ICT International Doctoral School, Trento @RT 2014 ICT International Doctoral School Department of Information Engineering and Computer Science University of Trento ICT International Doctoral School, Trento @RT 2014 Randomized Algorithms for Systems, Control and Networks Roberto Tempo CNR-IEIIT Consiglio Nazionale delle Ricerche Politecnico di Torino [email protected]ICT International Doctoral School, Trento @RT 2014 Objective and Prerequisites Objective: introduction to general purpose methods of randomization for analysis and design of uncertain systems Prerequisites: basic knowledge of probability theory and familiarity with state space methods for control system analysis and design ICT International Doctoral School, Trento @RT 2014 Course and Slides The course consists of three distinct sections - analysis - design - networks The slides include more material than that presented in the course pdf file with slides are provided ICT International Doctoral School, Trento @RT 2014 Final Project Course grade based on a final project to be discussed ICT International Doctoral School, Trento @RT 2014 Schedule Monday 15:00-17:00 Tuesday 9:00-12:00 and 15:00-17:00 Wednesday 9:00-12:00 and 15:00-17:00 Thursday 9:00-12:00 and 15:00-17:00 Friday 9:00-12:00
Transcript
ICT International Doctoral School, Trento @RT 2014
ICT International Doctoral School
Department of Information Engineering and Computer Science
University of Trento
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithms for Systems, Control and Networks
ICT International Doctoral School, Trento @RT 2014
Objective and Prerequisites
Objective: introduction to general purpose methods of randomization for analysis and design of uncertain systems
Prerequisites: basic knowledge of probability theory and familiarity with state space methods for control system analysis and design
ICT International Doctoral School, Trento @RT 2014
Course and Slides
The course consists of three distinct sections
- analysis
- design
- networks
The slides include more material than that presented in the course
pdf file with slides are provided
ICT International Doctoral School, Trento @RT 2014
Final Project
Course grade based on a final project to be discussed
ICT International Doctoral School, Trento @RT 2014
Schedule
Monday 15:00-17:00Tuesday 9:00-12:00 and 15:00-17:00Wednesday 9:00-12:00 and 15:00-17:00Thursday 9:00-12:00 and 15:00-17:00 Friday 9:00-12:00
ICT International Doctoral School, Trento @RT 2014
Main References - 1
R. Tempo, G. Calafiore and F. Dabbene,
“Randomized Algorithms for Analysis
and Control of Uncertain Systems, with
Applications,” Second Edition,
Springer-Verlag, London, 2013
F. Dabbene and R. Tempo, “Randomized Methods for
Control,” Encyclopedia of Systems and Control, 2014
(to appear)
ICT International Doctoral School, Trento @RT 2014
Main References - 2
F. Dabbene and R. Tempo, “Probabilistic and
Randomized Tools for Control Design,” The Control
Handbook, second edition, Taylor & Francis, 2010
G. Calafiore, F. Dabbene and R. Tempo “Research on
Probabilistic Design Methods,” Automatica, 2011
R. Tempo and H. Ishii, “Monte Carlo and Las Vegas
Randomized Algorithms for Systems and Control: An
Introduction,” European Journal of Control, 2007
ICT International Doctoral School, Trento @RT 2014
Software
R-RoMulOC: Randomized and Robust Multi-Objective
Control toolbox
http://projects.laas.fr/OLOCEP/rromuloc/
RACT: Randomized Algorithms Control Toolbox for
Matlab
http://ract.sourceforge.net
ICT International Doctoral School, Trento @RT 2014
Research Interests and Background
Question: What are your research interests andbackground?
