HELSINKI UNIVERSITY OF TECHNOLOGY ADAPTIVE INFORMATICS RESEARCH CENTRE Morpho Challenge in Pascal Challenges Workshop Venice, 12 April 2006 Morfessor in the Morpho Challenge Mathias Creutz and Krista Lagus Helsinki University of Technology (HUT) Adaptive Informatics Research Centre
Transcript
HELSINKI UNIVERSITY OF TECHNOLOGY
ADAPTIVE INFORMATICS RESEARCH CENTRE
Morpho Challenge in Pascal Challenges Workshop
Venice, 12 April 2006
Morfessor in the Morpho Challenge
Mathias Creutz and Krista Lagus
Helsinki University of Technology (HUT)Adaptive Informatics Research Centre
2HUT
Challenge for NLP: too many words
• E.g., Finnish words often consist of lengthy sequences of morphemes — stems, suffixes and prefixes:– kahvi + n + juo + ja + lle + kin
(coffee + of + drink + -er + for + also)
– nyky + ratkaisu + i + sta + mme(current + solution + -s + from + our)
– tietä + isi + mme + kö + hän(know + would + we + INTERR + indeed)
Huge number of word forms, few examples of each By splitting we get fewer basic units, each with more
examples Important to know the inner structure of words
• Learning of paradigms (e.g., John Goldsmith’s Linguistica)
believhopliv
movus
eedesing
6HUT
Linguistic evaluation using Hutmegs(Helsinki University of Technology Morphological Evaluation Gold Standard)
• Hutmegs contains gold standard segmentations obtained by processing the morphological analyses of FinTWOL and CELEX
– 1.4 million Finnish word forms (FInTWOL, from Lingsoft Inc.)
• Input: ahvenfileerullia (perch filet rolls)• FINTWOL: ahven#filee#rulla N PTV PL• Hutmegs: ahven + filee + rull + i + a
– 120 000 English word forms (CELEX, from LDC)• Input: housewives• CELEX: house wife, NNx, P• Hutmegs: house + wive + s
• Publicly available, see
M. Creutz and K. Lindén. 2004. Morpheme Segmentation Gold Standards for Finnish and English.
7HUT
Morfessor models in the Challenge
Morfessor Baseline (2002)• Program code available since 2002• Provided as a baseline model for the Morpho Challenge• Improves speech recognition; experiments since 2003• No model of morphotacticsMorfessor Categories ML (2004)• Category-based modeling (HMM) of morphotactics• No speech recognition experiments before this challenge• No public software yet
Morfessor Categories MAP (2005)• More elegant mathematically
M1
M2
M3
8HUT
Avoiding overlearning by controlling model complexity• When using powerful machine learning
methods, overlearning is always a problem
• Occam’s razor: given two equally accurate theories, choose the one that is less complex
We have used:• Heuristic control affecting the size of the
lexicon• Deriving a cost function that incorporates a
measure of model size, using– MDL (Minimum Description length)– MAP learning (Maximum A Posteriori)
M2
M3
M1
9HUT
Morfessor Baseline• Originally called the ”Recursive MDL method”• Optimizes roughly:
+ MDL based cost function optimizes size of the model- Morph contextual information not utilized
• undersegmentation of frequent strings (“forthepurposeof”)
• oversegmentation of rare strings (“in + s + an + e”)• syntactic / morphotactic violations (“s + can”)
M1
P (M | corpus ) P (M) P (corpus | M)
where M = (lexicon, grammar) and therefore
= P (lexicon) P (corpus | lexicon)
= P () P () letters morphs
10HUT
Search for the optimal model
Recursive binary splitting
reopened openminded
reopen minded
re open mind ed Morphs
conferences
openingwordsopenminded
reopened
Randomlyshuffle words
Convergenceof model prob.?
yesno Done
M1
11HUT
Challenge Results: Comparison to gold standard splitting (F-measures)
0
10
20
30
40
50
60
70
80
90
Finnish Turkish English
"Sumaa"
BernhardB
A3
BordagC
BordagLsv
Rehman
"RePortS"
Bonnier
A8
"Pacman"
Johnsen
"Swordfish"
Cheat
M1:Baseline
Bernhard
MorfessorBaseline: M1
Winners
12HUT
Morfessor- Categories – ML & MAP• Lexicon / Grammar dualism
– Word structure captured by a regular expression: word = ( prefix* stem suffix* )+
– Morph sequences (words) are generated by a Hidden Markov model (HMM):
– Lexicon: morpheme properties and contextual properties
– Morph segmentation is initialized using M1
P(STM | PRE) P(SUF | SUF)
ificover ationsimpl# s #
P(’s’ | SUF)P(’over’ | PRE)
Transition probs
Emission probs
M2M3
13HUT
Morph lexicon
Morph distributional features Form
14029
136 1 4 over
41 4 1 5 simpl
17259
1 4618 1 s
Freq
uency
Length
String
...
