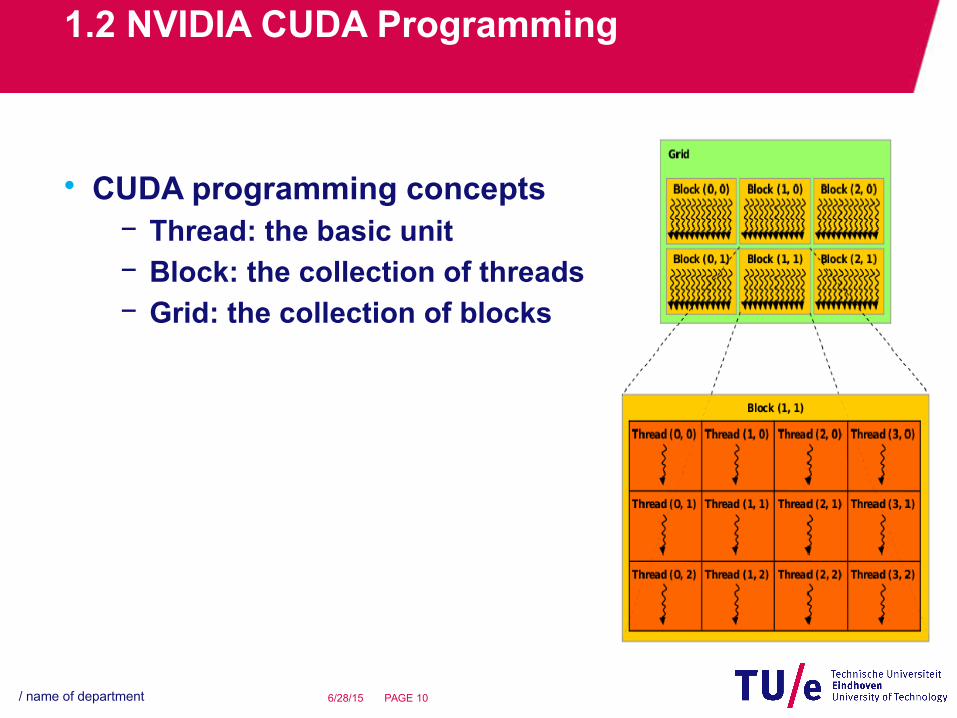
• CUDA programming concepts− Thread: the basic unit− Block: the collection of threads− Grid: the collection of blocks
/ name of department PAGE 106/28/15

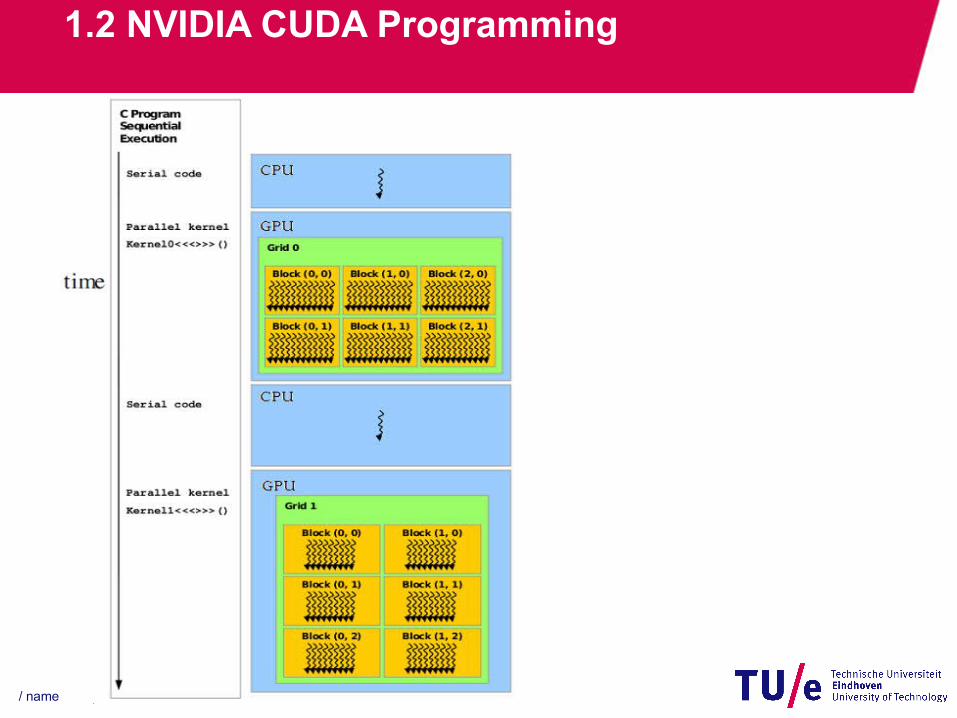
1.2 NVIDIA CUDA Programming
• CUDA programming concepts− A grid is mapped on GPU by the scheduler− A block is mapped on SM by the scheduler− A thread is mapped on SP by the scheduler
/ name of department PAGE 116/28/15
1.2 NVIDIA CUDA Programming
/ name of department PAGE 126/28/15

