IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009 101
A Framework for Foresighted ResourceReciprocation in P2P Networks
Hyunggon Park, Student Member, IEEE, and Mihaela van der Schaar, Senior Member, IEEE
Abstract—We consider peer-to-peer (P2P) networks, wheremultiple peers are interested in sharing multimedia content. Insuch P2P networks, the shared resources are the peers’ con-tributed content and their upload bandwidth. While sharingresources, autonomous and self-interested peers need to makedecisions on the amount of their resource reciprocation (i.e.,representing their actions) such that their individual utilitiesare maximized. We model the resource reciprocation among thepeers as a stochastic game and show how the peers can determineoptimal strategies for resource reciprocation using a MarkovDecision Process (MDP) framework. Unlike existing resourcereciprocation strategies, which focus on myopic decisions of peers,the optimal strategies determined based on MDP enable thepeers to make foresighted decisions about resource reciprocation,such that they can explicitly consider both their immediate aswell as future expected utilities. To successfully formulate theMDP framework, we propose a novel algorithm that identifiesthe state transition probabilities using representative resourcereciprocation models of peers. These models express the peers’different attitudes toward resource reciprocation. We analyticallyinvestigate how the error between the true and estimated statetransition probability impacts each peer’s decisions for selectingits actions as well as the resulting utilities. Moreover, we also ana-lytically study how bounded rationality (e.g., limited memory forreciprocation history and the limited number of state descriptions)can impact the interactions among the peers and the resultingresource reciprocation. Simulation results show that the proposedapproach based on reciprocation models can effectively copewith a dynamically changing environment such as peers’ joiningor leaving P2P networks. Moreover, we show that the proposedforesighted decisions lead to the best performance in terms of thecumulative expected utilities.
P eer-to-peer (P2P) applications (e.g., [1]–[3]) have re-cently become increasingly popular and represent a large
majority of the traffic currently transmitted over the Internet.One of the unique aspects of P2P networks stems from theirflexible and distributed nature, in which each peer can act as
Manuscript received March 16, 2008; revised September 16, 2008. First pub-lished December 16, 2008; current version published January 09, 2009. Thiswork was supported by NSF CAREER Award CCF-0541867, and grants fromMicrosoft Research. The associate editor coordinating the review of this manu-script and approving it for publication was Prof. Ling Guan.
The authors are with the Electrical Engineering Department, University ofCalifornia, Los Angeles CA 90095, USA (e-mail: [email protected]; [email protected]).
Digital Object Identifier 10.1109/TMM.2008.2008925
both server and client [4]. Hence, P2P networks provide a costeffective and easily deployable framework for disseminatinglarge files without relying on a centralized infrastructure [5].Due to these characteristics, it has been recently proposed touse P2P networks for general file sharing [2], [3], [6], [7] aswell as multimedia streaming [5], [8]–[10]. Moreover, severalmedia streaming systems have been successfully developed forP2P networks using different approaches such as tree-basedor data-driven approaches (e.g., [11], [12]). In this paper, wefocus on data-driven P2P systems such as CoolStreaming [8]and Chainsaw [9] for multimedia streaming, or BitTorrentsystems [6], [7] for general file sharing, which adopt pull-basedtechniques [8], [9]. In these systems, data (i.e., multimediastream or general files) are divided into chunks of uniformlength, which are distributed over the P2P network. Each peerpossesses several chunks which are shared among interested1
peers. Information about the availability of the chunks is alsoperiodically exchanged among the associated peers. Usingthis information, peers continuously associate themselves withother peers and exchange their chunks. While this approach hasbeen successfully deployed in real-time multimedia streamingand file distributions over P2P networks, key challenges suchas determining optimal resource reciprocation among self-in-terested peers still remain largely unaddressed. Specifically,pull-based techniques assume that the peers in the P2P networkare altruistic and they provide their available chunks wheneverrequested. However, such a reciprocation strategy is undesirablefrom the perspective of a self-interested peer, who is aiming atmaximizing its utility.
The resource reciprocation strategy deployed in BitTorrentis based on the equal upload bandwidth distribution. A peerin BitTorrent systems thus equally divides its available up-load bandwidth among multiple leechers [6], [7]. However,for heterogeneous content and diverse peers (with differentupload/download requirement), such reciprocation strategiesare not optimal. The resource reciprocation in [8] is based ona heuristic scheduling algorithm, which enables the peers todetermine the suppliers of required chunks and select the peerwith the highest bandwidth. Alternatively, the resource recipro-cation can be based on the random chunk selection algorithm asin [9]. As discussed, the solutions in [8] or [9] are implementedassuming that the associated peers are altruistic, such that theyprovide the chunks and bandwidth whenever requested. Hence,the resource reciprocation methods in these solutions do not
1In [6], [7], it is said that peer A is interested in peer B when B has chunks ofthe content that A would like to possess.
102 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
consider the strategic interactions of the heterogeneous andself-interested peers.
To take into account the interactions of heterogeneousand self-interested peers in P2P networks, game theoreticapproaches have been proposed. In [13], a micropaymentmechanism is used to model the rational peers’ interactions,and the resulting equilibria emerging when different paymentmechanisms are imposed. In general, a key assumption is thatpeers will follow the prescribed P2P protocols. It has beenfound, however, that self-interested peers will deviate from theprescribed protocols or free-ride unless preemptive solutionsexist in the network. For example, in [14], mechanism designsolutions are proposed in order to compel the peers to adhereto their reciprocation promises. In [15], an incentive schemefor compelling peers to contribute resources is proposed,which provides differential services based on the peer’s pastcontributions. The interactions for different types of peers(e.g., homogeneous or heterogeneous) are analyzed using thenotion of Nash equilibrium. In the above approaches, however,the peers determine their decisions (i.e., actions) to maximizetheir utilities myopically, without explicitly considering thefuture impact of the actions on their long-term utilities. In[16], the repeated interactions among peers are modeled asan evolutionary instantiation of the Prisoner’s Dilemma andthe Generalized Prisoner’s Dilemma, and incentive techniquesare proposed for peers in order to compel them to contributetheir resources. However, this research only considers the casewhere peers have a limited set of simple actions, i.e., allowingdownload or ignoring download requests, but does not addresshow to divide each peer’s available resources. Hence, they donot provide solutions for maximizing the foresighted utilitiesof peers, which is essential in P2P systems, where peers havelong-term interactions.
To address these challenges, in this paper, we model the re-source reciprocation among the interested peers as a stochasticgame [17], where peers determine their resource distributionsby explicitly considering the probabilistic behaviors (reciproca-tion) of their associated peers. Unlike existing resource recip-rocation strategies, which focus on myopic decisions, we for-malize the resource reciprocation game as a Markov DecisionProcess (MDP) [18] to enable peers to make foresighted deci-sions on their resource distribution in a way that maximizes theircumulative utilities, i.e., their immediate as well as future utili-ties.
To successfully formulate the resource reciprocation gameas an MDP problem, the peers need to identify the associatedpeers’ probabilistic behaviors for resource reciprocation. Theprobabilistic behaviors of the associated peers can be estimatedusing the past history of resource reciprocation and are repre-sented by state transition probabilities in the MDP framework.In this paper, the state of a peer is defined as the set of receivedresources from each of the associated peers. Hence, the actionsof the associated peers determine a peer’s state. We propose anovel algorithm that can efficiently identify the state transitionprobabilities using peers’ reciprocation models. The reciproca-tion models of the peers are motivated by [19], which classify
TABLE ISUMMARY OF NOTATIONS
the rational attitudes of players in a game towards their strate-gies as optimistic, pessimistic, and neutral archetypes. We con-struct reciprocation matrices to capture the reciprocation behav-iors of peers. Then, the state transition probabilities are identi-fied by linear combinations of weighted reciprocation matrices.Note that the decisions made by peers based on the estimatedstate transition probabilities can lead to different resource recip-rocation strategies than those based on the true state transitionprobabilities, thereby possibly deviating from the actual derivedutility. This impact on the accuracy of the estimated utility is an-alytically quantified.