Right p
erplex
ity
Left
perplex
ity
Morp
hs
M2M3
14HUT
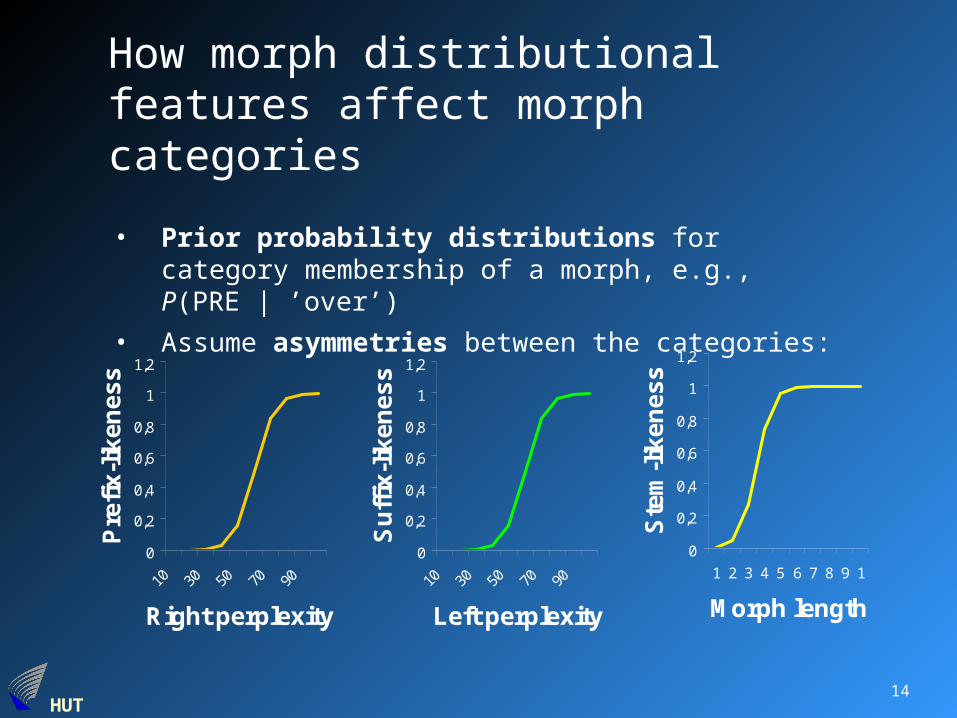
How morph distributional features affect morph categories
0
0,2
0,4
0,6
0,8
1
1,2
10 30 50 70 90
Left perplexity
Su
ffix
-lik
en
es
s
0
0,2
0,4
0,6
0,8
1
1,2
10 30 50 70 90
Right perplexity
Pre
fix
-lik
en
es
s
0
0,2
0,4
0,6
0,8
1
1,2
1 2 3 4 5 6 7 8 9 1
Morph length
Ste
m-l
ike
ne
ss
• Prior probability distributions for category membership of a morph, e.g., P(PRE | ’over’)
• Assume asymmetries between the categories:
15HUT
• There is an additional non-morpheme category for cases where none of the proper classes is likely:
• Distribute remaining probability mass proportionally, e.g.,
How distributional features affect categories (2)
16HUT
MAP vs. ML optimization
argmaxLexicon
P(Lexicon | Corpus)
argmaxLexicon
P(Corpus | Lexicon)P(Lexicon)
Morfessor Categories-MAP:
14029
136 1 4 over
41 4 1 5 simpl
17259
1 4618 1 s
...