1.2 NVIDIA CUDA Programming
• CPU programming custom:i. Allocate the CPU memory
ii. Run the CPU kernel
• CUDA programming custom:i. Allocate the GPU memory
ii. Copy the input to the GPU memory
iii. Run the GPU kernel
iv. Copy the output from the GPU memory
/ name of department PAGE 136/28/15

1.2 NVIDIA CUDA Programming
• Example:
/*******************************************************//* File: main.c/* Description: 8x8 matrix addition on CPU /*******************************************************/
//Data definitionconst int mat1[64] = {…};const int mat2[64] = {…};const int mat3[64];
//Matrix addition on CPUvoid matrixAdd_CPU(int index, int* IN1, int* IN2, int* OUT);
// Main bodyint main(){ // Run the matrix addition on CPU matrixAdd_CPU(64, mat1, mat2, mat3);
return 0;}
/****************************************************//* File: main.cu /* Description: 8x8 matrix addition on GPU /****************************************************/
//Data definitionconst int mat1[64] = {…};const int mat2[64] = {…};const int mat3[64];
//Matrix addition on GPUvoid matrixAdd_GPU(int index, int* IN1, int* IN2, int* OUT);
// Main bodyint main(){ // Run the matrix addition on CPU matrixAdd_GPU(row, col, mat1, mat2, mat3);
return 0;}

1.2 NVIDIA CUDA Programming
/**************************************************************//* File: main.c/* Description: 8x8 matrix addition on CPU /******************************************************************///Matrix addition on CPUvoid matrixAdd_CPU(int index, int* IN1, int* IN2, int* OUT){ int i;
for(i = 0; i < index ; i++){ OUT[i] = IN1[i] + IN2[i]; }}
/****************************************************//* File: main.cu /* Description: 8x8 matrix addition on GPU /****************************************************///Matrix addition on GPUvoid matrixAdd_GPU(int index, int* IN1, int* IN2, int* OUT){ int* deviceIN1; int* deviceIN2; int* deviceOUT; dim3 grid(1, 1, 1); dim3 block(index, 1, 1);
cutilSafeCall(cudaMalloc((void**) &deviceIN1, sizeof(int) * index)); cutilSafeCall(cudaMalloc((void**) &deviceIN2, sizeof(int) * index)); cutilSafeCall(cudaMalloc((void**) &deviceOUT, sizeof(int) * index));
cutilSafeCall(cudaMemcpy(deviceIN1, IN1, sizeof(int) * index, cudaMemcpyHostToDevice)); cutilSafeCall(cudaMemcpy(deviceIN2, IN2, sizeof(int) * index, cudaMemcpyHostToDevice));
GPU_kernel<<<grid, block>>>(deviceIN1, deviceIN2, deviceOUT);
cutilSafeCall(cudaMemcpy(OUT, deviceOUT, sizeof(int) * index, cudaMemcpyDeviceToHost));}
Allocate GPU memory
Copy the input
Copy the output
Run the matrix addition
/***********************************//* File: main.cu/* Description: GPU kernel /*****************************************/__global__ voidGPU_kernel( int* IN1, int* IN2, int* OUT){ int tx = threadIdx.x; OUT[tx] = IN1[tx] + IN2[tx];}

