31
Ian Bird Ian Bird LCG Project Leader LCG Project Leader Jamie Shiers Jamie Shiers Grid Support Group, CERN Grid Support Group, CERN WLCG Project Status Report NEC 2009 September 2009
| Date post: | 27-Dec-2015 |
| Category: |
Documents |
| Upload: | pearl-ford |
| View: | 220 times |
| Download: | 0 times |

Ian BirdIan BirdLCG Project LeaderLCG Project LeaderJamie ShiersJamie ShiersGrid Support Group, CERNGrid Support Group, CERN
WLCG Project Status Report
NEC 2009
September 2009

Introduction
• The sub-title of this talk is “Grids step-up to a set of new records: Scale Testing for the Experiment Programme (STEP’09)”
• STEP’09 means different things to different people• A two week period during June 2009 when there was intense
testing – particularly by ATLAS & CMS – of specific (overlapping) workflows
• A several month period, starting around CHEP’09, and encompassing the above
• I would like to “step back” and take a much wider viewpoint – with a reference to my earlier “HEP SSC” talk:• Are we ready to “successfully and efficiently exploit
the scientific and discovery potential of the LHC”? 2

“The Challenge”
• This challenge was clearly posed by Fabiola Gianotti during her CHEP 2004 plenary talk
• “Fast forward” 3 years – to CHEP 2007 – when some people were asking whether it was wise to travel to Vancouver when the LHC startup was imminent
At that time we clearly had not tested key Use Cases – sometimes not even by individual experiments, let alone all experiments (and at all concerned sites) together
• This led to the Common Computing Readiness Challenge (CCRC’08) which advanced the state of play significantly
>> to CHEP’09 – “ready but there will be problems”
3

CCRC’08
• Once again, this was supposed to be a final production test prior to real collisions between accelerated beams in the LHC
• It certainly raised the bar considerably – and much of our operations infrastructure was completed as a result of that exercise – but it still left some components untested
These were the focus of STEP’09
• The bottom line: we were not fully ready for data in 2007 – nor even 2008. The impressive results must be considered in the light of this sobering thought 4

So What Next?
• Whilst there is no doubt that the service has “stepped up” considerably since e.g. one year ago, can
• We (providers) live with this level of service and the operations load that it generates?
• The experiments live with this level of service and the problems that it causes? (Loss of useful work, significant additional work, …)
• Where are wrt “the challenge” of CHEP 2004?
5

An Aside
• Over the past few years there were a number of technical problems related to the LHC machine itself
• For me, a particularly large slice of “humble pie” came with the “IT problem”
• This was not about Indico being down or slow, or Twiki being inaccessible, it was about the (LHC) Inner Triplets
• To many, the collaboration is perceived to be “LHC machine + detectors” – “computing” is either an afterthought or more likely not a thought at all!
6

LHC + Experiments + WLCG???
• In reality, IT is needed from the very beginning – to design the machine, the detectors, to build and operate them...
• And – by the way – there would today be no physics discovery without major computational, network and storage facilities
We call this (loosely) WLCG – as you know!• But the only way to get on the map is through the
provision of reliable, stable, predictable services• And a service is determined as much by what
happens when things go wrong as by the “trivial” situation of smooth running…
7

STEP’09: Service Advances
• For CCRC’08 we had to put in place new or upgraded service / operations infrastructure• Some elements were an evolution of what had been used for
previous Data and Service challenges but key components were basically new
• Not only did these prove their worth in CCRC’08 but basically no major changes have been needed to date
• The operations infrastructure worked smoothly – sites were no longer in “hero” (unsustainable) mode – previously a major concern
Rather light-weight but collaborative procedures proved their worth
But most importantly, our ability to handle / recover from / circumvent even major disasters!
8

What Has Gone Wrong?
• Loss of LHC OPN to US – cables cut by fishing trawler• This happened during an early Service Challenge and at the
time we thought it was “unusual”
• Loss of LHC OPN within Europe – construction work near Madrid, motorway construction between Zurich and Basle (you can check the GPS coordinates with Google Earth), Tsunami in Asia, fire in Taipei, tornadoes, hurricanes, collapse of machine room floor due to municipal construction underneath(!), bugs in tape robot firmware taking drives offline, human errors, major loss of data due to s/w bugs, …
Some of the above occurred during STEP’09 – but the exercise was still globally a success!
9

