Professor Joongheon Kim (CSE@CAU) http://sites.google.com/site/joongheon Artificial Intelligent Lectures for Communication and Network Engineers/Researchers (14 April 2017) Hidden Markov Models (HMM) and Probabilistic Graphical Models (PGM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1
Transcript
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Hidden Markov Models (HMM) and Probabilistic Graphical Models (PGM)
Professor Joongheon Kim
School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea
1
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea
2
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Hidden Markov Models• Markov
• Markov Chain
• Markov Models and Markov Processes
• Hidden Markov Model (HMM)
• HMM Applications: Probability Evaluation
3
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Chain)
[Definition (𝑃𝑖𝑗)] The fixed probability (one-step transition probability) that it will next be in state 𝑗 whenever the process is in state 𝑖. That is,
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
[Markov Chain]
Markov (Markov Chain)
[Note]
• 𝑃𝑖𝑗 ≥ 0 where 𝑖 ≥ 0, 𝑗 ≥ 0
• 𝑗=0∞ 𝑃𝑖𝑗 = 1 for all 𝑖 = 0,1,⋯
5
𝑖
1
2
𝑛
⋯
𝑃𝑖1
𝑃𝑖2
𝑃𝑖𝑛
𝑃𝑖𝑖
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Chain)
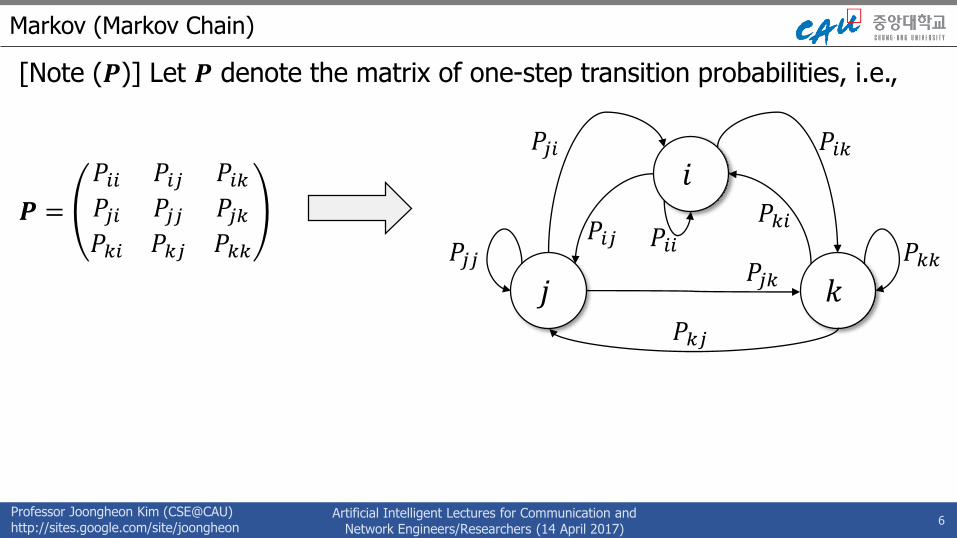
[Note (𝑷)] Let 𝑷 denote the matrix of one-step transition probabilities, i.e.,
𝑷 =
𝑃𝑖𝑖 𝑃𝑖𝑗 𝑃𝑖𝑘𝑃𝑗𝑖 𝑃𝑗𝑗 𝑃𝑗𝑘𝑃𝑘𝑖 𝑃𝑘𝑗 𝑃𝑘𝑘
6
𝑗
𝑖
𝑘
𝑃𝑖𝑖𝑃𝑖𝑗
𝑃𝑖𝑘𝑃𝑗𝑖
𝑃𝑗𝑗𝑃𝑗𝑘
𝑃𝑘𝑖
𝑃𝑘𝑗
𝑃𝑘𝑘
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
[Transition Matrix] [Markov Chain]
Markov (Markov Chain)
[Example] There are two milk companies in South Korea, i.e., 𝐴 and 𝐵. Based on last year statistics, the 88% customers of 𝐴 is currently still with 𝐴; and the other 12% customers are now with 𝐵. In addition, the 85% customer of 𝐵is currently with 𝐵; and the other 15% customers are now with 𝐴.
7
𝑷 =𝑃𝐴𝐴 𝑃𝐴𝐵𝑃𝐵𝐴 𝑃𝐵𝐵
=0.88 0.120.15 0.85
𝐵𝐴
𝑃𝐴𝐴 = 0.88 𝑃𝐴𝐵 = 0.12
𝑃𝐵𝐴 = 0.15 𝑃𝐵𝐵 = 0.85
[One-Step Transition]If initial market share is A = 0.25 and 𝐵 = 0.75,i.e., 𝑠0 = 0.25 0.75 , the next market share is:
𝑠1 = 𝑠0𝑷
= 0.25 0.750.88 0.120.15 0.85
= 0.3325 0.6675
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Chain)
[Example (Multi-Step Transition)] From the 𝑷 (in previous slide), suppose that we are in state 𝑖 in time 𝑡 and we have to compute the probability for being in state 𝑖 in time 𝑡 + 2 (denote by 𝑃𝑖𝑖
2).
