48
Implementing the “Wisdom of the Crowd” The Internet Economy With i) Ilan Kremer and Yishay Mansour 1 ii) Jacob Glazer and Ilan Kremer
| Date post: | 27-Dec-2015 |
| Category: |
Documents |
| Upload: | donald-edwards |
| View: | 218 times |
| Download: | 0 times |

1
Implementing the “Wisdom of the Crowd”
The Internet Economy
With
i) Ilan Kremer and Yishay Mansour
ii) Jacob Glazer and Ilan Kremer

Study Internet (but not only) applications like Crowd funding, Tripadvisor, Netflix, Waze, Amazon, OKCupid, and many more, that attempt to implement the wisdom of the crowd.
i) The multi-arm bandit problem (first paper). Rel. Lit: “Optimal Design for Social Learning” Horner and Che
To study these applications, we take a mechanism design approach to two classical economic problems.
ii) Information cascading (second paper). Rel. Lit: “Optimal Voting Schemes with Costly Information Acquization” Gershkov and Szentes
These sites (often called expert sites) collect information from customers while making recommendations to them.
MOTIVATION

Model Agents arrive sequentially:
o Have prior on possible rewards from a set of actions/arms. o Each makes one choice, and gets reward.
Only planner observes (part of) the history. Interested in maximizing social welfare. Choose what information to reveal.
Agents are strategic. Know planner’s strategy
Model I: Planner observes the whole history, choices & rewards. When IC constraints are ignored this is the
well known Multi Arm Bandit problem.
Model II: Planner observes only the choices made by agents but not their rewards.
When history is fully revealed, this is the model of Information Cascade (with costly signals).

Research Question
Controlling revelation of information, can the planner induce exploration, prevent an early information cascading?
What is the optimal policy of the planner.
What is the expected loss compared to the first best outcome?

Waze: Social Media User based navigation
Real time navigation recommendations based on user inputs; Cellular and GPS.
Recommendation dilemma:o Need to try alternate routes
to estimate time
Works well only if attracts large number of users
Motivation:
The site’s manager is interested in maximizing the social welfare

6
Websites such as TripAdvisor.com and yelp.com (and many others) try to Implement the ‘wisdom of the crowds’.
Motivation
How the ranking is done? How it should be done?
They collect information from customers while making recommendations to them by providing a ranking.
The site’s manager is interested in maximizing the social welfare
Works well only if attracts large number of users

Motivation
Also Crowd funding websites (InvestingZone or CrowdCube), or matching site like OKCupid, and many others, are all relevant examples.
In both cases the same conflict arises between the site and the agents.
Your Amazon.com
“We compare your activity on our site with that of other customers, and using this comparison, are able to recommend other items that may interest you in your Amazon.com Your recommendations change regularly based on a number of factors, including ….., as well as changes in the interests of other customers like you. “

In an interview to the NYT (Sep. 6, 2014), Mr. Rudder CEO and cofounder of OkCupid said:
“We told users something that wasn’t true....People come to us because they want the website to work, and we want the website to work.”
“Guess what, everybody,” he added, “if you use the Internet, you’re the subject of hundreds of experiments at any given time, on every site.”
We are interested in how much “manipulation” (experimentation) can be exercised when agents are strategic.
Motivation

Multi-Arms Model
(simplest possible example)
Two actions: a1 and a2
N risk-neutral agents
Each action has a fix unknown reward R1 and R2 (r.v).
Prior over the rewards; E[R1] > E[R2]=μ2
Planner observes choices and rewards.
provides agent n with message mn • Some information about past.

Example Action 1 has prior Uniform in [-1,+2] Action 2 has prior Uniform in [-2,+2]
No information:• All agents prefer action 1, the better a priori action• No exploration
Full information: • Assume first agent observes a value of zero or above • Then no incentive for other agents to explore action 2
0-1 2
-2 2
Can we do better?
Action 2Action 1

Impossibility Example Action 1 prior Unif[3/4, 5/4]
Action 2 prior Unif[-2,+2]• E[R2] = 0 < R1
Agent n knows:• all prior agents preferred action 1• Hence, he too prefers action 1
Planner has no influence
Action 2
Action 1
µ2
0 +2-2
• Required Assumption:
Pr[ R1 < μ2 ] > 0

