52
Improving Robustness in Distributed Systems Jeremy Russell Software Engineering Honours Project
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 219 times |
| Download: | 0 times |

Improving Robustness in Distributed SystemsJeremy RussellSoftware Engineering Honours Project

Overview
Introduction What is a distributed system What is robustness Aims of study
Method Development of simulated model Investigation of model
Results & Findings

Introduction
What is a distributed system? Network of connected entities (agents) Entities communicate via message
passing Agents can engage with any other agent
Decentralised control Contrast to P2P with centralised indexes
Behavior of individual agents conform to the goals of the system

Introduction
Example: Web services Services are offered by a collection
remote computers in a network Services are combined to build
complex super-services Appearance that super-services are
provided by a single interface agent (web-server)

Introduction
Insurance policy comparison service
Insurance Broker

Introduction
What is robustness? Correct operation under varied
conditions High tolerance of failure (extreme
conditions) Graceful in defeat

Introduction
Aim of study To improve robustness in distributed systems Implementation and comparison of two
alternative systems
How is robustness achieved? Redundancy Regeneracy (Adaptation) Load balancing

Method
Simulation model Offers services (tasks) Responds to service requests Services are highly coupled Agent based network consisting of 20
agents Measures
Success Response time

Method
Model framework Components Network mechanics Sequence of execution Representation of time Agent communication
Messages

Method
Components Object oriented Simulator object
Controls timing of events Agent objects
Provide services Communicate with other agents
Message objects Method of communication

Method
Components

Method
Components

Method
Network mechanics Underlying interconnection network (Internet) An agent can engage any other agent Agents form a subset of all possible
relationships Routing and propagation latencies are
abstracted by the Simulator Message types
Service Capability sharing Agent information

MethodNetwork mechanics (underlying network)

MethodNetwork mechanics (agent relationships)

Method
Sequence of execution Simulation is sliced into a sequence of time
steps (abstraction of real time) In each time step:
Messages are forwarded by Simulator Agents are prompted sequentially (any ordering)
to execute the time step Execute scheduled services Respond to received messages
Messages are received and ordered by Simulator

Method
Sequence of execution

Method
Representation of time Floating point number
Global time (GT) Current time step
Local time (LT) Function of the total number of processing cycles
used prior to event
Result: Time = GT.LT
available cycles total
used cycles totalused time%

Method
Agent communication Messages
Passed between agents Forwarded via Simulator Types
Request, Response, Forward, Receipt 11 across the 3 areas:
Service Capability sharing Agent information

Method
Agent communication Role of Simulator
Accepts messages and calculates delivery time
Applies latency
Orders messages according to time of delivery
Forwards all messages that reach their destination within the current time step

Method
Agent communication (sending)
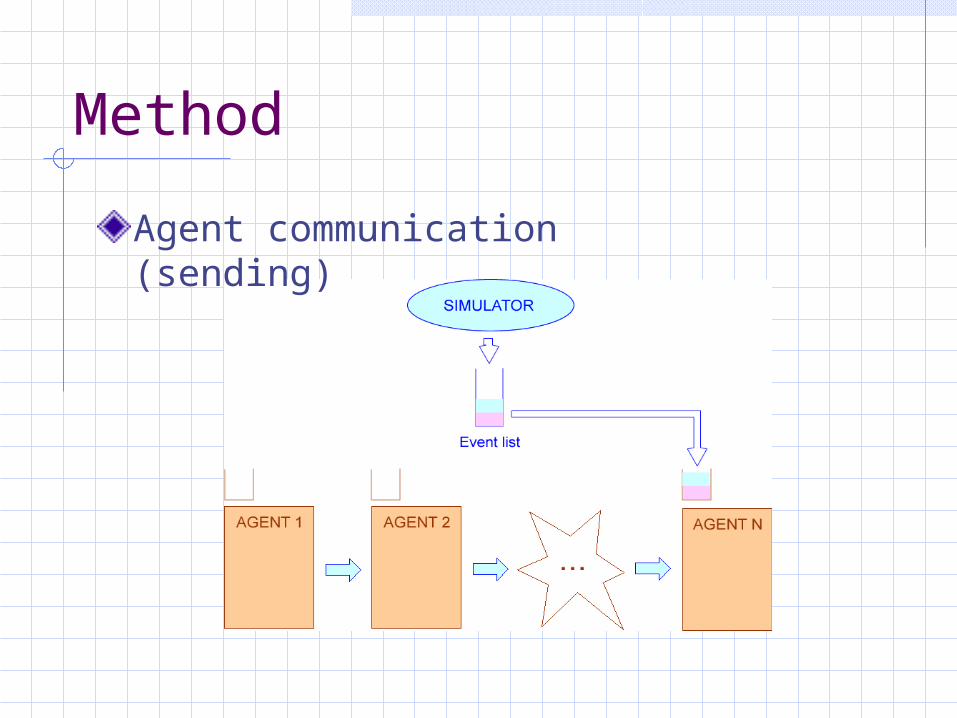
Method
Agent communication (sending)

