1 www.bioalgorithms.info An Introduction to Bioinformatics Algorithms Slides revised and adapted to Computational Biology IST 2015/2016 Ana Teresa Freitas Hidden Markov Models CpG-Islands • Given 4 nucleotides: probability of occurrence is ~ 1/4. Thus, probability of occurrence of a dinucleotide is ~ 1/16. • However, the frequencies of dinucleotides in DNA sequences vary widely. • In particular, CG is typically underrepresented (frequency of CG is typically < 1/16)
Transcript
1
www.bioalgorithms.info An Introduction to Bioinformatics Algorithms
Slides revised and adapted to
Computational Biology
IST
2015/2016
Ana Teresa Freitas
Hidden Markov Models
CpG-Islands • Given 4 nucleotides: probability of
occurrence is ~ 1/4. Thus, probability of occurrence of a dinucleotide is ~ 1/16.
• However, the frequencies of dinucleotides in DNA sequences vary widely.
• In particular, CG is typically underrepresented (frequency of CG is typically < 1/16)
2
Why CpG-Islands? • CG is the least frequent dinucleotide because
C in CG is easily methylated and has the tendency to mutate into T afterwards
• DNA methylation involves the addition of a methyl group to DNA — for example, to the number 5 carbon of the cytosine pyrimidine ring
CpG-Islands
3
Why CpG-Islands? • DNA methylation in vertebrates typically
occurs at CpG sites (cytosine-phosphate-guanine sites, that is, where a cytosine is directly followed by a guanine in the DNA sequence).
• This methylation results in the conversion of the cytosine to 5-methylcytosine. The formation of Me-CpG is catalyzed by the enzyme DNA methyltransferase.
Why CpG-Islands? • Human DNA has about 80%-90% of CpG
sites methylated, but there are certain areas, known as CpG islands, that are CG-rich (made up of about 65% CG residues), wherein none are methylated.
• However, the methylation is suppressed around genes in a genome.
• So, finding the CpG islands in a genome is an important problem
4
Markov Process • Markov process is a simple stochastic
process in which the distribution of future states depends only on the present state and not on how it arrived in the present state.
Markov Models – A finite state representation
5
Markov Property • Many systems in real world have the property
that given present state, the past states have no influence on the future. This property is called Markov property.
State Space and Time Space
State Space
Time Space
Discrete
Continuous
Discrete
(Markov chain)
X
Continuous
X
X
6
Markov Chain Let {Xt : t is in T} be a stochastic process with discrete-state space S and discrete-time space T satisfying Markov property
Input: A short DNA sequence X = (x1,...,xL) ∈ Σ (where Σ = {A,C,G,T}).
Question: Decide whether X is a CpG island. Use two Markov chain models:
- One for dealing with CpG islands (the + model) - Other for dealing with non CpG islands
(the – model)
Problem: Identifying a CpG island Let aZY+ denote the transition probability of Z,Y ∈ Σ inside a
CpG island Let aZY- denote the transition probability of Z,Y outside a
CpG island The logarithmic likelihood score for a sequence X The higher this score, the more likely it is that X is a CpG
island
∑=
−−
+−==
L
i xixi
xixi
aa
nonCpGXPCpGXPXScore
1 ,1
,1log),(),(log)(
12
Problem: Locating CpG island in a DNA sequence Input: A long DNA sequence X = (x1,...,xL) ∈ Σ (where Σ = {A,C,G,T}).
Question: Locate the CpG islands along X The naive approach:
- Extract a sliding window Xk = (xk+1,..., xk+l) of a given lenght l (l << L) from the sequence X - Calculate Score (Xk) for each one of the resulting subsequences - Subsequences that receive positive scores are potential CpG islands
Problem: Locating CpG island in a DNA sequence Disadvantage:
- We have no information about the lenghts of the islands - Assume that the islands are at least l nucleotides long - Different windows may classify the same position differently
A better solution: a unified model
13
CG Islands and the “Fair Bet Casino”
• The CG islands problem can be modelled after a problem named “The Fair Bet Casino”
• The game is to flip coins, which results in only two possible outcomes: Head or Tail.
• The Fair coin will give Heads and Tails with same probability ½.
• The Biased coin will give Heads with prob. ¾.
The “Fair Bet Casino” (cont’d)
• Thus, we define the probabilities: • P(H|F) = P(T|F) = ½ • P(H|B) = ¾, P(T|B) = ¼ • The crooked dealer changes between Fair
and Biased coins with probability 10%
14
The Fair Bet Casino Problem
• Input: A sequence x = x1x2x3…xn of coin tosses made by two possible coins (F or B).