1.2 NVIDIA CUDA Programming
• CUDA programming optimization1) Use the registers and shared memories
2) Maximize the number of threads per block
3) Global Memory access coalescence
4) Shared memory bank conflict
5) Group the byte access
6) Stream execution
/ name of department PAGE 166/28/15

1.2 NVIDIA CUDA Programming
1) Use the registers and shared memories− Register is the fastest. (8192 32-bit reg. per SM)− Shared memory is fast, but small. (16KB per SM)− Global memory is slow, but large. (at least 256MB )
/ name of department PAGE 176/28/15

1.2 NVIDIA CUDA Programming
2) Maximize the number of threads per blocki. Determine the register/memory budget per thread,
with the tool cudaProf.
ii. Determine the maximum number of threads, with the tool cudaCal.
iii. Determine the number of blocks
/ name of department PAGE 186/28/15

1.2 NVIDIA CUDA Programming
3) Global Memory access coalescence− Global memory access pattern: 16 threads per time− 16 threads must access the global memory with 16
continuous words− 1st thread must access the global memory address
which is 16-word aligned
/ name of department PAGE 196/28/15
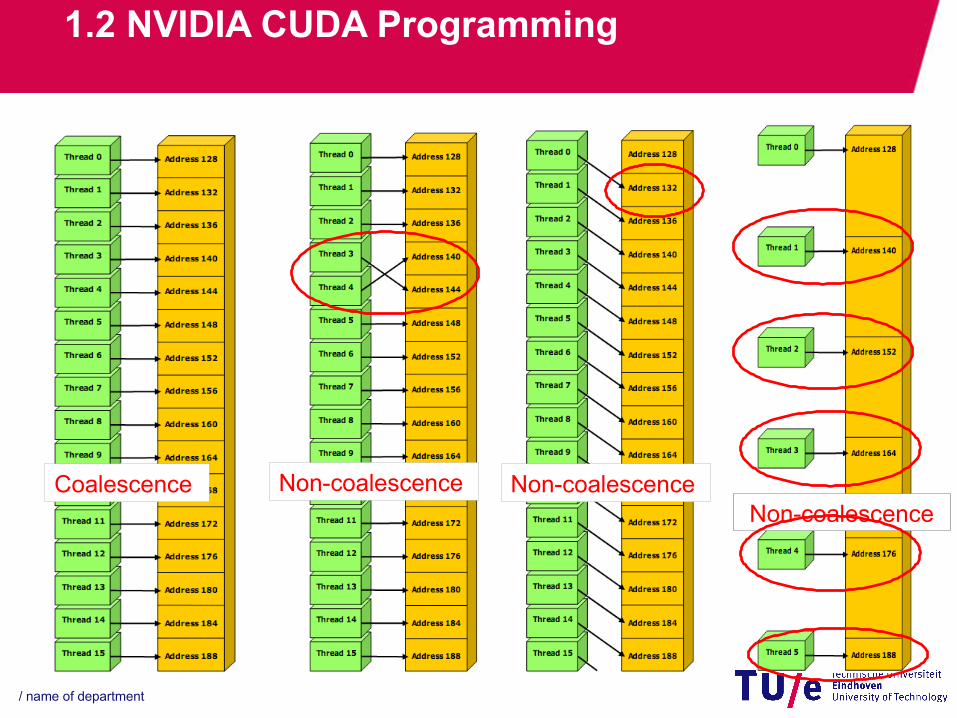
1.2 NVIDIA CUDA Programming
/ name of department
PAGE 206/28/15
Coalescence Non-coalescence Non-coalescenceNon-coalescence

