Imitative problem solving: Why transfer of learning often fails to occur Author(s): IAN ROBERTSON Source: Instructional Science, Vol. 28, No. 4 (2000), pp. 263-289 Published by: Springer Stable URL: http://www.jstor.org/stable/23371449 . Accessed: 28/06/2014 18:15 Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at . http://www.jstor.org/page/info/about/policies/terms.jsp . JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. . Springer is collaborating with JSTOR to digitize, preserve and extend access to Instructional Science. http://www.jstor.org This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PM All use subject to JSTOR Terms and Conditions
Transcript
Imitative problem solving: Why transfer of learning often fails to occurAuthor(s): IAN ROBERTSONSource: Instructional Science, Vol. 28, No. 4 (2000), pp. 263-289Published by: SpringerStable URL: http://www.jstor.org/stable/23371449 .
Accessed: 28/06/2014 18:15
Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at .http://www.jstor.org/page/info/about/policies/terms.jsp
.JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range ofcontent in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new formsof scholarship. For more information about JSTOR, please contact [email protected].
.
Springer is collaborating with JSTOR to digitize, preserve and extend access to Instructional Science.
http://www.jstor.org
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Imitative problem solving: Why transfer of learning often fails to occur
IAN ROBERTSON University of Luton, Department of Psychology, Luton, LUI 3JU, U.K.,
e-mail: ian. robertson@luton. ac. uk
Received: 9 March 1998; in final form: 2 August 1999; accepted: 16 August 1999
Abstract. The paper presents empirical evidence for imitative problem solving and the
Interpretation Theory described in Robertson and Kahney (1996). According to the theory
beginners use imitation as their primary problem solving method when learning about an
unfamiliar domain. Imitative problem solving can explain much of the evidence that ana
logical transfer even within a domain is often hard to find. The paper presents an analysis of algebra word problems to predict in detail exactly where solvers will have difficulty in
using a worked out example to solve either a close or distant variant of the problem type. In a 2x2 between-groups design, secondary school students were given an explanation of an
algebra word problem taken from Reed et al. (1985) or an explanation of the problem that
also included information about how the solution could be adapted to solve a distant variant.
They were then given either a close or distant variant to solve. Results were in line with the
predictions derived from the Interpretation Theory analysis.
Keywords: analogical problem solving, imitative problem solving, task analysis, transfer,
instructional design
Introduction
The issue of transfer of learning from one situation to another is of a perennial interest to psychologists and educationalists. Much research has focused on
the conditions under which it occurs or fails to occur both between domains
There are a number of assumptions built into the APS account that have to be borne in mind especially when applied to the kinds of academic prob lem solving that students are often required to engage in. First, an important assumption is that the source problem is represented in long-term memory. For example, in Gick and Holyoak's, (1980, 1983) experiments, participants had already studied the Fortress Problem, where a general has to divide his
army into groups that converge simultaneously on a fortress. When asked to solve Duncker's (1945) Radiation Problem, where a surgeon has to focus a number of weak rays on a tumour, most of them did not relate it to the Fortress Problem since there is no obvious reason why one should look to a problem of
military strategy to solve a problem in surgery (Medin & Ross, 1992). When
given a hint to use the previously presented problem the vast majority were able to retrieve and use it to solve the Radiation Problem.
Second, APS assumes the student understands the source problem; that
is, the student has at least an implicit knowledge of the solution structure in the source. Analogies work when we can understand or make inferences about a new domain because we already understand the source domain. When
Jacques Chirac called currency speculation the AIDS of the world economy we can infer from our knowledge of AIDS that he probably meant that cur
rency speculation was debilitating and there was no cure for it. Third, APS assumes that the student understands the target domain well enough to adapt the solution. In the Fortress Problem, dividing an army into groups (in Gick and Holyoak's studies) becomes reducing the intensity of rays and finding more of them in the Radiation Problem. Fourth, most models of APS assume that analogical mapping involves a hierarchical system of relations (Gentner, 1989; Gentner & Markman, 1997) that have to be put into correspondence. Objects in the source problem are mapped onto the objects in the target. There are some constraints on this mapping, governed by the relations between the objects and the relations between those relations. Constraints other than structural ones (such as semantic and pragmatic constraints) are also assumed to influence analogical mapping (Holyoak & Thagard, 1989) and the retrieval of a relevant source from long-term memory (Thagard et al., 1990).
The examples so far have referred to between-domain analogising. It
might be argued that in within-domain analogising the problem of retriev
ing an example is reduced since there are likely to be more relevant cues available. Within-domain analogising is often known as case-based reason
ing (Kolodner, 1993) which is essentially a sub-type of APS since the same
processes apply. A current example reminds one of an earlier problem of the same type which is used as the basis for reasoning about the current situation. Here again, solvers are assumed to have a 'case' in long-term memory that
they can be reminded of and that they already understand (otherwise they
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
would not be able to reason from it). However, when students are learning a new topic for the first time, the examples they are presented with may be poorly represented in long-term memory. They may not have a 'case' to reason from.
