53
HPC TECHNOLOGIES APPLIED TO THE BURROWS-WHEELER TRANSFORM TO ENHANCE SHORT READ ASSEMBLY Ignacio Blanquer
| Date post: | 12-Jan-2016 |
| Category: |
Documents |
| Upload: | elinor-spencer |
| View: | 220 times |
| Download: | 0 times |

HPC TECHNOLOGIES APPLIED TO THE BURROWS-WHEELER
TRANSFORM TO ENHANCE SHORT READ ASSEMBLY
Ignacio Blanquer

2
OBJECTIVES
• To justify the suitability of Burrows-Wheeler Transform for problems related with NGS, especially alignment and assembly.
• To present how GPUs can provide the computing resources needed for the large scale problems in assembly and NGS.
• To discuss about limitations and other approaches.
• All the work presented here is part of a collaboration between the I3M and the CIPF – Thanks to Ignacio Medina, José Salavert, Joaquin
Tárraga and Joaquin Dopazo.– First results published in Salavert J, Blanquer I, Tomas A, et al. "Using
GPUs for the Exact Alignment of Short-read Genetic Sequences by Means of the Burrows—Wheeler Transform“ IEEE/ACM transactions on computational biology and bioinformatics / IEEE, ACM. 2012.
SeqAhead Workshop on HPC4NGS

3
I AM A COMPUTER SCIENTIST(NOBODY IS PERFECT)
• Member of the High Performance and Grid Computing Research Group.
• Working in Medical and Life Science applications.
• Responsible of application communities in the Spanish e-Science Network, and VENUS-C cloud computing project.
SeqAhead Workshop on HPC4NGS

4
CONTENT
• The problem of assembly• The overlap detection: a main bottleneck for NGS• Techniques for efficiently mapping short reads
– Suffix tries and Suffix arrays.– Burrows-Wheeler Transform.– FM-Index.
• Porting of FM-Index based searching tool in GPUs– Zero-error techniques.– One-error techniques.– Bottlenecks and improvements.
• Extension to the problem of assembly.• Conclusions.
SeqAhead Workshop on HPC4NGS

5
THE PROBLEM OF ASSEMBLY IN NGS
• A puzzle with tens of thousands of million of pieces– Many of them are repeated.– Some of them are missing.– There is no exact reference, and
sometimes even there is no reference at all.
• Finding 1010 needles in 1010 haystacks!
SeqAhead Workshop on HPC4NGS

6
STAGES IN THE ASSEMBLY
• Experiments• Preprocessing• Overlap Detection• Layout• Consensus Sequence• Analysis
SeqAhead Workshop on HPC4NGS
Idury, R.M. & Waterman, M.S. “A new algorithm for DNA sequence assembly”.J. Comput. Biol. 2, 291–306 (1995).
T. Chen, S.. Skiena, “Trie..Based Data Structures for Sequence Assembly”,Combinatorial Pattern Matching 1997

7
COMPUTATIONAL ANALYSIS
• For the hard stages– Overlap detection1
• In practical terms, limited in the best case by |X|·log(|X|)+|X|·avg(|Xi|).
– Layout and Consensus Sequence2
• Described as a bidirectional weighted graph– Nodes are the different sequences and arrows describe
overlaps.– Arrows’ weights typically define the unoverlapped
fragment.
• Typically NP-Hard, but there exist solutions in O(|E|2log2(|V|))
– |E| is the number of cycles and |V| is the maximum number of nodes.
SeqAhead Workshop on HPC4NGS
1 Jared T Simpson and Richard Durbin, Efficient de novo assembly of large genomes using compressed data structures, Genome Res. December, 2011
2 Medvedev P, Georgiou K, Myers G, Brudno M: Computability of Models for Sequence Assembly.Lecture Notes in Computer Science 2007, 4645:289-301.