8
𝑗𝑖
𝑘
𝑖
𝑖
𝑡 𝑡 + 1 𝑡 + 2
𝑃𝑖𝑖
𝑃𝑖𝑘
𝑃𝑖𝑗
𝑃𝑖𝑖
𝑃𝑗𝑖
𝑃𝑘𝑖
𝑃𝑖𝑖2 = 𝑃 𝑋𝑛+2 = 𝑖 𝑋𝑛 = 𝑖
= 𝑃𝑖𝑖𝑃𝑖𝑖 + 𝑃𝑖𝑗𝑃𝑗𝑖 + 𝑃𝑖𝑘𝑃𝑘𝑖
=
𝑃𝑖𝑖 𝑃𝑖𝑗 𝑃𝑖𝑘𝑃𝑗𝑖 𝑃𝑗𝑗 𝑃𝑗𝑘𝑃𝑘𝑖 𝑃𝑘𝑗 𝑃𝑘𝑘
𝑃𝑖𝑖 𝑃𝑖𝑗 𝑃𝑖𝑘𝑃𝑗𝑖 𝑃𝑗𝑗 𝑃𝑗𝑘𝑃𝑘𝑖 𝑃𝑘𝑗 𝑃𝑘𝑘
= 𝑷𝑖𝑖2
[𝑋𝑛 = 𝑖: State in 𝑖 in time 𝑛]
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Models and Markov Processes)
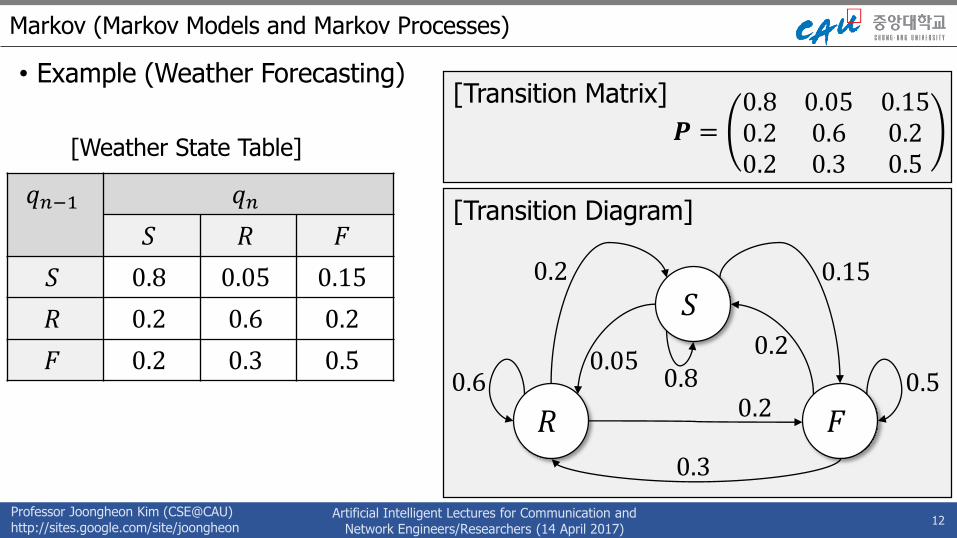
• Example for Markov Model (Weather Forecasting)• Weather State: Sunny (𝑆), Rainy (𝑅), Foggy (𝐹)
• Example: if the previous three weather conditions are 𝑞𝑛−1 = 𝑆,𝑞𝑛−2 = 𝑅, and𝑞𝑛−3 = 𝐹, subsequently, the probability where today weather (𝑞𝑛) is 𝑅 is as follows:
9
𝑃 𝑞𝑛 = 𝑅 𝑞𝑛−1 = 𝑆, 𝑞𝑛−2 = 𝑅, 𝑞𝑛−3 = 𝐹
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Models and Markov Processes)
• Observation from previous [Example]• If we have larger 𝑛, it means we have to gather more information.
• If 𝑛 = 6, we need to gather 3(6−1) = 243 weather data. Therefore, we need an assumption (called Markov Assumption) which reduces the number of gathering data.
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Markov (Markov Models and Markov Processes)
• Observation from previous [Example] (Continued)• With Markov Assumption, the probability that can observe a sequence 𝑞1, 𝑞2, ⋯ , 𝑞𝑛 can be presented by joint probability as follows:
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Hidden Markov Models• Markov
• Hidden Markov Model (HMM)• Example: Weather
• Example: Balls in Jars
• HMM Applications: Probability Evaluation
14
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM (Example: Weather)
• [Example (Weather)] You are in a house which has no windows. Your friend will visit you once a day. Now, you can estimate weather by checking whether your friend has an umbrella or not. Your friend carries an umbrella with the probabilities of 0.1, 0.8, and 0.3, when the weather is 𝑆, 𝑅, and 𝐹.
15
Observation: With Umbrella (𝑜𝑖 = 𝑈𝑂) or Without Umbrella (𝑜𝑖 = 𝑈𝑋).Now, the weather can be estimated by observing 0𝑖 , 𝑖 ≥ 1.
Therefore, according to Bayes’ theorem:
𝑃 𝑞𝑖 𝑜𝑖 =𝑃 𝑜𝑖 𝑞𝑖 𝑃 𝑞𝑖𝑃 𝑜𝑖
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM (Example: Weather)
• [Example (Weather)] You are in a house which has no windows. Your friend will visit you once a day. Now, you can estimate weather by checking whether your friend has an umbrella or not. Your friend carries an umbrella with the probabilities of 0.1, 0.8, and 0.3, when the weather is 𝑆, 𝑅, and 𝐹.
16
When the sequences of weather and umbrella are given, i.e., 𝑞1, ⋯ , 𝑞𝑛and 𝑜1, ⋯ , 𝑜𝑛 , the conditional probability is as follows:
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM (Example: Balls in Jars)
• [Example (Weather)] A room has a curtain and there are three jars and the jars contain balls (colors: red, blue, green, and purple). A person behind the curtain select one jar and pick one ball from there. The person shows the ball and put the ball into the jar. And the person repeats.
