Page 1
IBM Haifa Research Lab © 2008 IBM Corporation
Retrieving Spoken Information by Combining Multiple Speech Transcription Methods
Jonathan Mamou
Joint work with Ron Hoory, David Carmel, Yosi Mass, Bhuvana Ramabhadran, Benjamin Sznajder
Page 2
IBM Haifa Research Lab
© 2008 IBM Corporation2 Speech Technologies Seminar 2008
Motivation
Spoken data is everywhere!
Conference Meetings Broadcasts News
Surveillance & SecurityCall Center
Page 3
IBM Haifa Research Lab
© 2008 IBM Corporation3 Speech Technologies Seminar 2008
IR Tasks on Speech Data
Spoken Document Retrieval (SDR) Traditional search engine approach: find spoken documents
relevant to a query.
Spoken Term Detection (STD) Detect occurrences of a phrase in spoken documents. NIST STD evaluation
Page 4
IBM Haifa Research Lab
© 2008 IBM Corporation4 Speech Technologies Seminar 2008
Approaches for Speech Information Retrieval
Keyword spotting Based on direct detection of a predefined set of keywords in the
speech data
Build an index out of automatic transcription output Based on full transcription of the audio and indexing of the
transcription process output This is the approach we are using Part of this work has been done in the
framework of SAPIR, an EU FP6 project
of Search in Audiovisual Content using P2P
Page 5
IBM Haifa Research Lab
© 2008 IBM Corporation5 Speech Technologies Seminar 2008
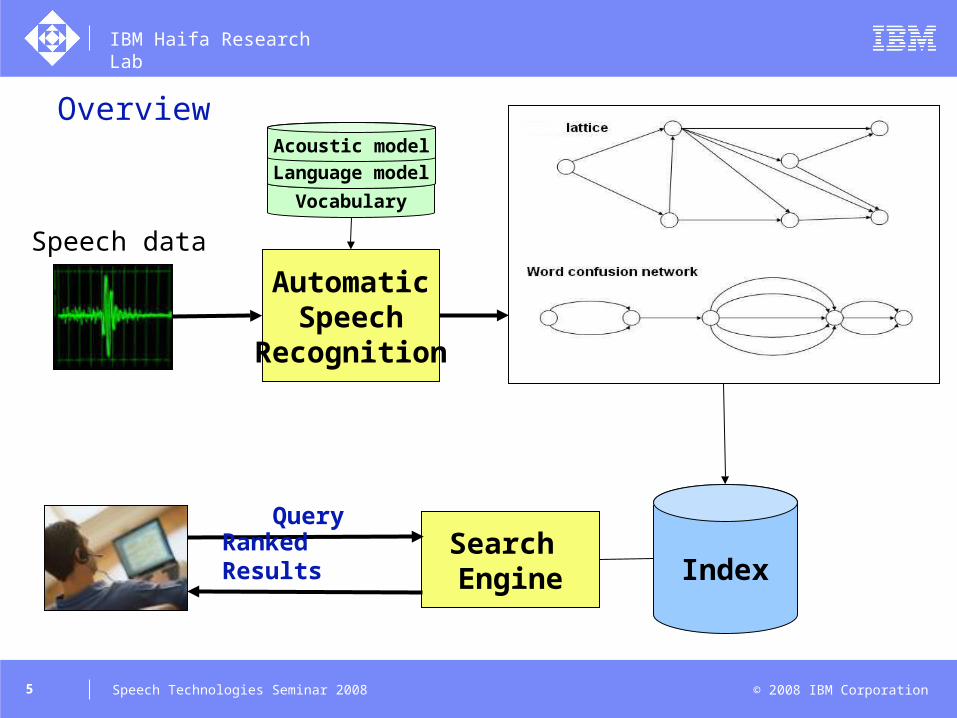
Overview
AutomaticSpeech
Recognition
Speech data
Vocabulary
Language model
Acoustic model
IndexSearch Engine
Query
Ranked Results
Page 6
IBM Haifa Research Lab
© 2008 IBM Corporation6 Speech Technologies Seminar 2008
Why is it different from classic text IR?
The classic text IR based solution would be an indexing and search of 1-best word transcript.