Anderson, Fincham & Douglas (1997) suggest that case-based reasoning is the final stage of their four-stage model of learning a new domain. The
first stage involves analogy where a training problem is used to help solve a test problem. Solving a problem in this way allows the learner to abstract out the principles underlying the problems. These abstractions can be used
to generate production rules that can be used in future to solve problems of the same kind. Finally, specific examples can be retrieved that remind the solver what principles to apply, and hence what production rules are relevant. Note that retrieving specific cases to reason from is the final stage because
examples take time to learn. It is the first stage of Anderson et al.'s four stage model that the present
paper investigates. The first steps in novice problem solving involve imitative
problem solving (IPS) (Robertson & Kahney, 1996), which is a subtype of APS. It makes fewer assumptions about the knowledge the student is sup
posed to have and makes different assumptions about the processes that take
place in the early stages of problem solving. First, IPS does not assume
that the student has an example problem in long-term memory. In textbook
problem solving, students are likely to go back and look at examples in
the preceding section of a textbook rather than trying to retrieve one from
memory. Second, students are assumed to pay attention to the superficial features
of the problems rather than the structural features. Assuming the student has
been given an example to model, the first task is to identify objects that
appear to play the same role in the two problems (Gentner, 1989; Gentner
et al., 1993; Ross, 1987, 1989). When students have little understanding of
the example, this process is guided more by the semantic similarity of the
objects involved than by the solution structure. Furthermore, there are often
gaps in the explanations of textbook problems where the reader is left to
make inferences. An inability to make those inferences is likely to prevent the construction of a complete representation of the problem (Britton et al., 1990; Neumann & Schwarz, 1998).
Third, the student tries to identify and apply the same operator in the target that appears to be applied to the mapped objects in the source. There may be
little attempt to relate this process to what Van Dijk and Kintsch (1983) have
called the 'situation model' - a mental model of the situation represented
by the text. Furthermore, when students have a poor representation of the
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
structure of the source, the ability to adapt it depends on the amount of domain
knowledge the student possesses (Novick & Holyoak, 1991).
Fourth, as in the traditional APS account, learning comes about as a result
of the process of using the example to solve the current problem. By using and implicitly (or explicitly) comparing examples, students can make a start
at generalizing from the two problems (Dellarosa-Cummins, 1992; Ross &
Kennedy, 1990).
Although an example is the salient aspect of instruction as far as the
student is concerned, 'the disadvantage of an example is that it may not be
very helpful for solving problems that are slightly different' (Reed & Bolstad,
1991, p. 753). Thus, when Reed, Dempster and Ettinger (1985) gave students
the solution to an algebra problem, the latter could only solve a problem that
was almost identical to the example even when they had the example and
an explanation of the solution in front of them. When their participants were
asked to solve more distant variants of the examples they were given they often did no better than if they had been given a completely unrelated training
problem. Ross (1984, 1987) also found that his participants were often poor at using solution principles such as equations to solve problems even when
the equation was in front of the student at all times.
The main aim of the present paper is to see the extent of the difficulties
novices have in textbook problem solving as predicted from the structure of
the textual explanations themselves. A solution explanation can be couched
in terms specific to the example or at a more abstract or general level. A more
general explanation should help indicate how the solution can be applied to a broader range of examples than the specific one provided. Reed and
Bolstad enhanced transfer to more distant problem variants by providing an
explanation at a general level along with specific examples. This approach is also advocated by Nathan et al. (1992). One would therefore expect that
a student attempting a problem that is very similar to a training example
(a 'close variant' of the example problem) would be relatively uninfluenced
by the type of explanation given. Students faced with an exercise problem that requires a degree of adaptation of the example (a 'distant variant') should
be helped by an example explanation couched at a more general level. The
present study therefore looks at the effect that a specific explanation and a
general explanation can have on a student's ability to solve either a close or a
distant variant of an example. A second aim is to show how this research fits into the Interpretation
Theory described in Robertson and Kahney (1996). This is a theory of text, task and protocol analysis that provides a unified notation for describing both
the structure of a text, or task embedded in a text, and the behaviour of the
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Figure 1. Example problems in textbooks represent a category of problems of which there can
be close and distant variants.
solver. One of its underlying assumptions is that novices in the early stages of learning a new domain engage in imitative problem solving.
The rest of this paper begins with a brief description of the Interpretation
Theory notation used to analyse texts and problem structure. Based on this
analysis, it is possible to predict where students are likely to have difficulty either because of the structure of the example problem or because of the
mappings between the example and the exercise problem. A full description of the Interpretation Theory as it applies to text and problem analysis can be
found in Robertson & Kahney (1996). (A summary diagram of the notation
is presented in Appendix A.) In this paper, I look at empirical investigations of IPS; particularly the types of errors that students make and how instruction
can be improved to reduce them, as revealed by the Interpretation Theory
analysis. This improvement can be produced in two ways: first by removing the gaps where students have to make inferences, and second by providing a
general explanation at a more abstract level alongside the specific example to
aid transfer to more distant variants of the problem. Before going on to the study itself, the Interpretation Theory is applied to
the analysis of specific problems based on those used in Reed et al. (1985).
The interpretation theory notation
In the early stages of problem solving in a novel domain, it is the solution
procedure that the novice tries to understand and which characterises the
problem. Exercise problems can be either very similar in terms of their solu
tion procedure (the 'close variants' in Figure 1) or they may require some
adaptation (the 'distant variants' in Figure 1).
Solving an exercise problem involves accessing or identifying a relevant
example problem, mapping the features of the example problem that appear to play the same role in the exercise problem, and applying the solution pro
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Example problem Example problem statement solution
2. mapping
5. (adapt)
Exercise problem Exercise problem statement solution
1
1. access
Figure 2. Some of the processes involved in using an example problem to solve an exercise
problem.
cedure instantiated in the example problem step by step to generate a solution.
