Page 1
1 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons for Hadoop Applica8ons
Mark Grover | @mark_grover Jonathan Seidman | @jseidman Gwen Shapira | @gwenshap
IEEE BigDataService 2015 | March 30th, 2015 8ny.cloudera.com/app-‐arch-‐slides
Page 2
2 © Cloudera, Inc. All rights reserved.
About the book
• @hadooparchbook • hadooparchitecturebook.com • github.com/hadooparchitecturebook • slideshare.com/hadooparchbook
Page 3
3 © Cloudera, Inc. All rights reserved.
About the presenters
• Principal Solu8ons Architect at Cloudera
• Previously, lead architect at FINRA
• Contributor to Apache Hadoop, HBase, Flume, Avro, Pig and Spark
• Senior Solu8ons Architect/Partner Enablement at Cloudera
• Previously, Technical Lead on the big data team at Orbitz Worldwide
• Co-‐founder of the Chicago Hadoop User Group and Chicago Big Data
Ted Malaska Jonathan Seidman
Page 4
4 © Cloudera, Inc. All rights reserved.
About the presenters
• Solu8ons Architect turned So]ware Engineer at Cloudera
• Commi^er on Apache Sqoop
• Contributor to Apache Flume and Apache Kaaa
• So]ware Engineer at Cloudera
• Commi^er on Apache Bigtop, PMC member on Apache Sentry (incuba8ng)
• Contributor to Apache Hadoop, Spark, Hive, Sqoop, Pig and Flume
Gwen Shapira Mark Grover
Page 5
5 © Cloudera, Inc. All rights reserved.
Logis8cs
• Break at 10:30-‐11:00 PM • Ques8ons at the end of each sec8on
Page 6
6 © Cloudera, Inc. All rights reserved.
Case Study Clickstream Analysis
Page 7
7 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 8
8 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 9
9 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 10
10 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 11
11 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 12
12 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 13
13 © Cloudera, Inc. All rights reserved.
Analy8cs
Page 14
14 © Cloudera, Inc. All rights reserved.
Web Logs – Combined Log Format
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1”
Page 15
15 © Cloudera, Inc. All rights reserved.
Clickstream Analy8cs
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
Page 16
16 © Cloudera, Inc. All rights reserved.
Similar use-‐cases
• Sensors – heart, agriculture, etc. • Casinos – session of a person at a table
Page 17
17 © Cloudera, Inc. All rights reserved.
Pre-‐Hadoop Architecture Clickstream Analysis
Page 18
18 © Cloudera, Inc. All rights reserved.
Click Stream Analysis (Before Hadoop)
Web logs (full fidelity) (2 weeks)
Data Warehouse Transform/Aggregate Business
Intelligence
Tape Archive
Page 19
19 © Cloudera, Inc. All rights reserved.
Problems with Pre-‐Hadoop Architecture • Full fidelity data is stored for small amount of 8me (~weeks). • Older data is sent to tape, or even worse, deleted! • Inflexible workflow -‐ think of all aggrega8ons beforehand
Page 20
20 © Cloudera, Inc. All rights reserved.
Effects of Pre-‐Hadoop Architecture • Regenera8ng aggregates is expensive or worse, impossible • Can’t correct bugs in the workflow/aggrega8on logic • Can’t do experiments on exis8ng data
Page 21
21 © Cloudera, Inc. All rights reserved.
Why is Hadoop A Great Fit? Clickstream Analysis
Page 22
22 © Cloudera, Inc. All rights reserved.
Why is Hadoop a great fit? • Volume of clickstream data is huge • Velocity at which it comes in is high • Variety of data is diverse -‐ semi-‐structured data • Hadoop enables
• ac8ve archival of data • Aggrega8on jobs • Querying the above aggregates or raw fidelity data
Page 23
23 © Cloudera, Inc. All rights reserved.
Click Stream Analysis (with Hadoop)
Web logs Hadoop Business Intelligence
Ac8ve archive (no tape) Aggrega8on engine Querying engine
Page 24
24 © Cloudera, Inc. All rights reserved.
Challenges of Hadoop Implementa8on
Page 25
25 © Cloudera, Inc. All rights reserved.
Challenges of Hadoop Implementa8on
Page 26
26 © Cloudera, Inc. All rights reserved.
Other challenges -‐ Architectural Considera8ons
• Storage managers? • HDFS? HBase?
• Data storage and modeling: • File formats? Compression? Schema design?
• Data movement • How do we actually get the data into Hadoop? How do we get it out?
• Metadata • How do we manage data about the data?
• Data access and processing • How will the data be accessed once in Hadoop? How can we transform it? How do we query it?
• Orchestra8on • How do we manage the workflow for all of this?
Page 27
27 © Cloudera, Inc. All rights reserved.
Case Study Requirements Overview of Requirements
Page 28
28 © Cloudera, Inc. All rights reserved.
Overview of Requirements
Data Sources Inges8on
Raw Data Storage (Formats, Schema)
Processed Data Storage (Formats, Schema)
Processing Data Consump8on
Orchestra8on (Scheduling, Managing, Monitoring)
Page 29
29 © Cloudera, Inc. All rights reserved.
Case Study Requirements Data Inges8on
Page 30
30 © Cloudera, Inc. All rights reserved.