Method
Agent communication (receiving) Messages in inbox are processed
according to delivery time At start of time step inbox contains all
messages for that time step Agent only reads a message when agent
time reaches time of delivery

Method
Service Unit of work provided by an agent Can be requested by external users or
agents within the system Complex workflows (dependencies)
Dependence represents the results of a service being used by another service
Virtual knowledge communities

Method
Service Example, task 1
1: do part12: do part23: request task2,task3,task4 wait task24: do part3 wait task3,task45: do finish

Method
Virtual knowledge communities Groups of agents with similar interests
Coupled services Benefits
More advantageous agent relationships Priority treatment for agents within a
community Improvements in reliability and response
times

Method
Virtual knowledge communities

Method
Agent implementation Service advertising Knowledge
Validation Scheduling Failure Performance metrics Entropy Strategy

Method
Service advertising (indexing) Performance metrics mitigate risk of
inefficient routing

Method
Knowledge Two forms
Neighbour relationships Capabilities (services)
Fixed storage allocation Services require twice the storage of a
relationship Initialised to:
8 relationships (50%) 4 services (50%)

Method
Knowledge Neighbour relationships
Services offered by neighbour is recorded Service directory is stored by each agent
Ranked collection of agents that provide a service Ranking based on weighted average of past results
Performance and utilization metrics are recorded Capabilities (services)
Space not used by simulation Allocation represents the demands of data carried
by a service (i.e. databases)

Method
Knowledge Validation
Occurs at set intervals Updates services advertised by
neighbours Updates neighbour utilization

Method
Routing Agents have multiple options Choose the best route based on
knowledge Rerouting requests upon failure
Investigations Limiting number of hops Limiting number of routing options
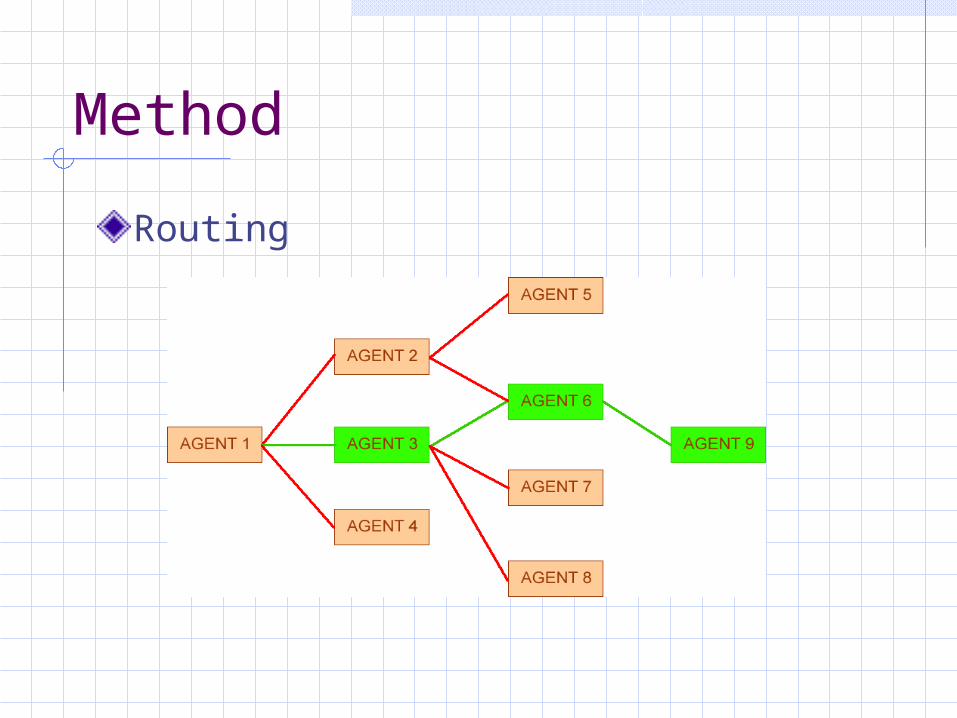
Method
Routing