Unlike the implicit assumptions on players’ rationality inconventional game theory, where players have the abilities tocollect and process relevant information, and select alternativeactions among all possible actions [20], [19], we considerthe bounded rationality [20] of peers. This is because per-fectly rational decisions are often infeasible in practice due tomemory and computational constraints. To illustrate the effectsof bounded rationality, we consider cases where the peers havelimited memory for storing the resource reciprocation history,and have a limited number of states based on which they maketheir decisions. We also quantify the impact of the boundedrationality on the peers’ interactions and their utilities.
This paper is organized as follows. In Section II, we modelthe resource reciprocation among peers as a resource reciproca-tion game. In Section III, the types of peers in the consideredP2P networks are discussed. They are classified based on theirobjectives in terms of utilities and their resource reciprocationattitudes. In Section IV, we analytically investigate the interac-tions among different types of peers with different constraints.In Section V, an algorithm that determines the state transitionprobabilities based on the reciprocation models is proposed. Weanalytically quantify the impact of this approach on the derivedutility. Simulation results are provided in Section VI and con-clusions are drawn in Section VII. For reader’s convenience,we summarize several notations frequently used in this paperin Table I.
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 103
Fig. 1. Group update process and related processes.
II. A NEW FRAMEWORK FOR RESOURCE RECIPROCATION
In P2P networks, peers would like to associate themselveswith other peers that possess multimedia content in which theyare interested. When peers agree to share content with eachother, they negotiate the amount of resources which they willprovide to each other. We model the resource reciprocationamong the peers as a resource reciprocation game. We beginwith a motivating example describing why the foresighteddecisions on the actions are important and how they can bebeneficial to peers.
A. A Simple Motivating Example for Myopic and ForesightedReciprocation
In this illustrative example, we consider a simple resource re-ciprocation game, where two self-interested peers interact witheach other to negotiate what resources they will provide to eachother. In this example, the peers’ actions are the divisions oftheir available resources (e.g., percentage of available uploadbandwidth) among their associated peers, and the states of thepeers are determined based on their received resources. Hence,one peer’s action can determine the other peer’s state and re-ward2. We assume that the resource reciprocation behaviors areperfectly known by both peers. Thus, both peers know the prob-abilities with which the other peer takes a certain action giventheir own actions. In this illustrative example, we assume thatthe available actions of peer 1 and peer 2 areand , respectively. Suppose that peer 1 and peer2 currently take their actions and , and hence, their cur-rent state is given by . For example,peer 1 in state can take action , while expecting that peer2 will take action with probability and ac-tion with probability . Hence, the expectedreward for peer 1 that takes in state becomes
(1)
Similarly, the expected reward for peer 1 that takesin state can be expressed as . Therefore, peer
1 makes decision on its action , such that it maximizes itsexpected reward from state , i.e.,
(2)
2The reward can be defined as the total received resources or the resultingutilities. More detailed definition of the reward in this paper will be discussedin Section II-B.
Fig. 2. Illustrative example for a resource reciprocation in � with four associ-ated peers at �. The resource reciprocation at � is denoted by �� � � � in thisexample.
Note that the decision of peer 1 given in (2) can be interpretedas myopic since it does not consider the future rewards by takingaction in state , but rather it focuses only on maximizingits immediate expected reward. Hence, this decision may not beoptimal if the future rewards are considered.
Let us now consider the foresighted decisions of the peerson their actions, which can maximize the cumulative rewardsincluding the immediate expected reward and the future (dis-counted) expected rewards. In this illustration, we assume thatthe peers make foresighted decisions considering the one stepfuture reward. Hence, a foresighted peer 1 needs to consider thefuture reward that can be derived in a next statewith the corresponding optimal action . Therefore,peer 1 in state determines its action considering the cumula-tive discounted expected reward, i.e.,
(3)
where is a constant referred to as the discount factor andis determined by . Note thatthe decisions in (2) are a subset of the decision in (3) (i.e., (3)is identical to (2) if ). Hence, if the decisions based on(2) and (3) are different, it can be inferred that an optimal actionthat maximizes the immediate expected reward cannot be theoptimal action that maximizes the cumulative rewards.
Summarizing, as shown in the above example, peers need totake foresighted decisions when engaging in resource recipro-cation games.
B. Resource Reciprocation Games in P2P Networks
Resource reciprocation games in P2P networks are playedby the peers interested in each other’s multimedia content.A resource reciprocation game is played in a group, wherea group consists of a peer and its associated peers. A groupcan be swarms in [6], [7], partnerships in [8], or neighbors in[9]. We denote the associated group members of a peer by
. Note that does not include peer but represents theassociated peers with peer . The peers in are indexed by
, i.e., . For a peer in group ,
104 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
Fig. 3. Resource reciprocation game played by peer � based on the MDP. (a) Determining optimal policy (b) Determining optimal actions.
peer also has its own group which includes peer . Due tothe dynamics introduced by peers joining, leaving, or switchingP2P networks, information about groups needs to be regularly(periodically) updated or it needs to be updated when groupmembers change [6], [7]. This is shown in Fig. 1.
The resource reciprocation game in a group is a stochasticgame [17], which consists of
• a finite set of players (i.e., peers): ;• for each peer , a nonempty set of actions: ;• for each peer , a preference relation (i.e., utility
function) of peer .To play the resource reciprocation game, a peer can deploy anMDP, as discussed as follows.
For a peer , an MDP is a tuple , whereis the state space, is the action space,
is a state transition probability function that maps the stateat time , corresponding action and the next
state at time to a real number between 0 and 1,and is a reward function, where is a rewardderived in state . The details are explained as follows.
1) State Space : A state of peer represents the set ofreceived resources from the peers in , expressed as
(4)
where denotes the provided resources (i.e., rate) by peerin and represents the available maximum upload band-width of peer 3. The total received rates of peer in is thus
. Due to the continuity of , the cardinality of theset defined in (4) can be infinite. Hence, we assume that peerhas a function for peer , which maps the received resource
into one of discrete values4, i.e.,. These values are referred to as state descrip-
tions in this paper. Hence, the state space can be considered tobe finite. The number of state descriptions will impact its perfor-mance and this will be discussed in Section IV. The state spaceof peer can be expressed as
(5)
3Note that the available maximum upload bandwidth � can be time-varying,because it depends on the physical maximum upload bandwidth �� � as wellas the available data (i.e., chunks) �� � that can be transmitted. Hence, �can be determined by � � ����� �� �. For example, in the initialstage of file sharing, � � � because peer � may not have enough chunksto transmit. However, � increases as peer � receives more chunks. While weassume that � � � in this paper, � � � can be explicitly addressedby selecting discount factors, which will be discussed in Section III-A.
4A continuous value of � can be discretized by peer � based on its quan-tization policy, as the bandwidth of each peer can be decomposed into several“units” of bandwidth by the client software, e.g., [21].
where denotes the th segment among segments thatcorresponds to the th state description of peer . For simplicity,we assume that each segment represents the uniformly dividedtotal bandwidth, i.e., if
for .2) Action Space : An action of peer is its resource allo-
cation to the peers in . Hence, the action space of peer incan be expressed as
(6)
where denotes the allocated resources to peer bypeer in . Hence, peer ’s action to peer becomes peer
’s received resources from peer , i.e., . To considera finite action space, we assume that the available resources(i.e., upload bandwidth) of peers are decomposed into “units”of bandwidth [21]. Thus, the actions represent the number ofallocated units of bandwidth to the associated peers in theirgroups. We define the resource reciprocation as a pair
comprising the peer ’s ac-tion, , and the corresponding modeled resource reciprocation
, which is determine as for all . Anillustrative resource reciprocation at is shown in Fig. 2.