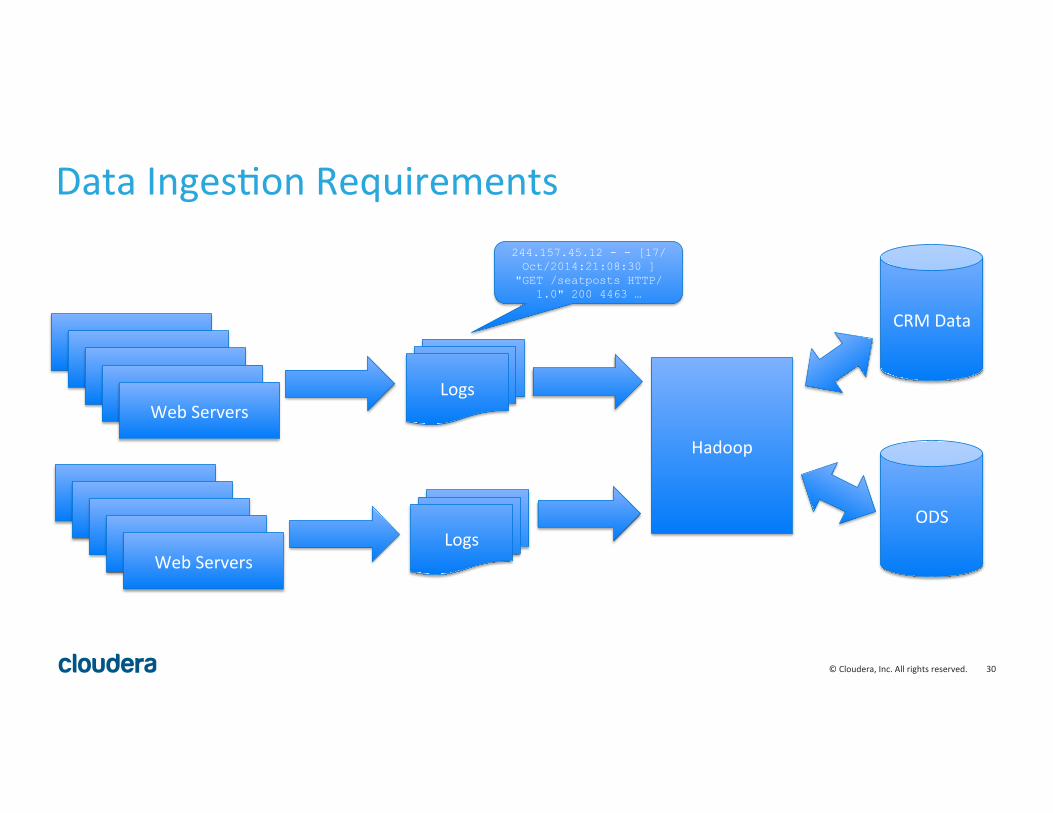
Data Inges8on Requirements
Web Servers Web Servers Web Servers Web Servers Web Servers
Logs
244.157.45.12 - - [17/Oct/2014:21:08:30 ]
"GET /seatposts HTTP/1.0" 200 4463 …
CRM Data
ODS Web Servers Web Servers Web Servers Web Servers Web Servers
Logs
Hadoop
Page 31
31 © Cloudera, Inc. All rights reserved.
Data Inges8on Requirements
• So we need to be able to support: • Reliable inges8on of large volumes of semi-‐structured event data arriving with high velocity (e.g. logs).
• Timeliness of data availability – data needs to be available for processing to meet business service level agreements.
• Periodic inges8on of data from rela8onal data stores.
Page 32
32 © Cloudera, Inc. All rights reserved.
Case Study Requirements Data Storage
Page 33
33 © Cloudera, Inc. All rights reserved.
Data Storage Requirements
Store all the data Make the data accessible for processing
Compress the data
Page 34
34 © Cloudera, Inc. All rights reserved.
Case Study Requirements Data Processing
Page 35
35 © Cloudera, Inc. All rights reserved.
Processing requirements
Be able to answer ques8ons like: • What is my website’s bounce rate?
• i.e. how many % of visitors don’t go past the landing page? • Which marke8ng channels are leading to most sessions? • Do a^ribu8on analysis
• Which channels are responsible for most conversions?
Page 36
36 © Cloudera, Inc. All rights reserved.
Sessioniza8on
Website visit
Visitor 1 Session 1
Visitor 1 Session 2
Visitor 2 Session 1
> 30 minutes
Page 37
37 © Cloudera, Inc. All rights reserved.
Case Study Requirements Orchestra8on
Page 38
38 © Cloudera, Inc. All rights reserved.
Orchestra8on is simple We just need to execute ac8ons One a]er another
Page 39
39 © Cloudera, Inc. All rights reserved.
Actually, we also need to handle errors And user no8fica8ons ….
Page 40
40 © Cloudera, Inc. All rights reserved.
And… • Re-‐start workflows a]er errors • Reuse of ac8ons in mul8ple workflows • Complex workflows with decision points • Trigger ac8ons based on events • Tracking metadata • Integra8on with enterprise so]ware • Data lifecycle • Data quality control • Reports
Page 41
41 © Cloudera, Inc. All rights reserved.
OK, maybe we need a product To help us do all that
Page 42
42 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Modeling
Page 43
43 © Cloudera, Inc. All rights reserved.
Data Modeling Considera8ons
• We need to consider the following in our architecture: • Storage layer – HDFS? HBase? Etc. • File system schemas – how will we lay out the data? • File formats – what storage formats to use for our data, both raw and processed data?
• Data compression formats?
Page 44
44 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Modeling – Storage Layer
Page 45
45 © Cloudera, Inc. All rights reserved.
Data Storage Layer Choices
• Two likely choices for raw data:
Page 46
46 © Cloudera, Inc. All rights reserved.
Data Storage Layer Choices
• Stores data directly as files • Fast scans • Poor random reads/writes
• Stores data as Hfiles on HDFS • Slow scans • Fast random reads/writes
Page 47
47 © Cloudera, Inc. All rights reserved.
Data Storage – Storage Manager Considera8ons
• Incoming raw data: • Processing requirements call for batch transforma8ons across mul8ple records – for example sessioniza8on.
• Processed data: • Access to processed data will be via things like analy8cal queries – again requiring access to mul8ple records.
• We choose HDFS • Processing needs in this case served be^er by fast scans.
Page 48
48 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Modeling – Raw Data Storage
Page 49
49 © Cloudera, Inc. All rights reserved.
Storage Formats – Raw Data and Processed Data
Processed Data
Raw Data
Page 50
50 © Cloudera, Inc. All rights reserved.
Data Storage – Format Considera8ons
Logs (plain text)
Page 51
51 © Cloudera, Inc. All rights reserved.
Data Storage – Format Considera8ons
Logs (plain text)
Logs (plain text)
Logs (plain text)
Logs (plain text)
Logs (plain text)
Logs (plain text)
Logs
Logs Logs
Logs Logs
Page 52
52 © Cloudera, Inc. All rights reserved.
Data Storage – Compression
snappy
Well, maybe. But not spli^able.
X Spli^able. Gewng be^er…
Hmmm…. Spli^able, but no...
Page 53
53 © Cloudera, Inc. All rights reserved.
Raw Data Storage – More About Snappy
• Designed at Google to provide high compression speeds with reasonable compression.
• Not the highest compression, but provides very good performance for processing on Hadoop.
• Snappy is not spli^able though, which brings us to…
Page 54
54 © Cloudera, Inc. All rights reserved.
Hadoop File Types
• Formats designed specifically to store and process data on Hadoop: • File based – SequenceFile • Serializa8on formats – Thri], Protocol Buffers, Avro • Columnar formats – RCFile, ORC, Parquet
Page 55
55 © Cloudera, Inc. All rights reserved.
SequenceFile
• Stores records as binary key/value pairs.
• SequenceFile “blocks” can be compressed.
• This enables spli^ability with non-‐spli^able compression.
Page 56
56 © Cloudera, Inc. All rights reserved.
Avro
• Kinda SequenceFile on Steroids.
• Self-‐documen8ng – stores schema in header.
• Provides very efficient storage.
• Supports spli^able compression.
Page 57
57 © Cloudera, Inc. All rights reserved.