ICT International Doctoral School, Trento @RT 2014
Main Topics Studied in this Course
Preliminaries
Probabilistic Analysis
Probabilistic Design: The Big Picture
Sequential Methods for Convex Problems
Non-Sequential Methods
RACT
Opinion dynamics in social networks
PageRank computation in Google
Sensor localization in wireless networks
ICT International Doctoral School, Trento @RT 2014
Part 1: Analysis
Analysis Paradigm:
Understanding Phenomena
ICT International Doctoral School, Trento @RT 2014
Overview of Part 1 (Analysis)
1. Preliminaries
2. Uncertainty
3. Randomized Algorithms
4. Random Vector Generation
5. Random Matrix Generation
ICT International Doctoral School, Trento @RT 2014
CHAPTER 1
Preliminaries
Keywords: Uncertainty, robustness, probability
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithms (RAs)
Randomized algorithms are frequently used in many
areas of engineering, computer science, physics,
finance, optimization,…
Main objective of this course: Introduction to rigorous
study of RAs for uncertain systems, control and
networks
The theory is ready for specific applications
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithms (RAs)
Computer science (RQS for sorting, data structuring)
Robotics (motion and path planning problems)
Mathematics of finance (path integrals)
Bioinformatics (string matching problems)
Computer vision (computational geometry)
PageRank computation (distributed algorithms)
Opinion dynamics in social networks
ICT International Doctoral School, Trento @RT 2014
A Success Story: Randomization in Computer Science
ICT International Doctoral School, Trento @RT 2014
A Success Story in CS
Problem: Sorting N real numbers
Algorithm: RandQuickSort (RQS)
RQS is implemented in a C library of Linux for sortingnumbers[1-2]
[1] C.A.R. Hoare (1962)[2] D.E. Knuth (1998)
ICT International Doctoral School, Trento @RT 2014
A Success Story in CS
Problem: Sorting N real numbers
Algorithm: RandQuickSort (RQS)
RQS is implemented in a C library of Linux for sortingnumbers
Sorting Problem
given N real x1 x2 x3 sort them in
numbers x4 x5 x6 increasing order
S1ICT International Doctoral School, Trento @RT 2014
RandQuickSort (RQS)
The idea is to divide the original set S1 into two setshaving (approximately) the same cardinality
This requires finding the median of S1 (which may bedifficult)
This operation is performed using randomization
ICT International Doctoral School, Trento @RT 2014
RandQuickSort (RQS)
RQS is a recursive algorithm consisting of two phases
1. randomly select a number xi (e.g. x4)2. deterministic comparisons between xi and other (N-1) numbers
x2 x3 x1 x5
x6
numbers smaller than x4 numbers larger than x4
S2 S3
4x
ICT International Doctoral School, Trento @RT 2014
RQS: Binary Tree Structure
We use randomization at each step of the (binary) tree
ICT International Doctoral School, Trento @RT 2014
Running Time of RQS
Because of randomization, running time may bedifferent from one run of the algorithm to the next one
RQS is very fast: Average running time is O(N log(N))
This is a major improvement compared to brute forceapproach (e.g. when N = 2M)
Average running time holds for every input withprobability at least 1-1/N (i.e. it is highly probable)
The so-called Chernoff bound can be used to prove this
Improvements for RQS to avoid achieving the worstcase running time O(N 2)
ICT International Doctoral School, Trento @RT 2014
Find Algorithm
Find Algorithm: Find the k-th smallest number in a set
Basically it is a RQS but it terminates when the numberis found
Average running time of Find is O(N)
ICT International Doctoral School, Trento @RT 2014
Another Success Story: Randomization in Mathematical Finance
ICT International Doctoral School, Trento @RT 2014
(Quasi) Monte Carlo Methods for Computational Finance
QMC methods to estimate the prize of collaterizedmortgage obligations
The problem is to approximate the average mortgage
taking N samples for each variable, but we need Nn
total number of points
Curse of dimensionality: n = 360!
[0,1]( ) d
nf u u
ICT International Doctoral School, Trento @RT 2014
Uncertainty and Robustness
Some History
ICT International Doctoral School, Trento @RT 2014
Uncertainty
“The use of equalizing structures to compensate for the variation
in the phase and attenuation characteristics of transmission lines
and other pieces of apparatus is well known in the communication
art… the characteristics demanded of the equalizer cannot be
prescribed in advance, either because… are not known with
sufficient precision, or because they vary with time… transmission
lines the exact lengths of which are unknown, or the
characteristics of which may be affected by changes in
temperature and humidity.... and since the daily cycle of
temperature changes may be large…”
ICT International Doctoral School, Trento @RT 2014
Variable Equalizers
The quote is taken from the paper titled “Variable
Equalizers” by Hendrik W. Bode published in 1938 in
Bell System Technical Journal
The quote continues “it is almost essential that theadjustments made be so simple that they can readily beperformed automatically by a suitable auxiliary circuit.”