8
OVERLAP DETECTION
SeqAhead Workshop on HPC4NGS

9
NOMENCLATURE
• X = {X1…Xu} is the set of all the u sequences in a NGS experiment.
• Each sequence Xi has a length of ni elements over an alphabet S of 4 symbols.– For simplicity, quality indicators are not
considered in the algorithms.– Actually implemented in the
final versions.
• W denotes a sequence to be searched over X or Xi.
SeqAhead Workshop on HPC4NGS

10
THE OVERLAP DETECTION
• Problem:– To find all pairs Xi , Xj that fulfil
• Xi -> Xj in at least k elements
• Xi -> Xj if Xj[ni-k..ni] == Xi[1: k ].
– In a brute-force approach, it will require checking each Xi with respect any Xj , i != j
• A NGS experiment may involve 20 Gigabases.• Unfeasible for any traditional searching
process (FASTA, BLAST, SW, etc.).
– Need for advanced searching structures.
Xi
Xj
k
SeqAhead Workshop on HPC4NGS

11
THE OVERLAP DETECTION
• Issues– Computational time
• We should avoid complete cross comparison. • Linear or quasi-linear methods are needed.
– Memory storage• Indexed searching requires 9-10 bytes per
base.• This would mean around 200 GB RAM.
• Need for efficient structures
SeqAhead Workshop on HPC4NGS

12
SEARCHING STRUCTURES
• Different structures speed-up the process of searching also
reducing memory requirements– Suffix arrays– Suffix tries– BWT-based Suffix tries– FM-Index.
• These techniques are also valuable when searching for short seeds that are then extended using dynamic programming– E.g. Smith-Waterman.
SeqAhead Workshop on HPC4NGS

13
SUFFIX ARRAYS & SUFFIX TREES
SeqAhead Workshop on HPC4NGS

14
SUFFIX ARRAYS
• A sorted list of the indexes to the different suffixes of a sequence.
• Can be built in O(n·log(n)) time– Being “n” the size of
the text.– Need 6n bytes and
searching for a string of length “p” requires O (p·log(n)).
1 2 3 4 5 6X = A G G A G C
6 C5 G C4 A G C3 G A G C2 G G A G C1 A G G A G C
351462
1 2 3 4 5 6S A = 4 1 6 3 5 2
W = “GAG”Li=1; Ls=6-> k=(6+1)/2-> 3
SA(3) = 6-> X(6:$) = “C” < W
Li=4; Ls=6-> k=(4+6)/2 -> 5SA(5) = 5-> X(5:$) = “GC” > W
Li=4; Ls=4 -> k=(4+4)/2-> 4SA(4) = 3-> X(3:$) = “GAGC” = WSeqAhead Workshop on HPC4NGS

15
SUFFIX TREES AND SUFFIX TRIES
• A Trie (from reTRIEval) is a special tree used to code the suffixes of a string or group of strings.
• Equivalent to the Suffix Array.
• By condexing the different leaves, a Suffix Tree is obtained.
1 2 3 4 5 6X = A G G A G C
6
3 2 15 4
CG
A
AGC GAGCC GAGC
C
SeqAhead Workshop on HPC4NGS
6
3
2 1
5 4
CG
A
A GC G
C
AAG
GGC
CC
Suffix Trie
Suffix Tree

16
BURROWS-WHEELER TRANSFORM
SeqAhead Workshop on HPC4NGS

BURROWS-WHEELER TRANSFORM
• Typically used in bzip compression and text searching.
• It consist on a sequence of all the previous characters to the beginnings of a Suffix Array.
• It can be seen as the last character of all the sorted rotations of the reference sequence.
• The BWT groups all possible suffixes speeding up the searching.
0123456
6305241
0 1 2 3 4 5 6
SeqAhead Workshop on HPC4NGS 17

RECOVERING THE ORIGINAL TEXT FROM BWT
• In order to recover the original text, only first and last (BWT) columns are needed• Starting from the last simbol B(2)
-> ‘$’.• The first symbol of the original
string should be F(2) -> ‘A’.• The following symbol should be
the first one in the row that ended by this ‘A’.
• Since it is the second ‘A’, it should be also the second one in the BWT -> B(6).
• So first one is F(6) -> ‘G’.
• The recurring sequence gives the original string:
• F(2), F(6), F(4), F(1), F(5), F(3), F(0)
• AGGAG$
0 1 2 3 4 5 6X = A G G A G C $
0123456
0 1 2 3 4 5 6B = C G $ G G A A
F B
6305241
SeqAhead Workshop on HPC4NGS 18

