Hidden Markov Models Hidden Markov Models Applied to Information Applied to Information Extraction Extraction Part I: Concept Part I: Concept HMM Tutorial HMM Tutorial Part II: Sample Application Part II: Sample Application AutoBib: web information AutoBib: web information extraction extraction Larry Reeve INFO629: Artificial Intelligence Dr. Weber, Fall 2004
Transcript
Hidden Markov ModelsHidden Markov ModelsApplied to Information Applied to Information
ExtractionExtraction
Part I: ConceptPart I: Concept HMM TutorialHMM Tutorial
Part II: Sample ApplicationPart II: Sample Application AutoBib: web information extractionAutoBib: web information extraction
Larry Reeve
INFO629: Artificial IntelligenceDr. Weber, Fall 2004
Part I: Concept Part I: Concept HMM MotivationHMM Motivation
Real-world has structures and processes Real-world has structures and processes which have (or produce) observable which have (or produce) observable outputsoutputs
Usually sequential (process unfolds over time)Usually sequential (process unfolds over time) Cannot see the event producing the outputCannot see the event producing the output
Example: speech signalsExample: speech signals
Problem: how to construct a model of the Problem: how to construct a model of the structure or process given only structure or process given only observationsobservations
HMM BackgroundHMM Background
Basic theory developed and published in 1960s Basic theory developed and published in 1960s and 70sand 70s
No widespread understanding and application No widespread understanding and application until late 80suntil late 80s
Why?Why? Theory published in mathematic journals which were Theory published in mathematic journals which were
not widely read by practicing engineersnot widely read by practicing engineers
Insufficient tutorial material for readers to understand Insufficient tutorial material for readers to understand and apply conceptsand apply concepts
HMM UsesHMM Uses UsesUses
Speech recognitionSpeech recognition Recognizing spoken words and phrasesRecognizing spoken words and phrases
Text processingText processing Parsing raw records into structured recordsParsing raw records into structured records
BioinformaticsBioinformatics Protein sequence predictionProtein sequence prediction
Makes use of state machinesMakes use of state machines
Based on probabilistic modelsBased on probabilistic models
Useful in problems having Useful in problems having sequential stepssequential steps
Can only observe output from Can only observe output from states, not the states themselvesstates, not the states themselves Example: speech recognitionExample: speech recognition
Each state corresponds to a Each state corresponds to a physical observable eventphysical observable event
State transition matrix
RainyRainy CloudyCloudy SunnySunny
RainyRainy 0.40.4 0.30.3 0.30.3
CloudyCloudy 0.20.2 0.60.6 0.20.2
SunnySunny 0.10.1 0.10.1 0.80.8
Observable Markov Observable Markov ModelModel