Bode fully recognized the importance to control a systemsubject to uncertainty
ICT International Doctoral School, Trento @RT 2014
Robustness
The examination of uncertainty in the mathematical
model of a system is known as robustness
Uncertainty is a central part of feedback and controllers
which guarantee an adequate level of performance are
called robust controllers
ICT International Doctoral School, Trento @RT 2014
History
Classical sensitivity period (before 1960)
State-variable period (1960-1975)
Modern robust control period (after 1975)
ICT International Doctoral School, Trento @RT 2014
Two Lines of Research in the Early Seventies
Design of adaptive guaranteed cost control in the
presence of large parameter variations[1]
Set-theoretic description of uncertainty (called
unknown-but-bounded) for estimation problems[2]
[1] S. Chang and T.K.C. Peng (1972)
[2] F. Schweppe (1973)
ICT International Doctoral School, Trento @RT 2014
Other Early Approaches where “Robust” Appeared
Robust controllers for linear regulators[1]
Robust control of general servomechanisms[2]
[1] J. Pearson and P.W. Staats (1974)
[2] E. Davison and A. Goldenberg (1975)
ICT International Doctoral School, Trento @RT 2014
Robustness and H Control
Lack of guaranteed robustness margins in LQG
control[1]
Robustness of systems with sector-type uncertainty[2]
Major stepping stone in 1981 by George Zames:
Formulation of the H control problem and solution of
the H sensitivity problem[3]
[1] J. Doyle (1978)
[2] M.G. Safonov (1980)
[3] G. Zames (1981)
ICT International Doctoral School, Trento @RT 2014
State Space Approach and Solution
Performance limitations in feedback control[1]
Further developments based on interpolation theory[2]
… but the theory moved in a state space direction[3]
[1] J. Freudenberg and D. Looze (1985)
[2] G. Zames and B. A. Francis (1983)
[3] J. C. Doyle, K. Glover, P. P. Khargonekar and B. Francis (1989)
ICT International Doctoral School, Trento @RT 2014
Today
Various “robust” methods to handle uncertainty now
exist: Structured singular values, Kharitonov,
optimization-based (LMI and SOS), integral quadratic
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithm: Definition
Randomized Algorithm (RA): An algorithm that makesrandom choices during its execution to produce a result
For hybrid systems, “random choices” could beswitching between different states or logical operations
For uncertain systems, “random choices” require (vectoror matrix) random sample generation
ICT International Doctoral School, Trento @RT 2014
Monte Carlo Randomized Algorithm
ICT International Doctoral School, Trento @RT 2014
Monte Carlo Randomized Algorithm
Monte Carlo Randomized Algorithm (MCRA): Arandomized algorithm that may produce incorrect results,but with bounded probability of error
ICT International Doctoral School, Trento @RT 2014
Monte Carlo Randomized Algorithm
Monte Carlo Randomized Algorithm (MCRA): Arandomized algorithm that may produce incorrect results,but with bounded probability of error
ICT International Doctoral School, Trento @RT 2014
Monte Carlo Randomized Algorithm
Monte Carlo Randomized Algorithm (MCRA): Arandomized algorithm that may produce incorrect results,but with bounded probability of error
Prob{error > } < 2e(-2N2) Hoeffding inequality
where is the probabilistic accuracy of the estimate, N isthe sample size (sample complexity) and e is the Eulernumber
ICT International Doctoral School, Trento @RT 2014
Example of Monte Carlo: Area/Volume Estimation
Estimate the volume of the red area: Generate N samplesuniformly in the rectangle; count how many (M) fallwithin the red area, then the estimated area = M/N
ICT International Doctoral School, Trento @RT 2014
One-Sided and Two-Sided Monte Carlo Randomized Algorithm
ICT International Doctoral School, Trento @RT 2014 128
Uncertain Decision Problems
Recall the definitions of reliability (probability ofperformance) and worst-case performance
R = Prob{J() }
Objective: Given a performance level , check if
and
These are uncertain decision problems
)(max
max
JJB
γR γmax J
ICT International Doctoral School, Trento @RT 2014
One-Sided and Two-Sided MCRA
Given we have two problem instances for probabilityof performance
and
and two problem instances for worst-case performance
and
This leads to one-sided and two-sided Monte Carlorandomized algorithms
γR γR
γmax Jγmax J
ICT International Doctoral School, Trento @RT 2014
One-Sided MCRA
One-sided MCRA: Always provides a correct solution inone of the instances (they may provide a wrong solutionin the other instance)
Consider the empirical maximum
Check if
)(maxˆ )(
,,1
iN JJ
Ni
γˆorγˆ NN JJ
ICT International Doctoral School, Trento @RT 2014
One-Sided MCRA: Case 1
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J algorithm provides a correct solution
Jmax
NJ
γˆmax JJN
ICT International Doctoral School, Trento @RT 2014
