Lauren Parker & Wei Ying| MUSA 507 | HW 5 Page | 1 LAUREN PARKER & WEI YING MUSA 507: MIDTERM Due: Oct. 17, 2014 1 Introduction The purpose of this project is to develop a regression model that can accurately predict home sale prices at multiple locations within Philadelphia. Property is a significant part of economy as well as relevant to city planning; as such, housing market prediction has a great impact on housing trade and economic development. Accordingly, accurate predictions of housing prices is a vital task, to which we should focus much attention. However, making accurate predictions is anything but an easy work, for the variability of actual home prices is affected by many factors. Therefore, the first challenge of this project is to determine what factors are related to home price by referring to housing articles and by testing candidate variablescorrelation to the home prices. Additionally, the accuracy of prediction depends on the regression model we build, but linear regressions are a somewhat simple approximation of reality and can fail to explain the exact relationship between independent variables and the dependent variable. Therefore, finding variables that are highly related to home prices is an important, yet difficult task for a good linear regression model. Our overall modeling strategy is building and improving a regression model using data of trainingsites, or observations for which we have home sale prices, and then using our best model to predict sales foƌ a test dataset, or sites for which we have no sale price. We set existing home prices of training sites as the dependent variable and compile several explanatory factors as independent variables. We check the relationship between each independent variable and home prices in order to make log transformations when necessary and remove outliers to improve the model. We then test the regression model within the training data and judge the residual error between actual values and predicted values. We included 12 variables in the final regression. The adjusted R 2 of our model in training samples is 0.56, which suggests a relatively explanatory regression. In our out of sample testing, we got a R 2 as 0.5624, and the root mean square error (RMSE) of 0.8533, which is generally a strong model. Overall, we believe the regression model to be a fairly reliable way to predict home prices in Philadelphia. 2 Methodology Data Collection and Processing In addition to the data originally provided by Ken Steif, we tried to find other possible variables that may explain home prices. Figure 1 presents all of our original candidate variables, data sources and processing steps. In total, we tested 44 variables to determine which were best at improving the explanatory power of the model. We also present maps of our dependent variable (Figure 2) and several key independent variables (Figure 3). Figure 1. Table of all variables tested for explanatory power. Variaďle DesĐriptioŶ Data SourĐe ProĐessiŶg KeŶ_ID UŶiƋue ID KeŶ “teif SalePriĐe DepeŶdeŶt Vaƌiaďles ;sale iŶ dollaƌsͿ KeŶ “teif SaleMoŶth MoŶth of the LJeaƌ iŶ ϮϬϭϮ of sale KeŶ “teif FroŶtage ǁidth of paƌĐel KeŶ “teif Depth leŶgth of paƌĐel KeŶ “teif GarageDuŵ Whetheƌ ĐoŶtaiŶ gaƌage KeŶ “teif EdžtCoŶd CategoƌiĐal ǀaƌiaďle desĐƌiďiŶg ĐoŶditioŶ of ďuildiŶg edžteƌioƌ KeŶ “teif
Transcript
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 1
LAUREN PARKER & WEI YING
MUSA 507: MIDTERM
Due: Oct. 17, 2014
1 Introduction
The purpose of this project is to develop a regression model that can accurately predict home sale prices at multiple
locations within Philadelphia. Property is a significant part of economy as well as relevant to city planning; as such,
housing market prediction has a great impact on housing trade and economic development. Accordingly, accurate
predictions of housing prices is a vital task, to which we should focus much attention.
However, making accurate predictions is anything but an easy work, for the variability of actual home prices is affected
by many factors. Therefore, the first challenge of this project is to determine what factors are related to home price by
referring to housing articles and by testing candidate variables correlation to the home prices. Additionally, the
accuracy of prediction depends on the regression model we build, but linear regressions are a somewhat simple
approximation of reality and can fail to explain the exact relationship between independent variables and the
dependent variable. Therefore, finding variables that are highly related to home prices is an important, yet difficult task
for a good linear regression model.
Our overall modeling strategy is building and improving a regression model using data of training sites, or observations
for which we have home sale prices, and then using our best model to predict sales fo a test dataset, or sites for
which we have no sale price. We set existing home prices of training sites as the dependent variable and compile several
explanatory factors as independent variables. We check the relationship between each independent variable and home
prices in order to make log transformations when necessary and remove outliers to improve the model. We then test
the regression model within the training data and judge the residual error between actual values and predicted values.