• Basic properties of optimal mechanism:
A mechanism is a sequence of functions {Mt}tєN where
Mt: Ht-1 → M
Sufficient to consider recommendations policy that are IC (Myerson 1986).
{Пt}tєN where Пt: Ht-1 → {1,2}
Two natural IC constraints• E[R2-R1 | recommend(2) ] ≥ 0
• E[R1-R2 | recommend(1) ] ≥ 0
Sufficient to consider only action 2• A mechanism that is IC for action 2 is
automatically IC for action 1

The optimal policy is a partition policy
• Recommends to first agent action 1
oThe only IC recommendation
• If both actions are sampled, recommend the better
• Mapping from values of r1 to agent that explores
• Conclusion: Consider only partition policy
R1
agent 4 agent 4agent 3 agent 5No exploration

The optimal policy is a threshold policy
• Agent 1: recommend action 1. Planner observes reward r1
• Agent 2: explores for all values below E[R2] (and above)
• Thresholds
• Agent t >2:o Both actions sampled: recommend the better actiono Otherwise: If r1 < θt then recommend action 2 otherwise action 1
Intuition: Inherent tradeoff between two potential reasons for being recommended action 2
Agent 2 Agent 3 Agent 4 Agent 5
µ2
No exploration
• IC constraints are tight

Recall the basic IC constraint:
OPTOMALITY
1 2 1 1
2 1 2 1
r ,R R r
[R – R ] [ – R ] 0n nI I
d d
Proper Swap:
B2 B1
Agent t1
(5) Agent t2 (10)
R1 b2 b1
1 1 1 1 2 2
2 1 2 1( ) ( )R b B R b B
R d R d
Since B2<B1 Pr[b2]>Pr[b1]
What is NOT a threshold policy:
Exploitation > 0 Exploration < 0

Information Cascading Modelplanner observes only choices not outcomes
AGENT: o risk-neutral arrive sequentially.o Known arrival order; do not observe history.o Each agent is asked to choose an action and then get a reward
Before making a choice, an agent, at a cost c>0, can obtain an informative signal.
Two actions A and B. One action is “good” and yields a payoff of one while the other is “bad” and yields a payoff of zero.

There exists a planner who observes (only) the chosen actions (A or B) taken by all agents.
For every t the planner decides what message to send the agent.
Planner's objective is to maximize the discounted present value of all agents' payoffs.
Let pt : Ht-1 → [0,1] denotes planner’s posterior after t-1 observations.
Let μt : {M} → [0,1] denotes agent t’s posterior.

Information structure and belief’s law of motion
• If A is the good action, the signal gets the value sa
with probability 1
• If B is the good action, the signal gets the value sb
with probability q, and sa with probability 1-q. Note that sb is fully revealing.
If a signal is obtained by agent t, then
0 1p0
sa sa sa
sb
Prob (A)
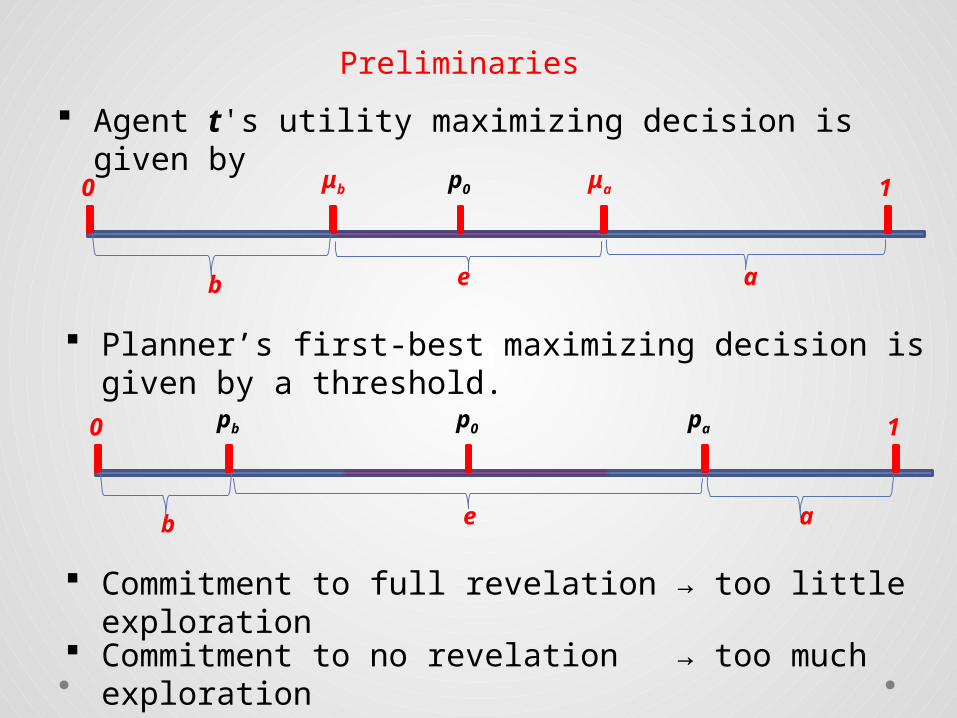
Agent t's utility maximizing decision is given by
0 μb 1μap0
Planner’s first-best maximizing decision is given by a threshold.
Commitment to full revelation → too little exploration
Commitment to no revelation → too much exploration
b ae
Preliminaries
0 pb 1pap0
b ae