17
Notations) • 𝑏𝑗 𝑘 : pick one ball from jar 𝑗 and the color of the ball is 𝑘 where 𝑘 = 1,2,3,4
when the color is red, blue, green, and purple, respectively.• 𝑁: The number of states (i.e., the number of jars): 𝑆 = 𝑆1, ⋯ , 𝑆𝑁• 𝑀: The number of observation (i.e., the number of colors): 𝑂 = 𝑂1, ⋯ , 𝑂𝑀• State Transition Matrix 𝐴 = 𝑎𝑖𝑗 where 𝑎𝑖𝑗 = 𝑃 𝑞𝑡+1 = 𝑆𝑗 𝑞𝑡 = 𝑆𝑖 and this
stands for the case where transition happens from state 𝑖 to state 𝑗.
• Observation 𝐵 = 𝑏𝑗 𝑘 where 𝑏𝑗 𝑘 = 𝑃 𝑂𝑡 = 𝑜𝑘 𝑞𝑡 = 𝑆𝑗 and this stands for
the case where 𝑘 is observed in state 𝑗.• Initial State Distribution 𝜋 = 𝜋𝑖 where 𝜋𝑖 = 𝑃 𝑞1 = 𝑆1 .
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Hidden Markov Models• Markov
• Hidden Markov Model (HMM)
• HMM Applications: Probability Evaluation
18
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
[Problem Definition (Probability Evaluation)] When 𝑂 = 𝑜1, 𝑜2, 𝑜3, ⋯ and HMM model 𝜆 = 𝐴, 𝐵, 𝜋 are given, find that the observation sequence can occur from which model with the highest probability? It means that how we can calculate 𝑃 𝑂 𝜆 ?
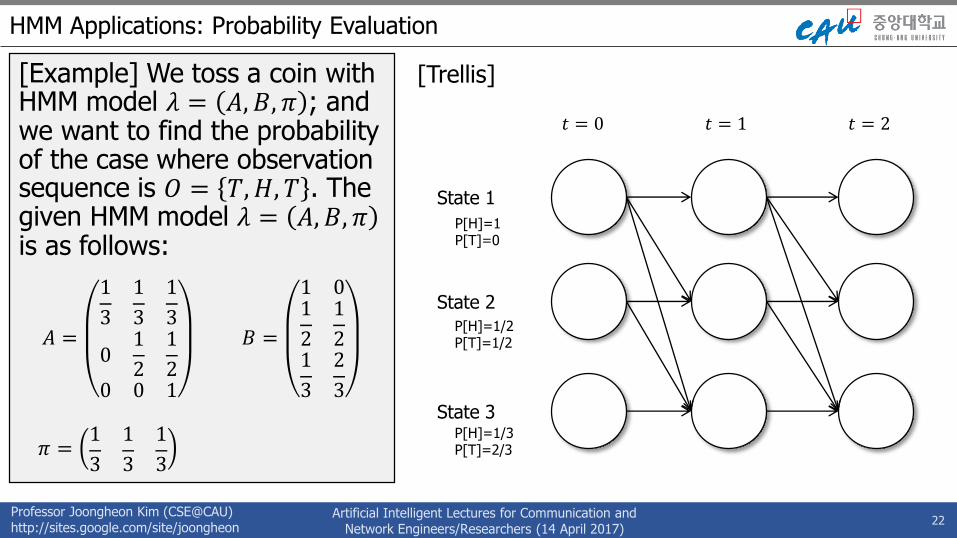
[Example] We are about to toss a coin with HMM model 𝜆 = 𝐴, 𝐵, 𝜋 ; and we want to find the probability of the case where observation is 𝑂 = 𝑇,𝐻, 𝑇 .
19
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
[Problem Definition (Probability Evaluation)] When 𝑂 = 𝑜1, 𝑜2, 𝑜3, ⋯ and HMM model 𝜆 = 𝐴, 𝐵, 𝜋 are given, find that the observation sequence can occur from which model with the highest probability? It means that how we can calculate 𝑃 𝑂 𝜆 ?