Our Format Recommenda8ons for Raw Data…
• Avro with Snappy • Snappy provides op8mized compression. • Avro provides compact storage, self-‐documen8ng files, and supports schema evolu8on.
• Avro also provides be^er failure handling than other choices. • SequenceFiles would also be a good choice, and are directly supported by inges8on tools in the ecosystem. • But only supports Java.
Page 58
58 © Cloudera, Inc. All rights reserved.
But Note…
• For simplicity, we’ll use plain text for raw data in our example.
Page 59
59 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Modeling – Processed Data Storage
Page 60
60 © Cloudera, Inc. All rights reserved.
Storage Formats – Raw Data and Processed Data
Processed Data
Raw Data
Page 61
61 © Cloudera, Inc. All rights reserved.
Access to Processed Data
Column A Column B Column C Column D
Value Value Value Value
Value Value Value Value
Value Value Value Value
Value Value Value Value
Analy8cal Queries
Page 62
62 © Cloudera, Inc. All rights reserved.
Columnar Formats
• Eliminates I/O for columns that are not part of a query. • Works well for queries that access a subset of columns. • O]en provide be^er compression. • These add up to drama8cally improved performance for many queries.
1 2014-‐10-‐13 abc
2 2014-‐10-‐14 def
3 2014-‐10-‐15 ghi
1 2 3
2014-‐10-‐13 2014-‐10-‐14 2014-‐10-‐15
abc def ghi
Page 63
63 © Cloudera, Inc. All rights reserved.
Columnar Choices – RCFile
• Designed to provide efficient processing for Hive queries. • Only supports Java. • No Avro support. • Limited compression support. • Sub-‐op8mal performance compared to newer columnar formats.
Page 64
64 © Cloudera, Inc. All rights reserved.
Columnar Choices – ORC
• A be^er RCFile. • Also designed to provide efficient processing of Hive queries. • Only supports Java.
Page 65
65 © Cloudera, Inc. All rights reserved.
Columnar Choices – Parquet
• Designed to provide efficient processing across Hadoop programming interfaces – MapReduce, Hive, Impala, Pig.
• Mul8ple language support – Java, C++ • Good object model support, including Avro. • Broad vendor support. • These features make Parquet a good choice for our processed data.
Page 66
66 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Modeling – Schema Design
Page 67
67 © Cloudera, Inc. All rights reserved.
HDFS Schema Design – One Recommenda8on
/etl – Data in various stages of ETL workflow /data – processed data to be shared data with the en8re organiza8on /tmp – temp data from tools or shared between users /user/<username> -‐ User specific data, jars, conf files /app – Everything but data: UDF jars, HQL files, Oozie workflows
Page 68
68 © Cloudera, Inc. All rights reserved.
Par88oning
• Split the dataset into smaller consumable chunks. • Rudimentary form of “indexing”. Reduces I/O needed to process queries.
Page 69
69 © Cloudera, Inc. All rights reserved.
Par88oning
dataset col=val1/file.txt col=val2/file.txt … col=valn/file.txt
dataset file1.txt file2.txt … filen.txt
Un-‐par88oned HDFS directory structure
Par88oned HDFS directory structure
Page 70
70 © Cloudera, Inc. All rights reserved.
Par88oning considera8ons
• What column to par88on by? • Don’t have too many par88ons (<10,000) • Don’t have too many small files in the par88ons • Good to have par88on sizes at least ~1 GB, generally a mul8ple of block size.
• We’ll par88on by 6mestamp. This applies to both our raw and processed data.
Page 71
71 © Cloudera, Inc. All rights reserved.
Par88oning For Our Case Study
• Raw dataset: • /etl/BI/casualcyclist/clicks/rawlogs/year=2014/month=10/day=10!
• Processed dataset: • /data/bikeshop/clickstream/year=2014/month=10/day=10!
Page 72
72 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Inges8on
Page 73
73 © Cloudera, Inc. All rights reserved.
• Omniture data on FTP • Apps • App Logs • RDBMS
Typical Clickstream data sources
Page 74
74 © Cloudera, Inc. All rights reserved.
Gewng Files from FTP
Page 75
75 © Cloudera, Inc. All rights reserved.
curl ftp://myftpsite.com/sitecatalyst/myreport_2014-10-05.tar.gz --user name:password | hdfs -put - /etl/clickstream/raw/sitecatalyst/myreport_2014-10-05.tar.gz
Don’t over-‐complicate things
Page 76
76 © Cloudera, Inc. All rights reserved.
Apache NiFi
Page 77
77 © Cloudera, Inc. All rights reserved.
Reliable, distributed and highly available systems That allow streaming events to Hadoop
Event Streaming – Flume and Kaaa
Page 78
78 © Cloudera, Inc. All rights reserved.
• Many available data collec8on sources • Well integrated into Hadoop • Supports file transforma8ons • Can implement complex topologies • Very low latency • No programming required
Flume:
Page 79
79 © Cloudera, Inc. All rights reserved.
“We just want to grab data from this directory and write it to HDFS”
We use Flume when:
Page 80
80 © Cloudera, Inc. All rights reserved.
• Very high-‐throughput publish-‐subscribe messaging • Highly available • Stores data and can replay • Can support many consumers with no extra latency
Kaaa is:
Page 81
81 © Cloudera, Inc. All rights reserved.
“Kaaa is awesome. We heard it cures cancer”
Use Kaaa When:
Page 82
82 © Cloudera, Inc. All rights reserved.
• Use Flume with a Kaaa Source • Allows to get data from Kaaa, run some transforma8ons write to HDFS, HBase or Solr
Actually, why choose?
Page 83
83 © Cloudera, Inc. All rights reserved.
• We want to ingest events from log files • Flume’s Spooling Directory source fits • With HDFS Sink
• We would have used Kaaa if… • We wanted the data in non-‐Hadoop systems too
In Our Example…
Page 84
84 © Cloudera, Inc. All rights reserved.
