26
In-Memory Data Grid Ampool - Girish Verma - Chinmay Kulkarni
| Date post: | 21-Jan-2017 |
| Category: |
Documents |
| Upload: | chinmay-kulkarni |
| View: | 30 times |
| Download: | 1 times |

In-Memory Data Grid Ampool
- Girish Verma- Chinmay Kulkarni

Latency- Why do we care about it ?
- because Amazon, Google and other financial firms care about it :)
- Google: 500ms == 20% traffic drop- Citi: 100ms == $1M
- How we reduce it ?- reduce data access time
- Cache- Redis, Memcached

Redis - Master - slave configuration
- slaves are just redundant copies
- Mesh topology with TCP connections between nodes
- How client reads the data ?

Memcached- There is nothing like memcached cluster
- Everything needs to be managed by client

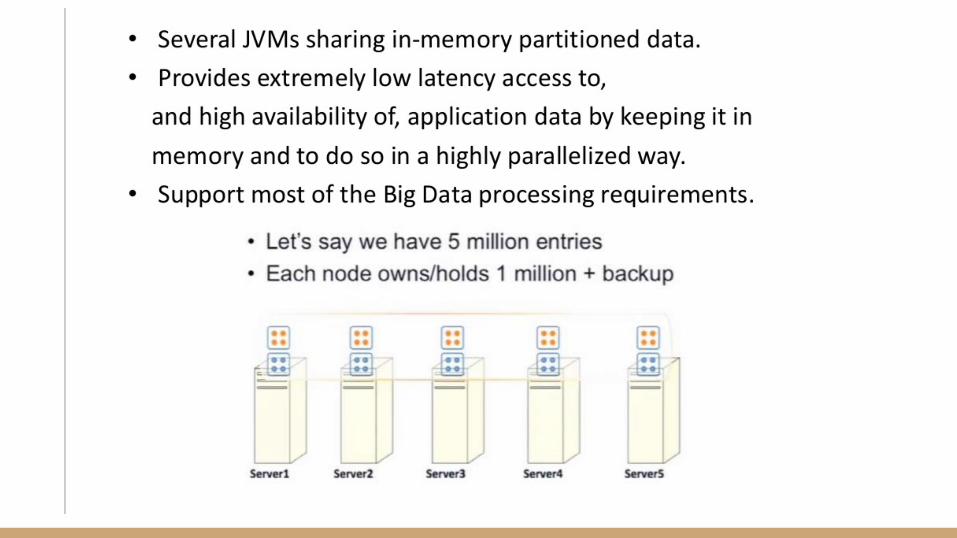
In-Memory Data Grid- Sophisticated In-memory data store
- Low latency Reads and Writes
- Partitioning and Replication
- Highly Scalable and Available
- Work with your existing data store

Ampool- Operational Analytics
- Store, Analyse and Serve your data from same place
- Active Data Store between compute and long-term storage
- Benefits
*Reference - http://docs.ampool-inc.com/adocs/core/index.html

Ampool
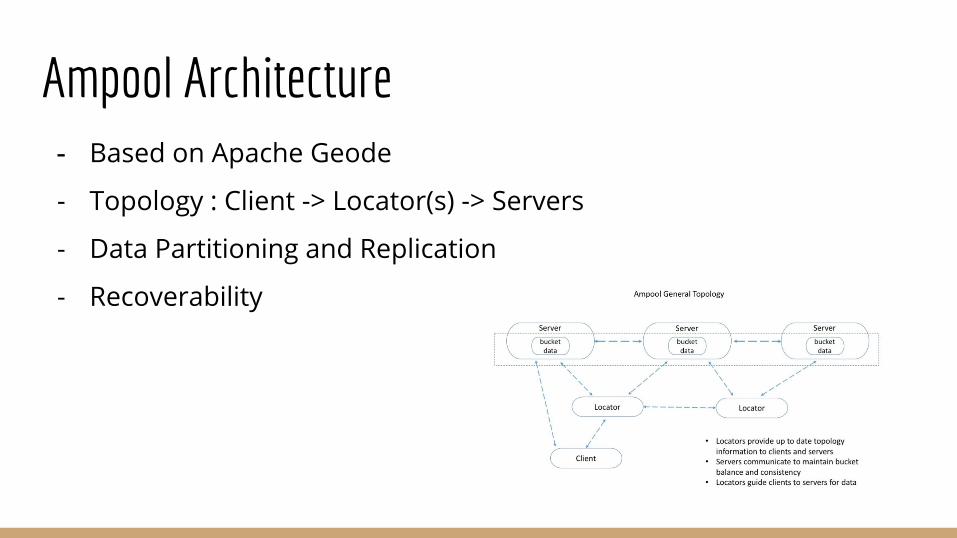
Ampool Architecture- Based on Apache Geode
- Topology : Client -> Locator(s) -> Servers
- Data Partitioning and Replication
- Recoverability