These three processes are indicated in Figure 2, which is based on a simplified version of Sternberg's (1977) model of the component processes involved in
analogical reasoning. The A term represents an example problem statement, the B term is the example solution, the C term represents the statement of
an exercise problem and the D terms is the goal - the solution the solver is
seeking. It should be emphasised that the notation described here is not intended to
be a model of how a student represents a problem. It is a way of analysing texts and problems based on IPS theoiy.
In Reed et al.'s (1985) third experiment, there is a condition in which a
group of students is presented with an 'elaborated' solution to a problem
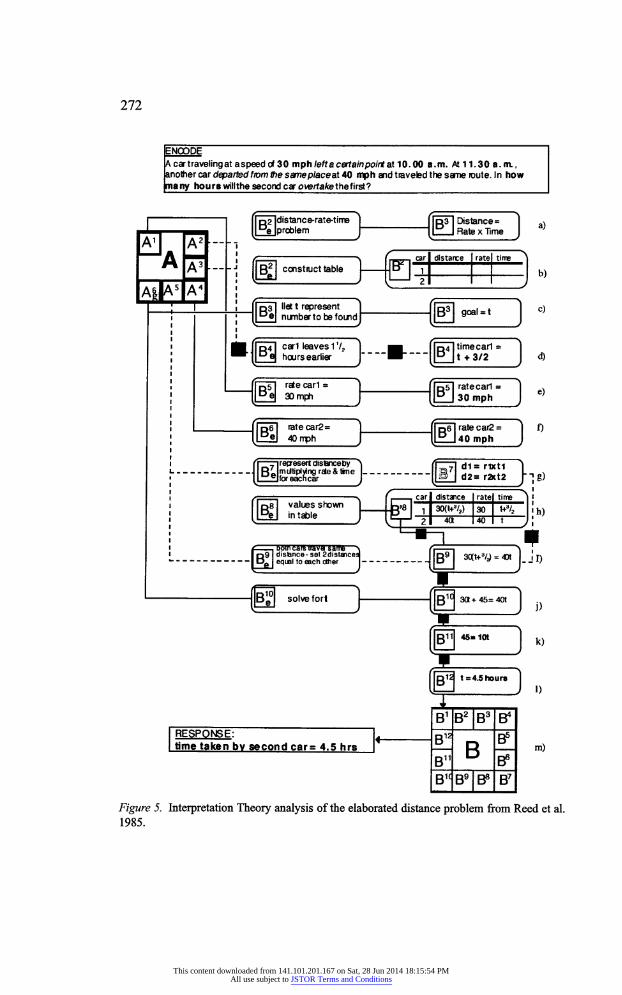
designed to enhance performance on subsequent test problems (Figure 3). The first paragraph presents the problem statement (the A term box in Fig ure 3). The goal is to generate an equation based on the information in the
problem statement (the B term). (Solving the equation to find't' is a different
type of problem and is not dealt with here.) Between the A term and the B
term is an explanation of the solution (Be). The explanation includes a table
as a way of represenaing the problem in terms of the variables in the equation. This is coded as B' which stands for any form of intermediate representation.
There are several sections highlighted in bold in the problem statement.
These represent the problem givens that play a role in the solution procedure. That is, a number of operators have to be applied to those problem givens to
generate the solution. The goal ('in how many hours... ') is also highlighted
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
A car travelling at a speed of 30 miles per hour (mph) left a certain place at 10.00 a.m. At 11.30 a.m. another car departed from the same place at 40
mph and travelled the same route. In how many hours will the second car overtake the first car?
The problem is a distance-rate-time problem in which
Distance = Rate x Time
Be
We begin by constructing a table to represent the distance, rate, and time for each of the two cars. We want to find how long the second car travels before it overtakes the first car. We let t represent the number that we want to find and enter it into the table. The first car then travels t + 3/2 hr because it left 1V2 hrs earlier. The rates are 30 mph for the first car and 40 mph for the second car. Notice that the first car must travel at a slower rate if the second car overtakes it We can now represent the distance each car travels by multiplying the rate and the time for each car. These values are shown in the following table.
B'
Distance Rate Time Car (miles) (mph) (hr)
First 30(t+3/2) 30 t+3/2 Second 40xt 40 t
B
Because both cars have travelled the same distance when the second car overtakes the first, we set the two distances equal to each other:
30(t + 3/2) = 40t
Solving for t yields the following:
30t + 45 = 40t; 45t = lOt; t = 4.5 hr.
Figure 3. An 'elaborated' explanation used by Reed et al. (1985).
since it implies the specific sequence of operators necessary to reach it. Thus
the A term (the example problem statement) can be seen as containing within
it those problem givens that play a role in the solution process - particularly in generating a sequence of subgoals (Figure 4).
One other feature of Figure 4 is worth mentioning. To understand the
solution fully, the solver has to be able to infer why both cars travel the same
distance. This is not stated in the problem. It can only be inferred from a
mental model (Nathan et al., 1989). The dotted line represents an inference
that has to be made based on the situation described in the problem statement.
It should also be pointed out that the solver does not need to make such
an inference - a close variant can still be solved by imitating the example
problem without understanding the underlying structure.
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Figure 4. Representation of the example problem statement as givens nested within the A
term box.
The explanation of the solution also requires the solver to make a number of other inferences. First, the explanation states:
The first car then travels t + | hr because it left 1 | hrs earlier.