However, two main issues can arise during the transcription of the speech data: Errors (substitutions, deletions, insertions) can occur during the
transcription Out-of-vocabulary (OOV) terms can be present in the spoken data and in
the query OOV words are missing words from the ASR system vocabulary They are replaced in the output transcript by alternatives that are probable,
given the acoustic model, vocabulary and language model of the ASR system. e.g., TALIBAN TELL A BAND
Over 10% of user queries can be OOV terms (especially named entities)
Page 7
IBM Haifa Research Lab
© 2008 IBM Corporation7 Speech Technologies Seminar 2008
Influence of the WER on the Retrieval
Substitutions and deletions reflect the fact that a term “appearing” in the speech signal is not recognized Impact on the recall of the search (i.e., fraction of the documents
relevant to the query that are successfully retrieved)
Substitutions and insertions reflect the fact that a term which is not part of the speech signal appears in the transcript Impact on the precision of the search (i.e., fraction of the retrieved
documents that are relevant to the query)
These issues may dramatically affect the effectiveness of the retrieval and prevent the “naïve” search engine from retrieving the information
Page 8
IBM Haifa Research Lab
© 2008 IBM Corporation8 Speech Technologies Seminar 2008
Technical Approach
We have developed algorithms to improve search effectiveness in the presence of errors, to allow OOV queries.
Indexing of the Word Confusion Network (WCN) including word alternatives and corresponding confidences, for IV terms.
Phonetic indexing and fuzzy search.
Page 9
IBM Haifa Research Lab © 2008 IBM Corporation
Retrieval Model
Page 10
IBM Haifa Research Lab
© 2008 IBM Corporation10 Speech Technologies Seminar 2008
Word Search We index Word Confusion Network (WCN) [Mangu et al., 2000]
It is a compact representation of a word lattice: the different word hypotheses that appear at a same time are aligned.
A vertex is associated with a timestamp. An edge is labeled with
a word hypothesis, its posterior probability: the probability of the word given the signal.
Page 11
IBM Haifa Research Lab
© 2008 IBM Corporation11 Speech Technologies Seminar 2008
…have 61%
graphic 22%
on 100%impressions 19 %
grass 3%
interested 9%
graphics 13% …and 39%
glasses 27%
impresses 7 %
my 100%
seen 1%
screen 99%
A fragment of WCN
Page 12
IBM Haifa Research Lab
© 2008 IBM Corporation12 Speech Technologies Seminar 2008
Improving Retrieval Effectiveness using WCNs
Recall is enhanced by expanding the 1-best transcript by extra words, taken from the other alternatives provided by the WCN. These alternatives may have been spoken but were not the top
choice of the ASR. However, such an expansion will probably decrease the precision!
Using an intelligent ranking model, we can improve the mean average precision (MAP) of the search. Average precision is average of precisions computed after
truncating the list of results after each of the relevant documents in turn.
MAP emphasizes returning more relevant documents earlier.
Page 13
IBM Haifa Research Lab
© 2008 IBM Corporation13 Speech Technologies Seminar 2008
Improving Retrieval Effectiveness using WCNs
We exploit two pieces of information provided by WCN concerning the occurrences of a term to improve our ranking model: The posterior probability of the hypothesis given the signal, The rank of the hypothesis among the other alternatives.
Page 14
IBM Haifa Research Lab
© 2008 IBM Corporation14 Speech Technologies Seminar 2008
Posterior Probability of the Hypothesis, Confidence Level
The posterior probability of the hypothesis given the signal reflects the confidence of the ASR in the hypothesis.
The retrieval process will boost documents for which the query term occurs with higher probability.
We denote by Pr(t|o,D) the posterior probability of a term t at offset o in the WCN of a document D.
Page 15
IBM Haifa Research Lab
© 2008 IBM Corporation15 Speech Technologies Seminar 2008
Rank of the Hypothesis, Relative Importance
The rank of the hypothesis among other alternatives reflects the importance of the term relatively to other alternatives.
A document containing a query term that is ranked higher, should be preferred over a document where the same term is ranked lower.
We denote by rank(t|o,D) the rank of a term t at the offset o in the WCN of a document D.
A boosting vector B=(B1,…,Bl) associates a boosting factor to each rank of the different hypotheses.