Ampool Vs Others- In-memory Data Grids (GridGain, Hazelcast)
- Designed for low latency, No or embedded analytics, Limited
persistence options
- In-memory File Systems (Alluxio)
- FS Interface with high serialization overhead, No low-latency
workloads
- In-memory Databases (MemSql, SAP-Hana)
- Vertically integrated, designed for transactions, proprietary and
expensive, Local persistence only

Demo time !!!
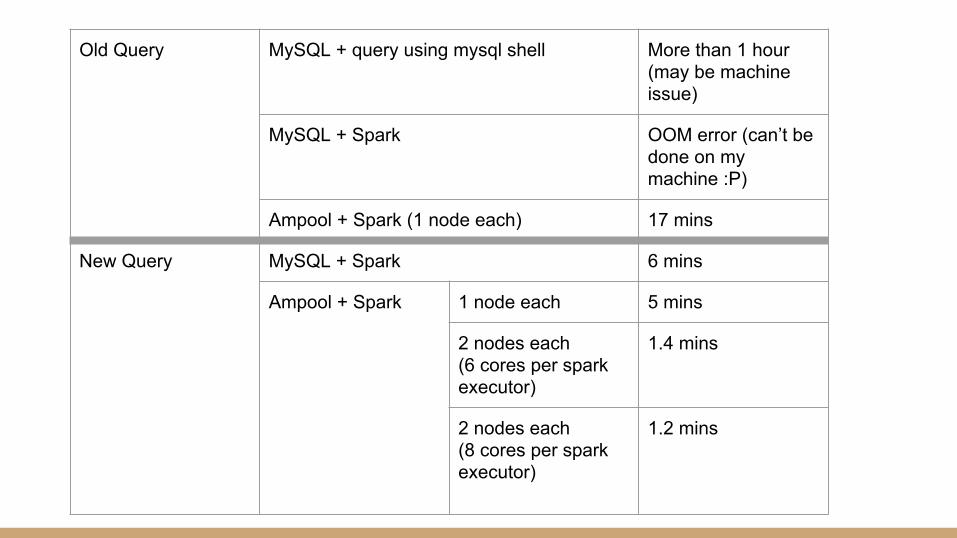
Old Query MySQL + query using mysql shell More than 1 hour (may be machine issue)
MySQL + Spark OOM error (can’t be done on my machine :P)
Ampool + Spark (1 node each) 17 mins
New Query MySQL + Spark 6 mins
Ampool + Spark 1 node each 5 mins
2 nodes each (6 cores per spark executor)
1.4 mins
2 nodes each (8 cores per spark executor)
1.2 mins

Thank you

Extra Info


REDIS IMDGs(Ampool/Gemfire/Geode)
No SQL Support SQL Support (Ampool)
Master Slave architecture Peer-to-Peer based configuration.
No member discovery service, managing slaves a bit difficult and not possible to bring up a crashed slave.
Inbuilt member discovery service (Locators).
Single threaded Multi Threaded. Configurable
Application-level sharding Auto-sharding. Auto rebalancing
Application must know which node has the data and which node to send request to
Application unware about the partitioning. Query automatically routed to the node where data resides
Based on Redis Virtual Memory subsystem. Stores Redis objects
JVM based.