The solver has to infer which problem givens produce the t + | hr. They also have to infer the missing operators that produce the | hr. (One of the difficulties in analyzing tasks in the detail presented here is finding that state of ignorance which allows us to identify where inferences are built into a text and therefore where novices are likely to encounter problems. For this reason no inference is considered trivial.) Where operators are not explicitly stated, it is represented by a 'black box' in Figure 4. The two black boxes in the
figure represent the missing operators (subtract A2 [10 am] from A3 [11:30 am]) and those used to convert 11 to |.
The overall goal (the B term) can be construed as having subgoals 'nested' within it just as the problem statement has givens nested within it. On the
right of Figure 4, for example, the subgoal (B4) is to generate the time taken
by car 1 (t + |) which can be slotted into the equation. Using this notation it is
possible to analyse the text of a problem in such a way that the inferences that solvers have to make can be identified and where adaptations are required to solve the problem.
Figure 5, therefore, represents the complete analysis of the elaborated distance problem used by Reed et al. in their study of transfer. There are several places where there is the potential for solvers to misunderstand the
problem explanation. Row d has already been discussed. In row g there is no
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
explanation of why the distance can be represented by multiplying the rate
by the time for each car since the reader is not referred back to the distance
equation, nor is the relevant equation given. For this reason B7 appears as a
'ghost' term (in outline format) since it is not explicitly stated.
There are 6 values represented in the table and the student may have diffi
culties mapping them onto Distance = Rate x Time equation particularly as it
is not the relevant one. The relevant equation is Ratecaii x Timecas\ = Ratecai2 x Timecar2 but it is not provided anywhere. The black boxes between B7 and B8 and B9 in Figure 5 indicate where this information is missing and hence where solvers may experience difficulties.
When students attempt an exercise problem, which is a close variant of
the example problem, we can predict that any misunderstandings will be in
those places marked by the inference lines and black boxes in Figure 5d to i.
Thereafter, they are obliged to rely on their prior knowledge of mathematics
to understand the transformations that take place to arrive at the overall solu
tion (rows i to 1). The focus of this study, however, is on the students' ability to generate the equation in row i. If they can successfully substitute elements in the target for elements in the source to generate the equation, then solving a close variant should not cause much difficulty.
Predicted sources of difficulty in mapping and adapting the practice problem to solve a close variant
In Reed et al.'s experiments, participants were presented with an 'equivalent' exercise problem (a close variant of the example problem - see the statement
of the problem in Figure 7). As Figure 6 shows, there is no direct match
between the '2 hours' mentioned in the exercise problem and the times given in the example problem (represented by A2 and A3 respectively). To solve a
problem by analogy to an earlier one, the solver has to map the objects that
play the same roles in both problems (departure times, speeds of vehicles, and
so on). The mapping line between C2 and A2 and A3 is therefore important in
representing the need to identify and map relevant objects. However, since the
objects mentioned in the problem givens do not map directly, the access and
mapping line from C2 to A2 and A3 is shown as being blocked (represented by the vertical bars). Participants have to infer that they have to find the
difference in departure times (represented by D4). In fact, they would have
to map the B4 term (representing the difference of | hours) onto the C2 one.
Some of the example problem givens can be mapped directly onto the
exercise problem. The first car in both problems travels at 30mph. This
information is represented as A1 and C1 in row e of Figure 7. By imitating the example, problem solvers can map the relevant values onto the variables
in the relevant equation (B5 and D5 in row e). By changing the rate of the
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Acartraveiingataspeedof30 mph left a certain point at 10.00 «.m. At 11.30 a.m., another car departed fiom the ssmeplaceat 40 mph and traveled the same route. In how ma ny hours willthe second car overtake the first?
EE
A2
A*
distance-rate-time problem
B3 Distance= Rate x time
b: constiuct table
r W
distance
Bl Met t represent number to be foird B3 ii = t
Bi carl leaves 1'/,
ej hours earlier B" time carl = t +3/2
B~TI ra(e car1 =
e[ 30 mph B rate carl = 30 mph
iatecar2= 40 mph
B rate cai2 = 40 mph
Be represert aisbnceDy miJtipMng rete & tine toreachcar
d1 = rtxtl d2= r2*t2
f rar
Bl values shown in table
Jd'8 1 30(1+%) 4a
30 40
t+% « ) M, V
b)
c)
<S)
e)
f)
"!g)
h)
B® BBtrresinBya rare—■ distance- set 2distance! eqial to each other B9 30(t+»/j = 4M _ J)
P
B^° solve fort B
1C 30t+ 45= 40t
B1 45" 101
j)
k)
B1 12 t =4.5 hours
RESPONSE: time taken by second car = 4.5 hrs
B' B2 B3 B4
B1J
B" B
B5
B?
B1( B9 B8 B7
m)
Figure 5. Interpretation Theory analysis of the elaborated distance problem from Reed et al.
1985.
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Figure 6. Mapping and adapting times in test and practice problems.
second car in the example from 40mph to 45mph in the test problem (A4 and
C3 in row f), the solver could also map this onto the rate term in the equation
(D6). When using the example to solve the test problem, the solver 'inherits'
all the difficulties mentioned above in understanding the example problem.
Apart from the added difficulty of mapping the times in row d, solvers will
have difficulties where there are dotted lines and black boxes. The summary Figure 7 demonstrates where mappings are blocked and where the solver is
still obliged to make inferences about which operators should be used in order
to relate the problem givens to the solution. We can therefore make further
predictions about the possible sources of difficulty for the participants:
Difficulties in mapping (Hypothesis 1). The major difficulty in solving a close variant of the problem is one of mapping corresponding values.