FZK
FNAL
TRIUMF
NGDF
CERN
Barcelona/PIC
Lyon/CCIN2P3
Bologna/CAF
Amsterdam/NIKHEF-SARA
BNL
RAL
Taipei/ASGC

FZK
FNAL
TRIUMF
NGDF
CERN
Barcelona/PIC
Lyon/CCIN2P3
Bologna/CAF
Amsterdam/NIKHEF-SARA
BNL
RAL
Taipei/ASGC

STEP’09: What Were The Metrics?
• Those set by the experiments: based on the main “functional blocks” that Tier1s and Tier2s support
• Primary (additional) Use Cases in STEP’09:
1. (Concurrent) reprocessing at Tier1s – including recall from tape2. Analysis – primarily at Tier2s (except LHCb)
• In addition, we set a single service / operations site metric, primarily aimed at the Tier1s (and Tier0)
• Details: • ATLAS (logbook, p-m w/s), CMS (p-m), blogs• Daily minutes: week1, week2• WLCG Post-mortem workshop
12

WLCG Tier1 [ Performance ] Metrics
~~~Points for Discussion
[email protected] [email protected] ~~~
WLCG GDB, 8th July 2009

The Perennial Question
• During this presentation and discussion we will attempt to sharpen and answer the question:
• How can a Tier1 know that it is doing OK?
• We will look at:• What we can (or do) measure (automatically);• What else is important – but harder to measure (at least
today);• How to understand what “OK” really means…
14

Resources
• In principle, we know what resources are pledged, can determine what are actually installed(?) and can measure what is currently being used;
• If installed capacity is significantly(?) lower than pledged, this is an anomaly and site in question “is not doing ok”
• But actual utilization may vary – and can even exceed – “available” capacity for a given VO (particularly CPU – less or unlikely for storage(?))
This should also be signaled as an anomaly to be understood (it is: poor utilization over prolonged periods impacts future funding, even if there are good reasons for it…)
15

Services
• Here we have extensive tests (OPS, VO) coupled with production use• A “test” can pass, which does not mean that experiment
production is not (severely) impacted…)• Some things are simply not realistic or too expensive to test…
• But again, significant anomalies should be identified and understood
• Automatic testing is one measure: GGUS tickets another (# tickets, including alarm, time taken for their resolution)• This can no doubt be improved iteratively; additional tests /
monitoring added (e.g. tape metrics)• A site which is “green”, has few or no tickets open for >