• Basic properties of optimal mechanism:
The optimal mechanism is:
Phase one: As long as there is no conflict between the planner and agent t,
(i.e., pt є [μb , μa] ) full revelation is exercised.
20
0 1μap0
e
20
0 1μap0
Or
t =1
t =2
t =3
t =
e
(ii) Public Mechanism
(i) A Recommendation Mechanism where Mt: Ht-1 → {a,b,e}
(iii) Three phases
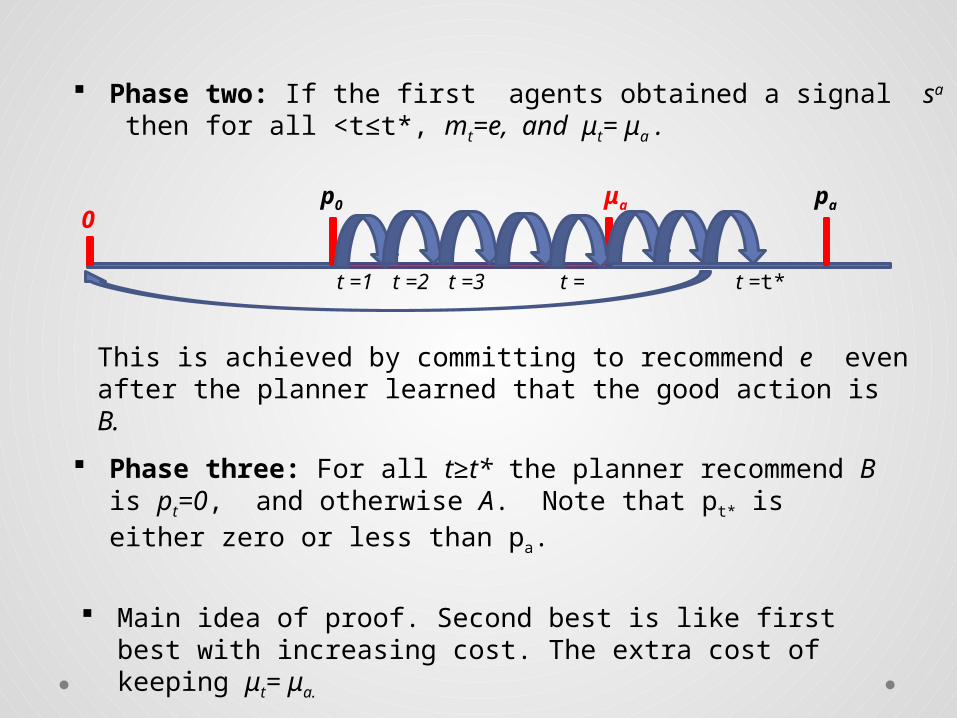
Phase two: If the first agents obtained a signal sa then for all <t≤t*, mt=e, and μt= μa .
This is achieved by committing to recommend e even after the planner learned that the good action is B.
0μap0
t =1
t =2
t =3
t =
Phase three: For all t≥t* the planner recommend B is pt=0, and otherwise A. Note that pt* is either zero or less than pa.
t =t*
pa
Main idea of proof. Second best is like first best with increasing cost. The extra cost of keeping μt= μa.