TRANSFORMADA BURROWS-WHEELER (BWT)
• The leaves of the suffix tree are anotated with the range of suffixes that match the input sequence.
• The advantage is that each node groups several matches and provides additional
information to deal with errors.
0,6
1,2
4,6
3,3
1,2 6,6
5,5
1,1
4,4
6,6
2,2
2,2
2,2
2,2
4,4
6,6
2,2
2,2
1,2
4,4
6,6
2,2
2,2
1,2
A
A
A
A
AA
A
G
G
G
G
GG
G
G
G
C
^
^
^
^
^
^
0123456
R= “^AGGAGC$”
6305241 0 1 2 3 4 5 6
SeqAhead Workshop on HPC4NGS 19

TRANSFORMADA BURROWS-WHEELER (BWT)
• AGC (Max 1F) • $ [0,6]
• agA (1F) [1,2]• A,C exclued.• aGA (1F) [4,4]
• A,C excluded.• GGA (2F) [6,6] > X
• agC (0F) [3,3]• A,C excluded.• aGC (0F) [5,5]
• C,G excluded.• AGC (0F) [1,1] > V
• agG (1F) [4,6]• C excluded.• aAG (2F) [1,2] > X• aGG (1F) [6,6]
• C, G excluded.• AGG (1F) [2,2] V
0123456
0,6
1,2
4,6
1,2 6,6
5,5
1,1
4,4
6,6
2,2
2,2
2,2
2,2
4,4
6,6
2,2
2,2
1,2
4,4
6,6
2,2
2,2
1,2
A
A
A
A
AA
A
G
G
G
G
GG
G
G
G
C
^
^
^
^
^
^
3,3
0,6
1,2
4,6
1,2 6,6
5,5
1,1
4,4
6,6
2,2
2,2
2,2
2,2
4,4
6,6
2,2
2,2
1,2
4,4
6,6
2,2
2,2
1,2
A
A
A
A
AA
A
G
G
G
G
GG
G
G
G
C
^
^
^
^
^
^
3,3
R= “AGGAGC$”
6
3
0
5
2
4
1
0 1 2 3 4 5 6
SeqAhead Workshop on HPC4NGS 20

21
FM-INDEX
SeqAhead Workshop on HPC4NGS

FM-INDEX
• Presented by Ferragina and Manzini (*)• Provides an efficient way to construct
and traverse a BWT suffix tree• Construction in O(n) time once the BWT is
constructed.• Searching in linear time proportional to the
length of the input sequence.
(*) Ferragina, P. and Manzini, G. (2000).Opportunistic data structures with applications. In 41st IEEE Sumposium on Foundations of Computer Science, FOCS, 390-398
SeqAhead Workshop on HPC4NGS 22

FM-INDEX
• Using the BWT, two data structures are created enabling searching in linear time.• Vector C contains the cummulative number
of occurences in the BWT for each one of the symbols in the alphabet, including their
predecessors.• Matrix O contains the number
of occurences for each symbol at each element in the
BWT.
BWT = “C$GGGAA”A C G T
A
C
G
T
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
SeqAhead Workshop on HPC4NGS 23

SEARCHING WITH THE FM-INDEX
• Searching along the tree• We use the formula:
k = C(b) + O(b, k) + 1
l = C(b) + O(b, l + 1)
Where b is the character to be processed.
• String is searched reversely.
• C represents the number of suffixes whose starts is alphabetically lower• E.g. the offset in the M matrix of the BWT.
• O represents the offset within the block of sequences where the complete actual sequence could appear.
SeqAhead Workshop on HPC4NGS
0123456
6
3
0
5
2
4
1
24

SEARCHING WITH THE FM-INDEXEXAMPLE
• X = “AGGAGC”, W=“GAG”• “G”: k=0, l=6
• k=C(G)+O(G,k)+1=3+0+1=4• l=C(G)+O(G,l+1)=3+3=6• [4,6] are the 3 sequences ending by
“G”.
• “A”: k=4, l=6• k=C(A)+O(A,k)+1=0+0+1=1• l=C(A)+O(A,l+1)=0+2=2• [1,2] are the 2 sequences ending by
“AG”.
• “G”: k=1, l=2• k=C(G)+O(G,k)+1=3+0+1=4• l=C(G)+O(G,l+1)=3+1=4• [4,4] is the sequence ending by “GAG”.
SeqAhead Workshop on HPC4NGS
0123456
6
3
0
5
2
4
1
A C G T
A
C
G
T
0 1 2 3 4 5 6 7
25

