35
Hidden Markov Models of Haplotype Diversity and Applications in Genetic Epidemiology Ion Mandoiu University of Connecticut
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| Upload: | abner-griffith |
| View: | 214 times |
| Download: | 0 times |

Hidden Markov Models of Haplotype
Diversity and Applications in
Genetic Epidemiology
Ion Mandoiu
University of Connecticut

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Main form of variation between individual genomes: single nucleotide polymorphisms (SNPs)
High density in the human genome: 1 107 SNPs out of total 3 109 base pairs
Single Nucleotide Polymorphisms
… ataggtccCtatttcgcgcCgtatacacgggActata …… ataggtccGtatttcgcgcCgtatacacgggTctata …… ataggtccCtatttcgcgcCgtatacacgggTctata …

Haplotypes and Genotypes
Diploids: two homologous copies of each autosomal chromosome
One inherited from mother and one from father
Haplotype: description of SNP alleles on a chromosome 0/1 vector: 0 for major allele, 1 for minor
Genotype: description of alleles on both chromosomes 0/1/2 vector: 0 (1) - both chromosomes contain the major (minor)
allele; 2 - the chromosomes contain different alleles
011100110001000010021200210
+two haplotypes per individual
genotype

Sources of Haplotype Diversity: Mutation
The International HapMap Consortium. A Haplotype Map of the Human Genome. Nature 437, 1299-1320. 2005.

Sources of Haplotype Diversity: Recombination

Haplotype Structure in Human Populations

Fi = founder haplotype at locus i, Hi = observed allele at locus i
P(Fi), P(Fi | Fi-1) and P(Hi | Fi) estimated from reference genotype or haplotype data
For given haplotype h, P(H=h|M) can be computed in O(nK2) using forward algorithm
Similar models proposed in [Schwartz 04, Rastas et al. 05, Kimmel&Shamir 05, Scheet&Stephens 06]
HMM Model of Haplotype Frequencies
F1 F2 Fn…
H1 H2 Hn

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Genotype Phasing
g: 0010212 ?
h1:0010111
h2:0010010
h3:0010011
h4:0010110
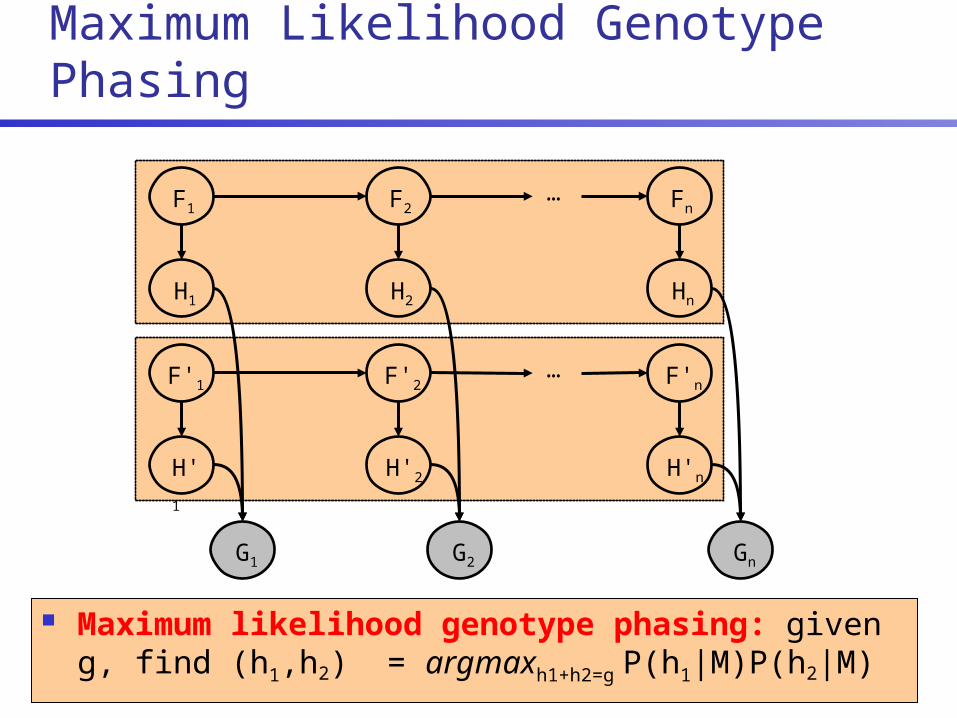
Maximum Likelihood Genotype Phasing
Maximum likelihood genotype phasing: given g, find (h1,h2) = argmaxh1+h2=g P(h1|M)P(h2|M)
F1 F2 Fn…
H1 H2 Hn
G1 G2 Gn
F'1 F'2 F'n…
H'1 H'2 H'n

Computational Complexity
• [KMP08] Cannot approximate maxh1+h2=g P(h1|M)P(h2|M) within a factor of O(n1/2 -), unless ZPP=NP
• [Rastas et al.] give Viterbi and randam sampling based heuristics that yield phasing accuracy comparable to best existing methods (PHASE)