[Example] We toss a coin with HMM model 𝜆 = 𝐴, 𝐵, 𝜋 ; and we want to find the probability of the case where observation sequence is 𝑂 = 𝑇,𝐻, 𝑇 . The given HMM model 𝜆 = 𝐴, 𝐵, 𝜋 is as follows:
20
𝜋 =1
3
1
3
1
3𝐴 =
1
3
1
3
1
3
01
2
1
20 0 1
𝐵 =
1 01
2
1
21
3
2
3
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
[Example] We toss a coin with HMM model 𝜆 = 𝐴, 𝐵, 𝜋 ; and we want to find the probability of the case where observation sequence is 𝑂 = 𝑇,𝐻, 𝑇 . The given HMM model 𝜆 = 𝐴, 𝐵, 𝜋is as follows:
21
𝜋 =1
3
1
3
1
3
𝐴 =
1
3
1
3
1
3
01
2
1
20 0 1
𝐵 =
1 01
2
1
21
3
2
3
21
1/3[Transition Diagram]
3
1/31/3
1/2 1
1/2
P[H]=1P[T]=0
P[H]=1/2P[T]=1/2
P[H]=1/3P[T]=2/3
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
[Example] We toss a coin with HMM model 𝜆 = 𝐴, 𝐵, 𝜋 ; and we want to find the probability of the case where observation sequence is 𝑂 = 𝑇,𝐻, 𝑇 . The given HMM model 𝜆 = 𝐴, 𝐵, 𝜋is as follows:
22
𝜋 =1
3
1
3
1
3
𝐴 =
1
3
1
3
1
3
01
2
1
20 0 1
𝐵 =
1 01
2
1
21
3
2
3
[Trellis]
State 1
State 2
State 3
𝑡 = 0 𝑡 = 1 𝑡 = 2
P[H]=1P[T]=0
P[H]=1/2P[T]=1/2
P[H]=1/3P[T]=2/3
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
23
[Trellis]
State 1
State 2
State 3
𝑡 = 0 𝑡 = 1 𝑡 = 2
P[H]=1P[T]=0
P[H]=1/2P[T]=1/2
P[H]=1/3P[T]=2/3
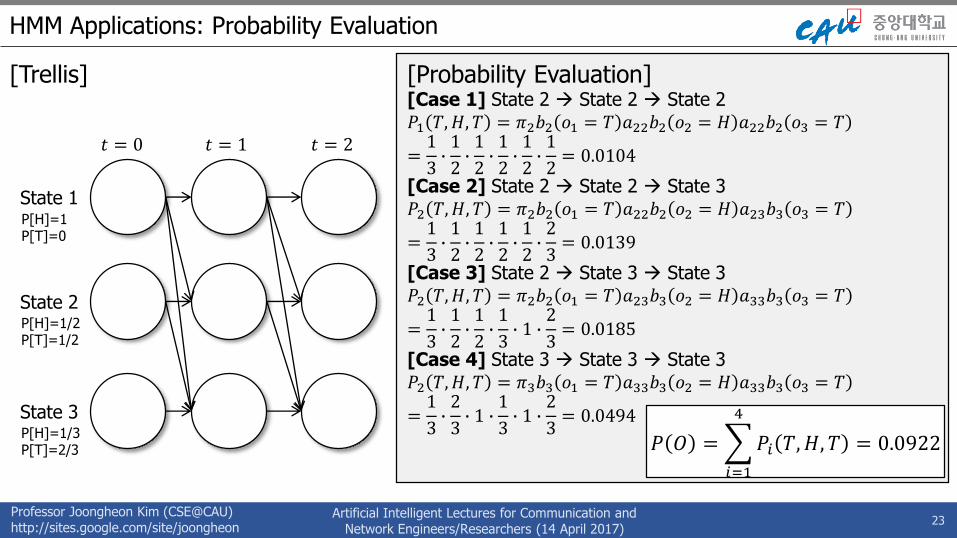
[Probability Evaluation][Case 1] State 2 State 2 State 2𝑃1 𝑇, 𝐻, 𝑇 = 𝜋2𝑏2 𝑜1 = 𝑇 𝑎22𝑏2 𝑜2 = 𝐻 𝑎22𝑏2 𝑜3 = 𝑇
=1
3∙1
2∙1
2∙1
2∙1
2∙1
2= 0.0104
[Case 2] State 2 State 2 State 3𝑃2 𝑇,𝐻, 𝑇 = 𝜋2𝑏2 𝑜1 = 𝑇 𝑎22𝑏2 𝑜2 = 𝐻 𝑎23𝑏3 𝑜3 = 𝑇
=1
3∙1
2∙1
2∙1
2∙1
2∙2
3= 0.0139
[Case 3] State 2 State 3 State 3𝑃2 𝑇,𝐻, 𝑇 = 𝜋2𝑏2 𝑜1 = 𝑇 𝑎23𝑏3 𝑜2 = 𝐻 𝑎33𝑏3 𝑜3 = 𝑇
=1
3∙1
2∙1
2∙1
3∙ 1 ∙2
3= 0.0185
[Case 4] State 3 State 3 State 3𝑃2 𝑇,𝐻, 𝑇 = 𝜋3𝑏3 𝑜1 = 𝑇 𝑎33𝑏3 𝑜2 = 𝐻 𝑎33𝑏3 𝑜3 = 𝑇
=1
3∙2
3∙ 1 ∙1
3∙ 1 ∙2
3= 0.0494
𝑃 𝑂 =
𝑖=1
4
𝑃𝑖 𝑇,𝐻, 𝑇 = 0.0922
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
HMM Applications: Probability Evaluation
• Forward Algorithm for Probability Evaluation• Step 1) Initialization (𝛼1 𝑖 = 𝜋𝑖𝑏𝑖 𝑜𝑖 , 1 ≤ 𝑖 ≤ 3)
24
𝑡 = 0 𝑖 = 1𝛼1 1 = 𝜋1𝑏1 𝑜1 = 𝑇 =
1
3∙ 0 = 0
𝑖 = 2𝛼1 2 = 𝜋2𝑏2 𝑜1 = 𝑇 =
1
3∙1
2=1
6
𝑖 = 3𝛼1 3 = 𝜋3𝑏3 𝑜1 = 𝑇 =
1
3∙2
3=2
9
State 1
State 2
State 3
P[H]=1P[T]=0
P[H]=1/2P[T]=1/2
P[H]=1/3P[T]=2/3
𝑡 = 0 𝑡 = 1 𝑡 = 2
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
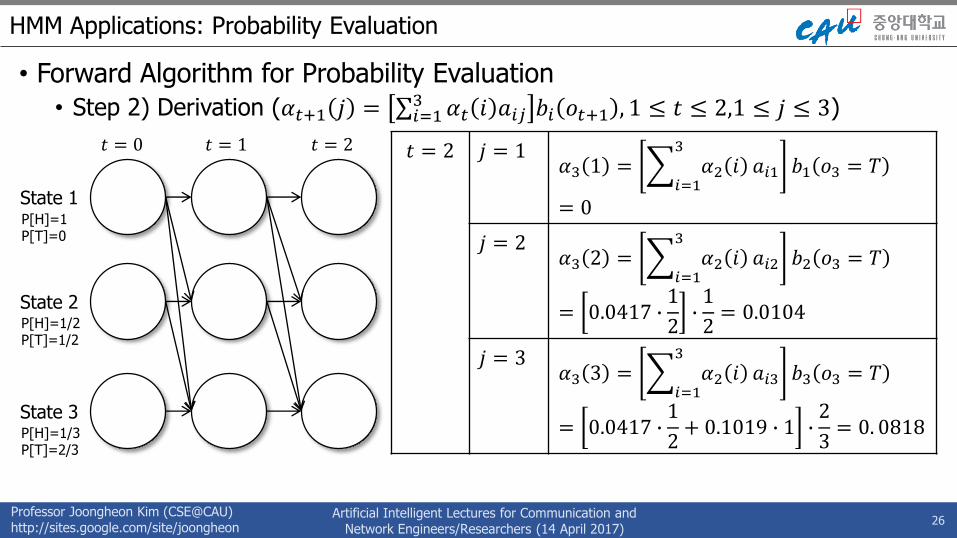
HMM Applications: Probability Evaluation
• Forward Algorithm for Probability Evaluation• Step 2) Termination (𝑃 𝑂 𝜆 = 𝑖=1
3 𝛼3 𝑖 )
27
State 1
State 2
State 3
P[H]=1P[T]=0
P[H]=1/2P[T]=1/2
P[H]=1/3P[T]=2/3
𝑡 = 0 𝑡 = 1 𝑡 = 2
𝑃 𝑂 𝜆 = 𝑖=1
3
𝛼3 𝑖 = 0.0922