One-Sided MCRA: Case 2
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J algorithm may provide a wrong solution
Jmax
NJ
maxγˆ JJN
ICT International Doctoral School, Trento @RT 2014
Two-Sided MCRA
Two-sided MCRA: May provide a wrong solution inboth instances
Consider the empirical reliability
where Ngood is the number of samples such that J(i)) Check if
N
NRN
goodˆ
γˆorγˆ NN RR
ICT International Doctoral School, Trento @RT 2014
Two-Sided MCRA: Case 1
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J algorithm may provide a wrong solution
RRN γˆ
R
NR
ICT International Doctoral School, Trento @RT 2014
Two-Sided MCRA: Case 2
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J algorithm may provide a wrong solution
NRR ˆγ
R
NR
ICT International Doctoral School, Trento @RT 2014
Las Vegas Randomized Algorithm
ICT International Doctoral School, Trento @RT 2014
Las Vegas Randomized Algorithm
Las Vegas Randomized Algorithm (LVRA): Arandomized algorithm that always produces correctresults, the only variation from one run to another is therunning time
ICT International Doctoral School, Trento @RT 2014
Las Vegas Randomized Algorithm
Las Vegas Randomized Algorithm (LVRA): Arandomized algorithm that always produces correctresults, the only variation from one run to another is therunning time
Example: Randomized Quick Sort (RQS)
ICT International Doctoral School, Trento @RT 2014
Las Vegas Randomized Algorithm
Las Vegas Randomized Algorithm (LVRA): Arandomized algorithm that always produces correctresults, the only variation from one run to another is therunning time
ICT International Doctoral School, Trento @RT 2014
Example of Las Vegas: Discrete Random Variables
q1 q2 q3 q4 q5 q6 q7 q8 q9 q10
Consider discrete random variables
ICT International Doctoral School, Trento @RT 2014
Example of Las Vegas: Discrete Random Variables
q1 q2 q3 q4 q5 q6 q7 q8 q9 q10
Consider discrete random variables
ICT International Doctoral School, Trento @RT 2014
Example of Las Vegas: Discrete Random Variables
q1 q2 q3 q4 q5 q6 q7 q8 q9 q10
Consider discrete random variables
ICT International Doctoral School, Trento @RT 2014
Las Vegas Viewpoint
ICT International Doctoral School, Trento @RT 2014
Las Vegas Randomized Algorithms
Las Vegas Randomized Algorithm (LVRA): Alwaysgive the correct solution
They are also called zero-sided randomized algorithms
The solution obtained with a LVRA is probabilistic, so“always” means with probability one
Running time may be different from one run to another
We study the average running time
ICT International Doctoral School, Trento @RT 2014
Las Vegas Viewpoint
Consider discrete random variables
The sample space is discrete and MN possible choicescan be made
In the binary case we have 2N
Finding maximum requires ordering the 2N choices
Las Vegas can be used for ordering real numbers
Example: RQS
ICT International Doctoral School, Trento @RT 2014
Complexity Relaxation
If N is too large (e.g. when N=2M), we may want toconsider only a subset of K samples out of N
This leads to (one-sided) Monte Carlo which gives asuboptimal, but more efficient, solution
Close connections with Ordinal Optimization[1] havingthe objective not to find the maximum value, but thevalue which is within the top N-th percent (for given N)
Conclusion: Ordering between elements is easier thanfinding their values
[1] Y.C. Ho, R. Sreenivas, P. Vakili (1992)
ICT International Doctoral School, Trento @RT 2014
Continuous versus Discrete Sample Space
The underlying problem may be continuous or discrete
For Lyapunov stability the original problem iscontinuous, but it may be equivalent to another discreteproblem in various instances (depending how theuncertainty enter into the state space matrices)
For consensus problems the original problem is discrete(binary), e.g. Byzantine Agreement
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithms for Control
ICT International Doctoral School, Trento @RT 2014
Ingredients for RAs
Assume that is random with given pdf and support B
Accuracy (0,1) and confidence (0,1) be assigned
Performance function for analysis and level
↓ ↓
J = J()
ICT International Doctoral School, Trento @RT 2014
Randomized Algorithms for Analysis
Different classes of randomized algorithms for
probabilistic analysis to estimate
Probability of performance
Worst-case performance
Probability of failure
They are based on uncertainty randomization of
Sample complexity is obtainedICT International Doctoral School, Trento @RT 2014
Estimating the Probability of Performance
ICT International Doctoral School, Trento @RT 2014
Estimate of the Probability of Performance
Objective: Construct a probabilistic estimate usingMonte Carlo randomized algorithms of reliability(probability of performance)
R = Prob{J() }
ICT International Doctoral School, Trento @RT 2014
Monte Carlo Experiment