1.2 NVIDIA CUDA Programming
4) Shared memory bank conflict− Shared memory access pattern: 16 thread− 16KB shared memory: 16 x 1KB memory bank− The threads shouldn’t access two different addresses
inside a memory bank
/ name of department PAGE 216/28/15

1.2 NVIDIA CUDA Programming
/ name of department PAGE 226/28/15
No bank confliction Bank confliction Bank confliction
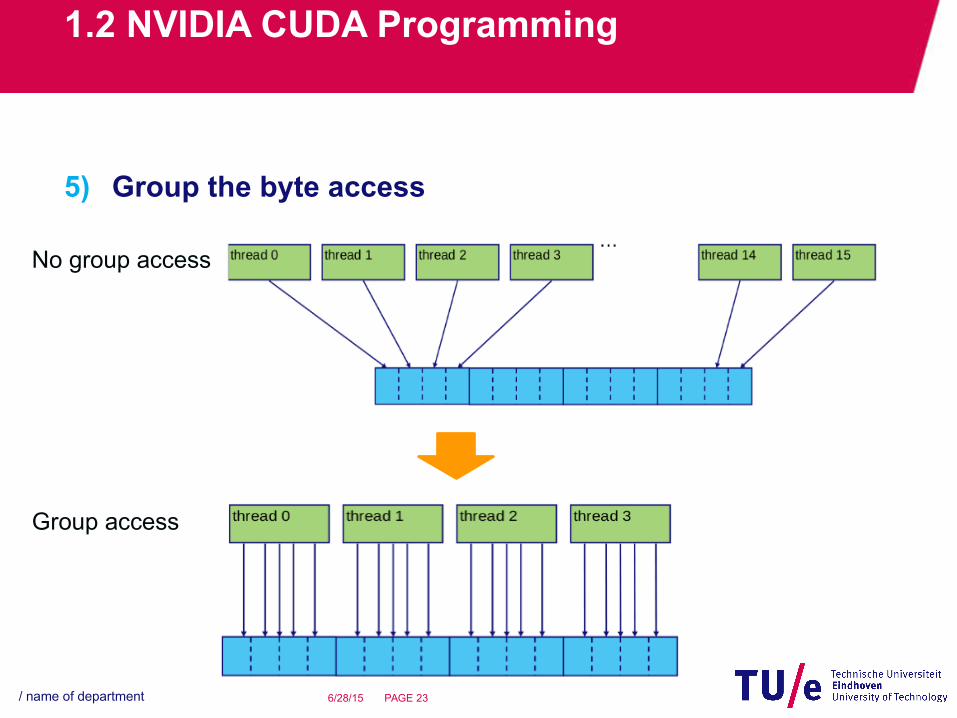
1.2 NVIDIA CUDA Programming
5) Group the byte access
/ name of department PAGE 236/28/15
No group access
Group access

1.2 NVIDIA CUDA Programming
6) Stream execution
/ name of department PAGE 246/28/15

1.2 NVIDIA CUDA Programming
• Tips− Examples: NVIDIA SDK− Programming: “NVIDIA CUDA Programming Guide”− Optimization: “NVIDIA CUDA C Programming: Best
Practices Guide”
/ name of department PAGE 256/28/15

1.3 Programming Environment
1. Preparation− Windows: Microsoft Visual C++ 2008 Express− Linux
/ name of department PAGE 266/28/15

1.3 Programming Environment
2. CUDA installment− Step 1: Download the CUDA package suitable for your
operation system (http://www.nvidia.com/object/cuda_get.html)
− Step 2: Install CUDA Driver− Step 3: Install CUDA Toolkit− Step 4: Install CUDA SDK− Step 5: Verify the installment with running the SDK
examples
/ name of department PAGE 276/28/15