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Hidden Markov Models (HMM) and Probabilistic Graphical Models (PGM)Part 2: Markov Decision Process
Professor Joongheon Kim
School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea
28
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Markov Decision Process (MDP)• Basics
• Markov Property
• Policy and Return
• Value Functions (V, Q)
• Solving MDP• Planning
• Reinforcement Learning (Value-based)
• Reinforcement Learning (Policy-based) advanced topic (out of scope)
29
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑆: Set of states
• 𝐴: Set of actions
• 𝑅: Reward function
• 𝑇: Transition function
• 𝛾: Discount factor
30
How can we use MDP to model agent in a maze?
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑺: Set of states
• 𝐴: Set of actions
• 𝑅: Reward function
• 𝑇: Transition function
• 𝛾: Discount factor
31
𝑆: location (𝑥, 𝑦) if the maze is a 2D grid• 𝑠0: starting state• 𝑠: current state• 𝑠′: next state• 𝑠𝑡: state at time 𝑡
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑆: Set of states
• 𝑨: Set of actions
• 𝑅: Reward function
• 𝑇: Transition function
• 𝛾: Discount factor
32
𝑆: location (𝑥, 𝑦) if the maze is a 2D grid𝐴: move up, down, left, or
right• 𝑠 → 𝑠′
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑆: Set of states
• 𝐴: Set of actions
• 𝑹: Reward function
• 𝑇: Transition function
• 𝛾: Discount factor
33
𝑆: location (𝑥, 𝑦) if the maze is a 2D grid𝐴: move up, down, left, or
right𝑅: how good was the chosen action?• 𝑟 = 𝑅 𝑠, 𝑎, 𝑠′
• -1 for moving (battery used)
• +1 for jewel? +100 for exit?
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑆: Set of states
• 𝐴: Set of actions
• 𝑅: Reward function
• 𝑻: Transition function
• 𝛾: Discount factor
34
𝑆: location (𝑥, 𝑦) if the maze is a 2D grid𝐴: move up, down, left, or
right𝑅: how good was the chosen action?𝑇: where is the robot’s new location?• 𝑇 = 𝑠′ 𝑠, 𝑎
Stochastic Transition
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Basics)
• Markov Decision Process (MDP) Components: <𝑆, 𝐴, 𝑅, 𝑇, 𝛾>• 𝑆: Set of states
• 𝐴: Set of actions
• 𝑅: Reward function
• 𝑇: Transition function
• 𝜸: Discount factor
35
𝑆: location (𝑥, 𝑦) if the maze is a 2D grid𝐴: move up, down, left, or right𝑅: how good was the chosen action?𝑇: where is the robot’s new location?𝛾: how much does future reward worth? • 0 ≤ 𝛾 ≤ 1, [𝛾 ≈ 0: future
reward is near 0 (immediate action is preferred)]
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Markov Property)
• Does 𝑠𝑡+1 depend on 𝑠0, 𝑠1, ⋯ , 𝑠𝑡−1, 𝑠𝑡 ? No.• Memoryless!