Method
Scheduling Agent receives service request for
service offered by agent Agent schedules service by
appending to service schedule Services are suspended if blocked Services resumed are pre-pended to
service schedule Fairness

Method
Failure Period of time an agent is non-
responsive Randomly generated for each time step Based on the reliability (parameter) of
network Implemented as a failure schedule
100 time steps, looped Ensures identical conditions for comparison
of the systems under analysis

Method
Performance metrics Weighted measures of ability
Response times Failures
Used to assess and rank neighbours Usage records
Popularity of Relationships Services
Used to reallocate storage

Method
Entropy Perceived unreliability of system Maintained by each agent Formed through interactions with
neighbours and subsequent analysis Will evolve over time Triggers strategic response

Method
Strategy Response to environmental conditions Aims to improve service delivery
Two alternatives implemented/tested Standard approach Adaptive memory approach

Method
Standard approach Fixed allocations of storage Aims to store most frequently used
Relationships Services
Weighted usage records Swap least popular allocated knowledge
with most popular unallocated knowledge
Swapping occurs at set intervals

Method
Adaptive memory approach Dynamic allocations of storage Manipulation
Triggered by entropy Tied to strategy
Low reliability = Increase neighbours High reliability = Increase services
Limited to avoid extreme reactions

Method
Adaptive memory approach Expectations
High reliability More services offered by agents Less time of response to global requests Agents specialise in services according to its
employment. Low reliability
More contingencies or routing options maintained by agents
Higher probability of success Brokers and workers
Run-time evolution