We included 12 variables in the final regression. The adjusted R2 of our model in training samples is 0.56, which suggests
a relatively explanatory regression. In our out of sample testing, we got a R2 as 0.5624, and the root mean square error
(RMSE) of 0.8533, which is generally a strong model. Overall, we believe the regression model to be a fairly reliable way
to predict home prices in Philadelphia.
2 Methodology
Data Collection and Processing
In addition to the data originally provided by Ken Steif, we tried to find other possible variables that may explain home
prices. Figure 1 presents all of our original candidate variables, data sources and processing steps. In total, we tested 44
variables to determine which were best at improving the explanatory power of the model. We also present maps of our
dependent variable (Figure 2) and several key independent variables (Figure 3).
Figure 1. Table of all variables tested for explanatory power.
Varia le Des riptio Data Sour e Pro essi g
Ke _ID U i ue ID Ke “teif
SalePri e Depe de t Va ia les sale i dolla s Ke “teif
SaleMo th Mo th of the ea i of sale Ke “teif
Fro tage idth of pa el Ke “teif
Depth le gth of pa el Ke “teif
GarageDu Whethe o tai ga age Ke “teif
E tCo d Catego i al a ia le des i i g o ditio of uildi g e te io
Ke “teif
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 2
Varia le Des riptio Data Sour e Pro essi g
YearBuilt ea of o st u tio Ke “teif
Nu Roo s Nu e of oo s Ke “teif
Nu BedR s Nu e of ed oo s Ke “teif
Nu Baths Nu e of aths Ke “teif
TotLi Area Total i te al s ua e footage Ke “teif
Pop Populatio i i lo k g oup of house poi t. Ce sus Bu eau, A GI“: spatial joi losest pol go
MedI Media household i o e of lo k g oup of house. A e i a Co u it “u e , -
A GI“: spatial joi losest pol go
White Nu e of hite households i lo k g oup of house. Ce sus Bu eau, A GI“: spatial joi losest pol go
AfA Nu e of Af i a -A e i a households i lo k g oup of house.
Ce sus Bu eau, A GI“: spatial joi losest pol go
A I Nu e of A e i a I dia households i lo k g oup of house.
Ce sus Bu eau, A GI“: spatial joi losest pol go
Asia Nu e of Asia households i lo k g oup of house. Ce sus Bu eau, A GI“: spatial joi losest pol go
HiPI Nu e of Ha aiia a d Pa ifi Isla de households i lo k g oup of house.
Ce sus Bu eau, A GI“: spatial joi losest pol go
Other Nu e of households of "Othe " a e i lo k g oup of house.
Ce sus Bu eau, A GI“: spatial joi losest pol go
T oRa e Nu e of households of "T o ‘a es" i lo k g oup of house.
Ce sus Bu eau, A GI“: spatial joi losest pol go
HH Nu e of households i lo k g oup. Ce sus Bu eau, A GI“: spatial joi losest pol go
O HH Nu e of o upied households i lo k g oup. Ce sus Bu eau, A GI“: spatial joi losest pol go
Va HH Nu e of a a t households i lo k g oup. Ce sus Bu eau, A GI“: spatial joi losest pol go
P tWhite Pe e t White households i lo k g oup. Ce sus Bu eau, A GI“: spatial joi losest pol go
A eTa MktVal A e age a ket alue of houses ea est to Ke 's house.
Cit of Phila. Offi e of P ope t Assess e t
A GI“: Ge e ate Nea Ta le tool; ge e ate a e age a ket alue of eigh o houses
S hDistFt Dista e ft to losest s hool. PA“DA A GI“: spatial joi losest poi t
BusDistFt Dista e ft to losest us stop. DV‘PC A GI“: spatial joi losest poi t
StrDistFt Dista e ft to losest st eet i te se tio . DV‘PC A GI“: spatial joi losest pol go
ParkDis Dista e ft to losest pa k poi t Ope Data Phill A GI“: spatial joi losest pol li e
HealthDis Dista e ft to losest health e te Ope Data Phill A GI“: spatial joi losest poi t
Re reaDis Dista e ft to losest e eatio pla e Ope Data Phill A GI“: spatial joi losest poi t
A eSalePrKe Near A e age sale p i e of houses ea est Ke 's house. Ke “teif A GI“: Ge e ate Nea Ta le tool
E pP tLa or E plo e t ate i hole la o fo e i e sus t a t of house poi t
A e i a Co u it “u e Cal ulate the pe e tage
E pP tTotal E plo e t ate i total populatio i e sus t a t of house poi t
A e i a Co u it “u e Cal ulate the pe e tage
GMAA ePri e A e age sale p i e of Ke 's houses ithi ea h Geog aphi Ma ket A ea GMA .