Thank You !

23
Thank You !

24
Your Amazon.com
We compare your activity on our site with that of other customers, and using this comparison, are able to recommend other items that may interest you in Your recommendations change regularly based on a number of factors, including ….., as well as changes in the interests of other customers like you.

25
Example Assume: R₁ ~ U [-1 , 5] R2 ~ U [-5 , 5]
N large (optimal to test the two alternatives).
Full Transparency Agent 2 chooses second alternative only if
R₁≤0. Otherwise all agents choose the first alternative.
Outcome is suboptimal for large N
0 5
5-1
-5

26
• recommends 2nd alternative to agent 2 whenever R₁≤1.
• This is IC because o E[R1 | recommend(2) ] = 0
This outcome is more efficient than the one under full transparency.
But we can do even better.
0 5
5-1
-5
1

27
• recommends third agent to use 2nd action if one of two cases occurs
i. Second agent tested 2nd action (R₁≤1) and the planner learned that R₂>R₁.
ii. 1<R₁≤1+x , so the third agent is the first to test 2nd action.
Agent n>4 never explores regardless of N. So at most 3 agents choose the wrong action.
1
R1
1+x=3.23
I2 I3
0=E[R2]
I4
-1 5

28
IC Analysis
• Agent t1 unchangedo Added b2 to and subtracted b1 o Proper swap implies equal effect.
• Agents other than t1 and t2
o Before t1 and after t2: unchanged
o Between t1 and t2:
• Gain (Pr[b2] - Pr[b1]) max{r1,r2}
• IC holds
1 2 1 1
2 1 2 1
r ,R R r
[R – R ] [ – R ] 0n nI I
d d
1tI

29
Multi-Arm Bandit• Simple, one player, decision
model
• Multiple independent (costly) actions
• Uncertainty regarding the rewards
• Tradeoff between exploration and exploitation (Gittins index)

30
Reflecting on Reality• Report-card systems
o Health-care, education, …o Public disclosure of
information • Patients health, students
scores, …
• Pro:o Incentives to improve qualityo Information to users
• Cons:o Incentives to “game” the
system • avoid problematic cases
We suggest a different point of view

31
Websites such as TripAdvisor.com and yelp.com (and many others) try to Implement the ‘wisdom of the crowds’.
Motivation: The New Internet Economy
How the ranking is done? How it should be done?
They collect information from customers while making recommendations to them by providing a ranking.
The site’s manager is interested in maximizing the social welfare
Works well only if attracts large number of users

32
Recommendation Policy
Recommendation Policy: Proof (Myerson’s (1986)):
• For agent n,o Gives recommendation xn
ϵ{a1,a2}
• Recommendation is IC ifo E[Rj – Ri | xn = aj ] ≥ 0
• Note that IC Implies: recommend to agent 1 action a1
• Claim: Optimal policy is a Recommendation Policy
• M(j,n) – set of messages that cause agent n to select action aj.
• H(j,n) – the corresponding histories
• E[Rj-Ri|m] ≥ 0 for m ϵ M(j,n)
• Consider the recommendation aj after H(j,n)
• Still IC, identical outcomes

33
Partition PolicyPartition Policy: Optimal policy is a partition:
• Recommendation policy• Agent 1: recommending
action a1 and observing r1
• If r1 in In , n≤No Agent n the one to explore a2
o Any agent n’>n uses the better of the actions
• Payoff max{r1,r2}
• If r1 in IN+1 no agent explores a2
• Disjoint subsets In
• Recommending the better action when both are knowno Optimizes sum of payoffso Strengthen the IC
Agent 2
Agent 3

34
Only worse action (a2) is “important”
Proof:
Lemma: Any policy that is IC w.r.t. a2 is IC w.r.t. a1
• Let Kn denotes the set of histories that cause xn=a2
• E[R2–R1|hϵ Kn] ≥0o Since it is an IC policy
• Originally: E[R2–R1] <0
• Therefore E[R2 – R1 | not in Kn] < 0