Hidden Markov Model Hidden Markov Model ExampleExample
Coin toss: Coin toss: Heads, tails sequence with 2 coinsHeads, tails sequence with 2 coins You are in a room, with a wallYou are in a room, with a wall Person behind wall flips coin, tells resultPerson behind wall flips coin, tells result
Coin selection and toss is Coin selection and toss is hiddenhidden Cannot observe events, only output (heads, Cannot observe events, only output (heads,
tails) from eventstails) from events
Problem is then to build a model to Problem is then to build a model to explain observed sequence of heads and explain observed sequence of heads and tailstails
HMM ComponentsHMM Components
A set of states (x’s)A set of states (x’s)
A set of possible output symbols A set of possible output symbols (y’s)(y’s)
A state transition matrix (a’s)A state transition matrix (a’s) probability of making transition probability of making transition
from one state to the nextfrom one state to the next
Output emission matrix (b’s)Output emission matrix (b’s) probability of a emitting/observing probability of a emitting/observing
a symbol at a particular statea symbol at a particular state
Initial probability vectorInitial probability vector probability of starting at a probability of starting at a
particular stateparticular state Not shown, sometimes assumed to Not shown, sometimes assumed to
be 1be 1
HMM ComponentsHMM Components
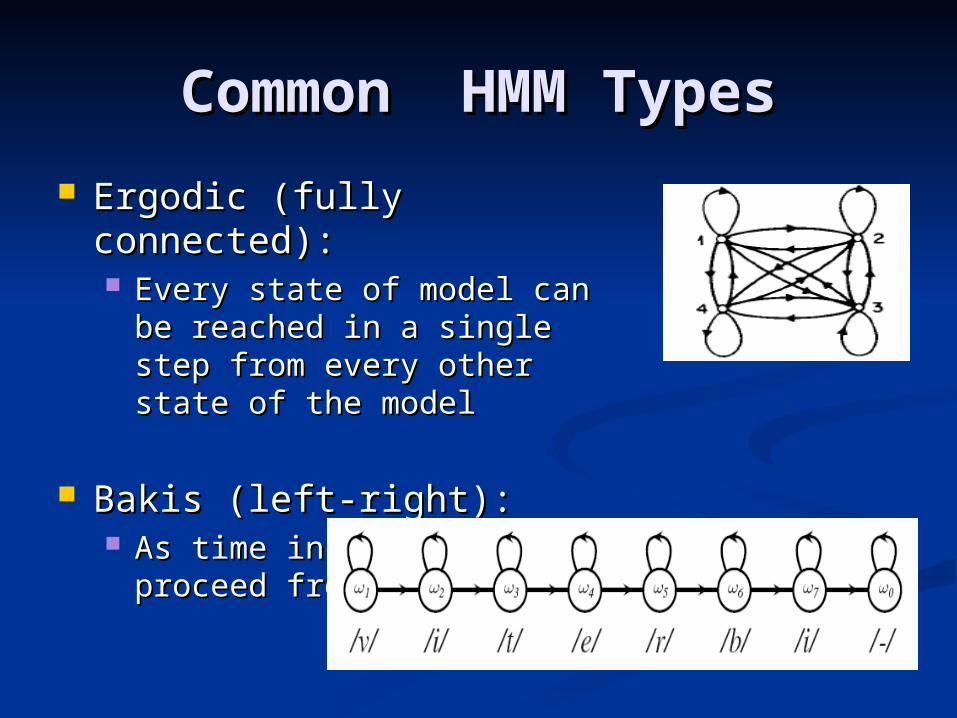
Common HMM TypesCommon HMM Types
Ergodic (fully connected):Ergodic (fully connected): Every state of model can be Every state of model can be
reached in a single step from reached in a single step from every other state of the modelevery other state of the model
Bakis (left-right):Bakis (left-right): As time increases, states As time increases, states
proceed from left to rightproceed from left to right
HMM Core ProblemsHMM Core Problems
Three problems must be solved for Three problems must be solved for HMMs to be useful in real-world HMMs to be useful in real-world applicationsapplications
1) Evaluation1) Evaluation
2) Decoding2) Decoding
3) Learning3) Learning
HMM Evaluation HMM Evaluation ProblemProblem
Purpose: score how well a given model Purpose: score how well a given model matches a given observation sequencematches a given observation sequence
Example (Speech recognition):Example (Speech recognition): Assume HMMs (models) have been built for Assume HMMs (models) have been built for
words ‘home’ and ‘work’. words ‘home’ and ‘work’.
Given a speech signal, evaluation can Given a speech signal, evaluation can determine the probability each model determine the probability each model represents the utterancerepresents the utterance
HMM Decoding ProblemHMM Decoding Problem
Given a model and a set of Given a model and a set of observations, what are the hidden observations, what are the hidden states most likely to have generated states most likely to have generated the observations?the observations?