1.3 Programming Environment
3. CUDA project setup (Windows)− Step 1: Download “CUDA Wizard” and install it
(http://www.comp.hkbu.edu.hk/~kyzhao/)− Step2 : Open VC++ 2008 express− Step 3: Click “File” and choose “New/Project”− Step 4: Choose “CUDA” in “Project types” and then
select “CUDAWinApp” in “Visual Studio installed templates”
− Step 5: Name the CUDA project and click “OK”. − Step 6: Click “Solution Explorer”
/ name of department PAGE 286/28/15

1.3 Programming Environment
3. CUDA project setup (Windows)− Step 7: right click “Source Files” and choose
“Add/New Item…”− Step 8: Click “Code” in “Categories” and then choose
“C++. File (.cpp)” in “Visual Studio installed templates”
− Step 9: Name the file as “main.cu” and click “Add”− Step 10: Repeat Step 6~8, and make the other file
named “GPU_kernel.cu”− Step 11: Click “Solution Explorer” and select
“GPU_kernel.cu” under the menu “Source Files”
/ name of department PAGE 296/28/15

1.3 Programming Environment
3. CUDA project setup (Windows)− Step 12: Right click “GPU_kernel.cu”− Step 13: Click “Configuration Properties” and then
click “General”− Step 14: Select “Custom Build Tool” in “Tool” and
click OK− Step 15: Implement your GPU kernel in
“GPU_kernel.cu” and the others in “main.cu”
/ name of department PAGE 306/28/15

1.3 Programming Environment
• Tips− Set up a CUDA project on Linux:
http://sites.google.com/site/5kk70gpu/installation
http://forums.nvidia.com/lofiversion/index.php?f62.html
/ name of department PAGE 316/28/15

Part 2: SMAC Case Study
/ name of department PAGE 326/28/15

2.1 SMAC Introduction
• SMAC algorithm• SMAC as “Simplified Method for Atmospheric
Correction”• A fast computation on the atmosphere reflections
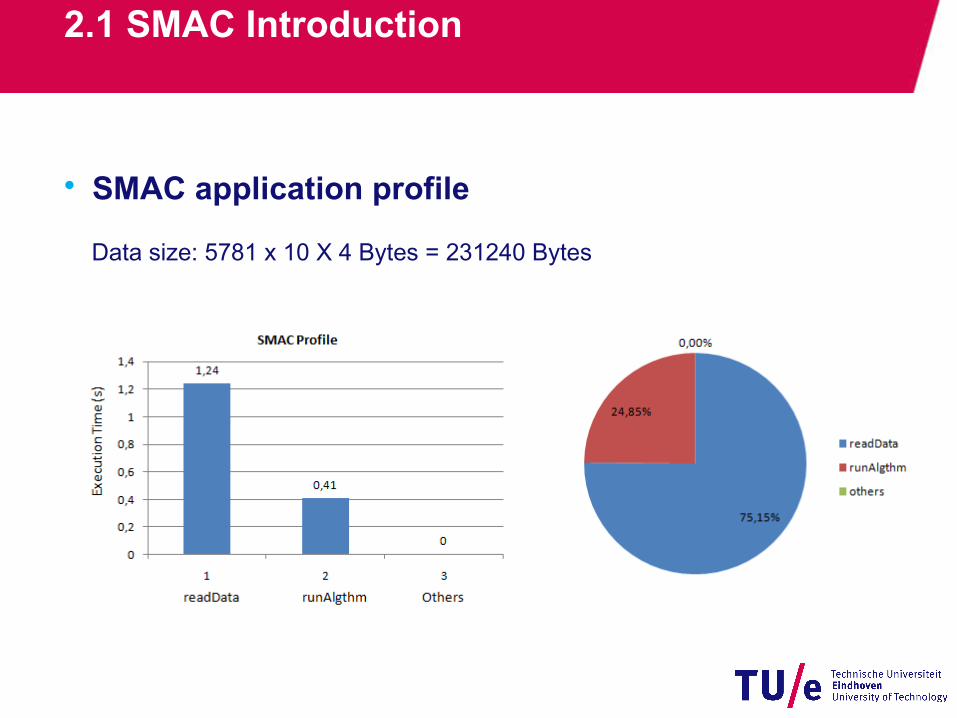
2.1 SMAC Introduction
• SMAC application profile
Data size: 5781 x 10 X 4 Bytes = 231240 Bytes