Where the exercise problem is literally similar (that is, where the relations
between the objects are identical in both problems and where the objects in
the problems are semantically similar), we would not expect mapping to pose a particular problem. On the other hand, any move away from isomorphism, however slight, will be a potential source of error. Some participants will
therefore have difficulty at line d since the times in the example do not map
directly onto the one in the exercise problem. Difficulties in mapping will also
lead to more errors in mapping from distant variants than from close variants, and more errors where a specific explanation is given than where there is a
general explanation since a more general explanation will give at least some
indication of how to map values to a broader range of problems.
Predicted sources of difficulty in mapping and adapting the practice problem to solve a distant variant
The statement of Reed et al.'s 'similar' exercise problem (a distant variant) is
shown at the top of Figure 8.
Mapping the example problem onto this distant variant gives quite a dif
ferent picture. None of the values in the problem statement (C1, C2 and C3 in
Figure 8) maps onto anything in the earlier problem.
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
en: cde A pick- ip truck lea/es 3 hr after a large delivery truck but overtakes it by traveling 1 5 mph faster. If it takes the pick-up truck 7 hr to reach the delivery truck, find the r ate of each vehicle.
|c1 c2 —► C c3
c4
B1 n
Distance= Speed x Time
B2 B!
I. car distance rate time ^
D* i v 2 -/
|A®'
IA3"'
B3 find rates goal =rl goal =r2
B4. BA r1 3 hoirs after fry ■ time>u;ltl = 7hr
+ 3hr= 10hr -i_ >
A1 B6
A5 B
c3 1
true k2 takes 7fr
D5
A TimefccW= "Ttir
C* true k2 travels "
DB 15mph faster Rate^ + 15 J ! i" V
ft Heaves overtakes
D7 di =d2
r1xtt= i2xt2 u
'ch car distance rate time
b'8 1 lor ' 7+3 Ar+15) r+15 7 )
a)
b>
c)
d)
e)
0
g)
h)
Rate of first truck = 35 mph Rate of second truck = 50 mph
D1 D2 D3 D4
n12
D
D5
D11 D14 D6
D1C D9 D8 D7
o)
Figure 8. Summary figure of mappings of a more distant variant onto the practice problem.
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
It follows from the above analysis of the word problems that, if the infer
ences inherent in the Reed et al. explanation are removed and a more general procedure provided, then participants will find it easier to map values across
and adapt the procedure to more distant variants.
Effects of a general procedure (Hypothesis 4). Removing inferences and
providing a more general procedure will enhance transfer to more distant
variants of a problem type. This should be evident in the participants' ability to produce the relevant solution procedure and identify the elements of the
relevant equation when solving distant variants.
Method
Participants
The participants were 40 Scottish secondary school students, aged between
14 and 16, who took part in the experiment during their normal mathemat
ics classes. They were divided into four groups of 10 by the mathematics
teacher so that there was the same general spread of mathematics ability in each group. The groups corresponded to four conditions: Specific/Close,
Specific/Distant, General/Close and General/Distant.
Materials
In the Specific/Close and Specific/Distant conditions, participants received an
example problem along with the explanation used by Reed et al. The only dif
ference was that the word 'rate' was replaced by 'speed'. In the General/Close
and General /Distant conditions, participants received the same problems but
the explanations had the identified inferences removed and included a general
explanation of the solution (one at a sufficient level of abstraction that it
might be applied to a more distant variant) as well as a specific one (see
Appendix B).
Design and procedure
The experiment used a 2x2 between-subjects design. The independent vari
ables were the type of instruction provided with the example problem
(Specific or General) and the type of exercise problem to be solved (Close or
Distant). The participants were asked to take part in a study of instructional
materials and were told that the study was not a test of their own problem
solving abilities. They were then presented with three sheets containing the
instructions, the example problem and associated solution procedure, and the
exercise problem. The instructions were as follows:
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
In a moment you will be asked to read the next sheet (sheet B) which
gives an example problem and an explanation of how to solve it. Please
read it carefully. Once you have read sheet B, turn to the third sheet (sheet
C) and write your name and class at the top. Then try to solve the problem which you find there.
Please use the example problem on sheet B to help you solve the
problem on sheet C.
There was no time limit imposed but the experiment was conducted
within the normal lesson time of approximately 35 minutes. Participants were
allowed to consult the example solution throughout the experiment.
Coding of solutions
Responses were analysed according to the following criteria:
Elements identified. This refers to the number of elements the student
identified as being part of the equation. That is, students were given a score
of 1 of they identified all four elements of the equation (the rates and times
for both cars). Correct equation. A score of 1 was given when the student generated
the correct equation by filling in the values in the equation: speedvcb,c\e] x
//mevchiciei =
speedveiàc\e2 x timeve\ùcie2- Note that an equation can be classified
as correct even though it may contain quantity or matching errors (see the
coding of errors below). This classification is in conformity with that used by Reed et al. (1985).
Correct solution. A score of 1 was given to a solution that included the
correct equation and that used the correct procedure. A correct solution also
contains the correct values in all variable slots in the equation. The correct
procedure here is defined as the procedure given in the training example. Note that the aim of the experiment was to identify how well participants
could generate the correct equation using the correct procedure. It did not concern itself with the participants' ability to manipulate the equation to
generate the correct answer once the equation had been generated.