Note that various scheduling schemes can be used in con-junction with the resource allocation (i.e., actions) deployedby peers in order to consider the different priorities of the dif-ferent data segments (chunks). We assume that the chunks thathave higher quality impact on average multimedia quality havehigher priority and are transmitted first when each peer takesits actions. However, other scheduling algorithms, such as therarest first [6], [7] method for general file sharing applicationsor several scheduling methods proposed in e.g., [8] for multi-media streaming applications, can also be adopted. It is impor-tant to note that appropriate scheduling schemes need to be de-ployed in conjunction with our proposed resource reciprocationstrategies, depending on the objectives of multimedia applica-tions (e.g., maximizing achieved quality, minimizing the play-back delay etc.). However, the selection of scheduling strategieswas already investigated in several existing papers and it is notthe focus of this paper, as existing scheduling solutions can beeasily incorporated into the proposed framework.
3) State Transition Probability : A state transitionprobability represents the probability that by taking an action,a peer will transit into a new state. We assume that the statetransition probability depends on the current state and the action
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 105
taken by the peer, as peers decide their actions based on theircurrently received resources (i.e., state). Hence, given a state
at time , an action of peer can lead toanother state at with probability
. Hence, for a state of peerin , the probability that an action leads to a state transitionfrom to can be expressed as
(7)
where . In this paper, the statetransition probabilities of peers are identified based on the pastresource reciprocation history. The details of how to build thestate transition probability functions will be discussed in Sec-tion V.
4) Reward : The utility of peer downloading its desiredmultimedia content from its peers at rate can be defined as
(8)
where is the minimum resource that corresponds to theminimum required utility and is a constant representing thepreference of peer for the content. The minimum resources(rates) are explicitly considered in the utility definition in (8) inorder to provide support the quality of service (QoS) requiredby delay-sensitive and bandwidth-intensive multimedia appli-cations [22]. The derived quality with downloading rate
can be represented by a widely used quality measure, peaksignal-to-noise ratio (PSNR), which is a non-decreasing func-tion of for multimedia applications [22]. Thus, we considerthat the reward for a peer in state is the total receivedresources in . Since the state of a peer is defined as the quan-tized received resources from the peers in , the reward in eachstate can be represented by a random variable, i.e.,
(9)
where is a random variable that represents the receivedresource in . Thus, the resulting utility of peer in state is
.
5) Reciprocation Policy : The solution to the MDP is rep-resented by peer ’s optimal policy , which is a mapping fromthe states to optimal actions. The optimal policy can be obtainedusing well-known methods such as value iteration and policy it-eration [18]. Hence, peer can decide its actions based on theoptimal policy , i.e., for all .
Hence, the resource reciprocation games in the P2P net-works that consist of total peers can be described by atuple , where is the set of peers, is theset of state profiles of all peers, i.e., ,and denotes the set of action profiles.
is a state transition probability functionthat maps from the current state profile , correspondingjoint action and the next state profile , into a realnumber between 0 and 1, and is a rewardfunction that maps an action profile and a state profile
into the derived reward. Thus, in this paper, our focus is
Fig. 4. Illustration of resource reciprocation based on peers’ attitudes. (a) Re-source reciprocation models (b) Examples of reciprocation matrices (four ac-tions and four state descriptions).
on the resource reciprocation game in a group, as this resourcegame can be extended to the resource reciprocation game in aP2P network. The resource reciprocation game, which includesthe processes of determining an optimal policy and optimalactions, played by peer based on the MDP is shown in Fig. 3.
We will discuss how the optimal policies can be determinedbased on different types of peers in the next section.
III. CATEGORIES OF PEERS IN P2P NETWORKS
The types of peers in the considered P2P networks can becharacterized based on different criteria. In this paper, we cate-gorize the peers as
• myopic or foresighted: depending on their objective utili-ties; and
• pessimistic, neutral, or optimistic: depending on their re-source reciprocation attitudes.
These different types of peers affect how the resource recipro-cation game is being played, thereby leading to various recipro-cation policies . More specifically, the decisions of myopic orforesighted peers directly influence their action selection. More-over, various resource reciprocation attitudes lead to differentstate transition probability functions, which eventually impactstheir actions and the resulting reciprocation policies.
A. Peer Types Depending on Their Adopted Utilities
In this paper, we consider two types of peers, myopic andforesighted peers, based on the utilities which they adopt. My-opic peers only focus on maximizing the immediate expectedreward. Hence, the objective of a myopic peer in state
106 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
at time is to maximize its immediate expectedreward, i.e.,
(10)
Hence, the peer takes its action (i.e., upload bandwidth allo-cation) such that the action maximizes the immediate expectedreward , i.e.,
(11)
As shown in (10), the immediate expected reward does not con-sider the future rewards.
Unlike the myopic peers, the foresighted peers take their ac-tions considering the immediate expected reward as well as thefuture rewards. Since future rewards are generally consideredto be worth less than the rewards received now [23], the fore-sighted peers try to maximize a cumulative discounted expectedreward. The cumulative discounted expected reward for a fore-sighted peer in state at timegiven a discount factor can be expressed as
(12)
More precisely, the cumulative discounted expected rewardin (12) can be rewritten as (13), shown at the
bottom of the page. Hence, peer can determine a set of actionsthat maximizes for every state in , which leadsto an optimal policy . The optimal policy thus mapseach state into a corresponding optimal action , i.e.,
for all .By comparing (10) and (13), we can observe that the myopic
decisions are a special case of the foresighted decisions when. Note that the discount factor in the considered P2P
network can alternatively represent the belief of the peer aboutthe validity of the expected future rewards, since the state tran-sition probability can be affected by system dynamics such asother peers’ joining, switching, or leaving groups. Hence, forexample, if the P2P network is in a transient regime, a small dis-count factor is desirable. However, a large discount factor can beused if the P2P network is in stationary regime [24]. Thus, weassume that the value of the discount factor can be determinedby the peers using information based on their past experiences,reputation of their associated peers [25], etc.
B. Peer Types Based on Their Attitudes
Peers in the considered P2P networks can also be character-ized based on their attitudes towards the resource reciprocation,which are pessimistic, neutral, or optimistic [19]. Letbe a resource reciprocation between peer and peer , i.e., apair of peer ’s action to peer and the corresponding peer
’s action that is mapped into . A peer is neutral if itpresumes that the resource reciprocation changes linearly5 de-pending on its actions . A peer is pessimistic if it presumesthat the resource reciprocation decreases fast for andincreases slow for . On the other hand, an optimisticpeer presumes that the resource reciprocation decreases slowfor and increases fast for . Illustrative exam-ples of resource reciprocation shapes that correspond to peers’different attitudes are shown in Fig. 4. In this paper, we considerthese resource reciprocation profiles, which will be referred toas reciprocation models. Note that these reciprocation modelscan be extended by considering different degrees of pessimismor optimism, which will be presented in Section V-B.
These types of peers discussed above obviously affect theirresource reciprocation strategies. In the following sections, wediscuss how the peers’ attitudes can impact the way in whichpeers model the other peers’ resource reciprocation behavior,and investigate several resulting properties that can be drawnfor the various peer types.
IV. ANALYSIS OF PEERS’ INTERACTIONSBASED ON THEIR ATTITUDES
In this section, we investigate several properties of the in-teractions among peers that can have different memory sizesfor maintaining their resource reciprocation history or differentnumber of state descriptions. Moreover, we also study how dif-ferent types of peers such as myopic/foresighted and their re-source reciprocation models can impact their resource recipro-cation. We analyze several interactions among the peers underparticular conditions that allow us to capture how the peer’scharacteristics can influence their interactions.