2.1 SMAC Introduction
• SMAC in the satellite data center
SMAC Algorithm
Image Remapping

2.2 SMAC Mapping
• Mapping approach

2.2 SMAC Mapping
• Mapping approach− GPU.cu: GPU operation functions− GPU_kernel.cu: SMAC kernel
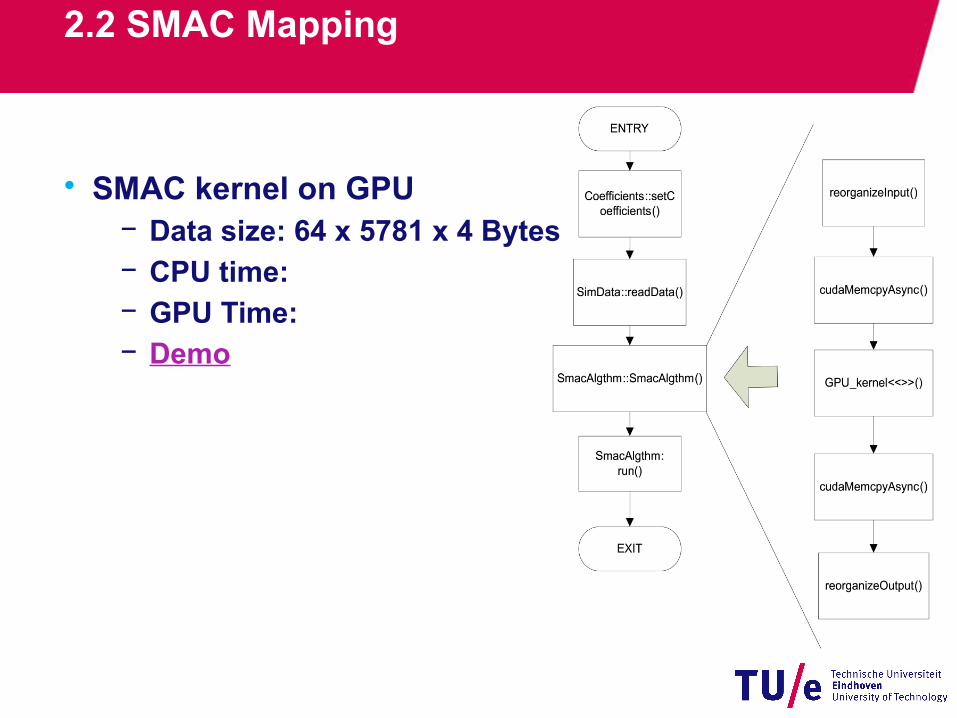
2.2 SMAC Mapping
• SMAC kernel on GPU− Data size: 64 x 5781 x 4 Bytes− CPU time:− GPU Time: − Demo

2.3 Experiment & Analysis
• Experiment Preparation
HARDWARECPU Intel Duo-Core, 2.5GHz per core.GPU nVidia 32-Core GPU, 0.95GHz per
core.Main Memory 4GBPCI-E PCI express 1.0 x 16Operation system Widows Vista EnterpriseCUDA version CUDA 1.1SOFTWAREGPU maximum registers per thread
60
GPU thread number 192 x 4 (#thread per block x #block)CPU thread number 1