Coding of errors
Responses were also examined to identify the types of errors made. The errors were classified as follows:
Nonalgebraic solution. In some cases, participants used both an algebraic and a nonalgebraic solution method; in such cases, the nonalgebraic solution
method was ignored for the purposes of coding. Otherwise participants are
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Figure 9. Success in the Specific and General Conditions.
coded as using a nonalgebraic method whether or not the method gives the
correct answer.
Wrong equation. Participants are coded as using the wrong equation when
it appears they are using any equation other than the 'correct' one as defined
above.
Quantity errors. A quantity error refers to an error produced when the
participant maps the wrong value from a target problem to the source. An
example would be mapping the difference between the speeds of the vehicles
(e.g. 15m/h) onto the speed of one of the cars in the source.
Matching errors. A matching error occurs when the participant substitutes
a value in the source problem for a value in the target without any attempt at
adapting it.
Frame errors. A frame error is an error in the form of the equation. If 30(7 + 2) = 451 is the correct equation, then an equation such as 30(/ + 2) = 45
would be a frame error since it does not preserve the form of the original
speed x time equation (the time of the second vehicle is missing).
Results
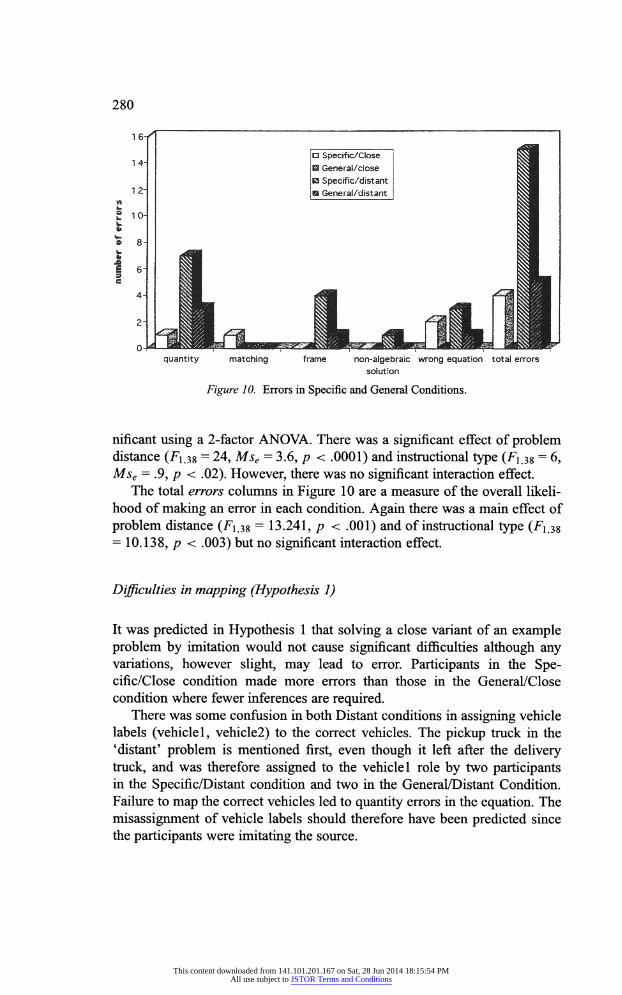
Figure 9 and Figure 10 present the results of the four groups. As expected the close variant is easier to solve than the distant variant and
the general explanation was more effective than the specific one at eliciting transfer to both near and distant variants of the training example (see the
correct solution columns in Figure 9). These results were found to be sig
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
□ Specific/Close E General/close □ Specific/distant s General/distant
quantity matching frame non-aigebraic wrong equation total < solution
Figure 10. Errors in Specific and General Conditions.
nificant using a 2-factor ANOVA. There was a significant effect of problem distance (Fi 38 = 24, Mse = 3.6, p < .0001) and instructional type (F| 38 = 6, Mse = .9, p < .02). However, there was no significant interaction effect.
The total errors columns in Figure 10 are a measure of the overall likeli
hood of making an error in each condition. Again there was a main effect of
problem distance (Fi 38 = 13.241, p < .001) and of instructional type (F\ 3$ = 10.138, p < .003) but no significant interaction effect.
Difficulties in mapping (Hypothesis 1)
It was predicted in Hypothesis 1 that solving a close variant of an example problem by imitation would not cause significant difficulties although any variations, however slight, may lead to error. Participants in the Spe cific/Close condition made more errors than those in the General/Close condition where fewer inferences are required.
There was some confusion in both Distant conditions in assigning vehicle labels (vehicle 1, vehicle2) to the correct vehicles. The pickup truck in the 'distant' problem is mentioned first, even though it left after the delivery truck, and was therefore assigned to the vehicle 1 role by two participants in the Specific/Distant condition and two in the General/Distant Condition. Failure to map the correct vehicles led to quantity errors in the equation. The
misassignment of vehicle labels should therefore have been predicted since the participants were imitating the source.
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
'Overt ' imitation and over-transfer (Hypothesis 2)
Figure 9 shows that participants in the 2 Distant conditions were more likely to make quantity errors than those in the Close conditions. There were also
fewer quantity errors in the General conditions (fis = 1.852, p = .04). In some
cases, participants attempted to adapt the exercise problem in order to make
it perceptually similar to the earlier problem. Such 'overt' imitation can take
various forms. Examples would be: ensuring that the solution to the exercise
problem has the same number of '=' signs or same number of lines as the
example when solving for t. Overt imitation is a form of over-transfer, where
the solver transfers too much information from the source. Matching error is
the most overt form of imitation where the participant copies a value from
the source problem across to the target without any attempt at adapting it. For
instance, one participant in the Specific/Close condition copied across t + | from the example.