Page 16
IBM Haifa Research Lab
© 2008 IBM Corporation16 Speech Technologies Seminar 2008
Scoring
Our scoring is based on Vector Space Model (VSM) [Salton and McGill, 1986] It is an algebraic model for representing documents as vectors of
words. Each dimension corresponds to a separate term. If a term occurs in
the document, its value in the vector is its tfidf. Relevance ranking of documents can be calculated by comparing
the cosine of the angles between each
document vector and the original query
vector where the query is represented
as same kind of vector as the documents.
d1
qd2
Page 17
IBM Haifa Research Lab
© 2008 IBM Corporation17 Speech Technologies Seminar 2008
Scoring
Term frequency – Inverse document frequency (tfidf) This weight is a statistical measure used to evaluate how important
a word is to a document in a corpus. The importance increases proportionally to the number of times a
word appears in the document (term frequency - tf) but is offset by the frequency of the word in the corpus (inverse document frequency - idf).
Page 18
IBM Haifa Research Lab
© 2008 IBM Corporation18 Speech Technologies Seminar 2008
Term Frequency
The term frequency is evaluated by summing the posterior probabilities of all the occurrences of the term over the document.
The term frequency is boosted by the rank of the term among the other hypotheses.
occ(t,D) is the sequence of all the occurrences of t in D.
Dtocc
iiDotrank DotBDttf
i
,
1, ,Pr,
Page 19
IBM Haifa Research Lab
© 2008 IBM Corporation19 Speech Technologies Seminar 2008
Phonetic Search
Different kinds of phonetic transcripts: Sub-word decoding [Siohan and Bacchiani, 2005] Sub-word representation of automatic 1-best word transcript Sub-word can be word-fragment, syllable, phone
Sub-word transcripts have high error rate Phonetic transcription cannot be an alternative to word transcripts
especially for in-vocabulary (IV) search. That is the reason why we need to combine word transcripts with
phonetic transcripts.
Page 20
IBM Haifa Research Lab
© 2008 IBM Corporation20 Speech Technologies Seminar 2008
Phonetic Search
Relevant to IV and OOV search
N-gram or sub-word based indexing
Retrieval approaches Exact search
High precision but low recall Fuzzy search
It improves recall while decreases precision Using an intelligent ranking model, we can improve the mean average
precision of the search. Based on Edit distance on pronunciations We have implemented a fail-fast dynamic algorithm for computing it
Page 21
IBM Haifa Research Lab
© 2008 IBM Corporation21 Speech Technologies Seminar 2008
Scoring
Our scoring model extends TFIDF. Let’s consider a query that is represented by the phonetic pronunciation
ph. sim(ph,ph’) is the edit distance based similarity between two phonetic
pronunciations ph and ph’. Term frequency:
Document frequency:
N is the number of documents in the corpus.
Dhp
hpphsimDphtf ,,
N
hpphsimDhpDphdf
0, s.t.
Page 22
IBM Haifa Research Lab
© 2008 IBM Corporation22 Speech Technologies Seminar 2008
Phonetic Query Expansion
Compensate for OOV spelling variations
Each query term is converted to its phonetic pronunciations using joint maximum entropy N-gram model [Chen, 2003].
Each pronunciation is associated with a score that reflects the probability of this pronunciation normalized by the probability of the best pronunciation, given the spelling.
Page 23
IBM Haifa Research Lab
© 2008 IBM Corporation23 Speech Technologies Seminar 2008
Phonetic Query Expansion
Let’s consider a query term t that is expanded to (ph1,s1), …, (phm,sm) where phi is a pronunciation and si its associated score.
The score of t in D is given by the aggregation of the scores of the search on D of the pronunciations phi weighted by their score si
i i
i ii
s
DphtfidfsDtscore
,,
Page 24
IBM Haifa Research Lab
© 2008 IBM Corporation24 Speech Technologies Seminar 2008
Combination of word search with phonetic search
Using the Threshold Algorithm [Fagin, 1996] Merging result lists of documents returned respectively by word and phonetic search, ordered according to their score
Using inverted indices with Boolean Constraints Merging posting lists extracted from inverted indices (word and phonetic), ordered by the document identifiers, according to Boolean constraints Based on query rewriting to combine word and phonetic parts of the original query
Page 25
IBM Haifa Research Lab © 2008 IBM Corporation
Experiments
Page 26
IBM Haifa Research Lab
© 2008 IBM Corporation26 Speech Technologies Seminar 2008
Experimental Setup
2236 calls made to the IBM internal customer support service. The calls deal with a large range of
software and hardware problems. The average length of a call is 18
minutes.