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Genotyping Errors
A real problem despite advances in technology & typing algorithms
1.1% of 20 million dbSNP genotypes typed multiple times are inconsistent [Zaitlen et al. 2005]
Systematic errors (e.g., assay failure) typically detected by departure from HWE [Hosking et al. 2004]
In pedigrees, some errors detected as Mendelian Inconsistencies (MIs)
Many errors remain undetected As much as 70% of errors are Mendelian consistent for
mother/father/child trios [Gordon et al. 1999]

0 1 2 1 0 2
0 2 2 1 0 2
0 2 2 1 0 2
Mother Father
Child
Likelihood of best phasing for original trio T
0 1 1 1 0 0 h1
0 0 0 1 0 1 h3
0 1 1 1 0 0 h1
0 1 0 1 0 1 h2
0 0 0 1 0 1 h3
0 1 1 1 0 0 h4
)()()()( MAX)( 4321 hphphphpTL
Likelihood Sensitivity Approach to Error Detection in Trios
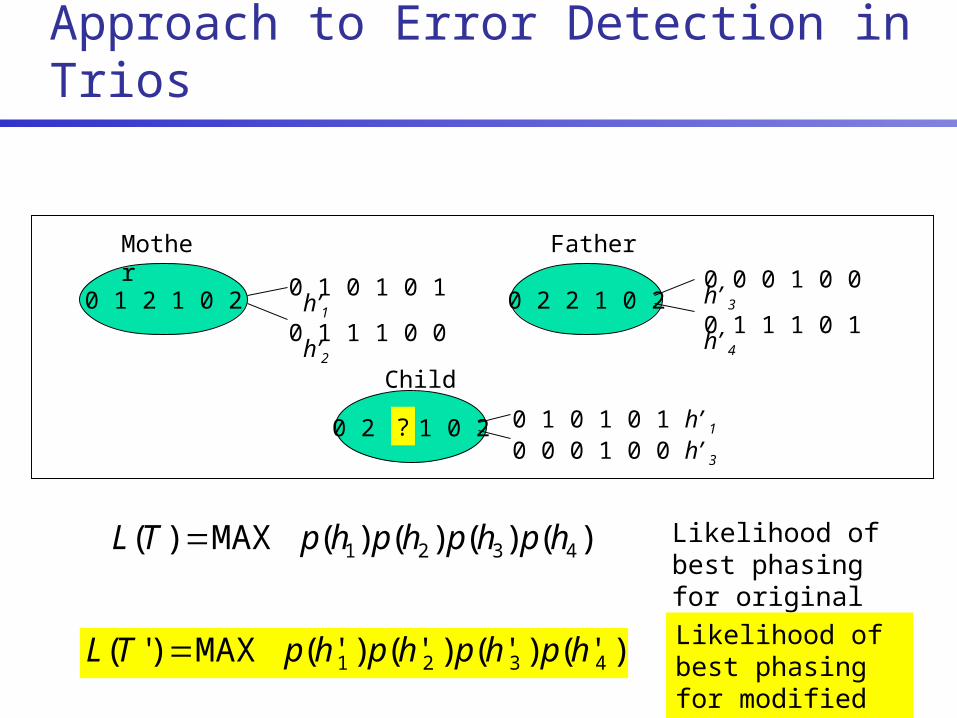
0 1 2 1 0 2
0 2 2 1 0 2
0 2 2 1 0 2
Mother Father
Child
Likelihood of best phasing for original trio T
)()()()( MAX)( 4321 hphphphpTL
? 0 1 0 1 0 1 h’ 1 0 0 0 1 0 0 h’ 3
0 1 0 1 0 1 h’1
0 1 1 1 0 0 h’2
0 0 0 1 0 0 h’ 3
0 1 1 1 0 1 h’ 4
Likelihood of best phasing for modified trio T’
)'()'()'()'( MAX)'( 4321 hphphphpTL
Likelihood Sensitivity Approach to Error Detection in Trios

0 1 2 1 0 2
0 2 2 1 0 2
0 2 2 1 0 2
Mother Father
Child
?
Large change in likelihood suggests likely error Flag genotype as an error if L(T’)/L(T) > R, where R is the detection threshold (e.g., R=104)
Likelihood Sensitivity Approach to Error Detection in Trios

Alternate Likelihood Functions
• Efficiently Computable Likelihood Functions
- Viterbi probability
- Probability of Viterbi Haplotypes
- Total Trio Probability
• [KMP08] Cannot approximate L(T) within O(n1/4 -), unless ZPP=NP

Comparison with FAMHAP (Children)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.005 0.01 0.015
FP rate
Sen
siti
vity
TotalProb-UNO
TotalProb-DUO
TotalProb-TRIO
TotalProb-COMBINED
FAMHAP-1
FAMHAP-3

Comparison with FAMHAP (Parents)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.005 0.01 0.015
FP rate
Sen
siti
vity
TotalProb-UNO
TotalProb-DUO
TotalProb-TRIO
TotalProb-COMBINED
FAMHAP-1
FAMHAP-3