Ope Data Phill A GI“: spatial joi a e age
Ce terCit Dis Dista e ft to Philadelphia e te it Ope Data Phill A GI“: spatial joi losest pol go
ParkPolDis Dista e ft to losest pa k pol go Ope Data Phill A GI“: spatial joi losest pol go
Co erDis Dista e ft to losest o e ial zo e Ope Data Phill A GI“: spatial joi losest pol go
I dusDis Dista e ft to losest i dust zo e Ope Data Phill A GI“: spatial joi losest pol go
WaterDis Dista e ft to losest h d olog pol go Ope Data Phill A GI“: spatial joi losest pol go
Parki gDis Dista e ft to losest pa ki g lot Ope Data Phill A GI“: spatial joi losest poi t
ParkNo Nu e of pa ks ithi . - ile uffe of house poi t Ope Data Phill A GI“: uffe ; spatial joi ou t
Re reNo Nu e of e eatio pla es ithi . - ile uffe of house poi t
Ope Data Phill A GI“: uffe ; spatial joi ou t
Parki gNo Nu e of pa ki g lots ithi . - ile uffe of house poi t
Ope Data Phill A GI“: uffe ; spatial joi ou t
Distri ts_I de Du : if Ke 's house as i of dist i ts. “et as fi ed a ia les e.g.Dist i t_
Ope Data Phill A GI“: spatial joi poi t falls i side
Co ditio _I de Du a ia le i di ati g o ditio of uildi g e te io e.g. HighCo d
Ke “teif Mask sites o ditio as High o ditio , Mediu Co ditio o Lo o ditio
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 3
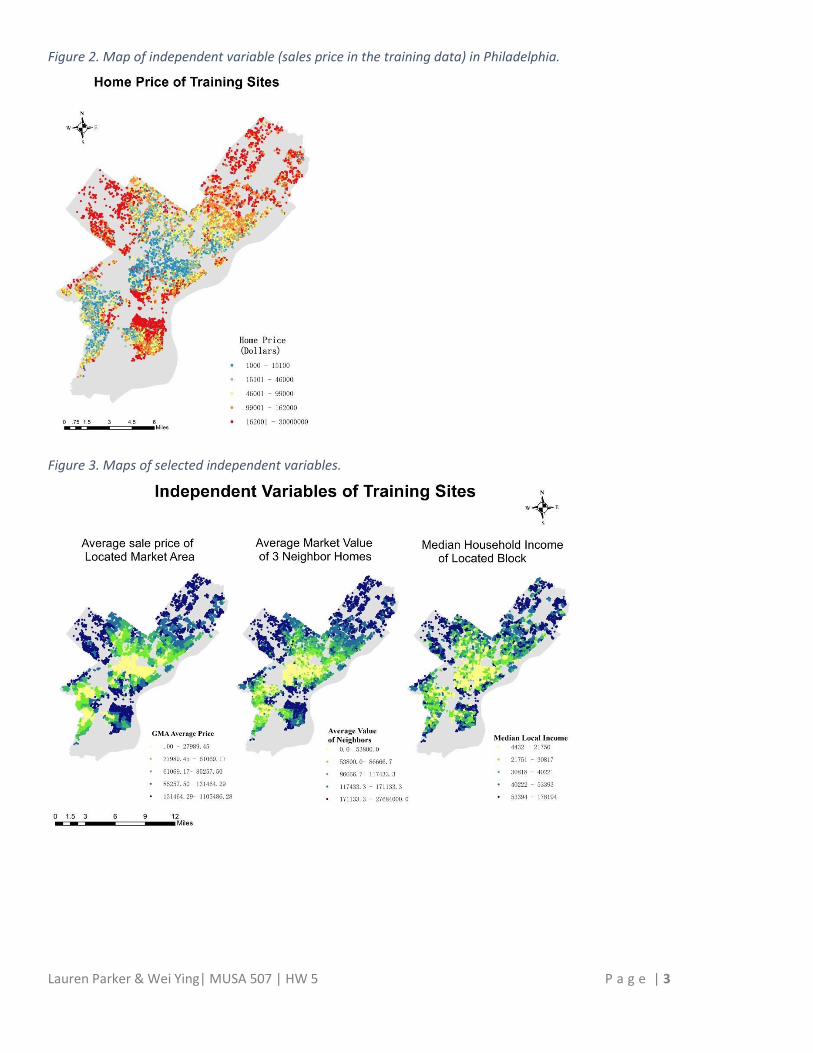
Figure 2. Map of independent variable (sales price in the training data) in Philadelphia.