Page 27
IBM Haifa Research Lab
© 2008 IBM Corporation27 Speech Technologies Seminar 2008
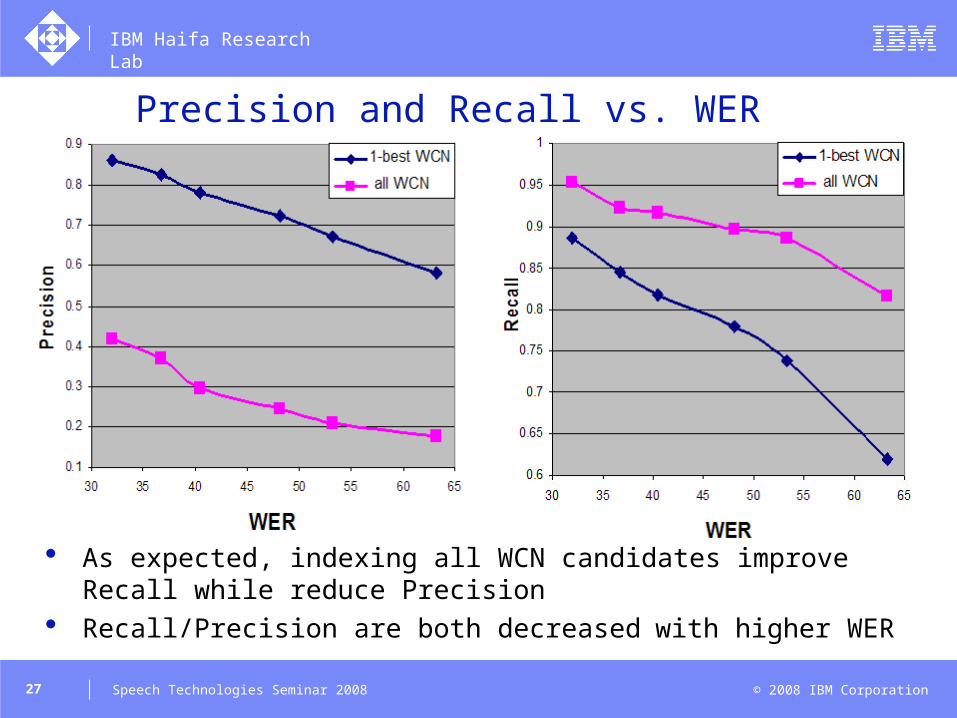
Precision and Recall vs. WER
As expected, indexing all WCN candidates improve Recall while reduce Precision
Recall/Precision are both decreased with higher WER
Page 28
IBM Haifa Research Lab
© 2008 IBM Corporation28 Speech Technologies Seminar 2008
Experiments with several retrieval strategies over WCN
1-best WCN TF Index: 1-best transcript obtained from WCN - Ranking: classic tf-idf
All WCN TF Index: all the WCN hypotheses - Ranking: classic tf-idf
1-best WCN CL Index: 1-best transcript obtained from WCN - Ranking: confidence levels
All WCN CL Index: all the WCN hypotheses - Ranking: confidence levels
ALL WCN CL boost Index: all the WCN hypotheses - Ranking: confidence levels and rank
among the other hypotheses
Page 29
IBM Haifa Research Lab
© 2008 IBM Corporation29 Speech Technologies Seminar 2008
MAP vs. WER
Using confidence level information provides significant contribution. all WCN CL boost always outperforms the other models, especially for
high WER.
Page 30
IBM Haifa Research Lab
© 2008 IBM Corporation30 Speech Technologies Seminar 2008
Experimental Setup
Data set provided by NIST for the STD evaluation 3 hours of broadcast news
We built three different indices Word: word index on the WCN WordPhone: a phonetic index of the phonetic representation of the
1-best word decoding Phone: a phonetic index of the 1-best word-fragment decoding
For phonetic retrieval, we compared two different search methods: exact and fuzzy match.