days | weeks, and no “complaints” at operations meeting is doing ok, surely?
• Can things be improved for reporting and long-term traceability? (expecting the answer YES)
16

The Metrics…
• For STEP’09 – as well as at other times – explicit metrics have been set against sites and for well defined activities
• Can such metrics allow us to “roll-up” the previous issues into a single view?
• If not, what is missing from what we currently do?
• Is it realistic to expect experiments to set such targets:• During the initial period of data taking? (Will it be known at
all what the “targets” actually are?)• In the longer “steady state” situation? Processing &
reprocessing? MC production? Analysis??? (largely not T1s…)
• Probable answer: only if it is useful for them to monitor their own production (which it should be..)
17

# Metric
1 Site is providing (usable) resources that match those pledged & requested;
2 The services are running smoothly, pass the tests and meet reliability and availability targets;
3 “WLCG operations” metrics on handling scheduled and unscheduled service interruptions and degradations are met;
4 Site is meeting or exceeding metrics for “functional blocks”.
WLCG Site Metrics

Critical Service Follow-up• Targets (not commitments) proposed for Tier0
services• Similar targets requested for Tier1s/Tier2s• Experience from first week of CCRC’08 suggests targets for
problem resolution should not be too high (if ~achievable)• The MoU lists targets for responding to problems (12 hours for
T1s)
¿ Tier1s: 95% of problems resolved <1 working day ?¿ Tier2s: 90% of problems resolved < 1 working day ?
Post-mortem triggered when targets not met!
19
Time Interval Issue (Tier0 Services) TargetEnd 2008 Consistent use of all WLCG Service Standards 100%
30’ Operator response to alarm / call to x5011 / alarm e-mail 99%
1 hour Operator response to alarm / call to x5011 / alarm e-mail 100%
4 hours Expert intervention in response to above 95%
8 hours Problem resolved 90%
24 hours Problem resolved 99%
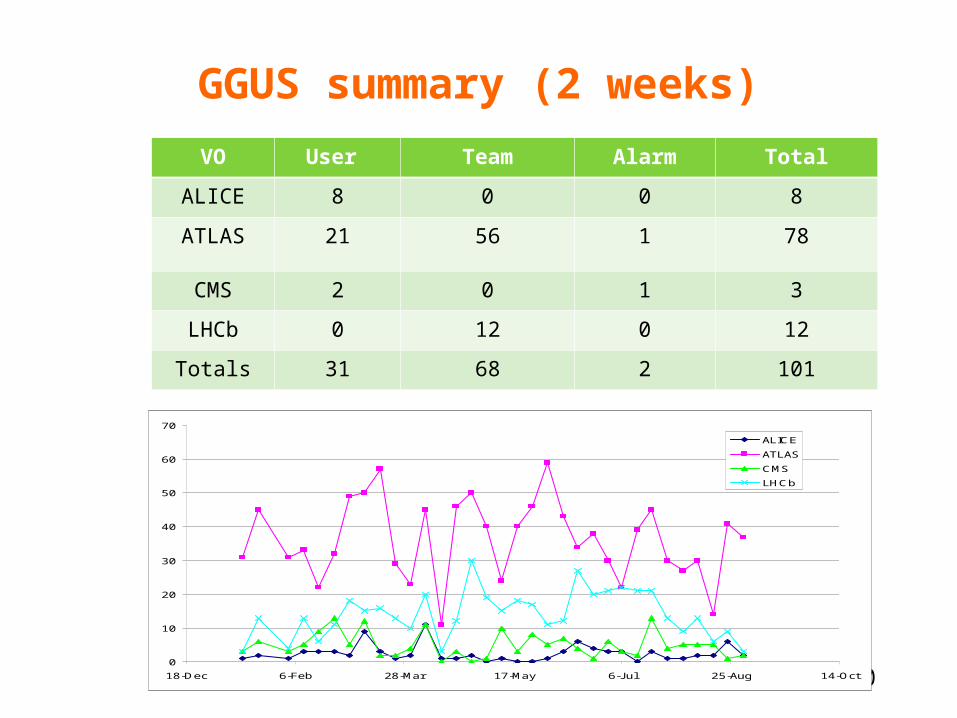
GGUS summary (2 weeks)
VO User Team Alarm Total
ALICE 8 0 0 8
ATLAS 21 56 1 78
CMS 2 0 1 3
LHCb 0 12 0 12
Totals 31 68 2 101
200
10
20
30
40
50
60
70
18-Dec 6-Feb 28-Mar 17-May 6-Jul 25-Aug 14-Oct
ALICE
ATLAS
CMS
LHCb

21

22
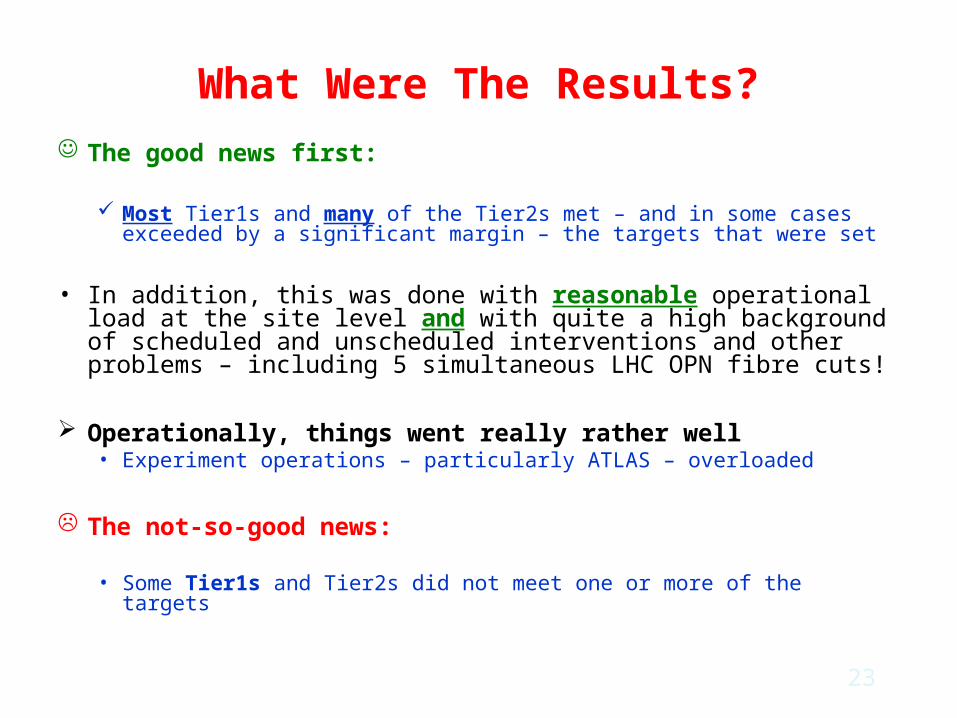
What Were The Results? The good news first:
Most Tier1s and many of the Tier2s met – and in some cases exceeded by a significant margin – the targets that were set
• In addition, this was done with reasonable operational load at the site level and with quite a high background of scheduled and unscheduled interventions and other problems – including 5 simultaneous LHC OPN fibre cuts!
Operationally, things went really rather well • Experiment operations – particularly ATLAS – overloaded
The not-so-good news:
• Some Tier1s and Tier2s did not meet one or more of the targets
23

Tier2s
• The results from Tier2s are somewhat more complex to analyse – an example this time from CMS:• Primary goal: use at least 50% of pledged T2 level for analysis
• backfill ongoing analysis activity • go above 50% if possible
• Preliminary results:• In aggregate: 88% of pledge was used. 14 sites with > 100% • 9 sites below 50%
• The number of Tier2s is such that it does not make sense to go through each by name, however: Need to understand primary causes for some sites to
perform well and some to perform relatively badly Some concerns on data access performance / data
management in general at Tier2s: this is an area which has not been looked at in (sufficient?) detail
24

Summary of Tier2s
• Detailed reports written by a number of Tier2s• MC conclusion “solved since a long time” (Glasgow)
• Also some numbers on specific tasks, e.g. GangaRobot• Some specific areas of concern (likely to grow IMHO)
• Networking: internal bandwidth and/or external• Data access: aside from constraints above, concern that data
access will met the load / requirements from heavy end-user analysis
• “Efficiency” – # successful analysis jobs – varies from 94% down to 56% per (ATLAS) cloud, but >99% down to 0% (e.g. 13K jobs failed, 100 succeed) (error analysis also exists)
• IMHO, the detailed summaries maintained by the experiments together with site reviews demonstrate that the process is under control, not withstanding concerns 25
STEP key points
General: Multi-VO aspects never tested before at this scale Almost all sites participated successfully CERN tape writing well above required level Most Tier1s showed impressive operation Demonstrated scale and sustainability of loads
Some limitations were seen; to be re-checked OPN suffered double fibre cut! ... But continued and recovered... Data rates well above required rates...

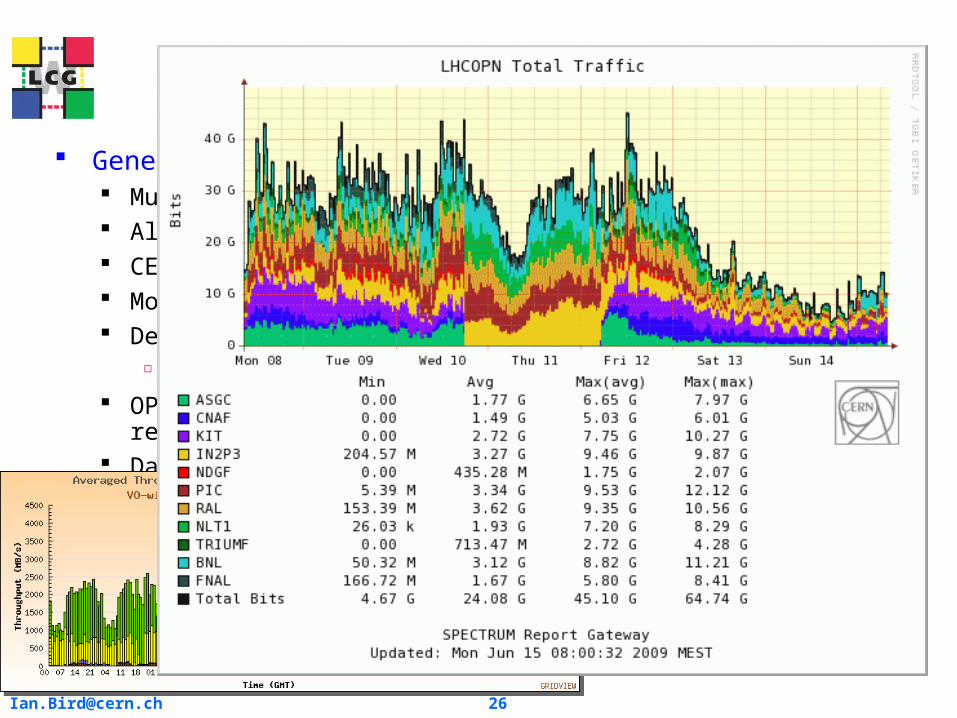