Useful to learn about internal model Useful to learn about internal model structure, determine state statistics, structure, determine state statistics, and so forthand so forth
HMM Learning ProblemHMM Learning Problem Goal is to learn HMM parameters (training)Goal is to learn HMM parameters (training)
State transition probabilitiesState transition probabilities Observation probabilities at each stateObservation probabilities at each state
Training is crucial:Training is crucial: it allows optimal adaptation of model parameters it allows optimal adaptation of model parameters
to observed training data using real-world to observed training data using real-world phenomenaphenomena
No known method for obtaining optimal No known method for obtaining optimal parameters from data – only approximationsparameters from data – only approximations
Can be a bottleneck in HMM usageCan be a bottleneck in HMM usage
HMM Concept SummaryHMM Concept Summary
Build models representing the hidden states of Build models representing the hidden states of a process or structure using only observationsa process or structure using only observations
Use the models to evaluate probability that a Use the models to evaluate probability that a model represents a particular observation model represents a particular observation sequencesequence
Use the evaluation information in an Use the evaluation information in an application to: recognize speech, parse application to: recognize speech, parse addresses, and many other applicationsaddresses, and many other applications
Part II: Application Part II: Application AutoBib SystemAutoBib System
Provide a uniform view of several computer Provide a uniform view of several computer science bibliographic web data sources science bibliographic web data sources
An automated web information extraction An automated web information extraction system that requires little human inputsystem that requires little human input Web pages designed differently from site-to-siteWeb pages designed differently from site-to-site IE requires training samplesIE requires training samples
HMMs used to parse unstructured HMMs used to parse unstructured bibliographic records into a structured bibliographic records into a structured format: NLPformat: NLP
Web Information Extraction Web Information Extraction
Converting Raw RecordsConverting Raw Records
ApproachApproach
1) Provide seed database of structured records1) Provide seed database of structured records
2) Extract raw records from relevant Web 2) Extract raw records from relevant Web pagespages
3) Match structured records to raw records3) Match structured records to raw records To build training samplesTo build training samples
5) Parse unmatched raw recs into structured 5) Parse unmatched raw recs into structured recsrecs
6) Merge new structured records into database6) Merge new structured records into database
AutoBib ArchitectureAutoBib Architecture
Step 1 - SeedingStep 1 - Seeding
Provide seed database of structured Provide seed database of structured recordsrecords Take small collection of BibTeX format Take small collection of BibTeX format
records and insert into databaserecords and insert into database
Cleaning step normalizes record fieldsCleaning step normalizes record fields Examples: Examples:
Manual step, executed once onlyManual step, executed once only
Step 2 – Extract Raw Step 2 – Extract Raw RecordsRecords
Extract raw records from relevant Web Extract raw records from relevant Web pagespages User specifiesUser specifies
Web pages to extract fromWeb pages to extract from How to follow ‘next page’ links for multiple How to follow ‘next page’ links for multiple
pagespages
Raw records are extracted Raw records are extracted Uses record-boundary discovery techniquesUses record-boundary discovery techniques
Subtree of Interest = largest subtree of HTML tagsSubtree of Interest = largest subtree of HTML tags Record separators = frequent HTML tagsRecord separators = frequent HTML tags
Tokenized RecordsTokenized Records
(Replace all HTML tags with ^)
Step 3 - MatchingStep 3 - Matching
Match raw records Match raw records RR to structured to structured records records SS
Apply 4 tests (heuristic-based)Apply 4 tests (heuristic-based)1)1) Match at least author in Match at least author in RR to an author in to an author in SS
2)2) S.yearS.year must appear in must appear in RR
3)3) If If S.pagesS.pages exists, exists, RR must contain it must contain it
4)4) S.titleS.title is ‘approximately contained’ in is ‘approximately contained’ in RRLevenshtein edit distance – approximate string Levenshtein edit distance – approximate string match match
Step 4 – Parser TrainingStep 4 – Parser Training
Train HMM-based parserTrain HMM-based parser For each pair of For each pair of RR and and SS that match, that match,
annotate tokens in raw record with field annotate tokens in raw record with field namesnames
Annotated raw records are fed into Annotated raw records are fed into HMM parser in order to learn:HMM parser in order to learn: State transition probabilitiesState transition probabilities Symbol probabilities at each stateSymbol probabilities at each state
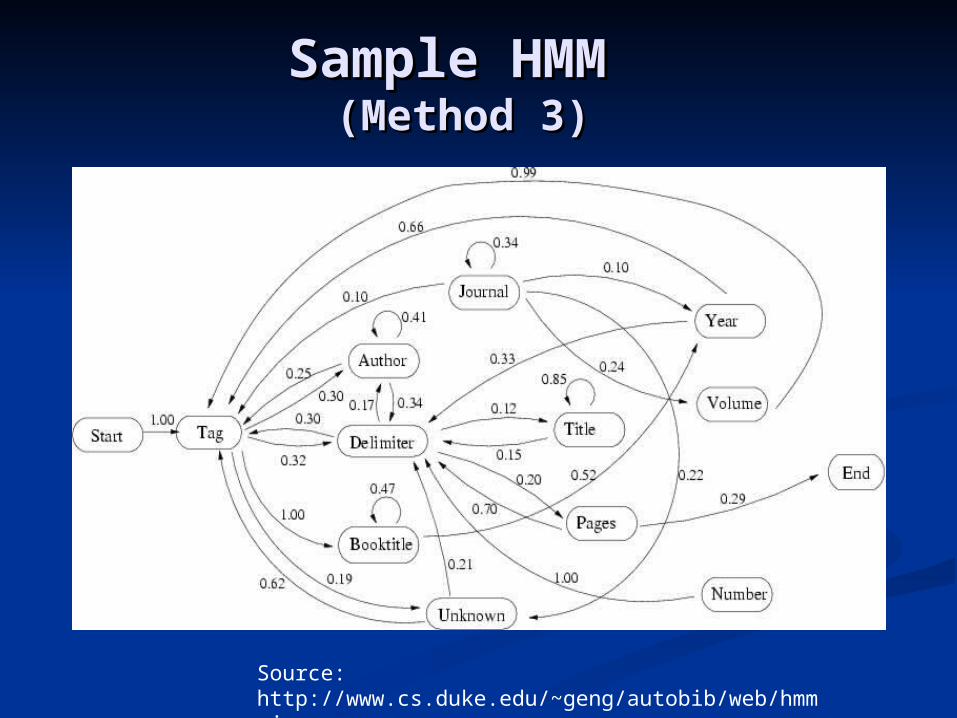
Key consideration is HMM structure for Key consideration is HMM structure for navigating record fields (fields, delimiters)navigating record fields (fields, delimiters) Special statesSpecial states
start, endstart, end Normal statesNormal states
author, title, year, etc.author, title, year, etc.