P(STM | PRE) P(SUF | SUF)
ificover ationsimpl# s #
P(’s’ | SUF)P(’over’ | PRE)
M3
Morfessor Categories-ML:
arg max P(Corpus | Lexicon) Lexicon
M2 Control lexicon size
heuristically
17HUT
Hierarchical structures in lexicon
straightforwardness
straightforward ness
straight
for
forward
Stem
Suffix
M3
ward
Non-morpheme
Maintain the hierarchy of splittings for each word
Ability to code efficiently also common substrings which are not morphemes (e.g. syllables in foreign names)
Bracketed output
18HUT
Example segmentations
Finnish English
[ aarre kammio ] issa [ accomplish es ]
[ aarre kammio ] on [ accomplish ment ]
bahama laiset [ beautiful ly ]
bahama [ saari en ] [ insur ed ]
[ epä [ [ tasa paino ] inen ] ]
[ insure s ]
maclare n [ insur ing ]
[ nais [ autoili ja ] ] a [ [ [ photo graph ] er ] s ]
[ sano ttiin ] ko [ present ly ] found
töhri ( mis istä ) [ re siding ]
[ [ voi mme ] ko ] [ [ un [ expect ed ] ] ly ]
M3
19HUT
Challenge Results: Comparison to gold standard splitting (F-measures)
0
10
20
30
40
50
60
70
80
90
Finnish Turkish English
"Sumaa"
BernhardB
A3
BordagC
BordagLsv
Rehman
"RePortS"
Bonnier
A8
"Pacman"
Johnsen
"Swordfish"
Cheat
M1:Baseline
M2
M3
CheatB
CheatC
Bernhard
Morfessor Categories models: M2 and M3
MorfessorBaseline: M1
Committees
Winner
20HUT
Morfessor results: closer look
M3
21HUT
Speech recognition results: Finnish
0,8
1
1,2
1,4
1,6
1,8
2
Letter error rate %
"Sumaa"
BernhardA
BernhardB
BordagComp
BordagLSV
Rehman
Bonnier
"Pacman"
"Swordfish"
"Cheat"
M1:Baseline
M2
M3
"CheatB"
"CheatC"6
7
8
9
10
11
12
13
14
Word error rate %
Morfessors:M1, M2, M3
CommitteesCompetitors
22HUT
Speech recognition results: Turkish
12
12,5
13
13,5
14
14,5
15
15,5
16
16,5
17
Letter error rate %
Sumaa
BernhardA
BernhardB
BordagComp
BordagLSV
Rehman
Bonnier
Pacman
Swordfish
Cheat
M1:Baseline
M2
M3
CheatB
CheatC
30
35
40
45
50
55
Word error rate %
Morfessors: M1, M2, M3
Committees
23HUT
A reason for differences?
Source: Creutz & Lagus, 2005 tech.rep.
24HUT
Discussion• This was the first time our Category methods
were evaluated in speech recognition, with nice results!
• Comparison with Morfessors and challenge participants is not quite fair
• Possibilities to extend the M3 model– add word contextual features for “meaning”– more fine-grained categories– beyond concatenative phenomena (e.g., goose –
• How language-general in fact are the methods?– Norwegian, French, German, Arabic, ...
• Did we, or can we succeed in inducing ”basic units of meaning”? – Evaluation in other NLP problems: MT, IR, QA,
TE, ...– Application of morphs to non-NLP problems?
Machine vision, image analysis, video analysis ...
• Will there be another Morpho Challenge?
26HUT
See you in another challenge!
best wishes, Krista (and Sade)
27HUT
Muistiinpanojani– kuvaa lyhyesti omat menetelmät– pohdi omien menetelmien eroja suhteessa niiden
ominaisuuksiin– ole nöyrä, tuo esiin miksi vertailu on epäreilu (aiempi
kokemus; oma data; ja puh.tunnistuskin on tuttu sovellus, joten sen ryhmän aiempi tutkimustyö on voinut vaikuttaa menetelmänkehitykseemme epäsuorasti)
+ pohdintaa meidän menetelmien eroista?+ esimerkkisegmentointeja kaikistamme?+ Diskussiokamaa Mikon paperista ja meidän paperista+ eka tuloskuva on nyt sekava + värit eri tavalla kuin
muissa: vaihda värit ja tuplaa, nosta voittajaa paremmin esiin
28HUT
Discussion
• Possibility to extend the model– rudimentary features used for “meaning”– more fine-grained categories– beyond concatenative phenomena (e.g., goose –