2.3 Experiment & Analysis
• Experiment setup− Performance
− GPU improvement
CPU timeGPU Improvement
GPU time
CPU time CPU stop timer CPU start timer -
GPU time GPU stop timer GPU start timer -

2.3 Experiment & Analysis
• Experiment setup− Linear execution-time prediction
CPU time CPU overhead Bytes CPU speed
( )
( )
( )
( )
GPU time GPU memory time GPU run time
GPUmemory overhead Bytes GPU memory speed
GPUkernel overhead Bytes GPU kernel speed
GPUmemory overhead GPUkernel overhead
Bytes GPU memory speed GPU kernel speed
GPU overhe
ad Bytes GPU speed
CPU overhead Bytes CPU speedImprovement
GPU overhead Bytes GPU speed
Bytes CPU speed CPU speed
Bytes GPU speed GPU speed
Only holds for large-size data !!!

2.3 Experiment & Analysis
• Experiment setup− Linear execution-time prediction
55.39 10CPU time data size 61.67 2.41 10GPU time data size 64.45 2.01 10GPU time data size
1-stream:
8-stream:
1-thread:

2.3 Experiment & Analysis
• Experiment result− GPU improvement

2.3 Experiment & Analysis
• Experiment result− Linear execution-time model
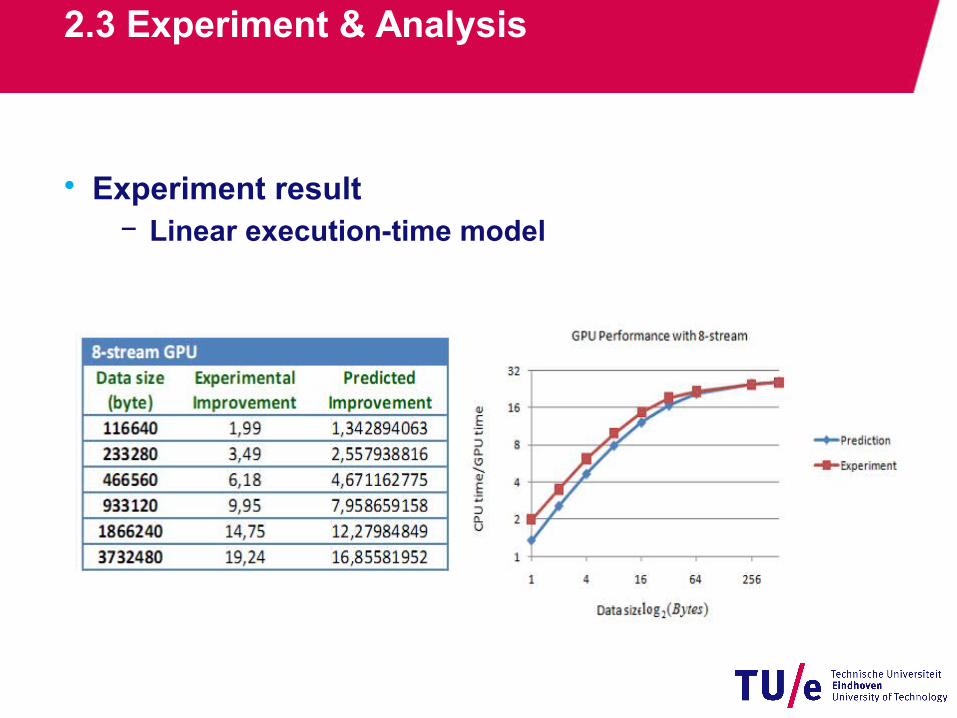
2.3 Experiment & Analysis
• Experiment result− Linear execution-time model

2.3 Experiment & Analysis
• Roofline model
/ name of department PAGE 466/28/15
Log Scaling
Log
Sca
ling

2.3 Experiment & Analysis
• Roofline model with SMAC kernel
Hardware: NVIDIA Quadro FX570MPCI express bandwidth (GB/sec): 4Peak performance (GFlops/sec): 91.2Peak performance without FMAU (Gflops/sec):
30.4
Software: SMAC kernel on GPUData size (Bytes): 5971968
0Issued instruction number (Flops):
4189335552
Execution time (ms): 79.2Instruction density (Flops/Byte): 70.15Instruction Throughput (GFlops/sec):
52.8