• Output: A sequence π = π1 π2 π3… πn, with
each πi being either F or B indicating that xi is the result of tossing the Fair or Biased coin respectively.
Problem…
Fair Bet Casino Problem Any observed outcome of coin tosses could have been generated by any sequence of states!
Need to incorporate a way to grade different sequences differently.
Decoding Problem
15
P(x|fair coin) vs. P(x|biased coin)
• Suppose first that dealer never changes coins. Some definitions: • P(x|fair coin): prob. of the dealer using the F coin and generating the outcome x. • P(x|biased coin): prob. of the dealer using
the B coin and generating outcome x.
P(x|fair coin) vs. P(x|biased coin)
• P(x|fair coin)=P(x1…xn|fair coin) Πi=1,n p (xi|fair coin)= (1/2)n
• P(x|biased coin)= P(x1…xn|biased coin)=
Πi=1,n p (xi|biased coin)=(3/4)k(1/4)n-k= 3k/4n
• k - the number of Heads in x.
16
P(x|fair coin) vs. P(x|biased coin)
• P(x|fair coin) = P(x|biased coin) 1/2n = 3k/4n 2n = 3k n = k log23 when k = n / log23 (k ~ 0.67n) If k < 0.67n, the dealer most likely used a fair
coin
Log-odds Ratio • We define log-odds ratio as follows:
log2(P(x|fair coin) / P(x|biased coin)) = Σk
i=1 log2(p+(xi) / p-(xi))
= n – k log23
17
Computing Log-odds Ratio in Sliding Windows
x1x2x3x4x5x6x7x8…xn
Consider a sliding window of the outcome sequence. Find the log-odds for this short window.
Log-odds value
0
Fair coin most likely used
Biased coin most likely used
34
Markov Chains
Sunny
Rain
Cloudy
State transition matrix : The probability of the weather given the previous day's weather.
Initial Distribution : Defining the probability of the system being in each of the states at time 0.
States : Three states - sunny, cloudy, rainy.
18
35
Hidden Markov Models
Hidden states : the (TRUE) states of a system that may be described by a Markov process (e.g., the weather). Observable states : the states of the process that are `visible' (e.g., seaweed dampness).
36
Components Of HMM
Output matrix : containing the probability of observing a particular observable state given that the hidden model is in a particular hidden state. Initial Distribution : contains the probability of the (hidden) model being in a particular hidden state at time t = 1. State transition matrix : holding the probability of a hidden state given the previous hidden state.
19
Hidden Markov Models: HMMs • There is no 1-1 correspondence between
states and (sequence) symbols. • You can’t always tell what state emitted a
particular character: states are “hidden”. • There can be more than one path that
generates any given sequence. • This allows us to model more complex
sequence distributions.
Hidden Markov Model (HMM) • Can be viewed as an abstract machine with k hidden
states that emits symbols from an alphabet Σ. • Each state has its own probability distribution, and the
machine switches between states according to this probability distribution.
• While in a certain state, the machine makes 2 decisions: • What state should I move to next? • What symbol - from the alphabet Σ - should I emit?
20
Why “Hidden”? • Observers can see the emitted symbols of an
HMM but have no ability to know which state the HMM is currently in.
• Thus, the goal is to infer the most likely hidden states of an HMM based on the given sequence of emitted symbols.