• Future only depends on present
• Current state is a sufficient statistic of agent’s history
• No need to remember agent’s history• 𝑠𝑡+1 depends only on 𝑠𝑡 and 𝑎𝑡• 𝑟𝑡 depends only on 𝑠𝑡 and 𝑎𝑡
36
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
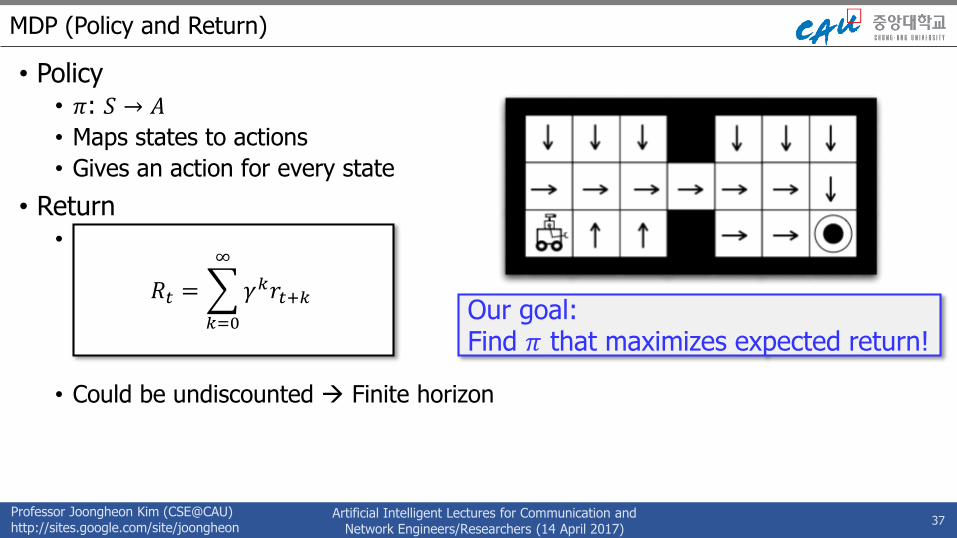
MDP (Policy and Return)
• Policy• 𝜋: 𝑆 → 𝐴
• Maps states to actions
• Gives an action for every state
• Return• Discounted sum of rewards
• Could be undiscounted Finite horizon
37
𝑅𝑡 =
𝑘=0
∞
𝛾𝑘𝑟𝑡+𝑘Our goal:Find 𝜋 that maximizes expected return!
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
MDP (Value Functions (V, Q))
• State Value Function (𝑉)
• Expected return of starting at state 𝑠 and following policy 𝜋• How much return do I expect starting from state 𝑠?
• Action Value Function (𝑄)
• Expected return of starting at state 𝑠, taking action 𝑎, and then following policy 𝜋• How much return do I expect starting from state 𝑠 and taking action 𝑎?
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Three Key Problems
• [Representing] Represent the world as a collection of random variables 𝑋1, ⋯ , 𝑋𝑛 with joint distribution, i.e., 𝑃 𝑋1, ⋯ , 𝑋𝑛• Basics of graph theory
• Families of probability distributions
• Markov properties and conditional independence
• Density estimation, classification and regression
47
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Three Key Problems
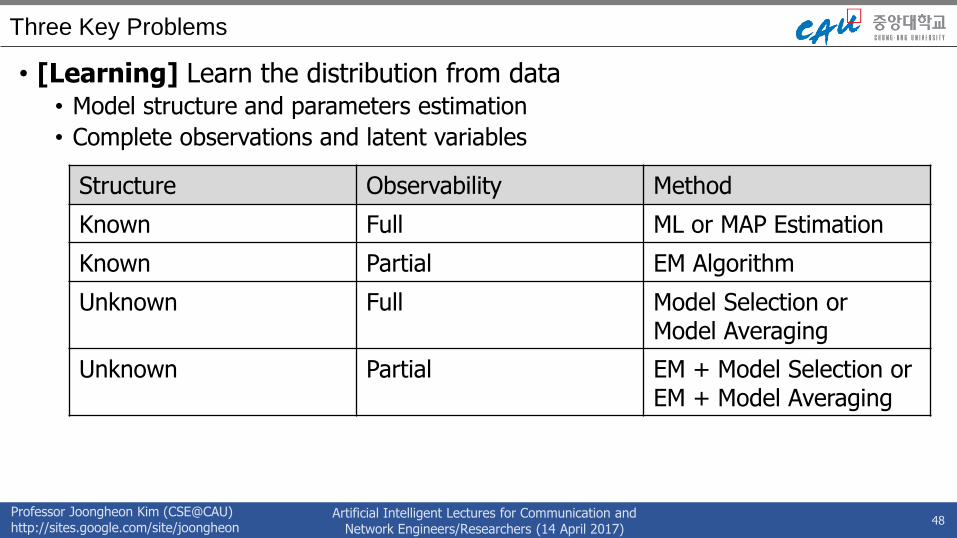
• [Learning] Learn the distribution from data• Model structure and parameters estimation
• Complete observations and latent variables
48
Structure Observability Method
Known Full ML or MAP Estimation
Known Partial EM Algorithm
Unknown Full Model Selection orModel Averaging
Unknown Partial EM + Model Selection or EM + Model Averaging
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Three Key Problems
• [Inferencing] Perform interference (i.e., compute conditional distributions), i.e., 𝑃 𝑋𝑖 𝑋1 = 𝑥1, ⋯ , 𝑋𝑛 = 𝑥𝑛• Inference is the problem of computing P(variables of interest | observed variables)
• Exact inference vs. Approximate inference • Exact inference
• The junction tree and related algorithms, belief propagation
• Limitation on the model
• Approximate inference
• Variational methods, Sampling (Monte Carlo Methods), Maximum entropy approach, Loopy BP, Bethe approximation
• Limitation on the correctness of solution
49
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Hidden Markov Models (HMM) and Probabilistic Graphical Models (PGM)Part 4: Support Vector Machine
Professor Joongheon Kim
School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea
50
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Main Idea
• Hyperplane in 𝑛-Dimensional Space
• Brief Introduction to Optimization for Support Vector Machine (SVM)
• SVM for Classification
51
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Main Idea
• How can we classify the give data?