2.3 Experiment & Analysis
0.25 2.5 25 2501
10
100 G
Flo
ps/
sec w/out FMA
Peak Performance
70.15
Roofline Model of SMAC on GPU
52.8 GFlops/sec
Flops/Byte
Hard
disk I
O BW

3. Conclusion & Future Development
• SMAC application: − The bottleneck is the hard disk IO.
• SMAC kernel on GPU:− The bottleneck is the computation.− 25 times faster than CPU, when large-size data is
processed with the streams.− The performance ceiling would occur when the data
size is “infinitely” huge.
/ name of department PAGE 496/28/15
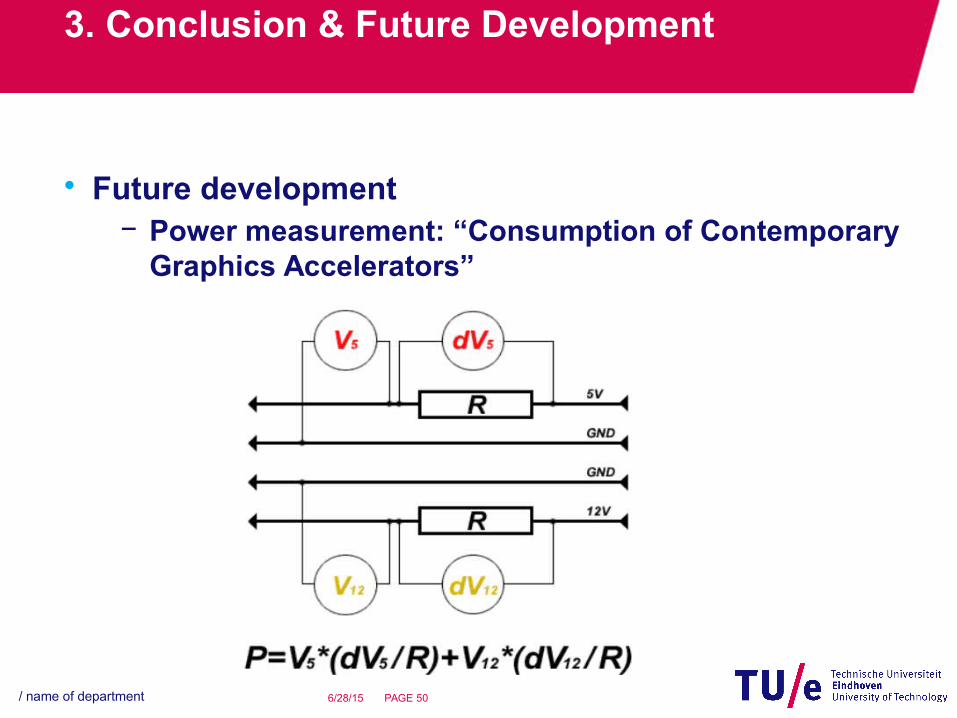
3. Conclusion & Future Development
• Future development− Power measurement: “Consumption of Contemporary
Graphics Accelerators”
/ name of department PAGE 506/28/15

3. Conclusion & Future Development
• Power measurement: physical setup
/ name of department PAGE 516/28/15
8 x 0.12 omg (5W)

3. Conclusion & Future Development
• Future development− Improve the hard disk I/O− Employ more powerful GPU
/ name of department PAGE 526/28/15
0 1 2 3 4 5 6 7 8 90
20
40
60
80
100
120
520937472
260468736
130234368
65117184
32558592
16279296
8139648
4069824
2034912
1017456
508728
254364

Q & A

Thanks for your attention!

