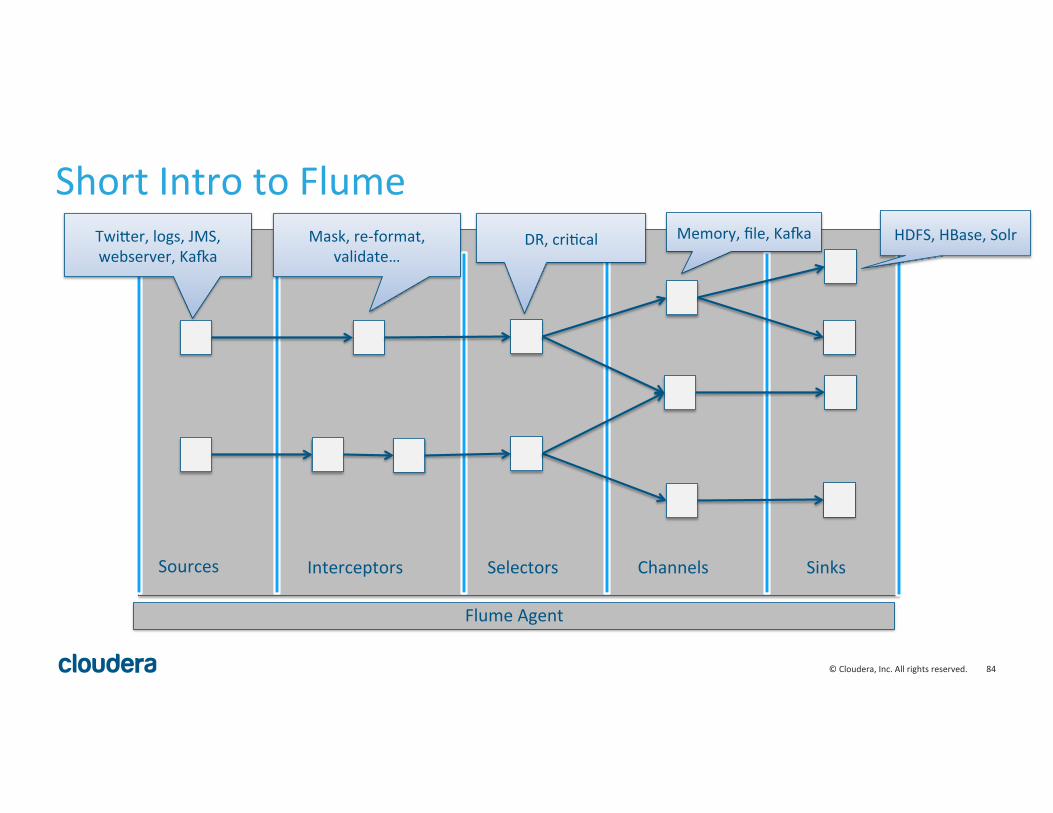
Sources Interceptors Selectors Channels Sinks
Flume Agent
Short Intro to Flume Twi^er, logs, JMS, webserver, Kaaa
Mask, re-‐format, validate…
DR, cri8cal Memory, file, Kaaa HDFS, HBase, Solr
Page 85
85 © Cloudera, Inc. All rights reserved.
Configura8on
• Declara8ve • No coding required. • Configura8on specifies how components are wired together.
Page 86
86 © Cloudera, Inc. All rights reserved.
Interceptors
• Mask fields • Validate informa8on against external source
• Extract fields • Modify data format • Filter or split events
Page 87
87 © Cloudera, Inc. All rights reserved.
Any sufficiently complex configura8on Is indis8nguishable from code
Page 88
88 © Cloudera, Inc. All rights reserved.
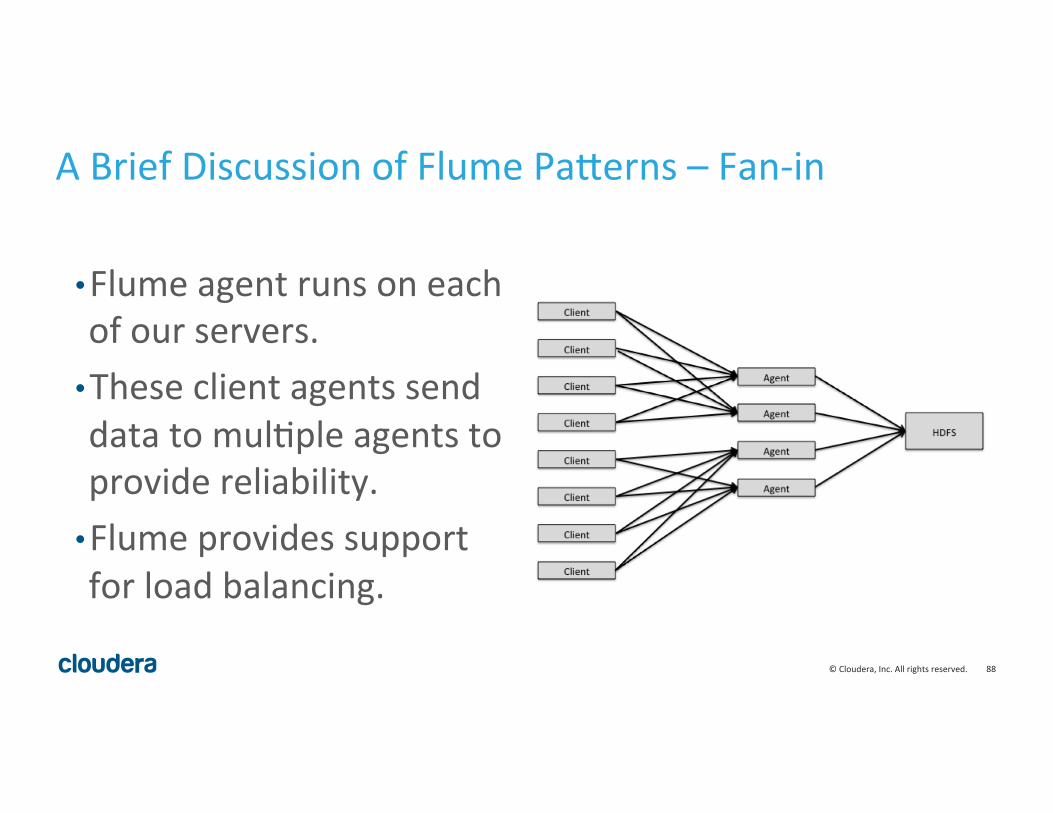
A Brief Discussion of Flume Pa^erns – Fan-‐in
• Flume agent runs on each of our servers.
• These client agents send data to mul8ple agents to provide reliability.
• Flume provides support for load balancing.
Page 89
89 © Cloudera, Inc. All rights reserved.
A Brief Discussion of Flume Pa^erns – Spliwng
• Common need is to split data on ingest.
• For example: • Sending data to mul8ple clusters for DR.
• To mul8ple des8na8ons. • Flume also supports par88oning, which is key to our implementa8on.
Page 90
90 © Cloudera, Inc. All rights reserved.
Flume Agent
Web Logs Spooling Dir
Source Timestamp Interceptor
File Channel
Avro Sink Avro Sink Avro Sink
Flume Architecture – Client Tier
Web Server Flume Agent
Page 91
91 © Cloudera, Inc. All rights reserved.
Flume Architecture – Collector Tier
Flume Agent
Flume Agent
HDFS Avro Source
File Channel
HDFS Sink HDFS Sink
Page 92
92 © Cloudera, Inc. All rights reserved.
• Add Kaaa producer to our webapp • Send clicks and searches as messages • Flume can ingest events from Kaaa • We can add a second consumer for real-‐8me processing in SparkStreaming
• Another consumer for aler8ng… • And maybe a batch consumer too
What if…. We were to use Kaaa?