35
Optimality → Tight IC constraintsLemma:
Proof:
If agent n+1 explores (Pr[In+1]>0), then agent n has a
tight IC constraint.
• Move exploration from agent n+1 to agent n (r1 ϵ ѴϵIn+1)
• Improves sum of payoffs o For r1 ϵѴ replaces r1+R2 by R2 + max{r1,r2}
• Keeps the IC for agent n (since it was not tight) and n+1
(remove exploration)
R1
In In+1( Ѵ )
r1 n I ,R2 R1
R2 R1d r1In
2 R1d 0

Information Cascading• Bikhchandani, Hirshleifer, and Welch
(1992), Banerjee (1992)
36
OR
Agents ignore (or do not acquire) own signals.
Same exercise is conducted but now planner observes only actions, and private signals are costly (Netflix)

37
The Story of Coventry and Turing
• In November 1940, Prime Minister, Winston Churchill, knew several days in advance that the Germans would attack Coventry but deliberately held back the information.
• His intelligence came from the scientists at Bletchley Park, who, in utmost secrecy, had cracked the Enigma code the Germans used for their military communications.
• Warning the city of Coventry and its residents of the imminent threat would have alerted the Germans to the fact that their codes had been cracked.
• Churchill considered it worth the sacrifice of a whole city and its people to protect his back-door route into Berlin’s secrets.
• The imitation game

38
How good is optimal?!• The expected loss due to IC
o Bounded (independent of N)
• Bounding the number of exploring agents by:
Where
1 2
1 2
1 2
2 1
,
( )RR R
R R

39
Proof
Consider the ‘exploitation’ term for agent n>2. It is an increasing sequence as for higher n the planner becomes better informed. Hence, it is bounded from bellow by the ‘exploitation’ term of agent 3. This in turns is bounded below by α.
The sum of the ‘exploration’ terms is bounded by 1 2
1 2 1 1
2 1 1 2
r ,R R r
[R – R ] [R ]n n
n
I I
IC d d
𝑒𝑥𝑝𝑙𝑜𝑖𝑡𝑎𝑡𝑖𝑜𝑛 𝑒𝑥𝑝𝑙𝑜𝑟𝑎𝑡𝑖𝑜𝑛

40
Extensions

41
Introducing money transfer
• Basically same policy• Planner invest all the money in agent 2
o Gets more exploration as early as possible.
• Otherwise, same construction.• When money costs money:
o The planner will subsidize some exploration of agent 2o Other agents as before.

42
Relaxing agents knowledge• So far agents knew their exact place
• Relaxation: Agents are divided to blockso early users, medium, late users
• Essentially the same property holdso In each block only the first explores
• Blocks can only increase social welfare
• The bigger the blocks the closer to first-best

43
Optimal Policy: performance
• Action 1 is better:o Only one agent explores action 2
• Action 2 is better:o Only a finite number of agents explore action 1. This number is
bounded and the bound is independent of N.
=> Conclusion Aggregate loss compared to first best is bounded

44
Now to some proofs …

45
Basic IC constraints
• Recommendation policy
o With sets In
1 2 1 1
2 1 2 1
r ,R R r
[R – R ] [ – R ] 0n nI I
d d
Positive (exploitation) Negative (exploration)
R1
In-1 In In-1
2 1 2E [ R – R | x a ] 0n
In In+1E[R2]

46
Threshold policy• Partition policy such that In = (in-1,in]
• I2 = (-∞,i2)
• IN+1 = (iN,∞)
• Main Characterization: The optimal policy is a threshold policy
No exploration Agent 2 Agent 3 Agent 4 Agent 5R1

47
Motivation: The New Internet Economy
Also websites such as Netflix, Amazon OKCupid, Tripadvisor and many others.
Regardless of what the planner/site observes, in both cases the same conflict arises between the site and the agents.

48
Crowd Funding sites collect information from investors by monitoring their choices and, use this information in making recommendations to future investors.
Motivation: The New Internet Economy
Also websites such as Netflix, Amazon OKCupid, Tripadvisor and many others.
Regardless of what the planner/site observes, in both cases the same conflict arises between the site and the agents.

