SEARCHING WITH THE FM-INDEX (*)
• Searching starts from the end of the string
• At element “j”, up to 9 possible branches should be explored• Exact matching: The counter for the number of errors is not increased, new values
for k and l are calculated according to the formula. Process continues with element j-1.
• Mismatch: If the search tree indicates that there are additional matches in the reference that differ in the current symbol. If the counter of errors has not reached the maximum allowed, all the possible branches are explored (up to 3). New values for k and l are calculated, error counter is incremented and processing continues in the element j-1.
• Deletion: In this case, the algorithm consider that current symbol may have been inserted and searches for matches in the reference skipping the current symbol. The error counter is increased (if possible), processing continues in the element j-1, but values of k and l are kept unmodified.
• Insertion: In this case, the algorithm consider that a symbol is missing and checks in the tree for the possible branches including a new symbol at the present position (up to 4 branches). The error counter is increased, new values for k and l are calculated and processing continues in the same symbol.
SeqAhead Workshop on HPC4NGS 26
(*) Fast and accurate short read alignment with Burrows–Wheeler Transform, Heng Li and Richard Durbin, BIOINFORMATICS Vol. 25 no. 14 2009, doi:10.1093/bioinformatics/btp324

SeqAhead Workshop on HPC4NGS 27
DEALING WITH ERRORS
• Early termination• It is possible to predict if a branch will lead to an
unfeasible solution by computing the number of errors that have to be assumed.
• It requires computing vector D for each searched sample, using the
inverted reference string.• It reduces the branching explosion.
ComputeD(W) z←0 j←0 for i=0 to |W|−1 do if W[j,i] X then z←z+1 j←i+1 fi D(i)←z endend

SeqAhead Workshop on HPC4NGS 28
THE GENERAL CASE – RECURSIVE APPROACH
InexRecur(W,i,z,k,l) if z<D(i) return ∅ if i<0 return {[k,l]} I←∅ I←I InexRecur(∪ W,i−1,z−1,k,l) for each b {∈ A,C,G,T} do k←C(b)+O(b,k−1)+1 l←C(b)+O(b,l) if k≤l I←I InexRecur(∪ W,i,z−1,k,l) if b=W[i] I←I InexRecur(∪ W,i−1,z,k,l) else I←I InexRecur(∪ W,i−1,z−1,k,l) end done return I
CalculateD(W) k←1 l←|X|−1 z←0 for i=0 to |W|−1 do k←C(W[i])+O(W[i],k−1)+1 l←C(W[i])+O(W[i],l) if k>l k←1 l←|X|−1 z←z+1 end done D(i)←z

DIFFICULTIES IN USING GPUS
• Recursive model, although supported in the last versions, is not effective.
• Multiple branches will reduce the parallelism degree.
• GPUs memory is reduced (insufficient for human genome).
• Memory access coherence has a critical impact on the final performance.
• Simplifications may be needed• Cooperation GPU-CPU is the key to success.
SeqAhead Workshop on HPC4NGS 29

EXACT SEARCH
• By removing (or limiting) the branching for multiple errors, code for processing multiple sequences simultaneously can be homogenenous.
• Different sequences have different values of k and l
• However, different sequences can stop at different steps• Due to different lengths or
the presence of mismatches.
• Pres-sorting by size could speed-up the algorithm.
SeqAhead Workshop on HPC4NGS 30

EXACT SEARCH WITH GPUS
• GPU algorithm parallelization is achieved by running simultaneous searches on each CUDA thread.
• FM index (C and O vectors) of the reference is copied to the GPU before searching.
• The search strings (W) and the transform intervals (k, l) must be transfered between CPU and GPU.
SeqAhead Workshop on HPC4NGS
void BWSearchGPU(W[][], nW[], k[], l[], k_ini, l_ini, C, O) {
id_thread = blockIdx.x * blockDim.x + threadIdx.x;
if (threadIdx.x<4) CopyToSharedMemory(C); __syncthreads();
k2 = k_ini; l2 = l_ini;
for (i=nW[id_thread]-1; (k2<=l2) && (i>=0); i--)
BWiteration(k2, l2, k2, l2, W[id_thread][i], C, O);
k[id_thread] = k2; l[id_thread] = l2;
}
31