Page 93
93 © Cloudera, Inc. All rights reserved.
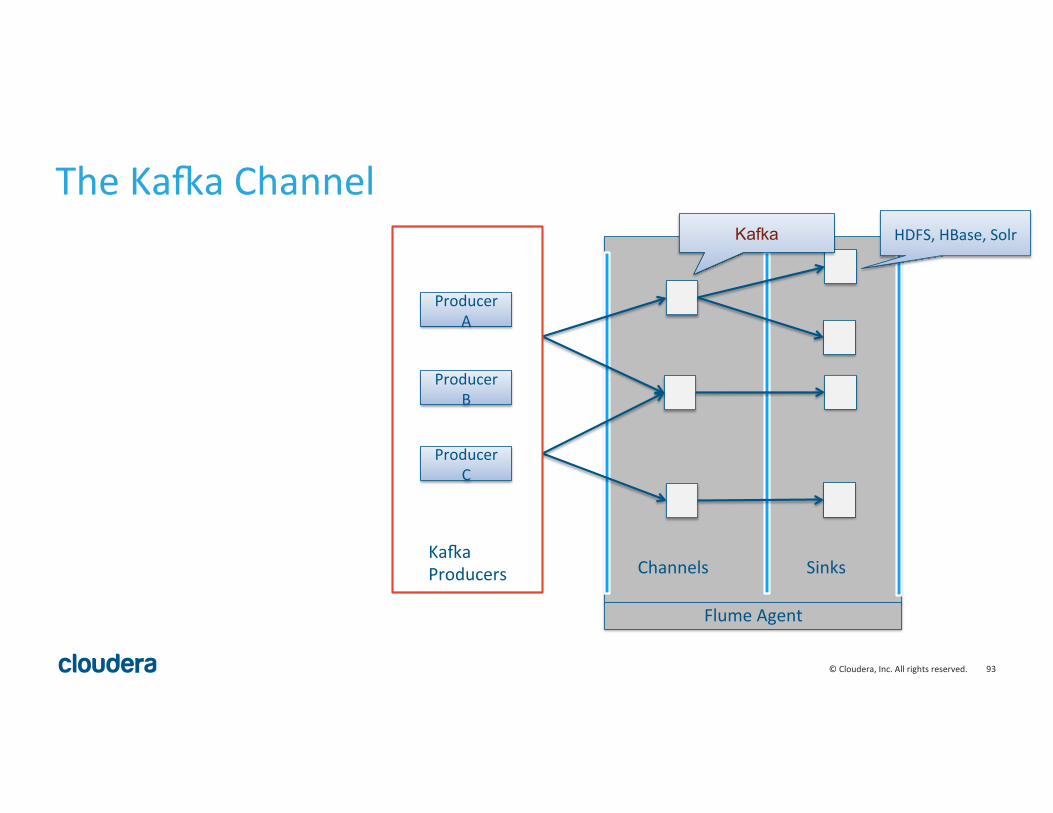
Channels Sinks
Flume Agent
The Kaaa Channel Kafka HDFS, HBase, Solr
Producer A
Producer B
Producer C
Kaaa Producers
Page 94
94 © Cloudera, Inc. All rights reserved.
Sources Interceptors Channels
Flume Agent
The Kaaa Channel Twi^er, logs, JMS,
webserver Mask, re-‐format,
validate… Kafka
Consumer A
Kaaa Consumers
Consumer B
Consumer C
Page 95
95 © Cloudera, Inc. All rights reserved.
Sources Interceptors Selectors Channels Sinks
Flume Agent
The Kaaa Channel Twi^er, logs, JMS,
webserver Mask, re-‐format,
validate… DR, cri8cal Kafka HDFS, HBase, Solr
Page 96
96 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Processing – Engines tiny.cloudera.com/app-‐arch-‐slides
Page 97
97 © Cloudera, Inc. All rights reserved.
Processing Engines
• MapReduce • Abstrac8ons • Spark • Spark Streaming • Impala
Page 98
98 © Cloudera, Inc. All rights reserved.
Data Processing Engines MapReduce and Abstrac8ons
Page 99
99 © Cloudera, Inc. All rights reserved.
MapReduce
• Oldie but goody • Restric8ve Framework / Innovated Work Around • Extreme Batch
Page 100
100 © Cloudera, Inc. All rights reserved.
MapReduce Basic High Level
Mapper
HDFS (Replicated)
Na8ve File System
Block of Data
Temp Spill Data
Par88oned Sorted Data
Reducer
Reducer Local Copy
Output File
Page 101
101 © Cloudera, Inc. All rights reserved.
MapReduce Innova8on
• Mapper Memory Joins • Reducer Memory Joins • Buckets Sorted Joins • Cross Task Communica8on • Windowing • And Much More
Page 102
102 © Cloudera, Inc. All rights reserved.
Abstrac8ons
• SQL • Hive
• Script/Code • Pig: Pig La8n • Crunch: Java/Scala • Cascading: Java/Scala
Page 103
103 © Cloudera, Inc. All rights reserved.
Data Processing Engines Spark and Spark Streaming
Page 104
104 © Cloudera, Inc. All rights reserved.
Spark
• The New Kid that isn’t that New Anymore • Easily 10x less code • Extremely Easy and Powerful API • Very good for machine learning • Scala, Java, and Python • RDDs • DAG Engine
Page 105
105 © Cloudera, Inc. All rights reserved.
Spark -‐ DAG
Page 106
106 © Cloudera, Inc. All rights reserved.
Spark -‐ DAG
Filter KeyBy
KeyBy
TextFile
TextFile
Join Filter Take
Page 107
107 © Cloudera, Inc. All rights reserved.
Spark -‐ DAG
Filter KeyBy
KeyBy
TextFile
TextFile
Join Filter Take
Good
Good
Good
Good
Good
Good
Good-‐Replay
Good-‐Replay
Good-‐Replay
Good
Good-‐Replay
Good
Good-‐Replay
Lost Block Replay
Good-‐Replay
Lost Block
Good
Future
Future
Future
Future
Page 108
108 © Cloudera, Inc. All rights reserved.