Examples of over-transfer were found in all conditions. In the distant con
ditions, some students attempted to incorporate 7' into the equation instead
of a more appropriate variable name since that was the variable used in the
training problem. This was despite the fact that the times for the vehicles were
given, or easily obtained by adding 7 and 3, in the problem statement. Again students were trying to copy the earlier procedure without adapting it. Reed &
Ettinger (1987) found the same effect in their studies, where their participants
copied over structures from the example problem which were unnecessary in the target problem. Such 'structure matching errors' are a form of over
transfer and played a great part in frustrating Reed & Ettinger's attempts to
induce transfer in their participants. In the Close conditions, over-transfer was
apparent in five participants who converted the 2 hours difference between
the departure times of the cars in the exercise problem to ~ so that it looked
like the | in the example. Similarly three participants in the Specific/Distant Condition converted the 3 to | or the 7 to In the latter case, the conversion
naturally led to incorrect answers.
Frame errors (Hypothesis 3)
There were no significant differences between the Specific and General
groups' ability to generate the correct equation. Almost all generated a correct
equation in the Close conditions and about half were successful in the Distant
conditions. Where frame errors occurred they were generally due to an inab
ility to identify the correct equation in the first place. In particular they tended
to use distance = rate x time or a variation of it, such as rate = distance /
time. The latter was usually generated by the participants themselves from the
distance-rate-time triangle:
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
which they had previously learned. Alternatively, they may have used the
distance = speed x time equation given in the explanations in the Specific condition.
Effects of a general procedure (Hypothesis 4)
The type of instruction had a significant effect on the likelihood of using the correct solution procedure and avoiding errors. In the Distant conditions, the general instructions were more effective at helping students identify the
relevant elements (t\% = -1.897, p < .04) and at finding the overall solution
(?i8 = -2.449, p = .01) since more information was provided in the General
conditions about how the problem givens should be mapped to the underlying
equation, and how the example relates to other problems of the same type.
Discussion
It would appear that the Interpretation Theory analysis of the problems and of
the mappings between them correctly predicted the areas where participants would have difficulty. It also shows that attempting to improve explanations in areas of potential difficulty, by removing the need for inferencing and
presenting a more general procedure, produces a greater degree of transfer
to variants, both near and distant, of a problem type. The better performance of participants in the General Conditions indicates
the beneficial effect of removing inferences when participants are reading an
example problem, and of providing an explanation at a level of generality sufficient to allow them to adapt the procedure to suit the target problem. This finding is in accordance with the results of Reed & Bolstad's (1991) experiments. The results clearly show where some participants had difficulty in adapting the source. One of the predictions from an analysis of Reed et al.'s text was that participants would find problems mapping elements onto the relevant equation. Half of the participants in the Specific conditions managed to fill in the times and speeds in the table. However, fewer than 10% managed to map these values onto the correct equation. These results contrast with those of Reed and Ettinger (1987) who found that their participants were able to generate the equation from the values in the table when those values were
given. Another notable aspect of the behaviour of the participants was the degree
to which they tried to imitate the example. Although it was predicted that
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
some participants would have difficulty in understanding where the | came
from in the example, and therefore that it would be hard to substitute the relevant value in the exercise problem, the lengths to which some participants went to adapt their solution to make it look like the example was often quite marked. Those who saw the correspondence between the 2 in the exercise
problem and the | in the example still adapted it to make it look like The
participants seemed to be imitating the example problem in the belief that
the closer the exercise problem resembled the example superficially the more
likely they were to get a correct answer.
According to Reed et al. (1985), the purpose of their experiments was
'to investigate how well students could use the solution of an algebra word
problem to solve other problems belonging to the same category.' The cat
egory (distance-rate-time problems) is one which has been imposed by the
authors and not one which is necessarily understood by the students (Hall et al., 1989). Similarly, stating that the earlier problem had to be 'slightly modified', as Reed et al. claim, is a judgement that only a relative expert can
make. In their experiments, only 22% of the participants given an 'elaborated'
solution to work from successfully solved the distant variant compared with
17% using a completely unrelated example problem. The difference between
these results is not statistically significant. According to Reed et al., the low
level of performance was due to participants' inability to generate the correct
equation rather than an inability to solve it. This does not explain why the
participants performed no better when an explanation was provided which
removed many of the inferences. The results can readily be explained if one
assumes that they are capable of imitating an example. Reed et al. were
aware of this and called it a 'syntactic pattern-matching procedure'. How
ever, the solution explanation provided by Reed et al. gave no information
to the participants about how to solve any other kind of problem, such as
one in which the rates are unknown. Figure 8 demonstrates that very little
in the example problem was of any use in solving the transfer problem. In
fact, it demonstrates that it was a different problem altogether, hence Reed
et al.'s participants were unable to imitate the example to solve the distant
variant.