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Genome-Wide Association Studies
Powerful method for finding genes associated with complex human diseases
Large number of markers (SNPs) typed in cases and controls
Disease causal SNPs unlikely to be typed directly Significant statistical power gained by performing
imputation of untyped Hapmap genotypes [WTCCC’07]

HMM Based Genotype Imputation Train HMM using the haplotypes from related
Hapmap or small cohor typed at high density
Probability of missing genotypes given the typed genotype data
gi is imputed as )|,(argmax }2,1,0{ MxggPx iix
)|(
)|,(),|(
MgP
MxggPMgxgP
i
iiii

Experimental Results
Estimates of the allele 0 frequency based on Imputation vs. Illumina 15k

Experimental Results
Accuracy and missing data rate for imputed genotypes at different thresholds

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Illumina / Solexa Genetic Analyzer 1G1000 Mb/run, 35bp reads
Roche / 454 Genome Sequencer FLX100 Mb/run, 400bp reads
Applied BiosystemsSOLiD3000 Mb/run, 25-35bp reads
New massively parallel sequencing technologies deliver orders of magnitude higher throughput compared to Sanger sequencing
Ultra-High Throughput Sequencing

F1 F2 Fn…
H1 H2 Hn
G1 G2 Gn
…R1,1 R2,1
F'1 F'2 F'n…
H'1 H'2 H'n
R1,c … R2,c …Rn,1 Rn,c1 2 n
Probabilistic Model

Initial founder probabilities P(f1), P(f’1), transition probabilities P(fi+1|fi), P(f’i+1|f’i), and emission probabilities P(hi|fi), P(h’i|f’i) trained using the Baum-Welch algorithm from haplotypes inferred from the populations of origin for mother/father
P(gi|hi,h’i) set to 1 if h+h’i=gi and to 0 otherwise
where is the probability that read r has an error at locus I
Conditional probabilities for sets of reads are given by:
Model Training
)(1)(
)()(
)()(
)(1)(, 1
2
21
2)|( ir
irir
iriir
irir
iri
iiji
gggGrRP
1)(r
)(
0)(r
)( )1()0|r(
irr
ir
irr
irii
ii
GP
0)(r
)(
1)(r
)( )1()2|r(
irr
ir
irr
irii
ii
GP ic
ii GP
2
1)1|r(
)(ir

Multilocus Genotyping Problem
GIVEN:
• Shotgun read sets r=(r1, r2, … , rn)
• Base quality scores
• HMMs for populations of origin for mother/father
FIND:
• Multilocus genotype g*=(g*1,g*2,…,g*n) with maximum posterior probability, i.e., g*=argmaxg P(g | r)

Joint probabilities can be computed using a forward-backward algorithm:
Direct implementation gives O(m+nK4) time, where m = number of reads n = number of SNPs K = number of founder haplotypes in HMMs
Runtime reduced to O(m+nK3) using speed-up idea similar to [Rastas et al. 08, Kennedy et al. 08]
)()|r()r,( '' ''1 ,1 ,, i
i
ff
K
f
i
ff
i
ff
K
fiii ggPgPiii iiiii
Posterior Decoding Algorithm1. For each i = 1..n, compute
2. Return *)*,...,(* 1 nggg
)r,(maxarg)r|(maxarg* igigi gPgPgii

Homozygous Watson SNPs (Affy 500k)
30.1
93.5
50.5
95.6
73.7
97.490.5
98.5 96.3 99.1
0
20
40
60
80
100
120
0.35
x Bi
nom
ial
0.35
x Po
ster
ior
0.70
x Bi
nom
ial
0.70
x Po
ster
ior
1.41
x Bi
nom
ial
1.41
x Po
ster
ior
2.82
x Bi
nom
ial
2.82
x Po
ster
ior
5.64
x Bi
nom
ial
5.64
x Po
ster
ior
Heterozygous Watson SNPs (Affy 500k)
2.8
67.8
9.2
80.0
25.7
88.5
54.6
93.7
82.5
96.8
0
20
40
60
80
100
120
0.35
x B
inom
ial
0.35
x P
oste
rior
0.70
x B
inom
ial
0.70
x P
oste
rior
1.41
x B
inom
ial
1.41
x P
oste
rior
2.82
x B
inom
ial
2.82
x P
oste
rior
5.64
x B
inom
ial
5.64
x P
oste
rior
Genotyping Accuracy on Watson Reads

HMM model of haplotype diversityApplications
- Phasing- Error detection- Imputation- Genotype calling from low-coverage
sequencing dataConclusions
Outline

Conclusions
HMM model of haplotype diversity provides a powerful framework for addressing central problems in population genetics & genetic epidemiology
Enables significant improvements in accuracy by exploiting the high amount of linkage disequilibrium in human populations
Despite hardness results, heuristics such as posterior or Viterbi decoding perform well in practice
Highly scalable runtime (linear in #SNPs and #individuals/reads)
Software available at http://www.engr.uconn.edu/~ion/SOFT/

Acknowledgements
Sanjiv Dinakar, Jorge Duitama, Yözen Hernández, Justin Kennedy, Bogdan Pasaniuc
NSF funding (awards IIS-0546457 and DBI-0543365)

