A. Impact of History on Resource Reciprocation
In this section, we first investigate the impact of the memorysize for the history of resource reciprocation and the recipro-cation models of peers. We assume that a peer has its ownunits of memory , where denotes the index of eachunit of memory, and one unit of memory is required to store aresource reciprocation, i.e., . Weconsider the interactions between a myopic peer (i.e., it fo-cuses on maximizing its immediate expected reward) that canonly recall and process (i.e., it identifies state transitionprobabilities based on its last resource reciprocation), and its
5Several levels of neutral attitudes can be represented by using different slopes[e.g., � in (20)].
(13)
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 107
associated self-interested peers aiming at maximizing their util-ities, in order to quantify how these constraints can affect thepeers’ decisions and the resulting utilities.
1) Resource Reciprocation of a Myopic and Pessimistic Peerfor Self-Interested Peers: We first consider the resource recip-rocation strategy that a myopic and pessimistic peer who canrecall and process only will adopt, while interacting withits associated peers. We assume that the associated peers canidentify the myopic and pessimistic peer and its reciprocationcharacteristics.
Proposition 1: When a myopic and pessimistic peer thatcan recall and process only interacts with self-interestedpeers aiming at maximizing their utilities in , peer will re-ceive for download its minimum required resource fromeach of its associated peers in .
Proof: Letbe a recent re-
source reciprocation for peer , where . Asshown in Fig. 4, a pessimistic peer presumes that
(14)
where denotes the actions that peer can take in the nextresource reciprocation. Given the conditions in (14), peer al-locates its available resources to maximize its reward. If peerreduces its current allocated resources to in thenext resource reciprocation interaction, which leads to decreaseof peer ’s reward, peer can adjust its actions in response to thechange of peer ’s resource allocation. Peer can compensatethe reward reduction only if there exists a peerwith the resource reciprocation such that
(15)
where . However, peer cannot find such apeer which satisfies (15), since this contradicts (14). There-fore, if peers in identify peer ’s reciprocation characteristics,they will select actions which provide the minimum required re-sources, i.e., for .
As a result of Proposition 1, the total received download ratesthat peer can achieve in is at most . A similarconclusion can be drawn from the interactions between a my-opic and optimistic peer and its associated self-interested peers.
2) Resource Reciprocation of a Myopic and Optimistic Peerfor Self-Interested Peers: Let us now consider the resource re-ciprocation strategy that a myopic and optimistic peer only witha recent resource reciprocation will take.
Proposition 2: When a myopic and optimistic peer thatcan recall and process only interacts with self-interestedpeers aiming at maximizing their utilities in , peer will re-ceive for download its minimum required resource fromeach of its associated peers in .
Proof: Letbe a recent re-
source reciprocation for peer , where .The current reward is . As shown in Fig. 4, anoptimistic peer presumes that
(16)
for peer . Based on and the conditionin (16), peer can take its next action such that it maximizesthe immediate expected reward, i.e.,
(17)
where is the resulting state for action .Based on the condition in (16), it can be easily shown that asolution to the optimization problem in (17) is given by
(18)
where is a positive constant satisfyingand a peer is selected by
(19)
Equation (18) and (19) imply that peer selects peer that cur-rently provides it with the most resources. Then, the peer al-locates the minimum required resource to peer . Hence,the associated peers in prefer not to be selected by peer ,which will lead to the associated peers selecting their actions
for all .From the above proposition, we can conclude that the total
received download rates that peer can achieve in are at most.
Based on the above two propositions (i.e., Proposition 1 andProposition 2), it can be observed that myopic and pessimistic/optimistic peers, which base their resource reciprocation onlyon the observed recent reciprocation, will receive only the min-imum resource reciprocation from their associated self-inter-ested peers, since there are no utility benefits for these peersto adopt other reciprocation policies. These results can be ex-plained based on the peer’s pessimistic or optimistic attitudesfor the resource reciprocation. Since these attitudes provide thepeer an overly simplified perspective on resource reciprocation(i.e., minimum/unchanged or unchanged/maximum reciproca-tion, respectively), the peer cannot effectively adopt its policies,which leads to inefficient response to the resource reciprocationof self-interested peers.
3) Resource Reciprocation of a Myopic and Neutral Peer forSelf-Interested Peers: We now consider the resource reciproca-tion among a myopic and neutral peer and its associated self-in-terested peers. In this analysis, we show that the best strategythat a myopic and neutral peer that can recall and processonly can adopt is the tit-for-tat (TFT) strategy. The TFTstrategy is currently deployed in BitTorrent system as a peerselection strategy [6], [7]. Specifically, a peer with the TFTstrategy in BitTorrent systems selects a fixed number of peersthat provides the highest upload rates (i.e., the most coopera-tive), and equally divides and allocates its resources to the se-lected peers.
Proposition 3: When a myopic and neutral peer that can re-call and process only interacts with self-interested peersaiming at maximizing their utilities in , the strategy that thepeer adopts is the TFT strategy.
108 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
TABLE IICOMPARISON OF RESOURCE RECIPROCATION STRATEGIES
Proof: Letbe a recent re-
source reciprocation for peer , where . Fig. 4shows that a neutral peer given presumesthat
(20)
where for . Therefore, to maximize peer’s rewards, it allocates the minimum required resources to
peer (i.e., ) and the residual availableresources to peer (i.e.,
), where the peer is selected by
(21)
The peer selection rule in (21) is the TFT strategy, as peerselects the peer with the highest .
Hence, the TFT strategy deployed in BitTorrent system is asimple extension (i.e., it allows a peer to select multiple peersrather than one) of the strategy that a myopic and neutral peercan take.
The conclusions from the propositions presented in thissection are summarized in Table II (Note that the comparisonof (a)–(c) in Table II will be discussed in Section VI-C). Thesepropositions show that a peer who myopically determines itsactions using a single reciprocation model and a single resourcereciprocation history (i.e., ) cannot adopt an efficientreciprocation policy. Although the TFT strategy enables aneutral peer to achieve higher download rates than a pessimisticor optimistic peer, actions based on this strategy result inlower expected rewards than myopic or foresighted actionsdetermined considering well-estimated associated peers’ be-haviors, as presented in Section VI-C. The difference betweenthese approaches can be easily understood by considering thatmethods such as TFT are based on feedback information ratherthan predictive information based on peer’s models. This showsthe importance of accurately modeling the associated peers’behavior. Hence, a peer should identify its associated peers’behavior (i.e., the state transition probabilities) using multiplereciprocation models and the history of several resource recip-rocation. How to determine the state transition probabilitiesbased on multiple reciprocation models and resource recipro-cation will be discussed in Section V.
In the subsequent section, we determine the impact that dif-ferent numbers of deployed state descriptions have on the policyselected by the peers, and hence, its rewards.
B. Impact of Number of State Descriptions on Rewards
As discussed previously, a peer’s received resources from theassociated peers are characterized by a state, and each state isrepresented by a set of finite state descriptions. Since a providedrate from peer is mapped into by peerusing finite state descriptions, there exists a quantization error
. Hence, there is an error between the expected
Fig. 5. Variances of the expected rewards given eight, four, and two state de-scriptions.
rewards computed based on the state descriptions and the actualrewards. We use the variance of the expected rewards to quan-tify how accurately the computed expected rewards representthe actual rewards. Moreover, we will show that the varianceof the expected rewards will decrease as finer state descriptions(i.e., more state descriptions) are used, providing more accuratemodeling for the resource reciprocation of the associated peers.Hence, this is consistent to minimizing the mean square error(MMSE) between the actual rewards and the expected rewardscomputed based on the state descriptions.