EXTENSION TO 1 ERROR
• Each node can lead up to 9 branches
• Ej. AGC
$ agA aGA XGA
agG aGG
agC
aGC
AGC
0,6
1,2
4,6
3,3
1,2 6,6
5,5
1,1
4,4
6,6
2,2
2,2
2,2
2,2
4,4
6,6
2,2
2,2
1,2
4,4
6,6
2,2
2,2
1,2
A
A
A
A
AA
A
G
G
G
G
GG
G
G
G
C
^
^
^
^
^
^
AGG Match
Match
A
G
TC
A
C
T
G A
C
T
G
G
G
G
A
SeqAhead Workshop on HPC4NGS 32

SUPPORT FOR A VARIABLE NUMBER OF ERRORS
• Use of exact searching for pre-filtering sequences leading to an exact matching • Short computing time• It may reduce the problem by a 39%.
• For the sequences not found, define a threshold and use the matching fragments as seeds• The rest of the sequence can be done
using Smith-Waterman or similar approaches.
• 1-error searching slightly increases alignment time (overlapped), but increases accuracy(42%).
SeqAhead Workshop on HPC4NGS 33

TOWARDS A USEFUL TOOL, COMBINATION OF CPU AND GPU
SeqAhead Workshop on HPC4NGS 34

OTHER OPTIMIZATIONS
• O matrix is huge• The number of elements stored can be reduced by storing only one
element of each 32 and storing the changes as bits in a 32-long word.
• Enables storing the whole O for the human genome is state-of-the art GPU boards.
• Performance is not compromised by the use of machine instructions, such as (_popcnt).
• Partial sorting of the reference• Considering genetic variability, the ordering of the S array can take
into account only the first n<|X| elements.• However, this is incompatible with the compression of the S vector.
• Overlaping I/O and processing• Input and Output of the different sequences of blocks during the
processing in the GPU.
SeqAhead Workshop on HPC4NGS 35

OTHER OPTIMIZATIONS
• Compression of the Suffix Array• Suffix array, again is huge (one integer per
element of the BWT).• Compression is feasible by storing a
fraction of the elements (with a fixed stride) and iterating with the formula
• S(k)=S((Y-1)(j)(k))+j• Y-1(i)=C(B[i])+O(B[i],i)
• Combining searching in both strands.
SeqAhead Workshop on HPC4NGS 36