We draw N i.i.d. random samples of according to thegiven probability measure
), 2), …, ) B
The multisample within B is
1,…,N = {(1), ... , N)}
We evaluate
J()), J()), …, J(N))
ICT International Doctoral School, Trento @RT 2014
Example
J
ICT International Doctoral School, Trento @RT 2014
Example
1 2 3 4 5 6
J
ICT International Doctoral School, Trento @RT 2014
Example
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J
ICT International Doctoral School, Trento @RT 2014
Empirical Reliability
We construct the empirical reliability
where I (·) denotes the indicator function
Notice that
where Ngood is the number of samples such that J(i))
N
i
iN J
NR
1
)( )1ˆ I
( )
( ) 1 if ( )( )
0 otherwise
ii J γ
J
I
N
NRN
goodˆ
ICT International Doctoral School, Trento @RT 2014
Sample Complexity
We need to compute the size of the Monte Carloexperiment (sample complexity)
This requires to introduce probabilistic accuracy (0,1) and confidence (0,1)
Given , (0,1), we want to determine N such that theprobability event
holds with probability at least 1-
εˆ NRR
ICT International Doctoral School, Trento @RT 2014
A Good Estimate
If the probability event
holds with probability at least 1- , the we say that theempirical reliability is a “good” estimate of thereliability R
εˆ NRR
ICT International Doctoral School, Trento @RT 2014
Law of Large Numbers[1]
Bernoulli Bound
Given , (0,1), if
then the probability inequality
holds with probability at least 1-
be 2
1
4ε δN N
[1] J. Bernoulli (1713)
εˆ NRR
ICT International Doctoral School, Trento @RT 2014
Remarks
The number of samples computed with the Law of LargeNumbers is independent of the number and dimension ofblocks in , the density function f and the size of B
The number of samples N is very large
1-
Nbe
ICT International Doctoral School, Trento @RT 2014
Other Bounds
The Bernoulli bound is based on the Chebyshev
inequality
Other bounds are also available, such as those based
on the Bienaymé inequality
A bound that largely improves the previous ones, for
small values of and , is the (additive) Chernoff
bound
ICT International Doctoral School, Trento @RT 2014
(Additive) Chernoff Bound[1]
(Additive) Chernoff Bound
Given , (0,1), if
then the probability inequality
holds with probability at least 1-
2δ2
ch ε2
logNN
[1] H. Chernoff (1952)
εˆ NRR
ICT International Doctoral School, Trento @RT 2014
Remarks
Chernoff bound improves upon other bounds such asthe Law of Large Numbers (Bernoulli)
Dependence is logarithmic on 1/ and quadratic on 1/ Sample size is independent on the number of
controller and uncertain parameters
1-
Nch
ICT International Doctoral School, Trento @RT 2014
Comparison Between Bounds
ICT International Doctoral School, Trento @RT 2014
Accuracy vs Confidence
Confidence is “cheap” because of the logarithmicdependence
Acccuracy is computationally more expensive becauseof quadratic dependence
Can we improve the quadratic dependence?
The answer to this question is provided by the(multiplicative) Chernoff Bound
ICT International Doctoral School, Trento @RT 2014
(Multiplicative) Chernoff Bound
(Multiplicative) Chernoff Bound
Fox fixed and for given , (0,1), if
then the probability inequality
holds with probability at least 1-
1δ
mu 2
2log
ε(1-β)N N
εˆ NRR
ˆβ=β( )NR
ICT International Doctoral School, Trento @RT 2014
A Priori and A Posteriori Analysis
Multiplicative Chernoff Bound has sample complexity1/ but it requires the parameter which depends onthe empirical mean (a posteriori analysis)
Additive Chernoff Bound has sample complexitywhich depends as 1/2 (a priori analysis)
ICT International Doctoral School, Trento @RT 2014
Hoeffding Inequality and Chernoff Bound - 1
Given (0,1), from the Hoeffding inequality we obtain
Prob{1,…,N : } ≤ 2e(-2N2)
where e denotes the Euler number
To guarantee confidence (0,1), we need to take N
samples such that 2e(-2N2) ≤ holds
We obtain the (additive) Chernoff bound
N ≥ 1/ (22) log(2/ )
ˆ- εNR R
ICT International Doctoral School, Trento @RT 2014
Hoeffding Inequality and Chernoff Bound - 2
The Hoeffding inequality provides a bound on the tail
distribution
2e(-2N2)
From the computational point of view, computing the
minimum value of N that 2e(-2N2) ≤ is immediate
(given and it is a one-parameter problem)
The Chernoff bound provides a fundamental explicit
relation (sample complexity) N = N(, ) showing that
1/ enters quadratically and 1/ logarithmicallyICT International Doctoral School, Trento @RT 2014
Hoeffding Inequality and Chernoff Bound - 3
Chernoff bound and the Hoeffding inequality hold only
for fixed performance function J
Some results are available for a finite number of
performance functions
For an infinite number of performance functions we need
to use statistical learning theory (studied later in this
course)
ICT International Doctoral School, Trento @RT 2014
Parallel and Distributed Simulations
Samples q(1), q(2), …, q(N) are i.i.d.