To compare the variances induced by different numberof state descriptions, we assume that an optimal policygiven an state transition probability matrix isknown to peer . As will be shown, the expected rewards
of peer from peer based onthe policy can be obtained by (28). Since no prior informationabout the action of peer is available, we assume thatin (28) is a uniform random variable, i.e., the mean and thevariance of for (i.e., )are given by and
.The simulation results in Fig. 5 show several illustrative ex-
amples for the variances of the expected rewards given eight,four, and two state descriptions. These results clearly show thathaving a larger number of state descriptions can decrease thevariance of the expected rewards regardless of the value of dis-count factors, thereby leading to a more accurate computationof the expected rewards.
V. DETERMINING THE STATE TRANSITION PROBABILITIES
A. State Transition Probability Computation Based onEmpirical Frequency
A peer can identify its state transition probabilities basedon the frequency of the reciprocation. For this, we consider atable that stores the history of resource reciprocation for peer
given actions of peer . An element of thetable denotes the number of state transitions fromto , given an action . Hence, the state transition
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 109
probability based on the empiricalfrequency can be expressed as
(22)
Algorithm 1 shows the steps for determining the state transitionprobabilities based on the empirical frequency.
A disadvantage of this algorithm is that it may require a con-siderable amount of observations of the resource reciprocationover time to accurately identify the state transition probabilities.To reduce the number of required observations, we propose analternative algorithm that can efficiently identify the state tran-sition probabilities by modeling the peers’ attitudes.
Algorithm 1: Determining State Transition Probabilitybased on Empirical Frequency
Set: initial state , initialize withfor all , for all
, and for all .1: Observe resource reciprocation given an action ;
2: State Mapping;, where for all
3: Update for all ;if and
4: Compute using and (7) and (22)
B. State Transition Probabilities Based on ReciprocationModels
The resource reciprocation models of peers are discussed inSection III. A set of the state transition probability functionsthat correspond to the resource reciprocation models is calledreciprocation matrix. The set of available reciprocation ma-trices of peer in for peer is denoted by
, where is a matrix withits element as shown inFig. 4. Hence, a reciprocation matrix fora pessimistic peer taking action in (given its resourcereciprocation ) shown in Fig. 4 can be expressed by(23), shown at the bottom of the previous page, where
is the number of state descriptions be-tween and , and denotes the available actions that
can be taken in the next state. represents the degree of pes-simism for the resource reciprocation. Hence, .
Similarly, a reciprocation matrix of an optimistic peerin for peer shown in Fig. 4 can be represented
by (24), shown at the bottom of the previous page, whereis the number of state descrip-
tions between and . represents the degree of opti-mism for the resource reciprocation. Hence, .
The reciprocation matrix for a neutral peer can also be ex-pressed as follows. A neutral peer presumes that an action
will lead to linear changes in resource reciprocationfrom the current resource reciprocation . Hence, thereciprocation matrix of a neutral peer can be expressed as
(25)
where denotes the slope determined based on thecurrent resource reciprocation. In the following subsection, wepropose an algorithm that uses the discussed reciprocation ma-trices to efficiently identify the state transition probability func-tions.
C. Building State Transition Probability Functions Based onReciprocation Matrices
We assume that a peer has a predetermined initial actionthat is used for initializing the reciproca-
tion matrices, i.e., a peer has a predetermined actionfor peer and the resulting . Based on the initial resourcereciprocation between peer and peer , thereciprocation matrices of peer can be initialized based on (23),(24), and (25). Note that peer can have several reciprocationmatrices, since it can select several levels of pessimism (or op-timism) for resource reciprocation based on and . Thenext step is to determine and adjust the weights for each recip-rocation matrices, such that the weighted sum of reciprocationmatrices represents a set of state transition probability functions.
Let be the setof reciprocation matrices that are initialized by peer withthe initial resource reciprocation . The weightsof peer for the reciprocation matrices are denoted by
for peer . Wealso define as the set ofnumber of hits, where the resource reciprocation between peer
and peer are matched to non-zero elements in the reciproca-tion matrices. Specifically, if a resource reciprocationis matched up to a non-zero element in , then
(23)
(24)
110 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
Fig. 6. Block diagram for updating the weights of the reciprocation matrices.
the number of hits increases, i.e., .is used to update the weights of reciprocation matrices
for peer , i.e.,
(26)
can be initialized by . Hence, theinitial weights are , and thus, theinitial state transition probability matrix for peer is given by
. This up-date process is depicted in Fig. 6 and the detailed algorithm ispresented in Algorithm 2.
Algorithm 2: Algorithm for Updating Peer ’s Weights ofReciprocation Matrices for Peer
Set: initial resource reciprocation , and , adesired maximum reward deviation .
1: Initialize withbased on (23), (24), and (25)
2: Initialize
3: repeat4: Take action , observe reciprocation , and
determine5: if does not exist6: Initialize with
based on (23), (24), and (25)7: Initialize
8: else9: for all such that do//Update
10: if then11:
12: Update using (26)13:14: until // is a distance metric.
See Proposition 4.
Finally, based on the identified weights, can beobtained by
(27)
In the next section, we investigate how the error in estimatingthe state transition probabilities can affect the peers’ decisionsand the resulting utilities.
D. Impact of Estimation Error in State Transition ProbabilityMatrices on Rewards
We study the impact of the state transition probability estima-tion error on the cumulative discounted expected rewards. As anillustration, we consider a case where peer and peer are in agroup and reciprocate their resources.
Suppose that is an state transition probabilitymatrix of peer for peer given peer ’s optimal actions ,which are determined by the optimal policy , i.e.,
for . Each elementdenotes the transition probability from to
given the optimal action , and its th row vector is denotedby . We assume that is an irreducible matrix since differentactions of a peer can induce different actions from its associ-ated peers [26]. Therefore, there exists a steady state distribu-tion , i.e., , where . Weuse the -norm to represent the distance between twovectors and , denotedby . The -norm of a vector is defined by
.
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 111
Proposition 4: For the true and estimated state transi-tion probability matrices and , let and be thecumulative discounted expected rewards of a peer froma peer based on an optimal policy and , respec-tively. Then, given a discount factor , the discrepancybetween and from initial state is bounded by
.Proof: The discounted expected rewards
of a peer from a peer basedon an optimal policy for can be computed by
......
... (28)
A compact expression for (28) is given by
(29)
and the solution to (29) is expressed as
(30)
Without loss of generality, we consider a cumulative discountedexpected reward from , i.e., . Using the expression in(30), can be expressed as
(31)
Since , (31) can be approximated by
(32)
Similarly, can be computed based on an optimal policyfor as
(33)
Using the approximations as in (32) and (33), the discrepancybetween the two cumulative discounted expected rewards areexpressed as
where . Since is a non-nega-tive constant, the discrepancy between the two cumula-tive discounted expected rewards from is bounded by
.Note that since
, the error of cu-mulative discounted expected rewards is bounded by both thedistances of state transition probabilities and the stationarydistributions. Hence, we can conclude that the discrepancybetween the cumulative discounted expected rewards can beaffected by the estimation error in state transition probabilitymatrix and the stationary distribution, as well as each peer’sdiscount factor. Since is
Fig. 7. Average discrepancy between true and approximated cumulative dis-counted expected rewards: 2-norm �� � �� is used.
dominated by the stationary distribution error. As ,however, it is dominated by the error in state transition prob-abilities. Hence, a peer can adjust the impact of the estimatedstate transition probability error on the cumulative discountedexpected reward by changing . We remark that the approx-imation of given by (32) is very accurate as shownin Fig. 7. Fig. 7 depicts the average discrepancy between
and its approximation for different number of states,i.e., .These illustrative examples show that the discrepancy increasesas approaches 0.5, while the discrepancy decreases asapproaches 0 or 1. These observations are reasonable sincethe approximation becomes more accurate as either ordominates.