CCRC 2008 vs STEP 2009
CCRC08CCRC08
MB/s
MB/sSTEP09STEP09
MB/s
2 weeks vs. 2 days4 GB/sec vs. 1 GB/sec

Recommendations
1. Resolution of major problems with in-depth written reports
2. Site visits to Tier1s that gave problems during STEP’09 (at least DE-KIT & NL-T1) [ ASGC being setup for October? ]
3. Understanding of Tier2 successes and failures
4. Rerun of “STEP’09” – perhaps split into reprocessing and analysis before a “final” re-run – on timescale of September 2009 [ Actually done as a set of sub-tasks ]
5. Review of results prior to LHC restart28

General Conclusions
• STEP’09 was an extremely valuable exercise and we all learned a great deal!
• Progress – again – has been significant
• The WLCG operations procedures / meetings have proven their worth
• Good progress since (see experiment talks) on understanding and resolving outstanding issues!
Overall, STEP’09 was a big step forward!
29

Outstanding Issues & Concerns
30
Issue Concern
Network
T0 – T1 well able to handle traffic that can be expected from normal data taking with plenty of headroom for recovery. Redundancy??T1 – T1 traffic – less predictable (driven by re-processing) – actually dominates. Concerns about use of largely star network for this purpose.Tn – T2 traffic – likely to become a problem, as well internal T2 bandwidth
Storage
We still do not have our storage systems under control. Significant updates to both CASTOR and dCache have been recommended by providers post-STEP’09. Upgrade paths unclear, untested or both.
Data Data access – particularly “chaotic” access patterns typical of analysis can be expected to cause problems – many sites configured for capacity, not optimized for many concurrent streams, random access etc.
Users Are we really ready to handle a significant increase in the number of (blissfully) grid-unaware users?

Summary
• We are probably ready for data taking and analysis and have a proven track record of resolving even major problems and / or handling major site downtimes in a way that lets production continue
• Analysis will surely bring some new challenges to the table – not only the ones that we expect!
• If funded, the HEP SSC and Service Deployment projects described this morning will help us get through the first years of LHC data taking
• Expect some larger changes – particularly in the areas of storage and data handing – after that
31

