RESPONSE TIME
Find and show 1 match
SeqAhead Workshop on HPC4NGS 37

RESPONSE TIME
Show all matches
SeqAhead Workshop on HPC4NGS 38
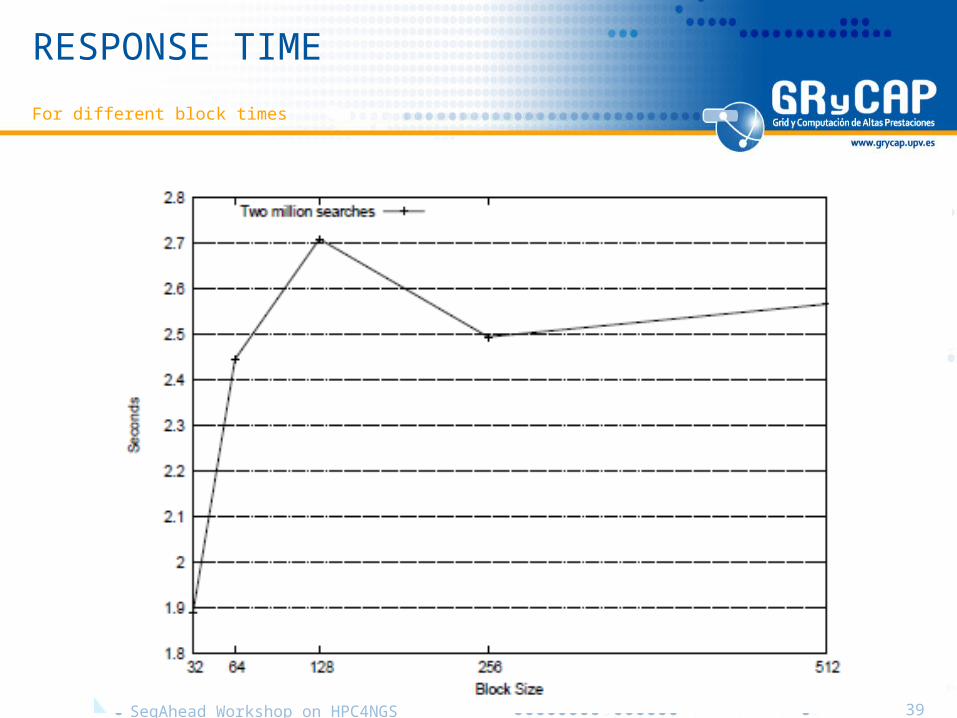
RESPONSE TIME
For different block times
SeqAhead Workshop on HPC4NGS 39
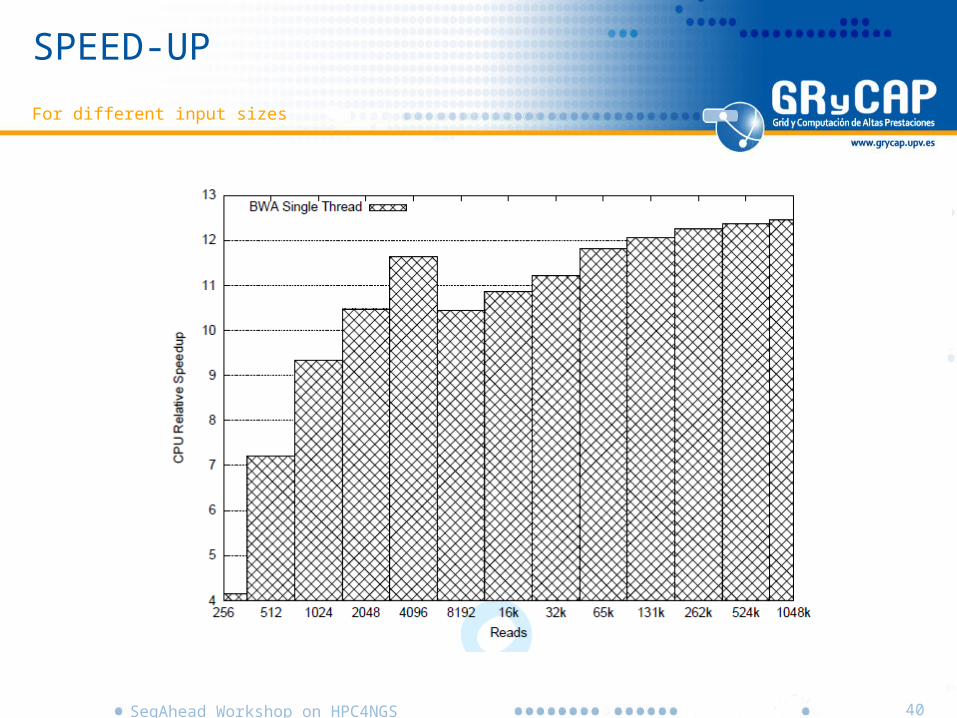
SPEED-UP
For different input sizes
SeqAhead Workshop on HPC4NGS 40

DISTRIBUTION OF PROCESSING TIME
With disk caching Without disk caching
SeqAhead Workshop on HPC4NGS 41

42
USE OF BWT IN ASSEMBLY
SeqAhead Workshop on HPC4NGS

43
CAN WE APPLY DIRECTLY THE FM-INDEX?
• Construct a BWT for the Xi sequences– Computational time: sum(|Xi|·log(|Xi|)+|Xi|)
• Search each Xi sequence over all the BWTs– Computational time: |X|·sum(|Xi|)
• Memory Requirements (FM-index)– O: 4·8·sum(|Xi|)
– S: 8·sum(|Xi|)
• Instantiation: 200 Million sequences of 100 bases– Computational time> Pf.– Memory Reqs: >600GB
• Unfeasible!!!!SeqAhead Workshop on HPC4NGS