Method
Investigation of model Effect of varying indexing depth Effect of limiting hops from source of
a request Effect of limiting routing options
explored by agents Effect of enforcing a minimum level of
redundancy
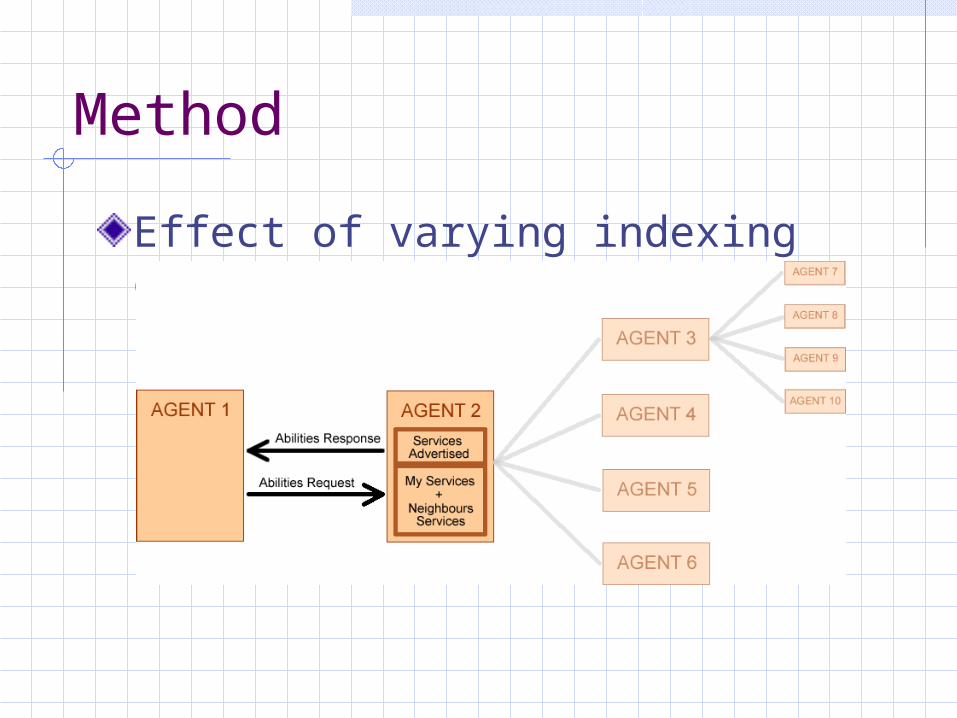
Method
Effect of varying indexing depth
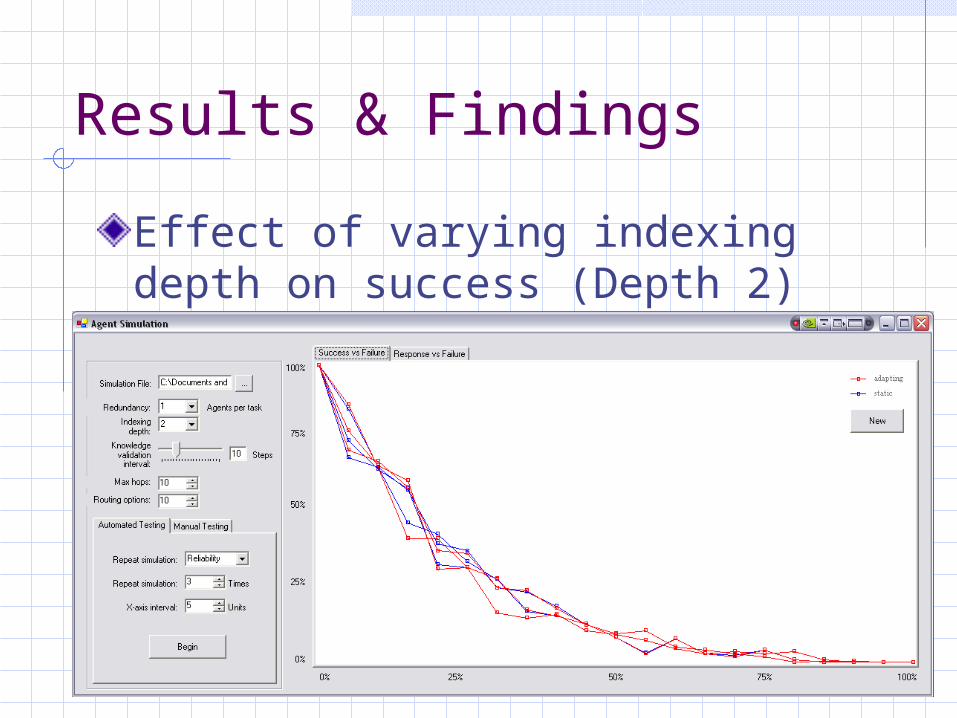
Results & Findings
Effect of varying indexing depth on success (Depth 2)

Results & Findings
Effect of varying indexing depth on success (Depth 3)

Results & Findings
Effect of varying indexing depth on success (Depth 4)

Results & Findings
Effect of varying indexing depth on time (Depth 2)

Results & Findings
Effect of varying indexing depth on time (Depth 3)

Results & Findings
Effect of varying indexing depth on time (Depth 4)

Results & Findings
Conclusions Comparison of two systems indicates
occasional improvements made by adaptive memory technique Improved through optimisations
Results indicate that increasing indexing depth does not improve robustness
Affecters Limitations of hops and routing options Service dependencies

Questions

