52
Any of these would be fine. But which is the best?
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Main Idea
53
Gene Y
Gene XCancer PatientsNormal Patients
Gap
Find a linear decision surface (hyperplane) that can separate patient classes and has the largest distance (i.e., largest gap (or margin)) between border-line patients (i.e., support vectors);
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
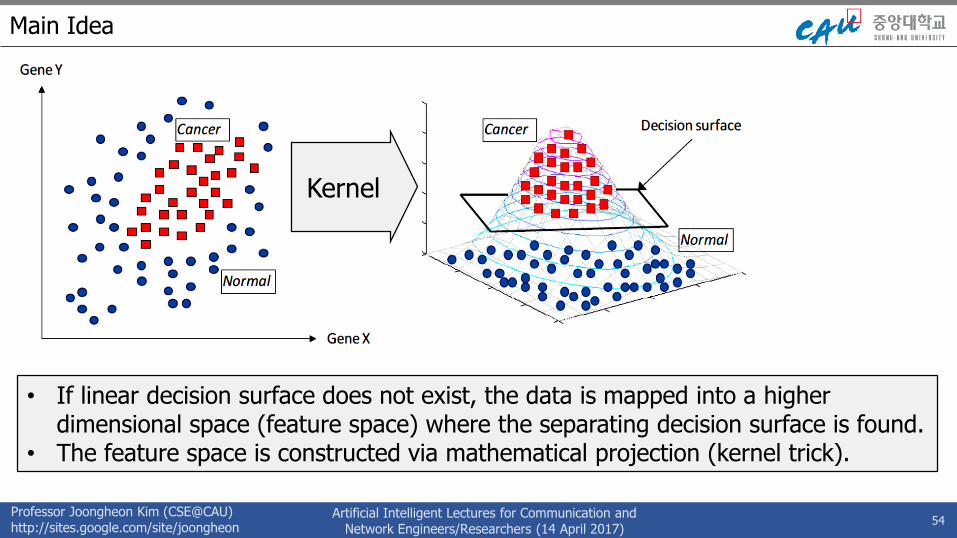
Main Idea
54
Kernel
• If linear decision surface does not exist, the data is mapped into a higher dimensional space (feature space) where the separating decision surface is found.
• The feature space is constructed via mathematical projection (kernel trick).
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Main Idea
• Hyperplane in 𝒏-Dimensional Space
• Brief Introduction to Optimization for Support Vector Machine (SVM)
• SVM for Classification
55
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
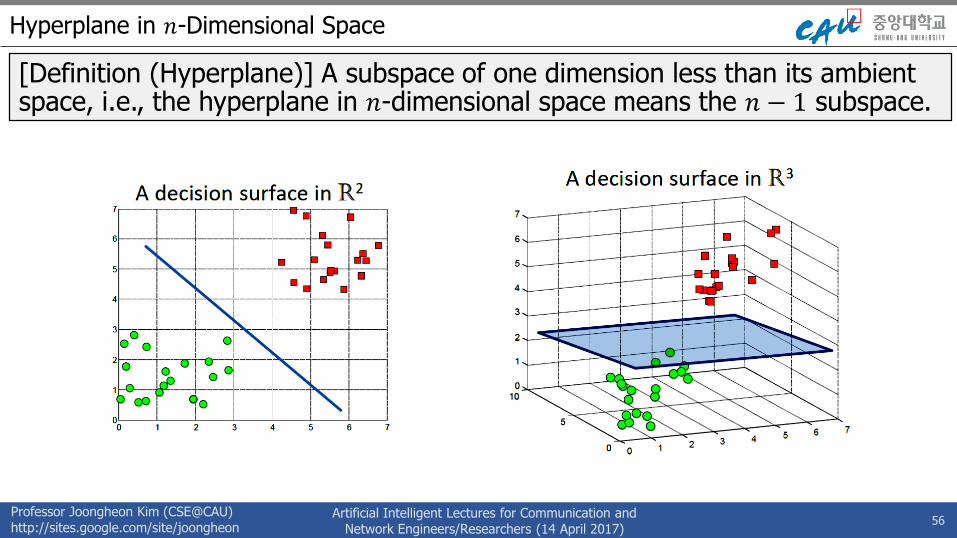
Hyperplane in 𝑛-Dimensional Space
[Definition (Hyperplane)] A subspace of one dimension less than its ambient space, i.e., the hyperplane in 𝑛-dimensional space means the 𝑛 − 1 subspace.
56
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Hyperplane in 𝑛-Dimensional Space
• Equations of a Hyperplane
57
• An equation of a hyperplane is defined by a point (𝑃0) and a perpendicular vector to the plane (𝑤) at that point.
• Define vectors: 𝑥0 and 𝑥 where 𝑃 is an arbitrary point on a hyperplane.
• A condition for 𝑃 to be one the plane is that the vector 𝑥 − 𝑥0 is perpendicular to 𝑤:
• The above equations hold for 𝑅𝑛 when 𝑛 > 3.
𝑤 ∙ 𝑥 − 𝑥0 = 0
𝑤 ∙ 𝑥 − 𝑤 ∙ 𝑥0 = 0 and define 𝑏 = −𝑤 ∙ 𝑥0
𝑤 ∙ 𝑥 + 𝑏 = 0
• Distance between two parallel hyperplanes 𝑤 ∙ 𝑥 +𝑏1 = 0 and 𝑤 ∙ 𝑥 + 𝑏2 = 0 is
equivalent to 𝐷 =𝑏1−𝑏2
𝑤.