VI. SIMULATION RESULTS
A. Comparison of Various Approaches for Identifying theState Transition Probabilities
We discuss two algorithms, one is based on the empiricalfrequency and the other one is based on the reciprocationmodels, to identify the state transition probability matrices inSection V. As discussed in Proposition 4, is proposed toquantify the maximum discrepancy between the discountedexpected rewards from a state, which is induced by the trueand estimated state transition probability error. To illustratethese tradeoffs between the efficiency and the accuracy ofthe two proposed approaches, we deploy them to identify thetrue state transition probability. For the reciprocation modelbased approach, three reciprocation models that represent thepessimistic, optimistic, and neutral behaviors are used. In ,we assume that is normalized to 1, and the 2-norm (i.e.,
) is used. The results are shown in Fig. 8.Since the observations are generated based on a stationary
state transition probability matrix, if there are enough observa-tions of resource reciprocation and the empirical frequency isdeployed to identify the state transition probability functions,
112 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
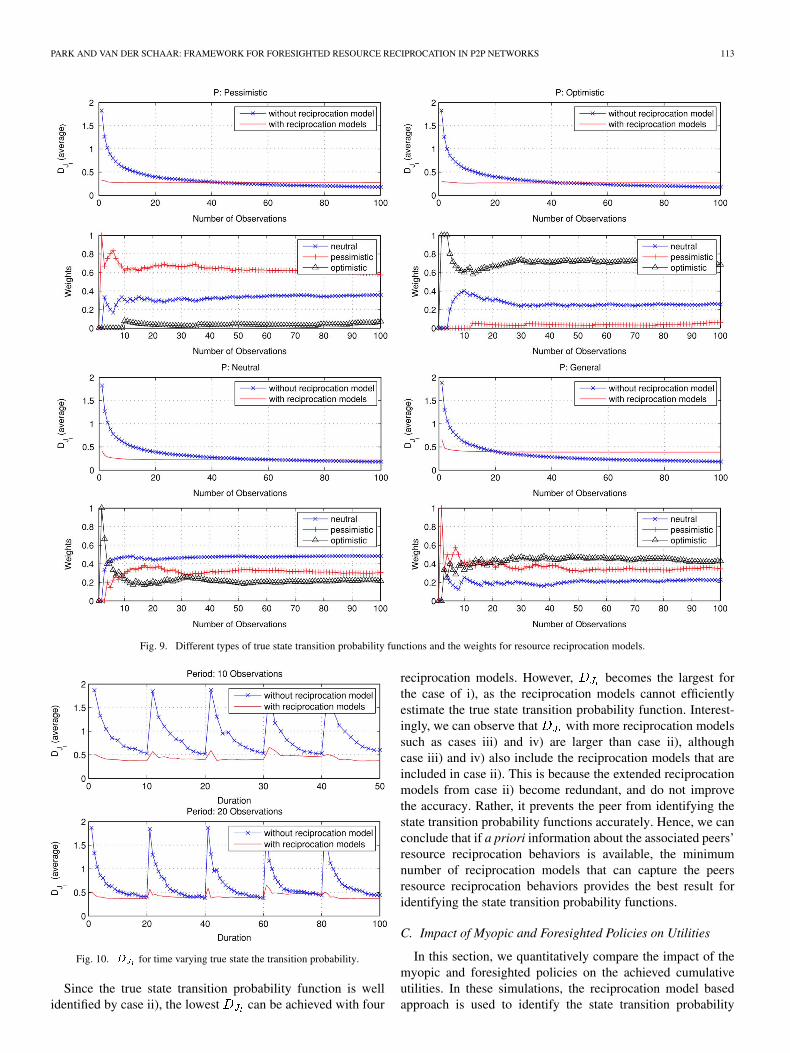
the state transition probability functions can be well-identified,i.e., the more observations, the higher accuracy. However, itmay require many peers’ interactions to obtain accurate statetransition probability functions. In contrast, the reciprocationmodel based approach can efficiently identify the state transitionprobability functions with fewer observations than the empiricalfrequency based approach. However, unlike the empirical fre-quency based approach, the improvement gained for more ob-servations diminishes rapidly (before reaching the best perfor-mance of the empirical frequency based approach), as the es-timation relies on predetermined reciprocation models. There-fore, it is important to decide an appropriate approach consid-ering these tradeoffs. The detailed weight update processes forthe reciprocation model based approach are shown in Fig. 9.
In order to show the weight update process, predeterminedtrue state transition probability functions for the resource recip-rocation models (i.e., neutral, pessimistic, optimistic, and gen-eral) are used in these simulations. As shown in Fig. 9, theproposed algorithm based on the reciprocation models effec-tively computes the weights with fewer observations, therebyproviding a faster convergence. This convergence property be-comes important when the state transition probabilities varyover time. Illustrative simulation results are shown in Fig. 10.
Fig. 10 shows the obtained by two approaches. To studythe effectiveness of the proposed algorithm in a dynamic envi-ronment, different state transition probability matrices of a peerare deployed every 10- or 20-resource reciprocation. As dis-cussed, the proposed reciprocation model based approach pro-vides a faster convergence, thereby enabling peers to efficientlycapture the changes of the state transition probability. There-fore, the proposed approach can cope with a dynamic environ-ment, thereby making it more suitable than the empirical fre-quency based approach for a peer.
B. Quantifying the Impact of the Number of ReciprocationModels
As discussed in Section V, various reciprocation models canbe deployed, which enable peers to identify the state transitionprobabilities more accurately. To study the impact of the numberof reciprocation models on the accuracy of the state transitionprobabilities, we assume that a true state transition probabilityof a peer is stationary and randomly generated. The achieved
when different number of reciprocation models are usedare shown in Fig. 11(a).
In these simulation results, the number of reciprocationmodels is increased by symmetrically extending the pessimisticand optimistic reciprocation models. For the case where tworeciprocation models are used, only the neutral and pessimisticresource models are used as an illustration. As expected, ingeneral, the more resource reciprocation models are deployed,the higher accuracy for identifying the state transition proba-bility matrices can be achieved. However, we can observe thatthe improvement decreases as the number of deployed re-ciprocation models increases. Since the decreases as morereciprocation models are deployed, the reward discrepancy dueto the estimation error is reduced as shown in the Proposition 4.
Fig. 8. (Averaged)� for estimated state transition probability matrices with/without reciprocation models.
Moreover, if the information about the relationship betweenthe number of deployed reciprocation models and the resulting
is available for peers, they can select the number of recipro-cation models and can expect the number of required observa-tions for the resource reciprocation. As discussed in Proposition4, the reward deviation is bounded by the , which can alsobe bounded by a peer’s desired maximum reward deviation ,i.e.,
(34)
For instance, in Fig. 11(a), if a desired maximum reward devia-tion is 0.15, i.e., , a peer can select 3, 5, 7, or 9 numberof reciprocation models, expecting 14, 7, 4, or 2 observationsof resource reciprocation, respectively, to achieve , as shownin Table III. Hence, peers can select the appropriate number ofreciprocation models, by explicitly considering their tolerabledurations for resource reciprocation and their desired maximumreward deviation.
If a priori information about the associated peers’ resourcereciprocation behavior is available (e.g., using reputation [25]),deploying the minimum number of reciprocation models thatclosely approximate their behaviors will result in the best per-formance to identify the state transition probabilities. As an il-lustration, we consider four cases where a different number ofreciprocation models are used: i) two models for the pessimisticand optimistic reciprocation; and these models are extended toii) four, iii) six, and iv) eight reciprocation models by consid-ering different degrees of pessimism/optimism. We assume thatthe true state transition probability of an associated peer is wellmatched by a set of reciprocation models included in the casesof ii), i.e., a linear combination of the deployed reciprocationmodels in ii) can lead to the true state transition probability.Note that the cases of iii) and iv) can also include a set of re-ciprocation models that approximates the associated peer’s re-source reciprocation as they are extended from the case of ii).The simulation results are shown in Fig. 11(b).