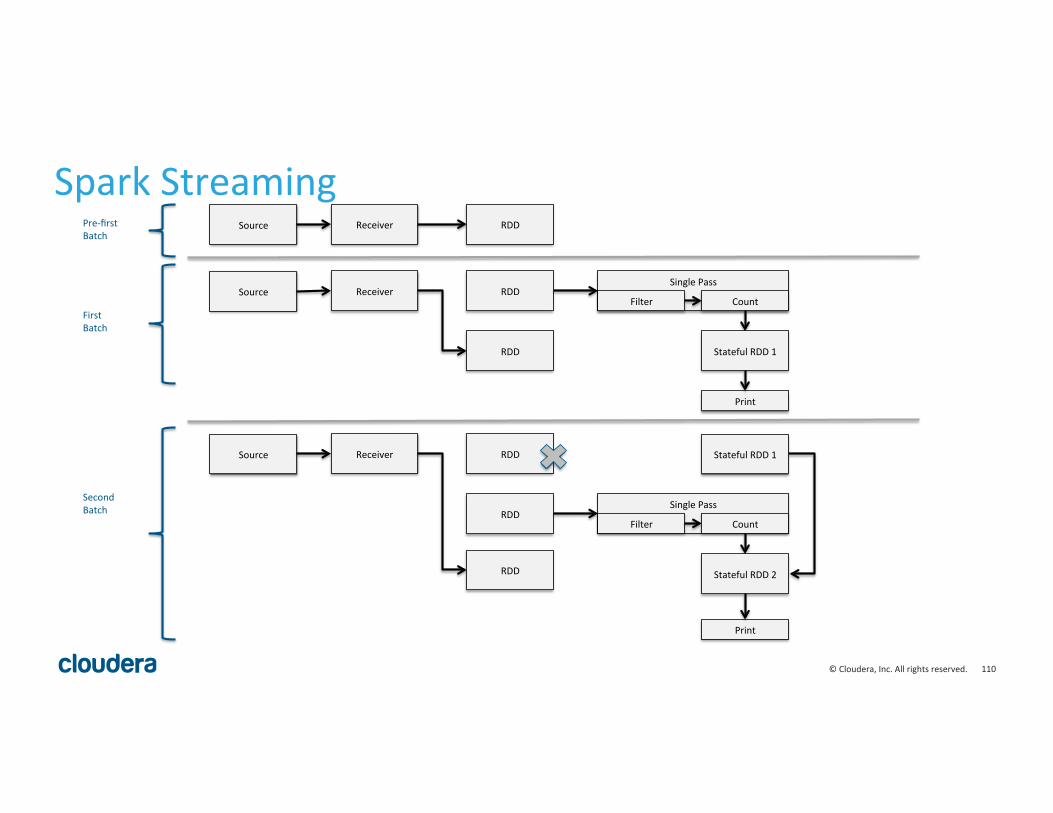
Spark Streaming
• Calling Spark in a Loop • Extends RDDs with DStream • Very Li^le Code Changes from ETL to Streaming
Page 109
109 © Cloudera, Inc. All rights reserved.
Spark Streaming
Single Pass
Source Receiver RDD
Source Receiver RDD
RDD
Filter Count Print
Source Receiver RDD
RDD
RDD
Single Pass
Filter Count Print
Pre-‐first Batch
First Batch
Second Batch
Page 110
110 © Cloudera, Inc. All rights reserved.
Spark Streaming
Single Pass
Source Receiver RDD
Source Receiver RDD
RDD
Filter Count
Print
Source Receiver RDD
RDD
RDD
Single Pass
Filter Count
Pre-‐first Batch
First Batch
Second Batch
Stateful RDD 1
Print
Stateful RDD 2
Stateful RDD 1
Page 111
111 © Cloudera, Inc. All rights reserved.
Data Processing Engines Impala
Page 112
112 © Cloudera, Inc. All rights reserved.
Impala
• MPP Style SQL Engine on top of Hadoop • Very Fast • High Concurrency • Analy8cal windowing func8ons (C5.2).
Page 113
113 © Cloudera, Inc. All rights reserved.
Impala – Broadcast Join Impala Daemon
Smaller Table Data Block
100% Cached Smaller Table
Smaller Table Data Block
Impala Daemon
100% Cached Smaller Table
Impala Daemon
100% Cached Smaller Table
Impala Daemon
Hash Join Func8on
Bigger Table Data Block
100% Cached Smaller Table
Output
Impala Daemon
Hash Join Func8on
Bigger Table Data Block
100% Cached Smaller Table
Output
Impala Daemon
Hash Join Func8on
Bigger Table Data Block
100% Cached Smaller Table
Output
Page 114
114 © Cloudera, Inc. All rights reserved.
Impala – Par88oned Hash Join
Impala Daemon
Smaller Table Data Block
~33% Cached Smaller Table
Smaller Table Data Block
Impala Daemon
~33% Cached Smaller Table
Impala Daemon
~33% Cached Smaller Table
Hash Par88oner Hash Par88oner
Impala Daemon
BiggerTable Data Block
Impala Daemon Impala Daemon
Hash Par88oner Hash Join Func8on
33% Cached Smaller Table
Hash Join Func8on
33% Cached Smaller Table
Hash Join Func8on
33% Cached Smaller Table
Output Output Output
BiggerTable Data Block
Hash Par88oner
BiggerTable Data Block
Hash Par88oner
Page 115
115 © Cloudera, Inc. All rights reserved.
Impala vs Hive
• Very different approaches and • We may see convergence at some point • But for now
• Impala for speed • Hive for batch
Page 116
116 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Data Processing – Pa^erns and Recommenda8ons
Page 117
117 © Cloudera, Inc. All rights reserved.
What processing needs to happen?
• Sessioniza8on • Filtering • Deduplica8on • BI / Discovery
Page 118
118 © Cloudera, Inc. All rights reserved.
Sessioniza8on
Website visit
Visitor 1 Session 1
Visitor 1 Session 2
Visitor 2 Session 1
> 30 minutes
Page 119
119 © Cloudera, Inc. All rights reserved.
Why sessionize?
Helps answers ques8ons like: • What is my website’s bounce rate?
• i.e. how many % of visitors don’t go past the landing page? • Which marke8ng channels (e.g. organic search, display ad, etc.) are leading to most sessions? • Which ones of those lead to most conversions (e.g. people buying things, signing up, etc.)
• Do a^ribu8on analysis – which channels are responsible for most conversions?
Page 120
120 © Cloudera, Inc. All rights reserved.
Sessioniza8on
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12+1413580110 244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1” 244.157.45.12+1413583199
Page 121
121 © Cloudera, Inc. All rights reserved.
How to Sessionize?
1. Given a list of clicks, determine which clicks came from the same user (Par88oning, ordering)
2. Given a par8cular user's clicks, determine if a given click is a part of a new session or a con8nua8on of the previous session (Iden8fying session boundaries)
Page 122
122 © Cloudera, Inc. All rights reserved.
#1 – Which clicks are from same user?
• We can use:
• IP address (244.157.45.12) • Cookies (A9A3BECE0563982D) • IP address (244.157.45.12)and user agent string ((KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36")
Page 123
123 © Cloudera, Inc. All rights reserved.
#1 – Which clicks are from same user?
• We can use:
• IP address (244.157.45.12) • Cookies (A9A3BECE0563982D) • IP address (244.157.45.12)and user agent string ((KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36")
Page 124
124 © Cloudera, Inc. All rights reserved.