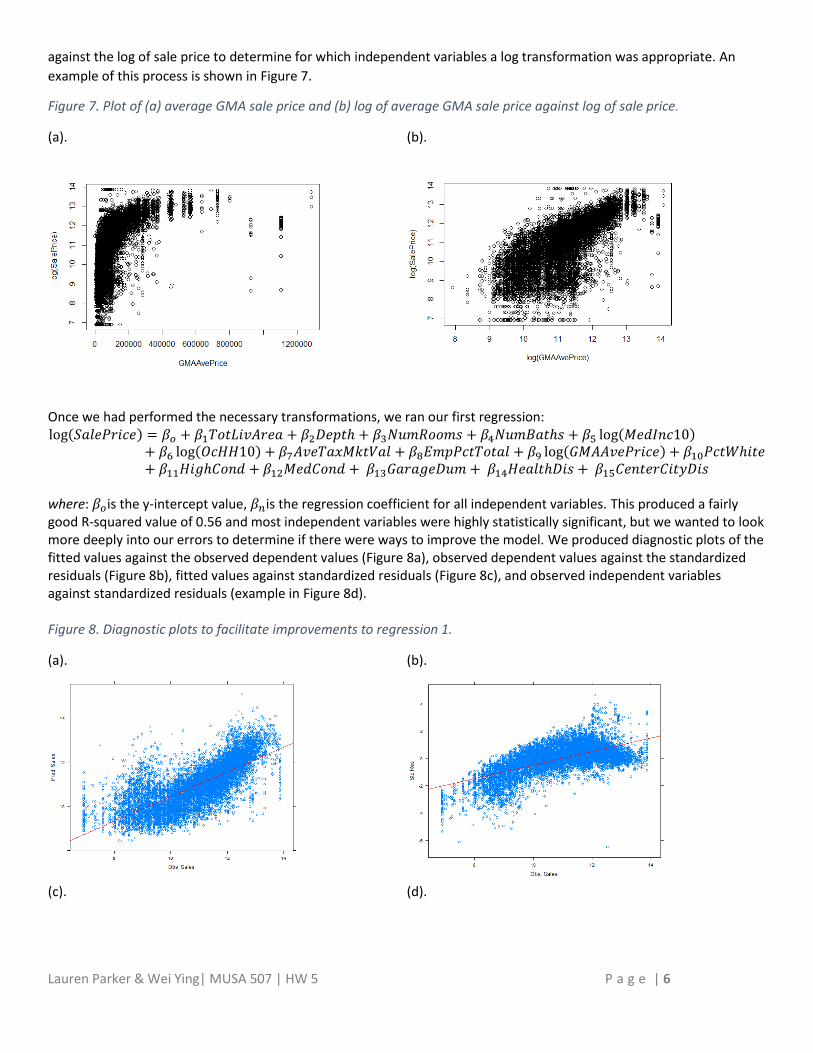
Figure 3. Maps of selected independent variables.
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 4
Methods
Our methodology involved 6 main parts: 1) preparing our dependent and independent variables before running the first
regression model, 2) running the first regression model, 3) removing variables and improving the model based on results
of regression 1, 4) running our final regression, 5) performing validation tests on our training dataset, and 6) making sale
price predictions on our test dataset. A flow chart of our methodology is presented in Figure 4.
Figure 4. Flow chart illustrating the methodology of the regression analysis.