Contrary to MCMC or sequential Monte Carlo, thisapproach leads to parallel and distributed simulations
IBM Blue Gene Cray-1 vector processorICT International Doctoral School, Trento @RT 2014
Parallel and Distributed Simulations
Samples q(1), q(2), …, q(N) are i.i.d.
Contrary to Markov Chain Monte Carlo (MCMC) orsequential Monte Carlo, this approach leads to paralleland distributed simulations
Sample generation requires tools from importantsampling techniques
Connections with the theory of random matrices[1]
[1] G. Calafiore, F. Dabbene, R. Tempo (2000)
ICT International Doctoral School, Trento @RT 2014
Estimating the Worst-Case Performance
ICT International Doctoral School, Trento @RT 2014
Worst-Case Performance
Using a Monte Carlo experiment compute aprobabilistic estimate of the worst-case performance
max max ( )J J Β
ICT International Doctoral School, Trento @RT 2014
Probabilistic Estimate of Worst-Case Performance
The multisample within B is
1,…,N = {(1), ... , N)}
We evaluate
J()), J()), …, J(N))
Compute the empirical maximum
)(maxˆ )(
,,1
iN JJ
Ni
ICT International Doctoral School, Trento @RT 2014
Log-over-log Bound[1]
Log-over-log Bound
Given , (0,1), if
then the probability inequality
holds with probability at least 1-
ε11
log
δ1
log
lolNN
[1] R. Tempo, E. W. Bai and F. Dabbene (1996)
ˆProb ( ) εNJ J
ICT International Doctoral School, Trento @RT 2014
Comments
Number of samples is much smaller than Chernoff
Bound is a specific instance of the fpras (fullypolynomial randomized approximated scheme) theory
Dependence on 1/ is basically linear
1-
Nlol
ε
ε1
1log
ICT International Doctoral School, Trento @RT 2014
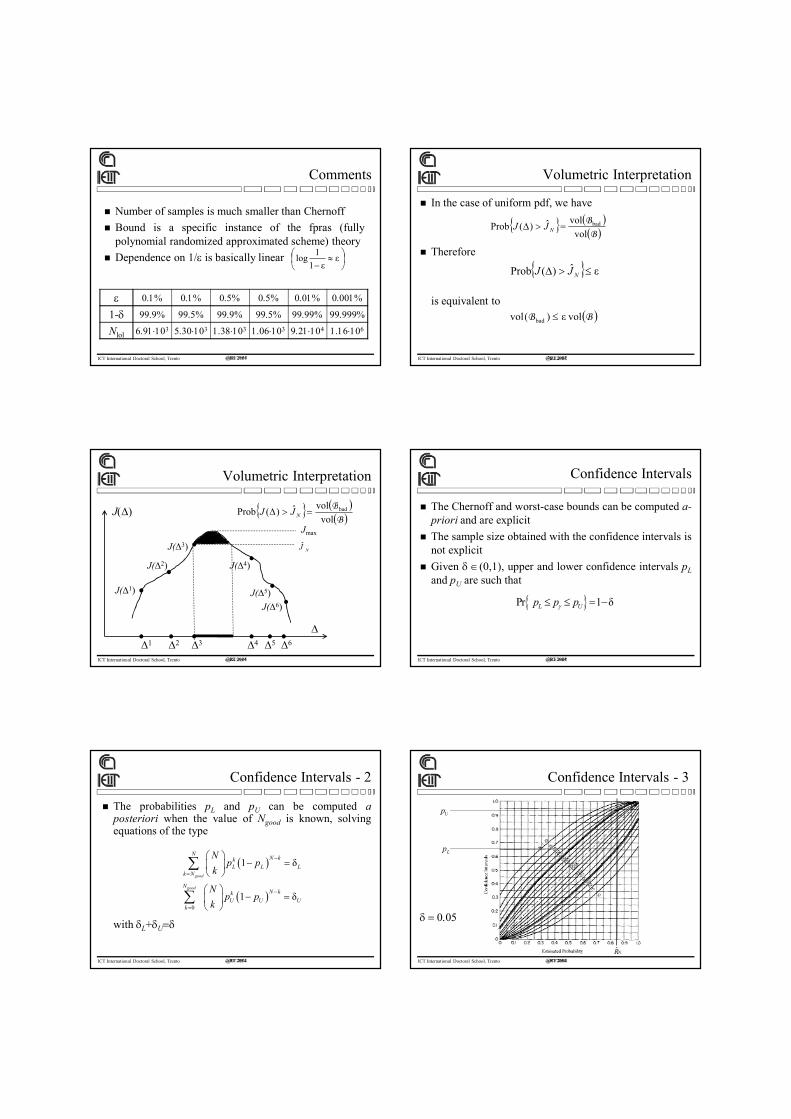
Volumetric Interpretation
In the case of uniform pdf, we have
Therefore
is equivalent to