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 113
Fig. 9. Different types of true state transition probability functions and the weights for resource reciprocation models.
Fig. 10. � for time varying true state the transition probability.
Since the true state transition probability function is wellidentified by case ii), the lowest can be achieved with four
reciprocation models. However, becomes the largest forthe case of i), as the reciprocation models cannot efficientlyestimate the true state transition probability function. Interest-ingly, we can observe that with more reciprocation modelssuch as cases iii) and iv) are larger than case ii), althoughcase iii) and iv) also include the reciprocation models that areincluded in case ii). This is because the extended reciprocationmodels from case ii) become redundant, and do not improvethe accuracy. Rather, it prevents the peer from identifying thestate transition probability functions accurately. Hence, we canconclude that if a priori information about the associated peers’resource reciprocation behaviors is available, the minimumnumber of reciprocation models that can capture the peersresource reciprocation behaviors provides the best result foridentifying the state transition probability functions.
C. Impact of Myopic and Foresighted Policies on Utilities
In this section, we quantitatively compare the impact of themyopic and foresighted policies on the achieved cumulativeutilities. In these simulations, the reciprocation model basedapproach is used to identify the state transition probability
114 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
Fig. 11. � for different number of reciprocation models: (a) randomly generated true state transition probability function. � � ����. (b) Predetermined truestate transition probability function.
TABLE IIINUMBER OF RECIPROCATION MODELS AND REQUIRED
RESOURCE RECIPROCATION FOR � � ����
functions. The myopic policies are made based on (11) and theforesighted policies are made based on maximizing in(12) with the discounted factor as an illustration. Thesolution to the MDP is implemented based on a well-knownpolicy iteration method [18], which performs policy improve-ment and policy evaluation iteratively. In addition, as anillustration, we compare the TFT strategy implemented inBitTorrent-like system supporting two leechers simultaneously.The simulation results are shown in Fig. 12.
Fig. 12 shows the immediate expected rewards and cumu-lative discounted expected rewards of a peer obtained basedon the actions determined by the myopic (including TFT) andforesighted policies. A state of peer isrepresented by four state descriptions of three associated peers,i.e., , whereif , for . The state indexes indicate the ini-tial state of peer , where it determines its optimal policy (andthe corresponding actions). The size of the state space is 64 inthis case. Each state is enumerated, and then, represented bystate index from 1 to 64. The y-axis represents the normalized(immediate or cumulative discounted expected) rewards. We as-sume that each state description is represented by a number, i.e.,
for , and the expected reward in each state isproportional to the numbers that corresponds to the states, i.e.,
for a constant for peer . Hence, theexpected rewards in a state is representedby . This can beeasily extended to represent actual rewards by assigning actualreceived resources to each state.
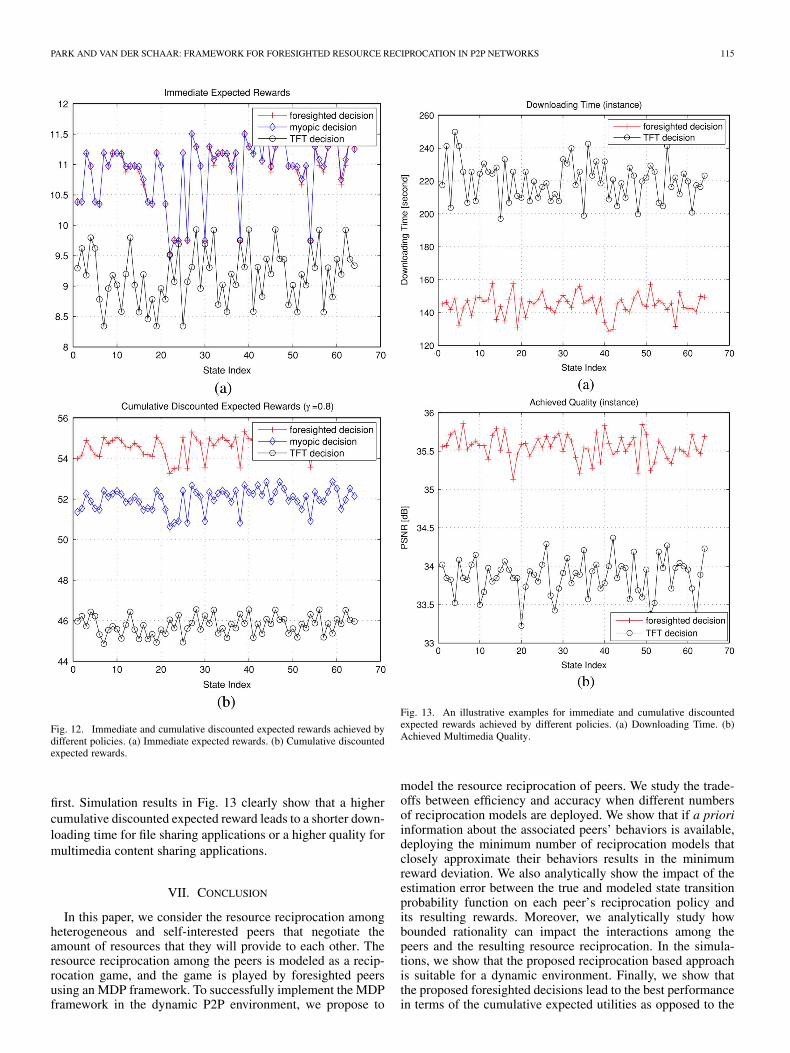
We can observe that the obtained utilities based on the TFTpolicy are worse than those based on the myopic or foresightedpolicies, since the actions determined by the TFT policy donot consider the expected utilities. Moreover, the constraints offixed concurrent allowable uploads to the leechers can preventthe decision process from selecting better actions. The proposedapproaches can enhance the resource reciprocation decisions ofTFT strategy, which is currently implemented in current BitTor-rent systems. By deploying the proposed approaches, peers canefficiently model their associated peers’ behavior (in e.g., everyrechoke period [6], [7]), and thus, the peers can allocate theirresources to their associated peers based on their levels of coop-eration. Hence, peers in the current BitTorrent systems can havemultiple actions, rather than two simple actions (i.e., allowingor rejecting downloads), thereby efficiently adjusting their re-source reciprocation and improving their performance.
As discussed previously, the myopic decisions are madebased on (11), which maximize the immediate expected re-wards. Hence, we can verify that the immediate expectedrewards obtained by the actions of myopic policy are alwayshigher (or equal) than the other policies in Fig. 12(a). However,as shown in Fig. 12(b), the foresighted decisions are made basedon (12), which maximize the cumulative expected discountedrewards (i.e., ). Therefore, the foresighted policy enablesthe peers to determine their decisions that lead to the highestcumulative discounted expected rewards.
A higher cumulative discounted expected reward can leadto a shorter downloading time or a higher multimedia quality.Fig. 13 shows illustrative examples of downloading time andachieved multimedia quality based on the proposed foresightedpolicy and the TFT strategy. In Fig. 13(a) and (b), we assumethat a peer is downloading a general file with size of 5 Mbytes,and Foreman sequence (CIF, 30 frames/s) from its associatedpeers, respectively. We assume that the associated peers have250Kbps maximum available upload bandwidth and haveenough chunks to transmit. Moreover, the associated peersuse five state descriptions. For Fig. 13(b), we assume that apeer downloads the packets that have higher quality impact
PARK AND VAN DER SCHAAR: FRAMEWORK FOR FORESIGHTED RESOURCE RECIPROCATION IN P2P NETWORKS 115
first. Simulation results in Fig. 13 clearly show that a highercumulative discounted expected reward leads to a shorter down-loading time for file sharing applications or a higher quality formultimedia content sharing applications.