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 5
We began by taking a subset of the data to only include training sites (n=12,155). We then removed any observations
that had very high values for sales price (above $1,100,000); these observations were considered to be outliers, and as
such, would reduce the predictive capability of the model. We then plotted a histogram of the sales price for all
remaining observations to determine if a log transformation would be appropriate. An exponential trend was observed,
so we did indeed use a log transformation of the dependent variable (Figure 5).
Figure 5. Histograms of (a) sale price, and (b) log(sale price) with a more normal distribution.
(a).
(b).
Before running a regression model, we tried to check for any correlation between each pair of variables in an effort to
omit any variables that were collinear. In Figure 6, we present 15 representative variables in a sample correlation matrix.
Figure 6. Correlation matrix between a sample of independent variables.
As shown in the matrix above, it is clear that using total households (HH10) and total occupied households (OcHH10) in
our regression, for example, would not be sound as these two variables were highly collinear. Based on the correlation
matrix, we removed total households as a candidate variable. We then plotted the each remaining independent variable
Key:
1. log(SalePrice) 6. HH10 11. CenterCityDis
2. TotLivArea 7. OcHH10 12. PctWhite
3. Depth 8. AveTaxMktVal 13. BusDistFt
4. NumRooms 9. EmpPctTotal 14. ParkingDis
5 MedInc10 10. GMAAvePrice 15. HealthDis
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 6
against the log of sale price to determine for which independent variables a log transformation was appropriate. An
example of this process is shown in Figure 7.
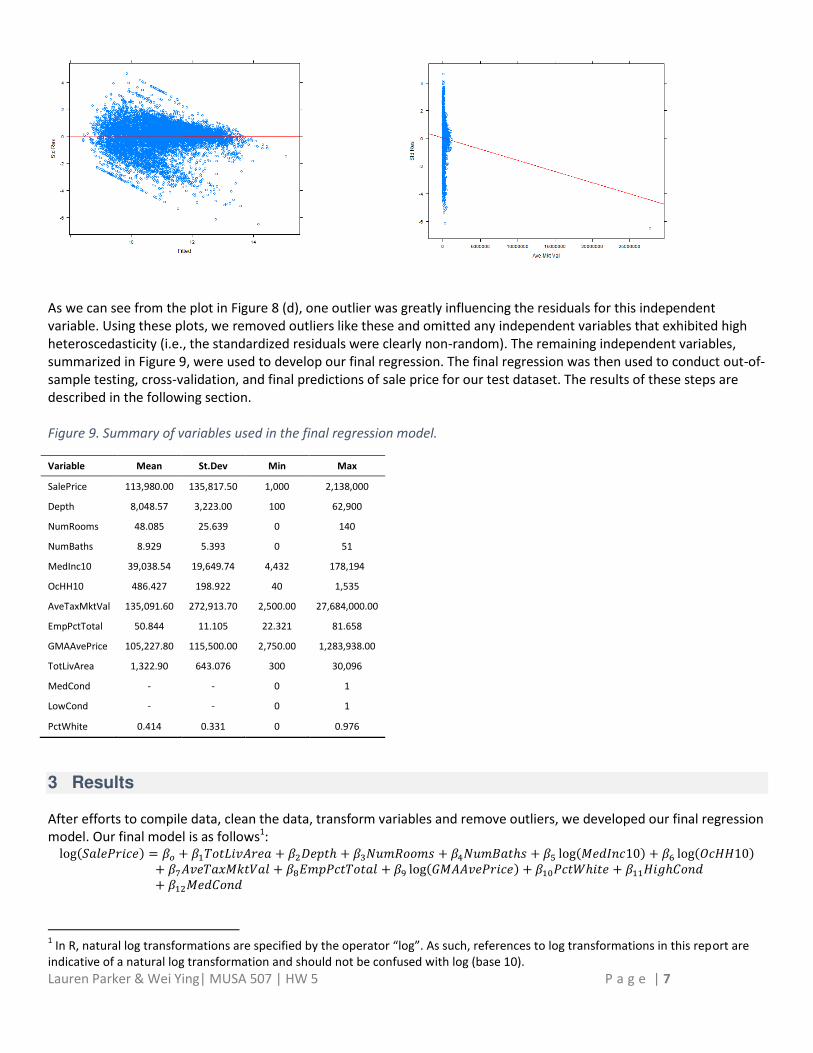
Figure 7. Plot of (a) average GMA sale price and (b) log of average GMA sale price against log of sale price.
(a).
(b).