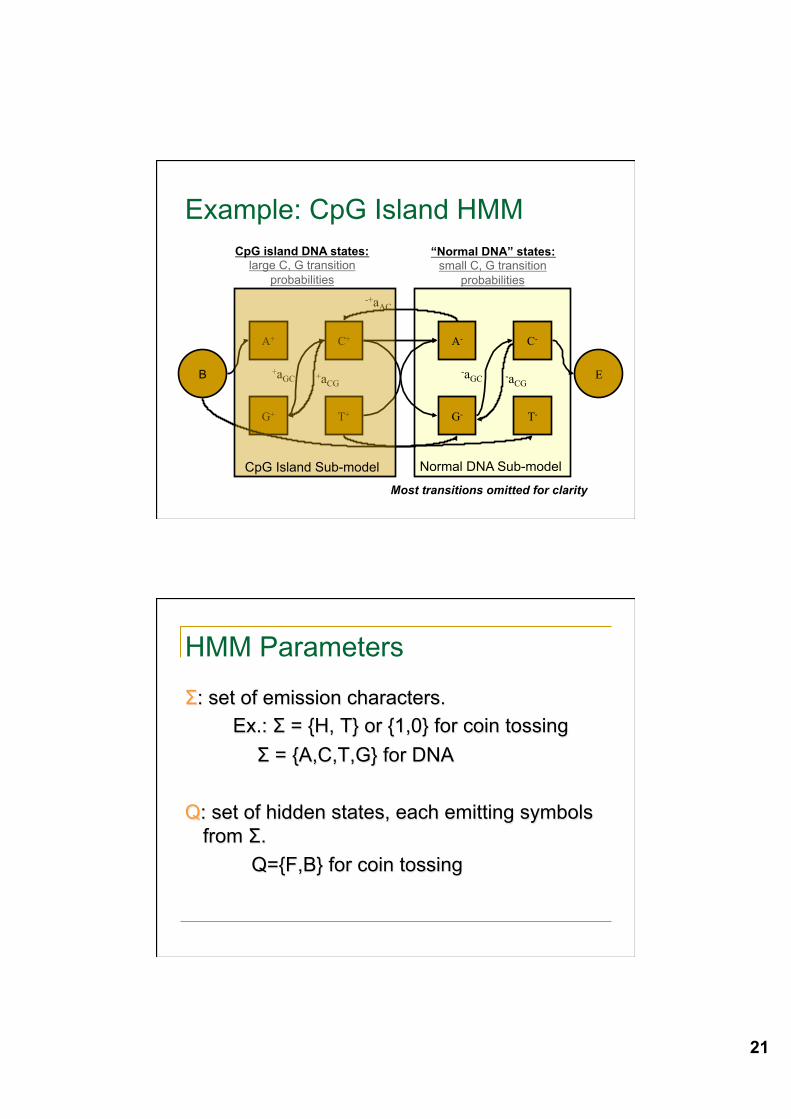
Example: Modeling CpG Islands • In a CpG island, the probability of a “C” following a “G” is
much higher than in “normal” intragenic DNA sequence. • We can construct an HMM to model this by combining two
HMMs: one for normal sequence and one for CpG island sequence.
• Transitions between the two sub-models allow the model to switch between CpG island and normal DNA.
• Because there is more than one state that can generate a given character, the states are “hidden” when you just see the sequence.
• For example, a “C” can be generated by either the C+ or C-
states in the following model.
21
Example: CpG Island HMM
Most transitions omitted for clarity
A+ C+
G+ T+
+aGC +aCG
A- C-
G- T-
-aGC -aCG B E
-+aAC
CpG island DNA states: large C, G transition
probabilities
“Normal DNA” states: small C, G transition
probabilities
CpG Island Sub-model Normal DNA Sub-model
HMM Parameters Σ: set of emission characters.
Ex.: Σ = {H, T} or {1,0} for coin tossing Σ = {A,C,T,G} for DNA Q: set of hidden states, each emitting symbols
from Σ. Q={F,B} for coin tossing
22
HMM Parameters (cont’d)
A = (akl): a |Q| x |Q| matrix of probability of changing from state k to state l.
aFF = 0.9 aFB = 0.1 aBF = 0.1 aBB = 0.9
E = (ek(b)): a |Q| x |Σ| matrix of probability of emitting symbol b while being in state k.
eF(0) = ½ eF(1) = ½ eB(0) = ¼ eB(1) = ¾
HMM for Fair Bet Casino (cont’d)
HMM model for the Fair Bet Casino Problem
23
HMM for Fair Bet Casino
• The Fair Bet Casino in HMM terms: Σ = {0, 1} (0 for Tails and 1 Heads) Q = {F,B} – F for Fair & B for Biased coin.
• Transition Probabilities A *** Emission Probabilities E
A Fair Biased
Fair aFF = 0.9 aFB = 0.1
Biased aBF = 0.1 aBB = 0.9
E Tails(0) Heads(1)
Fair eF(0) = ½ eF(1) = ½
Biased
eB(0) = ¼ eB(1) = ¾
Hidden Paths
• A path π = π1… πn in the HMM is defined as a sequence of states.
• Consider path π = FFFBBBBBFFF and sequence x = 01011101001
x 0 1 0 1 1 1 0 1 0 0 1
π = F F F B B B B B F F F P(xi|πi) ½ ½ ½ ¾ ¾ ¾ ¼ ¾ ½ ½ ½
P(πi-1 à πi) ½ 9/10 9/10 1/10
9/10 9/10
9/10 9/10
1/10 9/10
9/10
Transition probability from state πi-1 to state πi
Probability that xi was emitted from state πi
24
P(x,π) Calculation • P(x,π): Probability that sequence x was generated
by the path π: n P(x,π) = P(π0→ π1) . Π P(xi| πi) · P(πi → πi+1)
i=1
= a π0, π1 · Π e πi (xi) · a πi, πi+1
π0 and πn+1 represent the fictitious initial and terminal state (begin and end)