Redis and in-memory data grids are pretty different animals. I would characterize IMDG's like Geode to be concurrent write intensive, and have flexible data models. It also scales out better than Redis in a more automated fashion.Redis is a great read-intensive cache. It also has a powerful data model, but you have to use their data models. Example: If you want to run calculations on lists or sets, they have powerful operations you can call.
IMDG's such as Geode were built with the rise of automated trading in the finance industry.
https://news.ycombinator.com/item?id=10596859
http://vschart.com/compare/memcached/vs/gemfire
http://www.infoworld.com/article/3063161/application-development/why-redis-beats-memcached-for-caching.html

If avoiding disk I/O is the goal, why not achieve that through database caching?
Caching is the process whereby on-disk databases keep frequently-accessed records in memory, for faster access. However, caching only speeds up retrieval of information, or “database reads.” Any database write – that is, an update to a record or creation of a new record – must still be written through the cache, to disk. So, the performance benefit only applies to a subset of database tasks. In addition, managing the cache is itself a process that requires substantial memory and CPU resources, so even a “cache hit” underperforms an in-memory database.http://www.mcobject.com/in_memory_database
http://www.slideshare.net/MaxAlexejev/from-distributed-caches-to-inmemory-data-grids
https://spiegela.com/2014/04/30/but-i-need-a-database-that-scales-part-2/

Distributed - in memory cache● Group membership and failure detection● Consistent hashing to distribute data across cluster of nodes.● Fault tolerant●

ComparisonsData - ~1 GB / ~15 million records
Local - 1 ampool server 1 spark node with 4 threads -> 10 mins
Local - 1 ampool server 1 spark node with 2 threads
AWS - 1 ampool server 1 spark node with 4 threads
AWS - 2 ampool server 2 spark node
Rewrite sql query with Spark
AWS - change spark version and try with parquet data file

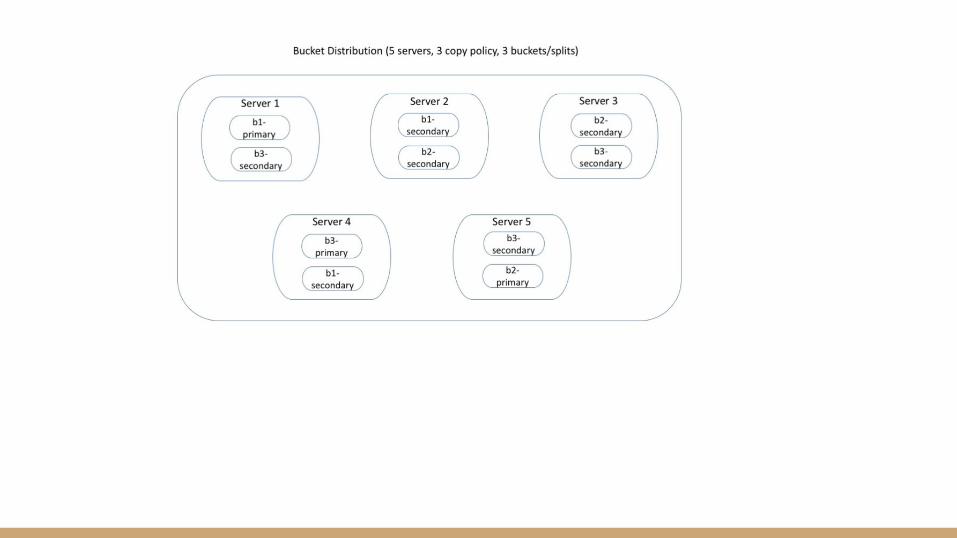
Ampool cluster With No redundant copies for table:
Initial cluster members - locator, server1
-> Stop server1 - no queries can be served
Restart server1 everything works
-> Start server2 now and stop server1 - no queries can be served
Data distribution doesn’t happen automatically

Ampool cluster With redundant copies for table set to 1:
Initial cluster members - locator, server1, server2
Load data - which will get distributed to both the servers
-> Stop on of the server - everything works fine
-> Stop both servers - no queries can be served
Start one of the servers - still no queries can be served
Start both servers - everything works fine

Ampool cluster With redundant copies for table set to 1:
Initial cluster members - locator, server1 - Load data - the data will be on only one server
-> start a new server - server2 and stop server1
Queries work :) - because data is replicated to server2 when it started
-> start server1 and stop server2
Queries still work - same reason as above
-> stop both servers and start one of them
Queries work :)
-> When only server1 is up add data to it
Start server2 and Stop server1
Queries on new data work with only server2 running

