44
THE SGA* ALGORITHM
• An approach could be to create a single BWT that could be used to search all the hits for each sequence simultaneously .
• Ideally, once the Multiple BWT is created, the computing time will be linear with the size of the sequencing.– Moreover, the Multiple BWT gives already
an information about similar sequences.
SeqAhead Workshop on HPC4NGS
(*) Efficient de novo assembly of large genomes using compressed data structures Jared T Simpson and Richard Durbin, Genome Res. December, 2011

45
SUFFIX ARRAYS FOR MULTIPLE SEQUENCES
• A Suffix Array can be extended to cover a set of sequences– SA(i) = (j,k)
• In the j-th sequence, the suffix [Sj(k).. Sj(|Sj(k)|)] occupies the i-th position in an alphabet order.
– All sequences are terminated by a $j
symbol, being $j alphabetically lower than any symbol of the alphabet and being $p < $q if p<q.
– If two sequences are equal, the order is given by the order of the sequence.SeqAhead Workshop on HPC4NGS

46
A PICTURE IS WORTH A MILLION WORDS
0 1 2 3 4 5 6 7R1 = A G G A G C $1
R2 = G A G C T A G $2
R3 = G C T A G A $3
7 $1
6 C $1
5 G C $1
4 A G C $1
3 G A G C $1
2 G G A G C $1
1 A G G A G C $1
8 $2
7 G $2
6 A G $2
5 T A G $2
4 C T A G $2
3 G C T A G $2
2 A G C T A G $2
1 G A G C T A G $2
7 $3
6 A $3
5 G A $3
4 A G A $3
3 T A G A $3
2 C T A G A $3
1 G C T A G A $3
1 – (1,7) 2 – (2,8) 3 – (3,7) 4 – (3,6) 5 – (2,6) 6 – (3,4) 7 – (1,4) 8 – (2,2) 9 – (1,1) 10 – (1,6) 11 – (2,4) 12 – (3,2) 13 – (2,7) 14 – (3,5) 15 – (1,3) 16 – (2,1) 17 – (1,5) 18 – (2,3) 19 – (3,1) 20 – (1,2) 21 – (2,5) 22 – (3,3)
SeqAhead Workshop on HPC4NGS
R1 R2 R3

47
DEFINITION FOR THE BWT
SA(i) = (j, k)B(i) = Rj(k-1)
i – SA(i) – B(i) - F(i) 1 – (1,7) – C - $1 2 – (2,8) – G - $2 3 – (3,7) – A - $3
4 – (3,6) – G - A 5 – (2,6) – T - A 6 – (3,4) – T - A 7 – (1,4) – G - A 8 – (2,2) – G - A 9 – (1,1) – $1 - A10 – (1,6) – G - C11 – (2,4) – G - C12 – (3,2) – G - C13 – (2,7) – A - G14 – (3,5) – A - G15 – (1,3) – G - G16 – (2,1) – $2 - G17 – (1,5) – A - G18 – (2,3) – A - G19 – (3,1) – $3 - G20 – (1,2) – A - G21 – (2,5) – C - T22 – (3,3) – C - T
0 1 2 3 4 5 6 7R1 = A G G A G C $1
R2 = G A G C T A G $2
R3 = G C T A G A $3
SeqAhead Workshop on HPC4NGS

48
FM-INDEX FOR MULTIPLE SEQUENCES
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22O(A)= 0 0 1 1 1 1 1 1 1 1 1 1 2 3 3 3 4 5 5 6 6 6O(C)= 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 3O(G)= 0 1 1 2 2 2 3 4 4 5 6 7 7 7 8 8 8 8 8 8 8 8O(T)= 0 0 0 0 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
C = [ 3 9 12 20 ]
BWT = C G A G T T G G $1 G G G A A G $2 A A $3 A C C
SeqAhead Workshop on HPC4NGS