This paper has argued that gaps in the explanations of example prob lems are often the source of error and misunderstanding. However, some
students can improve their understanding of worked examples when asked
to 'self-explain' (essentially filling in some of those gaps themselves). There
has been much recent work on the role of such self-explanations (Chi &
Bassok, 1989; Chi et al., 1994; Neumann & Schwarz, 1998; VanLehn et
al., 1992). For example, good students exhorted to 'self-explain' produce more clarification, justification and inference statements than poor students
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
who tend to produce more reformulation statements (Neumann & Schwarz,
1998). Beginners, however, may not know what inferences to make, espe
cially if their general domain knowledge is poor. The degree to which
students should be left to make their own inferences is an empirical one
and depends on the assumed prior knowledge of the student and whether the
writer wants only 'good' students to understand the text or most students to
understand it.
The theory of Imitative Problem Solving does not deal only with well
structured problems as exemplified here. In ill-structured problems such as
essay writing (another favourite task of students) imitation is often the pre ferred method. This does not just refer to outright plagiarism but rather to the
fact that the student will preferentially follow the structure of a textbook and
use the same examples the textbook uses, and so on. While the Interpretation Theory notation provides an analysis of the structure of well-structured prob lems, it is less well suited to such ill-structured problems. Nevertheless, it can
be modified to apply to the analysis of textbooks so that the behaviour of the
student can be mapped onto the text structure and the degree of convergence or divergence from the structure can be revealed (based on unpublished work
by the late Hank Kahney of the Open University, U.K.). The general aims of this research are to provide a unified methodology
for representing the structure of texts, problems and problem solving beha
viour; to improve thereby the structure of teaching texts; and to gain a better
understanding of the early stages of 'academic' problem solving. A unified
methodology or notation should allow us to see how the structure of a text (at a coarse grain of analysis) or the structure of an individual problem (at a fine
grain) affects problem solving behaviour (see Robertson & Kahney, 1996). As a result we should be in a better position to design instructional materials that are more explicit and that help teach students better.
The main pedagogical implication of IPS is that imitating an example is
the predominant method used by beginners in a domain with which they are unfamiliar. Imitation is very useful for two main reasons: first, it tends to allow the student to get an answer which may well be correct without
requiring the student to fully understand why (Reeves & Weisberg, 1993); second, it forms the basis for future learning. Comparing and using examples is the basis of understanding and learning through generalization (Reeves &
Weisberg, 1994; Ross & Kennedy, 1990). At a more practical level the Inter
pretation Theory demonstrated here can be used to help generate material which ensures that students do not need to make 'text external' inferences in
unfamiliar domains. Problem solving can also be speeded up by simply telling students which earlier example to use when solving an exercise problem in a
textbook. This would obviate the need for pointless searches through the book
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
for a relevant example. Finally, shifting the focus of attention to the structure of the expository text rather than looking at the 'failure' of particular students to understand might help us advance our understanding of problem solving behaviour, and may help maximize the rate at which all students learn.
General explanation of the overtaking vehicles problem
A car travelling at a speed of 30 miles per hour (m/h) left a certain place at 10:00 a.m. At 11:30 a.m. another car departed from the same place at
40 m/h and travelled the same route. Both cars therefore travelled the same
distance. In how many hours will the second car overtake the first car?
As you can see, the two cars travel at different speeds and leave at different
times: The first car leaves 1 \ hours before the second car (11:30-l0:00); The
second car travels 10 m/h faster than the first one (40 m/h-30 m/h). Since the first car has already been travelling for 1 \ hours you can work
out the distance it travelled. If it goes 30 miles in an hour then it will have
travelled 45 miles in 11 hours (30 m/h x 11 hours). The problem now becomes: How long will it take the second car to make
up this 45 miles by travelling 10 m/h faster?
In 1 hour the second car will travel 10 miles more than the first car, so it
will take 4.5 hours to make up the 45 miles (45 h -f- 10 m/h). In other words it will take 4.5 hours for the second car to overtake the first car.
1. Another way of solving this type of distance-speed-time problem is to
use an equation:
a] a) If you know the speed and time of a vehicle, then you can find the
distance it travelled by using the equation:
Distance = Speed x Time
For example, if a car travels at 40 m/h (Speed) for 2 hours {Time) then
it goes 80 miles {Distance - found by multiplying 40 by 2).
b] b) In problems like the one above, there are two vehicles (let's call them vehiclel and vehicle2). The equation for each vehicle would
be:
distance = speedyeucie\ x ft°/neVehiciei
and
distance = speedvchiclc2 x timevehicie2
c] c) But the two vehicles travel the same distance. So the distance travelled by one vehicle is equal to the distance travelled by the other. If the distances are equal then the speed x time for each vehicle must be equal too, so the equation to use when there are two vehicles travelling the same distance is:
Speedy^hiclel ^ ^//M£'Vehic!el Sp€€dvehicle2 X tiffîCvehick'2
This content downloaded from 141.101.201.167 on Sat, 28 Jun 2014 18:15:54 PMAll use subject to JSTOR Terms and Conditions
Hall, R., Kibler, D., Wenger, E. & Truxaw, C. (1989). Exploring the episodic structure of
algebra story problem solving. Cognition and Instruction 6(3): 223-283.
Holyoak, K.J. & Thagard, P. (1989). Analogical mapping by constraint satisfaction. Cognitive Science 13(3), 295-355.
Holyoak, K.J. & Thagard, P. (1990). A constraint satisfaction approach to analogical mapping and retrieval. In K.J. Gilhooly, M.T. Keane, R. Logie & G. Erdos, eds, Lines of Thinking:
Reflections on the Psychology of Thought (Vol. 1). Chichester: John Wiley.
Kolodner, J. (1993). Case-Based Reasoning. San Mateo, CA: Morgan Kaufmann.