BB
vol
volˆ)(Prob bad NJJ
εˆ)(Prob NJJ
BB volε)(vol bad
ICT International Doctoral School, Trento @RT 2014
Volumetric Interpretation
1 2 3 4 5 6
J(1)
J(2)
J(3)
J(4)
J(5)
J(6)
J
Jmax
NJ
BB
vol
volˆ)(Prob bad NJJ
ICT International Doctoral School, Trento @RT 2014
Confidence Intervals
The Chernoff and worst-case bounds can be computed a-priori and are explicit
The sample size obtained with the confidence intervals isnot explicit
Given (0,1), upper and lower confidence intervals pL
and pU are such that
Pr 1 δL Up p p
ICT International Doctoral School, Trento @RT 2014
Confidence Intervals - 2
The probabilities pL and pU can be computed aposteriori when the value of Ngood is known, solvingequations of the type
with L+U
0
1 δ
1 δ
good
good
NN kk
L L Lk N
NN kk
U U Uk
Np p
k
Np p
k
ICT International Doctoral School, Trento @RT 2014
Confidence Intervals - 3
ˆNR
Up
Lp
ICT International Doctoral School, Trento @RT 2014
Bounds on the Binomial Distribution
ICT International Doctoral School, Trento @RT 2014
Bounds on the Binomial Distribution
The so-called probability of failure is studied in the
scenario approach and in statistical learning theory
(discussed later in the course)
This required bounding the binomial distribution
0
B( ,ε, ) ε 1 εm
N ii
i
NN m
i
ICT International Doctoral School, Trento @RT 2014
Bounding the Binomial Distribution and Sample Complexity
Theorem[1]: Given , (0,1) and m 0, if
then
[1] T. Alamo, R. Tempo and A. Luque (2010)
1
1 1inf log log( )
ε 1 δa
aN m a
a
0
B( ,ε, ) ε 1 ε δm
N ii
i
NN m
i
ICT International Doctoral School, Trento @RT 2014
Bounding the Binomial Distribution and Sample Complexity
Suboptimal value of a is the Euler number e
Sample complexity is given by
Sample complexity is linear in
- 1/ (not quadratic!)