49
SEARCHING WITH THE FM-INDEX
0 1 2 3 4 5 6 7W = G A G C T A G $2
i – SA(i) – B(i) - F(i) 1 – (1,7) – C - $1 2 – (2,8) – G - $2 3 – (3,7) – A - $3
4 – (3,6) – G - A 5 – (2,6) – T - A 6 – (3,4) – T - A 7 – (1,4) – G - A 8 – (2,2) – G - A 9 – (1,1) – $1 - A10 – (1,6) – G - C11 – (2,4) – G - C12 – (3,2) – G - C13 – (2,7) – A - G14 – (3,5) – A - G15 – (1,3) – G - G16 – (2,1) – $2 - G17 – (1,5) – A - G18 – (2,3) – A - G19 – (3,1) – $3 - G20 – (1,2) – A - G21 – (2,5) – C - T22 – (3,3) – C - T
(k, l) = (2, 22)k’ = C(x)+O(x,k-1)+1l’ = C(x)+O(x,l)
G -> (C(G)+O(G,1)+1, C(G)+O(G,22) -> (12+0+1, 12+8) = (13, 20)
A -> (C(A)+O(A,12)+1, C(A)+O(A,20) -> (3+1+1, 3+6) = (5, 9)
T -> (C(T)+O(T,4)+1, C(T)+O(T,9) -> (20+0+1, 12+8) = (21, 22)
C -> (C(C)+O(C,20)+1, C(C)+O(C,22) -> (9+1+1, 9+3) = (11, 12)
G -> (C(G)+O(G,10)+1, C(G)+O(G,12) -> (12+5+1, 12+7) = (18, 19)
SeqAhead Workshop on HPC4NGS

50
A PICTURE IS WORTH A MILLION WORDS
0 1 2 3 4 5 6 7R1 = A G G A G C $1
R2 = G A G C T A G $2
R3 = G C T A G A $3
7 $1
6 C $1
5 G C $1
4 A G C $1
3 G A G C $1
2 G G A G C $1
1 A G G A G C $1
8 $2
7 G $2
6 A G $2
5 T A G $2
4 C T A G $2
3 G C T A G $2
2 A G C T A G $2
1 G A G C T A G $2
7 $3
6 A $3
5 G A $3
4 A G A $3
3 T A G A $3
2 C T A G A $3
1 G C T A G A $3
1 – (1,7) 2 – (2,8) 3 – (3,7) 4 – (3,6) 5 – (2,6) 6 – (3,4) 7 – (1,4) 8 – (2,2) 9 – (1,1) 10 – (1,6) 11 – (2,4) 12 – (3,2) 13 – (2,7) 14 – (3,5) 15 – (1,3) 16 – (2,1) 17 – (1,5) 18 – (2,3) 19 – (3,1) 20 – (1,2) 21 – (2,5) 22 – (3,3)
SeqAhead Workshop on HPC4NGS
R1 R2 R3
0 1 2 3 4 5 6 7W = G A G C T A G $2

SeqAhead Workshop on HPC4NGS 51
COMPUTING TIME ESTIMATION
• Computing the consolidated Index– Trivially: avg(|Xi|)·(|X|·log(|X|))
– Improvable up to pseudo-polinomical time (|X|·log(|X|).
• Searching– O(|Xi|·|X|)
• Memory– O: 4·8·|X|– S: 4 ·|X|
• Instantiation: 200 Million sequences of 100 bases– Computational time> Gflops.– Memory Reqs: >600GB <- effort on this point.

SeqAhead Workshop on HPC4NGS
CONCLUSIONS
• The FM-index provides with searching capabilities on linear time depending on the size of the input sequence.
• By reducing the variability of the code, parallelism can be exploited by searching simultaneous sequences on a GPU.
• We achieved a Speed-up of 2 over existing versions supporting GPUs (with the same approach and execution conditions)• Exact searching, same I/O workload and same number of
hits.
• Excluding I/O, and using only 1 GPU board, the Speed-up raises to 12 with respect to the CPU.
• The performance of the use of GPUs is limited by two technologic factors• Disk performance• GPU memory.
52

53
CONTACT
Ignacio Blanquer Universidad Politécnica de Valencia
Camino de Vera s/n
46022 Valencia, Spain
Tel: +34-963879743
Fax. +34-963877274
E-mail: [email protected]
SeqAhead Workshop on HPC4NGS

