VII. CONCLUSION
In this paper, we consider the resource reciprocation amongheterogeneous and self-interested peers that negotiate theamount of resources that they will provide to each other. Theresource reciprocation among the peers is modeled as a recip-rocation game, and the game is played by foresighted peersusing an MDP framework. To successfully implement the MDPframework in the dynamic P2P environment, we propose to
Fig. 13. An illustrative examples for immediate and cumulative discountedexpected rewards achieved by different policies. (a) Downloading Time. (b)Achieved Multimedia Quality.
model the resource reciprocation of peers. We study the trade-offs between efficiency and accuracy when different numbersof reciprocation models are deployed. We show that if a prioriinformation about the associated peers’ behaviors is available,deploying the minimum number of reciprocation models thatclosely approximate their behaviors results in the minimumreward deviation. We also analytically show the impact of theestimation error between the true and modeled state transitionprobability function on each peer’s reciprocation policy andits resulting rewards. Moreover, we analytically study howbounded rationality can impact the interactions among thepeers and the resulting resource reciprocation. In the simula-tions, we show that the proposed reciprocation based approachis suitable for a dynamic environment. Finally, we show thatthe proposed foresighted decisions lead to the best performancein terms of the cumulative expected utilities as opposed to the
116 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 11, NO. 1, JANUARY 2009
currently deployed strategy (i.e., TFT) in BitTorrent system orthe myopic decisions.
[4] S. Androutsellis-Theotokis and D. Spinellis, “A survey of peer-to-peercontent distribution technologies,” ACM Comp. Surv., vol. 36, no. 4,pp. 335–371, Dec. 2004.
[5] J. Liu, S. G. Rao, B. Li, and H. Zhang, “Opportunities and challenges ofpeer-to-peer internet video broadcast,” in Proc. IEEE Special Issue onRecent Advances in Distributed Multimedia Communications, 2007.
[6] B. Cohen, “Incentives build robustnessin bittorrent,” in Proc. P2P Eco-nomics Workshop, Berkerly, CA, 2003.
[7] A. Legout, N. Liogkas, E. Kohler, and L. Zhang, “Clustering andsharing incentives in bittorrent systems,” SIGMETRICS Perform. Eval.Rev., vol. 35, no. 1, pp. 301–312, 2007.
[8] X. Zhang, J. Liu, B. Li, and T. S. P. Yum, “CoolStreaming/DONet:A data-driven overlay network for efficient live media streaming,” inProc. INFOCOM’05, 2005.
[9] V. Pai, K. Kumar, K. Tamilmani, V. Sambamurthy, and A. E. Mohr,“Chainsaw: Eliminating trees from overlay multicast,” in Proc. 4th Int.Workshop on Peer-to-Peer Systems (IPTPS), Feb. 2005.
[10] Z. Xiang, Q. Zhang, W. Zhu, Z. Zhang, and Y.-Q. Zhang, “Peer-to-peerbased multimedia distribution service,” IEEE Trans. Multimedia, vol.6, no. 2, pp. 343–355, Apr. 2004.
[11] X. Jiang, Y. Dong, D. Xu, and B. Bhargava, “GnuStream: A P2P mediastreaming system prototype,” in Proc. of 4th Int. Conf. Multimedia andExpo., Jul. 2003.
[12] Y. Cui, B. Li, and K. Nahrstedt, “oStream: Asynchronous streamingmulticast in application-layer overlay networks,” IEEE J. Sel. AreasCommun., vol. 22, no. 1, pp. 91–106, Jan. 2004.
[13] B. Yu and M. Singh, “Incentive mechanisms for agent-based peer-to-peer systems,” in Proc. 2nd Int. Joint Conf. Autonomous Agents andMultiagent Systems, 2003.
[14] J. Shneidman and D. C. Parkes, “Rationality and self-interest in peerto peer networks,” Lecture Notes in Computer Science, vol. 2735, pp.139–148, 2003.
[15] C. Buragohain, D. Agrawal, and S. Suri, “A game theoretic frameworkfor incentives in P2P systems,” in Proc. 3rd Int. Conf. on Peer-to-PeerComputing (P2P’03), Sept. 2003, pp. 48–56.
[16] K. Lai, M. Feldman, I. Stoica, and J. Chuang, “Incentives for cooper-ation in peer-to-peer networks,” in Proc. Workshop on Economics ofPeer-to-Peer Systems, 2003.
[17] D. Fudenberg and J. Tirole, Game Theory. Cambridge, MA: MITPress, 1991.
[18] D. P. Bertsekas, Dynamic Programming and Stochastic Con-trol. New York: Academic , 1976.
[19] E. Haruvy, D. O. Stahl, and P. W. Wilson, “Evidence for optimistic andpessimistic behavior in normal-form games,” Econ. Lett., vol. 63, pp.255–259, 1999.
[20] H. A. Simon, “A behavioral model of rational choice,” Quart. J. Econ.,vol. 69, pp. 99–118, 1955.
[21] K. Jain, L. Lovász, and P. A. Chou, “Building scalable and robustpeer-to-peer overlay networks for broadcasting using network coding,”Distrib. Comput., vol. 19, no. 4, pp. 301–311, 2007.
[22] Multimedia Over IP and Wireless Networks, M. van der Schaar and P.A. Chou, Eds. New York: Academic, 2007.
[23] C. J. C. H. Watkins and P. Dayan, “Q-learning,” Mach. Learn., vol. 8,no. 3-4, pp. 279–292, May 1992.
[24] G. de Veciana and X. Yang, “Fairness, incentives and performance inpeer-to-peer networks,” in 41th Annu. Allerton Conf. Communication,Control and Computing, 2003.
[25] M. Gupta, P. Judge, and M. Ammar, “A reputation system for peer-to-peer networks,” in Proc. 13th Int. Workshop on Netw. and OperatingSystems Support for Digital Audio and Video (NOSSDAV’03), 2003,pp. 144–152, ACM Press.
[26] R. G. Gallager, Discrete Stochastic Processes. Norwell, MA:Kluwer, 1995.
Hyunggon Park received the B.S. degree (magnacum laude) in electronics and electrical engineeringfrom the Pohang University of Science and Tech-nology (POSTECH), Korea, in 2004, and the M.S.and Ph.D. degrees in electrical engineering from theUniversity of California, Los Angeles (UCLA), in2006 and 2008, respectively.
His research interests are game theoretic ap-proaches for distributed resource management(resource reciprocation and resource allocation)strategies for multi-user systems and multi-user
transmission over wireless/wired/peer-to-peer (P2P) networks. In 2008, he wasan intern at IBM T. J. Watson Research Center, Hawthorne, NY.
Dr. Park was a recipient of the Graduate Study Abroad Scholarship from theKorea Science and Engineering Foundation during 2004-2006, and a recipientof the Electrical Engineering Department Fellowship at UCLA in 2008.
Mihaela van der Schaar is currently an Associate Professor in the ElectricalEngineering Department at University of California, Los Angeles. Her researchinterests are in multimedia communications, networking, processing and sys-tems. Dr. van der Schaar received the NSF Career Award in 2004, the BestPaper Award from IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO
TECHNOLOGY in 2006, the Okawa Foundation Award in 2006, the IBM Fac-ulty Award in 2005, 2007 and 2008, and the Most Cited Paper Award fromEURASIP: Image Communications journal in 2005, 2007 and 2008.