- m
-
1 1log
ε 1 δ
eN m
e
1log
δ
ICT International Doctoral School, Trento @RT 2014
Probabilistic Methods:Benefits and Drawbacks
Benefits Drawbacks
very general method with immediatepractical applications, for example inaircraft design and process control industry
the results obtained provide no“deterministic certificate” of propertysatisfaction, for example H-infinityperformance
specific sample generation methods havebeen developed (e.g. for norm bounded sets,hit-and-run for convex sets, particlefiltering, importance sampling, MCMC)
for recursive methods the number ofrequired experiments is generally notspecified a priori
sample size bounds are available for non-recursive methods
the method does not cover the entire samplespace, but only a finite subset of it
Monte Carlo methods are very effective indealing with the “curse of dimensionality”;the probability of error is bounded
crucial points of the safety region can bemissed, this may lead to erroneousconclusions
ICT International Doctoral School, Trento @RT 2014
Probabilistic Sorting of Switched Systems
ICT International Doctoral School, Trento @RT 2014
Sorting of Switched Systems
Consider Lyapunov equations
L(P, A) = (Ai)T P + P Ai for all i =1, 2, …, N
The objective is to sort these N Lyapunov equations
according to their degree of stability (decay rate) using
a common P > 0 previously computed
Motivations: Deciding which systems are more stable
than others is useful information for the controller
ICT International Doctoral School, Trento @RT 2014
LVRA for Matrix Sorting
The sorting operation should be performed quickly
because we are switching between N = 22n systems
This requires finding a LVRA which provides a
matrix sorting for the N equations L(P)
Matrix version of RandQuickSort is developed[1]
Technical difficulty: The equations may be not
completely sortable because of sign indefiniteness
[1] H. Ishii, R. Tempo (2009)
ICT International Doctoral School, Trento @RT 2014
RandQuickSort for Matrices
Variation on RandQuickSort for sorting N = 22n
Lyapunov equations
Construction of the set of matrices which are not
sortable at that stage of the tree
We build a trinary (instead of binary) tree
ICT International Doctoral School, Trento @RT 2014
RQS for Matrices: Trinary Tree
We use randomization at each step of the (trinary) tree
ICT International Doctoral School, Trento @RT 2014
RQS for Matrices: Results
If the Lyapunov equations are completely sortable,
then the expected running time is (the same of RQS)
O(N log (N))
If the Lyapunov equations are not completely sortable,
then additional comparisons should be performed
The worst case number of additional comparisons is
N(N-1)/2
ICT International Doctoral School, Trento @RT 2014
Computational Complexity of RAs
ICT International Doctoral School, Trento @RT 2014
Computational Complexity of RAs
RAs are efficient (polynomial-time) because
1. Random sample generation of i) can be performed
in polynomial-time
2. Cost associated with the evaluation of J(i)) for
fixed i) is polynomial-time
3. Sample size is polynomial in the problem size and
probabilistic levels and
ICT International Doctoral School, Trento @RT 2014
1. Bounds on the Sample Size
Chernoff bound is independent on the size of B, on theuncertainty structure, on the pdf and on the number ofuncertainty blocks
It depends only on probabilistic accuracy andconfidence
Same comments can be made for other bounds (such
as Bernoulli)
ICT International Doctoral School, Trento @RT 2014
2. Cost of Checking Stability
Consider a polynomial
To check left half plane stability we can use the Routhtest. The number of multiplications needed is
The number of divisions and additions is equal to thisnumber
We conclude that checking stability is O(n2)
odd for 4
1 even for
4
22
nn
nn
nnsasaaasp 10),(
ICT International Doctoral School, Trento @RT 2014
3. Random Sample Generation
Random number generation (RNG): Linear and
nonlinear methods for uniform generation in [0,1) such
as Fibonacci, feedback shift register, BBS, MT, …
Non-uniform univariate random variables: Suitable
functional transformations (e.g., the inversion method)
Much harder problem: Multivariate generation of
samples of with given pdf and support B
.It can be resolved in polynomial-time
ICT International Doctoral School, Trento @RT 2014
Choice of the Probability Distribution
ICT International Doctoral School, Trento @RT 2014
Choice of the Probability Distribution - 1
The probability Prob{S}
depends on the underlying
pdf
It may vary between 0 and 1
depending on the pdf
ICT International Doctoral School, Trento @RT 2014
Choice of the ProbabilityDistribution - 2
The bounds discussed are independent on the choiceof the distribution but for computing an estimate ofProb{J() } we need to know the distribution
Research has been done in order to find the worst-casedistribution in a certain class[1]
Uniform distribution is the worst-case if a certaintarget is convex and centrally symmetric
[1] B. R. Barmish and C. M. Lagoa (1997)
ICT International Doctoral School, Trento @RT 2014
Choice of the ProbabilityDistribution - 3
Minimax properties of the uniform distribution have
been shown[1]
[1] E. W. Bai, R. Tempo and M. Fu (1998)
ICT International Doctoral School, Trento @RT 2014
CHAPTER 4
Random Vector Generation
Keywords: Radial distributions, inversion method, generalizedGamma density, uniform distribution in norm balls
ICT International Doctoral School, Trento @RT 2014
Random Sample Generation
ICT International Doctoral School, Trento @RT 2014
True Random Number Generators
Hardware sources of trulystatistically random numbers