Page 31
IBM Haifa Research Lab
© 2008 IBM Corporation31 Speech Technologies Seminar 2008
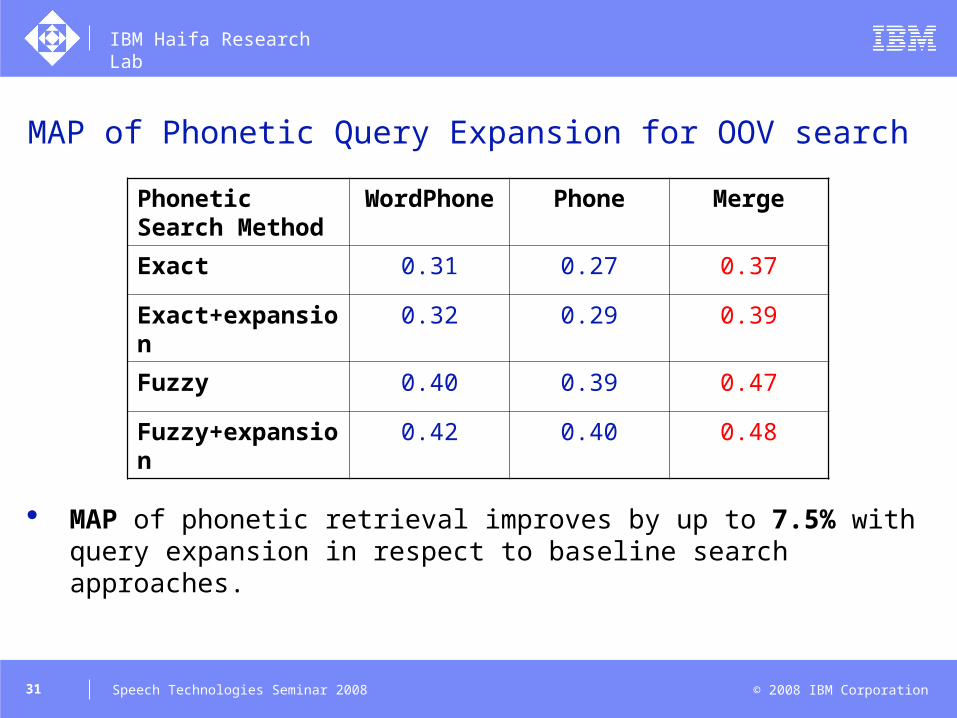
MAP of Phonetic Query Expansion for OOV search
MAP of phonetic retrieval improves by up to 7.5% with query expansion in respect to baseline search approaches.
Phonetic Search Method
WordPhone Phone Merge
Exact 0.31 0.27 0.37
Exact+expansion 0.32 0.29 0.39
Fuzzy 0.40 0.39 0.47
Fuzzy+expansion 0.42 0.40 0.48
Page 32
IBM Haifa Research Lab
© 2008 IBM Corporation32 Speech Technologies Seminar 2008
MAP for Hybrid Search
Queries combine IV and OOV terms under different query semantics
Improvement of merge approach with respect to word and phonetic approaches
Semantics Word WordPhone Phone Merge
OR 0.59 0.54 0.48 0.73
AND 0 0.5 0.36 0.57
Page 33
IBM Haifa Research Lab
© 2008 IBM Corporation33 Speech Technologies Seminar 2008
Conclusions
The Approach Word-based approach suffers from limited vocabulary of the recognition
system. Phonetic-based approach suffers from lower accuracy. Our spoken information retrieval system combines both approaches
Recall and MAP are significantly improved by searching all the hypotheses provided by the WCN in phonetic transcripts
This approach received the highest overall ranking for US English speech data in the last NIST Spoken Term Detection evaluation (December 2006).
Page 34
IBM Haifa Research Lab
© 2008 IBM Corporation34 Speech Technologies Seminar 2008
References
Spoken Document Retrieval from Call-Center Conversations, Jonathan Mamou, David Carmel, Ron Hoory, SIGIR 2006
Vocabulary Independent Spoken Term Detection, Jonathan Mamou, Bhuvana Ramabhadran, Olivier Siohan, SIGIR 2007
Audio-visual content analysis in P2P: the SAPIR approach, Walter Allasia, Francesco Gallo, Fabrizio Falchi, Mouna Kacimi, Aaron Kaplan, Jonathan Mamou, Yosi Mass, Nicola Orio, Workshop on Automated Information Extraction in Media Production, DEXA 2008
Combination of Multiple Speech Transcription Methods for Vocabulary Independent Search, Jonathan Mamou, Yosi Mass, Bhuvana Ramabhadran, Benjamin Sznajder, Search in Spontaneous Conversational Speech Workshop, SIGIR 2008
Phonetic Query Expansion for Spoken Document Retrieval, Jonathan Mamou, Bhuvana Ramabhadran, Interspeech 2008
Page 35
IBM Haifa Research Lab © 2008 IBM Corporation
Thank you!