Best structure found:Best structure found: Have multiple delimiter and tag states,Have multiple delimiter and tag states, one for each normal stateone for each normal state
Parse unmatched raw recs into Parse unmatched raw recs into structured recs using HMM parserstructured recs using HMM parser
Matched raw records can be directly Matched raw records can be directly converted without parsing because converted without parsing because they were annotated in matching they were annotated in matching stepstep
Step 6 - MergingStep 6 - Merging
Merge new structured records into Merge new structured records into databasedatabase
Initial seed database has now grownInitial seed database has now grown
New records will be used for New records will be used for improved matching on the next runimproved matching on the next run
EvaluationEvaluation
Success rate:Success rate:# of tokens labeled by HMM# of tokens labeled by HMM
AdvantagesAdvantages EffectiveEffective Can handle variations in record structureCan handle variations in record structure
Optional fieldsOptional fields Varying field orderingVarying field ordering
DisadvantagesDisadvantages Requires training using annotated dataRequires training using annotated data
Not completely automaticNot completely automatic May require manual markupMay require manual markup Size of training data may be an issueSize of training data may be an issue
Other methodsOther methods WrappersWrappers
Specification of areas of interest on Web pageSpecification of areas of interest on Web page Hand-crafted Hand-crafted
Wrapper inductionWrapper induction Requires manual trainingRequires manual training Not always accommodating to changing structureNot always accommodating to changing structure Syntax-based; no semantic labelingSyntax-based; no semantic labeling
Application to Other Application to Other DomainsDomains
Extract product/pricing information from many sitesExtract product/pricing information from many sites Convert information into structured format and storeConvert information into structured format and store Provide interface to look up product information and Provide interface to look up product information and
then display pricing information gathered from many then display pricing information gathered from many sitessites
Saves users time Saves users time Rather than navigating to and searching many sites, Rather than navigating to and searching many sites,
users can consult a single siteusers can consult a single site
ReferencesReferences Concept:Concept:
Rabiner, L. R. (1989). A Tutorial on Hidden Rabiner, L. R. (1989). A Tutorial on Hidden Markov Models and Selected Applications in Markov Models and Selected Applications in Speech Recognition. Speech Recognition. Proceedings of the IEEEProceedings of the IEEE,, 7777(2), 257-285. (2), 257-285.
Application:Application: Geng, J. and Yang, J. (2004). Automatic Geng, J. and Yang, J. (2004). Automatic
Extraction of Bibliographic Information on the Extraction of Bibliographic Information on the Web. Web. Proceedings of the 8th International Proceedings of the 8th International Database Engineering and Applications Database Engineering and Applications Symposium (IDEAS’04), Symposium (IDEAS’04), 193-204193-204..













































![Punjabi Pos Tagger: Rule Based and HMM...Sapna Kanwar[7] developed HMM based part of speech tagger for Punjabi. Bi-Gram HMM model was used to build this system. Accuracy of the system](https://static.documents.pub/doc/80x56/611945c139acac58f33364c1/punjabi-pos-tagger-rule-based-and-sapna-kanwar7-developed-hmm-based-part.jpg)