Once we had performed the necessary transformations, we ran our first regression: log � � = � + � � � + � ℎ + � + � � ℎ + � log+ � log + � � � + � � + � log � + � ℎ�+ � ��ℎ + � + � � �� + � � ℎ � + � � �
where: � is the y-intercept value, � is the regression coefficient for all independent variables. This produced a fairly
good R-squared value of 0.56 and most independent variables were highly statistically significant, but we wanted to look
more deeply into our errors to determine if there were ways to improve the model. We produced diagnostic plots of the
fitted values against the observed dependent values (Figure 8a), observed dependent values against the standardized
residuals (Figure 8b), fitted values against standardized residuals (Figure 8c), and observed independent variables
against standardized residuals (example in Figure 8d).
Figure 8. Diagnostic plots to facilitate improvements to regression 1.
(a).
(b).
(c). (d).
Lauren Parker & Wei Ying| MUSA 507 | HW 5 P a g e | 7
As we can see from the plot in Figure 8 (d), one outlier was greatly influencing the residuals for this independent
variable. Using these plots, we removed outliers like these and omitted any independent variables that exhibited high
heteroscedasticity (i.e., the standardized residuals were clearly non-random). The remaining independent variables,
summarized in Figure 9, were used to develop our final regression. The final regression was then used to conduct out-of-
sample testing, cross-validation, and final predictions of sale price for our test dataset. The results of these steps are
described in the following section.
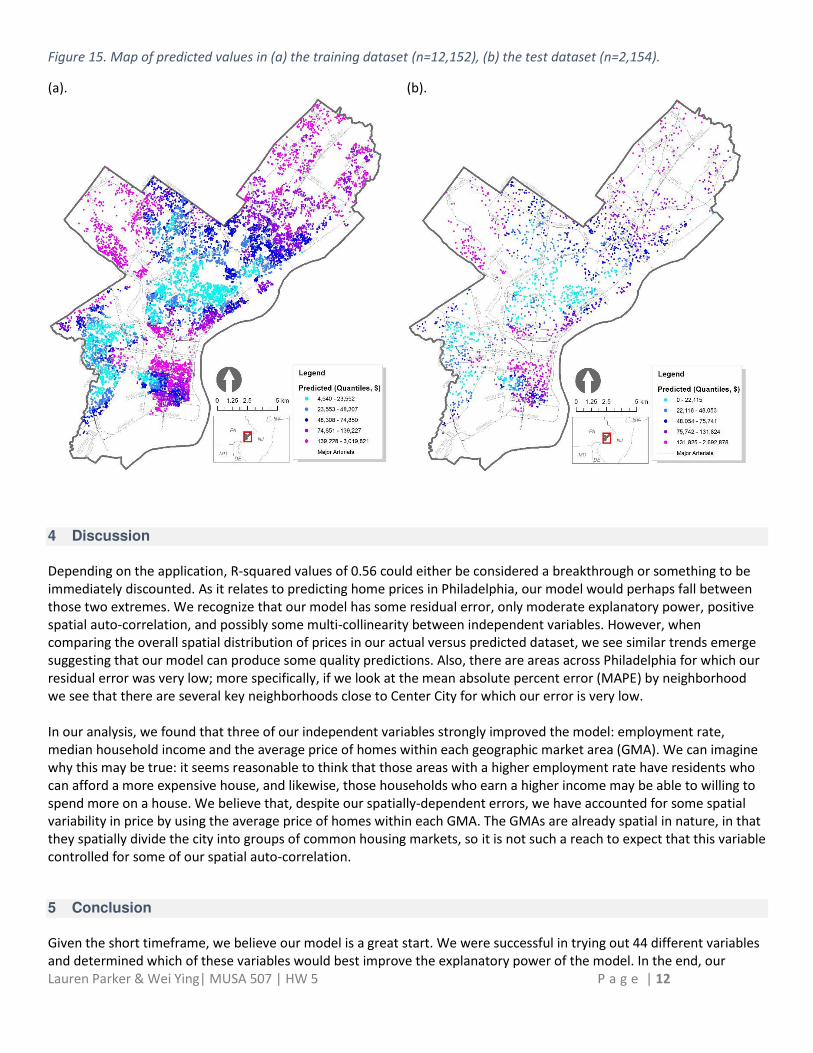
Figure 9. Summary of variables used in the final regression model.