#1 – Which clicks are from same user?
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1”
Page 125
125 © Cloudera, Inc. All rights reserved.
#2 – Which clicks part of the same session?
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1”
> 30 mins apart = different sessions
Page 126
126 © Cloudera, Inc. All rights reserved.
Sessioniza8on engine recommenda8on • We have sessioniza8on code in MR and Spark on github. The complexity of the code varies, depends on the exper8se in the organiza8on.
• We choose MR • MR API is stable and widely known • No Spark + Oozie (orchestra8on engine) integra8on currently
Page 127
127 © Cloudera, Inc. All rights reserved.
Filtering – filter out incomplete records
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U…
Page 128
128 © Cloudera, Inc. All rights reserved.
Filtering – filter out records from bots/spiders
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 209.85.238.11 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1”
Google spider IP address
Page 129
129 © Cloudera, Inc. All rights reserved.
Filtering recommenda8on • Bot/Spider filtering can be done easily in any of the engines • Incomplete records are harder to filter in schema systems like Hive, Impala, Pig, etc.
• Flume interceptors can also be used • Pre^y close choice between MR, Hive and Spark • Can be done in Spark using rdd.filter() • We can simply embed this in our MR sessioniza8on job
Page 130
130 © Cloudera, Inc. All rights reserved.
Deduplica8on – remove duplicate records
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36” 244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463 "http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
Page 131
131 © Cloudera, Inc. All rights reserved.
Deduplica8on recommenda8on • Can be done in all engines. • We already have a Hive table with all the columns, a simple DISTINCT query will perform deduplica8on
• reduce() in spark • We use Pig
Page 132
132 © Cloudera, Inc. All rights reserved.
BI/Discovery engine recommenda8on • Main requirements for this are:
• Low latency • SQL interface (e.g. JDBC/ODBC) • Users don’t know how to code
• We chose Impala • It’s a SQL engine • Much faster than other engines • Provides standard JDBC/ODBC interfaces
Page 133
133 © Cloudera, Inc. All rights reserved.
End-‐to-‐end processing
Sessioniza8on Filtering Deduplica8on
BI tools
Page 134
134 © Cloudera, Inc. All rights reserved.
Architectural Considera8ons Orchestra8on
Page 135
135 © Cloudera, Inc. All rights reserved.
• Data arrives through Flume • Triggers a processing event:
• Sessionize • Enrich – Loca8on, marke8ng channel… • Store as Parquet
• Each day we process events from the previous day
Orchestra8ng Clickstream
Page 136
136 © Cloudera, Inc. All rights reserved.
• Workflow is fairly simple • Need to trigger workflow based on data • Be able to recover from errors • Perhaps no8fy on the status • And collect metrics for repor8ng
Choosing Right
Page 137
137 © Cloudera, Inc. All rights reserved.
Oozie or Azkaban?
Page 138
138 © Cloudera, Inc. All rights reserved.
Oozie Architecture
Page 139
139 © Cloudera, Inc. All rights reserved.
• Part of all major Hadoop distribu8ons • Hue integra8on • Built -‐in ac8ons – Hive, Sqoop, MapReduce, SSH • Complex workflows with decisions • Event and 8me based scheduling • No8fica8ons • SLA Monitoring • REST API
Oozie features
Page 140
140 © Cloudera, Inc. All rights reserved.
• Overhead in launching jobs • Steep learning curve • XML Workflows
Oozie Drawbacks
Page 141
141 © Cloudera, Inc. All rights reserved.
Azkaban Architecture
Azkaban Executor Server
Azkaban Web Server
HDFS viewer plugin
Job types plugin
MySQL
Client Hadoop
Page 142
142 © Cloudera, Inc. All rights reserved.
• Simplicity • Great UI – including pluggable visualizers • Lots of plugins – Hive, Pig… • Repor8ng plugin
Azkaban features
Page 143
143 © Cloudera, Inc. All rights reserved.
• Doesn’t support workflow decisions • Can’t represent data dependency
Azkaban Limita8ons
Page 144
144 © Cloudera, Inc. All rights reserved.
• Workflow is fairly simple • Need to trigger workflow based on data • Be able to recover from errors • Perhaps no8fy on the status • And collect metrics for repor8ng
Choosing…
Easier in Oozie
Page 145
145 © Cloudera, Inc. All rights reserved.
• Workflow is fairly simple • Need to trigger workflow based on data • Be able to recover from errors • Perhaps no8fy on the status • And collect metrics for repor8ng
Choosing the right Orchestra8on Tool
Be^er in Azkaban
Page 146
146 © Cloudera, Inc. All rights reserved.
The best orchestra8on tool is the one you are an expert on
Important Decision Considera8on!
Page 147
147 © Cloudera, Inc. All rights reserved.
Orchestra8on Pa^erns – Fan Out
Page 148
148 © Cloudera, Inc. All rights reserved.
Capture & Decide Pa^ern
Page 149
149 © Cloudera, Inc. All rights reserved.
Puwng It All Together Final Architecture
Page 150
150 © Cloudera, Inc. All rights reserved.
Final Architecture – High Level Overview
Data Sources Inges8on
Raw Data Storage (Formats, Schema)
Processed Data Storage (Formats, Schema)
Processing Data Consump8on
Orchestra8on (Scheduling, Managing, Monitoring)
Page 151
151 © Cloudera, Inc. All rights reserved.
Final Architecture – High Level Overview
Data Sources Inges8on
Raw Data Storage (Formats, Schema)
Processed Data Storage (Formats, Schema)
Processing Data Consump8on
Orchestra8on (Scheduling, Managing, Monitoring)
Page 152
152 © Cloudera, Inc. All rights reserved.