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Distance between two parallel hyperplanes 𝑤 ∙ 𝑥 +𝑏1 = 0 and 𝑤 ∙ 𝑥 + 𝑏2 = 0 is equivalent to
𝐷 =𝑏1−𝑏2
𝑤.
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Main Idea
• Hyperplane in 𝑛-Dimensional Space
• Brief Introduction to Optimization for Support Vector Machine (SVM)
• SVM for Classification
59
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Brief Introduction to Optimization for Support Vector Machine
• Now, we understand• How to represent data (vectors)
• How to define a linear decision surface (hyperplane)
• We need to understand• How to efficiently compute the hyperplane that separates two classes with the
largest gap?
60
Need to understand the basics of relevant optimization theory
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Brief Introduction to Optimization for Support Vector Machine
• Convex Functions• A function is called convex if the function lies below the straight line segment
connecting two points, for any two points in the interval.
• Property: Any local minimum is a global minimum.
61
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Brief Introduction to Optimization for Support Vector Machine
• Quadratic programming (QP)• Quadratic programming (QP) is a special optimization problem: the function to
optimize (objective) is quadratic, subject to linear constraints.
• Convex QP problems have convex objective functions.
• These problems can be solved easily and efficiently by greedy algorithms (because every local minimum is a global minimum).
62
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Brief Introduction to Optimization for Support Vector Machine
• Quadratic programming (QP)• [Example]
63
Consider 𝑥 = 𝑥1, 𝑥2
Minimize 1
2 𝑥 22 subject to 𝑥1 + 𝑥2 − 1 ≥ 0
Quadratic Objective Linear Constraints
Consider 𝑥 = 𝑥1, 𝑥2
Minimize 1
2𝑥12 + 𝑥2
2 subject to 𝑥1 + 𝑥2 − 1 ≥ 0
Quadratic Objective Linear Constraints
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
Outline
• Main Idea
• Hyperplane in 𝑛-Dimensional Space
• Brief Introduction to Optimization for Support Vector Machine (SVM)
• SVM for Classification
64
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• SVM for Classification• (Case 1) Linearly Separable Data; Hard-Margin Linear SVM
• (Case 2) Not Linearly Separable Data; Soft-Margin Linear SVM
• (Case 3) Not Linearly Separable Data; Kernel Trick
65
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• (Case 1) Linearly Separable Data; Hard-Margin Linear SVM
66
• Want to find a classifier (hyperplane) to separate negative instances from the positive ones.
• An infinite number of such hyperplanes exist.
• SVMs finds the hyperplane that maximizes the gap between data points on the boundaries (so-called support vectors).
• If the points on the boundaries are not informative (e.g., due to noise), SVMs will not do well.
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• (Case 1) Linearly Separable Data; Hard-Margin Linear SVM
67
• The gap is distance between two parallel hyperplanes:𝑤 ∙ 𝑥 + 𝑏 = −1 and 𝑤 ∙ 𝑥 + 𝑏 = +1
• Now, we know that
𝐷 =𝑏1−𝑏2
𝑤, i.e., 𝐷 =
2
𝑤.
• Since we have to maximize the gap, we have to minimize 𝑤 .
• Or equivalently, we have to minimize 1
2𝑤 2.
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• (Case 1) Linearly Separable Data; Hard-Margin Linear SVM
68
• In addition, we need to impose constrains that all instances are correctly classified. In our case, 𝑤 ∙ 𝑥𝑖 + 𝑏 ≤ −1 if 𝑦𝑖 = −1𝑤 ∙ 𝑥𝑖 + 𝑏 ≥ +1 if 𝑦𝑖 = +1., i.e.,equivalently, 𝑦𝑖 𝑤 ∙ 𝑥𝑖 + 𝑏 ≥ 1.
In summary,
• Minimize 1
2𝑤 2 subject to
𝑦𝑖 𝑤 ∙ 𝑥𝑖 + 𝑏 ≥ 1, for 𝑖 = 1,⋯ , 𝑁
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• (Case 2) Not Linearly Separable Data; Soft-Margin Linear SVM
69
• What if the data is not linearly separable? E.g., there are outliers or noisy measurements, or the data is slightly non-linear.
Approach• Assign a slack variable to each instance 𝜉𝑖 ≥ 0,
which can be thought of distance from the separating hyperplane if an instance is misclassified and 0 otherwise.
• Minimize 1
2𝑤 2 + 𝐶 𝑖=1
𝑁 𝜉𝑖 subject to
𝑦𝑖 𝑤 ∙ 𝑥𝑖 + 𝑏 ≥ 1 − 𝜉𝑖, for 𝑖 = 1,⋯ ,𝑁
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)
SVM for Classification
• (Case 3) Not Linearly Separable Data; Kernel Trick
70
Data is not linearly separable in the input space
Data is linearly separable in the feature space obtained by a kernel
Professor Joongheon Kim (CSE@CAU)http://sites.google.com/site/joongheon
Artificial Intelligent Lectures for Communication andNetwork Engineers/Researchers (14 April 2017)













































































![Biological sequence annotation with hidden Markov modelscompbio.fmph.uniba.sk/papers/10nanasith.pdfHidden Markov Models A hidden Markov model (HMM) [DEKM98] is a frequently used generative](https://static.documents.pub/doc/80x56/5fb45168e0de87028d36a1d7/biological-sequence-annotation-with-hidden-markov-hidden-markov-models-a-hidden.jpg)