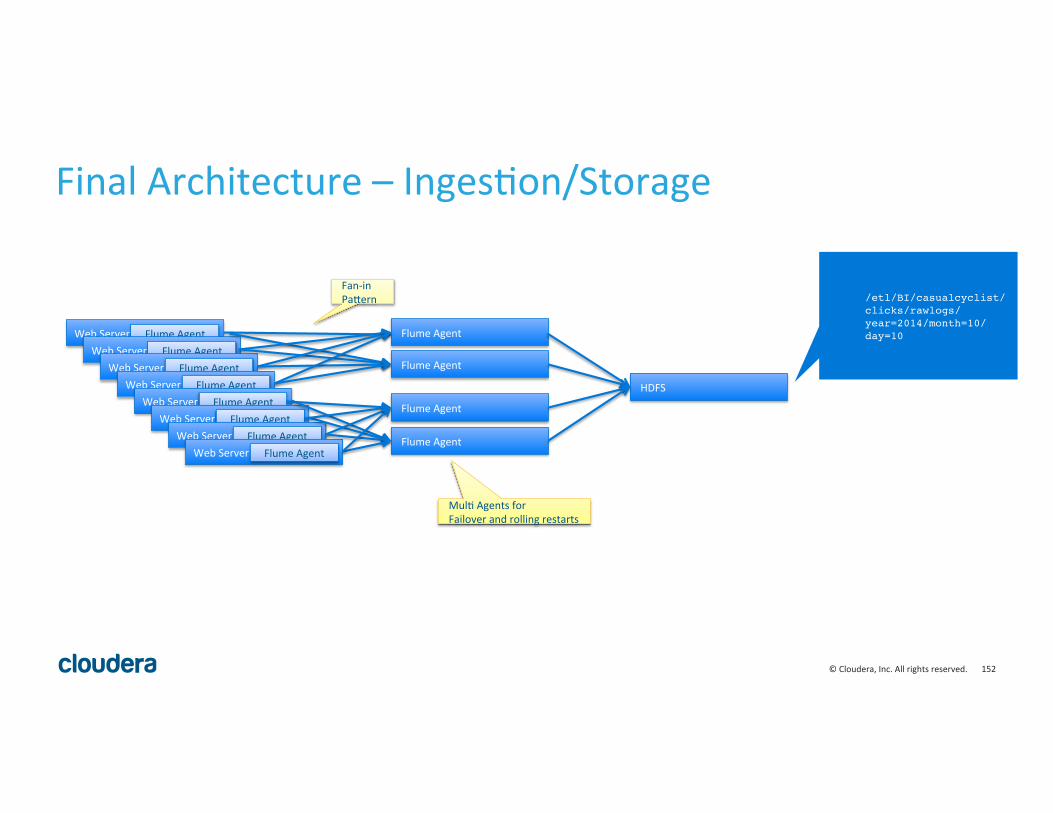
Final Architecture – Inges8on/Storage
Web Server Flume Agent Web Server Flume Agent
Web Server Flume Agent Web Server Flume Agent
Web Server Flume Agent Web Server Flume Agent
Web Server Flume Agent Web Server Flume Agent
Flume Agent
Flume Agent
Flume Agent
Flume Agent
Fan-‐in Pa^ern
Mul8 Agents for Failover and rolling restarts
HDFS
/etl/BI/casualcyclist/clicks/rawlogs/year=2014/month=10/day=10!
Page 153
153 © Cloudera, Inc. All rights reserved.
Final Architecture – High Level Overview
Data Sources Inges8on
Raw Data Storage (Formats, Schema)
Processed Data Storage (Formats, Schema)
Processing Data Consump8on
Orchestra8on (Scheduling, Managing, Monitoring)
Page 154
154 © Cloudera, Inc. All rights reserved.
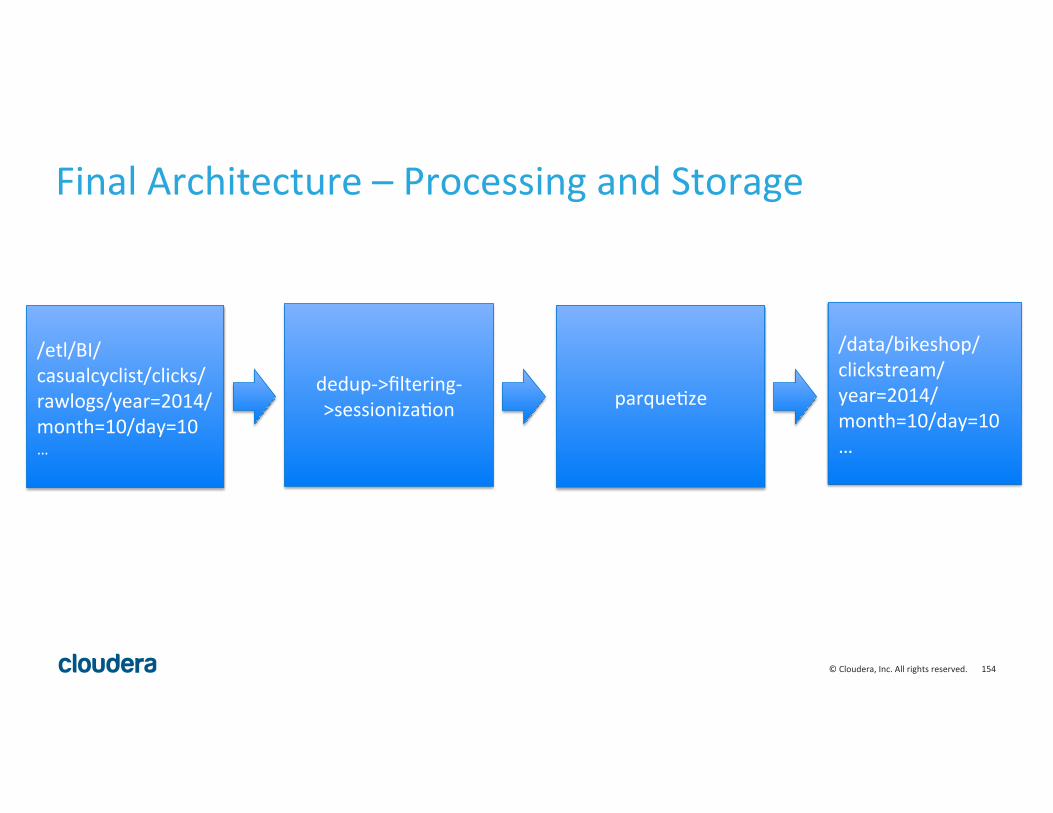
Final Architecture – Processing and Storage
/etl/BI/casualcyclist/clicks/rawlogs/year=2014/month=10/day=10 …
dedup-‐>filtering-‐>sessioniza8on
/data/bikeshop/clickstream/year=2014/month=10/day=10 …
parque8ze
Page 155
155 © Cloudera, Inc. All rights reserved.
Final Architecture – High Level Overview
Data Sources Inges8on
Raw Data Storage (Formats, Schema)
Processed Data Storage (Formats, Schema)
Processing Data Consump8on
Orchestra8on (Scheduling, Managing, Monitoring)
Page 156
156 © Cloudera, Inc. All rights reserved.
Final Architecture – Data Access
Hive/Impala
BI/Analy8cs Tools
DWH Sqoop
Local Disk R, etc.
DB import tool
JDBC/ODBC
Page 157
157 © Cloudera, Inc. All rights reserved.
Demo
Page 158
158 © Cloudera, Inc. All rights reserved.
Join the Discussion
Get community help or provide feedback cloudera.com/community
Page 159
159 © Cloudera, Inc. All rights reserved. Try Cloudera Live today—cloudera.com/live
Page 160
160 © Cloudera, Inc. All rights reserved.
Thank you hadooparchitecturebook.com 8ny.cloudera.com/app-‐arch-‐slides